1 多流连接 connect
connect连接(DataStream,DataStream→ConnectedStreams)
connect翻译成中文意为连接,可以将两个数据类型一样也可以类型不一样DataStream连接成一个新的ConnectedStreams。需要注意的是,connect方法与union方法不同,虽然调用connect方法将两个流连接成一个新的ConnectedStreams,但是里面的两个流依然是相互独立的,这个方法最大的好处是可以让两个流共享State状态,状态相关的内容在后面章节讲解
DataStreamSource<String> ds1 = see.fromElements("a", "b", "c", "d");
DataStreamSource<Integer> ds2 = see.fromElements(1, 2, 3, 4, 5, 6);
ConnectedStreams<String, Integer> wordAndNumber = ds1.connect(ds2);对ConnectedStreams调用map方法时需要传入CoMapFunction函数:
该接口需要指定3个泛型:
- 第一个输入DataStream的数据类型
- 第二个输入DataStream的数据类型
- 返回结果的数据类型。
- 该接口需要重写两个方法:
- map1方法,是对第1个流进行map的处理逻辑。
- map2方法,是对2个流进行map的处理逻辑
这两个方法必须是相同的返回值类型。指定的输出的数据类型一致.
package com.blok;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
/**
* @Date: 22.11.8
* @Author: Hang.Nian.YY
* @qq: 598196583
* @Tips: 学大数据 ,到多易教育
* @Description:
*/
public class _9Base_API_ConnectFunction{
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8888);
StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
see.setParallelism(1);
DataStreamSource<String> ds1 = see.fromElements("a", "b", "c", "d");
DataStreamSource<Integer> ds2 = see.fromElements(1, 2, 3, 4, 5, 6);
ConnectedStreams<String, Integer> wordAndNumber = ds1.connect(ds2);
// 针对 ConnectedStreams 以后调用的方法 传入的是 CoXXXFunction函数
SingleOutputStreamOperator<String> connectMaped = wordAndNumber.map(new CoMapFunction<String, Integer, String>() {
// 针对字符串 处理的是左边流的数据
@Override
public String map1(String value) throws Exception {
return null;
}
// 针对字符串 处理的是右边流的数据
@Override
public String map2(Integer value) throws Exception {
return null;
}
});
see.execute("连接算子") ;
}
}
对ConnectedStreams调用flatMap方法,调用flatMap方法,传入的Function是CoFlatMapFunction;
这个接口要重写两个方法:
- flatMap1方法,是对第1个流进行flatMap的处理逻辑;
- flatMap2方法,是对2个流进行flatMap的处理逻辑;
这两个方法都必须返回是相同的类型。
/**
* @Date: 22.11.8
* @Author: Hang.Nian.YY
* @qq: 598196583
* @Tips: 学大数据 ,到多易教育
* @Description:
*/
public class _9Base_API_ConnectFunction02 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8888);
StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
see.setParallelism(1);
DataStreamSource<String> ds1 = see.fromElements("a b c d", "e f g h", "j k l", "o p l a");
DataStreamSource<String> ds2 = see.fromElements("1 2 3 4 5" , "6 7 8 9 10");
ConnectedStreams<String, String> connectedStreams = ds1.connect(ds2);
connectedStreams.flatMap(new CoFlatMapFunction<String, String, String>() {
@Override
public void flatMap1(String value, Collector<String> out) throws Exception {
String[] split = value.split("\\s+");
for (String word : split) {
out.collect(word);
}
}
@Override
public void flatMap2(String value, Collector<String> out) throws Exception {
String[] split = value.split("\\s+");
for (String word : split) {
out.collect(word);
}
}
}) ;
see.execute("连接算子") ;
}
}
2 多流合并
该方法可以将两个或者多个数据类型一致的DataStream合并成一个DataStream。DataStream<T> union(DataStream<T>… streams)可以看出DataStream的union方法的参数为可变参数,即可以合并两个或多个数据类型一致的DataStream。
下面的例子是使用fromElements生成两个DataStream,一个是基数的,一个是偶数的,然后将两个DataStream合并成一个DataStream。
/**
* @Date: 22.11.8
* @Author: Hang.Nian.YY
* @qq: 598196583
* @Tips: 学大数据 ,到多易教育
* @Description:
*/
public class _10Base_API_Union {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8888);
StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
see.setParallelism(1);
DataStreamSource<Integer> odd = see.fromElements(1, 3, 5, 7, 9);
DataStreamSource<Integer> even = see.fromElements(2, 4, 6, 8, 10);
// 将两个流合并在一起
DataStream<Integer> union = odd.union(even);
union.print("所有的数据: ");
see.execute("合并union算子");
}
}
3 分流操作 - 测流输出
以下function函数,支持将特定数据输出到侧流中:凡是process的函数都有测流输出
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
/**
* @Date: 22.11.8
* @Author: Hang.Nian.YY
* @qq: 598196583
* @Tips: 学大数据 ,到多易教育
* @Description:
*/
public class _11Base_API_SideOut {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8888);
StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
see.setParallelism(1);
DataStreamSource<YY2> ds = see.fromElements(
new YY2(1, "DY", "NM_BT", 100),
new YY2(2, "XY", "NM_BT", 100),
new YY2(3, "HH", "SD_HZ", 10),
new YY2(4, "XH", "SD_HZ", 12)
);
final OutputTag<YY2> sideOut = new OutputTag<YY2>("not good"){};
// 使用测流 将不及格的那家伙和优秀的分开
// process方法支持测流输出
SingleOutputStreamOperator<YY2> processed = ds.process(new ProcessFunction<YY2, YY2>() {
@Override
public void processElement(YY2 value, ProcessFunction<YY2, YY2>.Context ctx, Collector<YY2> out) throws Exception {
if (value.getScore() < 60) { // 将指定规则的不及格的用户 输出到测流
ctx.output(sideOut, value);
} else { // 将及格的用户输出到主流中 [你们本来就不是一个世界的人, 就不应该有交集]
out.collect(value);
}
}
});
DataStream<YY2> sideOutput = processed.getSideOutput(sideOut);
sideOutput.print("测流输出:-->不优秀的你:") ;
processed.print("主流数据:-->优秀的你:") ;
see.execute("连接算子");
}
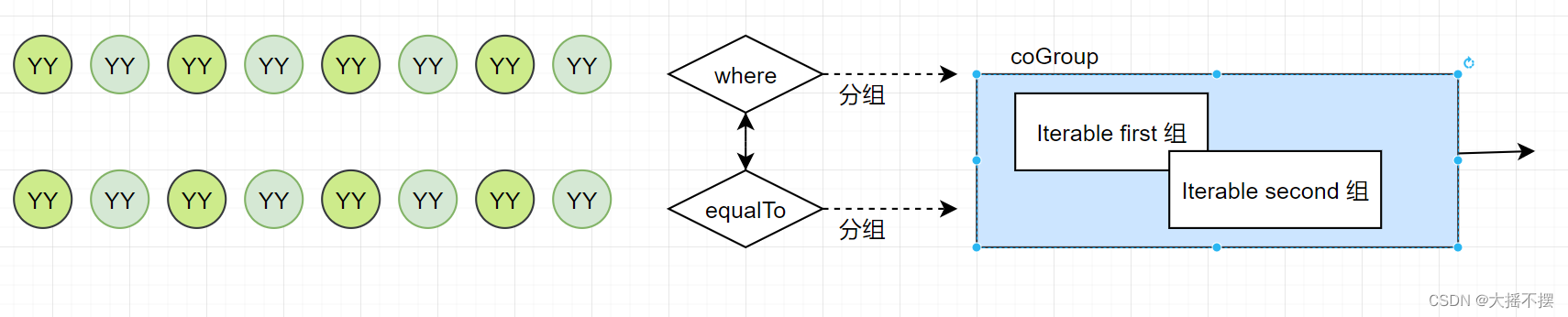
}4 协同分组
两个流按照指定的属性分别分组 ,将分组后的数据放在一起处理
package com.blok;
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* @Date: 22.11.8
* @Author: Hang.Nian.YY
* @qq: 598196583
* @Tips: 学大数据 ,到多易教育
* @Description: coGroup 协同分组
* 将两个流按照特定的规则进行分组 , 两个流相同的组数据关联
*/
public class _12Base_API_Cogroup {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8888);
StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
see.setParallelism(1);
/**
* 1 加载原始数据
*/
// 输入的数据格式 id,name
DataStreamSource<String> ds1 = see.socketTextStream("linux01", 8899);
// 输入的数据格式是 id,event,city
DataStreamSource<String> ds2 = see.socketTextStream("linux01", 9988);
/**
* 2 处理加载的数据成元组
*/
//id,name
SingleOutputStreamOperator<Tuple2<String, String>> users = ds1.map(line -> {
String[] arr = line.split(",");
return Tuple2.of(arr[0], arr[1]);
}).returns(new TypeHint<Tuple2<String, String>>() {
});
// id,event,city
SingleOutputStreamOperator<Tuple3<String, String, String>> events = ds2.map(line -> {
String[] arr = line.split(",");
return Tuple3.of(arr[0], arr[1], arr[2]);
}).returns(new TypeHint<Tuple3<String, String, String>>() {
});
//利用coGroup算子,来实现两个流的数据按id相等进行窗口关联(包含inner ,left, right, outer)
DataStream<String> res = users.coGroup(events)
.where(tp -> tp.f0)
.equalTo(tp -> tp.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
//只要在窗口函数之后才有apply算子
.apply(new CoGroupFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>() {
@Override
public void coGroup(Iterable<Tuple2<String, String>> users, Iterable<Tuple3<String, String, String>> events, Collector<String> out) throws Exception {
/**
* 实现 left join
*/
for (Tuple2<String, String> user : users) {
boolean flag = false;
for (Tuple3<String, String, String> event : events) {
out.collect(user.f0 + "," + user.f1 + "," + event.f0 + "," + event.f1 + "," + event.f2);
flag = true;
}
//说明没有事件
if (!flag) {
out.collect(user.f0 + "," + user.f1 + ",null,null,null");
}
}
}
});
res.print("left_join") ;
see.execute() ;
}
}
5 join算子
用于关联两个流(类似于sql中join) , 需要指定join的条件;需要在窗口中进行关联后的逻辑计算;
package com.blok;
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* @Date: 22.11.8
* @Author: Hang.Nian.YY
* @qq: 598196583
* @Tips: 学大数据 ,到多易教育
* @Description: join 两个流进行关联
*/
public class _13Base_API_Join {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8888);
StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
see.setParallelism(1);
/**
* 1 加载原始数据
*/
// 输入的数据格式 id,name
DataStreamSource<String> ds1 = see.socketTextStream("linux01", 8899);
// 输入的数据格式是 id,event,city
DataStreamSource<String> ds2 = see.socketTextStream("linux01", 9988);
/**
* 2 处理加载的数据成元组
*/
//id,name
SingleOutputStreamOperator<Tuple2<String, String>> users = ds1.map(line -> {
String[] arr = line.split(",");
return Tuple2.of(arr[0], arr[1]);
}).returns(new TypeHint<Tuple2<String, String>>() {
});
// id,event,city
SingleOutputStreamOperator<Tuple3<String, String, String>> events = ds2.map(line -> {
String[] arr = line.split(",");
return Tuple3.of(arr[0], arr[1], arr[2]);
}).returns(new TypeHint<Tuple3<String, String, String>>() {
});
/**
* 使用join算子将两个数据流关联在一起
*/
DataStream<String> res = users.join(events)
.where(tp -> tp.f0)
.equalTo(tp -> tp.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(20))) // 划分处理数据的窗口
.apply(new JoinFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>() {
@Override
public String join(Tuple2<String, String> t1, Tuple3<String, String, String> t2) throws Exception {
return t1.f0 + "," + t1.f1 + "," + t2.f0 + "," + t2.f1 + "," + t2.f2;
}
});
res.print("join-res: ") ;
see.execute() ;
}
}
只有同一个窗口中的数据才会触发相对应的数据关联计算
代码中设置不同的窗口类型 ,触发不同的计算时机
// 滚动窗口
// .window(TumblingProcessingTimeWindows.of(Time.seconds(20))) // 划分处理数据的窗口
// .window(TumblingProcessingTimeWindows.of(Time.seconds(30) , Time.seconds(10)))
// 滑动窗口
.window(SlidingProcessingTimeWindows.of(Time.seconds(30), Time.seconds(10)))
//会话窗口
// .window(ProcessingTimeSessionWindows.withGap(Time.seconds(30)))- tumbling window 滚动
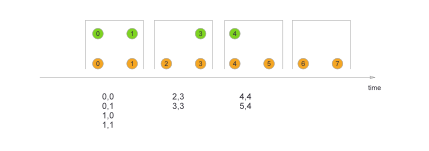
DataStream<String> res = users.join(events)
.where(tp -> tp.f0)
.equalTo(tp -> tp.f0)
// 滚动窗口
// .window(TumblingProcessingTimeWindows.of(Time.seconds(20))) // 划分处理数据的窗口
.apply(new JoinFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>() {
@Override
public String join(Tuple2<String, String> t1, Tuple3<String, String, String> t2) throws Exception {
return t1.f0 + "," + t1.f1 + "," + t2.f0 + "," + t2.f1 + "," + t2.f2;
}
});- sliding window滑动
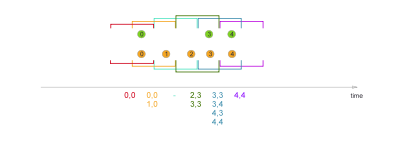
DataStream<String> res = users.join(events)
.where(tp -> tp.f0)
.equalTo(tp -> tp.f0)
// 滑动窗口
.window(SlidingProcessingTimeWindows.of(Time.seconds(30), Time.seconds(10)))
.apply(new JoinFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>() {
@Override
public String join(Tuple2<String, String> t1, Tuple3<String, String, String> t2) throws Exception {
return t1.f0 + "," + t1.f1 + "," + t2.f0 + "," + t2.f1 + "," + t2.f2;
}
});- session window 会话
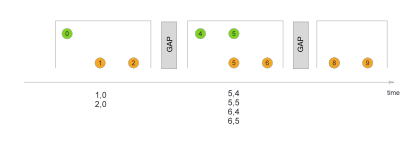
DataStream<String> res = users.join(events)
.where(tp -> tp.f0)
.equalTo(tp -> tp.f0)
//会话窗口
// .window(ProcessingTimeSessionWindows.withGap(Time.seconds(30)))
.apply(new JoinFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>() {
@Override
public String join(Tuple2<String, String> t1, Tuple3<String, String, String> t2) throws Exception {
return t1.f0 + "," + t1.f1 + "," + t2.f0 + "," + t2.f1 + "," + t2.f2;
}
});6 广播流
Broadcast State 是 Flink 1.5 引入的新特性。
在开发过程中,如果遇到需要下发/广播配置、规则等低吞吐事件流到下游所有task 时,就可以使用 Broadcast State 特性。下游的 task 接收这些配置、规则并保存为 BroadcastState, 将这些配置应用到另一个数据流的计算中 。
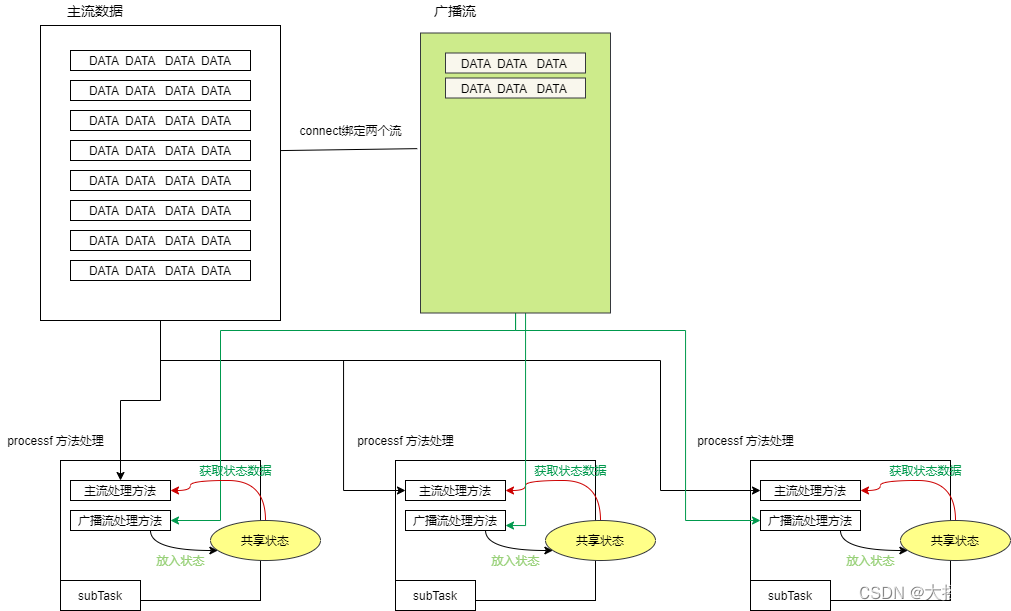
API 介绍 , 核心要点
- 将需要广播出去的流,调用broadcast方法进行广播转换,得到广播流BroadCastStream
- 然后在主流上调用connect算子,来连接广播流(以实现广播状态的共享处理)
- 在连接流上调用process算子,就会在同一个ProcessFunciton中提供两个方法分别对两个流进行处理,并在这个ProcessFunction内实现“广播状态”的共享
package com.blok;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import javax.swing.*;
/**
* @Date: 22.11.8
* @Author: Hang.Nian.YY
* @qq: 598196583
* @Tips: 学大数据 ,到多易教育
* @Description: join 两个流进行关联
*/
public class _14Base_API_BroadCast {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8888);
StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
see.setParallelism(1);
/**
* 1 加载原始数据
*/
// 输入的数据格式 id,name
DataStreamSource<String> ds1 = see.socketTextStream("linux01", 8899);
// 输入的数据格式是 id,event,city
DataStreamSource<String> ds2 = see.socketTextStream("linux01", 9988);
/**
* 2 处理加载的数据成元组
*/
//id,event
SingleOutputStreamOperator<Tuple2<String, String>> events = ds1.map(line -> {
String[] arr = line.split(",");
return Tuple2.of(arr[0], arr[1]);
}).returns(new TypeHint<Tuple2<String, String>>() {
});
// id,name,city
SingleOutputStreamOperator<Tuple3<String, String, String>> users = ds2.map(line -> {
String[] arr = line.split(",");
return Tuple3.of(arr[0], arr[1], arr[2]);
}).returns(new TypeHint<Tuple3<String, String, String>>() {
});
/**
* 示例代码 :
* 流1 用户行为事件 , 一个用户可能有很多不同的行为事件 出现的时间 出现的次数不确定
* 流2 用户信息 同一个用户信息数据只会来一次 ,但是来的时间不确定
*
* 将用户信息数据 封装成广播流
*/
//将用户信息数据 封装成广播流
MapStateDescriptor<String, Tuple2<String, String>> userInfo = new MapStateDescriptor<>("userInfo", TypeInformation.of(String.class), TypeInformation.of(new TypeHint<Tuple2<String, String>>() {}));
BroadcastStream<Tuple3<String, String, String>> broadcast = users.broadcast(userInfo);
// 要想使用广播流 , 主流要和广播流进行connect
BroadcastConnectedStream<Tuple2<String, String>, Tuple3<String, String, String>> connected = events.connect(broadcast);
// 使用 process方法 处理关联了广播流的连接流数据
connected.process(new BroadcastProcessFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>() {
/**
* 处理主流中的数据
* @throws Exception
*/
@Override
public void processElement(Tuple2<String, String> value, BroadcastProcessFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>.ReadOnlyContext ctx, Collector<String> out) throws Exception {
// 从上下文对象中 获取广播状态 这个广播状态是只读的
ReadOnlyBroadcastState<String, Tuple2<String, String>> bc = ctx.getBroadcastState(userInfo);
if (bc!=null){
Tuple2<String, String> user = bc.get(value.f0);
if(user!=null){
out.collect(value.f0+","+user.f0+","+user.f1+","+value.f1);
}else{
out.collect(value.f0+",null ,null"+value.f1);
}
}else{ // 广播变量中没有 用户信息
out.collect(value.f0+",null ,null"+value.f1);
}
}
/**
* 操作广播数据 ,将广播数据存储在共享状态中
* @throws Exception
*/
@Override
public void processBroadcastElement(Tuple3<String, String, String> value, BroadcastProcessFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>.Context ctx, Collector<String> out) throws Exception {
// 从上下文对象中 获取广播状态对象 (可以读写的广播流状态)
BroadcastState<String, Tuple2<String, String>> bc = ctx.getBroadcastState(userInfo);
// 将每条广播数据 存储在广播状态中
bc.put(value.f0, Tuple2.of(value.f1, value.f2));
}
});
}
}