文章目录
- 符号
- `#ifdef-#endif`
- \
- 接续符
- 转义
- 旋转光标
- 数字倒计时
- 单引号-双引号
- 逻辑运算符&& ||
- 短路
- 位运算符
- 异或
- 位运算最好使用定义好的宏
- 左移右移
- ++
- 后置++
- 前置++
- 复杂表达式
- 取整
- 0向取整(C中默认取整方式)
- floor地板取整
- ceil
- round 四舍五入
- 取模
- 取余和取模一样吗?
- 运算符优先级
符号
#ifdef-#endif
基于条件编译,代码编译期间处理 gcc -E test1.c -o test.i,生成预处理之后的.i文件查看宏替换,注释去掉的情况.
#ifdef-#endif宏


#if-#endif表达式是否为1

\
接续符
- 使用\之后,后面不要有任何字符,包括空格.
int main()
{
int a = 1;
int b = 2;
int c = 3;
//试试在\之后带上空格,行不行?
//试试在\之前带上空格,行不行?
//建议:不要带
if (a == 1 &&\
b == 2 &&\
c == 3){
printf("hello world!\n");
}
system("pause");
return 0;
}
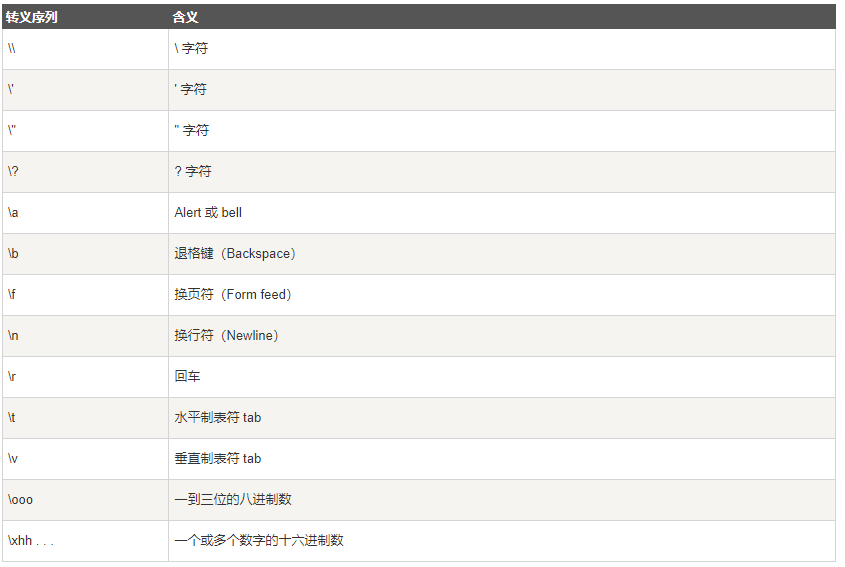
转义
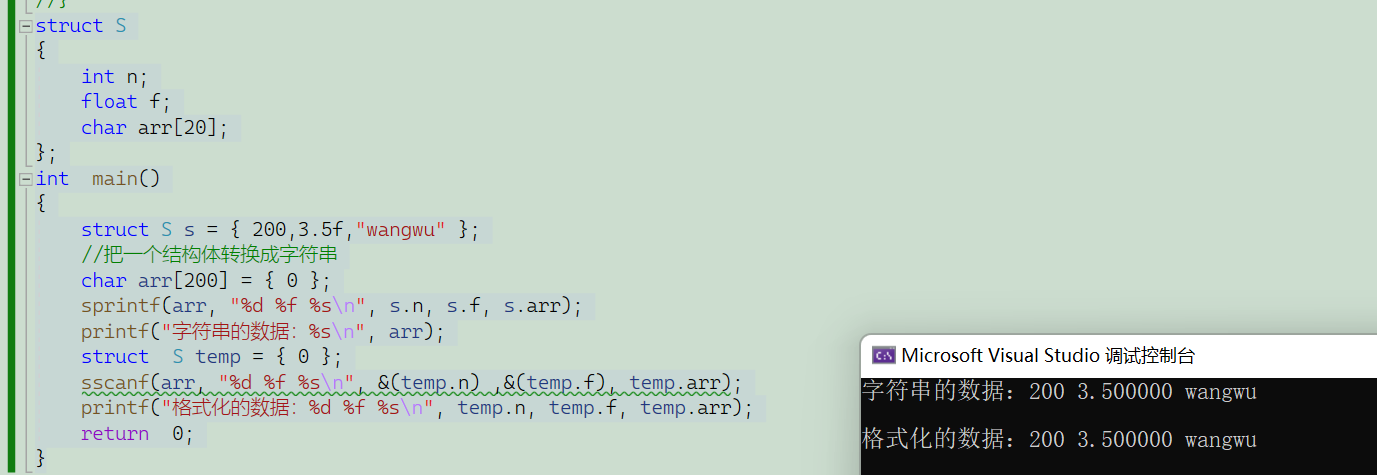
int main()
{
printf("\""); //特殊转字面
printf("\n");//字面转特殊
return 0;
}
-
回车
\r:光标回到当前行的位置 -
换行
\n:光标移动到下一行
旋转光标
int main()
{
const char* lable = "|/-\\";
int index = 0;
while (1)
{
index %= 4;
printf("[%c]\r",lable[index]);
index++;
Sleep(300);
}
}
数字倒计时
int main()
{
int i = 15;
for (; i >= 0; i--)
{
printf("[%2d]\r",i);
Sleep(1000);
}
}
单引号-双引号
变量是帮助我们操纵字面值常量运算的.
- 不同的语言识别’'的字符常量是不一样的.

- 为什么这么写也中?
因为C识别’'时就开辟的四字节空间.但是存的只有一个字节.
int main()
{
//char c1 = 'abscd';//error
char c2 = 'abcd';
printf("%c\n",c2);//d
}
逻辑运算符&& ||
短路
当前面的条件成立时执行后面的代码
int show()
{
printf("you can see me!\n");
return 1;
}
int main()
{
int a = 0;
scanf("%d", &a);
a == 10 && show();
system("pause");
return 0;
}
位运算符
int main()
{
printf("%d\n", 2 | 3); //3
printf("%d\n", 2 & 3); //2
printf("%d\n", 2 ^ 3); //1
printf("%d\n", ~0); //-1 按位取反符号位是参与运算的
system("pause");
return 0;
}
异或
任何数字和0异或都是他本身,和自己异或都是0.支持交换律和结合律.
- 交换值(不存在相加进位导致类型溢出的问题)
int main()
{
int a = 10;
int b = 20;
a = a ^ b;
b = a ^ b;
a = a ^ b;
printf("%d %d\n",a,b);
system("pause");
}
位运算最好使用定义好的宏
#define SETBIT(x,n) x|=(1<<(n-1))//注意赋值操作
#define RESTBIT(x,n) x&=(~(1<<(n-1)))
void ShowBit(int x)
{
int num = sizeof(x)*8-1;
while (num>=0)
{
if (x & (1<<num))
{
printf("1");
}
else
{
printf("0");
}
num--;
}
printf("\n");
}
int main()
{
int x = 0;
//设置指定比特位是1
SETBIT(x,5);
//显示int的所有比特位
ShowBit(x);
}
- 整形提升(不同的编译器方式不同)

在编译期间就已经处理好了,被硬编译为数字.
无论任何位运算符,目标都是要计算机进行计算的,而计算机中只有CPU具有运算能力(先这样简单理解),但计算的数据,都在内存中。
故,计算之前(无论任何运算),都必须将数据从内存拿到CPU中,拿到CPU哪里呢?毫无疑问,在CPU 寄存器中。而寄存器本身,随着计算机位数的不同,寄存器的位数也不同。一般,在32位下,寄存器的位数是32位。
可是,你的char类型数据,只有8比特位。读到寄存器中,只能填补低8位,那么高24位呢?就需要进行“整形提升”。
左移右移
<<(左移): 最高位丢弃,最低位补零
>>(右移):
1. 无符号数:最低位丢弃,最高位补零[逻辑右移](2倍操作)
2. 有符号数:最低位丢弃,最高位补符号位[算术右移]
补0还是1跟数据是没有关系的,数据正负都需要转化为补码写入内存
向外读取进行补0 or 1是看数据类型的,无符号就补0,有符号就具体来.

丢弃基本理解链:
<< 或者 >> 都是计算,都要在CPU中进行,可是参与移动的变量,是在内存中的。所以需要先把数据移动到CPU内寄存器中,在进行移动。
那么,在实际移动的过程中,是在寄存器中进行的,即大小固定的单位内。那么,左移右移一定会有位置跑到"外边"的情况
++
后置++

前置++

如果没人用于赋值使用,前置和后置没有区别.
- 初始化有一条汇编语句,赋值是两条汇编语句.
复杂表达式
在不同的编译器中,因为表达式的计算路径不唯一(编译器识别表达式是同时加载到寄存器还是分批加载,时不确定的)导致的.
相同的一份代码:
int main()
{
int i = 1;
int j = (++i) + (++i) + (++i);
printf("%d\n",j);
}
vs环境下:

Linux 环境下:

- 表达式匹配的规则是贪心算法(根据空格的划分)
int main()
{
int a = 10;
int b = 20;
printf("%d\n",a++ + ++b);//31
}
取整
0向取整(C中默认取整方式)
int main()
{
//本质是向0取整
int i = -2.9;
int j = 2.9;
printf("%d\n", i); //结果是:-2
printf("%d\n", j); //结果是:2
system("pause");
return 0;
}

floor地板取整
朝向负无穷大取整.-∞
//demo 2
#include <stdio.h>
#include <math.h> //因为使用了floor函数,需要添加该头文件
#include <windows.h>
int main()
{
//本质是向-∞取整,注意输出格式要不然看不到结果
printf("%.1f\n", floor(-2.9)); //-3
printf("%.1f\n", floor(-2.1)); //-3
printf("%.1f\n", floor(2.9)); //2
printf("%.1f\n", floor(2.1)); //2
system("pause");
return 0;
}
ceil
#include <stdio.h>
#include <math.h>
#include <windows.h>
int main()
{
//本质是向+∞取整,注意输出格式要不然看不到结果
printf("%.1f\n", ceil(-2.9)); //-2
printf("%.1f\n", ceil(-2.1)); //-2
printf("%.1f\n", ceil(2.9)); //3
printf("%.1f\n", ceil(2.1)); //3
system("pause");
return 0;
}
round 四舍五入
#include <stdio.h>
#include <math.h>
#include <windows.h>
int main()
{
//本质是四舍五入
printf("%.1f\n", round(2.1));
printf("%.1f\n", round(2.9));
printf("%.1f\n", round(-2.1));
printf("%.1f\n", round(-2.9));
system("pause");
return 0;
}
取模
取模概念:
如果a和d是两个自然数,d非零,可以证明存在两个唯一的整数 q 和 r,满足 a = q*d + r 且0 ≤ r < d。其中,q被称为商,r 被称为余数.

故,大家对取模有了一个修订版的定义:
如果a和d是两个自然数,d非零,可以证明存在两个唯一的整数 q 和 r,满足 a = q*d + r , q 为整数,且0 ≤ |r|
< |d|。其中,q 被称为商,r 被称为余数。
有了这个新的定义,那么C中或者Python中的“取模”,就都能解释了。
解释C: -10 = (-3) * 3 + (-1)
解释Python:-10 = (?)* 3 + 2,其中,可以推到出来,'?'必须是-4(后面验证).即-10 = (-4)* 3 + 2,才能满足定义。注意:python中 / 默认是浮点数除法,// 才是整数除法,并进行-∞取整
所以,在不同语言,同一个计算表达式,负数“取模”结果是不同的。我们可以称之为分别叫做正余数 和 负余数.
由上面的例子可以看出,具体余数r的大小,本质是取决于商q的。而商,又取决谁呢?取决于除法计算的时候,取整规则 .
取余和取模一样吗?
- 本质 1 取整:
取余:尽可能让商,进行向0取整。
取模:尽可能让商,向-∞方向取整。
故:
C中%,本质其实是取余。
Python中%,本质其实是取模。(后面不考虑python,减少难度)
理解链:
对任何一个大于0的数,对其进行0向取整和-∞取整,取整方向是一致的。故取模等价于取余
对任何一个小于0的数,对其进行0向取整和-∞取整,取整方向是相反的。故取模不等价于取余
同符号数据相除,得到的商,一定是正数(正数vs正整数),即大于0!
故,在对其商进行取整的时候,取模等价于取余。
- 本质 2 符号:参与取余的两个数据,如果同符号,取模等价于取余
int main()
{
printf("%d\n", -10 / 3); //结果:-3
printf("%d\n\n", -10 % 3); //结果:-1 为什么? -10=(-3)*3+(-1)
printf("%d\n", 10 / -3); //结果:-3
printf("%d\n\n", 10 % -3); //结果:1 为什么?10=(-3)*(-3)+1
system("pause");
return 0;
}
//如果不同符号,余数的求法,参考之前定义。C等向0取整的语言,余数符号,与被除数相同
结论:如果参与取余的两个数据符号不同,在C语言中(或者其他采用向0取整的语言如:C++,Java),余数符号,与被除数相同。
参与取余的两个数据,如果同符号,取模等价于取余
- 推导
如果a和d是两个自然数,d非零,可以证明存在两个唯一的整数 q 和 r,满足 a = q*d + r , q 为整数,且0 ≤ |r|< |d|。其中,q 被称为商,r 被称为余数。
a = q*d + r 变换成 r = a - q*d 变换成 r = a + (-q*d)
对于:x = y + z,这样的表达式,x的符号 与 |y|、|z|中大的数据一致
而r = a + (-q*d)中,|a| 和 |-q*d|的绝对值谁大,取决于商q的取整方式。
c是向0取整的,也就是q本身的绝对值是减小的。
如:
-10/3=-3.333.33 向0取整 -3. a=-10 |10|, -q*d=-(-3)*3=9
10/-3=-3.333.33 向0取整 -3. a=10 |10|, -q*d=-(-3)*(-3)=-9 q*d 变小了
python是向-∞取整的,也就是q本身的绝对值是增大的。
-10/3=-3.333.33 '//'向-∞取整 -4. a=-10 |10|, -q*d=-(-4)*3=12 |12|
10/-3=--3.333.33 '//'向-∞取整 -4. a=10 |10|, -q*d=-(-4)*(-3)=-12 |12|
绝对值都变大了,-10+12>0,就和被除数符号不同了.
int main()
{
printf("%d\n", 5 / (-2)); //-2
printf("%d\n", 5 % (-2)); //5=(-2)*(-2)+1
system("pause");
return 0;
}