
Listen
Encoder目标:
去掉noises,提取出相关信息
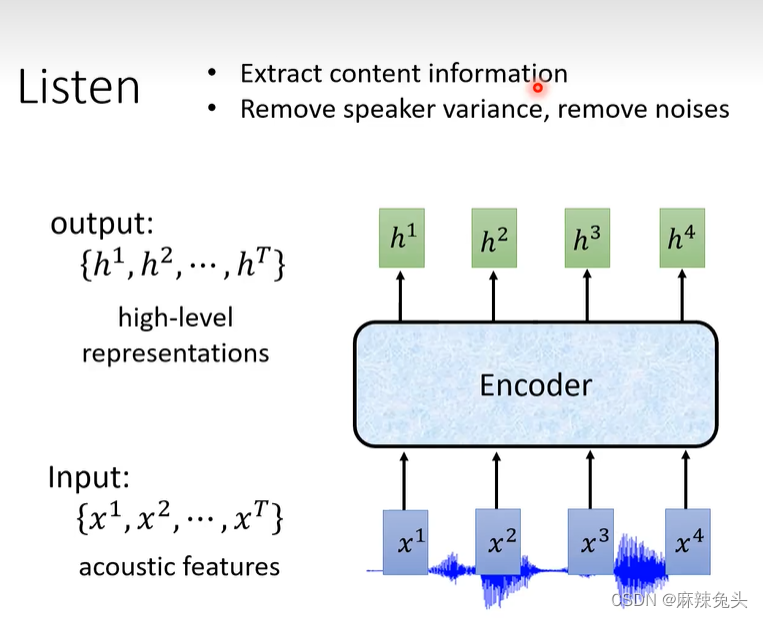
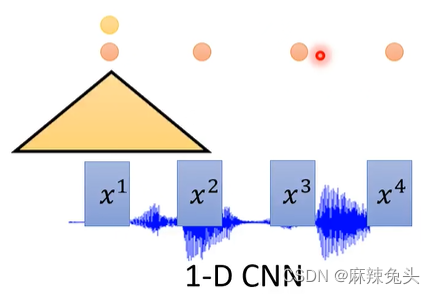
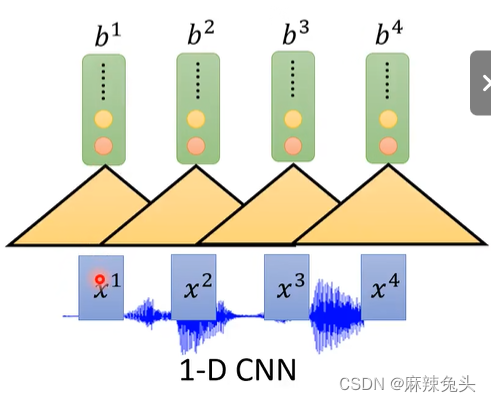
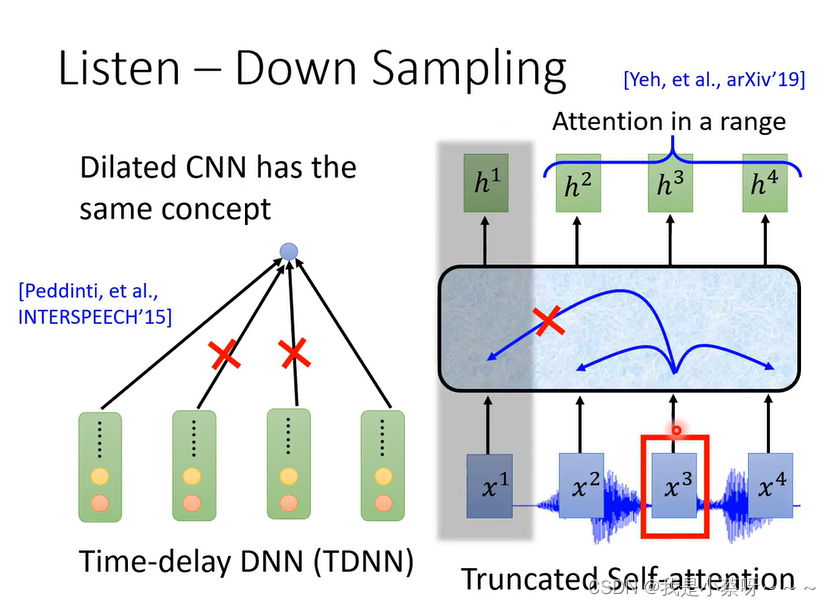
encoder有很多做法:
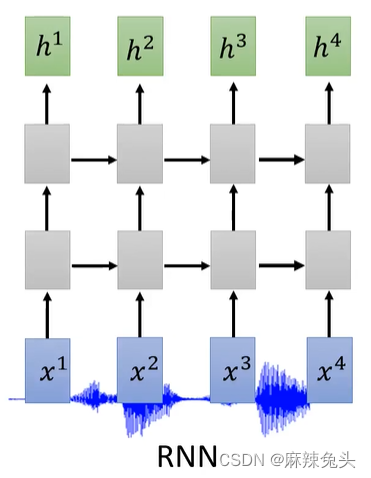
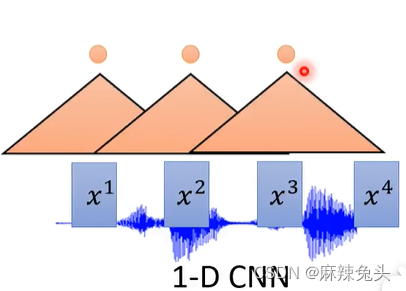
CNN见文章:CNN-卷积神经网络
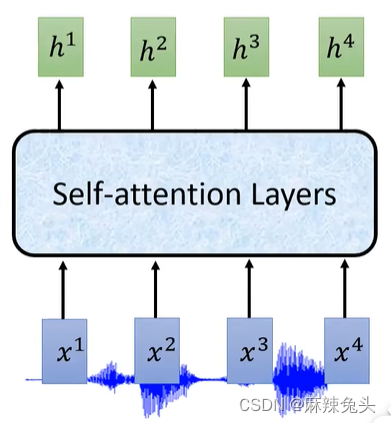
self-attention见文章self-attention
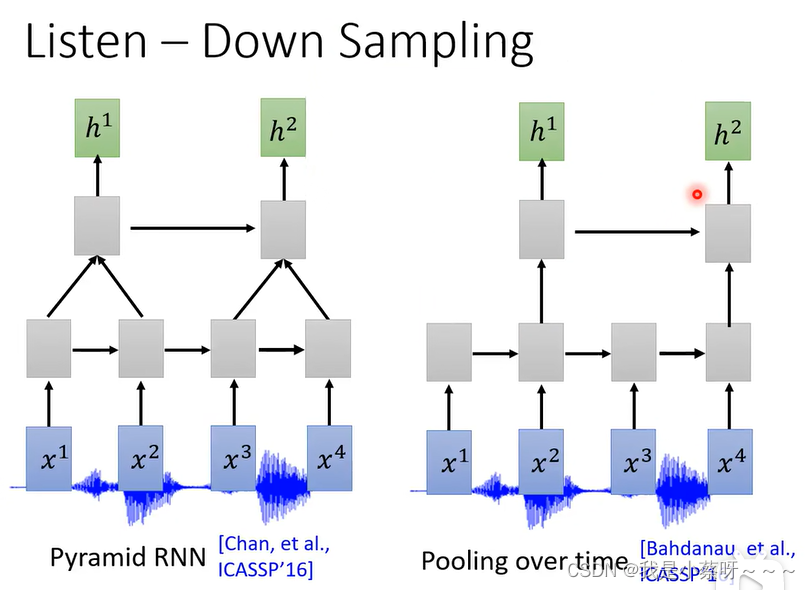
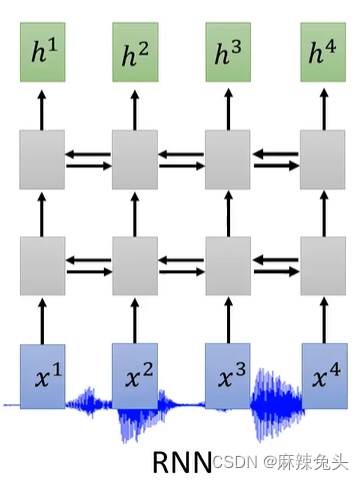
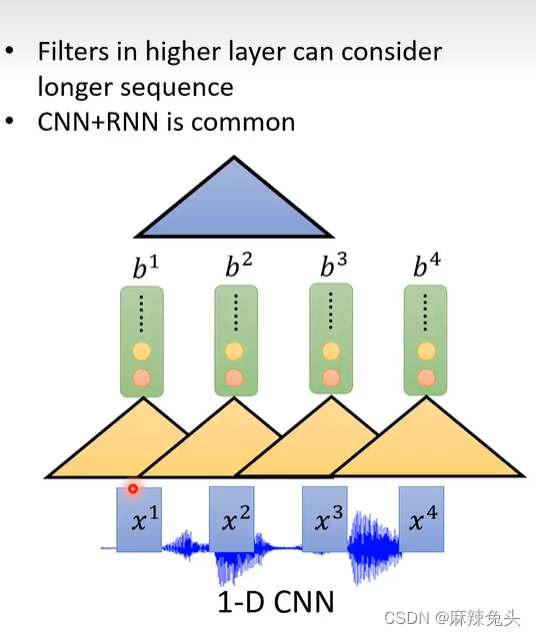
Pyramid RNN将两个结合,然后送到下一层。Pooling over time则是两个中取一个送到下一层。
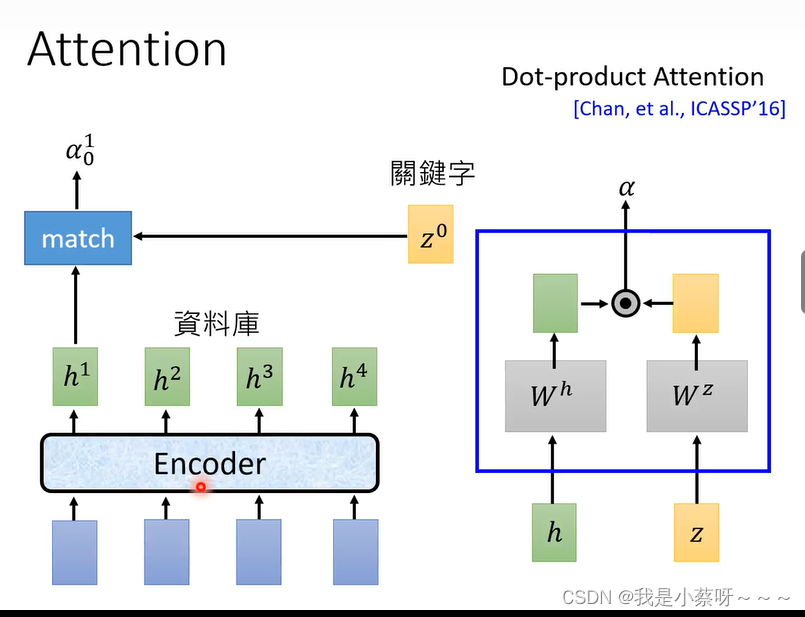
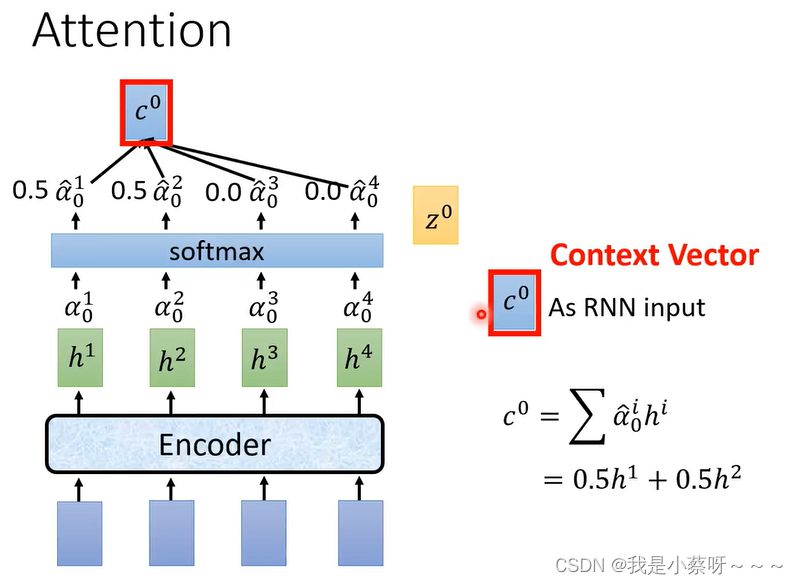
Attention
match这个function可以自己定义,常用的是dot-product attention,作用是计算h1和z0的相似度。
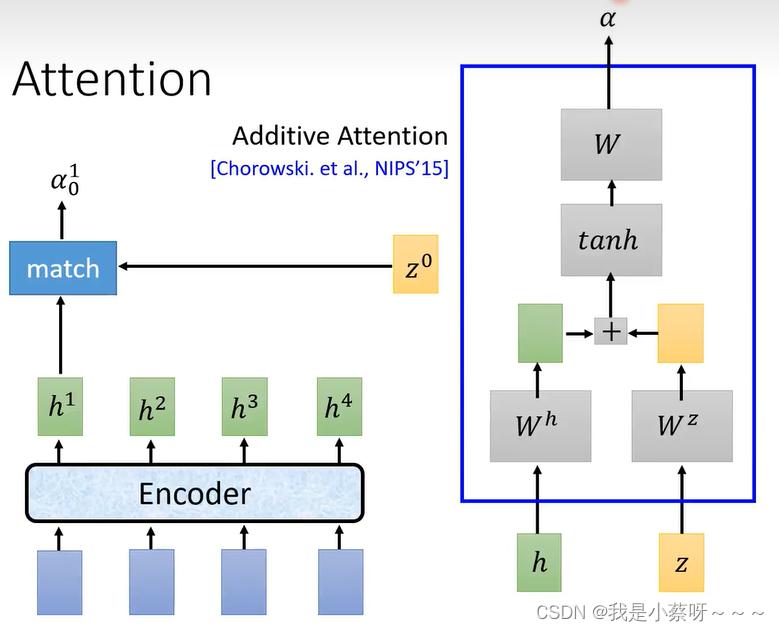
还有一种additive attention
c0(在文献上常常被成为Context Vector)会被当做decoder即RNN input
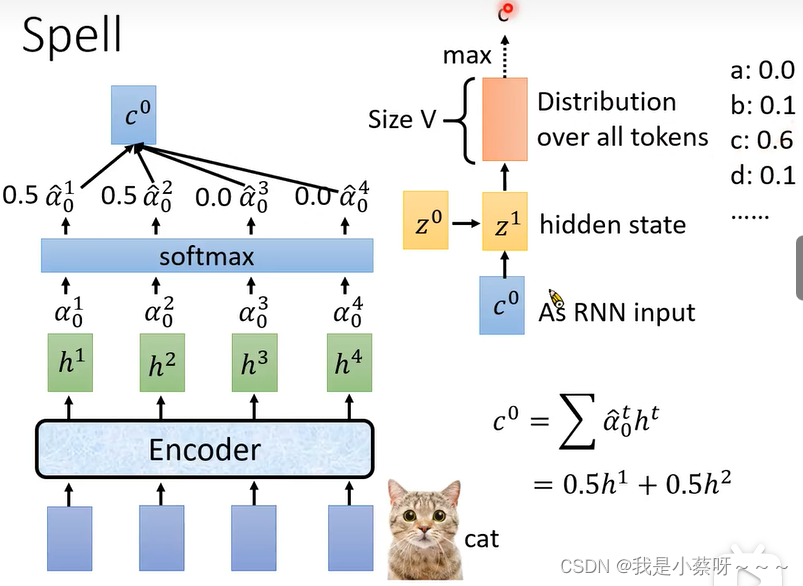
distribution(是通过softmax的)会给每一个token一个概率值

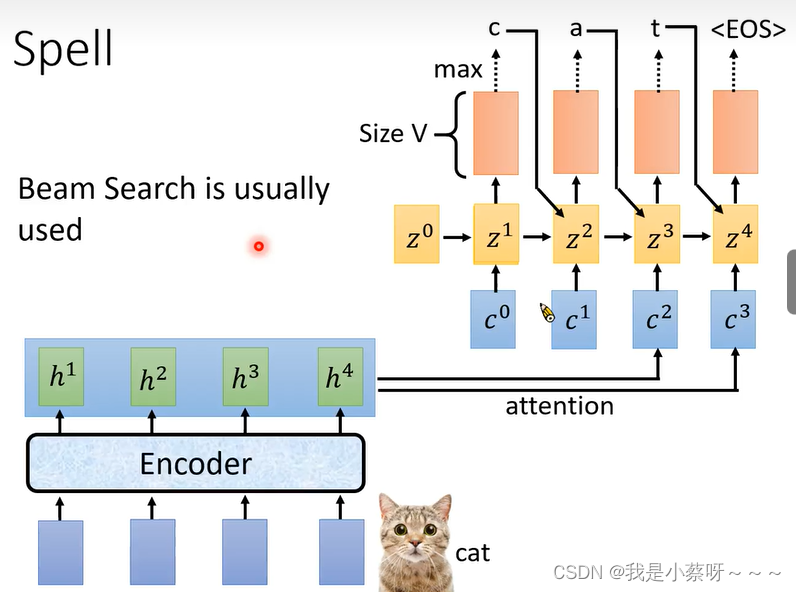
Spell
假设输入的一段声音讯号是cat,则model先后的需要输出c——a——t
先输出c
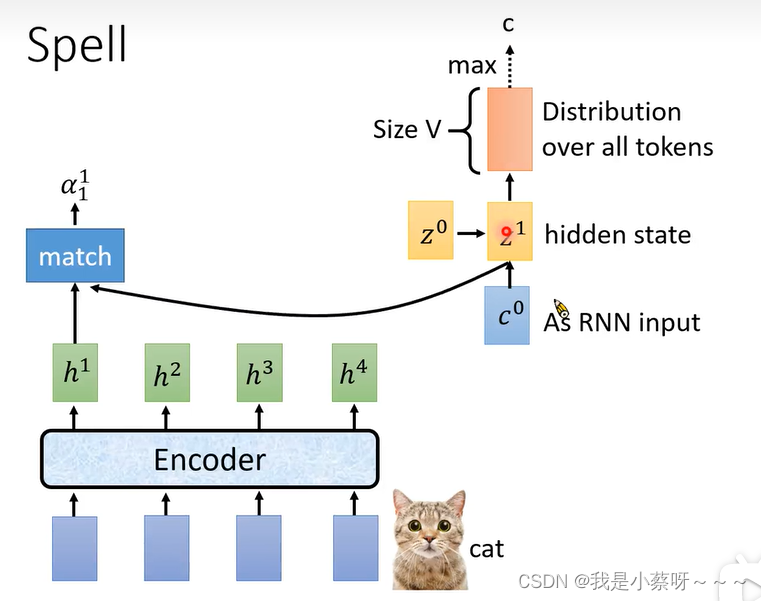
输出c后,用z1再次计算新的阿尔法的值
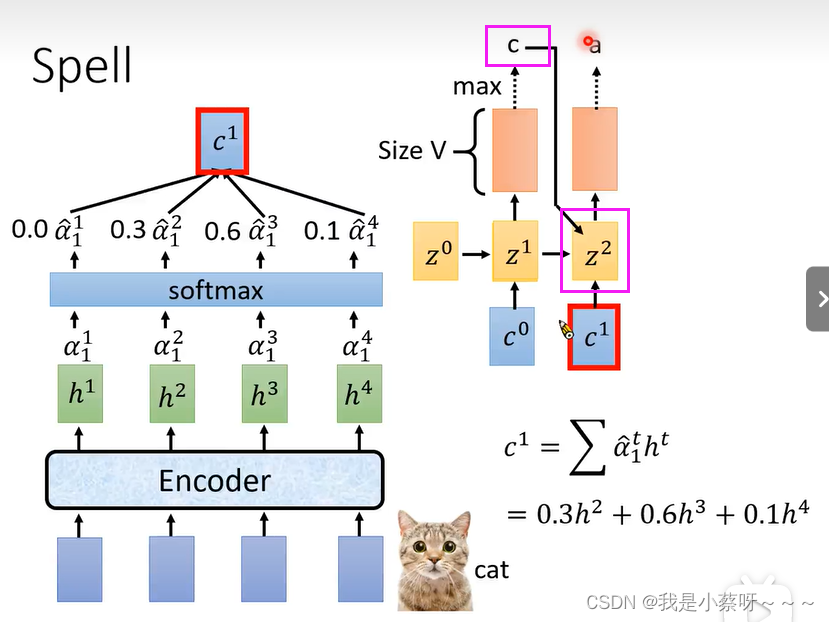
注意:a是由上一层的c和z2共同得到
EOS 代表辨识结束
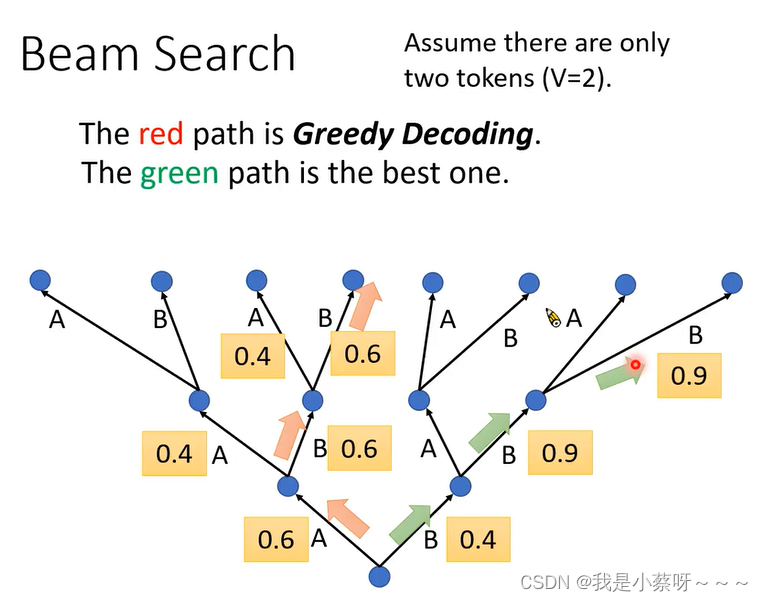
Beam Search
red path:每一次都选择概率最大的路径
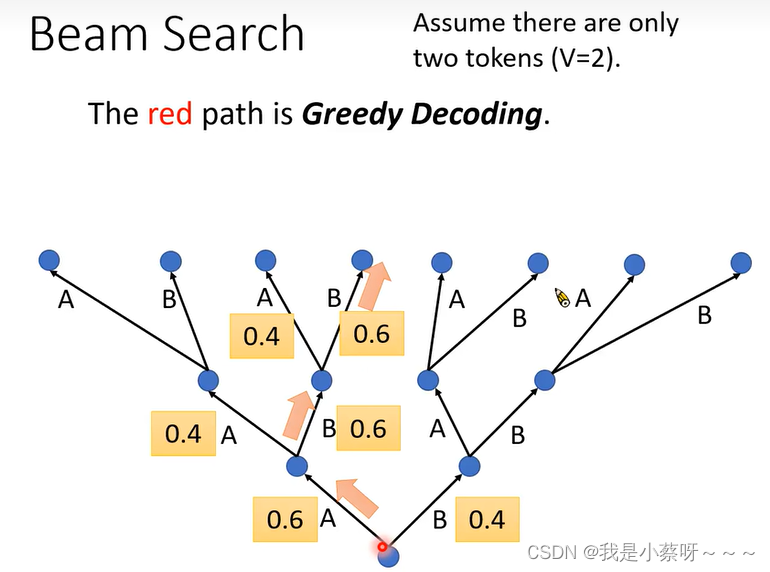
Greedy Decoding不见得能找到几率最大的那个
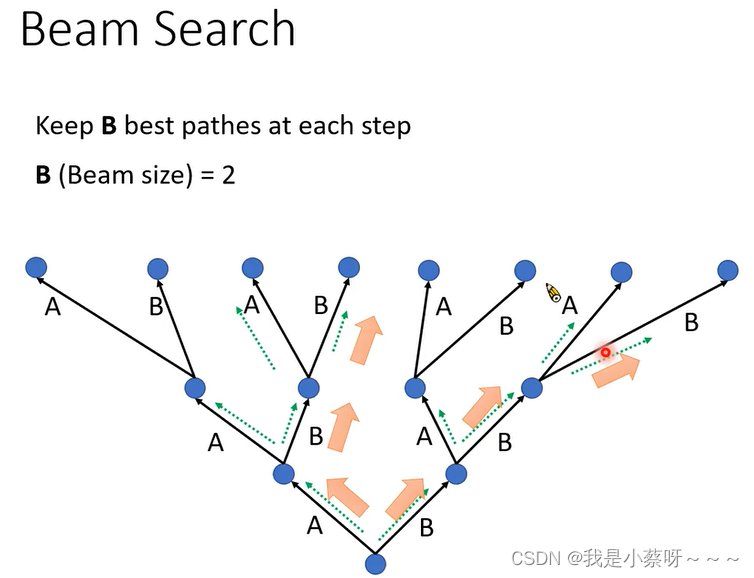
解决上述问题的方法:Beam Search,每次都保留B个最好的路径。Beam size的大小需要自己去考量的。
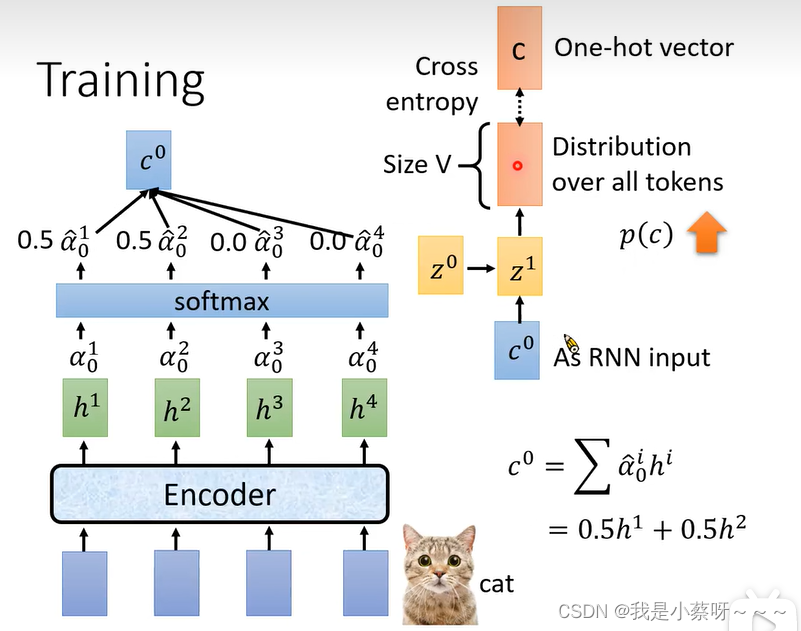
Training
输入是cat,我们希望Cross entropy越小越好,换言之p©越大越好
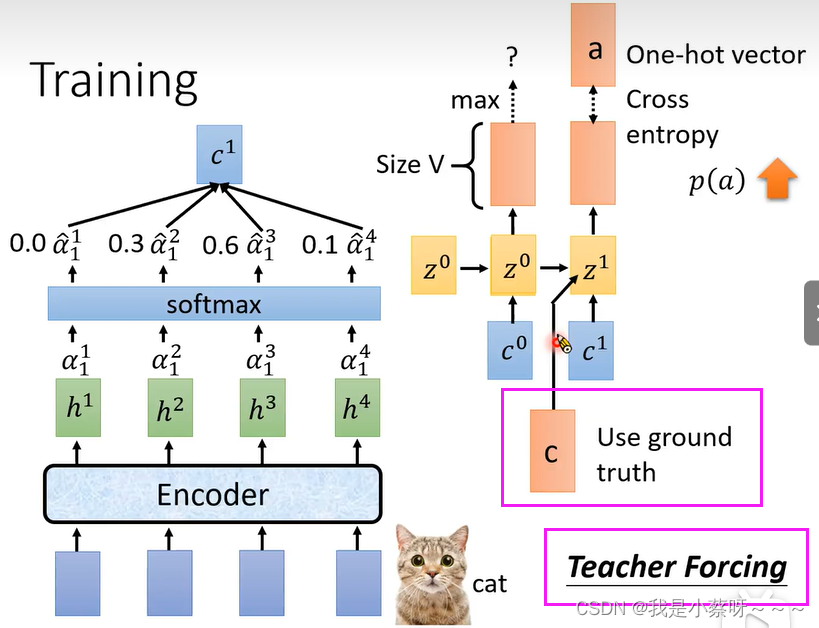
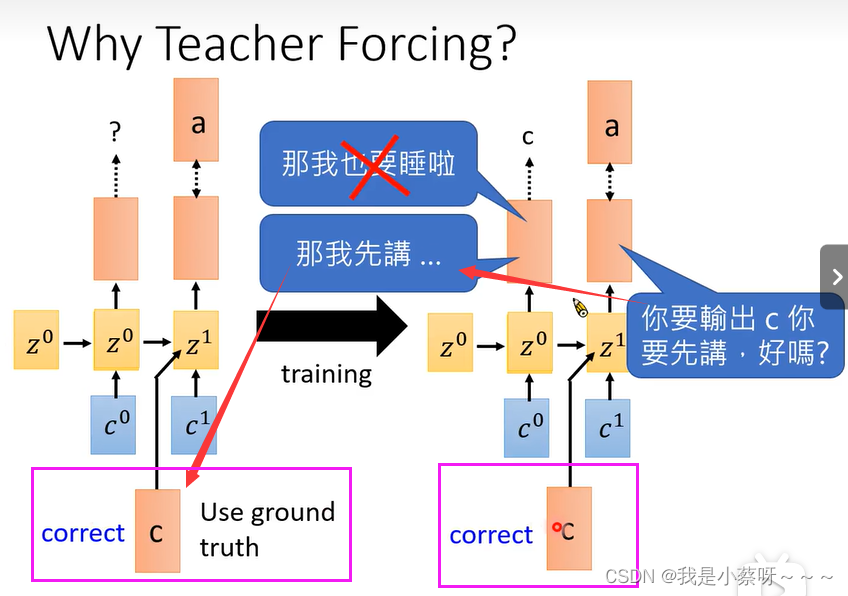
Why Teacher Forcing?
如果前面的输出是错误的
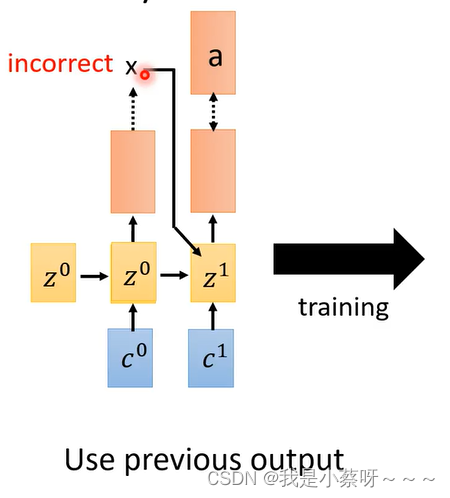
经过一连串的training后,Model变厉害了,得到了正确的输出
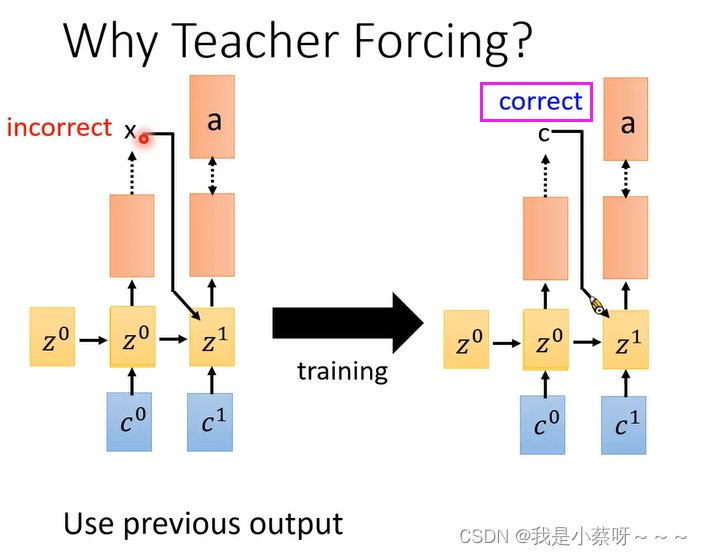
不管前面输出什么只专注训练c——>a这件事
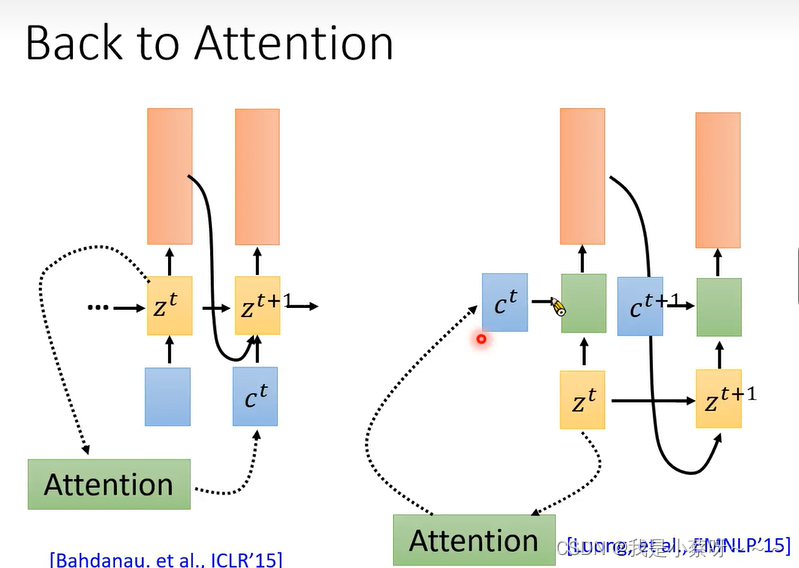
Back to Attention
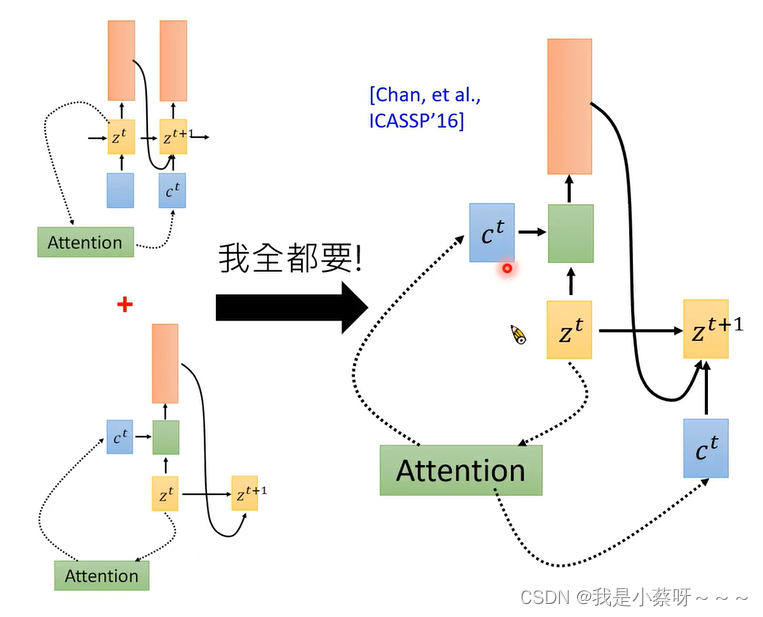
在语音识别上我们希望阿尔法是由左向右
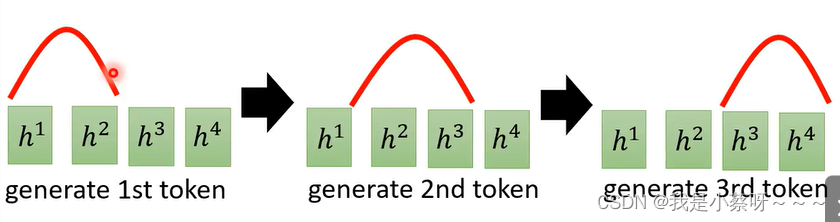
而不是阿尔法乱跳
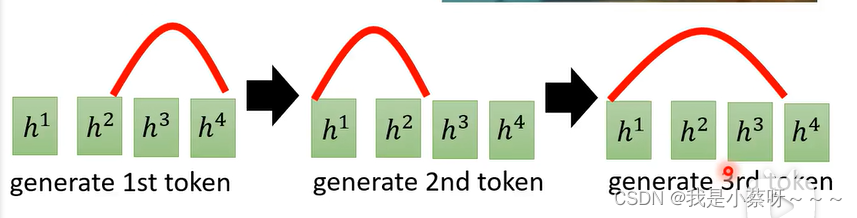
所以第一篇用LAS做语音辨识的作者加了一个机制:
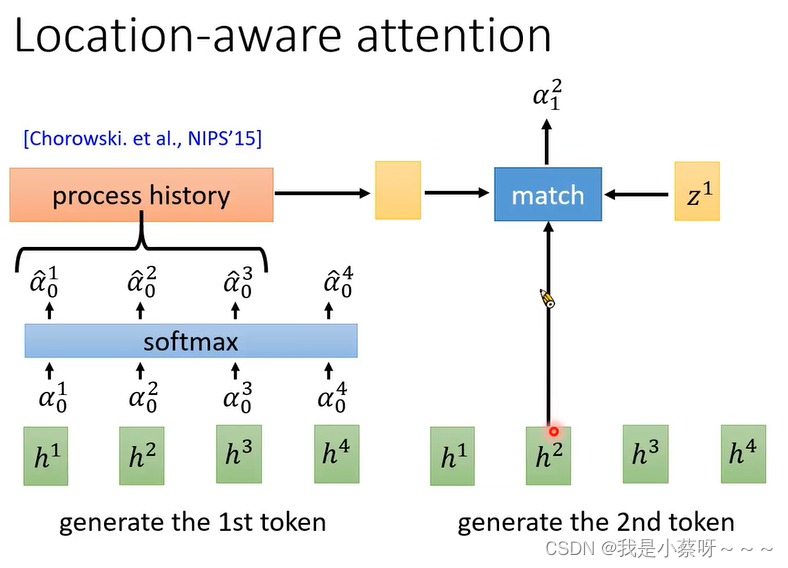
Location-aware attention


Limitation of LAS







![[附源码]SSM计算机毕业设计线上图书销售管理系统JAVA](https://img-blog.csdnimg.cn/a4bb736b839e4179bfc9ab142785bdd6.png)
