开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群。
本期继续上期的相关的部分,继续对POLARDB IMCI 列式的使用方式以及问题进行研究。在开始之前的,也想说说为什么要搞这个 IMCI 的初衷,众所周知,数据库OLTP OLAP 本来就是一对产生于不同业务的需求,业务的需求不同导致数据库应对不同的架构来进行不同的架构设计,所以OLTP OLAP 本来就应该是分开的,而为什么众多的数据库产品要进行 HTAP。
这些还是来自于需求,以及贪婪。 终究人类本性就是贪婪的,什么都想要,什么都想得到。HTAP 就产于与贪婪的欲望中,妄想一个数据库产品能解决所有的问题。实际上我们在进行POLARBD IMCI 的研究上不是出于无知和愚蠢的想法。我们仅仅是让一些基于MYSQL 上的一些应用,能稍微在不变动数据库的同时,能稍微有一些轻量级的OLAP 的特性,所以揣测我们都是一堆额度的欲望狂魔的人可以歇着了。
我们要解决的问题很明确
1 MYSQL 对于一些 COUNT , DISTINCT , GROUP BY ,ORDER BY ,以及一些SUM 等具有聚合方式的简单计算的提速工作。
2 稍微能在开发能力不行,业务要求开发进度紧的情况下,能稍微死的不难看,至少让管理数据库的我们,有一定的承受力,不至于让那些 developer and production manager 搞死数据库。
所以我们的任务也很简单,POLARDB IMCI 的研究和使用就不是要做OLAP ,而是轻奢的 OLTP 。OK 我们的需求与定位已经明确了,我们不是贪婪的,仅仅是要解决一个棘手的问题,提供一个POALRDB 可以给出的解决方案。至于 HTAP ,这个方案还没有到这个地步。
下面继续说相关这个解决方案的问题,或者说核心问题
分流
对分流,一个SQL 到底应该是去行存解决 问题,还是去列存解决问题,这是一个非常重要的问题,如果走错了,那么必然导致我们的解决方案的失败的问题。
这里POALRDB 的解决方案中如何进行SQL 语句的分离是一个核心的问题,这里POALRDB 通过cost 的阈值的问题的方式来将SQL 进行导流。实际上我们在看到这个方案的时候我们是有一些担心的,因为COST的部分如果是一个固定值,如果随着数据库的变大,那么一些适合在行中进行处理的部分也要通过列存在进行处理,那么可能就会引起更多的问题。
这里的设置是通过代理来进行设置的,这里的设置需要两个步骤
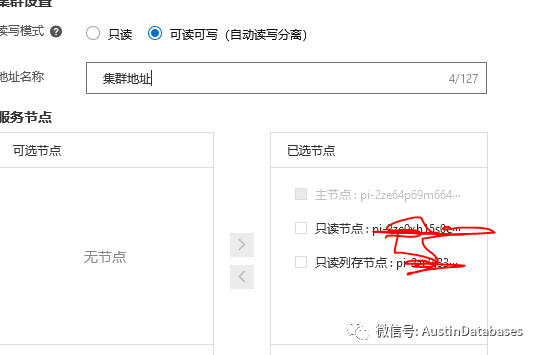
1 在集群地址的代理中设置为
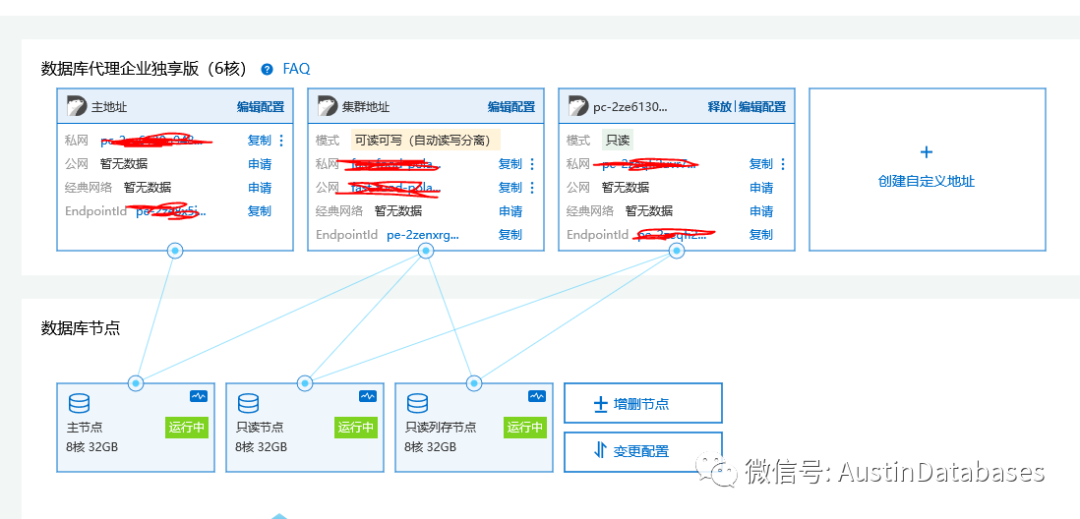
在主代理中选择 可读可写
在只读代理中选择 基于活跃请求负载均衡
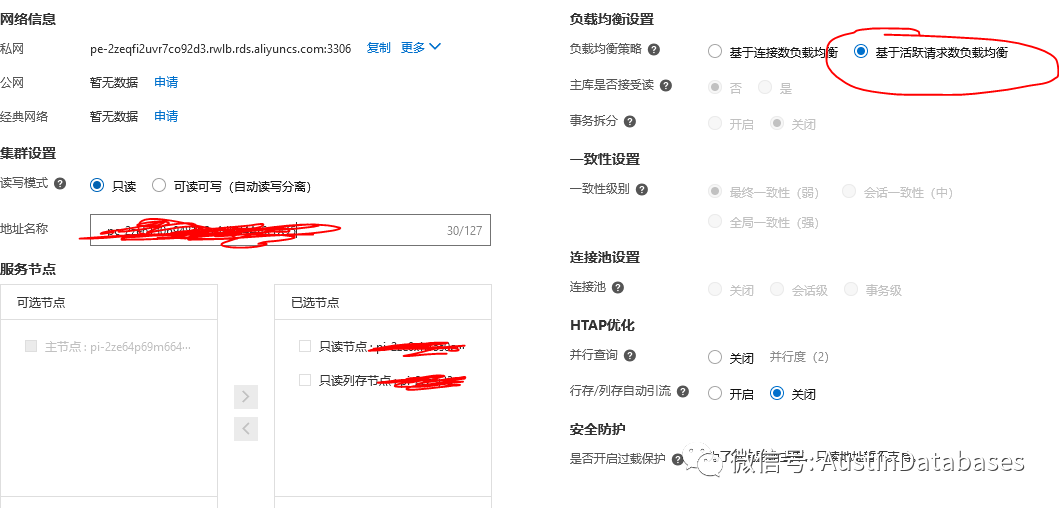
同时在HTAP 行/列自动引流 需要进行开启
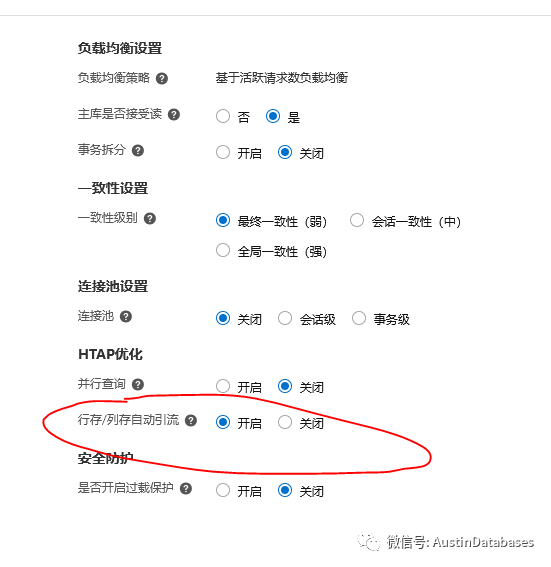
实际上学到这里,这个系统最关键的地方就已经到了,就是自动引流的部分,也就是需要 DBA 来设置判断语句 COST 进行值的设定后,保证超过DBA 设置的COST 值后的SQL 去列存来进行SQL 的处理。
那么在熟悉这个问题后,我们就已经知晓了我们工作的核心部分loose_imci_ap_thresold 这个参数是根据SQL的预估自行的代价的阈值来将SQL 发往不同的节点 (行 / 列)
loose_cost_threshold_for_imci 这个参数的目的是产生什么样的执行计划,如果超过值的设置就使用列存的执行计划。
读到这里,估计不少人会产生一个疑问,嗯,不是已经路由到了列式的节点中了吗为什么还要在判断一次是否执行列式的执行计划。
实际上这个列存,只是一个行存中保存了列的索引的部分的可见节点,在执行中有些语句并不适合列式存储计算,所以分配到了列式引擎中,如果无法进行执行那么还是需要返给行引擎来处理。
同时针对列引擎,POLARDB 优化了 table scan , nested loop join , hash join , group by aggregation 等特殊的一些数据处理的部分。
除此以外,POLARDB 还支持手动的方式来启动对列式引擎进行访问的方式,比如使用HINT 的方式。这里就不进行详细的介绍了。
除此之外,我们还有一些其他的问题,如需要更深入到POALRDB 的列存储的使用中。
举例
1 高频插入数据对于整体系统的影响问题,需要压测
2 索引的维护与数据量有效性的问题
3 语句的限制与什么样的情况更适合 POALRDB 列存
4 POALRDB 的列压缩对于系统性能的提升或影响
5 如何查看语句使用列式的执行计划
6 列式的参数和status以及列式的监控等