博主简介
博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介: 本专栏主要研究计算机视觉,涉及算法,案例实践,网络模型等知识。包括一些常用的数据处理算法,也会介绍很多的Python第三方库。如果需要,点击这里订阅专栏 。
给大家分享一个我很喜欢的一句话:“每天多努力一点,不为别的,只为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”

目录
R-CNN网络
Fast R-CNN网络
Faster R-CNN
作为基于深度学习的目标检测算法的开山之作,R-CNN由Ross Girshick在2014年首次发表,论文全名为Rich feature hierarchies for accurate object detection and semantic segmentation。在VOC2012数据集上,平均精度均值(mAP)较之前最好的模型提升30%,从此目标检测也正式进入深度学习时代。
R-CNN网络
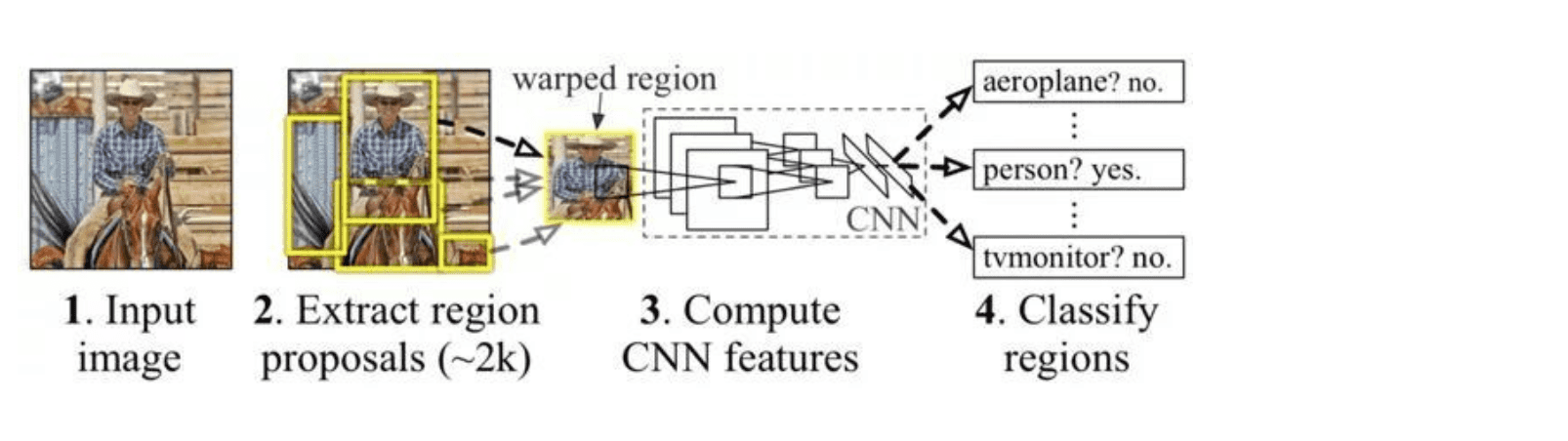
上面的是R-CNN网络目标检测的过程图,和传统方法相似,R-CNN网络还是分了两步解决目标检测问题,第一步先做候选框提取(约2000个),然后将每个候选框中的图片输入同一个卷积神经网络进行特征提取,最终训练分类器识别物体,所以也叫做两阶段算法。
| 方法 | 定位 | 特征提取 | 分类 |
| 传统方法 | 约束参数最小切割、滑动窗口等 | HOG、SIFT、LBP、BoW、DPW等 | SVM、逻辑回归 |
| R-CNN | 选择搜索 | 深度学习CNN | 二元线性SVM |
首先,后选框提取使用一种改进算法:选择性搜索,其根本思想是一个物体上的像素互相之间比较相似,所以可以把相似的像素合成一个物体。具体步骤为:首先将图像分成很多个小块,然后计算每两个相邻的区域的相似度,然后每次合并最相似的两块,直到最终只剩下一块完整的图片,这其中每次产生的图像块我们都保存下来作为候选框,此种方法比暴力窗口滑动方法速度更快,并且准确率更高。
接下来,提取特征的卷积神经网络用AlexNet网络结构,具体结构在前面已经介绍过了,输入图像尺寸统一为227x227,输出特征尺寸为2000x4096,选取2000个候选框,每个框输出4096个分类概率。
最后,训练线性SVM,权重矩阵尺寸为4096xN,输出维度N为物体的类别。

整个训练过程如下:
(1)、对于训练数据集中的图像,采用选择搜索方式来获取候选框,每个图像得到2000多个候选框。
(2)、准备正负样本。首先真实物体框为正样本,但是由于真实物体框很少(一般一张图片只有几个),从而会导致样本不平衡,所以还需要加入更多的正样本。如果某个候选框和当前图像上的某个物体框的IOU大于或等于0.5,则该候选框作为这个物体类别的正样本,否则作为负样本。需要注意的是,总共有N+1个类别,包括N个武器类别和一个背景类别。
(3)、对卷积神经网络进行预训练,由于标注的检测数据较少,所以采取迁移学习的方式,先利用ImageNet的数据集对网络进行预训练。
(4)、微调模型,首先将候选框选出的图像大小统一为227x227(这是因为卷积神经网络有全连接层,需要输入图像的大小固定)。然后在目标检测数据集(VOC和ILSVRC2013)进行训练,学习率调整为预训练的1/10。每个批次中有32个正样本和96个负样本。
(5)、存储第五层池化后的所有特征,并保存到磁盘,数据量大约有20GB。
(6)、训练SVM分类器,正样本为物体框,对于负样本,我们需要重新选择IOU的阈值。
(7)、在测试的时候,我们还需要使用非极大值抑制去除重复的候选框。
Fast R-CNN网络
其实在前面的介绍中,我们会发现选择算法选区的候选框有大量重叠,就产生了大量重复计算。至于解决方法嘛,就是对于输入的一整张图片,我们对于不同的候选框,在末尾层才加入候选框的位置的信息(或者说在末尾特征图上进行候选框选取)。 但是对于不同的候选框,大小也不同,我们就需要用到ROI池化层方法,对于ROI池化层,无论输入图像大小为多少,输出图像的大小都一样。其次,就是我们其实是可以去掉SVM训练器,将SVM训练器改为Softmax激活函数,直接输出每一类的概率,从而提高训练速度。然后,训练时,每个训练批次选用两张图片中的128个ROI进行训练,只需要计算两张图片的特征,大大减少计算量,从而提高速度。
最后就是修正损失函数,将分类损失和位置损失加总,并用一个参数控制两者平衡,其中分类损失使用交叉熵损失,而位置损失使用光滑L1损失。
在加入了这些改经后,Fast-CNN的训练速度和测试速度就比之前提高了很多。
(1)、和R-CNN类似,先进行候选框搜索,每张图像大约选取2000个候选框。
(2)、训练卷积神经网络,网络结构和之前类似,在最后的特征图中选择候选框对应的位置。
(3)、将特征图中选择的候选框输入ROI池化层,再经过全连接层后输出物体类别和位置回归参数,每个训练批次选择两张图片,每张图片选择64个候选框,其中25%有物体(IOU>0.5),其余为背景。数据增强使用了水平翻转。在测试的时候每张图像大约提取2000个候选框。损失函数将类别损失与位置损失相加,类别损失使用交叉熵损失,位置损失使用l1损失。
(4)、
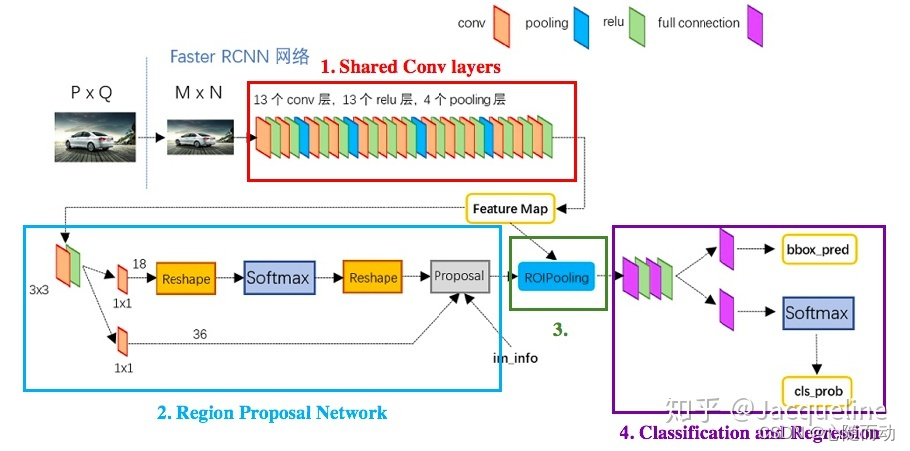
Faster R-CNN
在R-CNN和Fast R-CNN之后,Ross B.Girshick在2016年提出了新的Faster R-CNN,主要优化还是在速度上。在Faster R-CNN,作者将特征提取、候选框生成、位置回归统一在一个神经网络中运行。

在Faster R-CNN中,候选框生成部分叫做Region Proposal Networks(RPN)。
这里我们介绍一个新的概念:anchors,中文叫做预定义边框,顾名思义,是一组预设的边框,在训练时,以真实的边框相对于预设边框的便宜来生成标签。
anchor的大小如何定义?一般我们使用长宽比和尺度因子,例如长宽比为r,尺度因子为s,矩形基本面积 为,则anchor的长h,宽w。
在Faster R-CNN中,anchor的长宽比使用了三个值,分别为1、2、0.5,尺度因子也使用了三个值,分别为8,16,32,矩形基本面积为(16x16=)256,所以两组组合得到9个大小不同的anchor,其中面积比较大的就是512x512和724x362,比较小的是128x128和181x91.相较于原图大小(800x600),涵盖了大部分的情况。
现在来介绍一下训练过程:
(1)、将图片统一调整为800x600,这是由于现在我们anchor的大小位置固定,对于不同大小的图片稳健性变低。
(2)、通过预训练的卷积神经网络提取特征,CNN网络使用VGG16网络结构。
(3)、通过RPN网络得到候选框,训练RPN网络时,不用训练所有的anchor,而是随机选择128个正例和128个负例,IOU>0.7的anchor为正例,IOU<0.3的anchor为负例,其余不进行训练。
(4)、通过Proposal层,得到较精确的候选框,数量由17100下降300左右,正样本比例约为0.25.
(5)、从特征图上经过候选框剪裁,输入ROI池化层。
(6)、通过全连接层进行物体分类和位置回归。
(7)、最后当然还是进行非极大值抑制。
最终,Faster R-CNN比Fast -R-CNN测试速度又增加了10倍,准确率又有所增加,此为二阶段目标检测模型的巅峰。