爬虫数据的存储
- 数据存储概述
- MongDB数据库的概念
- MongDB的安装
- 使用PyMongo库存储到数据库
数据存储概述
通常,从网页爬取到的数据需要进行分析、处理或格式化,然后进行持久化存储,以备后续使用。数据存储主要有以下两种方式:
1)文件存储
文件存储时将爬虫数据以文件的形式存储到本地,对于这种中小规模的爬虫而言,可以将爬虫结果汇合到一个文件进行持久化存储。Python中的文件操作相当方便,既能将爬虫数据以二进制形式保存,又能处理成字符串后以文件形式保存,只需要改动打开文件的模式,就能以不同的形式保存数据。
2)数据库存储
对于爬取的数据种类丰富、数量庞大的大规模爬虫来说,把数据存储成一堆零散的文件就不太合适了。此时可以将这些爬虫结果存储到我们的数据库当中,不仅方便存储,也方便进一步整理。
Python中常见的数据库有以下两种:
- MySQL:一种开源的关系型数据库,使用最常用的数据库管理语言(SQL)进行数据库管理,它会将数据保存到不同的表中,不仅速度快,而且灵活性高。
- MongoDB:一个基于分布式文件存储的数据库,时当前NoSQL(非关系型数据库)中比较热门的一种,他面向集合存储,易存储对象类型的数据,具有高性能、易部署、易使用等特点。
MongDB数据库的概念
MongDB是一款由C++语言编写的,基于分布式文件存储的NoSQL数据库,具有免费操作简单、面向文档存储特点。为web应用提供可扩展的高性能数据存储解决方案。
MongoDB数据库主要的功能特征如下:
- 模式自由:可以把不同结构的文档存储在同一个数据库当中
- 面向集合的存储:适合存储JSON文件风格的形式
- 完整的索引支持:对任何属性可索引
- 复制和高可用性:支持服务器之间的数据复制,支持主-从模式及服务器之间的相互复制,复制的主要目的是提供冗余及自动故障转移
- 自动分片:支持云级别的伸缩性,自动分片功能支持水平的数据库集群,可动态地添加额外地机器
- 丰富的查询:支持丰富的查询表达方式,查询指令使用JSON形式的标记,可以轻易查询文档中内嵌的对象及数组
- 快速就地更新:查询优化器会分析查询表达式,并生成一个高效地查询计划
- 高效地传统存储方式:支持二进制数据及大型对象
MongDB的安装
MongDB的下载
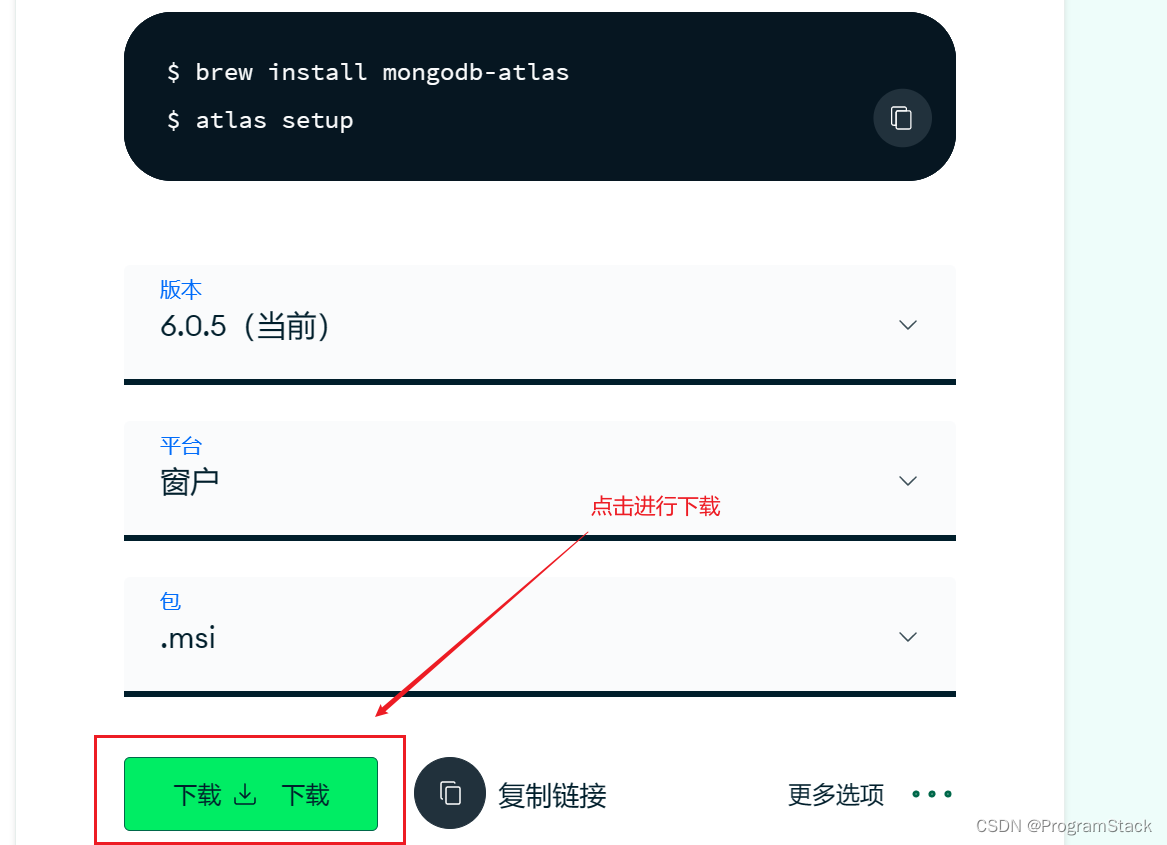
具体的安装过程比较简单,这里就不细讲了。
使用PyMongo库存储到数据库
PyMong是用于MongDB的开发工具,是Python操作MongoDB数据库的方式,由于PyMongo是第三方库,所以需要安装之后才能在Python中使用,在window环境中可直接使用pip install pymongo进行安装。
PyMongo库中主要提供了如下类与MongoDB数据库进行交互:
- MongoClient类:用于与MongoDB服务器建立连接
- DataBase类:表示MongoDB中的数据库
- Collection类:表示MongoDB中的集合
- Cursor类:表示查询方法返回的结果,用于对多行数据进行遍历
PyMongo库的基本使用流程如下:
1)创建一个MongoClient类的对象,与MongoDB服务器建立连接
2)通过MongoClient对象访问数据库(DataBase对象)
3)使用上个步骤的数据库创建一个集合 (Collection对象)
4)调用集合中提供的方法在集合中插入、删除、修改和查询文档
- 创建连接
通过MongoClient类的构造方法进行创建。
pymongo.mongo_client.MongoClient(host='localhost',port=27017,document_class=dict,tz_aware=False,connect=True,**kwargs)
其中
host:表示主机名或IP地址,默认为主机(localhost)
port:表示连接的端口号,默认27017
document_class:从此客户端查询,返回的文档默认使用此类
tz_aware:如果为True,则此MongoClient作为文档中的返回的datetime示例,将会被时区所识别
connect:默认为True,表示立即开始在后台连接到MongoDB,否则连接到第一个操作
from pymongo import *
# 这时没有传入任何参数host和port都是默认的值
client = MongoClient()
- 访问数据库
只要已经建立了与Mongo服务器的连接,就可以直接访问数据库中的内容了,他的访问方式比较简单。
可以当作属性进行访问:db = client.pymongo_test
也可以使用字典的形式访问:db = client["pymongo_test"]
如果指定的数据库已经存在,就直接访问这个数据库;如果不存在,就会自动创建一个数据库
-
创建集合
访问或创建db数据库中的student集合,通过s = db.student -
插入文档
insert_one():插入一条文档对象
insert_many():插入列表形式的多条文档对象
代码如下:
from pymongo import *
# 创建连接
client = MongoClient()
# 创建数据库或访问
db = client.pymongo_test
# 创建student集合
s = db.student
# 向集合中插入一条文档
result1 = s.insert_one({'name':'lisi','sex':'nan'})
# 向集合中插入多条文档,通过列表的形式
result2 = s.insert_many([{'name':'lisi','sex':'nan'},{'age':12}])
print('result1的结果为:',result1)
print('result2的结果为:',result2)
输出结果为:

- 查询文档
find_one():查找一条文档对象
find_many():查找多条文档对象
find():查找所有文档对象
代码如下:
from pymongo import *
# 创建连接
client = MongoClient()
# 创建数据库或访问
db = client.pymongo_test
# 创建student集合
s = db.student
# 向集合中插入一条文档
result1 = s.insert_one({'name':'lisi','sex':'nan'})
# 向集合中插入多条文档,通过列表的形式
result2 = s.insert_many([{'name':'lisi','sex':'nan'},{'age':12}])
print('result1的结果为:',result1)
print('result2的结果为:',result2)
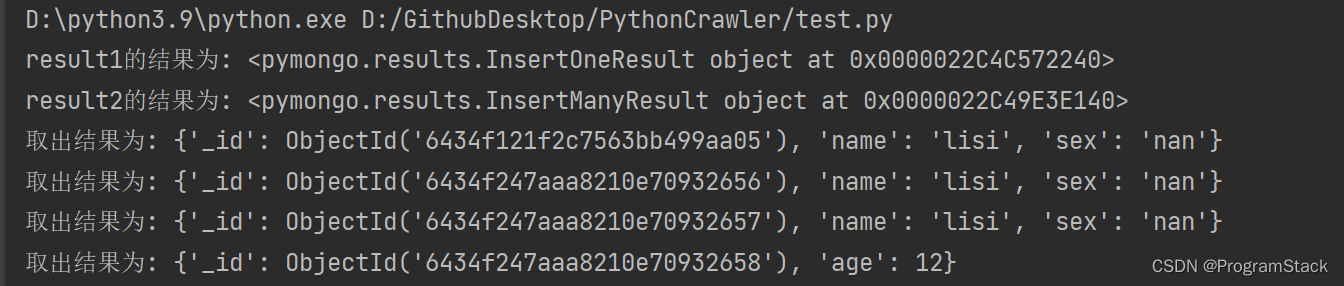
# 查询所有文档对象
result3 = s.find()
# 对返回的结果进行取出
for column in result3:
print('取出结果为:',column)
输出结果为:
- 更新文档
update_one():更新一条文档对象
update_many():更新多条文档对象
代码如下:
from pymongo import *
# 创建连接
client = MongoClient()
# 创建数据库或访问
db = client.pymongo_test
# 创建student集合
s = db.student
# 向集合中插入一条文档
result1 = s.insert_one({'name':'lisi','sex':'nan'})
# 向集合中插入多条文档,通过列表的形式
result2 = s.insert_many([{'name':'lisi','sex':'nan'},{'age':12}])
print('result1的结果为:',result1)
print('result2的结果为:',result2)
# 查询所有文档对象
result3 = s.find()
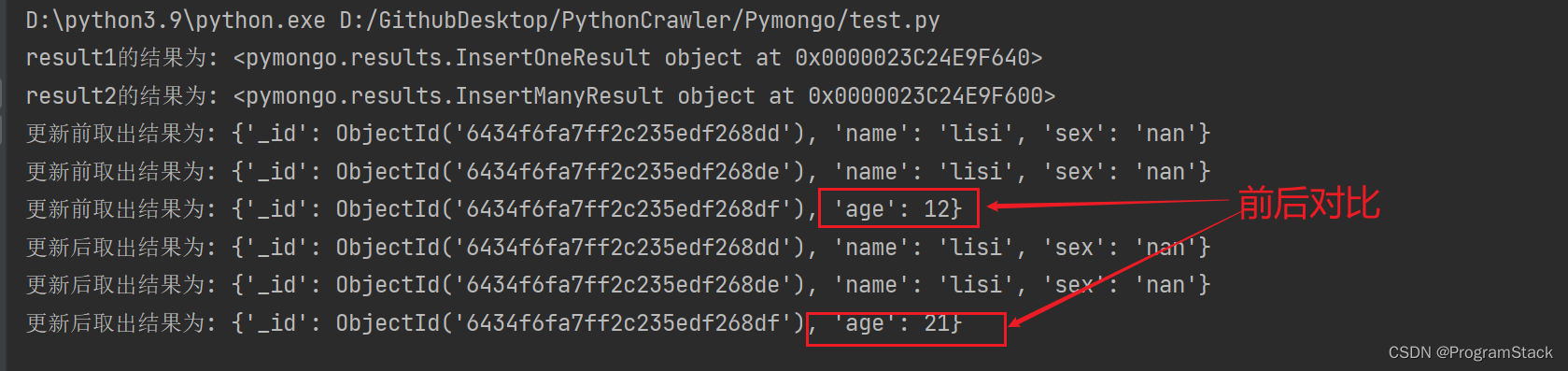
# 对跟新前返回的结果进行取出
for column1 in result3:
print('更新前取出结果为:',column1)
# 更新一条数据,多条数据一样的原理,这里就不过多的阐述了
s.update_one({'age':12},{'$set':{'age':21}})
# 查询更新后的所有文档对象
result4 = s.find()
# 对更新后的数据进行取出
for column2 in result4:
print('更新后取出结果为:',column2)
输出结果为:
- 删除文档
delete_one():删除一条文档对象
delete_many():删除所有记录
直接就s.delete_one()这里就不演示代码了,可以自己去尝试