文章目录
- HBase的高可用
- 一、HBase高可用简介
- 二、搭建HBase的高可用
- 1.在HBase的conf文件夹中创建一个backup-masters的文件
- 2.修改backup-masters,添加作为备份master的节点信息
- 3.分发backup-masters文件到其他的服务器
- 4.重新启动HBase
- 5.查看web ui
- 三、测试高可用
- 1.尝试杀掉hadoop001的HMaster进程,模拟hadoop001宕机
- 2.查看hadoop001的web ui
- 3.再查看hadoop003的web ui
- 4.进入HBase shell,可以继续使用
- 5.再次运行Java api程序,查看结果
- 四、高可用原理
- 五、HBase的高可用架构及原理
- 1.系统架构
- 2.Client
- 3.Master Server
- 4.Region Server
- 5.Region
- 6. Store
- 7. MemStore
- 8. StoreFile
- 9. WAL

HBase的高可用
一、HBase高可用简介
HBase集群如果只有一个master,一旦master出现故障,将导致整个集群无法使用,所以在实际的生产环境中,需要搭建HBase的高可用,也就是让HMaster高可用,也就是需要再选择一个或多个节点也作为HMaster,但是只有一个是active,其他的都为backup master当active的master宕机时,从backup master中选举一个作为active。
二、搭建HBase的高可用
1.在HBase的conf文件夹中创建一个backup-masters的文件
进入conf目录下:
新建文件:
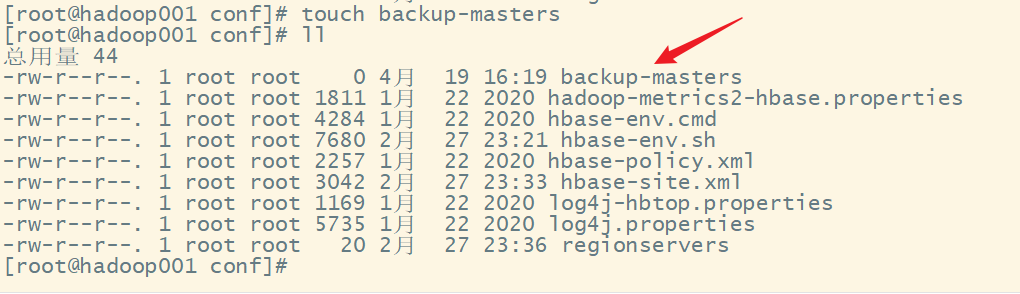
2.修改backup-masters,添加作为备份master的节点信息
修改backup-masters:

添加备份节点:

3.分发backup-masters文件到其他的服务器

4.重新启动HBase
查看 hadoop001:
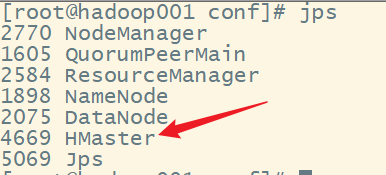
查看hadoop002:
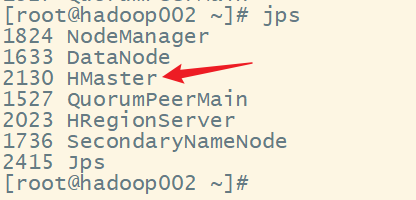
查看 hadoop003:
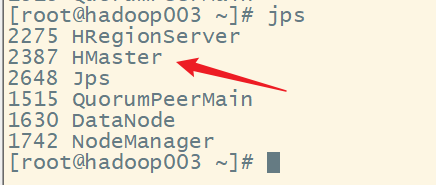
5.查看web ui
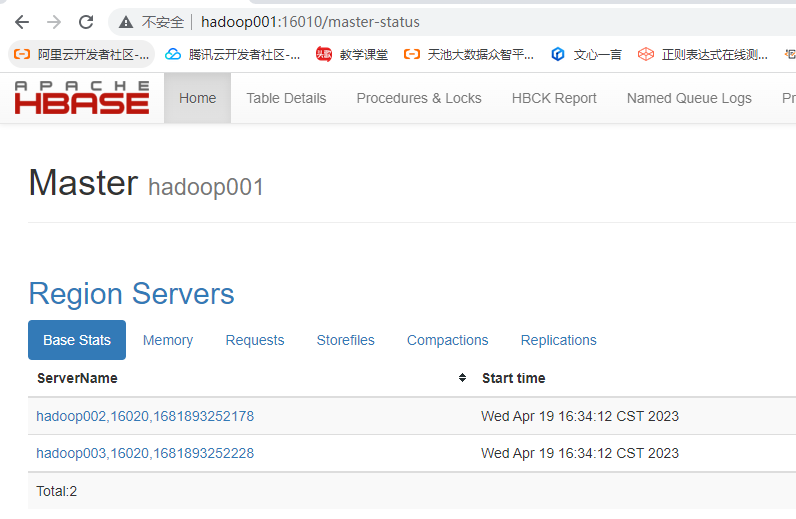
备份节点:
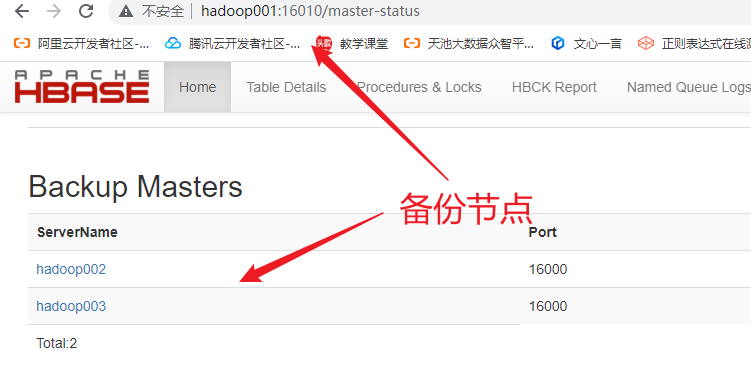
查看hadoop002:
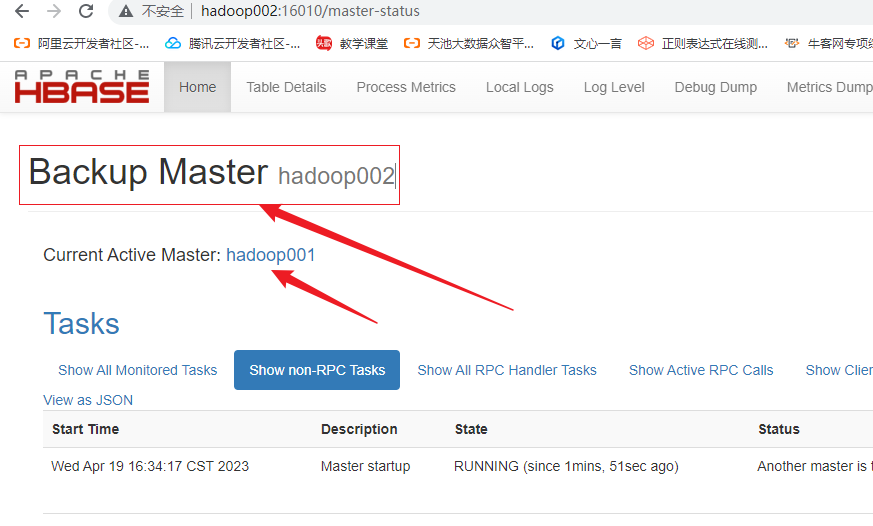
查看hadoop003:
三、测试高可用
1.尝试杀掉hadoop001的HMaster进程,模拟hadoop001宕机
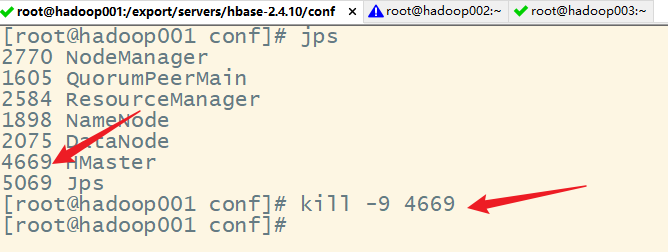
2.查看hadoop001的web ui
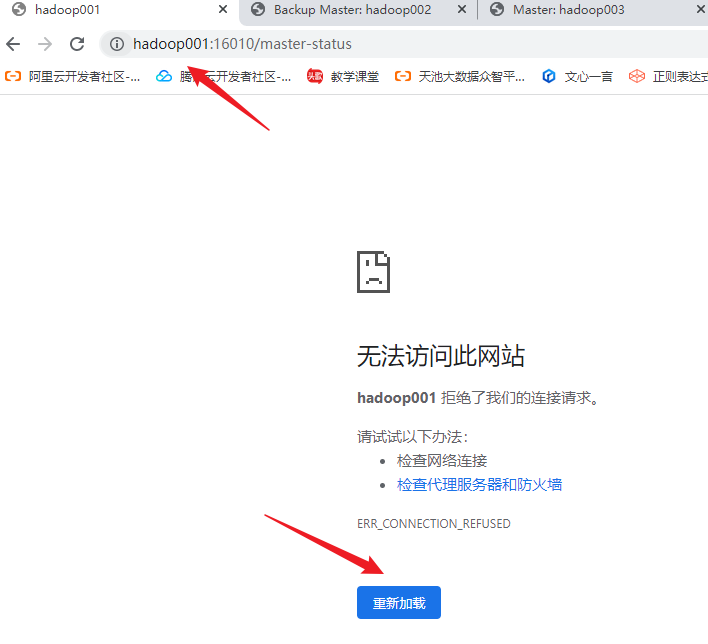
3.再查看hadoop003的web ui
发现hadoop003成为新的Master:
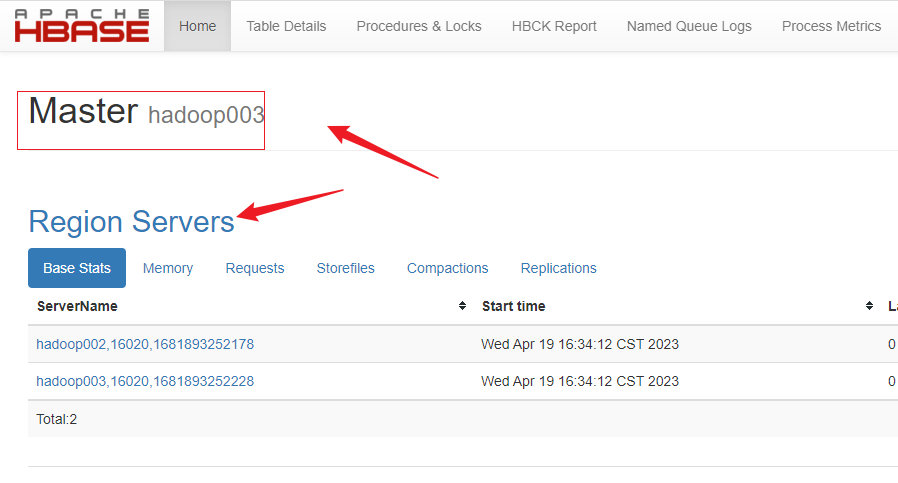
查看备用节点:

hadoop003已启用,所以备用节点还剩hadoop002。
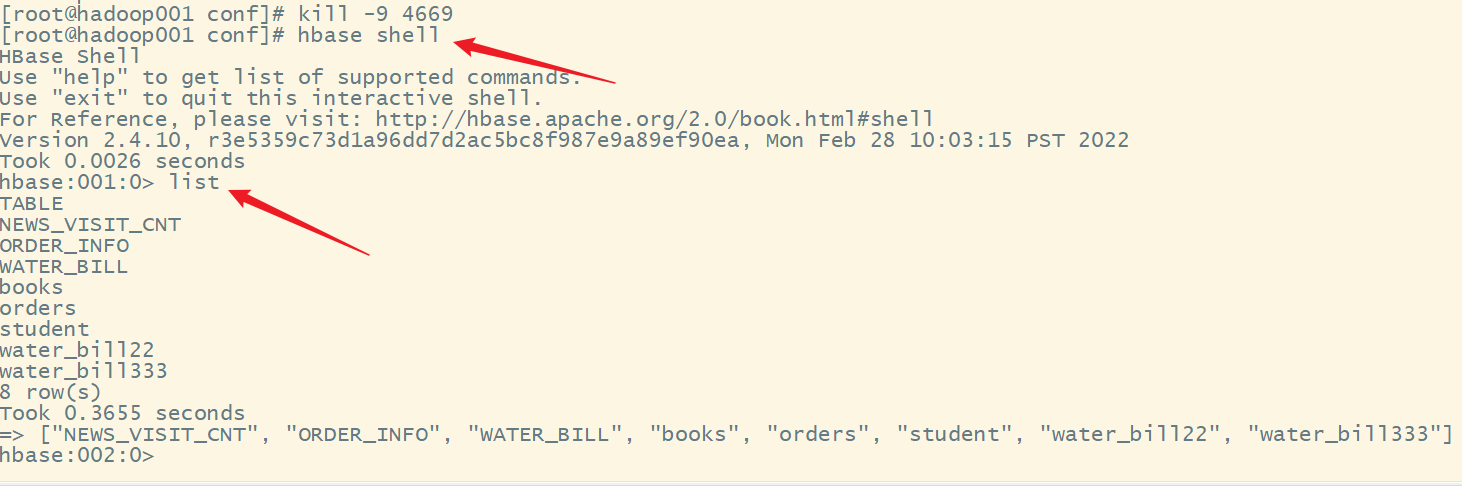
4.进入HBase shell,可以继续使用
虽然我们把hadoop001的HMaster进程给删除了,但是可以在hadoop001上继续使用HBase shell:
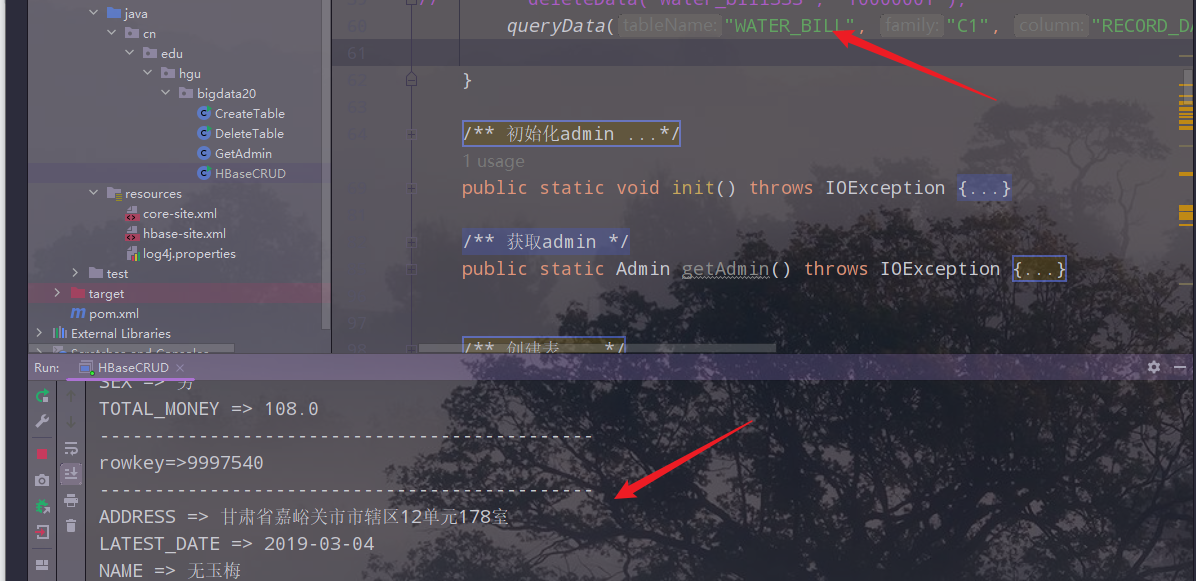
5.再次运行Java api程序,查看结果
运行Java api 程序,程序可以正常运行:
四、高可用原理
zookeeper临时节点 + watch + select
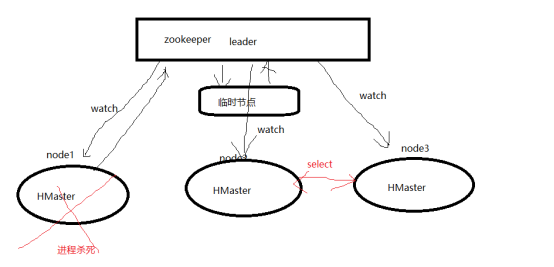
五、HBase的高可用架构及原理
1.系统架构
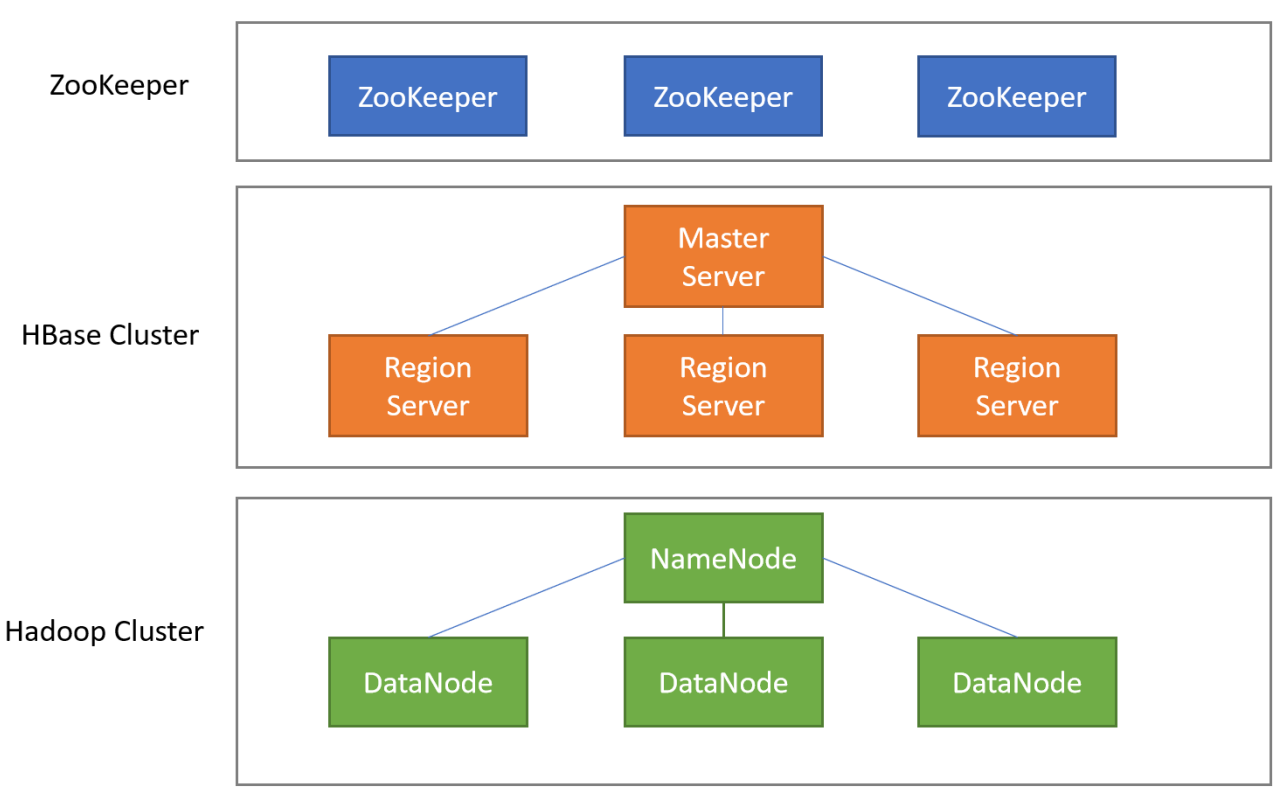
2.Client
客户端,例如:发出HBase操作的请求。例如:之前我们编写的Java API代码、以及HBase shell,都是CLient。
3.Master Server
作用:
- 监控RegionServer
- 处理RegionServer的故障
- 处理元数据的变更
- 处理region的分配或移除
- 处理负载均衡
- 通过zookeeper发布自己的状态信息
4.Region Server
-
处理分配给它的Region
-
负责存储HBase的实际数据
-
刷新缓存到HDFS
-
维护HLog
-
执行压缩
-
负责处理Region分片
-
RegionServer中包含了大量丰富的组件,如下:
- Write-Ahead logs
- HFile(StoreFile)
- Store
- MemStore
- Region
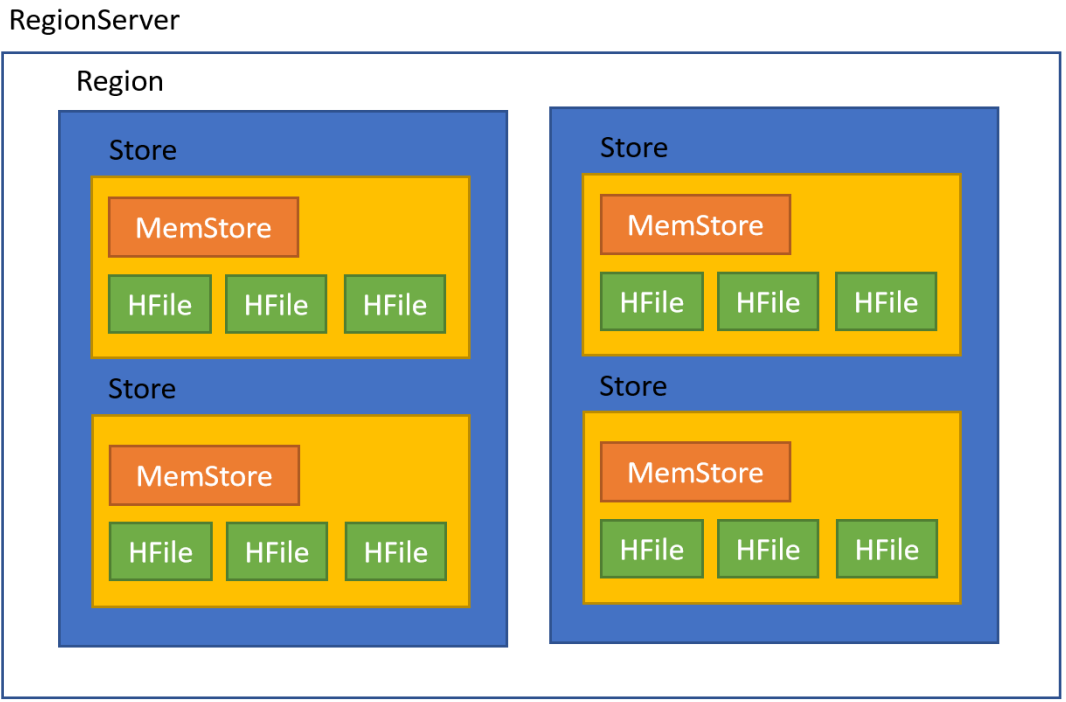
5.Region
在HBASE中,表被划分为很多「Region」,并由Region Server提供服务
6. Store
Region按列簇垂直划分为Store,存储在hdfs的HFile中
7. MemStore
- MemStore与缓存内存类似
- 当往HBase中写入数据时,首先是写入到MemStore
- 每个列族将有一个MemStore
- 当MemStore存储快满的时候,整个数据将写入到HDFS中的HFile中
8. StoreFile
- 每当任何数据被写入HBASE时,首先要写入MemStore
- 当MemStore快满时,整个排序的key-value数据将被写入HDFS中的一个新的HFile中
- 写入HFile的操作是连续的,速度非常快
- 物理上存储的是HFile
9. WAL
- WAL全称为Write Ahead Log,它最大的作用就是 故障恢复
- WAL是HBase中提供的一种高并发、持久化的日志保存与回放机制
- 每个业务数据的写入操作(PUT/DELETE/INCR),都会保存在WAL中
- 一旦服务器崩溃,通过回放WAL,就可以实现恢复崩溃之前的数据
- 物理上存储是Hadoop的Sequence File
AL全称为Write Ahead Log,它最大的作用就是 故障恢复
- WAL是HBase中提供的一种高并发、持久化的日志保存与回放机制
- 每个业务数据的写入操作(PUT/DELETE/INCR),都会保存在WAL中
- 一旦服务器崩溃,通过回放WAL,就可以实现恢复崩溃之前的数据
- 物理上存储是Hadoop的Sequence File