一、如何衡量CPU的负载
衡量CPU负载
简单衡量
C P U 负 载 = 就 绪 队 列 的 总 权 重 CPU负载 = 就绪队列的总权重 CPU负载=就绪队列的总权重
量化负载
C P U 负 载 = ( 采 样 期 间 累 计 运 行 时 间 / 采 样 总 时 间 ) ∗ 就 绪 队 列 总 权 重 CPU负载 = (采样期间累计运行时间/采样总时间)*就绪队列总权重 CPU负载=(采样期间累计运行时间/采样总时间)∗就绪队列总权重
工作负载
C P U 工 作 负 载 = 采 样 期 间 累 计 运 行 时 间 ∗ 就 绪 队 列 总 权 重 CPU工作负载 = 采样期间累计运行时间*就绪队列总权重 CPU工作负载=采样期间累计运行时间∗就绪队列总权重
历史衰减工作负载计算
上述中量化负载是把采样总时间段内的所有工作负载等同化,这是不准确的;比如采样时间内,分成若干个period,每个period中运行时间都不一样(也即CPU占用率不一样),随着时间推移,过去的period中负载对未来的负载估算/计算的贡献是需要减弱的
把1ms(准确说是1024us,方便移位操作)的时间跨度作为一个计算周期period,简称PI。一个entity在PI周期内对工作负载的贡献主要与两个因素有关:
-
进程的权重
-
PI内可运行时间的衰减累计值(这个我理解为:计算某个PI周期时的负载贡献,需要计算上该周期距离最新周期的累计衰减,也就是该周期内实际运行时间x衰减系数)
历史累计衰减工作负载计算公式:
d
e
c
a
y
_
s
u
m
_
l
o
a
d
=
d
e
c
a
y
_
s
u
m
_
t
i
m
e
∗
w
e
i
g
h
t
(
1.4
)
decay\_sum\_load = decay\_sum\_time * weight\ \ \ \ \ \ \ \ \ \ \ (1.4)
decay_sum_load=decay_sum_time∗weight (1.4)
decay_sum_load: 累计工作总负载
decay_sum_time: 累计衰减总时间,这里是计算过去若干个PI周期内的可运行时间的衰减累计值
weight:权重
上述计算累计负载的意义是:把该进程在过去的若干周期内的工作负载贡献都考虑进来
为何需要这样考虑呢?进程的行为并不是统一的,有些进程是长时间睡眠后突然占用CPU,所以如果只以此时该进程的负载来计算未来该进程可能贡献的负载就相当不准确,所以需要考虑历史累计工作负载
说到底,还是为了公平调度,完美的调度算法需要一个能够预知未来的水晶球:只有当内核准确地推测出每个进程对系统的需求,她才能最佳地完成调度任务。所以做这么多运算,就是为更好的预测未来每个进程对CPU的需求。只是预测罢了。
如果我们让Li表示在周期PI中该调度实体的对系统负载贡献,那么一个调度实体对系统负荷的总贡献可以表示为:
L
=
L
0
+
L
1
∗
y
+
L
2
∗
y
2
+
L
3
∗
y
3
+
…
(
1.5
)
L = L0 + L1*y + L2*y2 + L3*y3 + … \ \ \ \ \ \ \ (1.5)
L=L0+L1∗y+L2∗y2+L3∗y3+… (1.5)
其中y是衰减因子,3.8内核后已约定好y的32次方约等于0.5,也就是32个周期PI后,Li贡献度降一半。通过上面的公式可以看出:
(1) 调度实体对系统负荷的贡献值是一个序列之和组成
(2) 最近的负荷值拥有最大的权重
(3) 过去的负荷也会被累计,但是是以递减的方式来影响负载计算。
量化负载计算
公式(1.4)中计算的工作负载直接用来比较两个进程的负载大小是不合理的。原因:公式(1.4)中,权重weight是个容易量化的值,而累计衰减时间是很难量化的。假设进程A和进程B的权重相同,A运行了几天几夜,B才运行了几分钟,如果按照公式(1.4)计算,那么进程A的累计工作负载大于B,但这可能计算的没有意义
所以,需要量化负载(其实就是计算某个采样时间段内的工作负载占比)
d
e
c
a
y
_
a
v
g
_
l
o
a
d
=
(
d
e
c
a
y
_
s
u
m
_
r
u
n
n
a
b
l
e
_
t
i
m
e
/
d
e
c
a
y
_
s
u
m
_
p
e
r
i
o
d
_
t
i
m
e
)
∗
w
e
i
g
h
t
(
1.6
)
decay\_avg\_load = (decay\_sum\_runnable\_time/decay\_sum\_period\_time) * weight \ \ \ \ \ \ \ \ \ \ \ \ \ (1.6)
decay_avg_load=(decay_sum_runnable_time/decay_sum_period_time)∗weight (1.6)
其中:
decay_avg_load: 量化负载
decay_sum_runnable_time: 就绪队列或调度实体在可运行状态下的所有历史累计衰减时间
decay_sum_period_time: 就绪队列或调度实体在所有的采样周期里全部时间的累加衰减时间。通常从进程开始执行时就计算和累计该值
weight: 就绪队列或调度实体的权重
Linux中,CPU对应的就绪队列中所有进程的量化负载累加起来得到CPU总负载。SMP负载均衡算法使用量化负载来比较两个CPU的负载是否均衡。
实际算力
处理器的算力:处理器最大的处理能力。SMP架构下,CPU计算能力相同。ARM的大小核架构下,CPU计算能力就不同。
量化计算能力:如果最强大的CPU的量化计算能力设定为1024,那么其他计算力较弱的CPU的量化计算能力就小于1024。CPU的量化计算能力是通过设备树或者BIOS等方式提供给Linux内核,rq数据结构体中用cpu_capacity_orig来描述这个量化计算能力。
实际算力:
u
t
i
l
_
a
v
g
=
(
d
e
c
a
y
_
s
u
m
_
r
u
n
n
i
n
g
_
t
i
m
e
/
d
e
c
a
y
_
s
u
m
_
p
e
r
i
o
d
_
t
i
m
e
)
∗
c
p
u
_
c
a
p
a
c
i
t
y
util\_avg = (decay\_sum\_running\_time/decay\_sum\_period\_time) * cpu\_capacity
util_avg=(decay_sum_running_time/decay_sum_period_time)∗cpu_capacity
其中,cpu_capacity是处理器的额定算力,默认值是1024(SCHED_CAPACITY_SCALE)
二、CFS中的负载计算
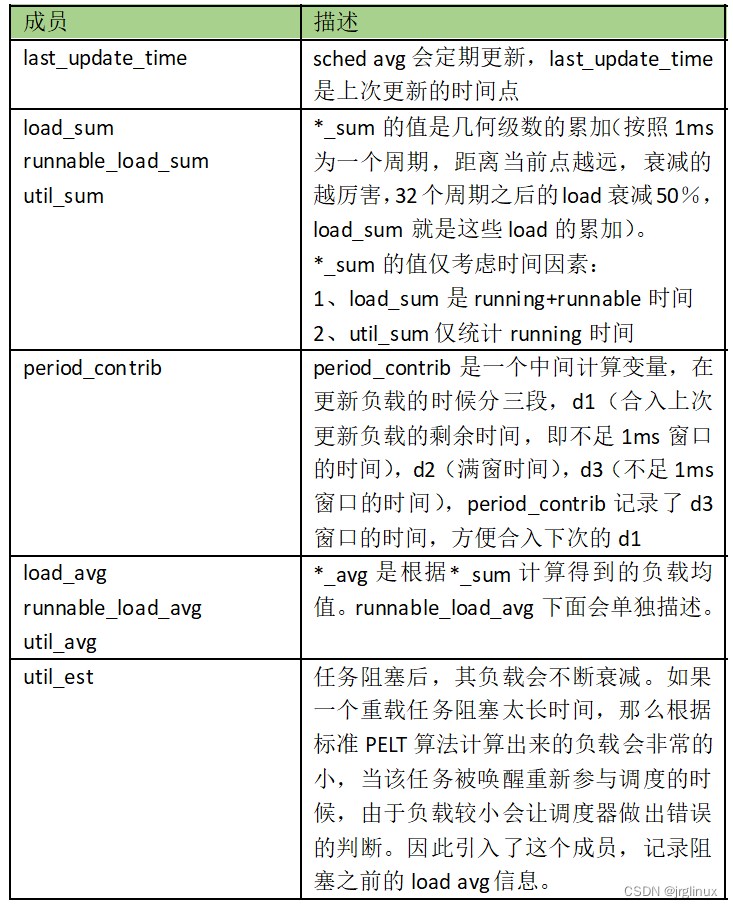
sched_avg结构体
struct sched_avg {
u64 last_update_time;
u64 load_sum;
u64 runnable_sum;
u32 util_sum;
u32 period_contrib;
unsigned long load_avg;
unsigned long runnable_avg;
unsigned long util_avg;
struct util_est util_est;
} ____cacheline_aligned;
| 成员 | 类型 | 针对sched_entity | 针对cfs_rq |
|---|---|---|---|
| last_update_time | u64 | 上一次更新的时间点,用于计算时间间隔,这好像是ns单位 | |
| load_sum | u64 | 对于sched_entity: 进程在就绪队列里的可运行状态下的累计衰减总时间(decay_sum_time),计算的是时间值 | 对于cfs_rq:调度队列中所有进程的累计工作总负载(decay_sum_load) |
| runnable_sum | u64 | 对于sched_entity:进程在就绪队列里的可运行状态下的累计衰减总时间(decay_sum_time); | 对于cfs_rq:调度队列中所有可运行状态下进程的累计工作总负载(decay_sum_load) |
| util_sum | u32 | 对于sched_entity:正在运行状态下的累计衰减总时间(decay_sum_time)。(使用cfs_rq->curr == se来判断进程是否正在运行); | 对于cfs_rq:就绪队列中所有处于运行状态进程的累计衰减总时间(decay_sum_time)。只要就绪队列里有正在运行的进程,它就会累加 |
| period_contrib | u32 | 存放上一次时间采样时,不能凑成一个周期(1024us)的剩余的时间 | |
| load_avg | unsigned long | 对于sched_entity:可运行状态下的量化负载(decay_avg_load)。负载均衡中,使用该成员来衡量一个进程的负载贡献值,如衡量迁移进程的负载量 | 对于cfs_rq:就绪队列中总的量化负载 |
| runnable_avg | unsigned long | 对于sched_entity:可运行状态下的量化负载,等同load_avg; | 对于cfs_rq:就绪队列里所有课运行状态下进程的总量化负载,SMP负载均衡算法中,使用该值来比较CPU的负载大小 |
| util_avg | unsigned long | 实际算力。通常体现于一个调度实体或者CPU的实际算力需求 | |
| util_est | struct util_est | 用于估算FAIR进程的CPU使用率,和指数加权移动平均算法有关系,参考3.4节的表格 |
sched_entity包含sched_avg,描述调度实体的负载信息
cfs_rq也包含sched_avg,描述CFS队列的负载信息
但是rt 、dl等不是这样的,需要另外再分析再看。
(1)可运行状态(runnable) 和正在运行状态(running)如何区分?
se在cfs_rq中,runnable状态,然后还要分成两个时间部分:
- 正在运行时间,running时间
- 在就绪队列中的时间,runnable时间,包含正在运行时间和等待运行时间
三、PELT算法
runnable_avg_yN_inv[ ]是内核为了方便计算,换算过得中间值。为了移位运算而不是浮点数运算。
static const u32 runnable_avg_yN_inv[] __maybe_unused = {
0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6,
0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85,
0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581,
0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9,
0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80,
0x85aac367, 0x82cd8698,
};
#define LOAD_AVG_PERIOD 32 //1ms(1024us)为一个周期,32ms(32个周期)负载就会下降一半
#define LOAD_AVG_MAX 47742 //47742是无限个周期内(n无限大)的最大衰减负载总和值
比如当前负载是100,计算过去第32ms周期的负载值:((100 * runable_avg_yN_inv[31]) >> 32) = 51
LOAD_AVG_MAX
该宏是无限个周期内的最大衰减负载,为何是1024来乘呢?因为1ms这里计算为1024us(为了方便移位操作)
最大负载load_avg_max:
1024(1+y+y2 + y3 + ... ) = 1024*((1-yn)/(1-y)) = 47742 #这个公式可推导出来, yn趋向于0,这个无穷级数在-1<y<1时是收敛的
y=0.97855138(大约)
y^32 = 0.5(大约)


2021.04.25回过头来看这个无穷级数的使用,真是666啊,负载总体趋向一个确定值,因为它是收敛的,不是发散的。
反推PELT的衰减系数因子,保留3位小数,((1000 * runnable_avg_yN_inv[]) >> 32)/1000
//将runnable_avg_yN_inv[ ]折算成系数,保留3位小数:
static const u32 runnable_avg_yN_orig[] = {
0.999, 0.978(这个值就是y), 0.957, 0.937, 0.917, 0.897,
0.878, 0.859, 0.840, 0.822, 0.805, 0.787,
...
0.522, 0.510,
};
//看上面这个数组,是不是就是 "y0, y, y2, y3, y4, ..., y31",对不对
3.1 dedcay_load–计算第n个周期的衰减负载值
**decay_load()**函数用于计算第n个周期的衰减负载值
/*
* Approximate:
* val * y^n, where y^32 ~= 0.5 (~1 scheduling period)
*/
/*val是第n个周期前的负载值,n是第n个周期*/
static u64 decay_load(u64 val, u64 n)
{
unsigned int local_n;
if (unlikely(n > LOAD_AVG_PERIOD * 63)) //如果n较大,大于32ms*63 = 2016ms,则太久远,负载可以不计算,结果为0
return 0;
/* after bounds checking we can collapse to 32-bit */
local_n = n;
/*
* As y^PERIOD = 1/2, we can combine
* y^n = 1/2^(n/PERIOD) * y^(n%PERIOD)
* With a look-up table which covers y^n (n<PERIOD)
*
* To achieve constant time decay_load.
*/
//如果n是在32~2016之间,则n/32个周期直接就是右移多少位(因为每32ms,衰减一半相当于除以2),n%32再去查表找到对应的衰减系数
if (unlikely(local_n >= LOAD_AVG_PERIOD)) {
val >>= local_n / LOAD_AVG_PERIOD; //右移n/32
local_n %= LOAD_AVG_PERIOD; //n%32就是查表的下标
}
val = mul_u64_u32_shr(val, runnable_avg_yN_inv[local_n], 32); //查表找到衰减系数,再乘以val,再右移32位,得到第n个周期的衰减负载值
return val;
}
mul_u64_u32_shr函数简单看,就是用负载值(val * [runnable_avg_yN_inv系数]) >> 32
static inline u64 mul_u64_u64_shr(u64 a, u64 mul, unsigned int shift)
{
return (u64)(((unsigned __int128)a * mul) >> shift);
}
cfs的load计算函数大体流程
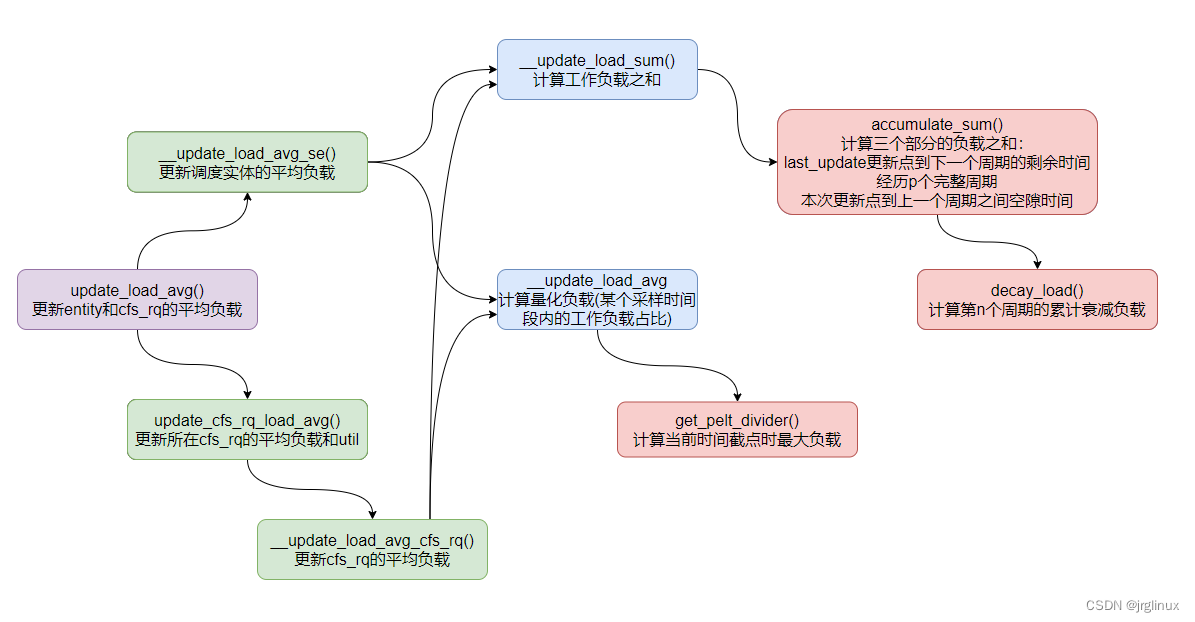
3.2 __update_load_sum计算工作负载之和
函数__update_load_sum()
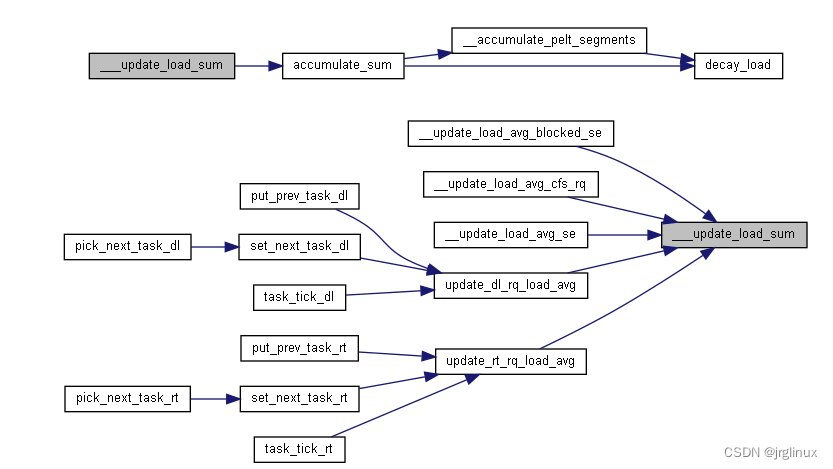
dl和rt调度器也会调用到这里,暂时先不看。
本文主要关心cfs调度器如何去更新其工作负载总和的。
代码注释中解释了:
用几何级数系列来计算历史负载贡献,以1ms为周期(1024us),p_0代表当前周期,p_N代表过去的第Nms周期
用u_i表示p_i周期中调度实体是可运行状态的时间部分,然后用u_i作为该周期计算负载的系数,用公司u_0 + u_1y + u_2y^2 + … 来表示历史负载,其中y^32=0.5(y约等于0.979),这就意味着:过去的第32ms周期,对当前最新周期u_0周期的负载计算贡献只贡献其当时的一半值
这个计算方式奇妙的地方我认为就在于:当一个周期过去后,我们就有了新的周期u_0’,直接用这个u_0’ + (之前load总和) * y 得到的就是新的负载总和
/*
* [<- 1024us ->|<- 1024us ->|<- 1024us ->| ...
* p0 p1 p2
* (now) (~1ms ago) (~2ms ago)
*
* We then designate the fractions u_i as our co-efficients, yielding the
* following representation of historical load:
* u_0 + u_1*y + u_2*y^2 + u_3*y^3 + ...
*
* When a period "rolls over" and we have new u_0`, multiplying the previous
* sum again by y is sufficient to update:
* load_avg = u_0` + y*(u_0 + u_1*y + u_2*y^2 + ... )
* = u_0 + u_1*y + u_2*y^2 + ... [re-labeling u_i --> u_{i+1}]
*/
static __always_inline int
___update_load_sum(u64 now, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u64 delta;
delta = now - sa->last_update_time; //delta用于计算当前时间点与上次更新点的时间差,单位应该是ns
/*
* This should only happen when time goes backwards, which it
* unfortunately does during sched clock init when we swap over to TSC.
* 这里处理TSC特殊情况,可以不管
*/
if ((s64)delta < 0) {
sa->last_update_time = now;
return 0;
}
/*
* Use 1024ns as the unit of measurement since it's a reasonable
* approximation of 1us and fast to compute.
*/
delta >>= 10; //将ns转为us,右移10位,也就是除以1024
if (!delta) //如果delta不足1us,则工作负载总和为0?
return 0;
sa->last_update_time += delta << 10; //这就是下一次计算时的last_update_time,这次更新时间点;
//sa->last_update_time = now? 这个地方为何不是直接等于now?也就是说这里记录的last_update_time是以us为单位的,少于1us的就没有记上,记在了后面的period_contrib里面
/*
* running is a subset of runnable (weight) so running can't be set if
* runnable is clear. But there are some corner cases where the current
* se has been already dequeued but cfs_rq->curr still points to it.
* This means that weight will be 0 but not running for a sched_entity
* but also for a cfs_rq if the latter becomes idle. As an example,
* this happens during idle_balance() which calls
* update_blocked_averages().
*
* Also see the comment in accumulate_sum().
*/
//这里的load,如果是sched_entity,load则是!!se->on_rq(两个!!是把非0值都转为1,0值还是0),也就是有可能se已经不在runqueue里了,但cfs_rq->curr还指向该se,此时load应该是0; 如果是cfs_rq调用进来,则load是cfs_rq的权重值
if (!load)
runnable = running = 0;
/*
* Now we know we crossed measurement unit boundaries. The *_avg
* accrues by two steps:
*
* Step 1: accumulate *_sum since last_update_time. If we haven't
* crossed period boundaries, finish.
*/
if (!accumulate_sum(delta, sa, load, runnable, running))
return 0;
return 1;
}
tatic u32 __accumulate_pelt_segments(u64 periods, u32 d1, u32 d3)
{
u32 c1, c2, c3 = d3; /* y^0 == 1 */
/*
* c1 = d1 y^p
*/
c1 = decay_load((u64)d1, periods);
/*
* p-1
* c2 = 1024 \Sum y^n
* n=1
*
* inf inf
* = 1024 ( \Sum y^n - \Sum y^n - y^0 )
* n=0 n=p
*/
c2 = LOAD_AVG_MAX - decay_load(LOAD_AVG_MAX, periods) - 1024;
return c1 + c2 + c3; //d3时间段就不用乘以y系数,所以直接加上
}
/*
* Accumulate the three separate parts of the sum; d1 the remainder
* of the last (incomplete) period, d2 the span of full periods and d3
* the remainder of the (incomplete) current period.
*
* d1 d2 d3
* ^ ^ ^
* | | |
* |<->|<----------------->|<--->|
* ... |---x---|------| ... |------|-----x (now)
*
* p-1
* u' = (u + d1) y^p + 1024 \Sum y^n + d3 y^0
* n=1
*
* = u y^p + (Step 1) //u*y^p就是p个周期之前的衰减总负载,就是下文step1中用decay_load()计算出来的load_sum
*
* p-1
* d1 y^p + 1024 \Sum y^n + d3 y^0 (Step 2)
* n=1
*/
static __always_inline u32
accumulate_sum(u64 delta, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u32 contrib = (u32)delta; /* p == 0 -> delta < 1024 */
u64 periods;
delta += sa->period_contrib; //这里就是两次更新之间的时间差 + 上一次更新的时间差%1024(就是上次更新时没有满足一个1024us周期的)
periods = delta / 1024; /* A period is 1024us (~1ms) */
/*
* Step 1: decay old *_sum if we crossed period boundaries.
*/
if (periods) { //如果横跨了一个周期或以上,就需要进行负载贡献衰减计算了
sa->load_sum = decay_load(sa->load_sum, periods); //这里就只计算了前面第periods周期的工作负载,刚好此时的load_sum是periods周期之前的load_sum,这样理解就符合decay_load的函数作用了---计算第n周期的工作负载
sa->runnable_sum =
decay_load(sa->runnable_sum, periods);
sa->util_sum = decay_load((u64)(sa->util_sum), periods);
/*
* Step 2
*/
delta %= 1024;
if (load) {
/*
* This relies on the:
*
* if (!load)
* runnable = running = 0;
*
* clause from ___update_load_sum(); this results in
* the below usage of @contrib to dissapear entirely,
* so no point in calculating it.
*/
contrib = __accumulate_pelt_segments(periods,
1024 - sa->period_contrib, delta);
}
}
sa->period_contrib = delta; //这里是保存的这次计算完后,取余1024,也就是不满足一个1024us周期的时间
//这里load,如果是sched_entity,它在on_rq,那么load为1,也就是它算下来这d1+d2+d3的时间里的贡献就是contrib值
//如果是cfs_rq,则load是权重,也就是用weight再乘以contrib系数,这里代码复用的很巧妙啊
if (load)
sa->load_sum += load * contrib;
if (runnable)
sa->runnable_sum += runnable * contrib << SCHED_CAPACITY_SHIFT;
if (running)
sa->util_sum += contrib << SCHED_CAPACITY_SHIFT;
return periods;
}
整理了一下整体过程,配合代码看,一下子就明白了
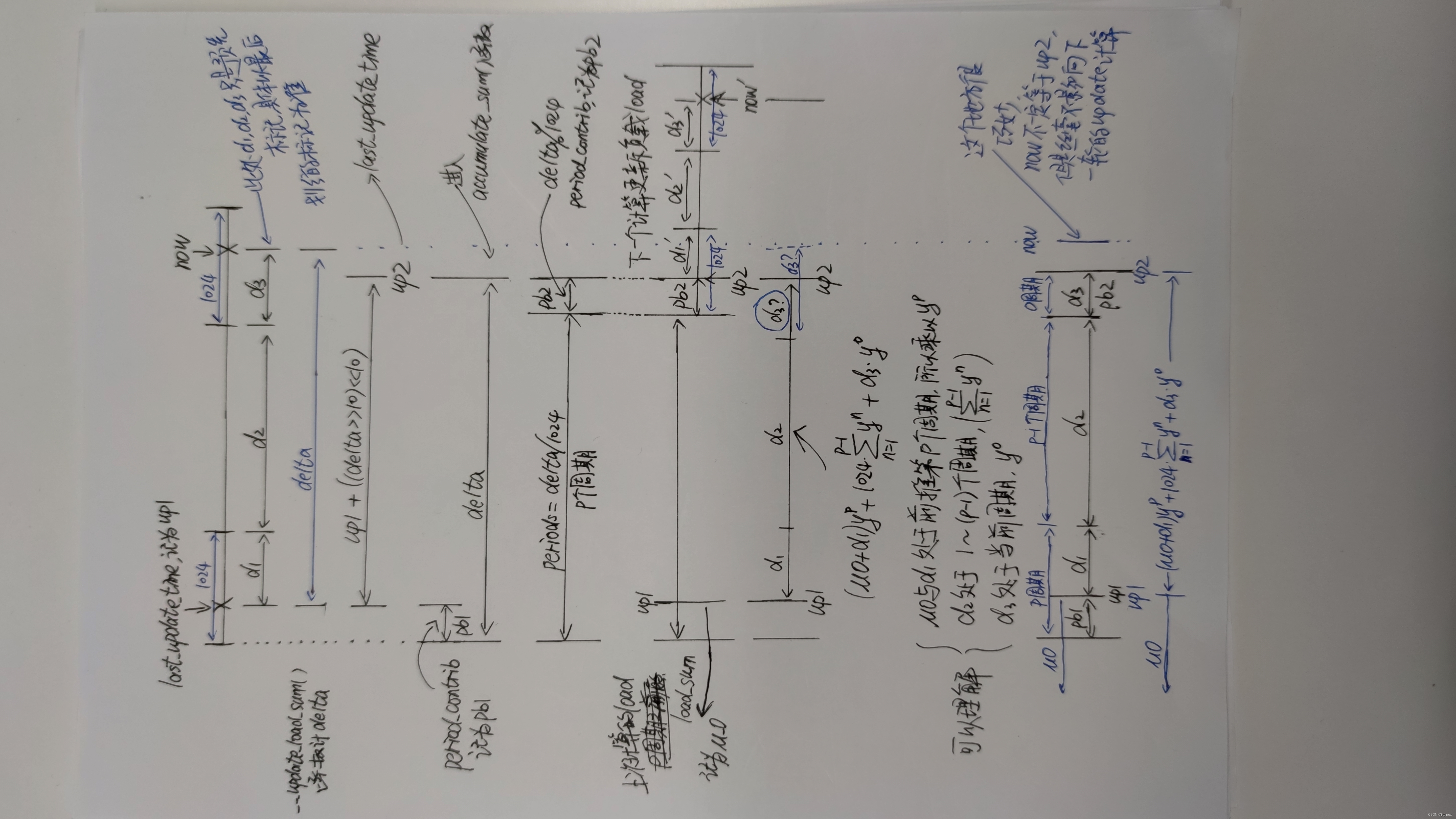
上面一个是我一边看代码一边画的,看完代码自己再根据理解重新画一下逻辑,就更简单了:
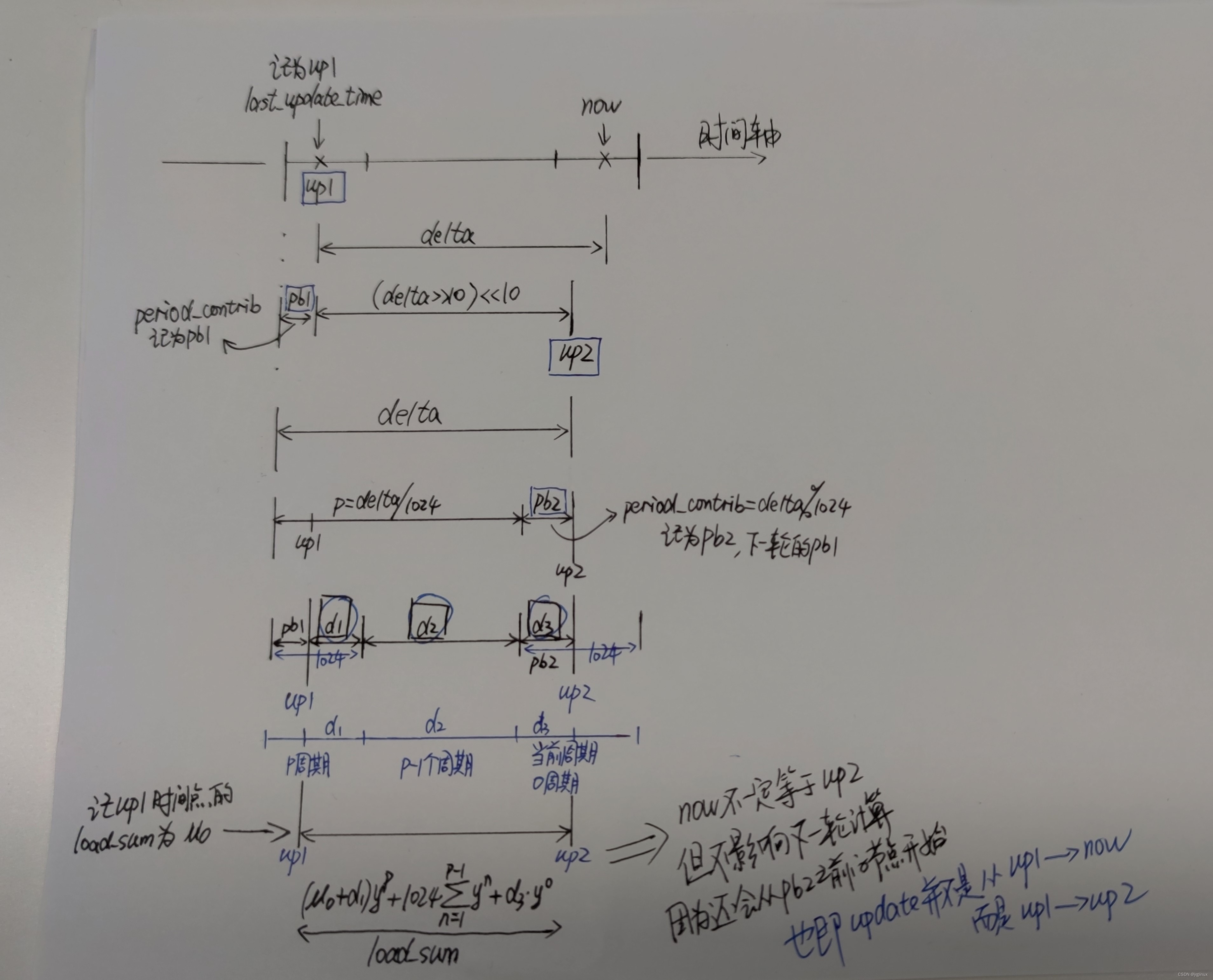
3.3 更新se或cfs_rq的负载
两个函数__update_load_avg_se(), __update_load_avg_cfs_rq()
问题1:__update_load_avg总是在判断__update_Load_sum是否为1之后才调用,这是为什么?
解答:在3.4节中解答
问题2:对于调度实体和调度队列,__update_load_sum的入参load、runnable、running分别意味着什么?
解答:
对于sched_entity,load是0或1(看on_rq),runnable也是0或1(也是看on_rq), running还是0或1布尔值,看是否是当前正在运行的
对于cfs_rq,load是队列权重,runnable是CFS就绪队列里中包含组调度里所有可运行状态的进程数量,running是cfs_rq当前curr是否为空判断0或1
int __update_load_avg_se(u64 now, struct cfs_rq *cfs_rq, struct sched_entity *se)
{
/*对于sched_entity,load是0或1(看on_rq),runnable也是0或1(也是看on_rq), running还是0或1布尔值,看是否是当前正在运行的*/
if (___update_load_sum(now, &se->avg, !!se->on_rq, se_runnable(se),
cfs_rq->curr == se)) {
___update_load_avg(&se->avg, se_weight(se));
cfs_se_util_change(&se->avg);
trace_pelt_se_tp(se);
return 1;
}
return 0;
}
int __update_load_avg_cfs_rq(u64 now, struct cfs_rq *cfs_rq)
{
/*对于cfs_rq,load是队列权重,runnable是CFS就绪队列里中包含组调度里所有可运行状态的进程数量,running是cfs_rq当前curr是否为空判断0或1*/
if (___update_load_sum(now, &cfs_rq->avg,
scale_load_down(cfs_rq->load.weight),
cfs_rq->h_nr_running,
cfs_rq->curr != NULL)) {
___update_load_avg(&cfs_rq->avg, 1);
trace_pelt_cfs_tp(cfs_rq);
return 1;
}
return 0;
}
再看一下accumulate_sum函数的最后几句:
sa->period_contrib = delta; //这个是记录下up2时间点之前的最近的一个周期点的时间间隙,就是上面手绘图里的d3
if (load)
sa->load_sum += load * contrib; //这里要区分se还是cfs_rq,se如果是在队列里load=1,cfs_rq的load则是权重;
if (runnable)
sa->runnable_sum += runnable * contrib << SCHED_CAPACITY_SHIFT;
if (running)
sa->util_sum += contrib << SCHED_CAPACITY_SHIFT;
return periods;
| sched_avg部分成员 | 调度实体sched_entity | 调度队列cfs_rq |
|---|---|---|
| load_sum | 调度实体在可运行状态的累计衰减总时间 | cfs_rq中所有在可运行状态下进程的累计工作负载总和 |
| runnable_sum | 调度实体在可运行状态下的累计衰减总时间,等于load_sum | 《奔跑吧linux内核》:cfs_rq在可运行状态下的工作负载,一般等于load_sum 《我的理解》:cfs_rq中包含组调度中所有可运行状态下进程的累计衰减总时间之和,单位us? |
| util_sum | 《奔跑吧linux内核》:调度实体在可运行状态下的总算力; 《我的理解》:就是调度实体的占用cpu的累计衰减总时间,cpu使用率? | 《奔跑吧linux内核》:cfs_rq在可运行状态下的总算力; 《我的理解》:就是cfs_rq的占用cpu的累计衰减总时间,cpu使用率? |
《内核工匠》博客里的解释如下,我觉得这个解释才是到位的:
3.4 __update_load_avg计算量化负载
函数__update_load_avg()
该函数为何这么设计-没看懂
/*
* When syncing *_avg with *_sum, we must take into account the current
* position in the PELT segment otherwise the remaining part of the segment
* will be considered as idle time whereas it's not yet elapsed and this will
* generate unwanted oscillation in the range [1002..1024[.
*
* The max value of *_sum varies with the position in the time segment and is
* equals to :
*
* LOAD_AVG_MAX*y + sa->period_contrib
*
* which can be simplified into:
*
* LOAD_AVG_MAX - 1024 + sa->period_contrib
*
* because LOAD_AVG_MAX*y == LOAD_AVG_MAX-1024
*
* The same care must be taken when a sched entity is added, updated or
* removed from a cfs_rq and we need to update sched_avg. Scheduler entities
* and the cfs rq, to which they are attached, have the same position in the
* time segment because they use the same clock. This means that we can use
* the period_contrib of cfs_rq when updating the sched_avg of a sched_entity
* if it's more convenient.
*/
static __always_inline void
___update_load_avg(struct sched_avg *sa, unsigned long load)
{
u32 divider = get_pelt_divider(sa);
/*
* Step 2: update *_avg.
*/
sa->load_avg = div_u64(load * sa->load_sum, divider); // load_sum / (1024y+period_contrib)
sa->runnable_avg = div_u64(sa->runnable_sum, divider); // runnable_sum / (1024y+period_contrib)
WRITE_ONCE(sa->util_avg, sa->util_sum / divider); //util_sum /(1024y+period_contrib)
}
static inline u32 get_pelt_divider(struct sched_avg *avg)
{
return LOAD_AVG_MAX - 1024 + avg->period_contrib;
}
__update_load_avg看注释我也没看懂为何要这么计算
1024 /(1-y) = LOAD_AVG_MAX
LOAD_AVG_MAX * y = LOAD_AVG_MAX - 1024
但是为何需要用load_sum/(LOAD_AVG_MAX -1024 + period_contrib这个零散时间)来算平均负载贡献时间呢
为何是要处理 ( 1024y + period_contrib )这个时间呢?
看注释是说,这个时间段的__sum值是最大的,不能不考虑period_contrib这段时间,如果不考虑进来,则认为period_contrib这个后面还不满一个周期的时间是idle的,会导致在[1002,1024]之间震荡?
没理解这地方的原因,why?
是不是可以理解,load_avg是计算的平均负载嘛,就要用将load_sum按照最长累计衰减时间(一个周期左右)来进行等分?所以记上period_contrib
__update_load_avg总是在判断__update_Load_sum是否为1之后才调用,这是为什么?
解答:未能找到说服我自己的答案; period_contrib(也就是时间轴图里的d3)如果为0,则不需要执行update load_avg了?也就说,up2与up1之前的那个周期节点之间刚好是若干个周期时间,此时为何load_sum增加了,但load_avg就不更新了?不更新load_avg是不是就意味着load_avg没有变?没有变意味着啥,load_avg也不能以有无period_contrib来决定要不要更新啊?period_contrib是跟update_time有关系的
实在没理解__update_load_avg这个函数为何需要这么做?
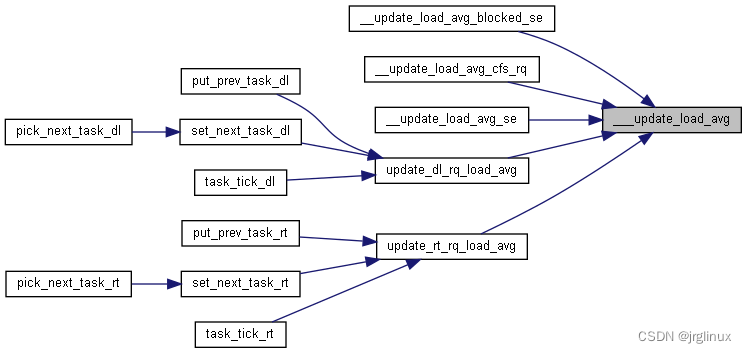
3.5 PELT中的负载计算接口API
cfs调度器
通过update_load_avg接口进入pelt中的算法。更新调度实体和调度队列的负载
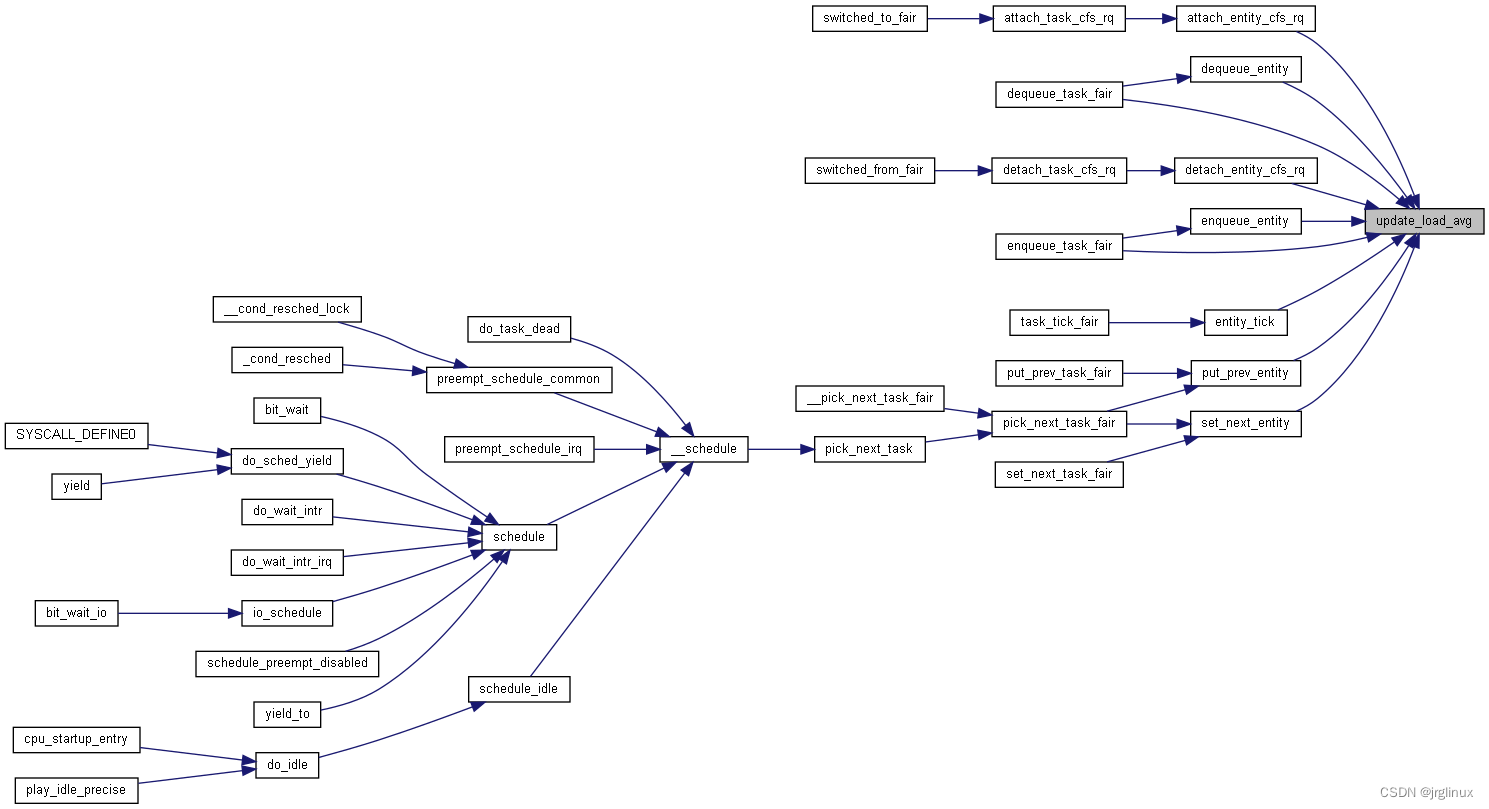
下图中是先调用 __update_load_sum, 再调用 __update_load_avg

rt调度器
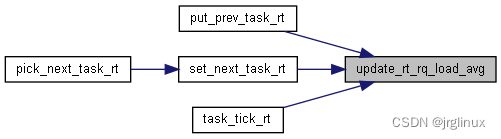
/*
* rt_rq:
*
* util_sum = \Sum se->avg.util_sum but se->avg.util_sum is not tracked
* util_sum = cpu_scale * load_sum
* runnable_sum = util_sum
*
* load_avg and runnable_avg are not supported and meaningless.
*
*/
int update_rt_rq_load_avg(u64 now, struct rq *rq, int running)
{
if (___update_load_sum(now, &rq->avg_rt,
running,
running,
running)) {
___update_load_avg(&rq->avg_rt, 1);
trace_pelt_rt_tp(rq);
return 1;
}
return 0;
}
dl调度器
/*
* dl_rq:
*
* util_sum = \Sum se->avg.util_sum but se->avg.util_sum is not tracked
* util_sum = cpu_scale * load_sum
* runnable_sum = util_sum
*
* load_avg and runnable_avg are not supported and meaningless.
*
*/
int update_dl_rq_load_avg(u64 now, struct rq *rq, int running)
{
if (___update_load_sum(now, &rq->avg_dl,
running,
running,
running)) {
___update_load_avg(&rq->avg_dl, 1);
trace_pelt_dl_tp(rq);
return 1;
}
return 0;
}








![[附源码]SSM计算机毕业设计校园超市进销存管理系统JAVA](https://img-blog.csdnimg.cn/1bd23675070d45a2b6b47f84dfd3c398.png)

![五、Javascript 空间坐标[尺寸、滑动]](https://img-blog.csdnimg.cn/ae8b594654b74898b073994af964c502.png)