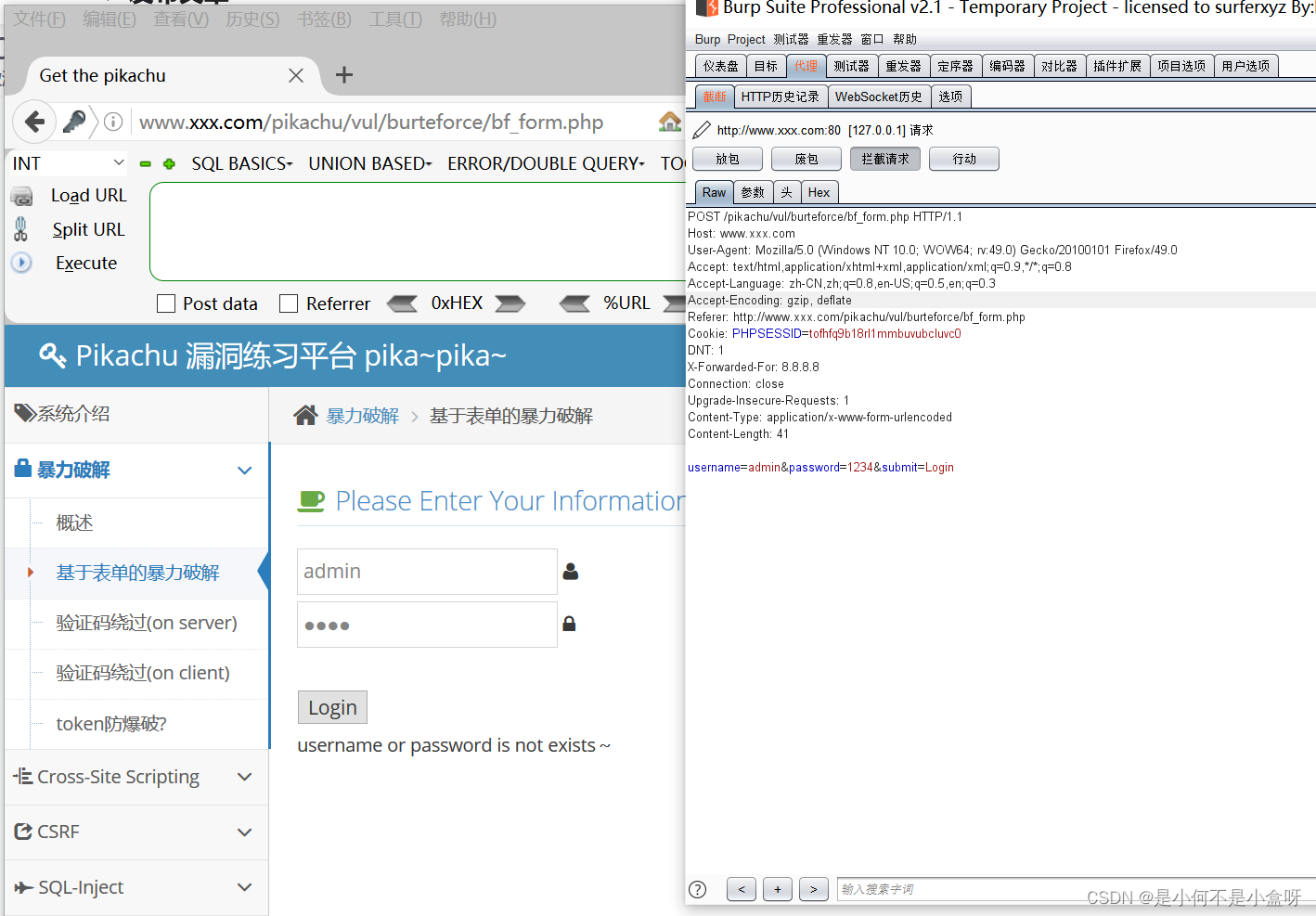
Elasticsearch 是一个可扩展的分布式系统,可为企业搜索、日志聚合、可观察性和安全性提供解决方案。 Elastic 解决方案建立在一个单一、灵活的技术堆栈之上,可以部署在任何地方。 要在自托管或云端运行生产环境 Elasticsearch,需要规划基础架构和集群配置,以确保健康且高度可靠的性能部署。在本文中,我们将重点介绍如何在部署生产级集群之前根据使用量估算和创建一个实施计划。

容量规划
- 确定最小主节点数
- Elasticsearch Service 的规模
确定主节点的最小数量
主节点,也即 master node。有关 master node 的作用我们在文章 “Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica” 已经讲过。集群中最重要的节点是Master节点。 主节点负责集群范围内的各种活动,例如创建、删除、分片分配等。稳定的集群取决于主节点的健康状况。
建议拥有专用主节点(不具有其它的任何角色),因为具有其他职责可能造成超载主节点将使得主节点无法正常运行。 避免 master 因其他任务而超载的最可靠方法是将所有符合 master 资格的节点配置为专用的符合 master 资格的节点,这些节点仅具有 master 角色,从而使它们能够专注于管理集群。
轻量级集群可能不需要 master-eligible 资格的节点,但一旦集群超过 6 个节点,建议使用专用的 master-eligible 节点。选择最小主节点时的决策法定节点数(quorum)使用以下公式计算:
Minimum Master Nodes = (N / 2) + 1N 是集群中 master-eligible 节点的总数(四舍五入到最接近的整数)
在理想的环境中,主节点的最小数量为 3,如果不维护,可能会导致 “脑裂”,从而导致集群不健康和数据丢失。
让我们考虑以下示例以更好地理解:

在场景 A 中,你有 10 个常规节点(既可以保存数据又可以成为 master 的节点),quorum 为 6。即使我们由于网络连接而失去 master 节点,集群也会选举一个新的 master 并且仍然是健康。

在场景 B 中,你有 3 个专用主节点和 100 个数据节点,法定节点数 quorum 为 2。即使我们因故障失去主节点,集群也会选举一个新的主节点并且仍然是健康的。

在场景 C 中,你有两个常规节点,quorum 为 2。如果节点之间出现网络故障,那么每个节点都会尝试选举自己作为 Master,从而使集群无法运行。
将值设置为 1 是允许的,但它不能保证在主节点出现故障时不会丢失数据。
注意:避免重复更改主节点设置,因为当服务尝试更改专用主节点的数量时,这可能会导致集群不稳定。
Elasticsearch Service 的规模
Elasticsearch Service 的规模调整更多的是做出有根据的估计,而不是有一个万无一失的方法。 估计更多的是考虑到存储、要使用的服务和 Elasticsearch 本身。 该估计可作为确定大小的最关键方面的有用起点; 用具有代表性的工作负载测试它们并监控它们的性能。
以下是在调整大小之前要记住的关键部分:
- 用例,(即)用于实时搜索或安全监控、日志分析等。
- 长期和短期的增长规划。
由于 Elasticsearch 是横向可扩展的,如果在初始阶段没有适当地进行适当的索引和分片,那么将不得不通过痛苦的批准来添加硬件,最终将导致基础设施利用率不足。
在选择适当的集群设置之前要记住的三个关键组成部分如下:
- 计算存储要求
- 选择分片数量
- 选择实例类型和测试
选择分片数量
要考虑的第二个组成部分是为指数选择正确的索引策略。 在 Elasticsearch 中,默认情况下,每个索引都分为 n 个主副本。 (例如,如果有 2 个主分片和 1 个副本分片,则分片总数为 4)。 现有索引的主分片数量一旦创建就无法更改。有关分片方面的知识,请参阅 “Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica”。
每个分片都使用一定数量的 CPU 和内存,拥有太多小分片会导致性能问题和内存不足错误。 但这也不能使人有权创建太大的分片。
经验法则是确保分片大小始终在 10–50 GiB 之间。
分片数量的大致计算公式如下:
App. Number of Primary Shards =
(Source Data + Room to Grow) * (1 + Indexing Overhead) / Desired Shard Size简单来说,分片大小应该很小,但不能小到底层 Elasticsearch 实例不会对硬件造成不必要的压力。
让我们考虑以下示例以更好地理解:
场景一
假设你有 50 GiB 的数据,并且你不希望它随着时间的推移而增长。 根据上面的公式,分片的数量应该是 (50 * 1.1 / 30) = 2。
注意:选择的所需分片大小为 30 GiB
场景二
假设相同的 50 GiB 预计到明年将翻两番,那么近似的分片数量将为 ((50 + 150) * 1.1 / 30) = 8。
即使我们不会立即拥有额外的 150 GiB 数据,重要的是要注意准备工作最终不会创建多个不必要的分片。 如果您还记得之前的话,分片会消耗大量的 CPU 和内存,在这种情况下,如果我们最终创建小分片,这可能会导致目前的性能下降。
将上述分片大小设为 8,让我们进行计算:(50 * 1.1) / 8 = 每个分片 6.86 GiB。
分片大小远低于建议的大小范围 (10–50 GiB),这最终会消耗额外的资源。 为了解决这个问题,我们应该更多地考虑 5 个分片的中间地带方法,目前有 11 GiB (50 * 1.1 / 5) 个分片和 44 GiB ((50 + 150) * 1.1 / 5) 个分片 未来。
在上述两种方法中,分片大小都是近似值而不是合适的。
非常重要的是要注意,永远不要选择合适的值来设定大小,因为在达到我们设置的阈值限制之前,你就有磁盘空间用完的风险。 例如,让我们考虑一个磁盘空间为 128 GiB 的实例。 如果磁盘使用率保持在 80% (103 GiB) 以下并且分片大小为 10 GiB,那么我们大约可以容纳 10 个分片。
注意:在给定节点上,建议每个 GiB Java 堆中的分片不超过 20 个。
选择实例类型和测试
在计算了存储需求并选择了所需的分片数量之后,下一步就是做出硬件决策。 硬件要求因工作负载而异,但我们可以进行猜测。 通常,每个实例类型的存储限制映射到你的工作负载可能需要的 CPU 和内存量。
在选择正确的实例类型时,以下公式有助于更好地理解:
Total Data (GB) = Raw data (GB) per day * Number of days retained * (Number of replicas + 1)
Total Storage (GB) = Total data (GB) * (1 + 0.15 disk Watermark threshold + 0.1 Margin of error)
Total Data Nodes = ROUNDUP(Total storage (GB) / Memory per data node / Memory:Data ratio)为了更好地理解公式,让我们考虑以下示例:
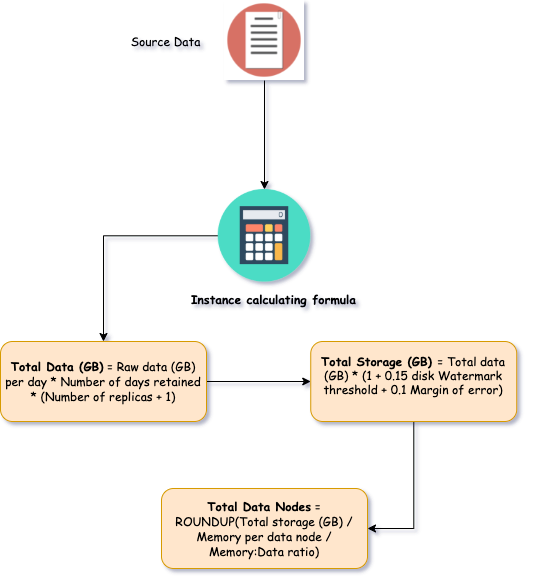
日志记录应用程序每天推送近 3 GiB 数据,数据保留期为 90 天
你可以为这个小型部署使用每个节点 8GB 的内存。 让我们算一下:
总数据 (GB) = 3GB x(3 x 30 天)x 2 = 540GB
总存储空间 (GB)= 540GB x (1+0.15+0.1) = 675GB
总数据节点 = 675GB 磁盘 / 8GB RAM /30 比率 = 3 个节点。总结到目前为止我们所看到的一切。
更多阅读:
-
Elasticsearch:我的 Elasticsearch 集群中应该有多少个分片?
-
Elasticsearch:如何部署 Elasticsearch 来满足自己的要求