A Dual Augmented Two-tower Model for Online Large-scale Recommendation
美团的对偶增强双塔为了user塔和item塔操碎了心,众所周知,双塔的一个大毛病就是item和user的交叉太晚,重要的信息经过层层神经网络的抽象提取,有些重要的信息活不到交叉的那一刻就在中途丢失了。怎么尽早实现user塔和item塔的交叉是个让大家都想破脑袋的事,腾讯的MVKE通过全局向量作为桥梁,一桥架起双塔,实现早期的user塔和item的交叉,在实际业务中落地效果不错,美团的DAT通过在user塔和item塔分别构造一个增强向量,user塔的增强向量作为user塔输入的一部分,去学item塔的输出,item塔的增强向量作为item塔输入的一部分,去学user塔的输出,从而实现user塔和item塔的交叉。这个做法也是非常巧妙。
做法
结构如图
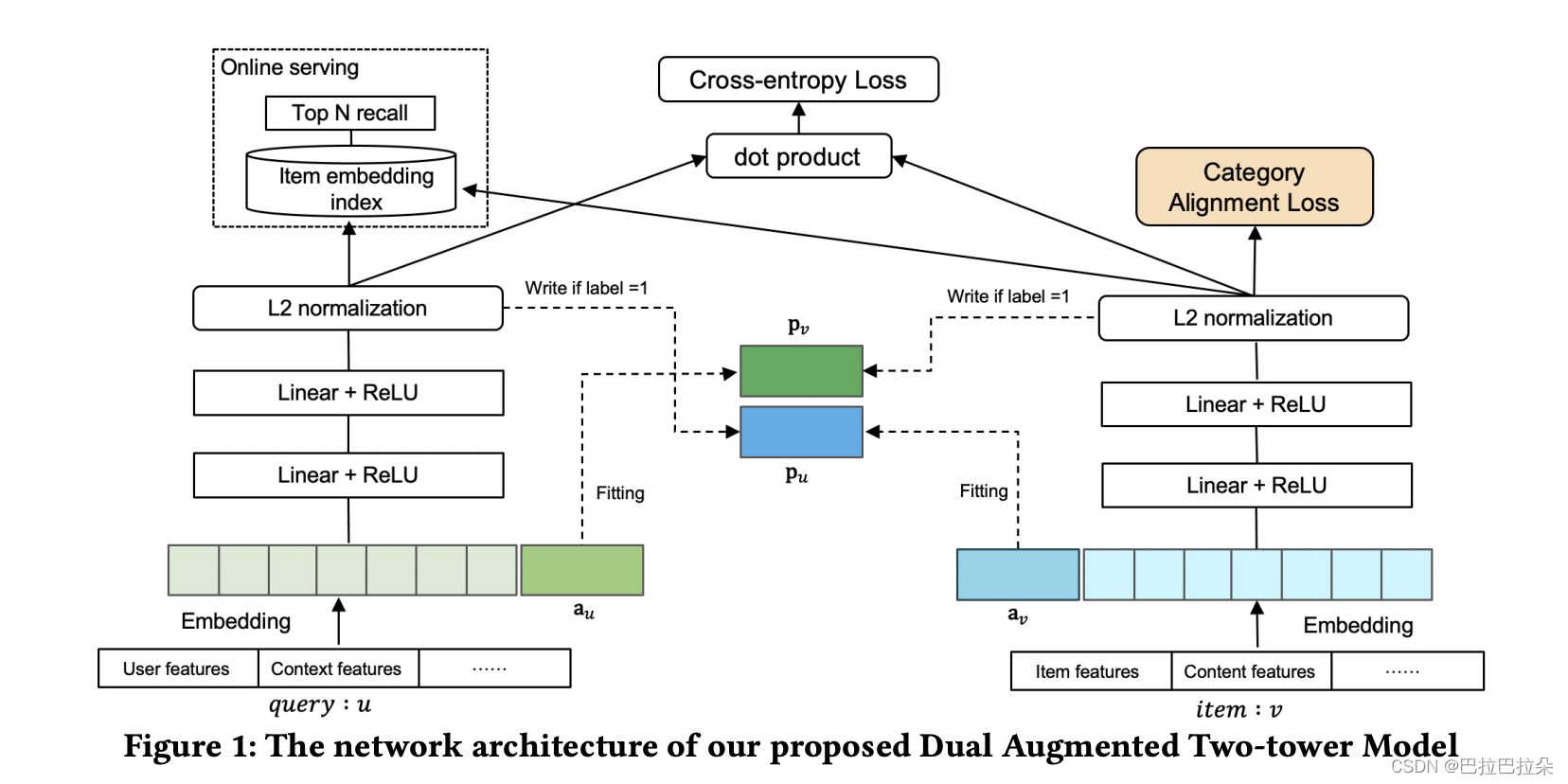
可以看到,一个重要的改动就是user塔的Embedding层多了一个增强向量
a
u
\mathbf a_u
au,item塔的Embedding多了一个增量向量
a
v
\mathbf a_v
av,user塔的增强向量
a
u
\mathbf a_u
au学习item塔的最终输出向量
p
v
\mathbf p_v
pv,item塔的增强向量学习user塔最终输出向量
p
u
\mathbf p_u
pu。
同时user塔的增强向量 a u \mathbf a_u au也作为user塔的Embedding输入,作为user塔炼丹原材料,最终产出用户塔的输出 p u \mathbf p_u pu,也就是item塔的信息实际上成为了user塔输入的一部分,item塔也是同样的操作。这样就实现了item塔和user的尽可能早的交叉。
详细做法
输入侧,以用户塔为例,第
i
i
i个特征域的Embedding记为
e
i
\mathbf e_i
ei,用户侧的各个特征域(年龄、性别、地域、…)拼接起来就是如下
[
e
1
,
e
2
,
.
.
.
e
n
]
[\mathbf e_1, \mathbf e_2, ... \mathbf e_n]
[e1,e2,...en]
再拼接上构造的用户侧增强向量
a
u
\mathbf a_u
au,用户侧Embedding可以表示为
z
=
[
e
1
,
e
2
,
.
.
.
e
n
,
a
u
]
\mathbf z = [\mathbf e_1, \mathbf e_2, ... \mathbf e_n, \mathbf a_u]
z=[e1,e2,...en,au]
经过炼丹炉炼制,炼制过程表示为
h
1
=
R
e
L
U
(
W
1
z
+
b
1
)
\mathbf h_1 = ReLU(\mathbf W_1 \mathbf z + \mathbf b_1)
h1=ReLU(W1z+b1)
h
L
=
R
e
L
U
(
W
l
h
L
−
1
+
b
l
)
\mathbf h_L = ReLU(\mathbf W_l \mathbf h_{L-1} + \mathbf b_l)
hL=ReLU(WlhL−1+bl)
p
u
=
L
2
N
o
r
m
(
h
L
)
\mathbf p_u = L2 Norm(\mathbf h_L)
pu=L2Norm(hL)
同理可以炼制item塔,得到item塔输出
p
v
\mathbf p_v
pv
那么增强的向量怎么学习塔对面的输出呢,每个增强向量通过一个辅助loss的方式,这个辅助loss在论文中称为AMM(Adaptive-Mimic Mechanism),对label为1(y=1)的样本计算辅助loss,其实就是要求这2个向量是一致的,形式如下
l
o
s
s
u
=
1
T
∑
y
(
a
u
−
p
v
)
2
loss_u = \frac 1 T \sum y(\mathbf a_u - \mathbf p_v)^2
lossu=T1∑y(au−pv)2
l
o
s
s
v
=
1
T
∑
y
(
a
v
−
p
u
)
2
loss_v= \frac 1 T \sum y(\mathbf a_v - \mathbf p_u)^2
lossv=T1∑y(av−pu)2
*因为这个loss是为了更新增强向量用的,所以需要固定 p v \mathbf p_v pv和 p u \mathbf p_u pu,反向传播的时候,需要阻塞loss对 p v \mathbf p_v pv和 p u \mathbf p_u pu的梯度更新。
类目信息迁移
业务生产中,各个item所属的类目通常是极度不均衡的,有的类目包含的item少,有的类目包含的item多,通常包含较少类目的item学习可能会不充分,这里设置了一个loss来让占主导的类目信息往长尾类目信息上面迁移。通过占主导的类目协方差和其他类目协方差的模来约束。
l
o
s
s
C
A
=
∑
i
=
2
m
∣
∣
C
(
S
m
a
j
o
r
)
−
C
(
S
i
)
∣
∣
F
2
loss_{CA} = \sum_{i=2}^m \vert \vert C(S^{major}) - C(S^i) \vert \vert^2_F
lossCA=i=2∑m∣∣C(Smajor)−C(Si)∣∣F2
loss计算
主loss,item塔的输出和user塔的输出 s ( u , v ) = < p u , p v > s(u, v) = <\mathbf p_u, \mathbf p_v> s(u,v)=<pu,pv>
l o s s p = − 1 T ∑ ( y log σ ( < p u , p v > ) + ( 1 − y ) log ( 1 − σ ( < p u , p v > ) ) ) loss_p = - \frac 1 T \sum (y \log \sigma (<\mathbf p_u, \mathbf p_v>) +(1-y) \log (1 - \sigma (<\mathbf p_u, \mathbf p_v>)) ) lossp=−T1∑(ylogσ(<pu,pv>)+(1−y)log(1−σ(<pu,pv>)))
最后的loss为
l o s s = l o s s p + λ 1 l o s s u + λ 2 l o s s v + λ 3 l o s s C A loss = loss_p + \lambda_1 loss_u + \lambda_2 loss_v + \lambda_3 loss_{CA} loss=lossp+λ1lossu+λ2lossv+λ3lossCA
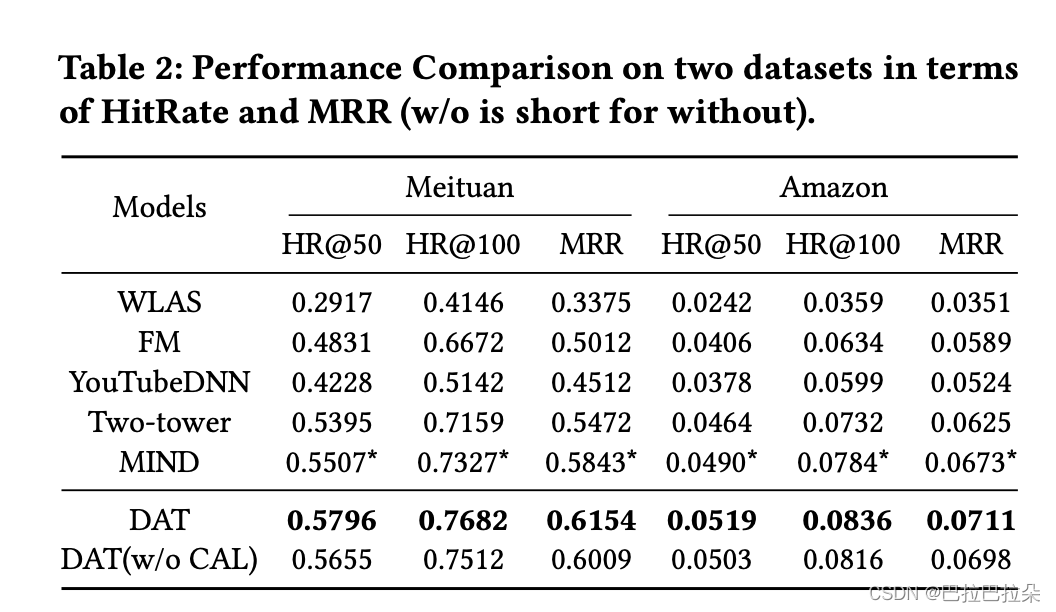
实验效果
可以看到加了增强向量的双塔效果还是不错的。
论文地址:https://dlp-kdd.github.io/assets/pdf/DLP-KDD_2021_paper_4.pdf