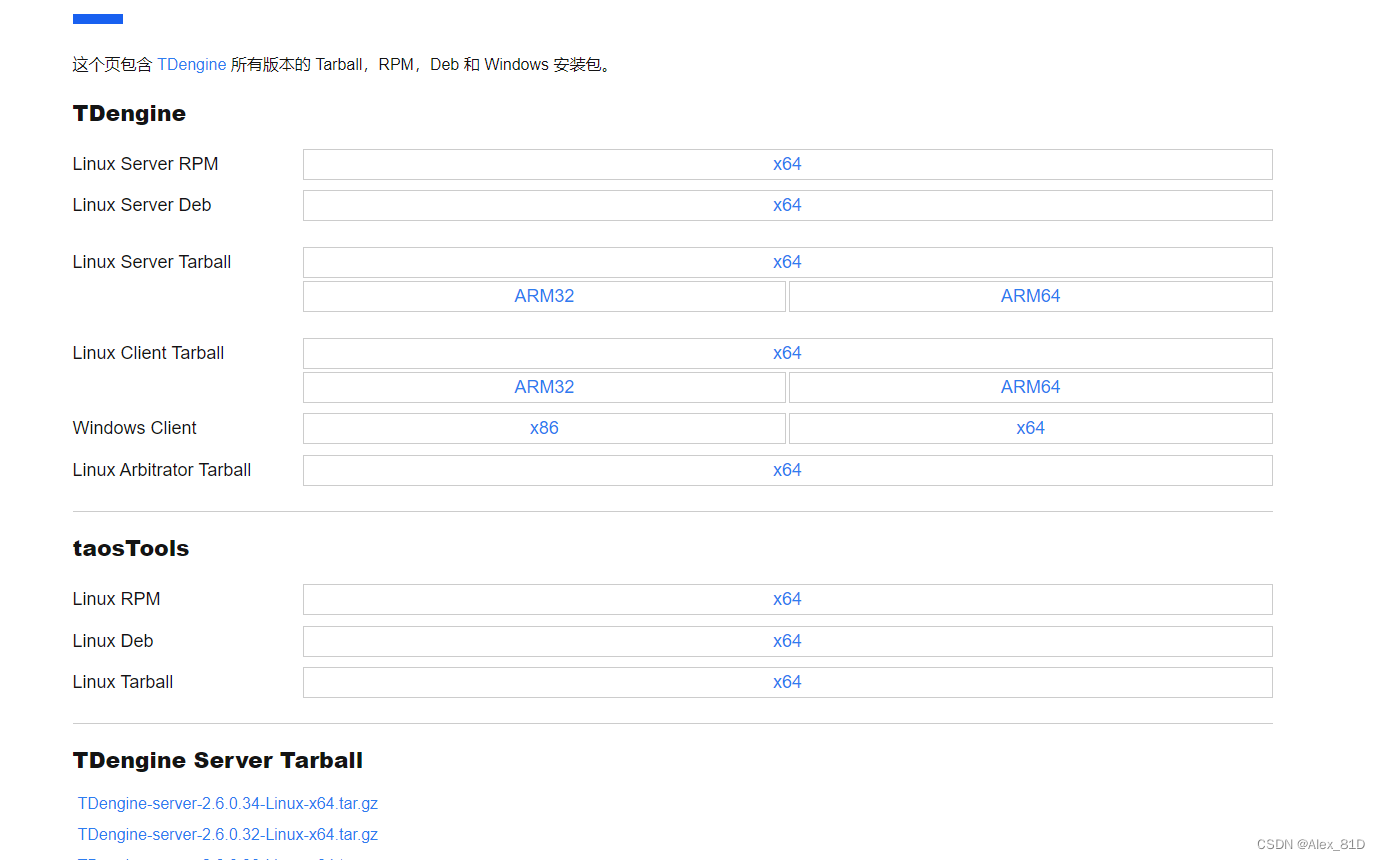
文章目录
- 1 对picodet xs
- 1.1 动态图转静态图
- 1.2 静态图转onnx
- 1.3 paddle 含后处理 all 版本的推理
- 1.4 onnx 含后处理 all 进行推理
- 1.5 onnx 不含后处量 base模型推理
- 1.5.1 获取onnx模型任一节点的输出
- 1.5.2 base模型的推理
- 1.6、对picodet-xs模型进行优化
- 1.6.1 picodet-xs base 原始模型优化
- 1.6.2 为onnx增加shape方便可视化
- 1.6.3 对模型进行简化
- 1.6.4 裁剪模型
- 1.6.5 再次优化模型
- 1.6.6 裁剪后模型推理
- 2、统计测试集上检测结果是那个检测头的输出
1 对picodet xs
! tree -L 2 inference_model/picodet_xs_256_base_20230405
96982.22s - pydevd: Sending message related to process being replaced timed-out after 5 seconds
[01;34minference_model/picodet_xs_256_base_20230405[0m
├── [01;34mpicodet_xs_320_voc_256_20230405[0m
│ ├── [00minfer_cfg.yml[0m
│ ├── [00mmodel.pdiparams[0m
│ ├── [00mmodel.pdiparams.info[0m
│ └── [00mmodel.pdmodel[0m
├── [00mpicodet_xs_320_voc_256_20230405.onnx[0m
├── [00mpicodet_xs_320_voc_256_20230405_prune_2head.onnx[0m
├── [00mpicodet_xs_320_voc_256_20230405_prune.onnx[0m
├── [00mpicodet_xs_320_voc_256_20230405_prune_sim.onnx[0m
├── [00mpicodet_xs_320_voc_256_20230405_shape.onnx[0m
├── [00mpicodet_xs_320_voc_256_20230405_shape_sim.onnx[0m
├── [00mpicodet_xs_320_voc_256_20230405_shape_sim_prune.onnx[0m
└── [00mpicodet_xs_320_voc_256_20230405_shape_sim_prune_sim.onnx[0m
2 directories, 12 files
1.1 动态图转静态图
! python tools/export_model.py -c configs/picodet/picodet_xs_320_voc_256_20230405.yml -o weights=output/picodet_xs_320_voc_256_20230405/0.pdparams TestReader.inputs_def.image_shape=[3,256,256] export.benchmark=False --output_dir inference_model/picodet_xs_256_all_20230405
Warning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly
[04/10 19:44:17] ppdet.utils.checkpoint INFO: Finish loading model weights: output/picodet_xs_320_voc_256_20230405/0.pdparams
[04/10 19:44:17] ppdet.engine INFO: Export inference config file to inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405/infer_cfg.yml
[04/10 19:44:21] ppdet.engine INFO: Export model and saved in inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405
! python tools/export_model.py -c configs/picodet/picodet_xs_320_voc_256_20230405.yml -o weights=output/picodet_xs_320_voc_256_20230405/0.pdparams TestReader.inputs_def.image_shape=[3,256,256] export.benchmark=True --output_dir inference_model/picodet_xs_256_base_20230405
Warning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly
[04/10 19:44:27] ppdet.utils.checkpoint INFO: Finish loading model weights: output/picodet_xs_320_voc_256_20230405/0.pdparams
[04/10 19:44:27] ppdet.engine INFO: Export inference config file to inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405/infer_cfg.yml
[04/10 19:44:31] ppdet.engine INFO: Export model and saved in inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405
以上两部分的代码的差异无非只是benchmark True与False的区别。True的时候,不含用后处理和nms;否则会包括。同时输入节点会多一个,下文我们讲。
从代码上来看主要改变的是head,代码在这里ppdet/modeling/heads/pico_head.py.
forward_eval中benchmark True与False走了两条分支,post_process在benchmark False才会调用nms
#两个函数
def forward_eval(self, fpn_feats, export_post_process=True):
if self.eval_size:
anchor_points, stride_tensor = self.anchor_points, self.stride_tensor
else:
anchor_points, stride_tensor = self._generate_anchors(fpn_feats)
cls_score_list, box_list = [], []
for i, (fpn_feat, stride) in enumerate(zip(fpn_feats, self.fpn_stride)):
_, _, h, w = fpn_feat.shape
# task decomposition
conv_cls_feat, se_feat = self.conv_feat(fpn_feat, i)
cls_logit = self.head_cls_list[i](se_feat)
reg_pred = self.head_reg_list[i](se_feat)
# cls prediction and alignment
if self.use_align_head:
cls_prob = F.sigmoid(self.cls_align[i](conv_cls_feat))
cls_score = (F.sigmoid(cls_logit) * cls_prob + eps).sqrt()
else:
cls_score = F.sigmoid(cls_logit)
################################从这一部分开始变的不一样###################################
if not export_post_process:
# Now only supports batch size = 1 in deploy
cls_score_list.append(
cls_score.reshape([1, self.cls_out_channels, -1]).transpose(
[0, 2, 1]))
box_list.append(
reg_pred.reshape([1, (self.reg_max + 1) * 4, -1]).transpose(
[0, 2, 1]))
else:
l = h * w
cls_score_out = cls_score.reshape(
[-1, self.cls_out_channels, l])
bbox_pred = reg_pred.transpose([0, 2, 3, 1])
bbox_pred = self.distribution_project(bbox_pred)
bbox_pred = bbox_pred.reshape([-1, l, 4])
cls_score_list.append(cls_score_out)
box_list.append(bbox_pred)
if export_post_process:
cls_score_list = paddle.concat(cls_score_list, axis=-1)
box_list = paddle.concat(box_list, axis=1)
box_list = batch_distance2bbox(anchor_points, box_list)
box_list *= stride_tensor
return cls_score_list, box_list
#这部分是包括nms的,这个nms 是ppdet/modeling/layers.py 里边的,paddle.ops.multiclass_nms(bboxes, score, **kwargs)不是python㝍的
def post_process(self, head_outs, scale_factor, export_nms=True):
pred_scores, pred_bboxes = head_outs
if not export_nms:
return pred_bboxes, pred_scores
else:
# rescale: [h_scale, w_scale] -> [w_scale, h_scale, w_scale, h_scale]
scale_y, scale_x = paddle.split(scale_factor, 2, axis=-1)
scale_factor = paddle.concat(
[scale_x, scale_y, scale_x, scale_y],
axis=-1).reshape([-1, 1, 4])
# scale bbox to origin image size.
pred_bboxes /= scale_factor
bbox_pred, bbox_num, _ = self.nms(pred_bboxes, pred_scores)
return bbox_pred, bbox_num
1.2 静态图转onnx
%%bash
paddle2onnx --model_dir inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405 \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--opset_version 11 \
--input_shape_dict="{'image':[1, 3, 256, 256]}" \
--save_file inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405.onnx
[1;31;40m2023-04-10 12:32:31 [WARNING] [Deprecated] The flag `--input_shape_dict` is deprecated, if you need to modify the input shape of PaddlePaddle model, please refer to this tool https://github.com/jiangjiajun/PaddleUtils/tree/main/paddle [0m
[Paddle2ONNX] Start to parse PaddlePaddle model...
[Paddle2ONNX] Model file path: inference_model/picodet_s_256_all_20230404/picodet_s_416_voc_npu_256_20230404/model.pdmodel
[Paddle2ONNX] Paramters file path: inference_model/picodet_s_256_all_20230404/picodet_s_416_voc_npu_256_20230404/model.pdiparams
[Paddle2ONNX] Start to parsing Paddle model...
[Paddle2ONNX] Use opset_version = 11 for ONNX export.
[WARN][Paddle2ONNX] [multiclass_nms3: multiclass_nms3_0.tmp_1] [WARNING] Due to the operator multiclass_nms3, the exported ONNX model will only supports inference with input batch_size == 1.
[Paddle2ONNX] PaddlePaddle model is exported as ONNX format now.
2023-04-10 12:32:32 [INFO] ===============Make PaddlePaddle Better!================
2023-04-10 12:32:32 [INFO] A little survey: https://iwenjuan.baidu.com/?code=r8hu2s
%%bash
paddle2onnx --model_dir inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405 \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--opset_version 11 \
--input_shape_dict="{'image':[1, 3, 256, 256]}" \
--save_file inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405.onnx
[1;31;40m2023-04-10 12:33:24 [WARNING] [Deprecated] The flag `--input_shape_dict` is deprecated, if you need to modify the input shape of PaddlePaddle model, please refer to this tool https://github.com/jiangjiajun/PaddleUtils/tree/main/paddle [0m
[Paddle2ONNX] Start to parse PaddlePaddle model...
[Paddle2ONNX] Model file path: inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405/model.pdmodel
[Paddle2ONNX] Paramters file path: inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405/model.pdiparams
[Paddle2ONNX] Start to parsing Paddle model...
[Paddle2ONNX] Use opset_version = 11 for ONNX export.
[Paddle2ONNX] PaddlePaddle model is exported as ONNX format now.
2023-04-10 12:33:24 [INFO] ===============Make PaddlePaddle Better!================
2023-04-10 12:33:24 [INFO] A little survey: https://iwenjuan.baidu.com/?code=r8hu2s
以上两部分一个是all,一个是base,我们分别做一次转换,并有把输入形状固定成batch size=1, w h 都 是256.事实上,这些都是可以变的,按需求改就可以,要支持变batch可以改成-1,要变尺度输入,那么也要用多尺度来训练。
我是要用到一个自己的芯片上,所以必须固定。
对于这两个模型的差异,可以用netron工具来查看。
1.3 paddle 含后处理 all 版本的推理
! python deploy/python/infer.py --model_dir=inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405 --image_file=dataset/pqdetection_sliced2voc/pq_160_75/images/1_280_120_440_280.jpg --output_dir=inference_model/picodet_xs_256_all_20230405/
156452.34s - pydevd: Sending message related to process being replaced timed-out after 5 seconds
----------- Running Arguments -----------
action_file: None
batch_size: 1
camera_id: -1
combine_method: nms
cpu_threads: 1
device: cpu
enable_mkldnn: False
enable_mkldnn_bfloat16: False
image_dir: None
image_file: dataset/pqdetection_sliced2voc/pq_160_75/images/1_280_120_440_280.jpg
match_metric: ios
match_threshold: 0.6
model_dir: inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405
output_dir: inference_model/picodet_xs_256_all_20230405/
overlap_ratio: [0.25, 0.25]
random_pad: False
reid_batch_size: 50
reid_model_dir: None
run_benchmark: False
run_mode: paddle
save_images: True
save_mot_txt_per_img: False
save_mot_txts: False
save_results: False
scaled: False
slice_infer: False
slice_size: [640, 640]
threshold: 0.5
tracker_config: None
trt_calib_mode: False
trt_max_shape: 1280
trt_min_shape: 1
trt_opt_shape: 640
use_coco_category: False
use_dark: True
use_gpu: False
video_file: None
window_size: 50
------------------------------------------
<class 'str'>
----------- Model Configuration -----------
Model Arch: GFL
Transform Order:
--transform op: Resize
--transform op: NormalizeImage
--transform op: Permute
--------------------------------------------
class_id:0, confidence:0.9329, left_top:[24.32,83.76],right_bottom:[76.05,132.11]
/home/tl/PD26/deploy/python/visualize.py:162: DeprecationWarning: textsize is deprecated and will be removed in Pillow 10 (2023-07-01). Use textbbox or textlength instead.
tw, th = draw.textsize(text)
save result to: inference_model/picodet_xs_256_all_20230405/1_280_120_440_280.jpg
Test iter 0
------------------ Inference Time Info ----------------------
total_time(ms): 110.9, img_num: 1
average latency time(ms): 110.90, QPS: 9.017133
preprocess_time(ms): 5.70, inference_time(ms): 105.20, postprocess_time(ms): 0.00
from IPython import display
display.Image("inference_model/picodet_xs_256_all_20230405/1_280_120_440_280.jpg")

1.4 onnx 含后处理 all 进行推理
! python deploy/third_engine/onnx/infer.py --infer_cfg inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405/infer_cfg.yml --onnx_file inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405.onnx --image_file dataset/pqdetection_sliced2voc/pq_160_75/images/1_280_120_440_280.jpg
156483.59s - pydevd: Sending message related to process being replaced timed-out after 5 seconds
2023-04-12 15:51:28.317660597 [W:onnxruntime:, graph.cc:3494 CleanUnusedInitializersAndNodeArgs] Removing initializer 'Constant_34'. It is not used by any node and should be removed from the model.
----------- Model Configuration -----------
Model Arch: GFL
Transform Order:
--transform op: Resize
--transform op: NormalizeImage
--transform op: Permute
--------------------------------------------
ONNXRuntime predict:
0 0.9328661561012268 24.321531295776367 83.75709533691406 76.04914855957031 132.11187744140625
可以看到结果是相同的
1.5 onnx 不含后处量 base模型推理
benchmark为True时,需要自己写后处理和nms,这些代码都是从pico_head.py(继承gflhead)中提取出来的
1.5.1 获取onnx模型任一节点的输出
这个是我们先要总结的,在调试onnx模型时非常必要,我们要查看每个节点的输入(某另一节点的输出)输出,也能推测出这一层的权重,或者是op的作用.默认模型的输出节点是可以直接获取,而
其它节点需要先加入到输出节点中
import cv2
import numpy as np
import math
import onnx
from scipy.special import softmax
from onnxruntime import InferenceSession
base model的输入输出如图:
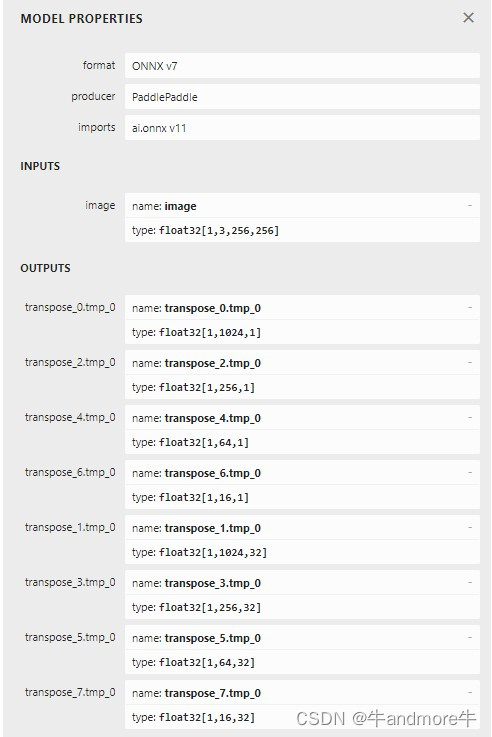
‘tmp_1’, ‘tmp_3’, ‘tmp_5’, ‘tmp_7’, ‘conv2d_146.tmp_1’, ‘conv2d_154.tmp_1’, ‘conv2d_162.tmp_1’ 这几个都是我们计划要用到的,用netron可以查看
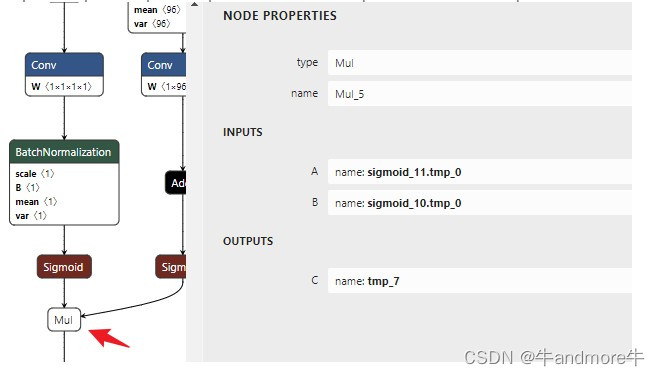
model = onnx.load("inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405.onnx")
my_outputs=['tmp_1', 'tmp_3', 'tmp_5', 'tmp_7', 'conv2d_146.tmp_1', 'conv2d_154.tmp_1', 'conv2d_162.tmp_1']
model.graph.output.extend([onnx.ValueInfoProto(name=i) for i in my_outputs])
predictor = InferenceSession(model.SerializeToString())
#####################预处理###################################
data = np.fromfile("dataset/pqdetection_sliced2voc/pq_160_75/images/1_280_120_440_280.jpg", dtype='uint8')
im = cv2.imdecode(data, 1) # BGR mode, but need RGB mode
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
#resize
h,w = im.shape[:2]
resize_h=256
resize_w=256
im_scale_y = resize_h / float(h)
im_scale_x = resize_w / float(w)
im = cv2.resize(
im,
None,
None,
fx=im_scale_x,
fy=im_scale_y,
interpolation=2)
#normalize
scale = 1.0 / 255.0
mean=[0,0,0]
std=[1,1,1]
im = im.astype(np.float32, copy=False)
im *= scale
mean = np.array(mean)[np.newaxis, np.newaxis, :]
std = np.array(std)[np.newaxis, np.newaxis, :]
im -= mean
im /= std
#permute
im = np.expand_dims(im.transpose((2, 0, 1)).copy(),0)
#####################forward###########################
inputs_name = [var.name for var in predictor.get_inputs()]
inputs ={inputs_name[0]:im}
# inputs = {inputs_name[0]:im,inputs_name[1]:np.array(
# [im_scale_y, im_scale_x]).astype('float32')[None,]}
outputs = predictor.run(output_names=my_outputs, input_feed=inputs)
for i in outputs:
print(f"type:{type(i)} shape:{i.shape}")
type:<class 'numpy.ndarray'> shape:(1, 1, 32, 32)
type:<class 'numpy.ndarray'> shape:(1, 1, 16, 16)
type:<class 'numpy.ndarray'> shape:(1, 1, 8, 8)
type:<class 'numpy.ndarray'> shape:(1, 1, 4, 4)
type:<class 'numpy.ndarray'> shape:(1, 32, 32, 32)
type:<class 'numpy.ndarray'> shape:(1, 32, 16, 16)
type:<class 'numpy.ndarray'> shape:(1, 32, 8, 8)
1.5.2 base模型的推理
def generate_anchors(eval_size,fpn_stride,cell_offset=0):
# just use in eval time
anchor_points = []
stride_tensor = []
for i, stride in enumerate(fpn_stride):
h = math.ceil(eval_size[0] / stride)
w = math.ceil(eval_size[1] / stride)
shift_x = np.arange(w) + cell_offset
shift_y = np.arange(h) + cell_offset
shift_x, shift_y = np.meshgrid(shift_y, shift_x)
anchor_point = np.array(
np.stack(
[shift_x, shift_y], axis=-1), dtype='float32')
anchor_points.append(anchor_point.reshape([-1, 2]))
stride_tensor.append(
np.full(
[h * w, 1], stride, dtype='float32'))
anchor_points = np.concatenate(anchor_points)
stride_tensor = np.concatenate(stride_tensor)
return anchor_points, stride_tensor
def nms(scores,boxes,match_threshold=0.4):
""" Apply NMS to avoid detecting too many overlapping bounding boxes.
Args:
scores: shape [N,], [score]
bboxes: shape [N,4] [x1, y1, x2, y2]
match_threshold: overlap thresh for match metric.
"""
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
areas = (x2-x1+1)*(y2-y1+1)
order = scores.argsort()[::-1]
keep=[]
while order.size>0:
i =order[0] #无条件保留每次迭代中置信度最高的框
keep.append(i)
#计算置信度最高的框与其它框的交
xx1 = np.maximum(x1[i],x1[order[1:]])
yy1 = np.maximum(y1[i],y1[order[1:]])
xx2 = np.minimum(x2[i],x2[order[1:]])
yy2 = np.minimum(y2[i],y2[order[1:]])
#求交的面积
w = np.maximum(0,xx2-xx1+1)
h = np.maximum(0,yy2-yy1+1)
inter=w*h
#求交并
ovr = inter/(areas[i]+areas[order[1:]]-inter)
inds = np.where(ovr<=match_threshold)[0]
#因为不包括order[0]
order=order[inds+1]
return keep
predictor = InferenceSession("inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405.onnx")
#####################预处理###################################
data = np.fromfile("dataset/pqdetection_sliced2voc/pq_160_75/images/1_280_120_440_280.jpg", dtype='uint8')
im = cv2.imdecode(data, 1) # BGR mode, but need RGB mode
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
#resize
h,w = im.shape[:2]
resize_h=256
resize_w=256
im_scale_y = resize_h / float(h)
im_scale_x = resize_w / float(w)
im = cv2.resize(
im,
None,
None,
fx=im_scale_x,
fy=im_scale_y,
interpolation=2)
#normalize
scale = 1.0 / 255.0
mean=[0,0,0]
std=[1,1,1]
im = im.astype(np.float32, copy=False)
im *= scale
mean = np.array(mean)[np.newaxis, np.newaxis, :]
std = np.array(std)[np.newaxis, np.newaxis, :]
im -= mean
im /= std
#permute
im = np.expand_dims(im.transpose((2, 0, 1)).copy(),0)
#####################forward###########################
inputs_name = [var.name for var in predictor.get_inputs()]
inputs = {inputs_name[0]:im}
outputs = predictor.run(output_names=None, input_feed=inputs)
for i in outputs:
print(f"type:{type(i)} shape:{i.shape}")
# post preprocess
c1,c2,c3,c4,reg1,reg2,reg3,reg4=outputs
project = np.array([0,1,2,3,4,5,6,7],dtype="float32")
h,w= 32,32
c1 = c1.transpose(0,2,1) # 1 1024 1 to 1,1,1024
reg1 = reg1.reshape(-1,8) # 1 1024 32 to 4096,8
reg1 = softmax(reg1,axis=1)
reg1 = np.matmul(reg1,project)
reg1 = reg1.reshape(-1,h*w,4)
h,w= 16,16
c2 = c2.transpose(0,2,1)
reg2 = reg2.reshape(-1,8)
reg2 = softmax(reg2,axis=1)
reg2 = np.matmul(reg2,project)
reg2 = reg2.reshape(-1,h*w,4)
h,w= 8,8 #1, 32, 8, 8
c3 = c3.transpose(0,2,1)
reg3 = reg3.reshape(-1,8)
reg3 = softmax(reg3,axis=1)
reg3 = np.matmul(reg3,project)
reg3 = reg3.reshape(-1,h*w,4)
h,w= 4,4
c4 = c4.transpose(0,2,1)
reg4 = reg4.reshape(-1,8)
reg4 = softmax(reg4,axis=1)
reg4 = np.matmul(reg4,project)
reg4 = reg4.reshape(-1,h*w,4)
cls_score_list=[c1,c2,c3,c4]
box_list=[reg1,reg2,reg3,reg4]
cls_score_list = np.concatenate(cls_score_list,axis=-1)
box_list = np.concatenate(box_list,axis=1)
eval_size=[resize_h,resize_w]
fpn_stride=[8,16,32,64]
anchor_points,stride_tensor = generate_anchors(eval_size, fpn_stride,cell_offset=0.5)
scale_factor =np.array([im_scale_x, im_scale_y, im_scale_x, im_scale_y]).reshape([-1, 1, 4])
lt, rb = np.split(box_list, 2, -1)
# # while tensor add parameters, parameters should be better placed on the second place
x1y1 = -lt + anchor_points
x2y2 = rb + anchor_points
out_bbox = np.concatenate([x1y1, x2y2], -1)
out_bbox *=stride_tensor
out_bbox /= scale_factor
cls_score_list = cls_score_list.flatten()
box_list = out_bbox.reshape(-1,4)
cls_threshold=0.4
keep = cls_score_list > cls_threshold
scores=cls_score_list[keep]
boxes=box_list[keep]
nms_keep = nms(scores,boxes,0.1)
for i in nms_keep:
print(f" result {i+1} score:{scores[i]} box:{boxes[i]}")
type:<class 'numpy.ndarray'> shape:(1, 1024, 1)
type:<class 'numpy.ndarray'> shape:(1, 256, 1)
type:<class 'numpy.ndarray'> shape:(1, 64, 1)
type:<class 'numpy.ndarray'> shape:(1, 16, 1)
type:<class 'numpy.ndarray'> shape:(1, 1024, 32)
type:<class 'numpy.ndarray'> shape:(1, 256, 32)
type:<class 'numpy.ndarray'> shape:(1, 64, 32)
type:<class 'numpy.ndarray'> shape:(1, 16, 32)
result 5 score:0.9328661561012268 box:[ 24.342953 83.770905 76.035545 132.09286 ]
print(nms_keep)
可以看出结果也是相等的
1.6、对picodet-xs模型进行优化
这部分工作主要是基于onnx base模型,把不常见的算子,后处理等都另外处理.这里是因为我们自己芯片不支持后处理中的sqrt和reshape,transpose算子,所以我们对onnx模型进行截取裁剪。
另外我们这个模型为了运行速度达到最快,已经把se和share (配置文件中)去掉。
1.6.1 picodet-xs base 原始模型优化
| 分类分支 | 检测分支 |
|---|---|
| “transpose_0.tmp_0” | “transpose_1.tmp_0” |
| “transpose_2.tmp_0” | “transpose_3.tmp_0” |
| “transpose_4.tmp_0” | “transpose_5.tmp_0” |
| “transpose_6.tmp_0” | “transpose_7.tmp_0” |
如图:
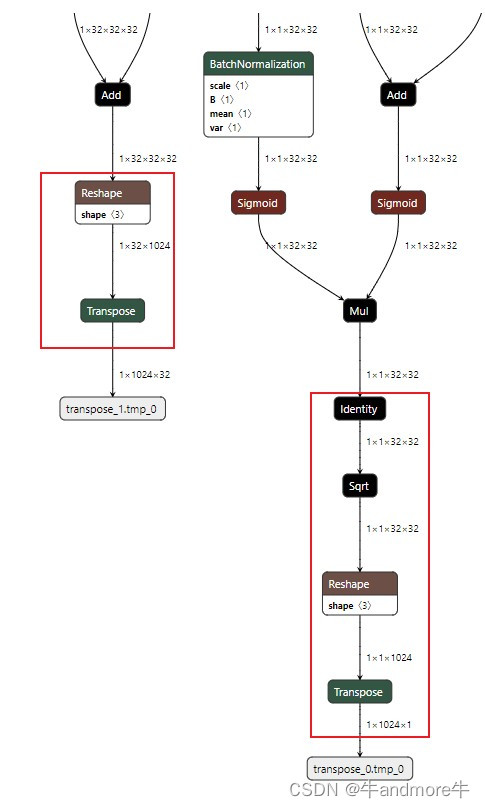
在有些板子的芯片上,可能sqrt,reshape和transpose是不支持的,所以把这些个去掉,新的输出结点(用netron查看)是:
| 分类分支 | 检测分支 |
|---|---|
| “tmp_1” | “conv2d_138.tmp_0” |
| “tmp_3” | “conv2d_146.tmp_0” |
| “tmp_5” | “conv2d_154.tmp_0” |
| “tmp_7” | “conv2d_162.tmp_0” |
如果是sim后的模型则
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a8uh261t-1681868232130)(attachment:image-2.png)]
| 分类分支 | 检测分支 |
|---|---|
| “tmp_1” | “conv2d_146.tmp_1” |
| “tmp_3” | “conv2d_154.tmp_1” |
| “tmp_5” | “conv2d_162.tmp_1” |
| “tmp_7” | “conv2d_170.tmp_1” |
| 对比过,两都是一样的,不过直接使用原始的了 |
1.6.2 为onnx增加shape方便可视化
!python ~/Paddle2ONNX/tools/onnx/onnx_infer_shape.py --input inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405.onnx --output inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405_shape.onnx
1.6.3 对模型进行简化
! python -m onnxsim inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405_shape.onnx inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405_shape_sim.onnx
94309.73s - pydevd: Sending message related to process being replaced timed-out after 5 seconds
Simplifying[33m...[0m
Finish! Here is the difference:
┏━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┓
┃ ┃ Original Mode┃Simplified Model ┃
┡━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━┩
│ Add │ 13 │ 1 │
│ BatchNormalization │ 82 │0 │
│ Concat │ 4 │ 4 │
│ Constant │ 458 │0 │
│ Conv │ 94 │ 94 │
│ GlobalAveragePool │ 2 │ 2 │
│ Identity │ 4 │0 │
│ Mul │ 6 │ 6 │
│ Relu │ 60 │ 60 │
│ Reshape │ 20 │ 8 │
│ Resize │ 2 │ 2 │
│ Sigmoid │ 10 │ 10 │
│ Sqrt │ 4 │ 4 │
│ Transpose │ 8 │ 8 │
│ Model Size │ 2.6MiB │ 2.4M │
└────────────────────┴────────────────┴──────────────────┘
1.6.4 裁剪模型
!python ~/Paddle2ONNX/tools/onnx/prune_onnx_model.py --model inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405.onnx --output_names tmp_1 tmp_3 tmp_5 tmp_7 conv2d_146.tmp_1 conv2d_154.tmp_1 conv2d_162.tmp_1 conv2d_170.tmp_1 --save_file inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405_prune.onnx
159750.21s - pydevd: Sending message related to process being replaced timed-out after 5 seconds
735 xxxx
[Finished] The new model saved in inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405_prune.onnx.
[DEBUG INFO] The inputs of new model: ['image']
[DEBUG INFO] The outputs of new model: ['tmp_1', 'tmp_3', 'tmp_5', 'tmp_7', 'conv2d_146.tmp_1', 'conv2d_154.tmp_1', 'conv2d_162.tmp_1', 'conv2d_170.tmp_1']
!python ~/Paddle2ONNX/tools/onnx/prune_onnx_model.py --model inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405_shape_sim.onnx --output_names tmp_1 tmp_3 tmp_5 tmp_7 conv2d_146.tmp_0 conv2d_154.tmp_0 conv2d_162.tmp_0 conv2d_170.tmp_0 --save_file inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405_shape_sim_prune.onnx
179 xxxx
[Finished] The new model saved in inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405_shape_sim_prune.onnx.
[DEBUG INFO] The inputs of new model: ['image']
[DEBUG INFO] The outputs of new model: ['tmp_1', 'tmp_3', 'tmp_5', 'tmp_7', 'conv2d_146.tmp_0', 'conv2d_154.tmp_0', 'conv2d_162.tmp_0', 'conv2d_170.tmp_0']
1.6.5 再次优化模型
! python -m onnxsim inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405_prune.onnx inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405_prune_sim.onnx
94359.18s - pydevd: Sending message related to process being replaced timed-out after 5 seconds
Simplifying[33m...[0m
Finish! Here is the difference:
┏━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┓
┃[1m [0m[1m [0m[1m [0m┃[1m [0m[1mOriginal Model[0m[1m [0m┃[1m [0m[1mSimplified Model[0m[1m [0m┃
┡━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━┩
│ Add │ 12 │ 1 │
│ BatchNormalization │ 82 │ 0 │
│ Concat │ 4 │ 4 │
│ Constant │ 447 │0 │
│ Conv │ 93 │ 93 │
│ GlobalAveragePool │ 2 │ 2 │
│ Mul │ 6 │ 6 │
│ Relu │ 60 │ 60 │
│ Reshape │ 11 │0 │
│ Resize │ 2 │ 2 │
│ Sigmoid │ 10 │ 10 │
│ Model Size │ 2.6MiB │2.4M │
└────────────────────┴────────────────┴──────────────────┘
可以看到我们的算子个数大量减少,类型有Add,Concat,Conv,GlobalAveragePool,Relu,Mul,Resize,Sigmoid,非常常规的操作
1.6.6 裁剪后模型推理
这部分只要把裁剪的部分加下即可,我们用的是直接从原始模型上进行裁剪的,与原始模型相比,差的部分就是:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iXOCCfDC-1681868232154)(attachment:image.png)]
所以把这部分加上就可以了
def generate_anchors(eval_size,fpn_stride,cell_offset=0):
# just use in eval time
anchor_points = []
stride_tensor = []
for i, stride in enumerate(fpn_stride):
h = math.ceil(eval_size[0] / stride)
w = math.ceil(eval_size[1] / stride)
shift_x = np.arange(w) + cell_offset
shift_y = np.arange(h) + cell_offset
shift_x, shift_y = np.meshgrid(shift_y, shift_x)
anchor_point = np.array(
np.stack(
[shift_x, shift_y], axis=-1), dtype='float32')
anchor_points.append(anchor_point.reshape([-1, 2]))
stride_tensor.append(
np.full(
[h * w, 1], stride, dtype='float32'))
anchor_points = np.concatenate(anchor_points)
stride_tensor = np.concatenate(stride_tensor)
return anchor_points, stride_tensor
def nms(scores,boxes,match_threshold=0.4):
""" Apply NMS to avoid detecting too many overlapping bounding boxes.
Args:
scores: shape [N,], [score]
bboxes: shape [N,4] [x1, y1, x2, y2]
match_threshold: overlap thresh for match metric.
"""
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
areas = (x2-x1+1)*(y2-y1+1)
order = scores.argsort()[::-1]
keep=[]
while order.size>0:
i =order[0] #无条件保留每次迭代中置信度最高的框
keep.append(i)
#计算置信度最高的框与其它框的交
xx1 = np.maximum(x1[i],x1[order[1:]])
yy1 = np.maximum(y1[i],y1[order[1:]])
xx2 = np.minimum(x2[i],x2[order[1:]])
yy2 = np.minimum(y2[i],y2[order[1:]])
#求交的面积
w = np.maximum(0,xx2-xx1+1)
h = np.maximum(0,yy2-yy1+1)
inter=w*h
#求交并
ovr = inter/(areas[i]+areas[order[1:]]-inter)
inds = np.where(ovr<=match_threshold)[0]
#因为不包括order[0]
order=order[inds+1]
return keep
# predictor = InferenceSession("inference_model/picodet_s_256_all_20230405/picodet_s_416_voc_npu_256_20230405.onnx")
predictor = InferenceSession("inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405_prune.onnx")
# predictor = InferenceSession("inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405_shape_sim_prune_sim.onnx")
#####################预处理###################################
data = np.fromfile("dataset/pqdetection_sliced2voc/pq_160_75/images/1_280_120_440_280.jpg", dtype='uint8')
im = cv2.imdecode(data, 1) # BGR mode, but need RGB mode
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
#resize
h,w = im.shape[:2]
resize_h=256
resize_w=256
im_scale_y = resize_h / float(h)
im_scale_x = resize_w / float(w)
im = cv2.resize(
im,
None,
None,
fx=im_scale_x,
fy=im_scale_y,
interpolation=2)
#normalize
scale = 1.0 / 255.0
mean=[0,0,0]
std=[1,1,1]
im = im.astype(np.float32, copy=False)
im *= scale
mean = np.array(mean)[np.newaxis, np.newaxis, :]
std = np.array(std)[np.newaxis, np.newaxis, :]
im -= mean
im /= std
#permute
im = np.expand_dims(im.transpose((2, 0, 1)).copy(),0)
#####################forward###########################
inputs_name = [var.name for var in predictor.get_inputs()]
inputs = {inputs_name[0]:im}
outputs1 = predictor.run(output_names=None, input_feed=inputs)
# for i in outputs1:
# print(f"type:{type(i)} shape:{i.shape}")
# post preprocess
c1,c2,c3,c4,reg1,reg2,reg3,reg4=outputs1
# project = np.array([0., 1.0006256, 2.0012512, 3.0021927, 4.0025024, 5.003126 ,6.0043855, 7.0043807],dtype='float32')
project = np.array([0,1,2,3,4,5,6,7],dtype="float32")
h,w= reg1.shape[2:] #1, 32, 32, 32
c1 = np.sqrt(c1).reshape(1,1,h*w) #1,1,32,32 to 1,1,1024
reg1 = reg1.transpose([0,2,3,1])
reg1 = reg1.reshape(-1,8)
reg1 = softmax(reg1,axis=1)
reg1 = np.matmul(reg1,project)
reg1 = reg1.reshape(-1,h*w,4)
h,w= reg2.shape[2:] #1, 32, 16, 16
c2 = np.sqrt(c2).reshape(1,1,h*w) #1,1,16,16 to 1,1,256
reg2 = reg2.transpose([0,2,3,1]).reshape(-1,8)
reg2 = softmax(reg2,axis=1)
reg2 = np.matmul(reg2,project)
reg2 = reg2.reshape(-1,h*w,4)
h,w= reg3.shape[2:] #1, 32, 8, 8
c3 = np.sqrt(c3).reshape(1,1,h*w) #1,1,8,8 to 1,1,64
reg3 = reg3.transpose([0,2,3,1]).reshape(-1,8)
reg3 = softmax(reg3,axis=1)
reg3 = np.matmul(reg3,project)
reg3 = reg3.reshape(-1,h*w,4)
h,w= reg4.shape[2:]
c4 = np.sqrt(c4).reshape(1,1,h*w) #1,1,4,4 to 1,1,16
reg4 = reg4.transpose([0,2,3,1]).reshape(-1,8)
reg4 = softmax(reg4,axis=1)
reg4 = np.matmul(reg4,project)
reg4 = reg4.reshape(-1,h*w,4)
cls_score_list=[c1,c2,c3,c4]
box_list=[reg1,reg2,reg3,reg4]
cls_score_list = np.concatenate(cls_score_list,axis=-1)
box_list = np.concatenate(box_list,axis=1)
eval_size=[resize_h,resize_w]
fpn_stride=[8,16,32,64]
anchor_points,stride_tensor = generate_anchors(eval_size, fpn_stride,cell_offset=0.5)
scale_factor =np.array([im_scale_x, im_scale_y, im_scale_x, im_scale_y]).reshape([-1, 1, 4])
lt, rb = np.split(box_list, 2, -1)
# # while tensor add parameters, parameters should be better placed on the second place
x1y1 = -lt + anchor_points
x2y2 = rb + anchor_points
out_bbox = np.concatenate([x1y1, x2y2], -1)
out_bbox *=stride_tensor
out_bbox /= scale_factor
cls_score_list = cls_score_list.flatten()
box_list = out_bbox.reshape(-1,4)
cls_threshold=0.4
keep = cls_score_list > cls_threshold
scores=cls_score_list[keep]
boxes=box_list[keep]
nms_keep = nms(scores,boxes,0.1)
for i in nms_keep:
print(f" result {i+1} score:{scores[i]} box:{boxes[i]}")
result 5 score:0.9328662157058716 box:[ 24.342953 83.770905 76.035545 132.09286 ]
2、统计测试集上检测结果是那个检测头的输出
这个工作是因为我们已经拿到所有检测头的检测结果,可以分析不同头对不同尺度的目标的检测情况。对于我的这次目标,是乒乓球,小目标,经过统计
发现,98%在第一个检测头上检出;这也就是说我们在提取onnx模型时,可以只提取前两个头,进行处理,这样还会进一步缩小模型并加快推理速度
import cv2
import os
import tqdm
import numpy as np
import math
import onnx
from scipy.special import softmax
from onnxruntime import InferenceSession
def generate_anchors(eval_size,fpn_stride,cell_offset=0):
# just use in eval time
anchor_points = []
stride_tensor = []
for i, stride in enumerate(fpn_stride):
h = math.ceil(eval_size[0] / stride)
w = math.ceil(eval_size[1] / stride)
shift_x = np.arange(w) + cell_offset
shift_y = np.arange(h) + cell_offset
shift_x, shift_y = np.meshgrid(shift_y, shift_x)
anchor_point = np.array(
np.stack(
[shift_x, shift_y], axis=-1), dtype='float32')
anchor_points.append(anchor_point.reshape([-1, 2]))
stride_tensor.append(
np.full(
[h * w, 1], stride, dtype='float32'))
anchor_points = np.concatenate(anchor_points)
stride_tensor = np.concatenate(stride_tensor)
return anchor_points, stride_tensor
def nms(scores,boxes,match_threshold=0.4):
""" Apply NMS to avoid detecting too many overlapping bounding boxes.
Args:
scores: shape [N,], [score]
bboxes: shape [N,4] [x1, y1, x2, y2]
match_threshold: overlap thresh for match metric.
"""
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
areas = (x2-x1+1)*(y2-y1+1)
order = scores.argsort()[::-1]
keep=[]
while order.size>0:
i =order[0] #无条件保留每次迭代中置信度最高的框
keep.append(i)
#计算置信度最高的框与其它框的交
xx1 = np.maximum(x1[i],x1[order[1:]])
yy1 = np.maximum(y1[i],y1[order[1:]])
xx2 = np.minimum(x2[i],x2[order[1:]])
yy2 = np.minimum(y2[i],y2[order[1:]])
#求交的面积
w = np.maximum(0,xx2-xx1+1)
h = np.maximum(0,yy2-yy1+1)
inter=w*h
#求交并
ovr = inter/(areas[i]+areas[order[1:]]-inter)
inds = np.where(ovr<=match_threshold)[0]
#因为不包括order[0]
order=order[inds+1]
return keep
# predictor = InferenceSession("inference_model/picodet_s_256_all_20230405/picodet_s_416_voc_npu_256_20230405.onnx")
predictor = InferenceSession("inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405.onnx")
# predictor = InferenceSession("inference_model/picodet_xs_256_base_20230405/picodet_xs_320_voc_256_20230405_shape_sim_prune_sim.onnx")
#####################预处理###################################
all_get={"stride8":0,"stride16":0,"stride32":0,"stride64":0,"other":0}
all_images=[]
stride16=[]
for root,dir,files in os.walk('dataset/pqdetection_sliced2voc'):
if len(files):
for file in files:
if file.endswith('.jpg'):
p = os.path.join(root,file)
all_images.append(p)
for img in tqdm.tqdm(all_images):
data = np.fromfile(img, dtype='uint8')
im = cv2.imdecode(data, 1) # BGR mode, but need RGB mode
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
#resize
h,w = im.shape[:2]
resize_h=256
resize_w=256
im_scale_y = resize_h / float(h)
im_scale_x = resize_w / float(w)
im = cv2.resize(
im,
None,
None,
fx=im_scale_x,
fy=im_scale_y,
interpolation=2)
#normalize
scale = 1.0 / 255.0
mean=[0,0,0]
std=[1,1,1]
im = im.astype(np.float32, copy=False)
im *= scale
mean = np.array(mean)[np.newaxis, np.newaxis, :]
std = np.array(std)[np.newaxis, np.newaxis, :]
im -= mean
im /= std
#permute
im = np.expand_dims(im.transpose((2, 0, 1)).copy(),0)
#####################forward###########################
inputs_name = [var.name for var in predictor.get_inputs()]
inputs = {inputs_name[0]:im}
outputs1 = predictor.run(output_names=None, input_feed=inputs)
# for i in outputs1:
# print(f"type:{type(i)} shape:{i.shape}")
# post preprocess
c1,c2,c3,c4,reg1,reg2,reg3,reg4=outputs1
# project = np.array([0., 1.0006256, 2.0012512, 3.0021927, 4.0025024, 5.003126 ,6.0043855, 7.0043807],dtype='float32')
project = np.array([0,1,2,3,4,5,6,7],dtype="float32")
h,w= 32,32 #1, 32, 32, 32
c1 = c1.transpose([0,2,1]) # 1,1024,1 to 1,1,1024
reg1 = reg1.reshape(-1,8)
reg1 = softmax(reg1,axis=1)
reg1 = np.matmul(reg1,project)
reg1 = reg1.reshape(-1,h*w,4)
h,w= 16,16 #1, 32, 16, 16
c2 = c2.transpose([0,2,1]) #1,1,16,16 to 1,1,256
reg2 = reg2.reshape(-1,8)
reg2 = softmax(reg2,axis=1)
reg2 = np.matmul(reg2,project)
reg2 = reg2.reshape(-1,h*w,4)
h,w= 8,8 #1, 32, 8, 8
c3 = c3.transpose([0,2,1]) #1,1,8,8 to 1,1,64
reg3 = reg3.reshape(-1,8)
reg3 = softmax(reg3,axis=1)
reg3 = np.matmul(reg3,project)
reg3 = reg3.reshape(-1,h*w,4)
h,w= 4,4
c4 = c4.transpose([0,2,1]) #1,1,4,4 to 1,1,16
reg4 = reg4.reshape(-1,8)
reg4 = softmax(reg4,axis=1)
reg4 = np.matmul(reg4,project)
reg4 = reg4.reshape(-1,h*w,4)
cls_score_list=[c1,c2,c3,c4]
box_list=[reg1,reg2,reg3,reg4]
cls_score_list = np.concatenate(cls_score_list,axis=-1)
box_list = np.concatenate(box_list,axis=1)
eval_size=[resize_h,resize_w]
fpn_stride=[8,16,32,64]
anchor_points,stride_tensor = generate_anchors(eval_size, fpn_stride,cell_offset=0.5)
scale_factor =np.array([im_scale_x, im_scale_y, im_scale_x, im_scale_y]).reshape([-1, 1, 4])
lt, rb = np.split(box_list, 2, -1)
# # while tensor add parameters, parameters should be better placed on the second place
x1y1 = -lt + anchor_points
x2y2 = rb + anchor_points
out_bbox = np.concatenate([x1y1, x2y2], -1)
out_bbox *=stride_tensor
out_bbox /= scale_factor
cls_score_list = cls_score_list.flatten()
box_list = out_bbox.reshape(-1,4)
cls_threshold=0.4
#keep = cls_score_list > cls_threshold
#scores=cls_score_list[keep]
#boxes=box_list[keep]
keep = np.where(cls_score_list>cls_threshold)
scores = np.take(cls_score_list,keep)[0]
boxes=np.take(box_list,keep,axis=0)[0]
nms_keep = nms(scores,boxes,0.2)
get = np.take(keep,nms_keep).tolist()
for g in get:
if g<1024:
all_get['stride8']+=1
elif 1024<=g<1280:
all_get['stride16']+=1
stride16.append(img)
elif 1280<=g<1344:
all_get['stride32']+=1
elif 1344<=g<1360:
all_get['stride64']+=1
else:
all_get['other']+=1
print(f"all we get is {all_get}")