Diffusion Model for Object Detection
一种用于目标检测的扩散模型
-
Motivation
1、如何使用一种更简单的方法代替可查询的object queries
2、Bounding box的生成方式过去是三种,第一种为sliding windows、第二种anchor box、第三种object queries,这里其实还有一种当时非常非常火的anchor free
3、本文提出基于生成的的检测方式,主要在目标检测方面的两大发现 -
Innovation
1、将目标检测表示为从噪声框到对象框的去噪扩散过程。
2、发现一随机框相比预设锚点、目标检索的方式不同但同样能实现从候选区域找到目标。
3、发现二目标检测的特征感知提取任务可以通过生成的方式解决。
4、图1中C的表述为目标检测表示为从噪声框到目标框的去噪扩散逆向过程 -
Contribution
1、首次将扩散模型用于目标检测,将目标检测过程定义为一个去噪过程
2、从噪声框到检测框通过动态框的解耦训练和评估阶段及渐进式细化
3、在两个数据集上的实验证明了这种检测器的有效性 -
Methodology
方差时间表控制获取噪声框的过程,通过生成技术从随机噪声框中国预测真实框
将噪声框从骨干编码器输出的特征图中裁剪感兴趣的区域ROI特征
将ROI特征发送到解码器预测出没有包含噪声的真实值,从而实现从随机框中预测出真实框
1、目标检测的几种常见范式

2、扩散模型的去噪方法应用
3、感知任务的扩散模型:参考采用像素比特扩散模型对图像和视频的全景分割,图像通过编码器进行对输入的数据特征提取表示,解码器将噪声框作为输入后预测分类和框坐标。训练过程种,噪声框是通过向真实值添加高斯噪声来构建的。推理过程种,噪声框是从高斯分布种随机采样得到的。
4、本文的实现方式:x表示输入图像向量;b表示边框矩阵,c表示类别标签矩阵。
4.1、通过马尔可夫链逐渐向样本数据添加噪音来定向设计扩散过程的前向传播方法,训练过程通过L2范数学习从目标噪音目标到真实目标过程(这个思路本人认为是非常经典的创新),推理阶段是从噪声图像中重建目标图像数据样本思路,由于扩散迭代所以网络结果如下。
4.2、网络结构:编码器运行从原始输入图像提取特征,解码器逐步细化来自噪声框的真实框得到结果。
4.3、图像编码器:从原始输入图像提取高级特征,这一部分基于ResNet、Swin的特征金字塔实现。
4.4、图像解码器:从一组建议噪声框作为输入选举ROI,并对这些ROI借助Sparse R-CNN的6个级联对应到真实框中。
4.5、训练过程:先从真实框到噪声框扩散生成,然后训练过程反转将额外的框填充到真实的框。

4.6推理过程:从噪声框中寻找目标框的采样实现是通过高斯分布采样框开始逐步预测,第一步是解码器预测分类和坐标,第二步是采用DDIM进一步预测坐标,bbox通过随机框过滤恢复框,然后通过高斯分布采用把新随机框预测。 -
Result
1、在MS-COCO上和LVIS上验证了它的通用性(once for all)
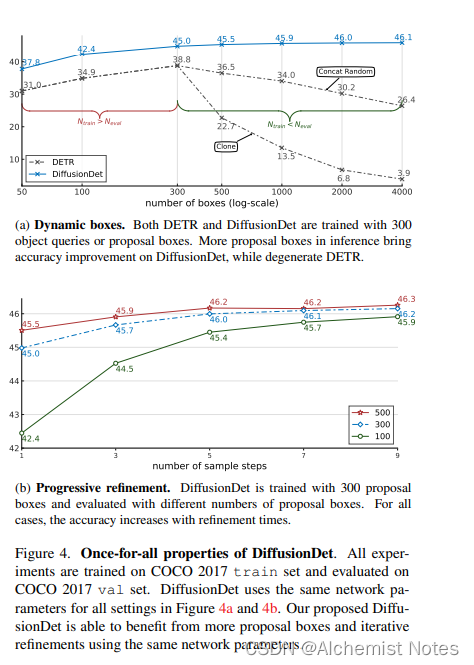
-
Application
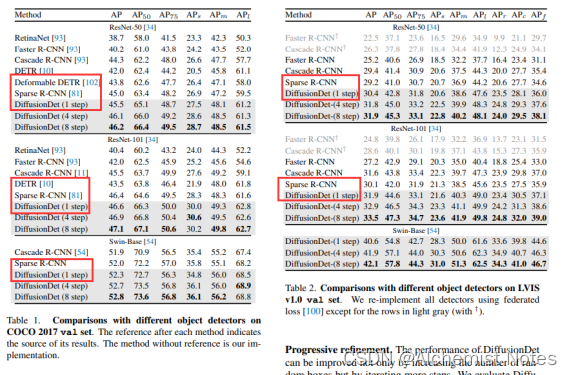
AP表现最佳
对比了Faster R-CNN、Cascade R-CNN、Sparse R-CNN,未来在多目标跟踪、关键点动作识别。
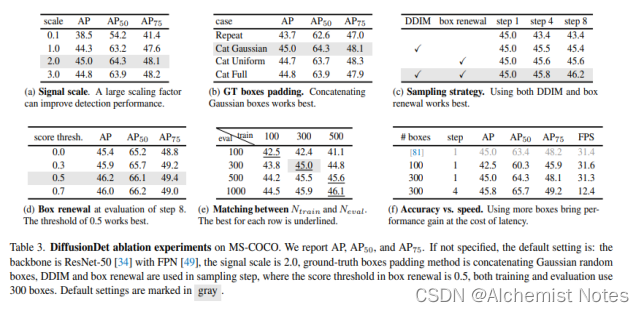

相关评论:https://www.zhihu.com/question/567414823/answer/2767617257





![[附源码]SSM计算机毕业设计校园超市进销存管理系统JAVA](https://img-blog.csdnimg.cn/1bd23675070d45a2b6b47f84dfd3c398.png)

![五、Javascript 空间坐标[尺寸、滑动]](https://img-blog.csdnimg.cn/ae8b594654b74898b073994af964c502.png)