笔记二
- 流程控制
- if条件语句
- for循环语句
- while循环语句
- break 和continue
- python 函数定义与调用
- 函数与调用函数的脚本分离
- 脚本模板
- 函数参数
- 匿名参数
- 变量作用域
- 全局变量与局部变量
- python面向对象
- 类的创建
- 实例的创建
- 属性、方法的访问
- 属性的添加、删除和修改
- 属性的访问
- python内置类属性
流程控制
if条件语句
if 条件1
语句1
elif 条件2
语句2
else:
语句3
注意:
1.所有程序体用了缩进的方式。
2.python对于缩进十分严格
3.elif关键字、else后会跟一个冒号 :
# region 条件判断
print("条件判断:")
age = 5
if age >= 18:
print('Your age is: ', age)# 缩进尽量采用 tap缩进
print('adult')
elif age >= 6:
print('Your age is: ', age)
print('teenager')
else:# 别忘记有一个:
print('Your age is: ', age)
print('kid')
s = input('Birth year: ')#此时,S是一个字符串
birth_year = int(s)#这里涉及了强制类型转换
if birth_year < 2000:
print("00前")
else:
print("00后")
#endregion
for循环语句
与while比较起来,特点是知道循环多少次。当然了while我们也有办法知道,只不过需要再设置变量罢了。
for 循环变量 in 循环对象 : #注意这里有一个冒号
语句1 # 注意缩进
else:#一般情况下用不到else:
语句2
# region for循环
#一般情况下用不到else:
print("for循环:")
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name)#name是循环变量 names是循环对象,有一个冒号 : 有一个缩进。
#对比下面缩进部分,运行结果的区别
sum = 0
for x in [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]:
sum = sum + x
print(sum)
sum = 0
for x in [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]:
sum = sum + x
print(sum)
#当循环次数很多的时候,可以使用range函数
print(range(101))#0~100
sum = 0
for x in range(101):
sum = sum + x
print(sum)
# endregion
while循环语句
while 条件
语句1
else:
语句2
注意:while需要两点:
1.进的来
2.出的去
这里是是一个while-do循环,还有一些语言还有do-while循环,注意区别。
# region while循环
print("while循环:")
sum = 0
n = 99 # 保证进的来
while n > 0:
sum = sum + n
n = n - 2 #保证出的去
print(sum)
# endregion
break 和continue
1.break语句用在while和for循环中,break语句用来终
止循环语句,即循环条件没有False条件或者序列还没被完全递归完,也会停止执行循环语句。
2.continue语句用在while和for循环中,continue 语句
用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
3.continue语句跳出本次循环,而break跳出整个循环。
这里break 和continue其实和C、C++、C#、IDL等等语言类似都是一样的作用。
# region break
print("break: ")
n = 1
while n <= 100:
if n > 10: # 当n = 11时,条件满足,执行break语句
break # break语句会结束当前循环
print(n)
n = n + 1
print('END')
# endregion
# region continue
print("continue: ")
n = 0
while n < 10:
n = n + 1
if n % 2 == 0: # n除以2,余数是0,即如果n是偶数,执行continue语句
continue # continue语句会直接继续下一轮循环,后续的print()语句不会执行
print(n)# 注意看缩进,在while循环体内部
# endregion
python 函数定义与调用
1.函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
2.函数能提高应用的模块性,和代码的重复利用率。
3.Python提供了许多内建函数,比如print()。也可以自己创建函数,这被叫做用户自定义函数。
4.**函数代码块以def关键词开头**,后接函数标识符名称和圆括号()。
5.任何**传入参数和自变量**必须放在**圆括号**中
间。**圆括号之间可以用于定义参数**。
6.函数内容**以冒号起始,并且缩进**。
7.**return[表达式]**结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回None。
有时候拿到别人的代码,运行有问题,需要区别是否是主文件。其中,函数文件是不能单独运行的。
def functionNameHere (parameters):
#your code here
def是关键字,表明后面是一个函数
functionNameHere是函数名
parameters是参数
注意也是以缩进形式缩进进去的,且有一个:不要遗忘。有时候会用到return 返回一个值。
print("函数:")
def my_abs(x):
if not isinstance(x, (int, float)):#isinstance判断是否为整型或者浮点型
raise TypeError('bad operand type')#若不是整型或者浮点型,则运行该代码,返回一个错误信息
if x >= 0:
return x
else:
return -x
print(my_abs(-99))#调用函数的脚本
#print(my_abs('A'))#调用函数的脚本,因为不是整型或者浮点型,所以返回错误信息
此时,我们思考一个问题,上述代码是函数与调用函数的脚本是在一个程序内的。这样它一定是会识别的。那如何将函数与脚本分离开呢?这样别人也可以调用我们的函数。
函数与调用函数的脚本分离
①第一步,在main.py处new一个新的python脚本
②第二步,粘贴我们的函数
③第三步,学会调用
下图为函数文件:
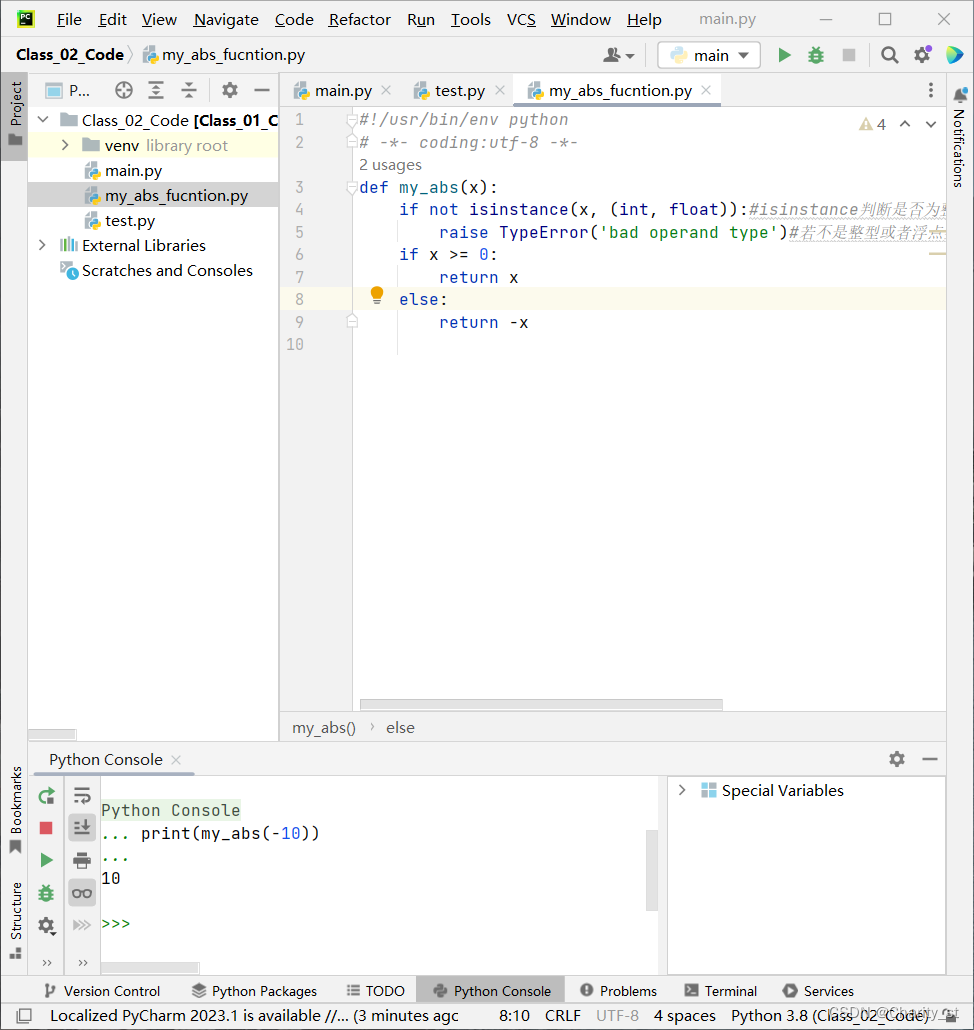
#!/usr/bin/env python
# -*- coding:utf-8 -*-
def my_abs(x):
if not isinstance(x, (int, float)):#isinstance判断是否为整型或者浮点型
raise TypeError('bad operand type')#若不是整型或者浮点型,则运行该代码,返回一个错误信息
if x >= 0:
return x
else:
return -x
新建了一个脚本,调用我们写好的函数文件。
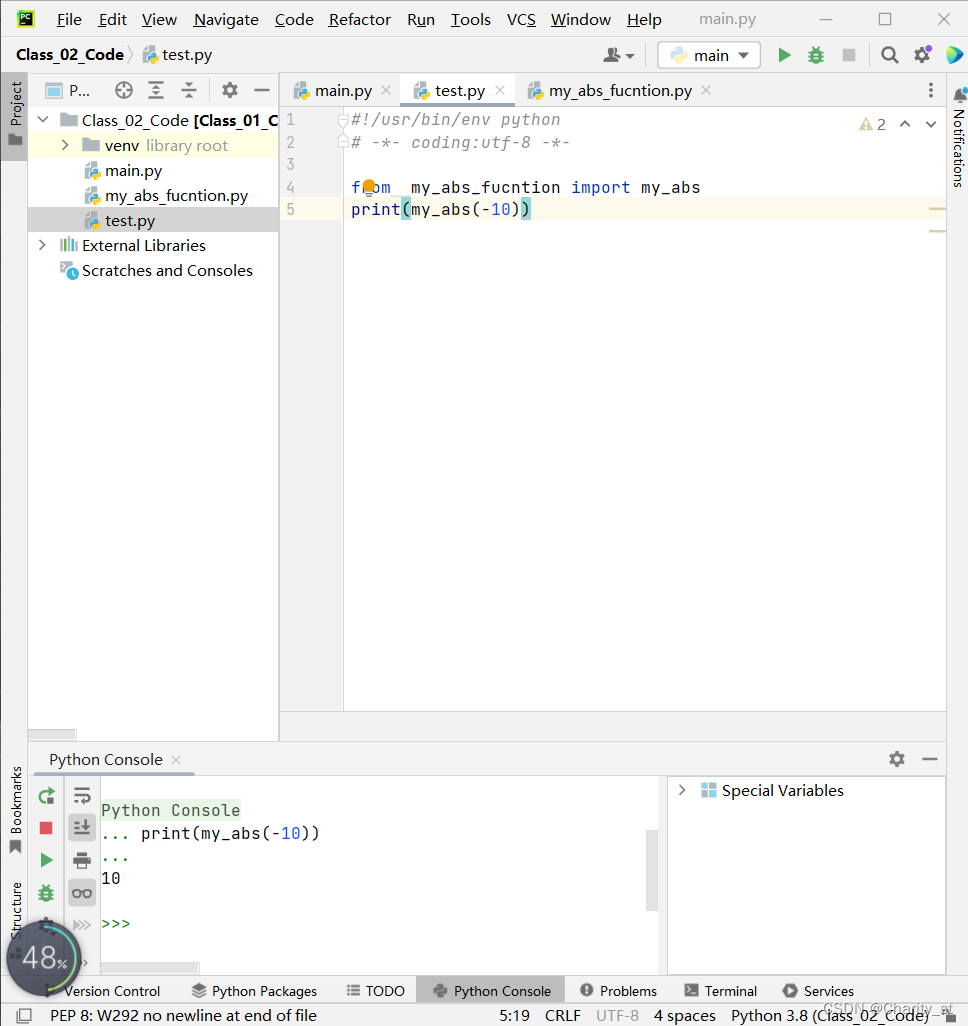
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from my_abs_fucntion import my_abs
print(my_abs(-10))
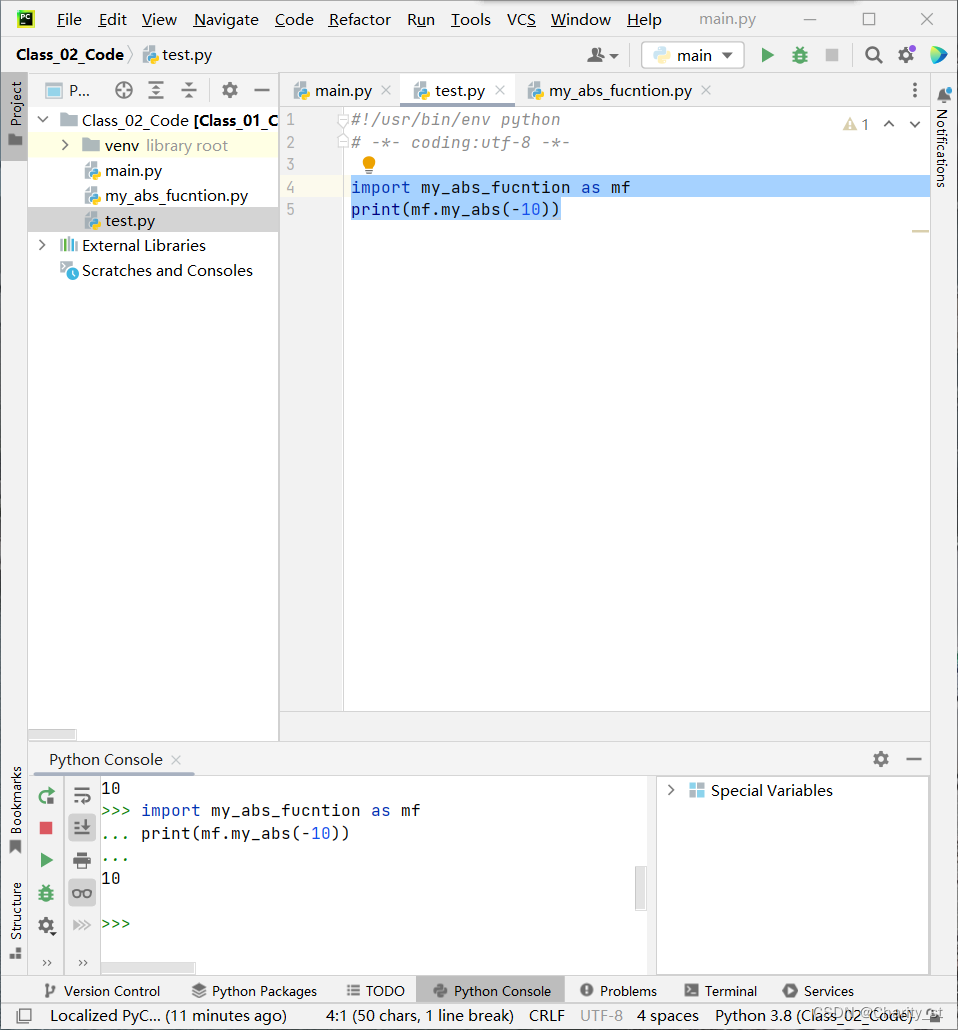
也可以写为:
import my_abs_fucntion as mf
print(mf.my_abs(-10))
脚本模板
此时可以发现,新建的函数文件以及新建的调用函数文件的脚本,开头其实都是一样的,那么我们有什么办法来简化流程呢?
于是我们可以在pycharm里进行python脚本模板的设置,首先在菜单栏的file下面找到settings。
其次,我们选择如下:
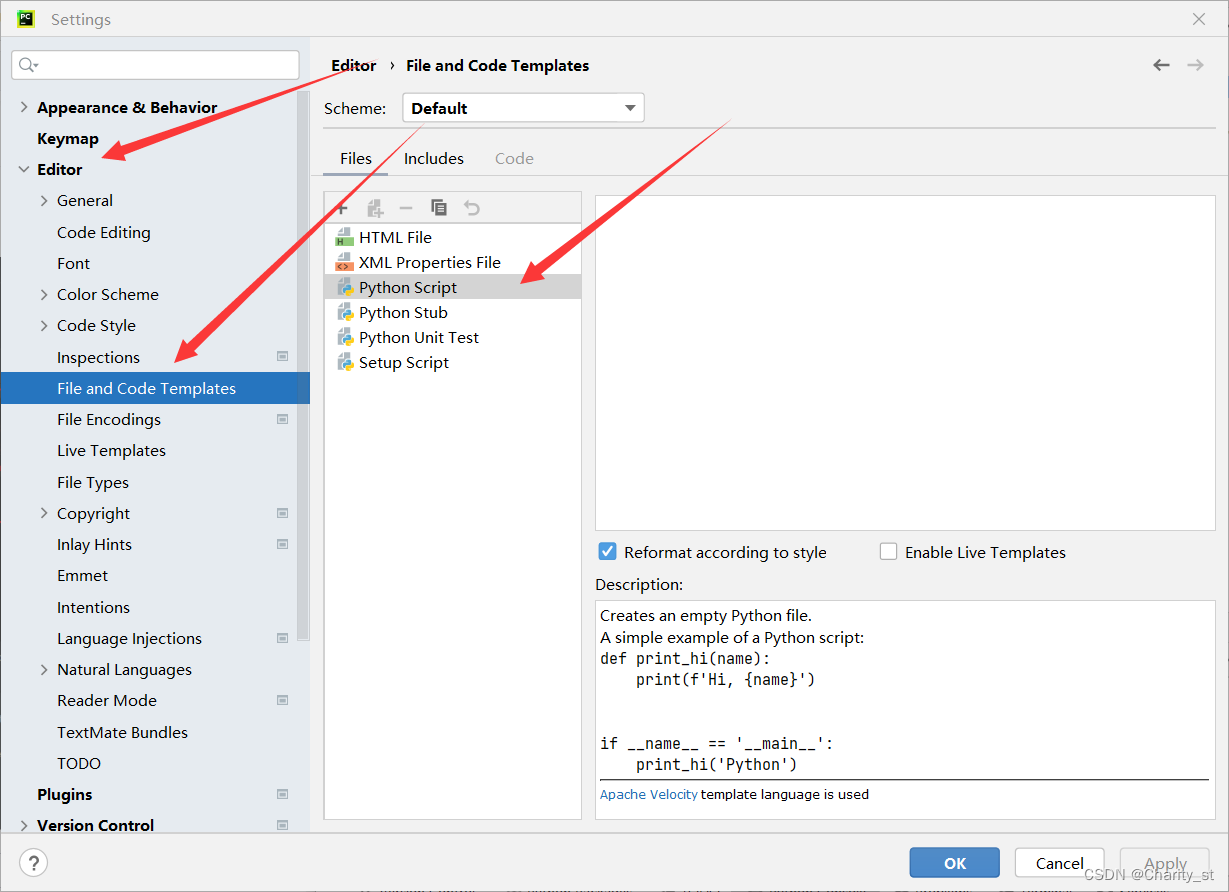
然后便可在右边空白处进行编写模板了。
我的模板为:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author : SunTong0116@163.com
# Time: ${DATE} ${TIME} ${YEAR}
# Project : ${PROJECT_NAME}
具体模板编写可以参考下文的介绍:
https://blog.csdn.net/buside/article/details/121230733?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168154172016800180635343%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=168154172016800180635343&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v31_ecpm-1-121230733-null-null.142v83insert_down38,239v2insert_chatgpt&utm_term=pycharm%E7%9A%84%E8%84%9A%E6%9C%AC%E6%A8%A1%E6%9D%BF%E8%AE%BE%E7%BD%AE&spm=1018.2226.3001.4187
函数部分:
# region 函数
total = 0 #全局变量
# 函数作用说明或者应用说明
def sum (arg1,agr2): #注意这里有一个冒号 :
#返回2个参数的和
print(arg1, agr2)
total = arg1 + agr2 #这里的total 是局部变量
print('函数内部的局部变量是',total)
return total
#调用sum函数
sum (10,20)
print('函数外是全局变量',total)
print("函数:")
def my_abs(x):
if not isinstance(x, (int, float)):#isinstance判断是否为整型或者浮点型
raise TypeError('bad operand type')#若不是整型或者浮点型,则运行该代码,返回一个错误信息
if x >= 0:
return x
else:
return -x
print(my_abs(-99))#调用函数的脚本
#print(my_abs('A'))#调用函数的脚本,因为不是整型或者浮点型,所以返回错误信息
# 返回多个值
def move(x, y, step, angle=0):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny # 返回多个值
x, y = move(100, 100, 60, math.pi / 6)# 返回多个值,则需要多个变量来接收返回的值
print(x, y)
r = move(100, 100, 60, math.pi / 6)
print(r) # 本质上返回值是个tuple
# 多个输入参数
def power(x, n=2):#n的缺省值(默认值)是2
s = 1
while n > 0:
n = n - 1
s = s * x
return s
print(power(5))
print(power(5, 2))
# 可变参数
def calc(numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
print(calc([1, 2, 3])) # 先把输入参数组装成一个list或tuple
print(calc((1, 3, 5, 7)))
def calc(*numbers):#前面加一个*表示是一个可变的参数
sum = 0
for n in numbers:
sum = sum + n * n
return sum
print(calc(1, 2, 3))
print(calc(1, 3, 5, 7))
nums = [1, 2, 3]
print(calc(*nums))
# 关键字参数
def person(name, age, **kw):#两个**表示支持关键字定义改参数,前面的name和age是必要的参数是必须有要提供的
print('name:', name, 'age:', age, 'other:', kw)
person('Michael', 30)
person('Bob', 35, city='Beijing')#带关键字的也可以去调用
person('Adam', 45, gender='M', job='Engineer')
extra = {'city': 'Beijing', 'job': 'Engineer'}#封装成字典
person('Jack', 24, **extra)
# endregion
注意:如果提示没有导进来例如math等包,则导入即可,导入的方法也很简单,即先运行import …再运行我们的代码即可。
例如:
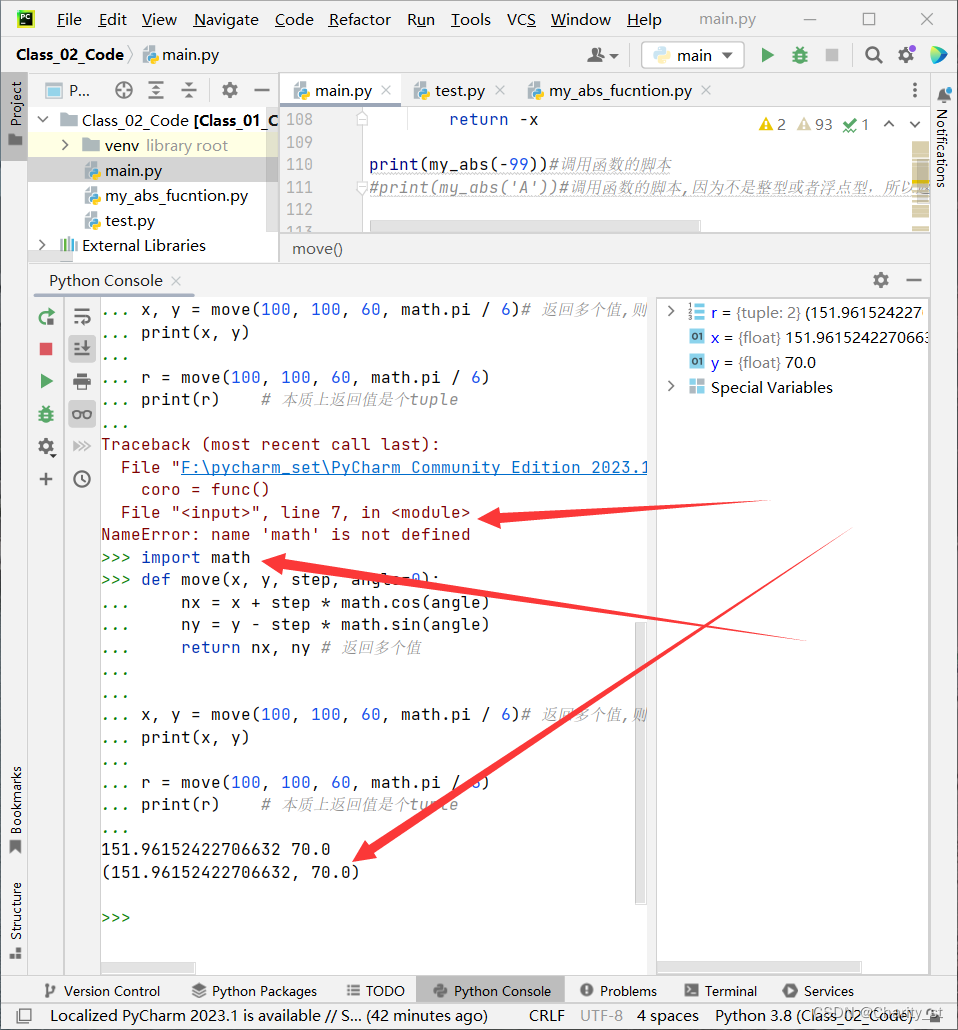
其中,这里会发现,r是一个变量但接收了两个参数的返回值,这里r自动为tuple类型了,避免有的返回值遗失。这里可以与matlab语言作对比,matlab只会将第一个进行存储。且这里的r是一个元组而不是列表,因为返回回来的值不能再修改了,自动为这个数据类型是十分合理的。
函数参数
参与计算的参数,
1.必备参数:须以正确的顺序传入函数,调用时的数量必须和声明时的一样。(不给不行)
2.关键字参数:函数调用使在这里插入代码片用关键字参数来确定传入的参数值,使用关键字参数允许函数调用时参数的顺序与声明时不一致。
3.默认参数:调用函数时,默认参数的值如果没有传入,则被认为是默认值。
4.不定长参数:函数能处理比当初声明时更多的参数,这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。加了星号(*)的变量名会存放所有未命名的变量参数。
匿名参数
1.python使用 lambda来创建匿名函数。
2.lambda只是一个表达式,函数体比def简单很多。
3.lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
4. lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
5.虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
lambda [arg1 [,arg2,.....argn]]:expression
关键字:lamda
参数:arg1、arg2…
表达式:expression
# region 匿名函数
sum_new = lambda arg1, arg2: arg1 + arg2
print("相加后的值为 : ", sum_new(10, 20))
print("相加后的值为 : ", sum_new(20, 20))
# endregion
变量作用域
1.全局变量
2.局部变量
全局变量与局部变量
1.定义在函数内部的变量拥有一个局部作用
域,定义在函数外的拥有全局作用域。
2.局部变量只能在其被声明的函数内部访问。
3.全局变量可以在整个程序范围内访问。
total = 0 #全局变量
# 函数作用说明或者应用说明
def sum (arg1,agr2): #注意这里有一个冒号 :
#返回2个参数的和
print(arg1, agr2)
total = arg1 + agr2 #这里的total 是局部变量
print('函数内部的局部变量是',total)
return total
#调用sum函数
sum (10,20)
print('函数外是全局变量',total)
输出结果为:
10 20
函数内部的局部变量是 30
函数外是全局变量 0
python面向对象
1.类(Class):用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
2.类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
3.数据成员:类变量或者实例变量,用于处理类及其实例对象的相关的数据。
4.方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
5.局部变量:定义在方法中的变量,只作用于当前实例的类。
6.实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但是在类的其他成员方法之外声明的。
7.继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。
例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
8.实例化:创建一个类的实例,类的具体对象。
9.方法:类中定义的函数。
10.对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量〉和方法。
类的创建
1.使用class语句来创建一个新类,class之后为类的名称并以冒号结尾。
2.类的帮助信息可以通过ClassName._ doc_
查看。
3.class suite由类成员,方法,数据属性组成。
class className:
'类的帮助信息'#类文档字符串
class_suite #类体
4.empCount变量是一个类变量,它的值将在这个类的所有实例之间共享。你可以在内部类或外部类使用Employee.empCount访问。
5.第一种方法 _init_() 方法是一种特殊的方法,被称为**类的构造函数或初始化方法**,当创建了这个类的实例时就会调用该方法
6.self 代表类的实例,self在定义类的方法时是必
须有的,虽然在调用时不必传入相应的参数。
7.类的方法与普通的函数只有一个特别的区别,它们必须有一个额外的第一个参数名称,按照惯例它的名称是self。
实例的创建
1.实例化类其他编程语言中一般用**关键字new**,但是在 Python中并没有这个关键字,类的实例化类似函数调用方式。
2.以下使用类的名称Employee来实例化,并
通过_init__方法接收参数。
属性、方法的访问
使用点号.来访问对象的属性。
属性的添加、删除和修改
属性的访问
1.getattr(obj,name[,default]):访问对象的属性。 2…hasattr(obj,name):检查是否存在一个属性。3.setattr(obj,name,value):设置一个属性。如果
属性不存在,会创建一个新属性。
4.delattr(obj, name):删除属性。
python内置类属性
1.__dict__ :类的属性(包含一个字典,由类的数据属性组成)
2.__doc__ :类的文档字符串√name_:类名
3.__module__:类定义所在的模块(类的全名
是'__main__.className',如果类位于一个导入模块mymod中,那么className.__module___等于mymod)
4.__bases__:类的所有父类构成元素(包含了一个由所有父类组成的元组>
注意:下划线是两个短的下划线而不是长的下划线。
# region 类的创建与实例化
class Employee:
'所有员工的基类'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print("Total Employee %d" % Employee.empCount)
def displayEmployee(self):
print("Name : ", self.name, ", Salary: ", self.salary)
# 创建 Employee 类的第一个对象
emp1 = Employee("Zara", 2000)
# 创建 Employee 类的第二个对象
emp2 = Employee("Manni", 5000)
emp1.displayEmployee()
emp2.displayEmployee()
print("Total Employee %d" % Employee.empCount)
# 添加、修改、删除属性
emp1.age = 7 # 添加一个 'age' 属性
print("Age: ", emp1.age)
emp1.age = 8 # 修改 'age' 属性
print("Age: ", emp1.age)
del emp1.age # 删除 'age' 属性
print("Age: ", emp1.age)
# 属性访问
hasattr(emp1, 'age') # 如果存在 'age' 属性返回 True。
getattr(emp1, 'age') # 返回 'age' 属性的值
setattr(emp1, 'age', 10) # 添加属性 'age' 值为 8
delattr(emp1, 'age') # 删除属性 'age'
# Python内置类属性调用
print("Employee.__doc__:", Employee.__doc__)
print("Employee.__name__:", Employee.__name__)
print("Employee.__module__:", Employee.__module__)
print("Employee.__bases__:", Employee.__bases__)
print("Employee.__dict__:", Employee.__dict__)
# endregion