文章目录
- Hadoop高手之路3-Hadoop集群搭建
- 一、集群的规划
- 二、再准备两台虚拟机作为服务器
- 1. 根据hadoop001克隆出hadoop002和hadoop003
- 2. 配置hadoop002和hadoop003
- 1) 启动hadoop002虚拟机并登录
- 2) 配置ip地址
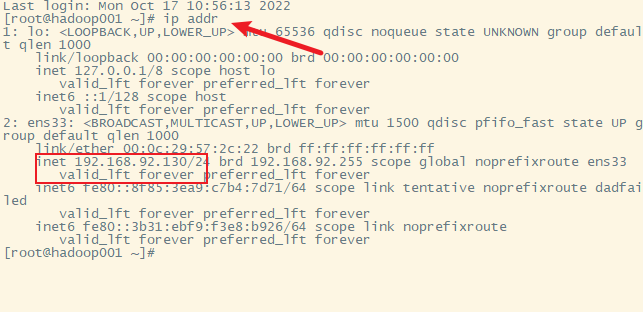
- 3) 重启网络服务器,查看ip
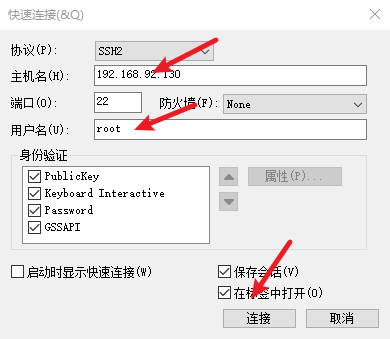
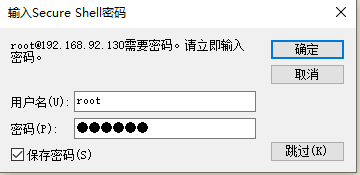
- 4) 远程连接hadoop002
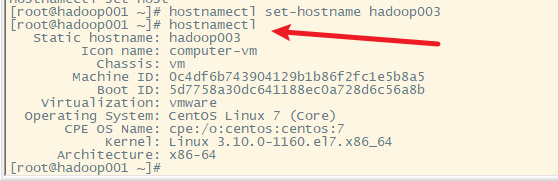
- 5) 修改主机名为hadoop002
- 6) 用同样的方法操作一遍hadoop003
- 三、建立主机名和ip地址的映射关系
- 1. 修改hadoop001的hosts文件
- 2. 复制hadoop001的/etc/hosts到hadoop002和hadoop003
- 3. 测试各主机之间的连通性
- 4. 本地windows主机和各虚拟机的映射关系
- 5. 测试各虚拟机跟外网的连通性
- 四、各主机之间的SSH免密登录
- 1. 查看hadoop的密钥存放文件夹
- 2. 生成密钥
- 3. 复制生成的密钥文件到其他主机(包括hadoop001自己)
- 1) hadoop001免密登录hadoop001
- 2)hadoop001免密登录hadoop002
- 3)hadoop001免密登录hadoop003
- 4) hadoop002免密登录hadoop001
- 5) hadoop002免密登录hadoop002
- 6) hadoop002免密登录hadoop003
- 7) hadoop003免密登录hadoop001
- 8) hadoop003免密登录hadoop002
- 9) hadoop003免密登录hadoop003
- 五、安装上传下载的小工具
- 六、JDK的安装
- 1. 下载JDK
- 2. 上传到服务器
- 3.解压
- 4.配置环境变量
- 5.使环境变量起作用
- 6. 分发hadoop001上的jdk到hadoop002和hadoop003上
- 7. 分发hadoop001的/etc/profile到hadoop002和hadoop003上
- 8. 使hadoop002和hadoop003的环境变量起作用
- 七、安装notepad++的插件
- 八、Hadoop的安装
- 1. hadoop集群的安装模式
- 1) 独立模式standalone
- 2) 伪分布模式 pseudodistributed
- 3) 完全分布模式 fulldistributed
- 2. 下载hadoop
- 3. 上传到服务器
- 4. 也可以通过centos的wget命令直接下载到服务器
- 5.解压
- 6. 配置环境变量
- 7. 使配置起作用
- 8. 测试
- 9. hadoop的命令说明
- 九、hadoop的独立模式启动
- 1. 启动集群命令sbin目录下,start-all.sh
- 2. 配置hadoop
- 3. 配置hadoop的环境变量
- 4. 在启动hadoop独立模式之前用jps查看java进程
- 5. 再次启动hadoop独立模式
- 十、Hadoop集群配置
- 1. hadoop的配置文件
- 2. 修改hadoop-env.sh文件
- 3. 修改core-site.xml文件
- 4. 修改hdfs-site.xml文件
- 5. 修改mapred-site.xml文件
- 6. 修改yarn-site.xml文件
- 7. 修改workers文件
- 8. 分发hadoop目录到hadoop002和hadoop003上
- 9. 分发环境变量配置文件到hadoop002和hadoop003上
- 10. 使hadoop002和hadoop003上的环境变量起作用
- 11. 测试hadoop是否安装正确
- 十一、hadoop集群的文件系统格式化
- 十二、启动和关闭hadoop集群
- 1. 关闭防火墙
- 2. jps查看java进程
- 3. 启动hadoop集群
- 1) 启动hfds
- 2)启动yarn
- 3) 一键启动
- 十三、关闭集群
- 1. 关闭yarn集群
- 2. 关闭hdfs
- 3. 一键关闭
- 十四、Hadoop集群测试
- 1. 通过WebUI(图形界面)查看Hadoop的运行状态
- 1) 查看hdfs的webui
- 2) 查看yarn的web UI
- 2. hdfs的shell命令的使用
- 3. mapreduce的体验测试
- 1) 首先创建多个包含单词的文件
- 2) 在hdfs上创建一个input文件夹,并把上述两个文本文件上传到该文件夹
- 3) 执行单词计数的mapreduce程序
- 4) 解决配置错误,修改mapred-site.xml配置文件
- 5) 关闭hadoop,再重启
- 6) 重新执行单词计数的mapreduce程序
- 7) 查看结果
- 4. mapreduce的计数圆周率的测试
- 5.问题解决

Hadoop高手之路3-Hadoop集群搭建
一、集群的规划
需要三台服务器(虚拟机)
| 服务器 | hadoop001 | hadoop002 | hadoop003 |
|---|---|---|---|
| NameNode | √ | ||
| SecondaryNameNode | √ | ||
| DataNode | √ | √ | √ |
| ResourceManager | √ | ||
| NodeManager | √ | √ | √ |
二、再准备两台虚拟机作为服务器
1. 根据hadoop001克隆出hadoop002和hadoop003
选择完整克隆
2. 配置hadoop002和hadoop003
1) 启动hadoop002虚拟机并登录
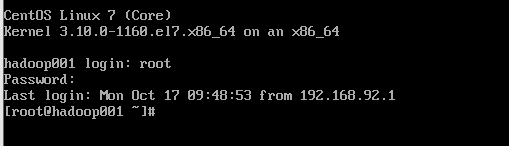
2) 配置ip地址
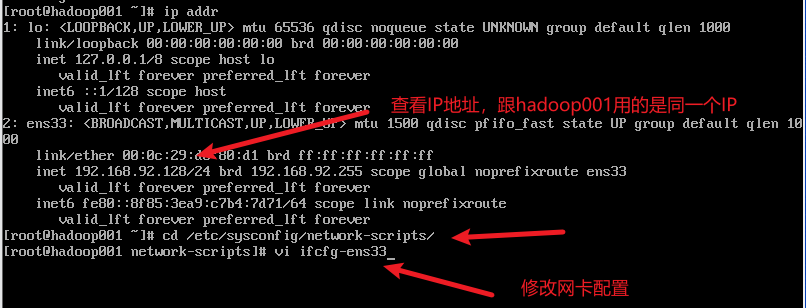
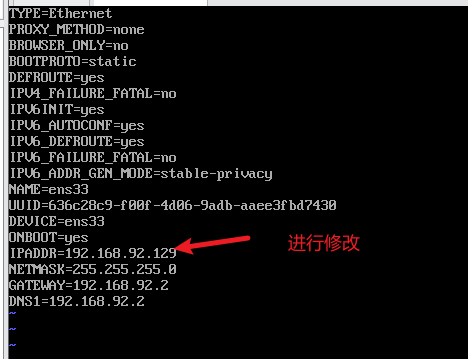
3) 重启网络服务器,查看ip
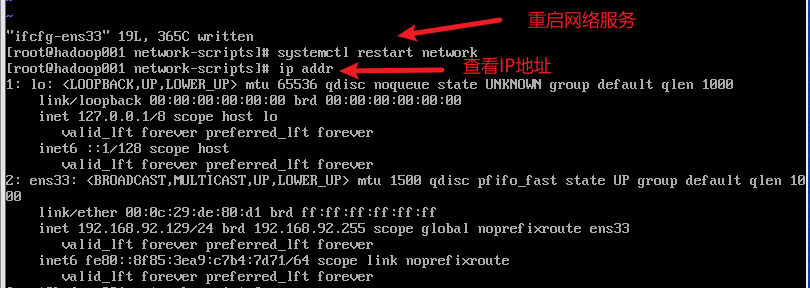
4) 远程连接hadoop002
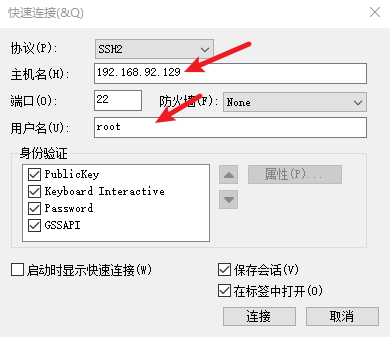
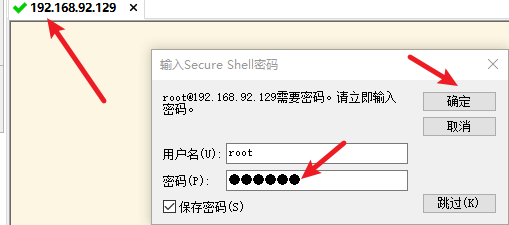
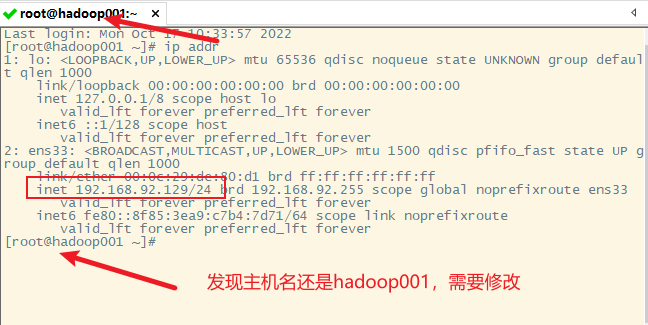
5) 修改主机名为hadoop002
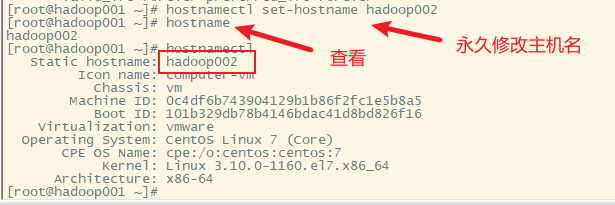

再登录
6) 用同样的方法操作一遍hadoop003
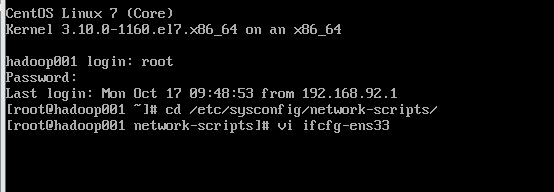
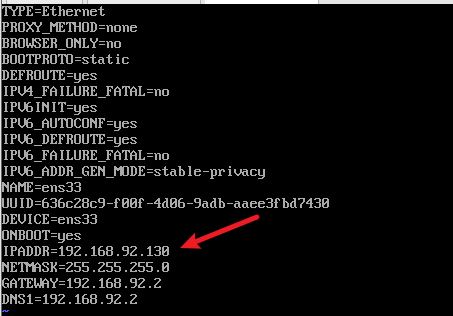
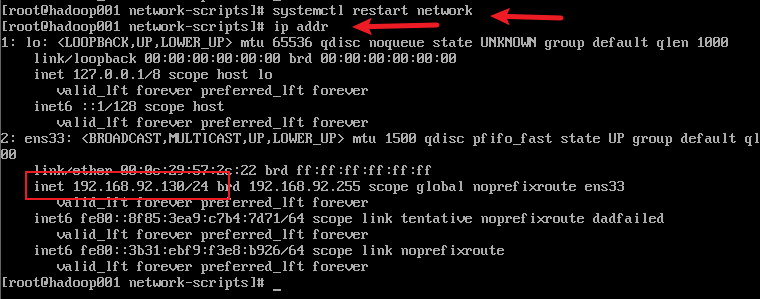
三、建立主机名和ip地址的映射关系
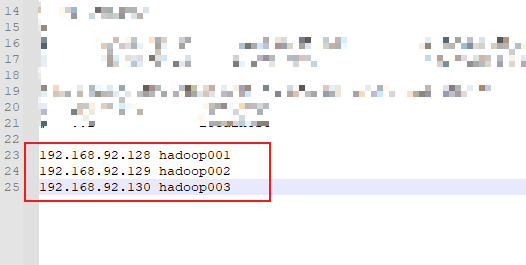
1. 修改hadoop001的hosts文件

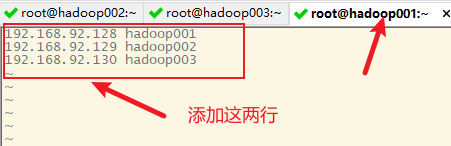
保存退出,并测试连通性
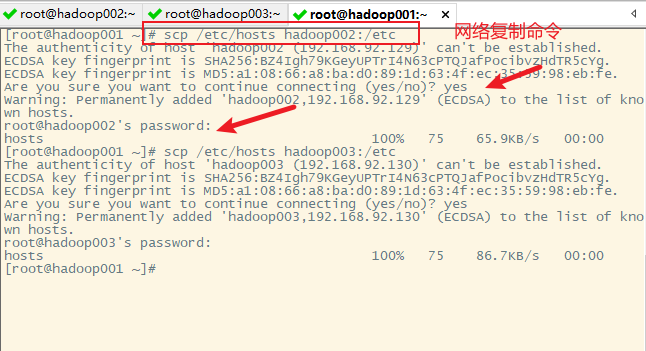
2. 复制hadoop001的/etc/hosts到hadoop002和hadoop003
主机之间的文件复制使用命令scp
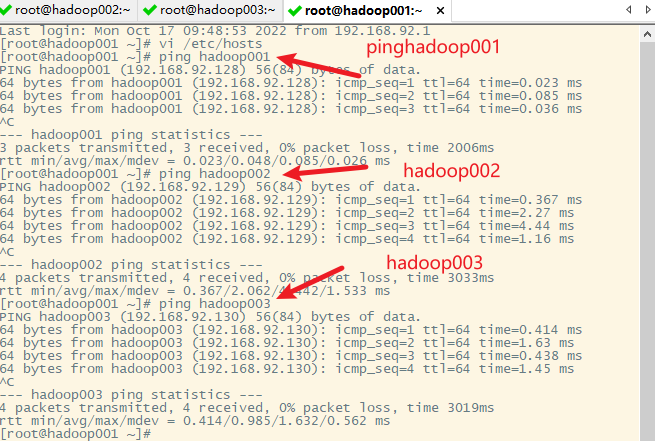
3. 测试各主机之间的连通性
在hadoop001上已做
在hadoop002上
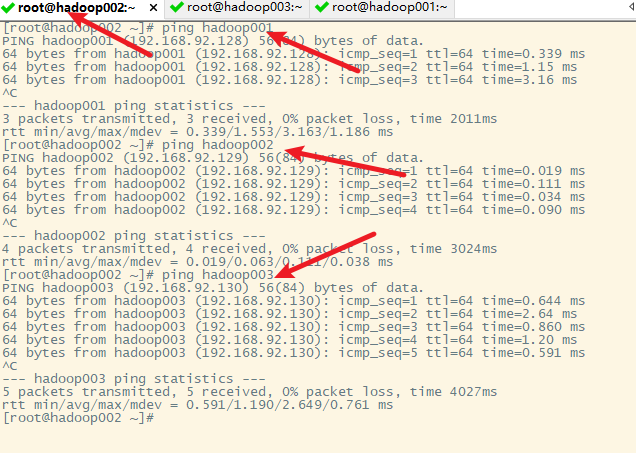
在hadoop003上
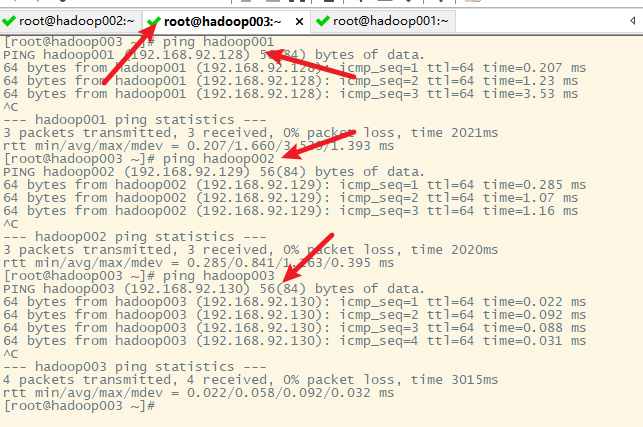
4. 本地windows主机和各虚拟机的映射关系
测试连通性
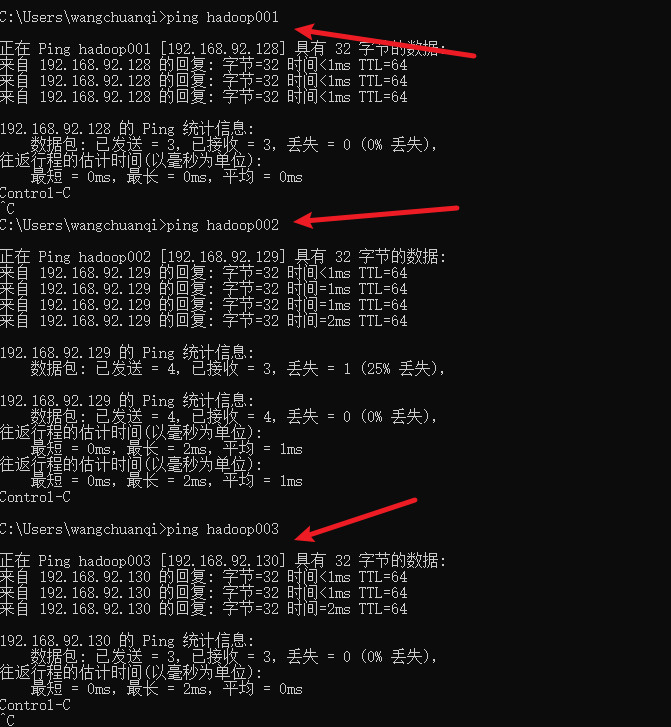
5. 测试各虚拟机跟外网的连通性
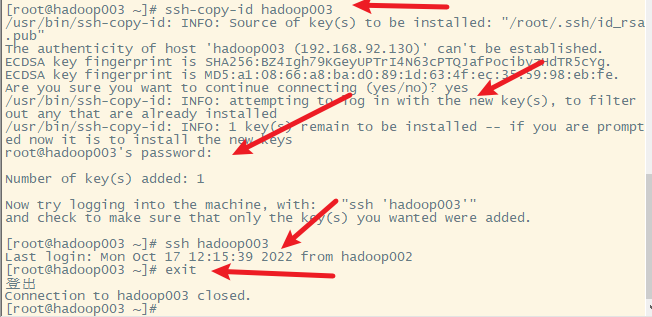
四、各主机之间的SSH免密登录
1. 查看hadoop的密钥存放文件夹
在hadoop001上进行操作
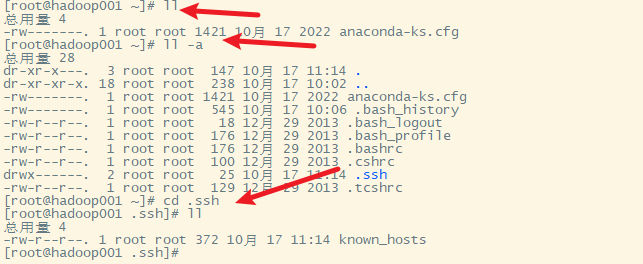
2. 生成密钥
使用的命令ssh-keygen生成密钥,id_rsa为私钥
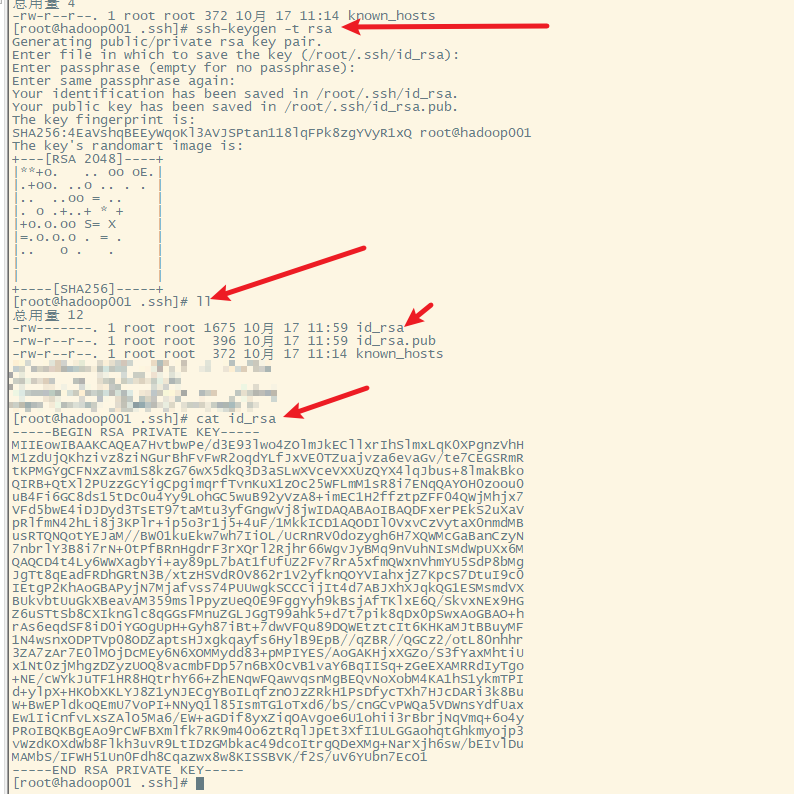
id_rsa.pub是公钥

3. 复制生成的密钥文件到其他主机(包括hadoop001自己)
1) hadoop001免密登录hadoop001
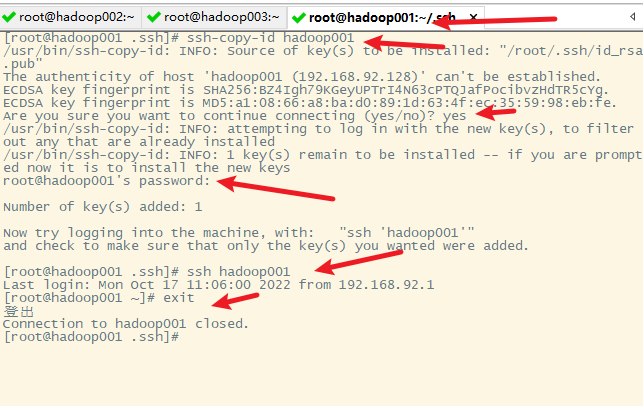
2)hadoop001免密登录hadoop002
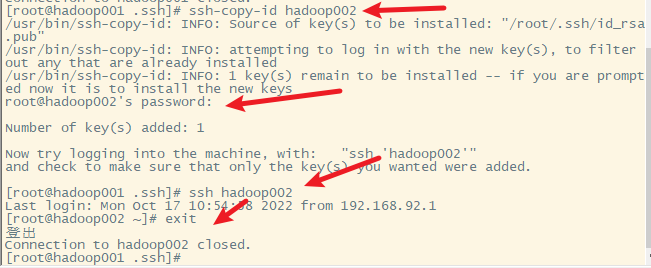
在hadoop002上进行查看
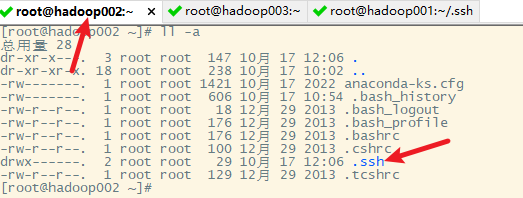
3)hadoop001免密登录hadoop003
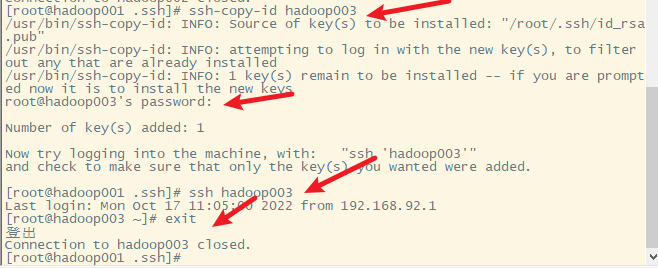
在hadoop003上进行查看
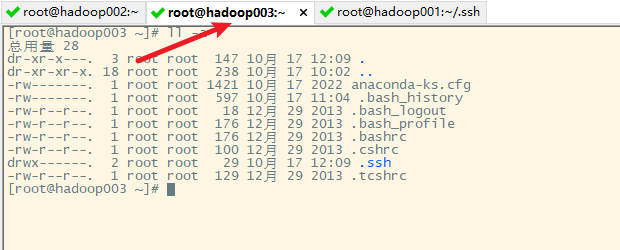
在hadoop002和hadoop003上也进行同样的操作
4) hadoop002免密登录hadoop001
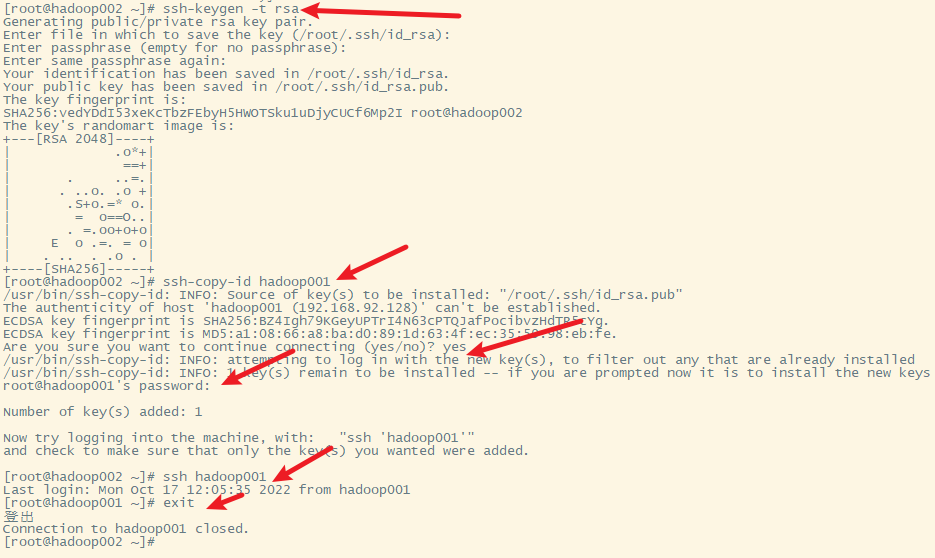
5) hadoop002免密登录hadoop002
6) hadoop002免密登录hadoop003
7) hadoop003免密登录hadoop001
8) hadoop003免密登录hadoop002
9) hadoop003免密登录hadoop003
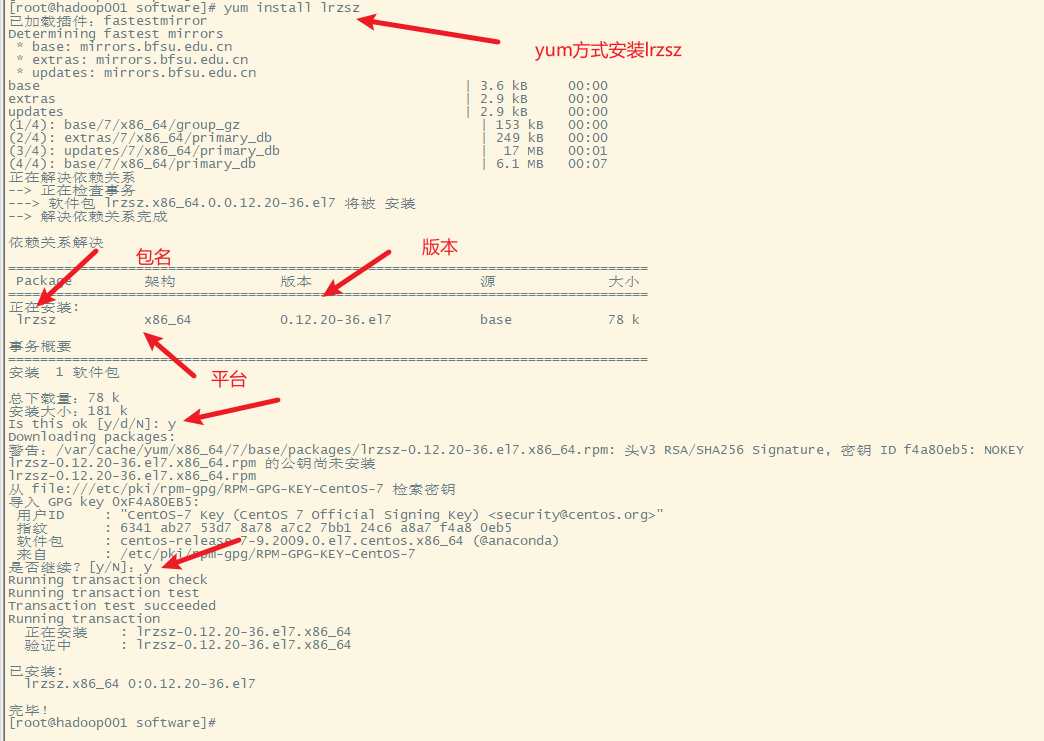
五、安装上传下载的小工具
Lrzsz
六、JDK的安装
JDK是java的开发工具包,hadoop是用java开发的,所以需要安装jdk
1. 下载JDK
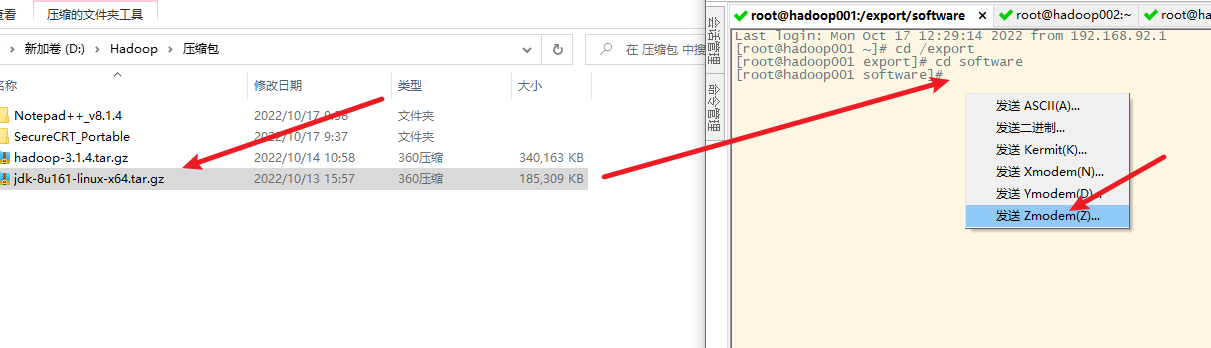
2. 上传到服务器
要上传到以下文件夹

将jdk拖动到software文件夹下
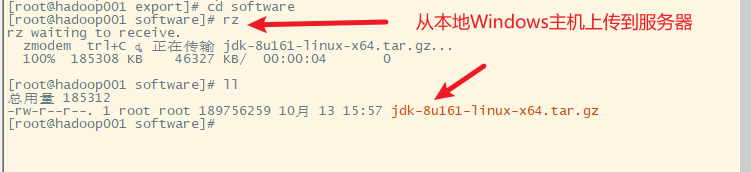
3.解压

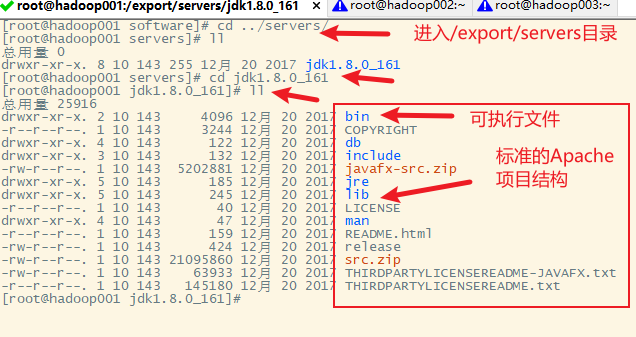
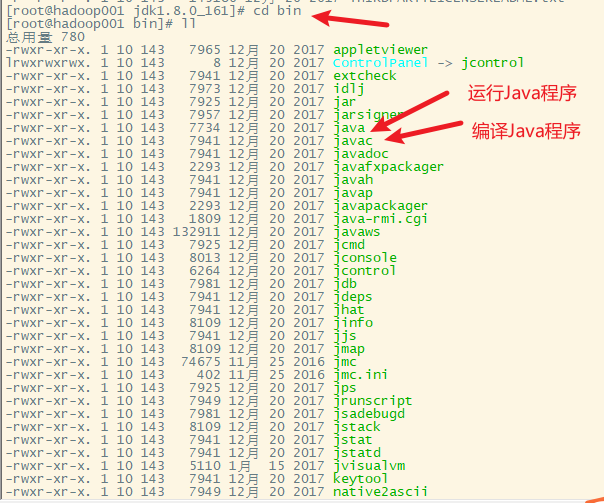

4.配置环境变量
修改/etc/profile,在文件末尾添加如下内容
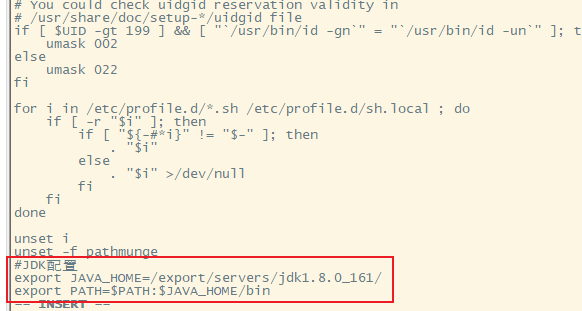
5.使环境变量起作用
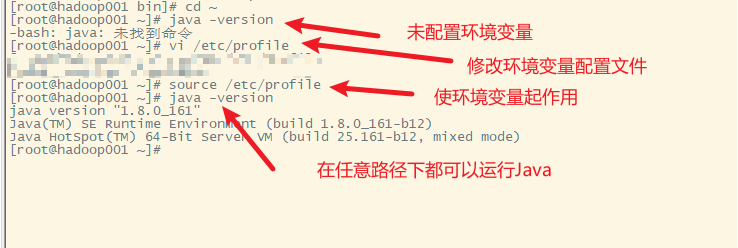
6. 分发hadoop001上的jdk到hadoop002和hadoop003上


7. 分发hadoop001的/etc/profile到hadoop002和hadoop003上

8. 使hadoop002和hadoop003的环境变量起作用
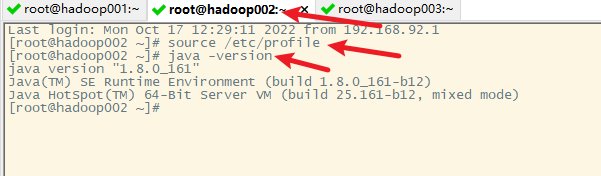
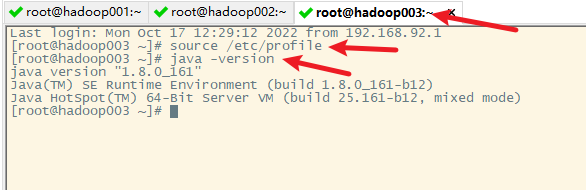
小技巧:发送命令给所有的节点
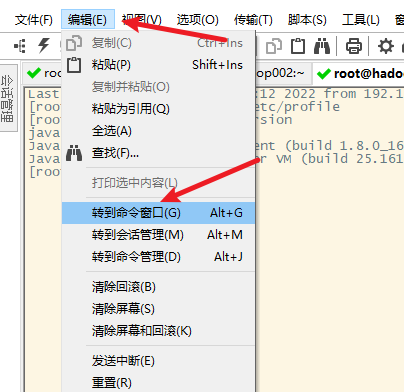
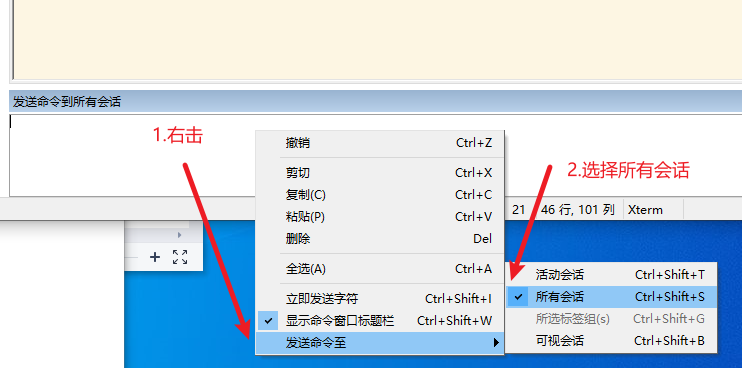
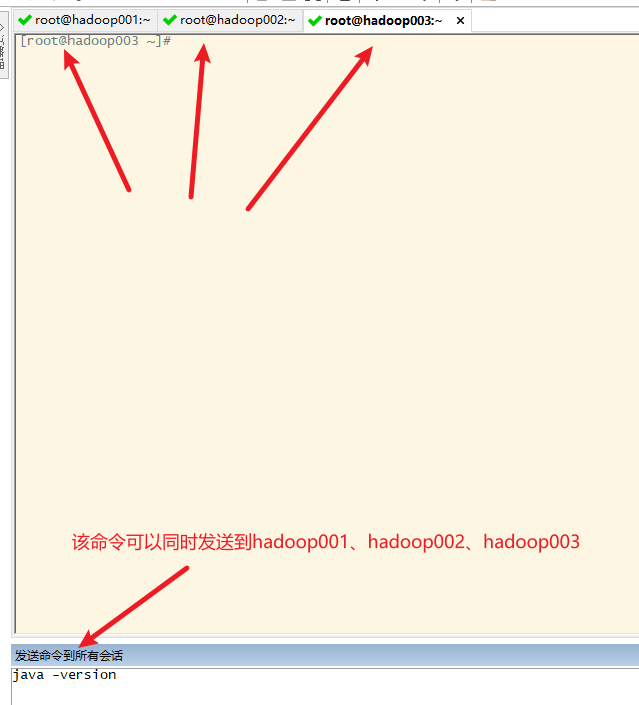
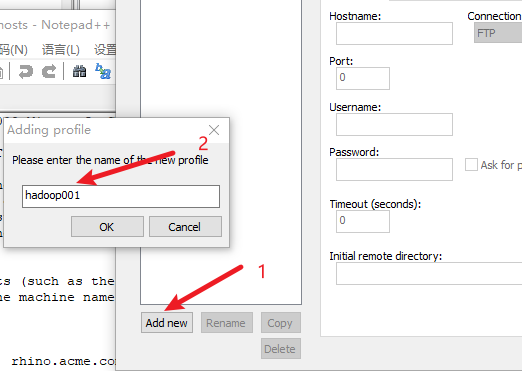
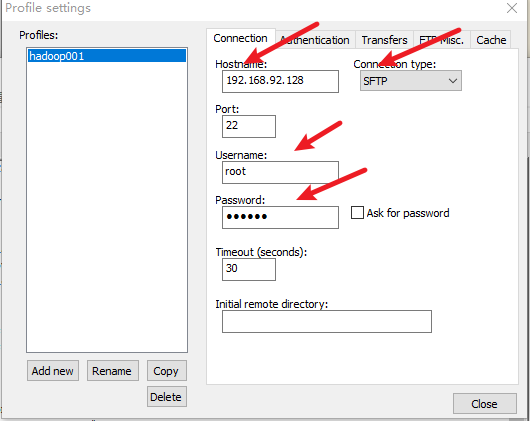
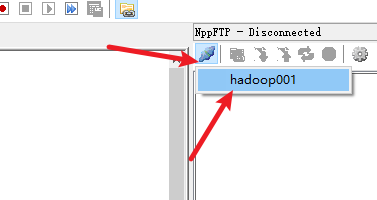
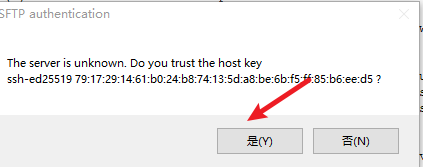
七、安装notepad++的插件
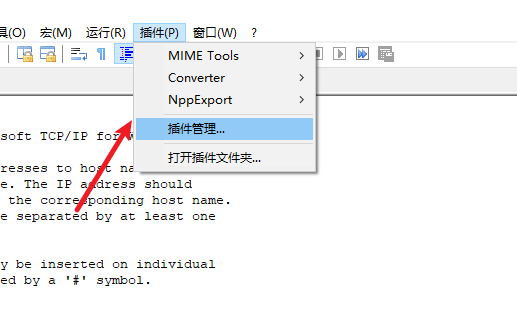
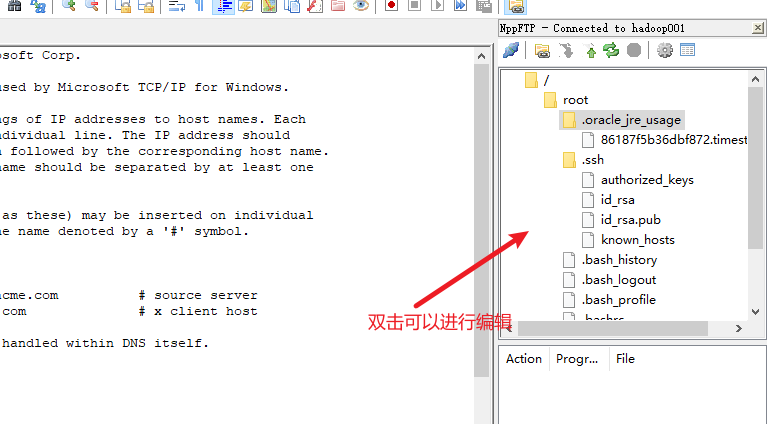
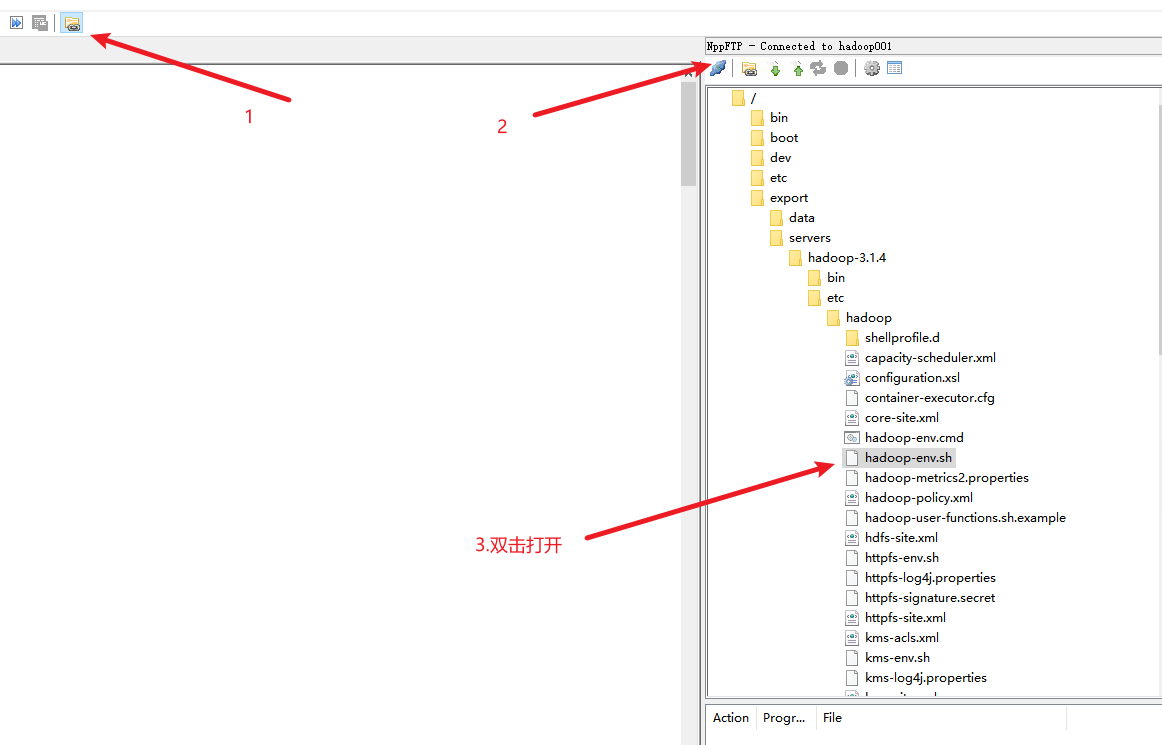
安装nppftp插件
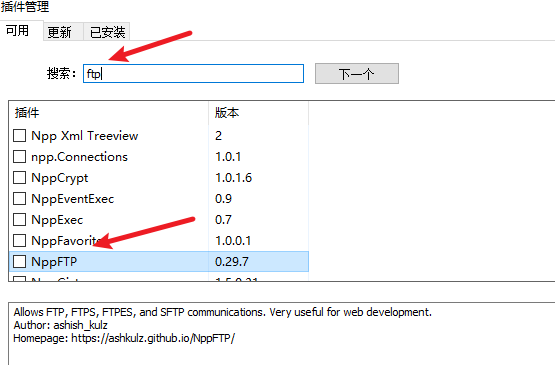
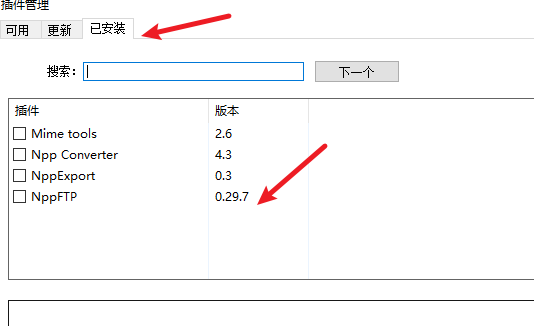
使用该插件
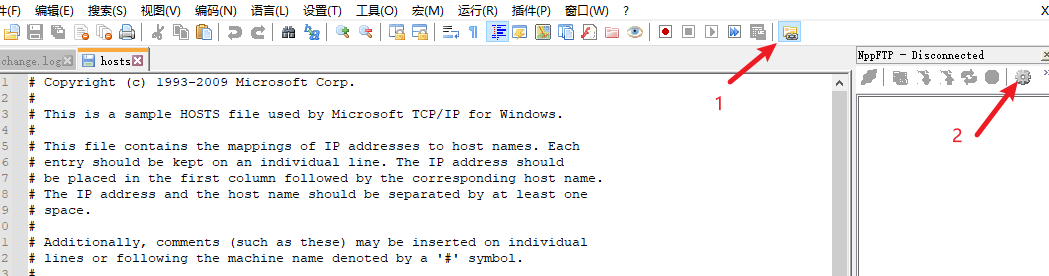
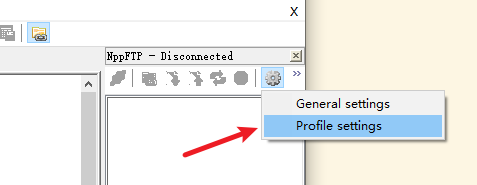
八、Hadoop的安装
1. hadoop集群的安装模式
1) 独立模式standalone
又称单机模式,所有的进程运行在一台主机上
2) 伪分布模式 pseudodistributed
在一台主机模拟多主机
3) 完全分布模式 fulldistributed
守护进程运行在由多台主机搭建的集群上,是真正的生产环境
2. 下载hadoop
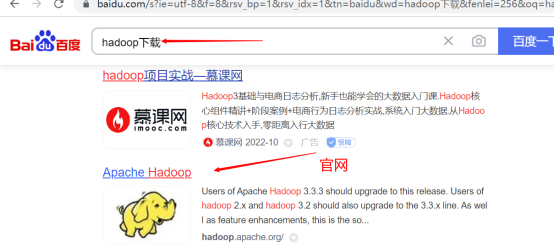
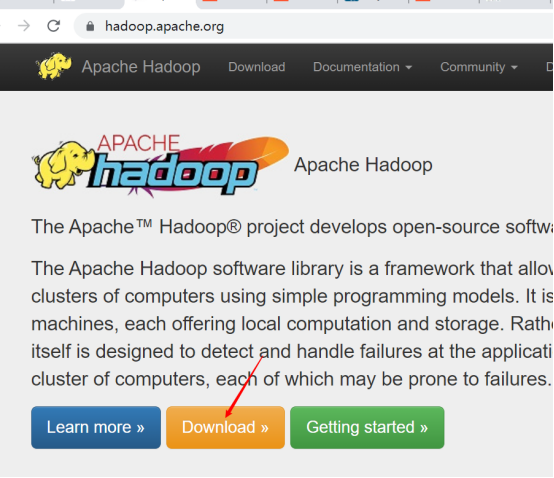
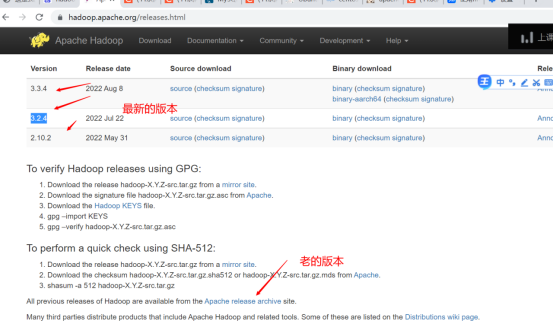
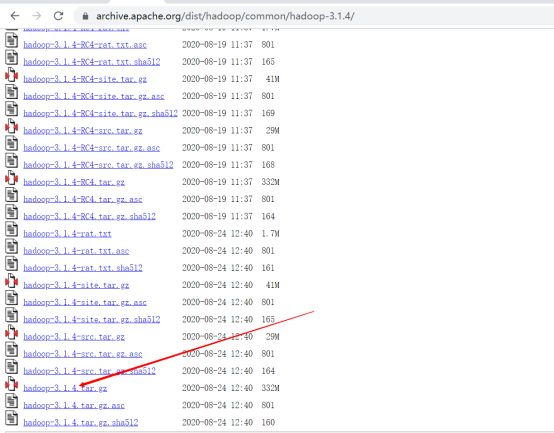
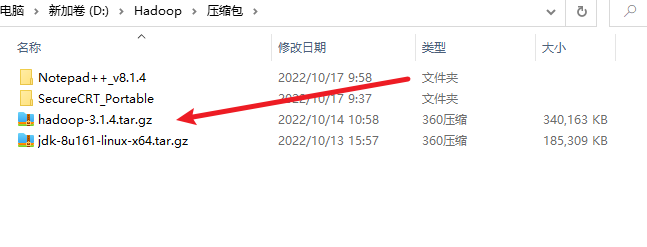
3. 上传到服务器
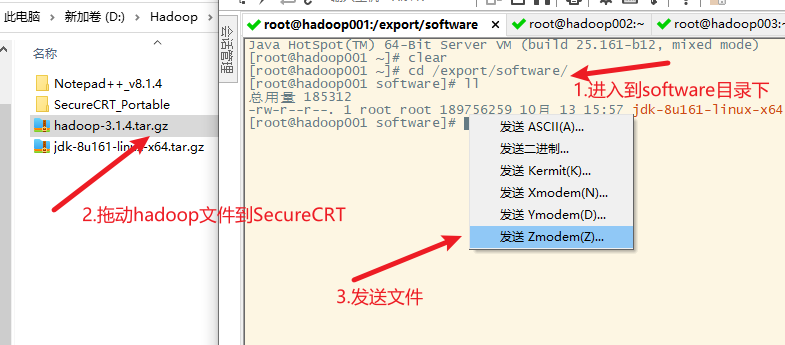
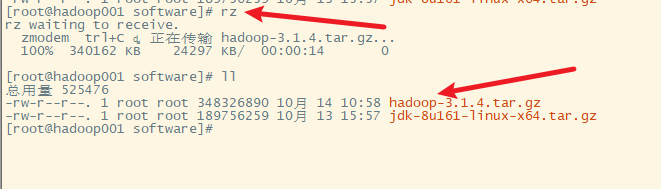
4. 也可以通过centos的wget命令直接下载到服务器
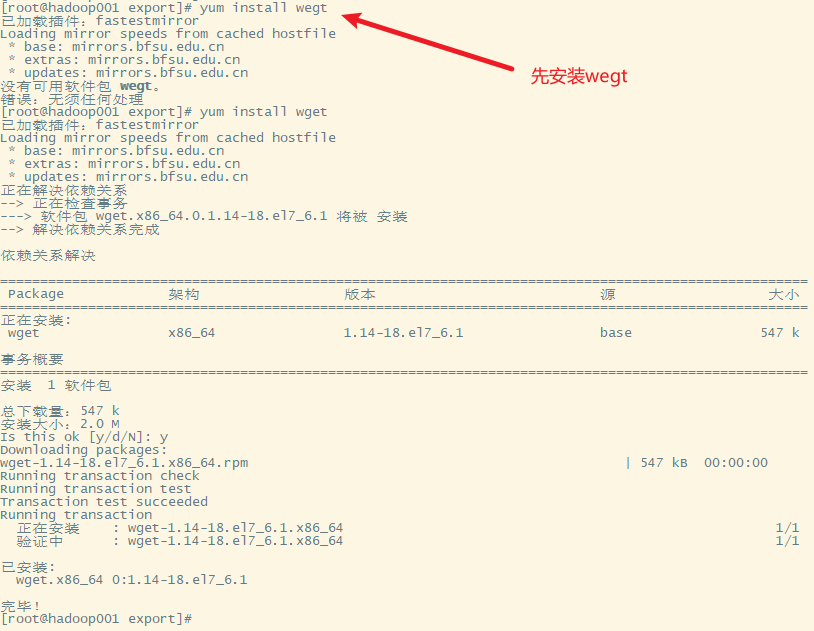

5.解压


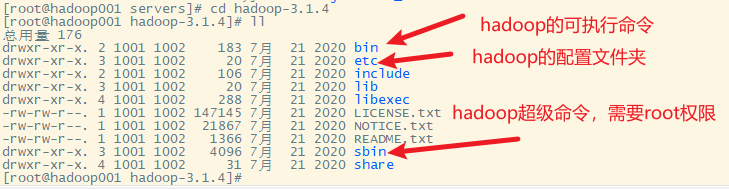
6. 配置环境变量

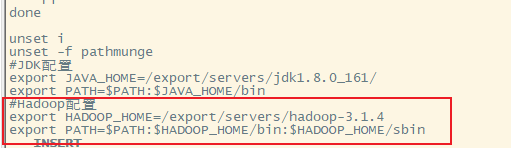
7. 使配置起作用

8. 测试

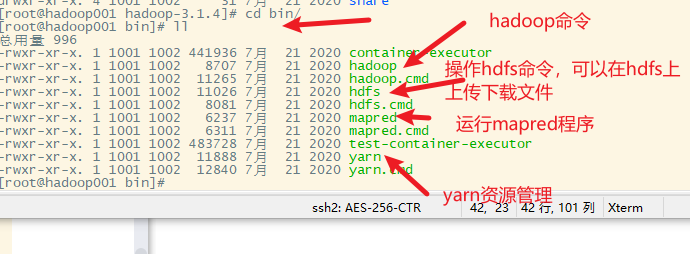
9. hadoop的命令说明
bin子目录下
sbin子目录下
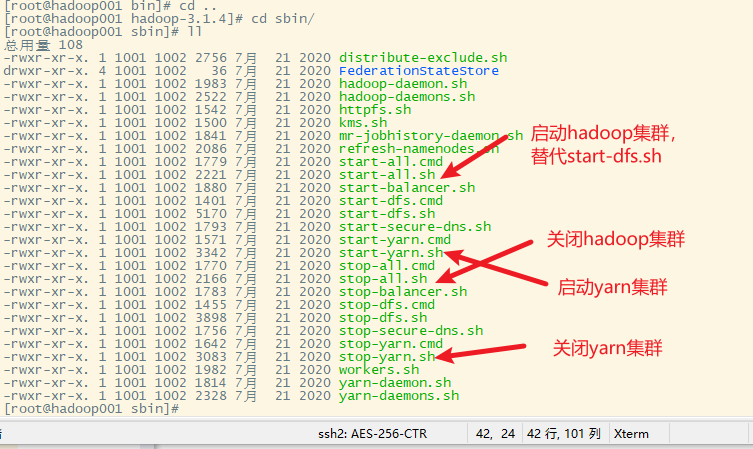
九、hadoop的独立模式启动
不做任何配置,直接启动hadoop集群就是独立模式
1. 启动集群命令sbin目录下,start-all.sh
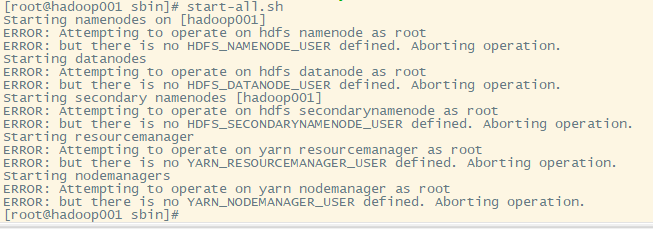
出现提示,需要配置hadoop的环境
2. 配置hadoop
3. 配置hadoop的环境变量
可以通过vi直接进行修改环境配置文件
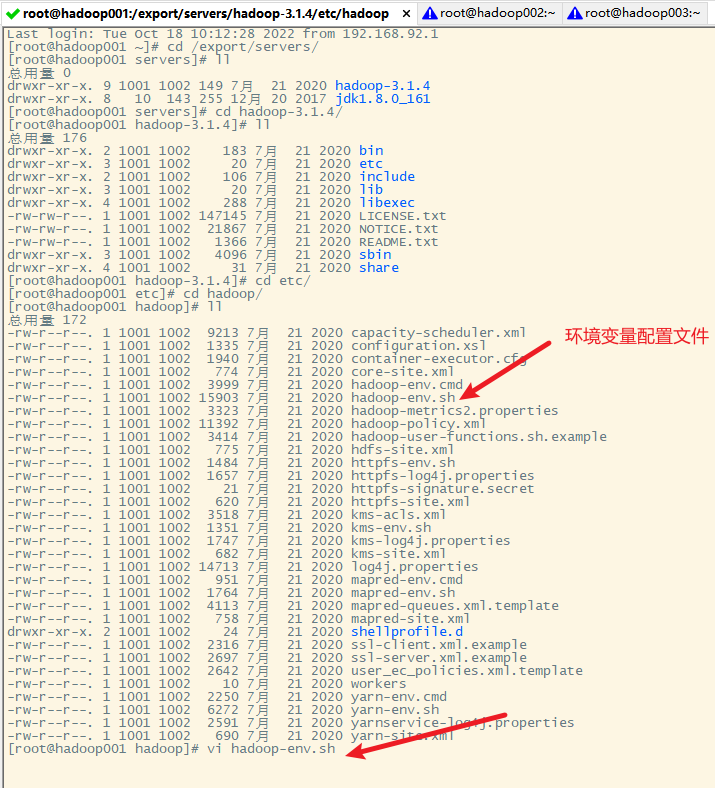
也可以通过notepad++的插件进行编辑环境配置文件
4. 在启动hadoop独立模式之前用jps查看java进程

5. 再次启动hadoop独立模式
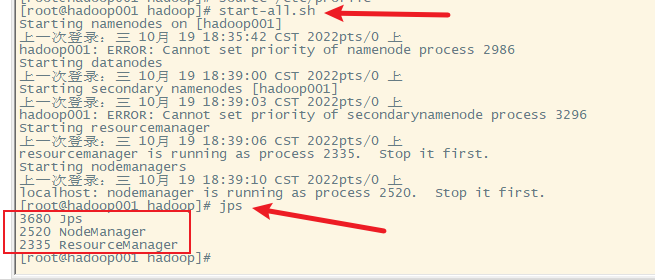
并没有启动独立模式,也就是启动独立模式也需要对hadoop进行配置
十、Hadoop集群配置
在hadoop001上进行配置
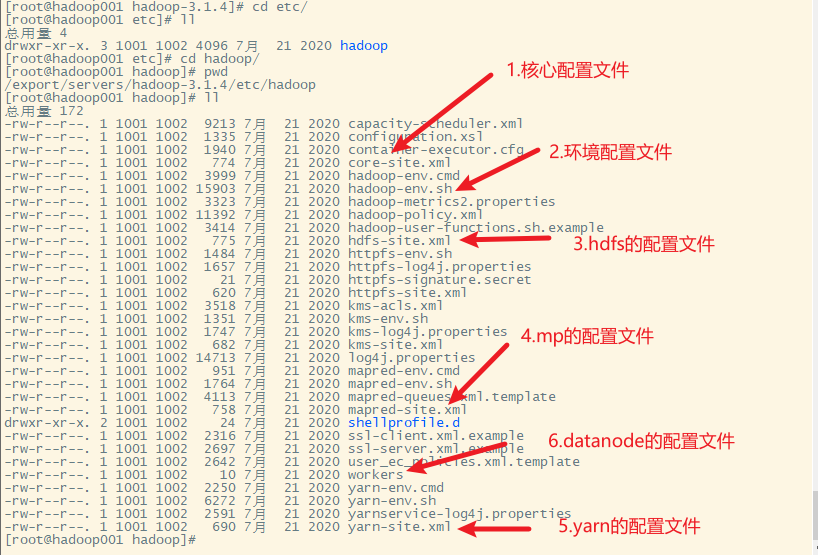
1. hadoop的配置文件
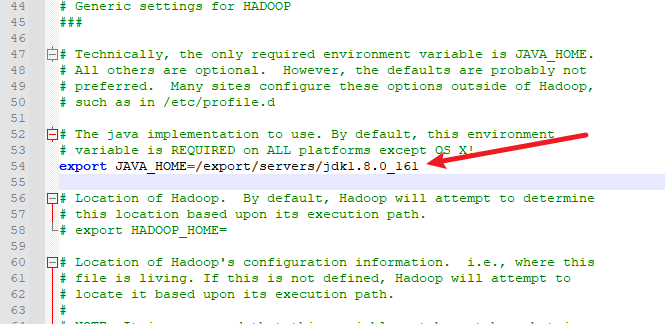
2. 修改hadoop-env.sh文件
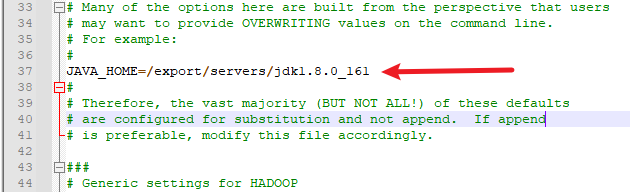
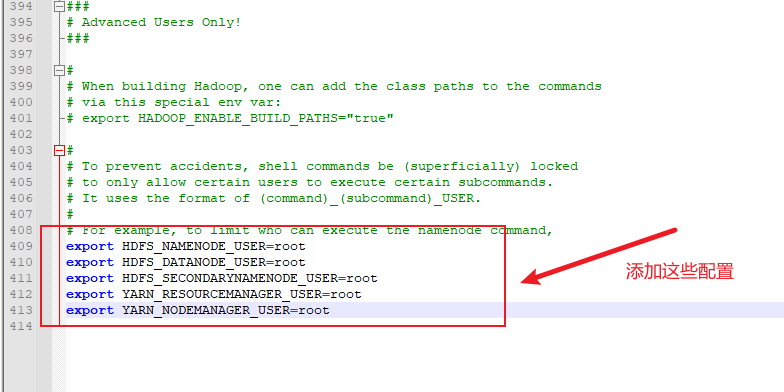
配置JAVA_HOME,在第54行左右
配置操作用户
3. 修改core-site.xml文件
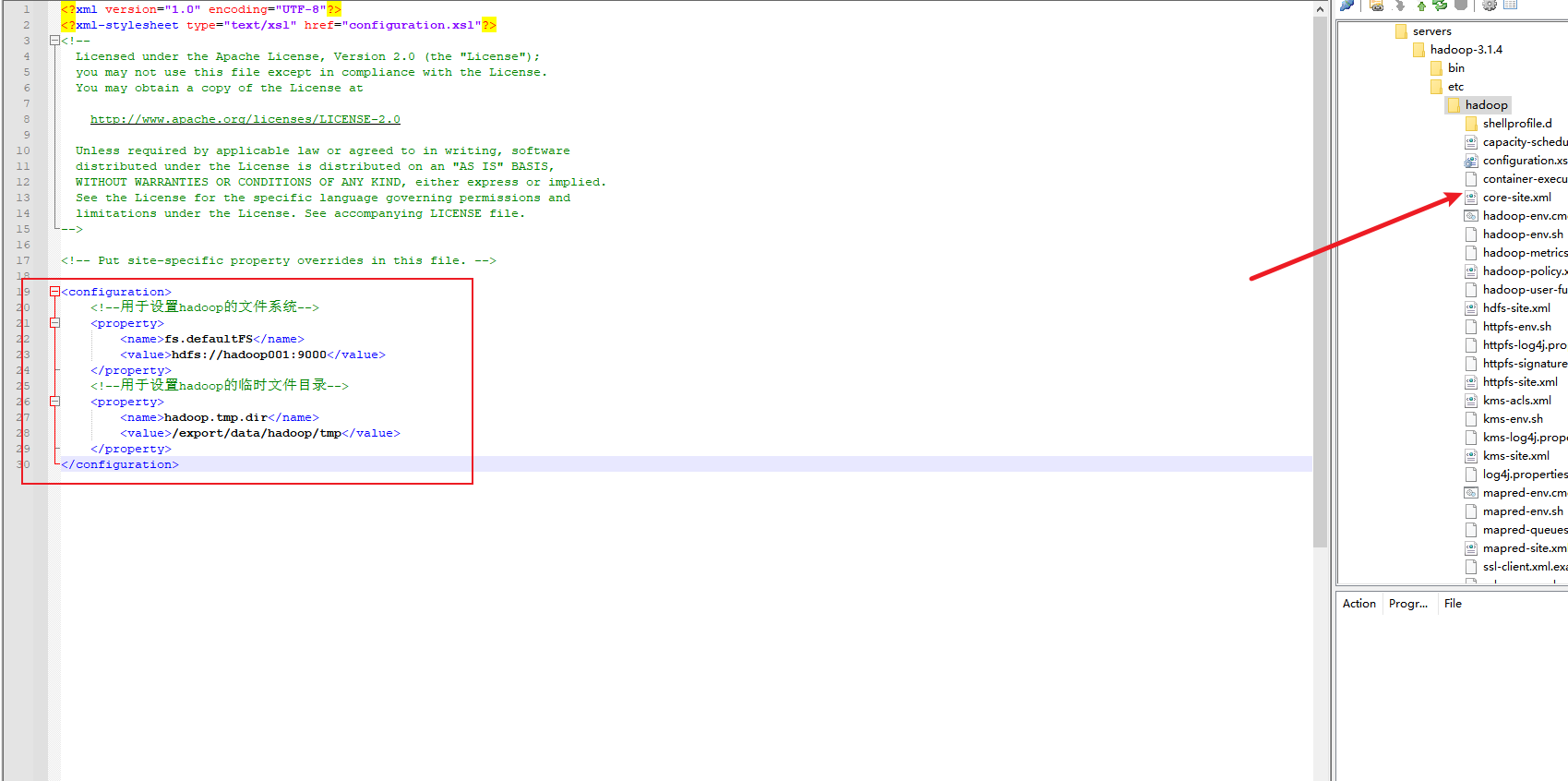
4. 修改hdfs-site.xml文件
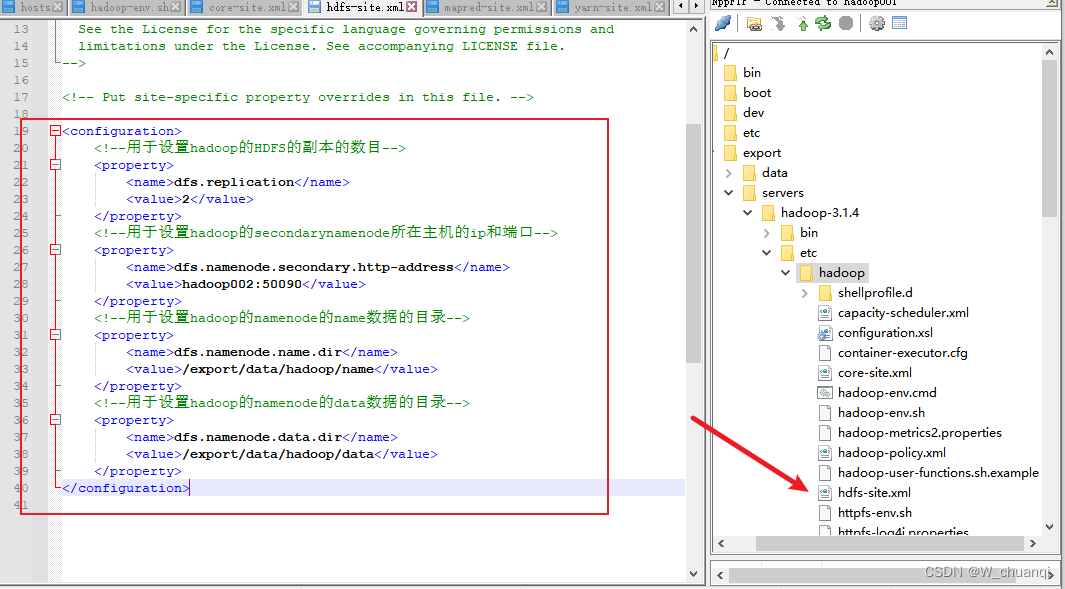
5. 修改mapred-site.xml文件
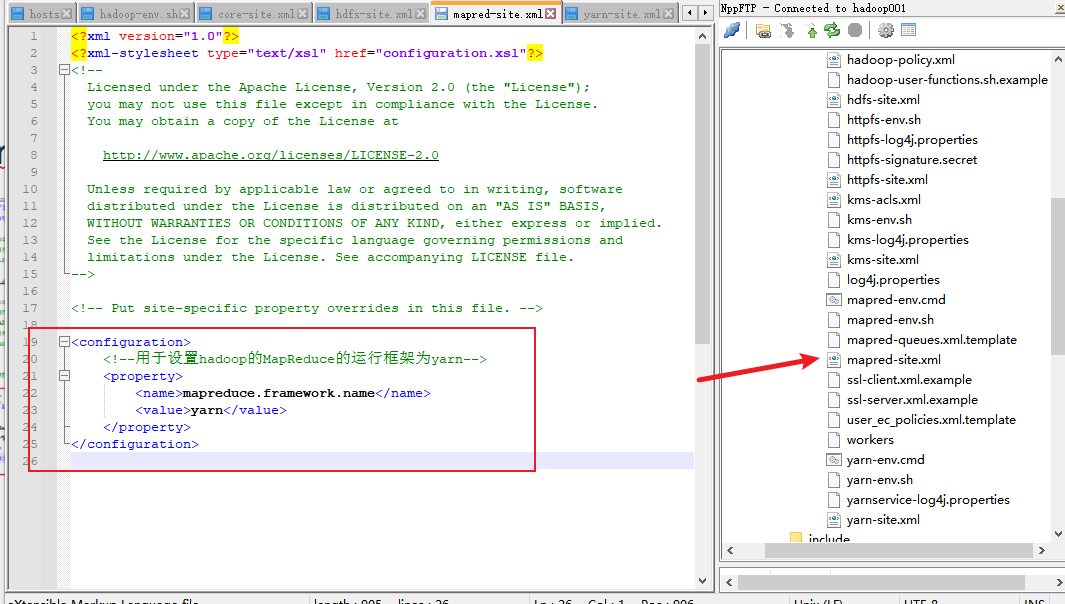
6. 修改yarn-site.xml文件
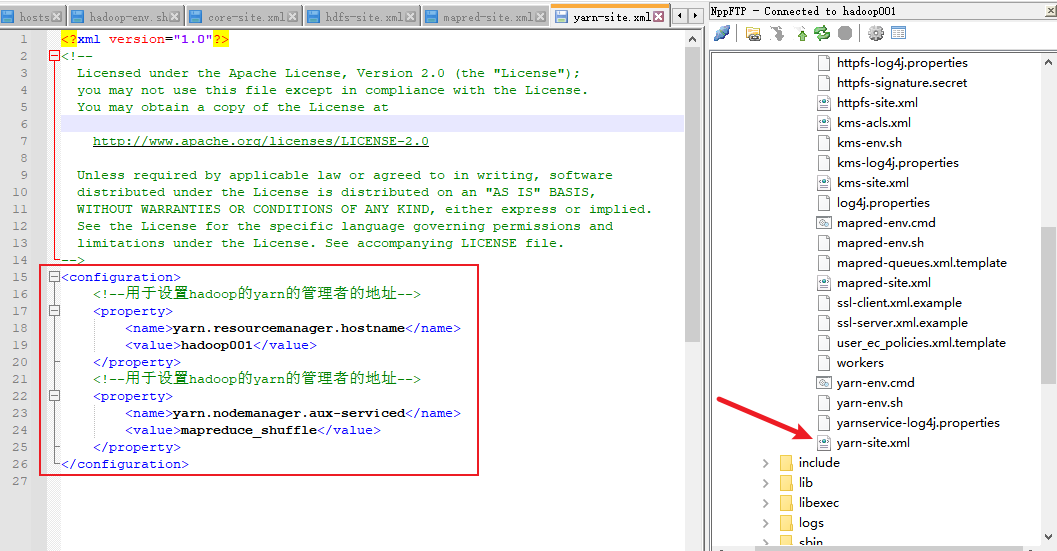
7. 修改workers文件
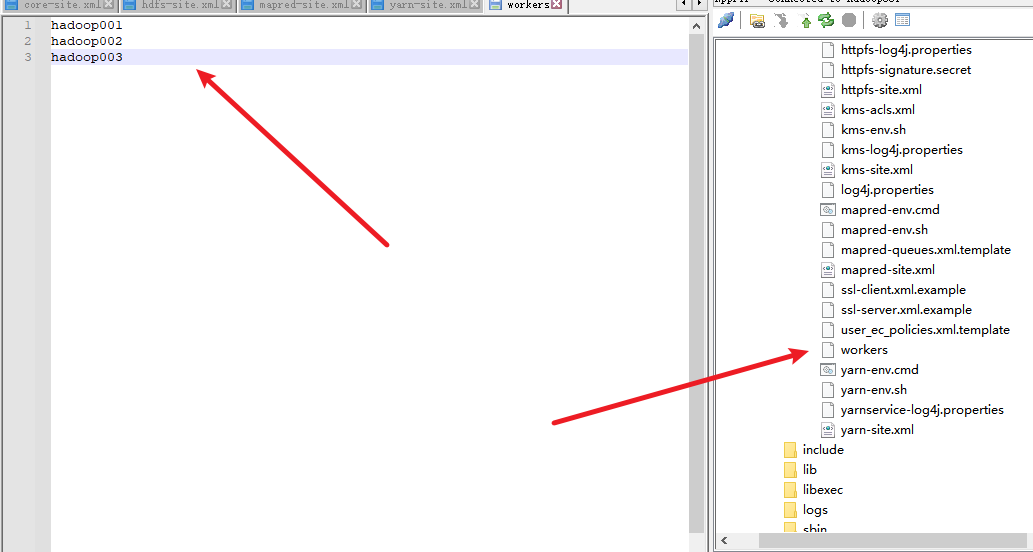
8. 分发hadoop目录到hadoop002和hadoop003上
注意前面的集群配置错误要重新分法相应的文件。
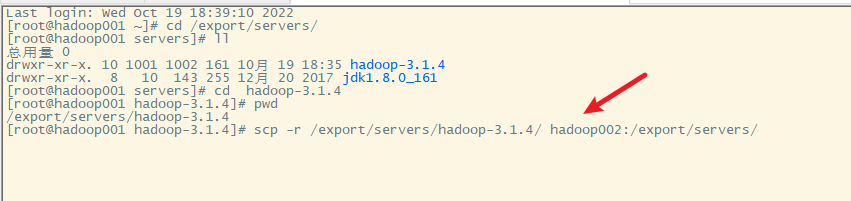

9. 分发环境变量配置文件到hadoop002和hadoop003上

10. 使hadoop002和hadoop003上的环境变量起作用
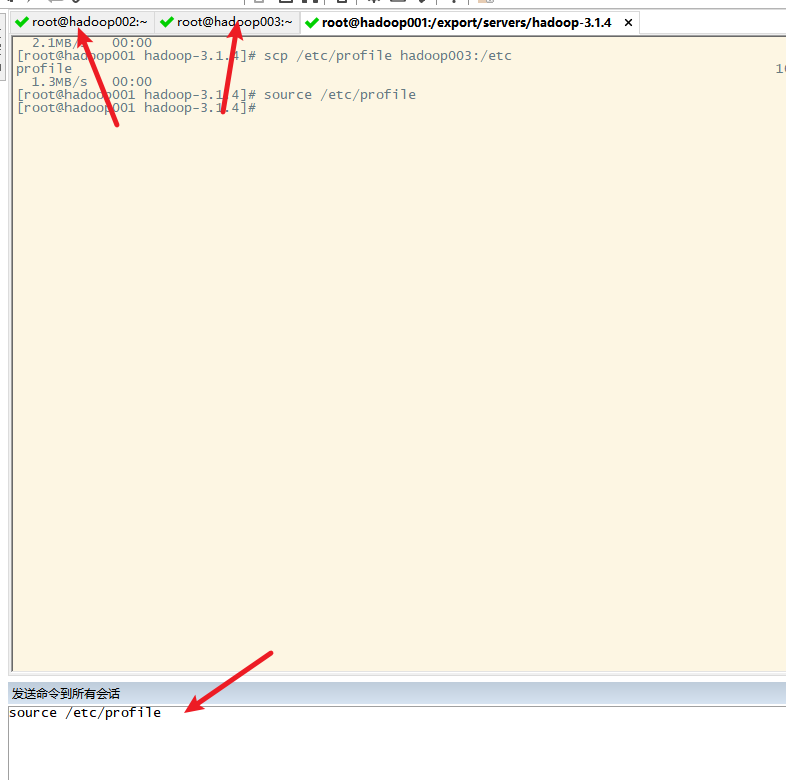
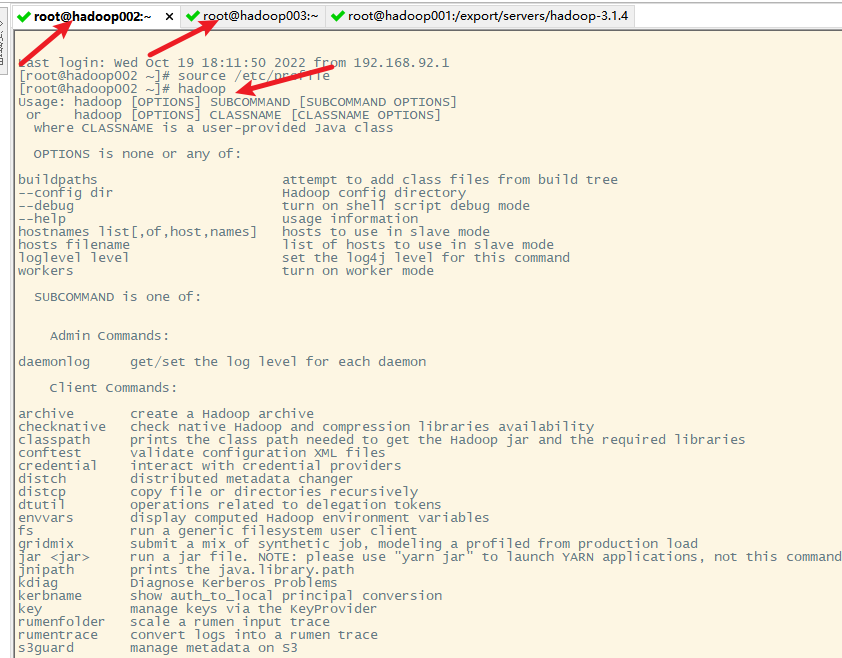
11. 测试hadoop是否安装正确
十一、hadoop集群的文件系统格式化
在启动hadoop集群之前,需要对主节点hadoop001进行格式化
hadoop namenode -format
也可以用
hdfs namenode -format
在集群格式化之前,/export/data文件夹为空

格式化集群

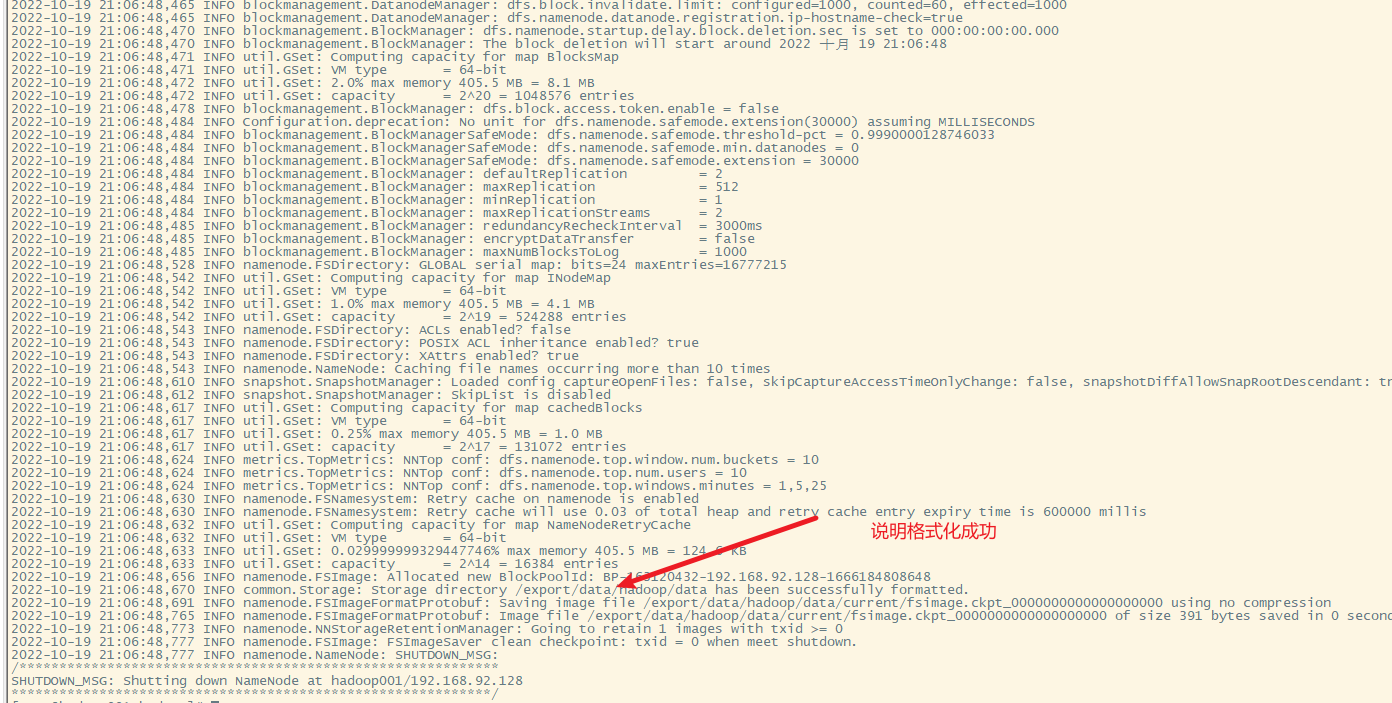
此时的hadoop存储目录结构
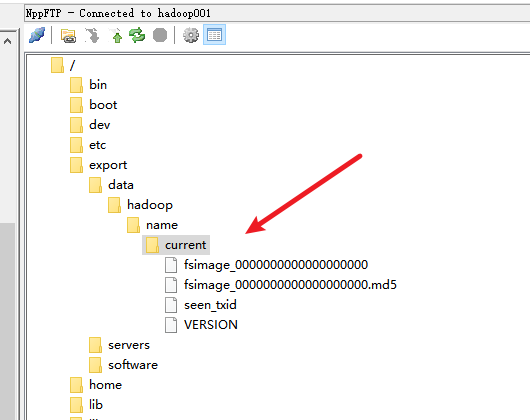
十二、启动和关闭hadoop集群
一键启动或者分布启动
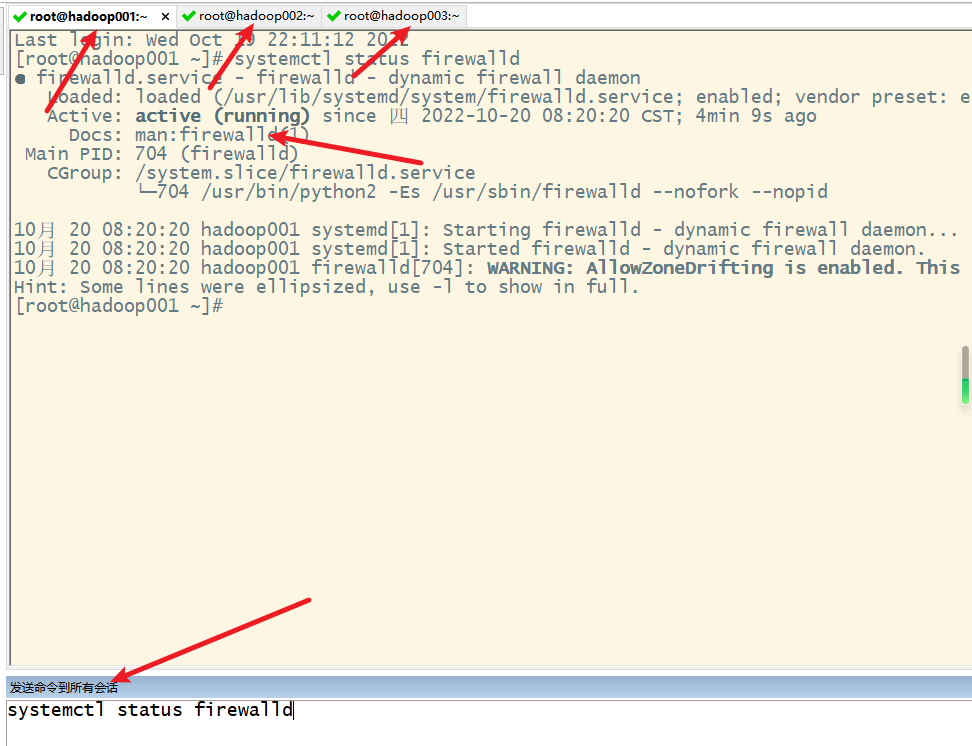
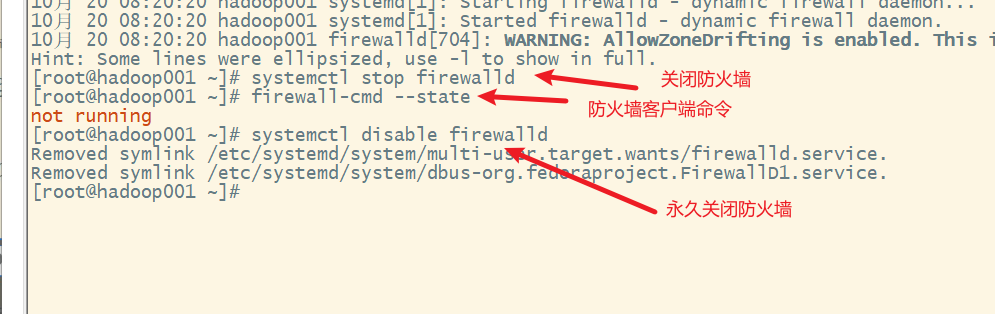
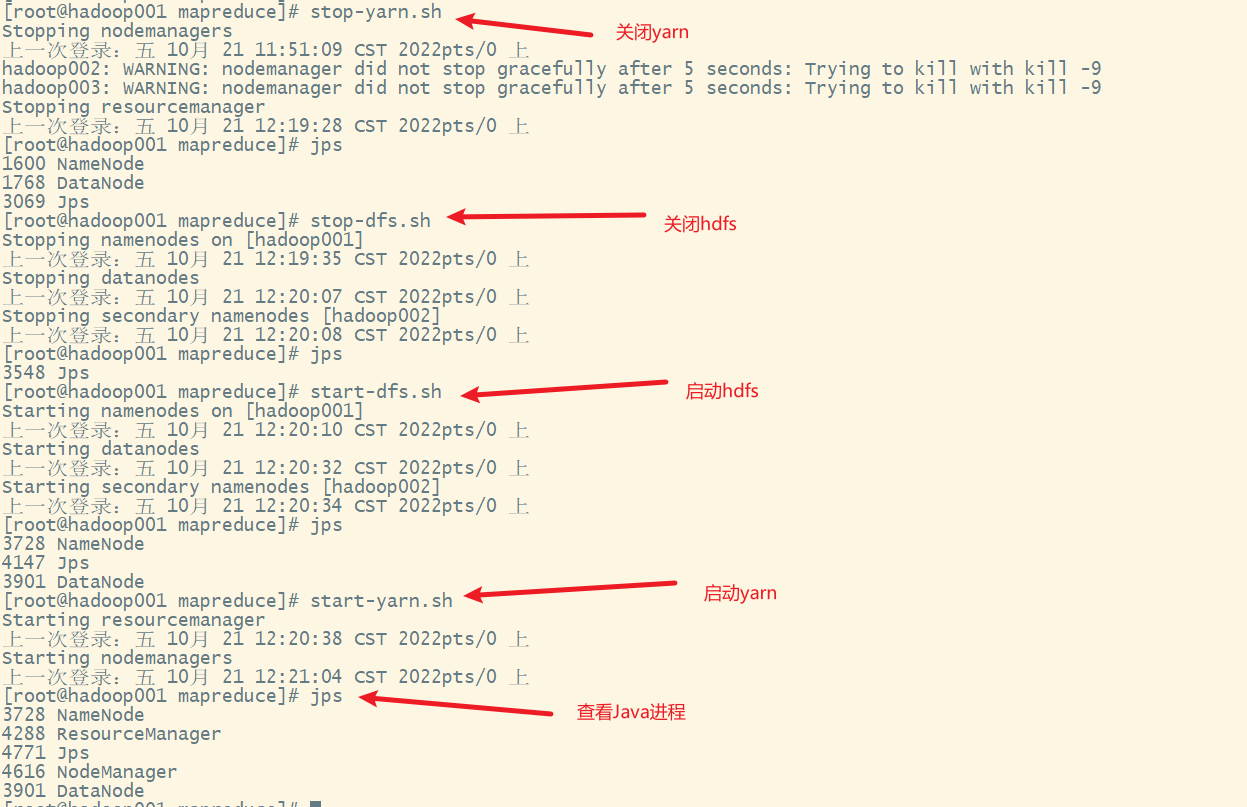
1. 关闭防火墙
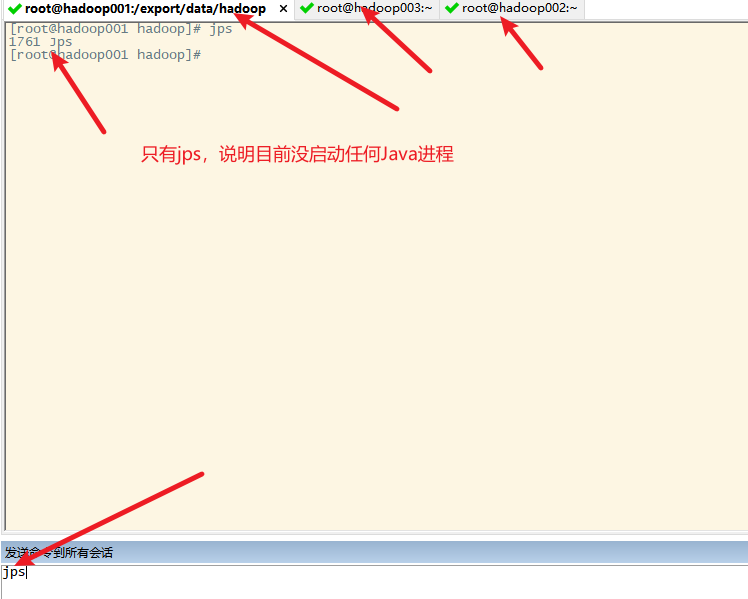
2. jps查看java进程
3. 启动hadoop集群
分布启动
1) 启动hfds
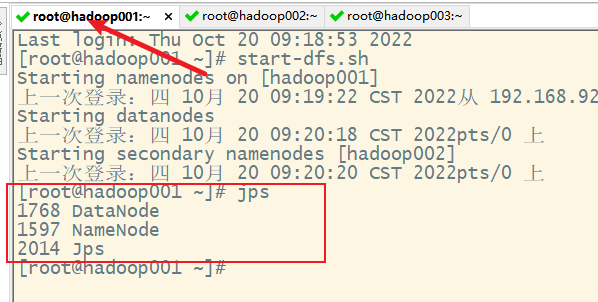
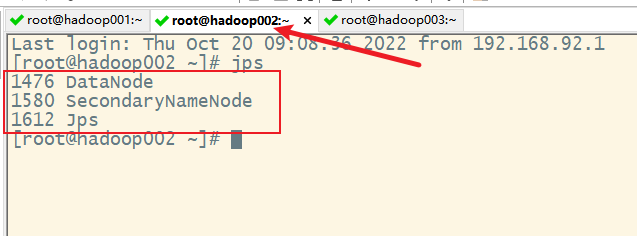
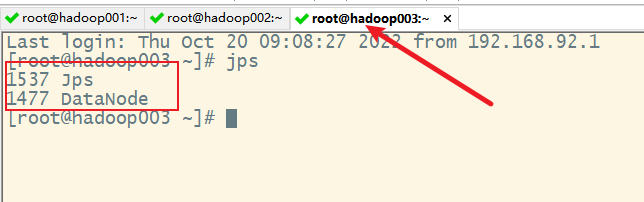
2)启动yarn
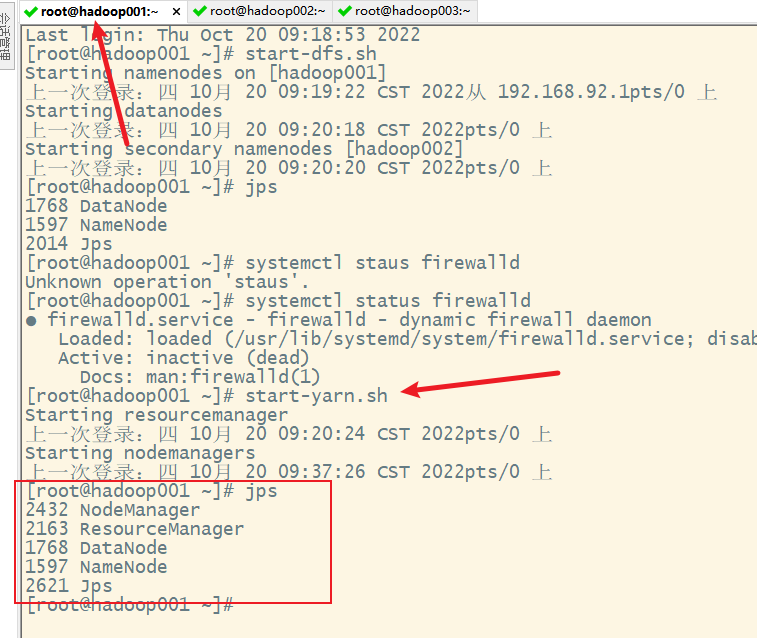
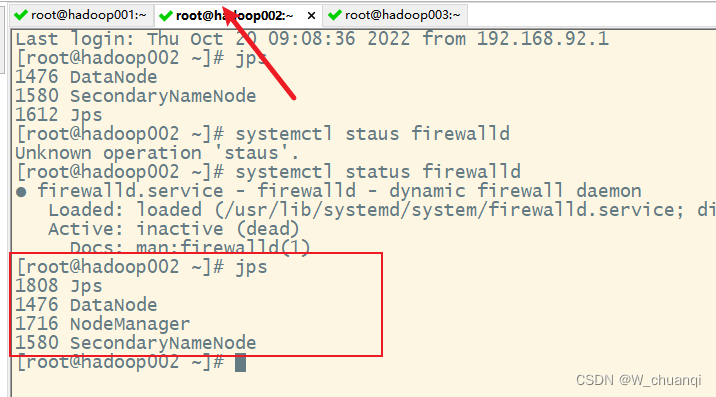
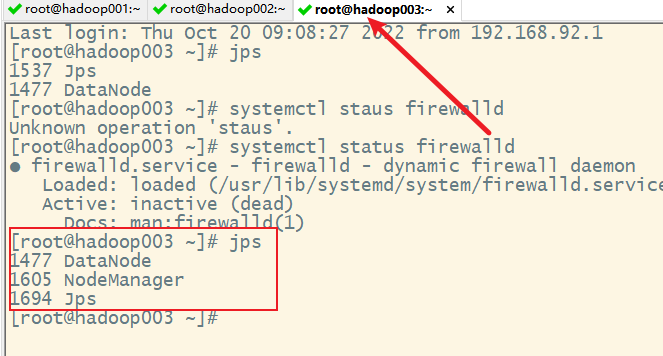
说明hadoop集群启动成功
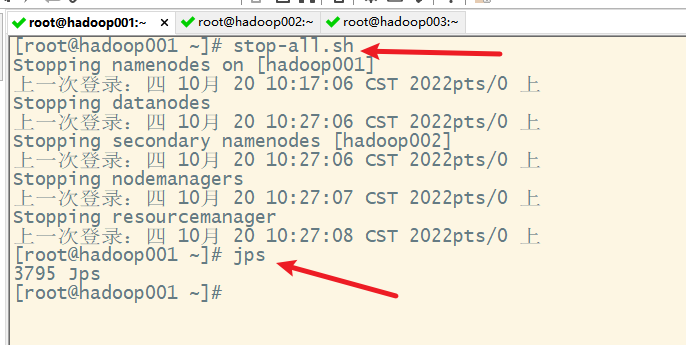
3) 一键启动
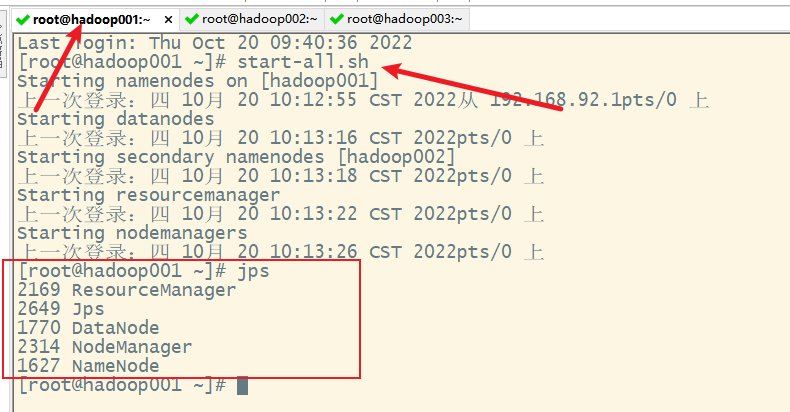
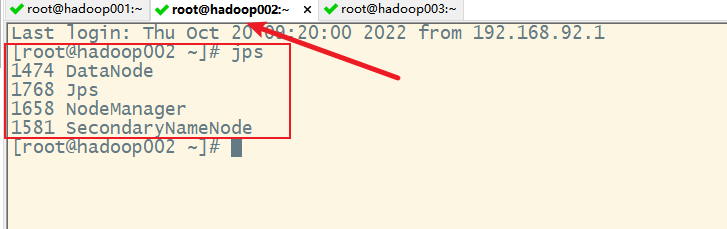
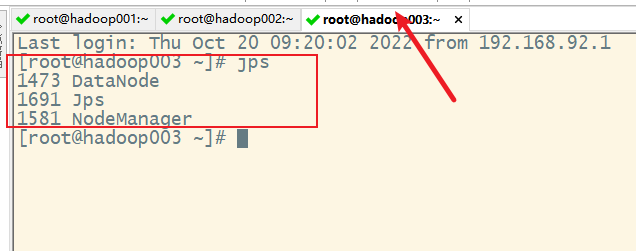
十三、关闭集群
1. 关闭yarn集群
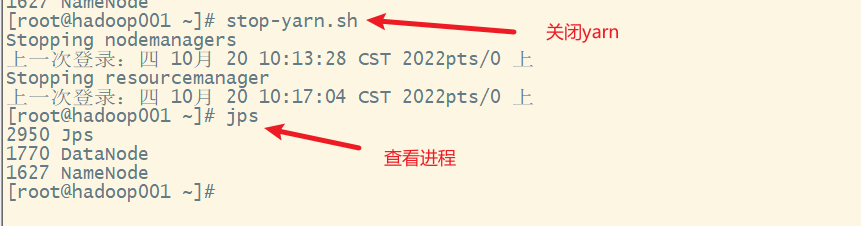
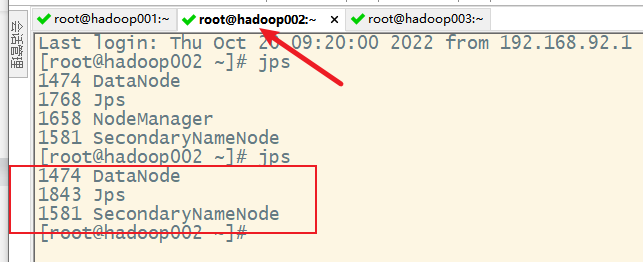
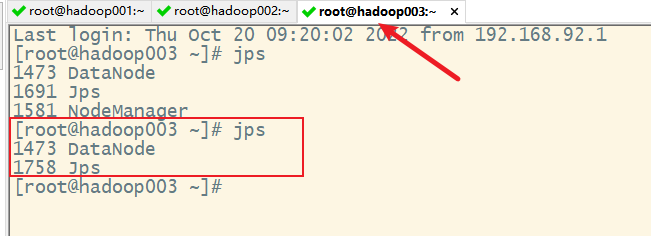
2. 关闭hdfs
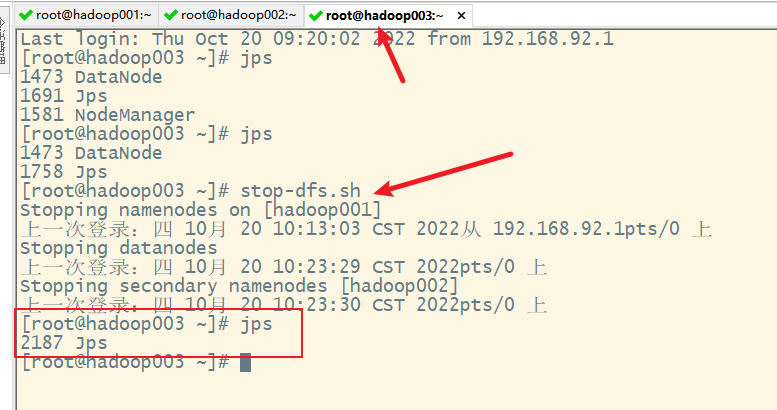
3. 一键关闭
十四、Hadoop集群测试
1. 通过WebUI(图形界面)查看Hadoop的运行状态
Hadoop集群启动后,默认开发了9870端口(hadoop3.0以上版本,老版本使用50070)用于监控hdfs,8088用于监控yarn,可以通过WebUI查看
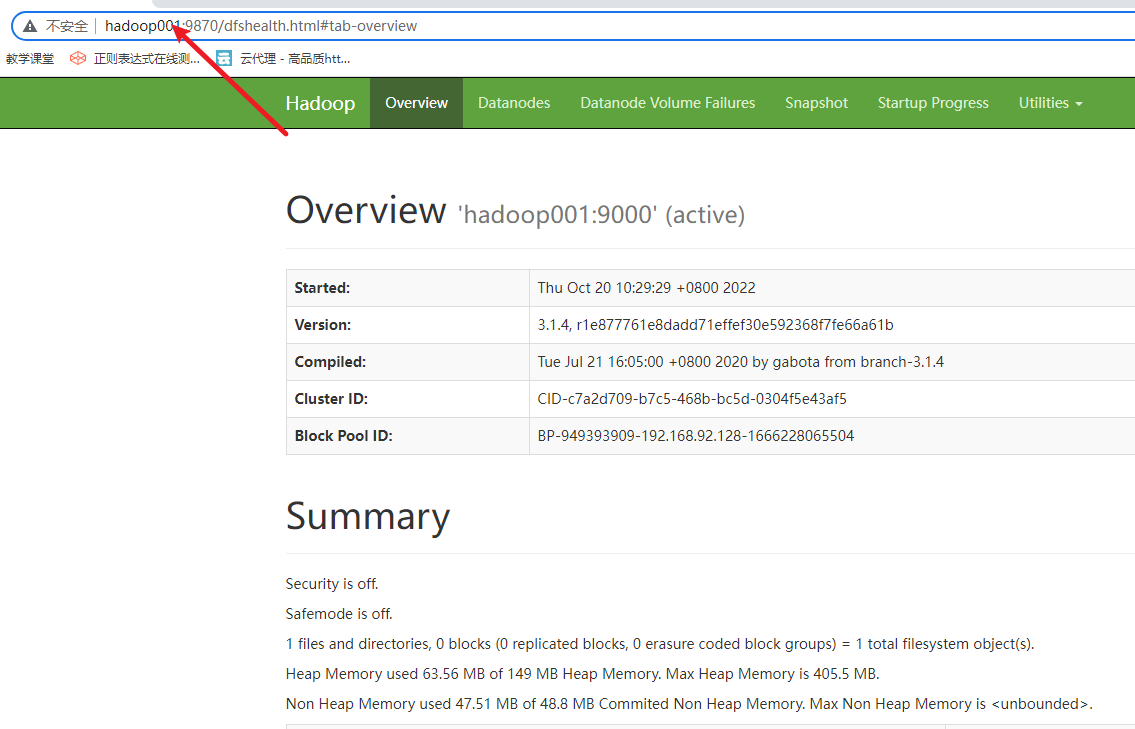
1) 查看hdfs的webui
在浏览器的地址栏中输入
http://hadoop001:9870
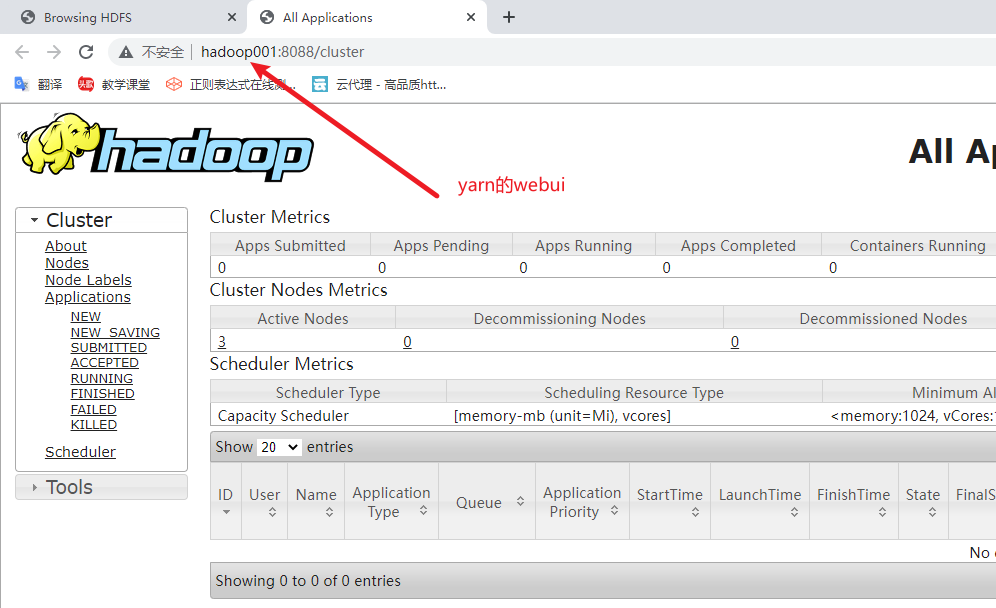
2) 查看yarn的web UI
在浏览器地址栏中输入
http://hadoop001:8088
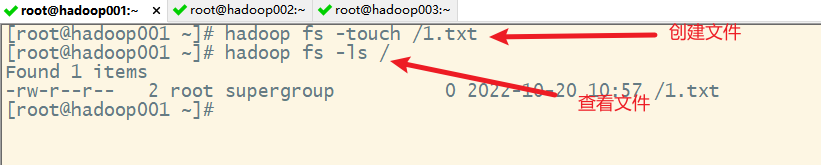
2. hdfs的shell命令的使用
hdfs通过了一些命令来对hdfs进行操作,类似于linux的命令,两种格式:
- hadoop fs 命令
- hdfs dfs 命令

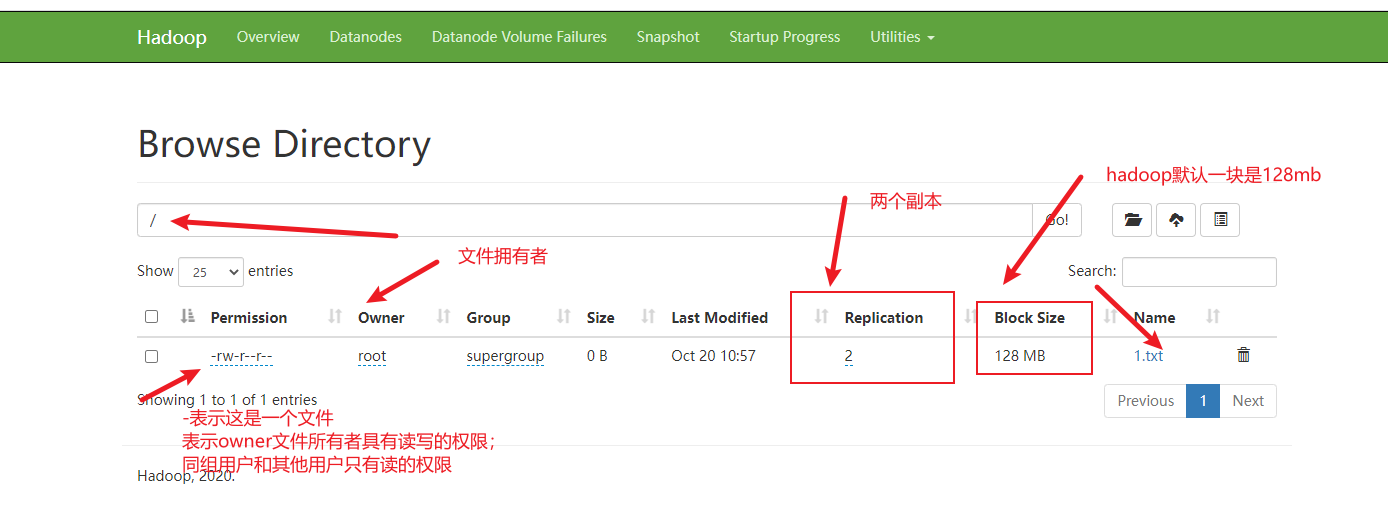
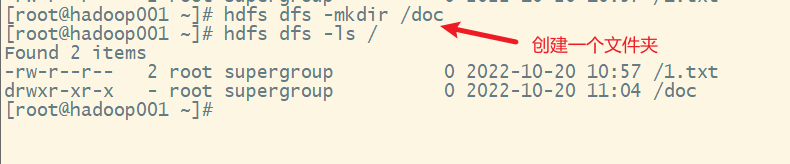
webui查看
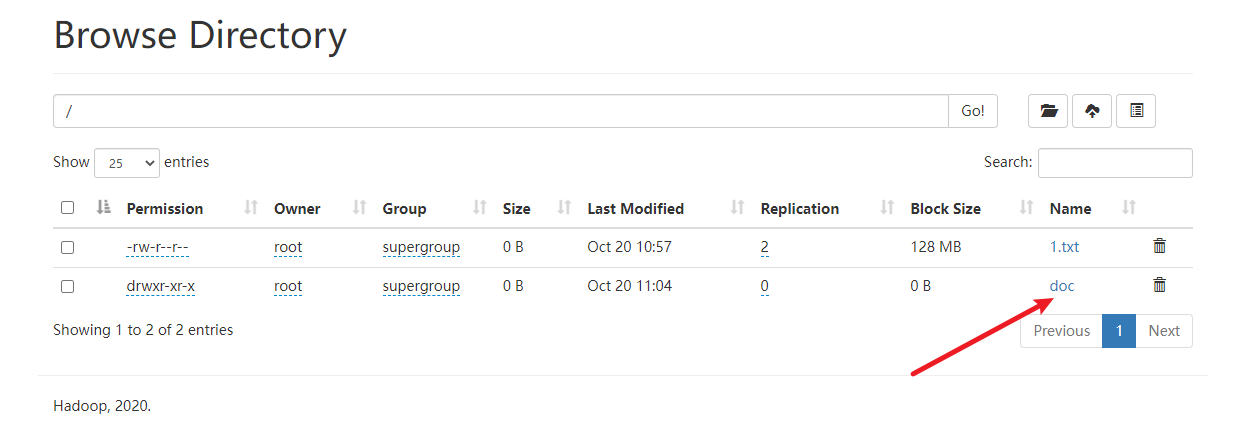
3. mapreduce的体验测试
单词计数的案例
1) 首先创建多个包含单词的文件

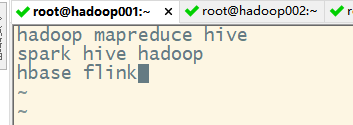
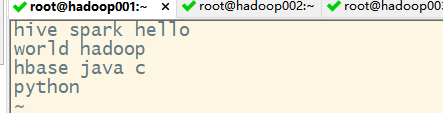
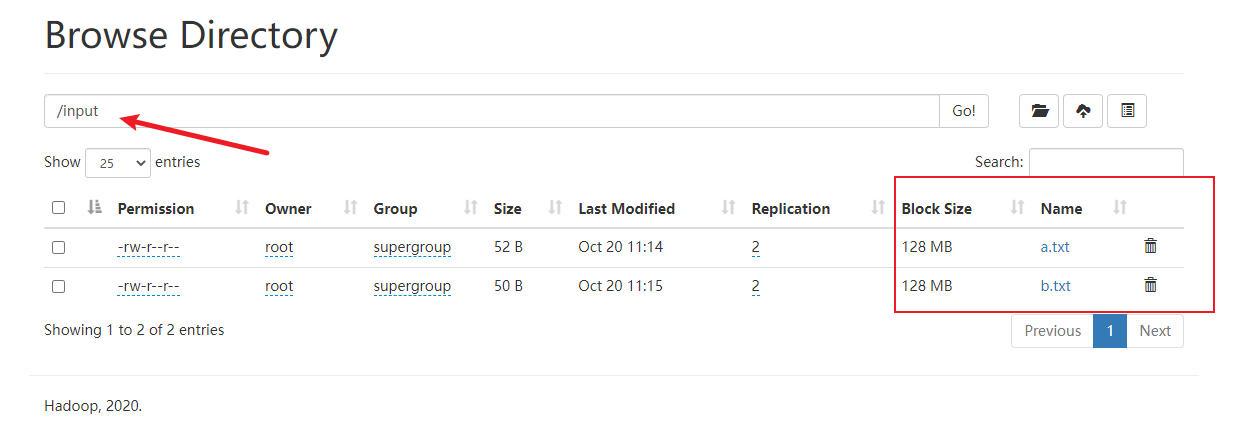
2) 在hdfs上创建一个input文件夹,并把上述两个文本文件上传到该文件夹
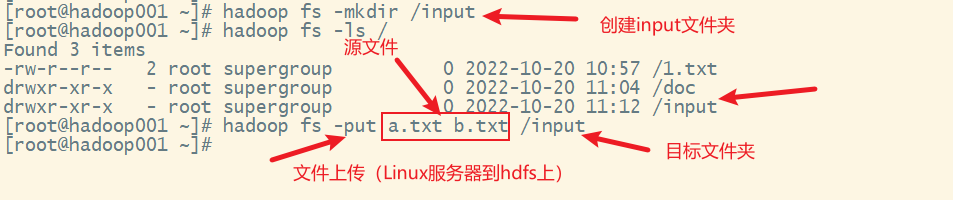
可以看到,文件已经上传到服务器上了。
3) 执行单词计数的mapreduce程序
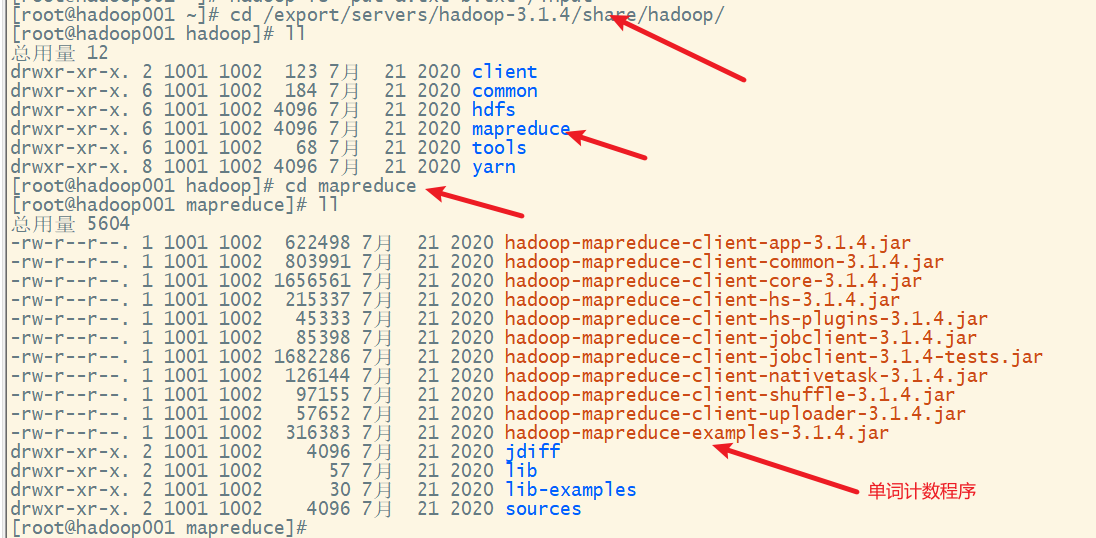
添加执行权限
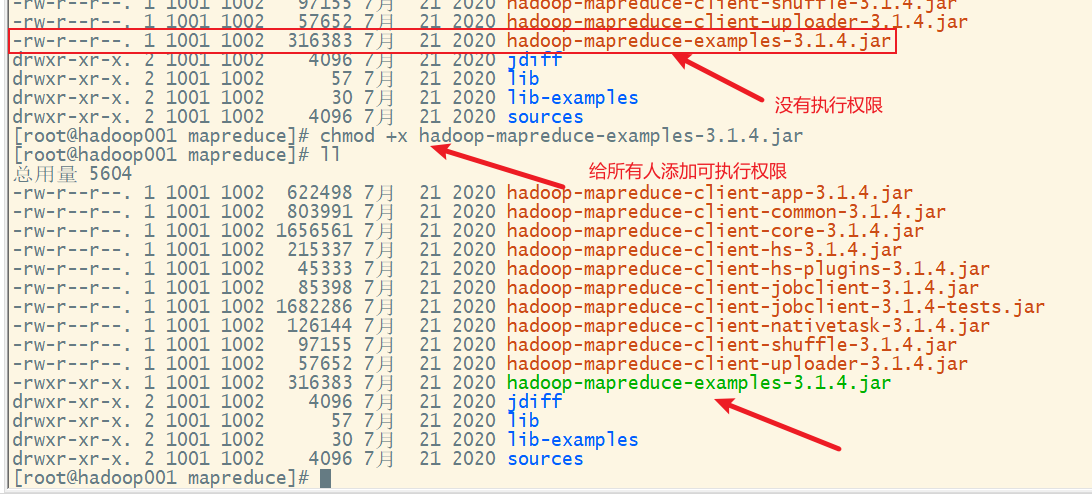

这里output文件夹不用提前创建,否则会报错。
执行出现错误提示:
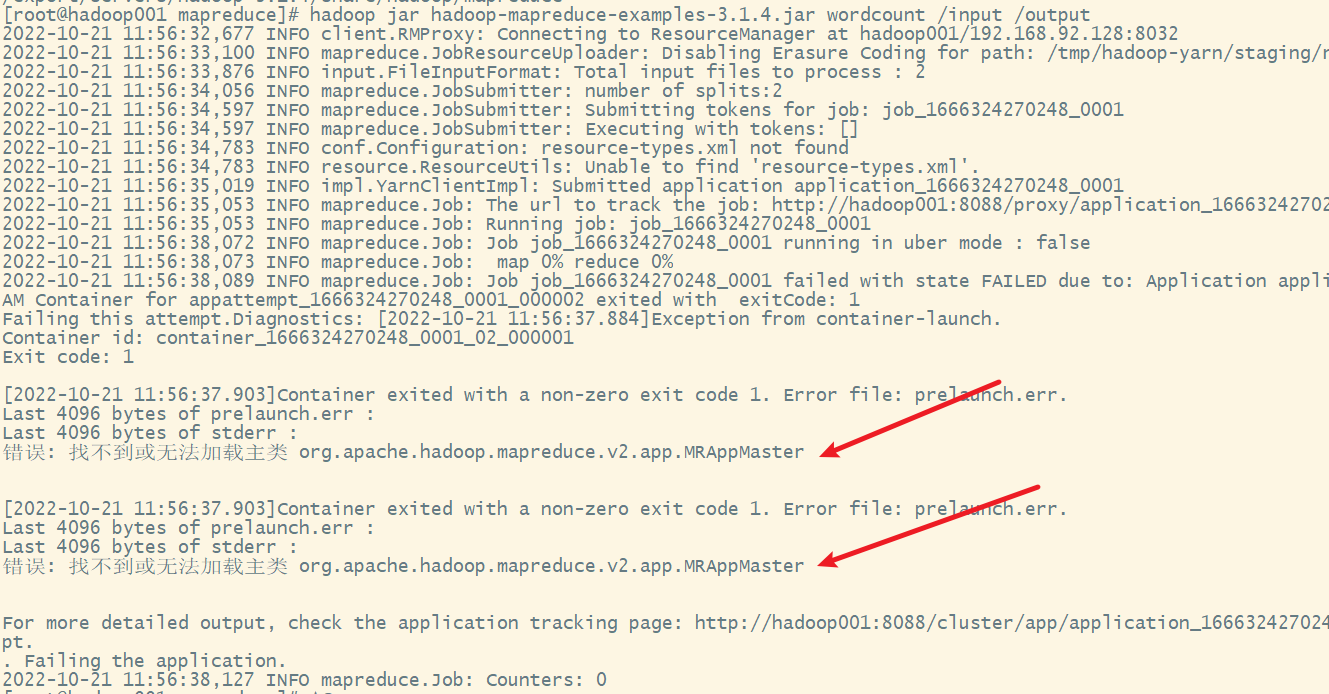
4) 解决配置错误,修改mapred-site.xml配置文件
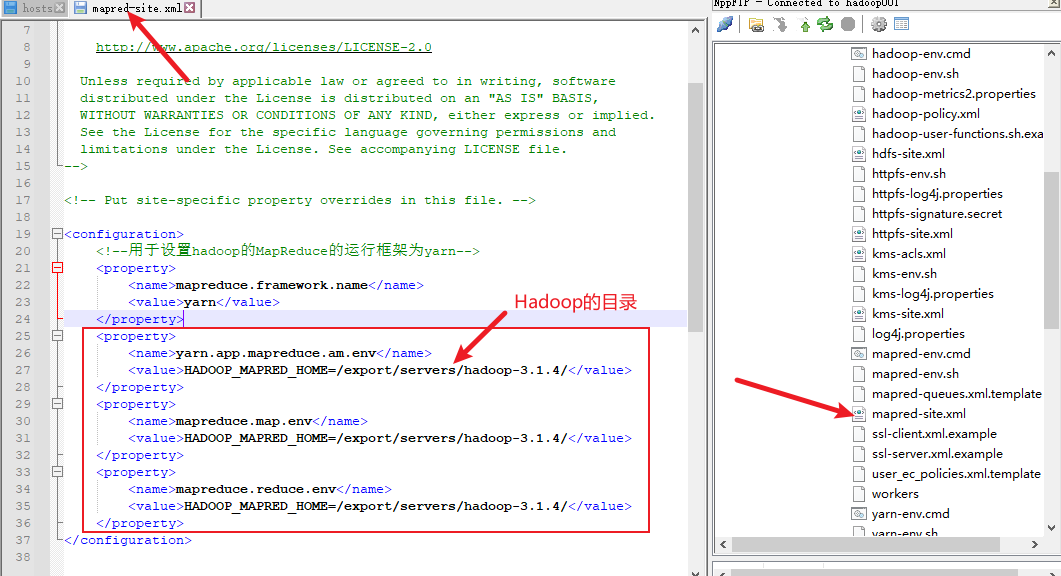
分发到其他主机

5) 关闭hadoop,再重启
6) 重新执行单词计数的mapreduce程序
若目录下存在 output 文件夹需要进行删除
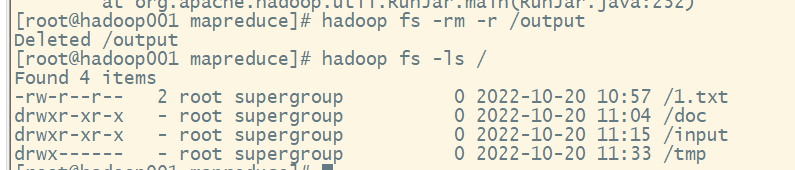
重新执行命令
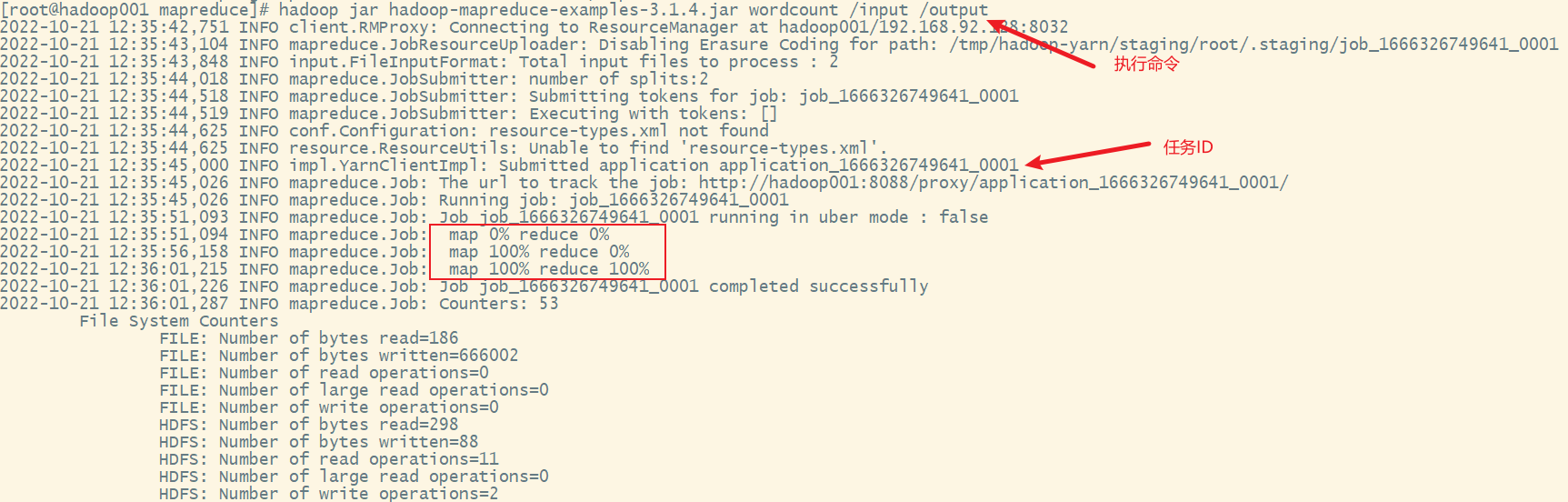
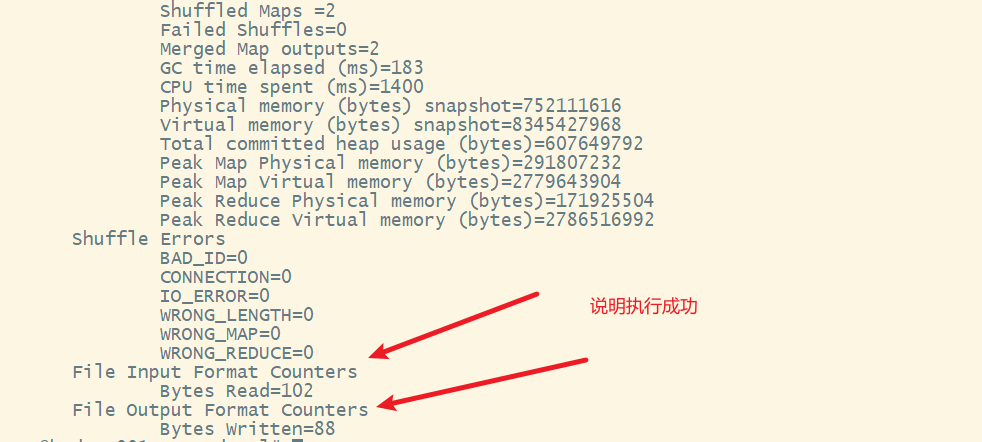
查看yarn的webui
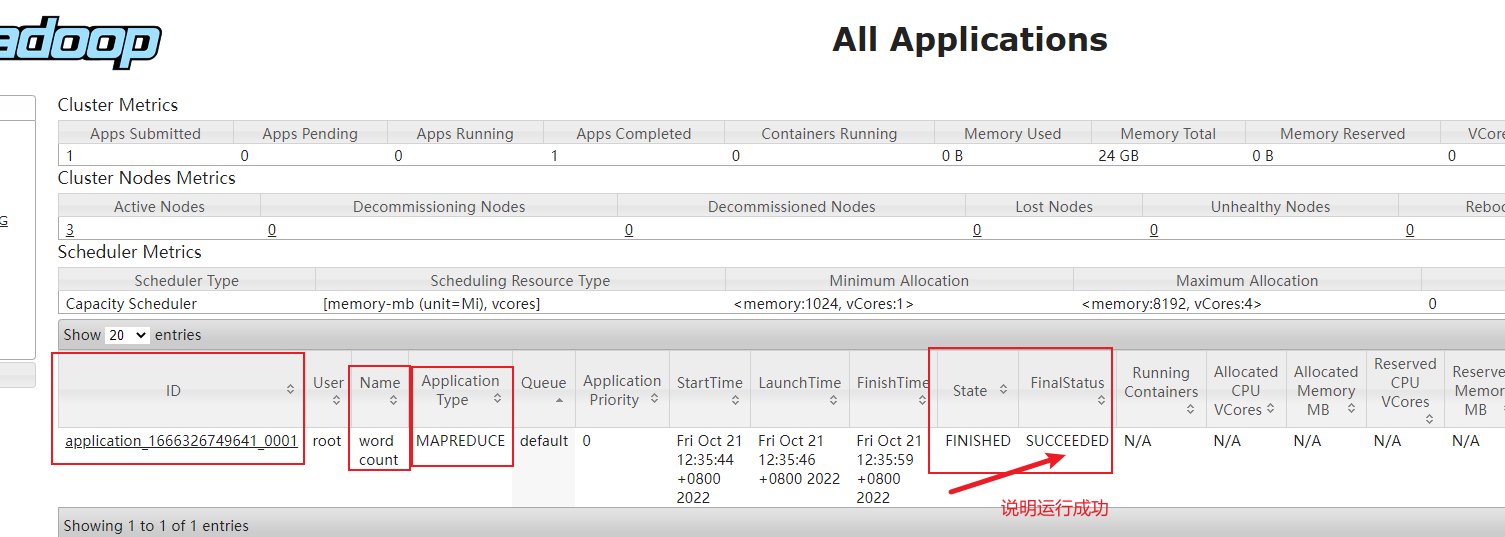
7) 查看结果
hdfs的webui
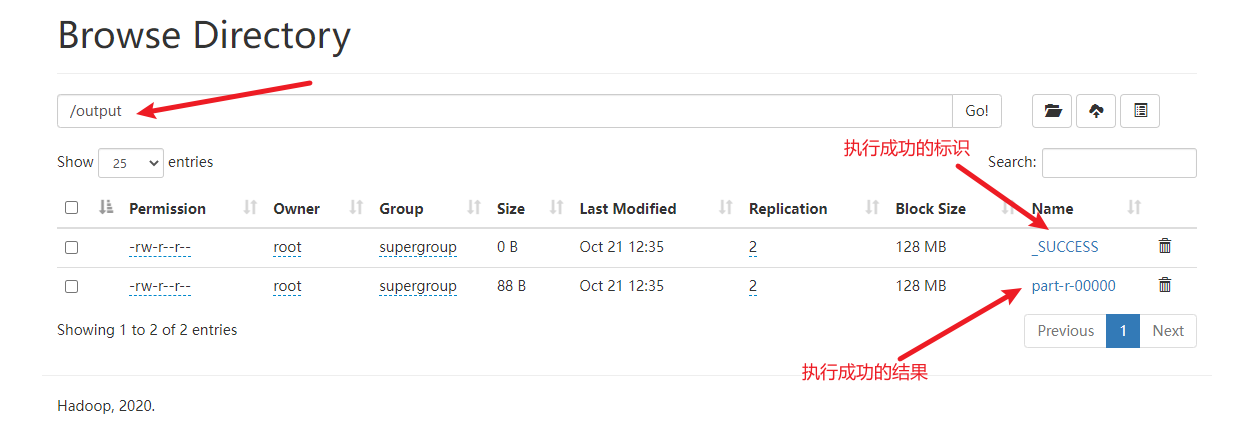
下载结果后查看
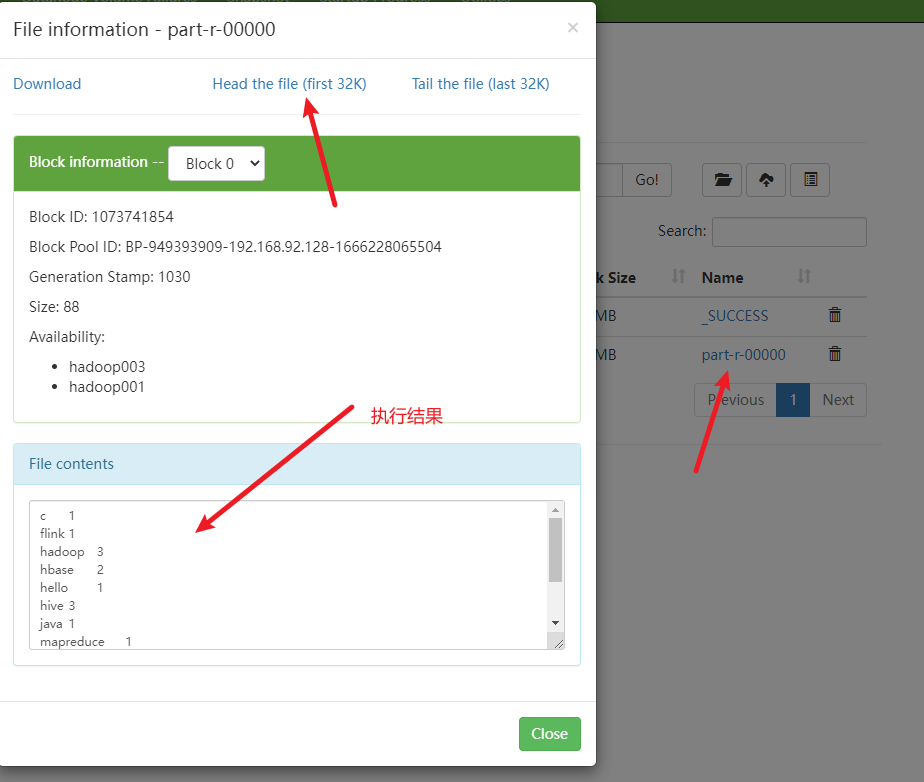
下载结果后查看
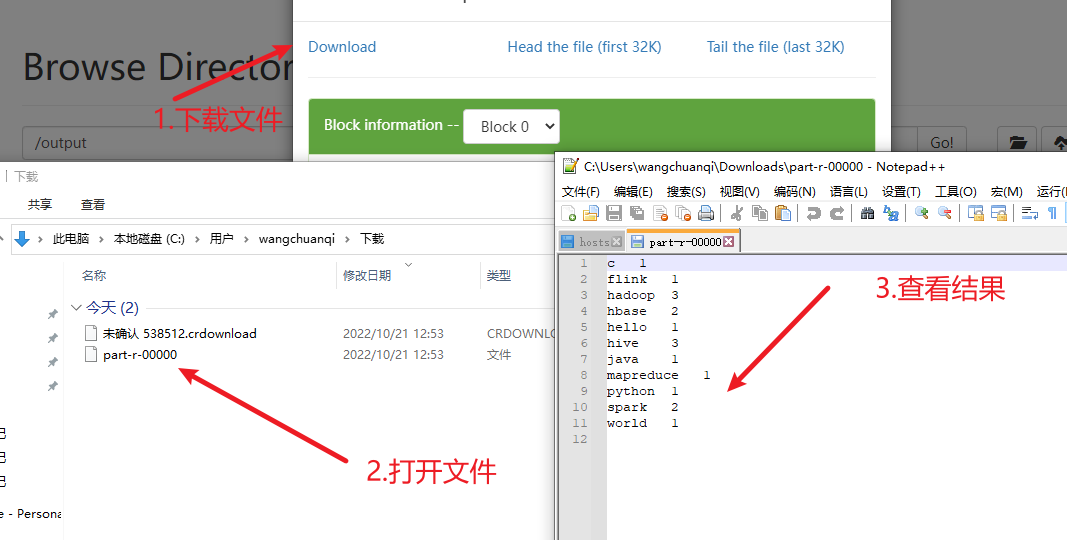
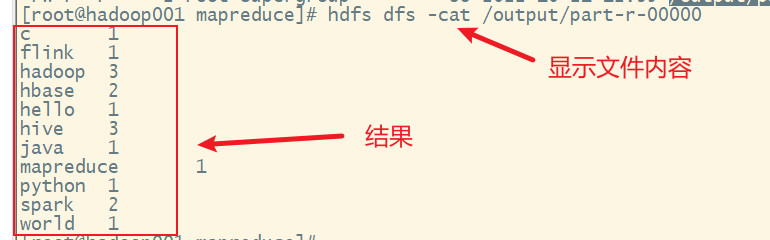
也可以通过命令行查看结果


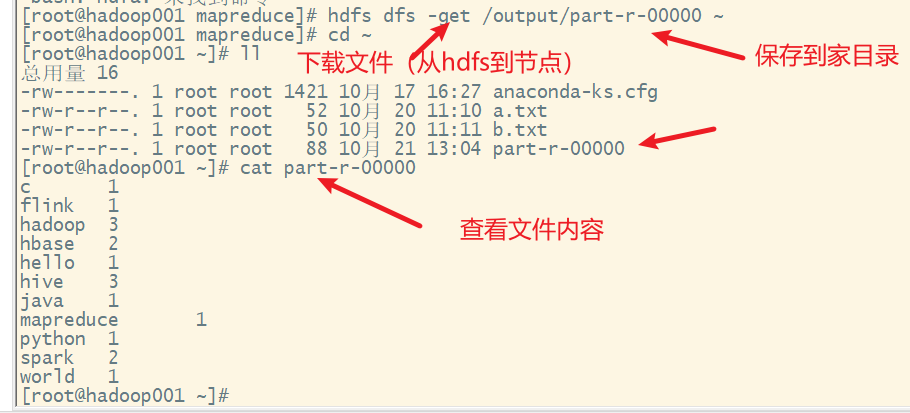
也可以下载下来查看
4. mapreduce的计数圆周率的测试
计算圆周率也是在跟单词计数在同一个jar包中
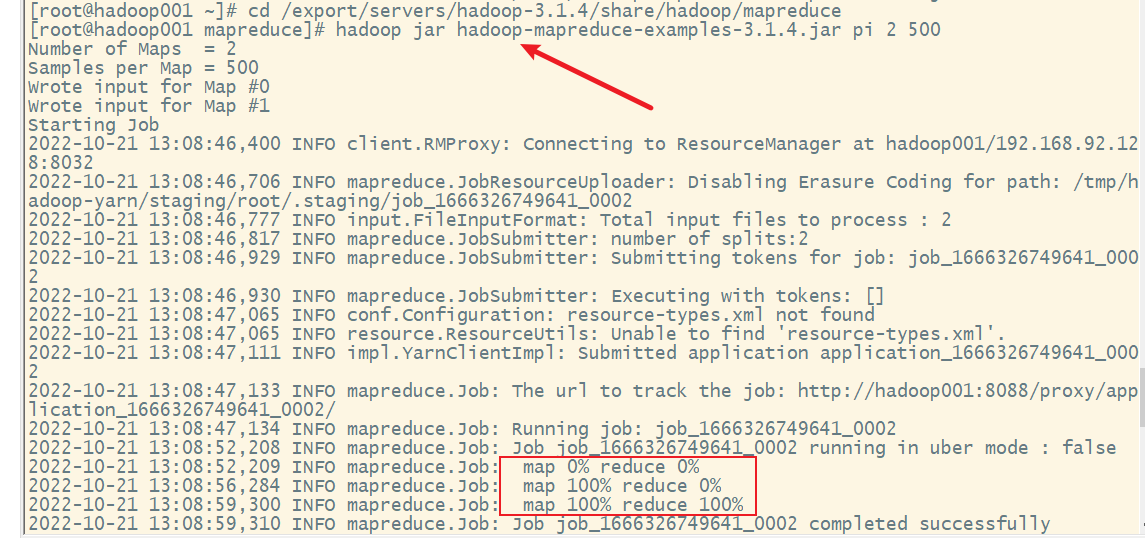
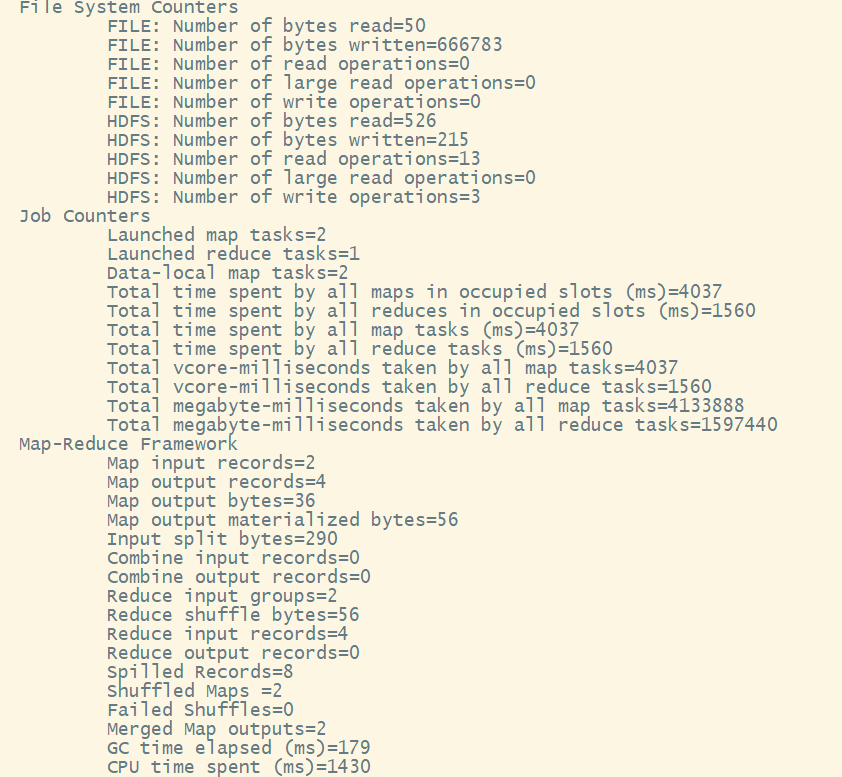
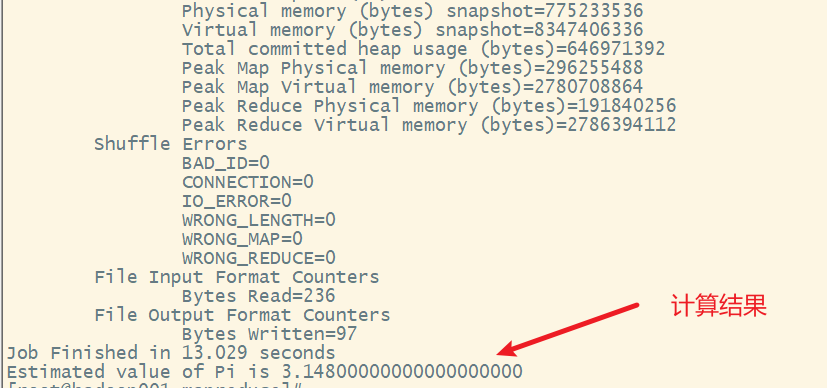
通过这个案例可以看出,圆周率的精度很低,mapreduce不善于数据计算,而在于数据的分析
5.问题解决
若出现内存溢出问题:
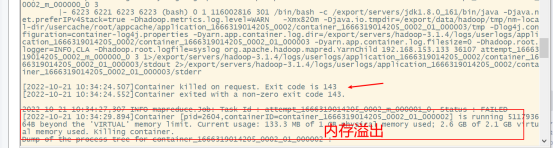
需要修改yarn-site.xml文件
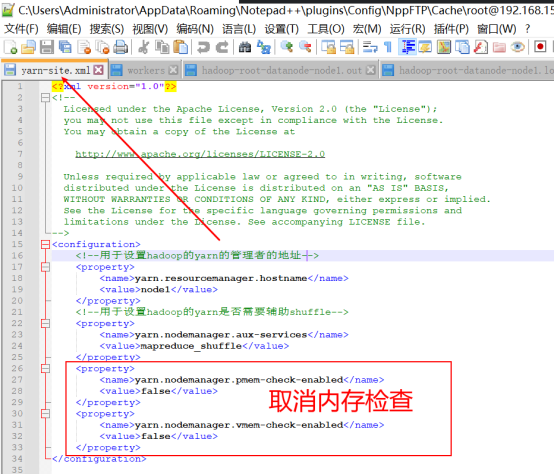
修改完成后,分发到其他节点。