一、初始Pandas
pandas 是数据分析三大件之一,是Python的核心分析库,它提供了快捷、灵活、明确的数据结构,它能够简单、直观、快速的处理各种类型的数据结构。
pandas 支持的数据结构如下:
- SQL 或Excel 类似的数据
- 有序或无序的时间序列数据。
- 带行列标签的矩阵数据
- 任意其他形式的观测、统计数据集。
pandas 提供主要的数据结构Series(一维数组结构)与DataFrame(二维数组结构),可以处理金融、统计、社会科学、工程等领域。
二、数据分析的标准环境Anaconda
Anaconda 是适合数据分析的Python开发环境, 它是一个开源的Python发行版本,其中包含了conda(包管理/环境管理)、Python等180多个科学包及其依赖项。
Windows 安装Anaconda 详解
三、Pandas 快速入门
Pandas 轻松导入 Excel 数据
学生成绩表:
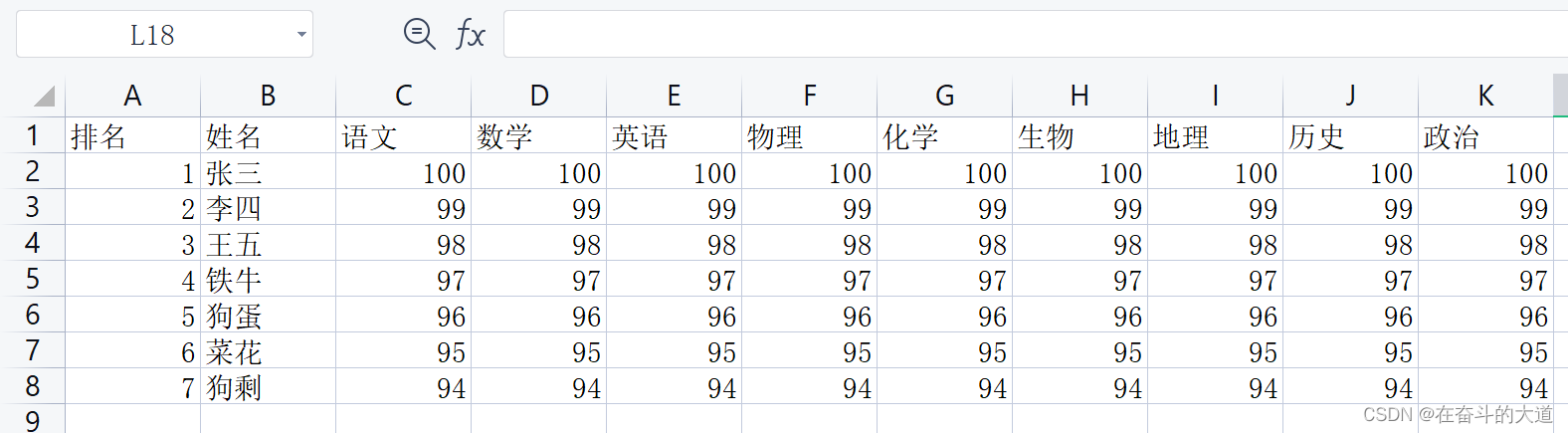
Python 功能代码:
import pandas as pd #导入pandas 模块
# 读取excel 文件内容
df = pd.read_excel("excel/data.xlsx")
# 输出前5条记录
print(df.head())
效果展示:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-one.py
排名 姓名 语文 数学 英语 物理 化学 生物 地理 历史 政治
0 1 张三 100 100 100 100 100 100 100 100 100
1 2 李四 99 99 99 99 99 99 99 99 99
2 3 王五 98 98 98 98 98 98 98 98 98
3 4 铁牛 97 97 97 97 97 97 97 97 97
4 5 狗蛋 96 96 96 96 96 96 96 96 96问题:Pandas 输出结果,出现列不对齐的情况。
通过将display.unicode.east_asian_width 设置为true,使列名对其。
import pandas as pd #导入pandas 模块
#解决输出列名不对齐的问题
pd.set_option("display.unicode.east_asian_width", True)
# 读取excel 文件内容
df = pd.read_excel("excel/data.xlsx")
# 输出前5条记录
print(df.head())

通过将 display.max_rows 和display.max_columns 修改默认输出最大行数和列数
Pandas Series快速入门
Series 是Pandas 库中的一种数据结构,类似一维数组,由一组数据值(value)和一组标签组成,其中标签与数据值之间是一一对应的关系。
Series 可以保存任何数据类型,比如整数、字符串、浮点数、Python 对象等,它的标签默认为整数,从 0 开始依次递增。Series 的结构图,如下所示:

通过不同颜色标签我们可以更加直观地查看数据所在和对应的索引位置。
Series 对象创建
创建Series 对象,主要使用Pandas 的Series类。
基本语法:
import pandas as pd
s = pd.Series(data, index, dtype, name, copy, fastpath)参数说明:
| 参数名 | 描述 |
| data | 输入的数据,可以是列表、常量、ndarray 数组等。 |
| index | 索引值必须是惟一的,如果没有传递索引,则默认为 np.arrange(n)。 |
| dtype | dtype表示数据类型,如果没有提供,则会自动判断得出。 |
| name | Series 对象名称 |
| copy | 表示对 data 进行拷贝,默认为 False。 |
| fastpath | 校验Series 对象名称,默认为False。 |
1) 创建一个空Series对象
使用以下方法可以创建一个空的 Series 对象,如下所示:
import pandas as pd
# 创建一个空Series 对象
s = pd.Series()
print(s)
输出结果:
e:\py_workspace\conda-demo\pandas-series-one.py:3: FutureWarning: The default dtype for empty Series will be 'object' instead of 'float64' in a future version. Specify a dtype explicitly to silence this warning.
s = pd.Series()
Series([], dtype: float64)2) ndarray创建Series对象
ndarray 是 NumPy 中的数组类型,当 data 是 ndarry 时,传递的索引必须具有与数组相同的长度。假如没有给 index 参数传参,在默认情况下,索引值将使用是 range(n) 生成,其中 n 代表数组长度,如下所示:
[0,1,2,3…. range(len(array))-1]
使用默认索引,创建 Series 序列对象:
# 创建一个ndarray 数组类型的Series 对象
data = np.array([100, 99, 98, 97])
snp = pd.Series(data)
print(snp)输出结果:
0 100
1 99
2 98
3 97
dtype: int323) 手动设置Series对象索引
创建Series对象会自动生成索引,索引默认从 0 开始分配 ,其索引范围为 0 到len(data)-1。这种设置方式被称为“隐式索引”。
下面通过手动设置索引,也被称为"显式索引"
# 创建一个ndarray 数组类型的Series 对象, 并且手动设置索引
sindex = pd.Series(data, index=['a', 'b', 'c', 'd'])
print(sindex)输出结果:
a 100
b 99
c 98
d 97
dtype: int324) dict创建Series对象
您可以把 dict 作为输入数据。如果没有传入索引时会按照字典的键来构造索引;反之,当传递了索引时需要将索引标签与字典中的值一一对应。
# 创建一个dict 字典类型的Series 对象
dt ={ "a" : 100, "b" : 120, "c" : 150}
sdt = pd.Series(dt)
print(sdt)输出结果:
a 100
b 120
c 150
dtype: int64知识拓展:如果为Series 对象的 data 属性类型为dict(字典) 传递了index (索引) 会产生什么样的效果?
# 创建一个dict 字典类型的Series 对象, 并且设置index
sdtindex = pd.Series(dt, index=["a", "1", "2"])
print(sdtindex)输出结果:
a 100.0
1 NaN
2 NaN
dtype: float64结论:当传递的索引值无法找到与其对应的值时,使用 NaN(非数字)填充。
5) 标量创建Series对象
如果 data 是标量值,则必须提供索引。
# 创建标量的Series 对象,并且必须设置index
sscalar = pd.Series(10, index=[1, 2, 3, 4])
print(sscalar)输出结果:
1 10
2 10
3 10
4 10
dtype: int64标量值按照 index 的数量进行重复,并与其一一对应。
访问Series数据
在上一章节中,我们总结了创建 Series 对象的多种方式,本章节主要讲解:如何访问 Series 序列中的元素?
主要分为两种方式:位置索引和索引标签。
1) 位置索引/标签索引访问
Series 位置索引是从0 开始,[0]是Series 的第一个数;[1]是Series 的第二个数,依次类推。
import pandas as pd
import numpy as np
# 基于ndarray 创建一个Series 对象
data = np.array([98, 100, 102, 110, 148])
s = pd.Series(data, index = ["1", "2", "3", "4", "5"])
print(s)
# 通过位置索引访问数据
print(s[0])
# 通过标签索引访问数据
print(s['1'])
输出结果:
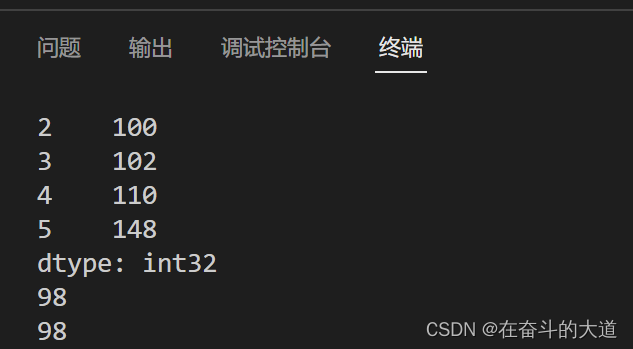
2) 切片位置索引/标签索引
通过Series对象用位置索引做切片,和list 列表用法一样。
import pandas as pd
import numpy as np
# 基于ndarray 创建一个Series 对象
data = np.array([98, 100, 102, 110, 148])
s = pd.Series(data, index = ["1", "2", "3", "4", "5"])
print(s)
# 通过位置索引访问数据
print(s[0])
# 通过标签索引访问数据
print(s['1'])
# 通过切片位置索引访问数据
print(s[0:4])
# 通过切片标签索引访问数据
print(s['1':'5'])输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/panfas-series-two.py
1 98
2 100
3 102
4 110
5 148
dtype: int32
98
98
1 98
2 100
3 102
4 110
dtype: int32
1 98
2 100
3 102
4 110
5 148
dtype: int32Series常用属性
本章节我们将介绍 Series 的常用属性和方法。在下表列出了 Series 对象的常用属性。
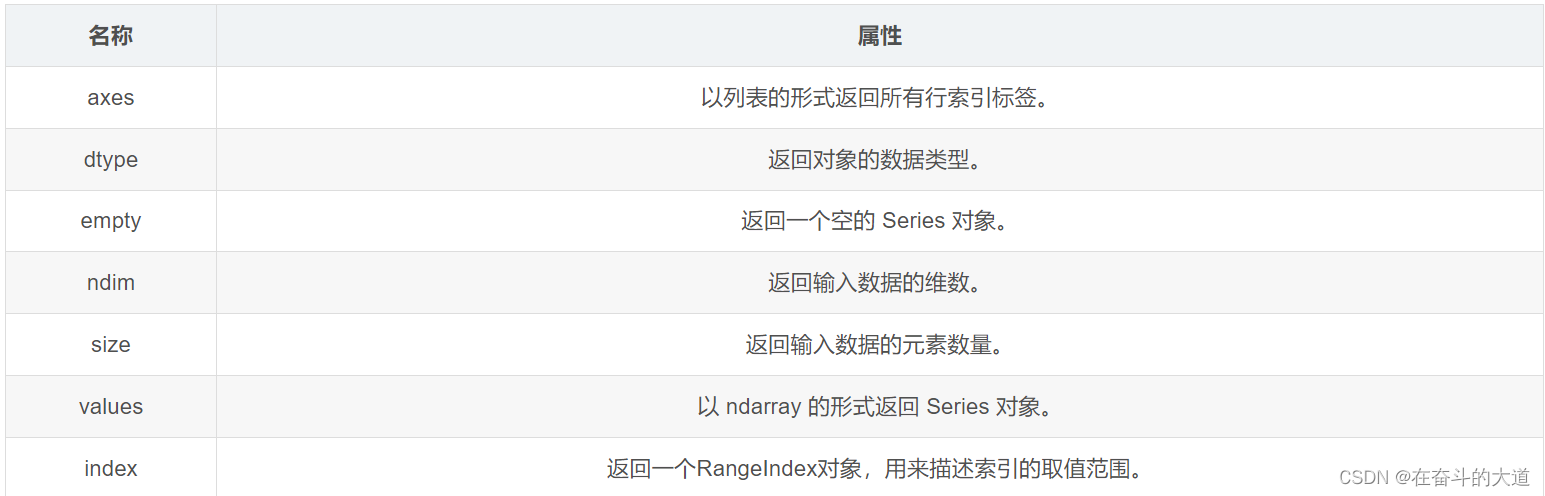
Python 功能代码:
import pandas as pd
import numpy as np
# 定义一个ndarray 数组类型的Series 对象
data = np.array([100, 98, 102, 78, 102])
s = pd.Series(data, index=["A", "B", "C", "D", "E"])
# Series 对象的axes属性
print(s.axes)
# Series 对象的dtype 属性
print(s.dtype)
# 判断 Series 对象是否为空, empty 属性
print(s.empty)
# 查看 Series 对象的维度, ndim 属性
print(s.ndim)
# 查询 Series 对象的长度, size 属性
print(s.size)
# 以数组形式返回Serise 对象中的value, values 属性
print(s.values)
# 查看Serise 对象的位置索引范围, index
print(s.index)
输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-series-three.py
[Index(['A', 'B', 'C', 'D', 'E'], dtype='object')]
int32
False
1
5
[100 98 102 78 102]
Index(['A', 'B', 'C', 'D', 'E'], dtype='object')Series常用方法
1) head()&tail()查看数据
想要查看 Series 的某一部分数据,可以使用 head() 或者 tail() 方法。其中 head() 返回前 n 行数据,默认显示前 5 行数据。
Python 功能代码:
import pandas as pd
import numpy as np
# 定义一个ndarray 数组类型的Series 对象
data = np.array([100, 98, 102, 78, 102, 110, 143, 144])
s = pd.Series(data, index=["A", "B", "C", "D", "E", "F", "G", "H"])
# head() 函数,查看Serise 对象前几行数据, 默认前五行
print(s.head())
# head() 函数, 指定前*行数据
print(s.head(1))
# tail() 函数, 查看Serise 对象后几行数据, 默认后五行
print(s.tail())
# tail() 函数, 指定后*行数据
print(s.tail(1))
输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-series-four.py
A 100
B 98
C 102
D 78
E 102
dtype: int32
A 100
dtype: int32
D 78
E 102
F 110
G 143
H 144
dtype: int32
H 144
dtype: int322) isnull()¬null()检测缺失值
isnull() 和 nonull() 用于检测 Series 中的缺失值。所谓缺失值,顾名思义就是元素值不存在、丢失、缺少。
isnull():如果元素值不存在或者缺失,则返回 True。
notnull():如果元素值不存在或者缺失,则返回 False。
Python 功能代码:
# 定义一个普通数组类型 的Series 对象
datas = [1, 2, 3, None]
sbool = pd.Series(datas)
# isnull 判断Series 对象中的数据项是否包含空
print(sbool.isnull())
# nonull 判断Serise 对象中的数据项是否包含空
print(sbool.notnull())输出结果:
0 False
1 False
2 False
3 True
dtype: bool
0 True
1 True
2 True
3 False
dtype: boolPandas DataFrame 快速入门
DataFrame 是 Pandas 的重要数据结构之一,也是在使用 Pandas 进行数据分析过程中最常用的结构之一。
DataFrame 数据结构
DataFrame 一个表格型的数据结构,既有行标签(index),又有列标签(columns),它也被称异构数据表,所谓异构,指的是表格中每列的数据类型可以不同,比如可以是字符串、整型或者浮点型等。DataFrame 数据结构图如下:
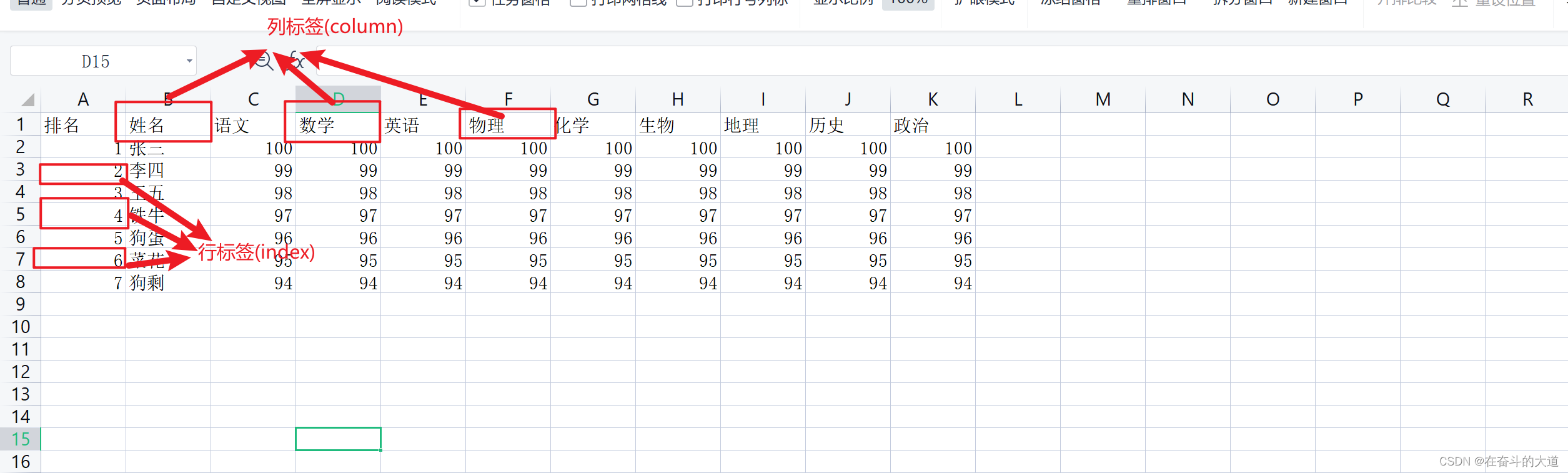
表格中展示了某班同学考试各科成绩的相关数据。数据以行和列形式来表示,其中每一列表示一个属性,而每一行表示一个条目的信息。
下表展示了上述表格中每一列标签所描述数据的数据类型,如下所示:
| Column | Type |
| 排名 | String |
| 姓名 | String |
| 语文 | Integer |
| 数学 | Integer |
| 英语 | Integer |
| 物理 | Integer |
| 化学 | Integer |
| 生物 | Integer |
| 地理 | Integer |
| 历史 | Integer |
| 政治 | Integer |
DataFrame 的每一行数据都可以看成一个 Series 结构,只不过,DataFrame 为这些行中每个数据值增加了一个列标签。因此 DataFrame 其实是从 Series 的基础上演变而来。在数据分析任务中 DataFrame 的应用非常广泛,因为它描述数据的更为清晰、直观。
DataFrame 总结:
- DataFrame 每一列的标签值允许使用不同的数据类型;
- DataFrame 是表格型的数据结构,具有行和列;
- DataFrame 中的每个数据值都可以被修改。
- DataFrame 结构的行数、列数允许增加或者删除;
- DataFrame 有两个方向的标签轴,分别是行标签和列标签;
- DataFrame 可以对行和列执行算术运算。
创建DataFrame对象
创建 DataFrame 对象的基本语法格式:
import pandas as pd
pd.DataFrame( data, index, columns, dtype, copy)
参数说明:
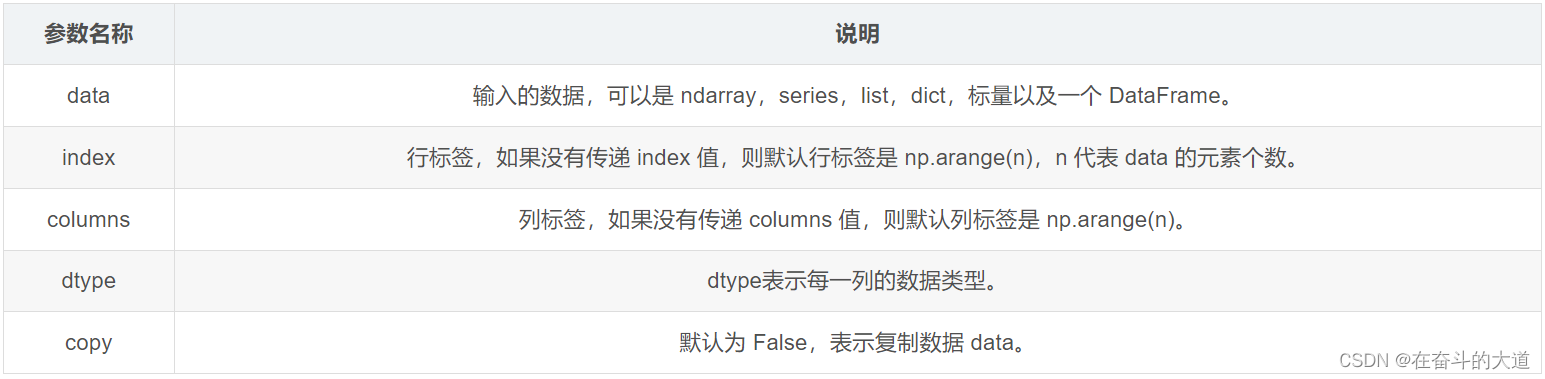
Pandas 提供了多种创建 DataFrame 对象的方式,主要包含以下五种。
1) 创建空的DataFrame对象
import pandas as pd
# 创建一个DataFrame 空对象
df = pd.DataFrame()
print(df)输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-dataframe-one.py
Empty DataFrame
Columns: []
Index: []2) 列表创建DataFame对象
可以使用单一列表或嵌套列表来创建一个 DataFrame。
Python 功能代码:单一列表
# 创建一个ndarray 数组类型,单一列表的DataFrame 对象
data = np.array([1, 10, 100])
dataf = pd.DataFrame(data)
print(dataf)输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-dataframe-one.py
Empty DataFrame
Columns: []
Index: []
0
0 1
1 10
2 100Python 功能代码:嵌套式列表
# 创建一个嵌套式数组, 嵌套式列表的DataFrame 对象
nestData = [["张三", 20], ["李四", 43], ["王五", 54]]
nestDF = pd.DataFrame(nestData, columns=["name", "score"])
print(nestDF)
输出结果:
name score
0 张三 20
1 李四 43
2 王五 543) 字典嵌套列表创建
字典中,键对应的值的元素长度必须相同(也就是列表长度相同)。如果传递了索引,那么索引的长度应该等于数组的长度;如果没有传递索引,那么默认情况下,索引将是 range(n),其中 n 代表数组长度。
Python 功能代码
# 使用字典数据, 创建DataFrame 对象
dictData = {"name": ["小丽", "小米", "小胡"], "height":[110, 109, 112]}
dictDF = pd.DataFrame(dictData)
print(dictDF)输出结果:
name height
0 小丽 110
1 小米 109
2 小胡 112注意:这里使用了默认行标签,也就是 range(n)。它生成了 0,1,2,3,并分别对应了列表中的每个元素值。
4) 列表嵌套字典创建DataFrame对象
列表嵌套字典可以作为输入数据传递给 DataFrame 构造函数。默认情况下,字典的键被用作列名。
Python 功能代码
# 使用列表嵌套字典, 创建DataFrame 对象
listNest =[{"name": "小王", "age": 32}, {"name": "雄霸", "age": 100}, {"name": "完颜康", "address": "中都"}]
listNestDF = pd.DataFrame(listNest)
print(listNestDF)输出结果:
name age address
0 小王 32.0 NaN
1 雄霸 100.0 NaN
2 完颜康 NaN 中都注意:如果其中某个元素值缺失,也就是字典的 key 无法找到对应的 value,将使用 NaN 代替。
Python 功能代码:为DataFrame 对象,指定标签索引。
# 使用列表嵌套字典,并且指定标签索引
listNestIndexDF = pd.DataFrame(listNest, index=[1, 2, 3])
print(listNestIndexDF)输出结果:
name age address
1 小王 32.0 NaN
2 雄霸 100.0 NaN
3 完颜康 NaN 中都5) Series创建DataFrame对象
可以传递一个字典形式的 Series,从而创建一个 DataFrame 对象,其输出结果的行索引是所有 index 的合集。
Python 功能代码:
# 使用字典,且value 对应Series 对象, 创建DataFrame 对象
dictSeries ={"one": pd.Series([1, 2, 3]),
"two": pd.Series([10, 20, 10, 100])}
seriesDF = pd.DataFrame(dictSeries)
print(seriesDF)输出结果:
one two
0 1.0 10
1 2.0 20
2 3.0 10
3 NaN 100注意:对于 one 列而言,此处虽然显示了行索引 ‘d’,但由于没有与其对应的值,所以它的值为 NaN。
列索引操作DataFrame
DataFrame 可以使用列索(columns)引来完成数据的选取、添加和删除操作。
1) 列索引选取数据列
Python 功能代码:
import pandas as pd
import numpy as np
# 基于字典Series 创建一个DataFrame 对象
dictSeries = {1: pd.Series([10, 100, 102, 104]),
2: pd.Series([1100, 203, 110, 119, 405]),
3: pd.Series([110, 80, 102])}
serieseDF = pd.DataFrame(dictSeries)
print(serieseDF)
# 使用列索引选取数据列
print(serieseDF[1])输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-dataframe-two.py
1 2 3
0 10.0 1100 110.0
1 100.0 203 80.0
2 102.0 110 102.0
3 104.0 119 NaN
4 NaN 405 NaN
0 10.0
1 100.0
2 102.0
3 104.0
4 NaN2) 列索引添加数据列
#使用serieseDF['列']=值,插入新的数据列
serieseDF[4]=pd.Series([10,20,30])
print(serieseDF)输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-dataframe-two.py
1 2 3
0 10.0 1100 110.0
1 100.0 203 80.0
2 102.0 110 102.0
3 104.0 119 NaN
4 NaN 405 NaN
0 10.0
1 100.0
2 102.0
3 104.0
4 NaN
Name: 1, dtype: float64
1 2 3 4
0 10.0 1100 110.0 10.0
1 100.0 203 80.0 20.0
2 102.0 110 102.0 30.0
3 104.0 119 NaN NaN
4 NaN 405 NaN NaN除了使用serieseDF[]=value的方式外,您还可以使用 insert() 方法插入新的列。
Python 功能代码:
# 使用insert 方法, 插入新的数据列
serieseDF.insert(4, column=5, value= [1, 2, 3, 4, 5])
print(serieseDF)输出结果:
1 2 3 4 5
0 10.0 1100 110.0 10.0 1
1 100.0 203 80.0 20.0 2
2 102.0 110 102.0 30.0 3
3 104.0 119 NaN NaN 4
4 NaN 405 NaN NaN 53) 列索引删除数据列
通过 del 和 pop() 都能够删除 DataFrame 中的数据列。
Python 功能代码:
# 通过del 函数, 删除DataFrame 数据列
del serieseDF[5]
print(serieseDF)输出结果:
1 2 3 4
0 10.0 1100 110.0 10.0
1 100.0 203 80.0 20.0
2 102.0 110 102.0 30.0
3 104.0 119 NaN NaN
4 NaN 405 NaN NaNPython 功能代码:
# 通过pop 函数, 删除DataFrame 数据列
serieseDF.pop(4)
print(serieseDF)输出结果:
1 2 3
0 10.0 1100 110.0
1 100.0 203 80.0
2 102.0 110 102.0
3 104.0 119 NaN
4 NaN 405 NaN行索引操作DataFrame
理解上一章节列索引操作DataFrame, 行索引操作就变的简单。
1) 标签索引选取
将行标签传递给 loc 函数,来选取数据。
Python 功能代码:
# 通过loc 函数, 读取DataFrame 指定行数据
print(serieseDF.loc[0])输出结果:
1 10.0
2 1100.0
3 110.0
Name: 0, dtype: float64注意:loc 允许接两个参数分别是行和列,参数之间需要使用“逗号”隔开,但该函数只能接收标签索引。
2) 整数索引选取
通过将数据行所在的索引位置传递给 iloc 函数,也可以实现数据行选取。
Python 功能代码:
# 通过iloc 函数, 读取DataFrame 指定行数据
print(serieseDF.iloc[1])输出结果:
1 100.0
2 203.0
3 80.0
Name: 1, dtype: float64注意:iloc 允许接受两个参数分别是行和列,参数之间使用“逗号”隔开,但该函数只能接收整数索引。
3) 切片操作多行选取
使用切片的方式同时选取多行。
Python 功能代码:
# 使用切片方式, 读取DataFrame 指定多行数据。行数据范围:左闭右开
print(serieseDF[1:3])输出结果:
1 2 3
1 100.0 203 80.0
2 102.0 110 102.04) 添加数据行
使用 concat() 函数,可以将新的数据行添加到 DataFrame 中,该函数会在行末追加数据行。
Python 功能代码:
import pandas as pd
import numpy as np
# 定义 两个DataFrame 对象
df = pd.DataFrame([["小王", 12], ["小李", 14]], columns = ['name','age'])
dfAppend = pd.DataFrame([["小刚", 16], ["肥龙", 18]], columns = ['name','age'])
#在行末追加新数据行
dfMerge = pd.concat([df, dfAppend])
print(dfMerge)输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-dataframe-three.py
name age
0 小王 12
1 小李 14
0 小刚 16
1 肥龙 185) 删除数据行
使用行索引标签,从 DataFrame 中删除某一行数据。如果索引标签存在重复,那么它们将被一起删除。
Python 功能代码:
# 删除指定数据行
dfConcat = dfConcat.drop(0)
print(dfConcat)输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-dataframe-three.py
name age
0 小王 12
1 小李 14
0 小刚 16
1 肥龙 18
name age
1 小李 14
1 肥龙 18DataFrame 常见属性和方法
DataFrame 的属性和方法

DataFrame 数据初始化
import pandas as pd
import numpy as np
data = {'Name':pd.Series(['c语言从入门到精通','Java从入门到精通',"Python从入门到精通",'JavaScript从入门到精通','C++从入门到精通','MYSQL从入门到精通','Spring5 企业级开发实战']),
'years':pd.Series([5,6,15,28,3,19,23]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])}
#构建DataFrame
df = pd.DataFrame(data)
print(df)输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-dataframe-four.py
Name years Rating
0 c语言从入门到精通 5 4.23
1 Java从入门到精通 6 3.24
2 Python从入门到精通 15 3.98
3 JavaScript从入门到精通 28 2.56
4 C++从入门到精通 3 3.20
5 MYSQL从入门到精通 19 4.60
6 Spring5 企业级开发实战 23 3.801) T(Transpose)转置
返回 DataFrame 的转置,也就是把行和列进行交换。
Python功能代码:
# T 转置
print(df.T)输出结果:
0 1 2 3 4 5 6
Name c语言从入门到精通 Java从入门到精通 Python从入门到精通 JavaScript从入门到精通 C++从入门到精通 MYSQL从入门到精通 Spring5 企业级开发实战
years 5 6 15 28 3 19 23
Rating 4.23 3.24 3.98 2.56 3.2 4.6 3.82) axes
返回一个行标签、列标签组成的列表。
Python 功能代码:
#输出行、列标签
print(df.axes)输出结果:
[RangeIndex(start=0, stop=7, step=1), Index(['Name', 'years', 'Rating'], dtype='object')]3) dtypes
返回每一列的数据类型。
Python 功能代码:
# 输出行、列标签的数据类型
print(df.dtypes)输出结果:
Name object
years int64
Rating float64
dtype: object4) empty
返回一个布尔值,判断输出的数据对象是否为空,若为 True 表示对象为空。
Python 功能代码:
#判断输入数据是否为空
print(df.empty)输出结果:
False5) ndim
返回数据对象的维数。
Python 功能代码:
#DataFrame的维度
print(df.ndim)输出结果:
26) shape
返回一个代表 DataFrame 维度的元组。返回值元组 (a,b),其中 a 表示行数,b 表示列数。
Python 功能代码:
#DataFrame的形状
print(df.shape)输出结果:
(7, 3)7) size
返回 DataFrame 中的元素数量。
#DataFrame的中元素个数
print(df.size)输出结果:
218) values
以 ndarray 数组的形式返回 DataFrame 中的数据。
Python 功能代码:
#DataFrame的数据
print(df.values)输出结果:\
[['c语言从入门到精通' 5 4.23]
['Java从入门到精通' 6 3.24]
['Python从入门到精通' 15 3.98]
['JavaScript从入门到精通' 28 2.56]
['C++从入门到精通' 3 3.2]
['MYSQL从入门到精通' 19 4.6]
['Spring5 企业级开发实战' 23 3.8]]9) head()&tail()查看数据
想要查看 DataFrame 的一部分数据,可以使用 head() 或者 tail() 方法。其中 head() 返回前 n 行数据,默认显示前 5 行数据。
# DataFrame 读取默认行数
print(df.head())
# DataFrame 读取指定行数
print(df.head(3))输出结果:
Name years Rating
0 c语言从入门到精通 5 4.23
1 Java从入门到精通 6 3.24
2 Python从入门到精通 15 3.98
3 JavaScript从入门到精通 28 2.56
4 C++从入门到精通 3 3.20
Name years Rating
0 c语言从入门到精通 5 4.23
1 Java从入门到精通 6 3.24
2 Python从入门到精通 15 3.98tail() 返回后 n 行数据
# DataFrame 读取末尾默认行数, 默认 5行
print(df.tail())输出结果:
Name years Rating
2 Python从入门到精通 15 3.98
3 JavaScript从入门到精通 28 2.56
4 C++从入门到精通 3 3.20
5 MYSQL从入门到精通 19 4.60
6 Spring5 企业级开发实战 23 3.8010) shift()移动行或列
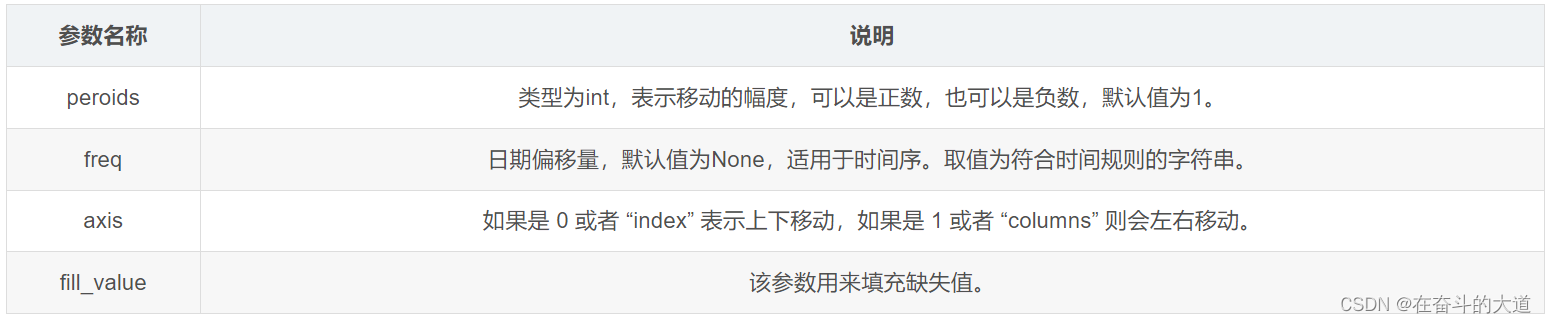
如果您想要移动 DataFrame 中的某一行/列,可以使用 shift() 函数实现。它提供了一个periods参数,该参数表示在特定的轴上移动指定的步幅。
shif() 函数的语法格式如下:
DataFrame.shift(periods=1, freq=None, axis=0)参数说明如下:
Python 功能代码:
import pandas as pd
info= pd.DataFrame({'a_data': [40, 28, 39, 32, 18],
'b_data': [20, 37, 41, 35, 45],
'c_data': [22, 17, 11, 25, 15]})
#移动幅度为3
info.shift(periods=3)
输出结果:
a_data b_data c_data
0 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
3 40.0 20.0 22.0
4 28.0 37.0 17.0
使用 fill_value 参数填充 DataFrame 中的缺失值, Python 功能代码:
import pandas as pd
info= pd.DataFrame({'a_data': [40, 28, 39, 32, 18],
'b_data': [20, 37, 41, 35, 45],
'c_data': [22, 17, 11, 25, 15]})
#移动幅度为3
print(info.shift(periods=3))
#将缺失值和原数值替换为52
info.shift(periods=3,axis=1,fill_value= 52)
输出结果:
原输出结果:
a_data b_data c_data
0 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
3 40.0 20.0 22.0
4 28.0 37.0 17.0
替换后输出:
a_data b_data c_data
0 52 52 52
1 52 52 52
2 52 52 52
3 52 52 52
4 52 52 52
注意:fill_value 参数不仅可以填充缺失值,还也可以对原数据进行替换。
Pandas 数据统计
描述统计学(descriptive statistics)是一门统计学领域的学科,主要研究如何取得反映客观现象的数据,并以图表形式对所搜集的数据进行处理和显示,最终对数据的规律、特征做出综合性的描述分析。
Pandas常见统计函数
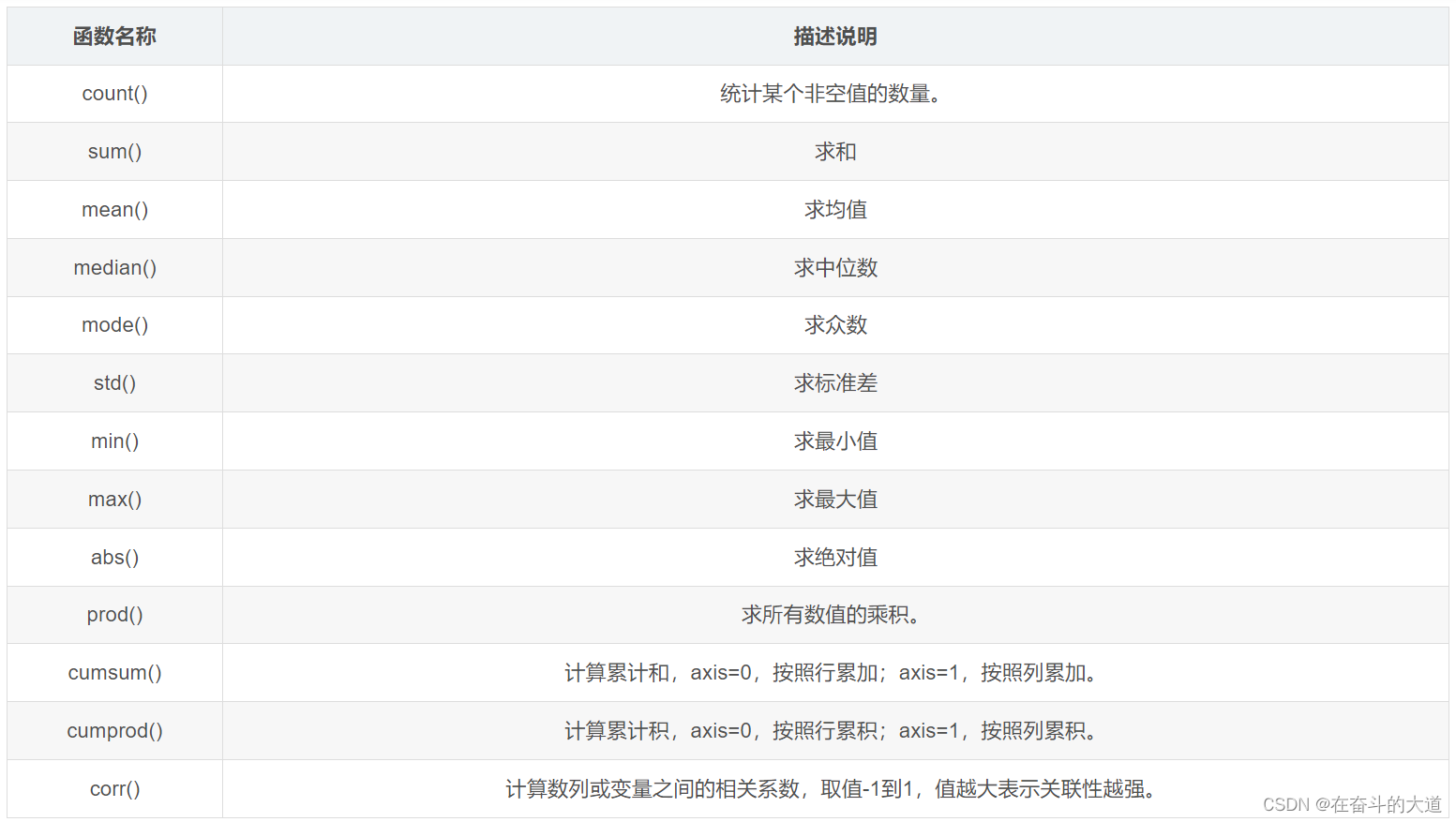
在 DataFrame 中,使用聚合类方法时需要指定轴(axis)参数。下面介绍两种传参方式:
- 对行操作,默认使用 axis=0 或者使用 “index”;
- 对列操作,默认使用 axis=1 或者使用 “columns”。
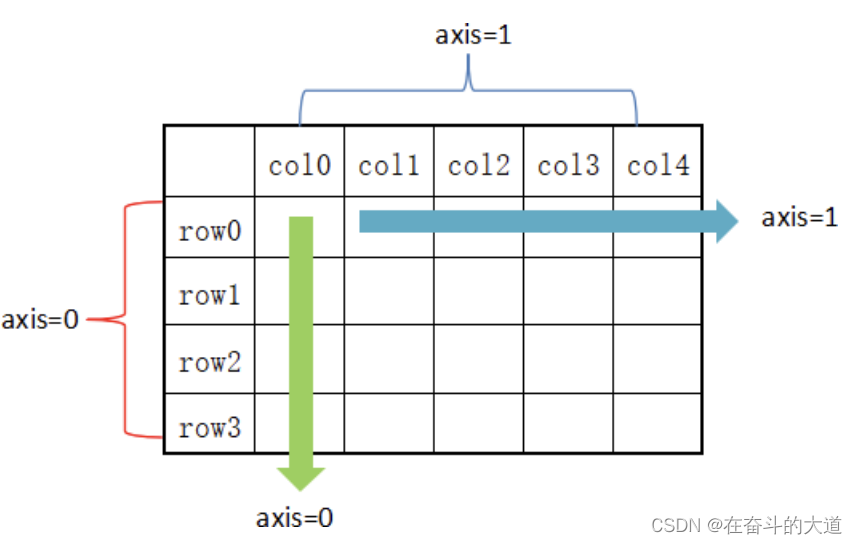
从上图可以看出,axis=0 表示按垂直方向进行计算,而 axis=1 则表示按水平方向。
创建一个 DataFrame 结构
import pandas as pd
import numpy as np
#创建字典型series结构
data = {'Name':pd.Series(['小明','小亮','小红','小华','老赵','小曹','小陈',
'老李','老王','小冯','小何','老张']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])
}
df = pd.DataFrame(data)
print(df)
sum()求和
在默认情况下,返回 axis=0 的所有值的和。
# sum 求和
print(df.sum())输出结果:
Name 小明小亮小红小华老赵小曹小陈老李老王小冯小何老张
Age 382
Rating 44.92
dtype: object注意:sum() 和 cumsum() 函数可以同时处理数字和字符串数据。虽然字符聚合通常不被使用,但使用这两个函数并不会抛出异常;而对于 abs()、cumprod() 函数则会抛出异常,因为它们无法操作字符串数据。
指定axios 行列模式,汇总 统计
# sum 指定 列模式统计
print(df.sum(axis=0))
# sum 指定 行模式统计
print(df.sum(axis=1))输出结果:
Name 小明小亮小红小华老赵小曹小陈老李老王小冯小何老张
Age 382
Rating 44.92
dtype: object
e:\py_workspace\conda-demo\pandas-dataframe-five.py:20: FutureWarning: Dropping of nuisance columns in DataFrame reductions (with 'numeric_only=None') is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the reduction.
print(df.sum(axis=1))
0 29.23
1 29.24
2 28.98
3 25.56
4 33.20
5 33.60
6 26.80
7 37.78
8 42.98
9 34.80
10 55.10
11 49.65
dtype: float64mean()求均值
Python 功能代码:
# mean() 平均值
print(df.mean())输出结果:
e:\py_workspace\conda-demo\pandas-dataframe-five.py:23: FutureWarning: The default value of numeric_only in DataFrame.mean is deprecated. In a future version, it will default to False. In addition, specifying 'numeric_only=None' is deprecated. Select only valid columns or specify the value of numeric_only to silence this warning.
print(df.mean())
Age 31.833333
Rating 3.743333
dtype: float64std()求标准差
返回数值列的标准差.
# std() 标准差
print(df.std())Python 功能代码:
输出结果:
e:\py_workspace\conda-demo\pandas-dataframe-five.py:26: FutureWarning: The default value of numeric_only in DataFrame.std is deprecated. In a future version, it will default to False. In addition, specifying 'numeric_only=None' is deprecated. Select only valid columns or specify the value of numeric_only to silence this warning.
print(df.std())
Age 9.232682
Rating 0.661628
dtype: float64标准差是方差的算术平方根,它能反映一个数据集的离散程度。注意,平均数相同的两组数据,标准差未必相同。
数据汇总描述
describe() 函数显示与 DataFrame 数据列相关的统计信息摘要。
Python 功能代码:
#求出数据的所有描述信息
print(df.describe())输出结果:
Age Rating
count 12.000000 12.000000
mean 31.833333 3.743333
std 9.232682 0.661628
min 23.000000 2.560000
25% 25.000000 3.230000
50% 29.500000 3.790000
75% 35.500000 4.132500
max 51.000000 4.800000注意:返回一个有多个行的所有数字列的统计表,每个行是一个统计指标,有总数、平均数、标准差、最大最小值、四分位数等。
通过 describe() 提供的include能够筛选字符列或者数字列的摘要信息。
include 相关参数值说明如下:
- object: 表示对字符列进行统计信息描述;
- number:表示对数字列进行统计信息描述;
- all:汇总所有列的统计信息。
Python 功能代码:
print(df.describe(include=["object"]))输出结果:
Name
count 12
unique 12
top 小明
freq 1Pandas 可视化
Pandas 在数据分析、数据可视化方面有着较为广泛的应用,Pandas 对 Matplotlib 绘图软件包的基础上单独封装了一个plot()接口,通过调用该接口可以实现常用的绘图操作。
Pandas 之所以能够实现了数据可视化,主要利用了 Matplotlib 库的 plot() 方法,它对 plot() 方法做了简单的封装,因此您可以直接调用该接口。
Python Pandas 可视化示例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#创建包含时间序列的DataFrame 数据
ts = pd.Series(np.random.randn(365), index=pd.date_range("1/1/2020", periods=365))
# 图像绘制
ts.plot()
# 图像显示
plt.show()Matplotlib 绘制:
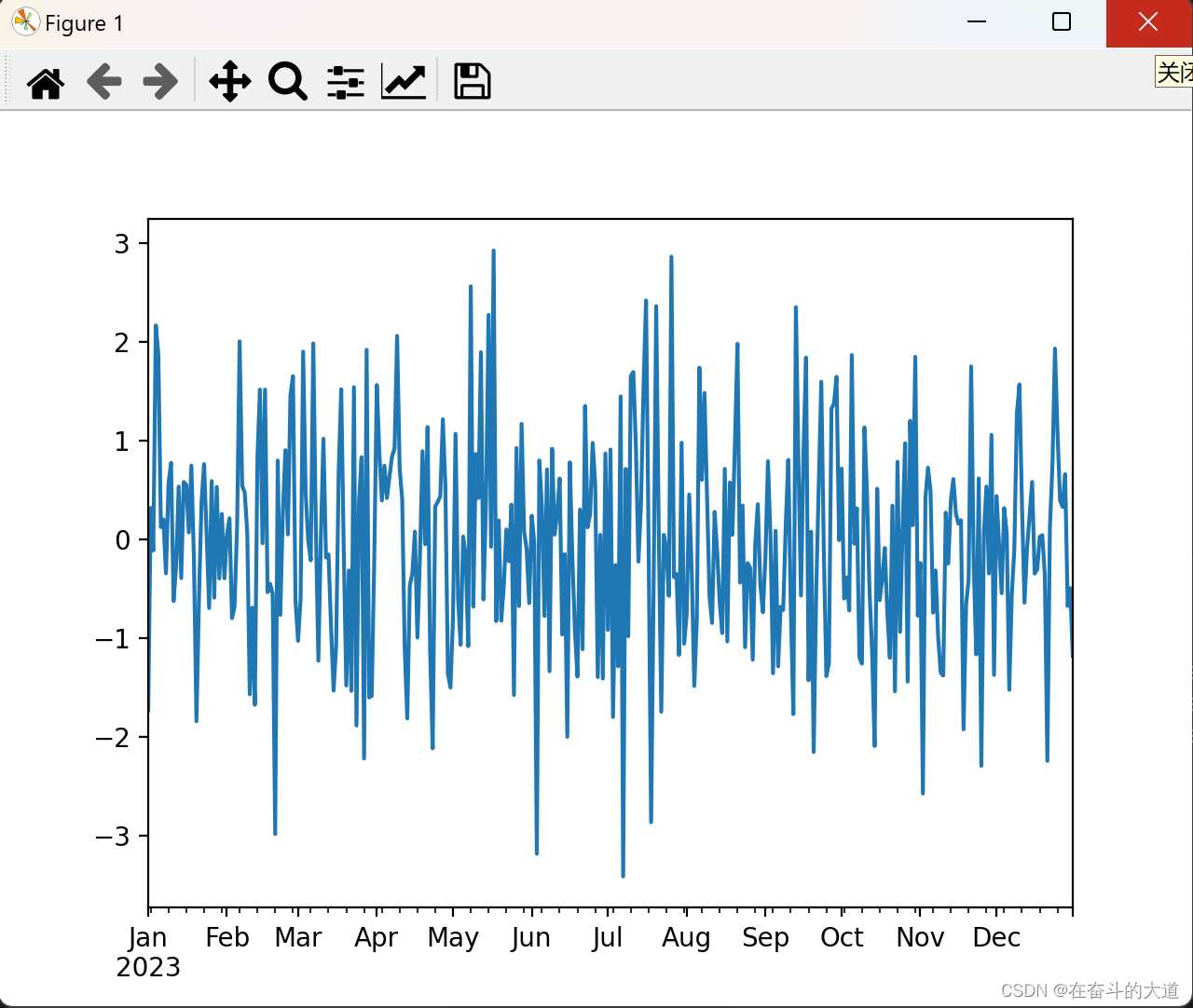
如上图所示,如果行索引中包含日期,Pandas 会自动调用 gct().autofmt_xdate() 来格式化 x 轴。
除了使用默认的线条绘图外,您还可以使用其他绘图方式,如下所示:
- 柱状图:bar() 或 barh()
- 直方图:hist()
- 箱状箱:box()
- 区域图:area()
- 散点图:scatter()
通过关键字参数kind可以把上述方法传递给 plot()。
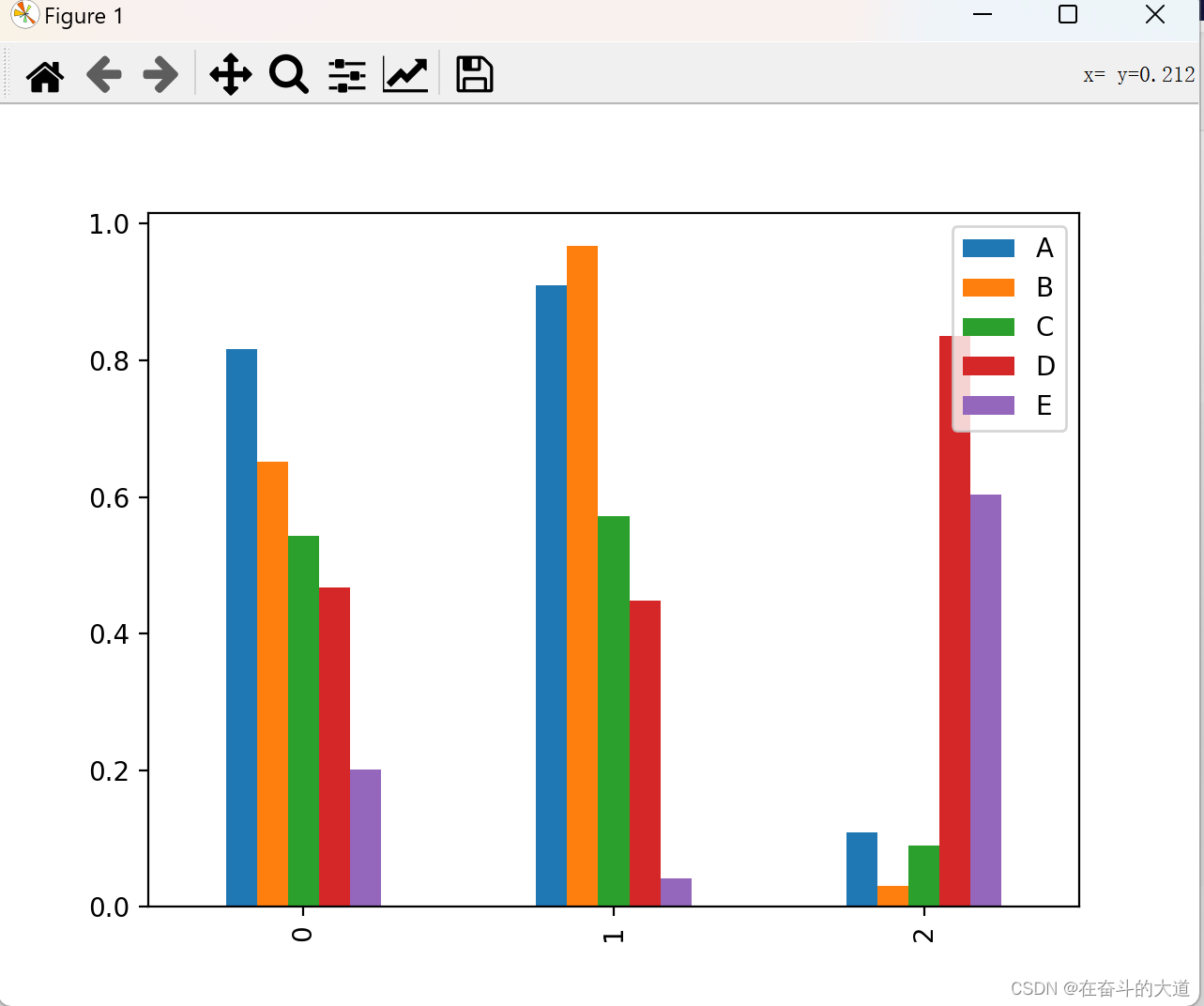
柱状图
创建一个柱状图。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建一个柱状图
df = pd.DataFrame(np.random.rand(3,5),columns=['A','B','C','D','E'])
print(df)
#或使用df.plot(kind="bar")
df.plot.bar()
# 图像显示
plt.show()
Matplotlib 图绘制
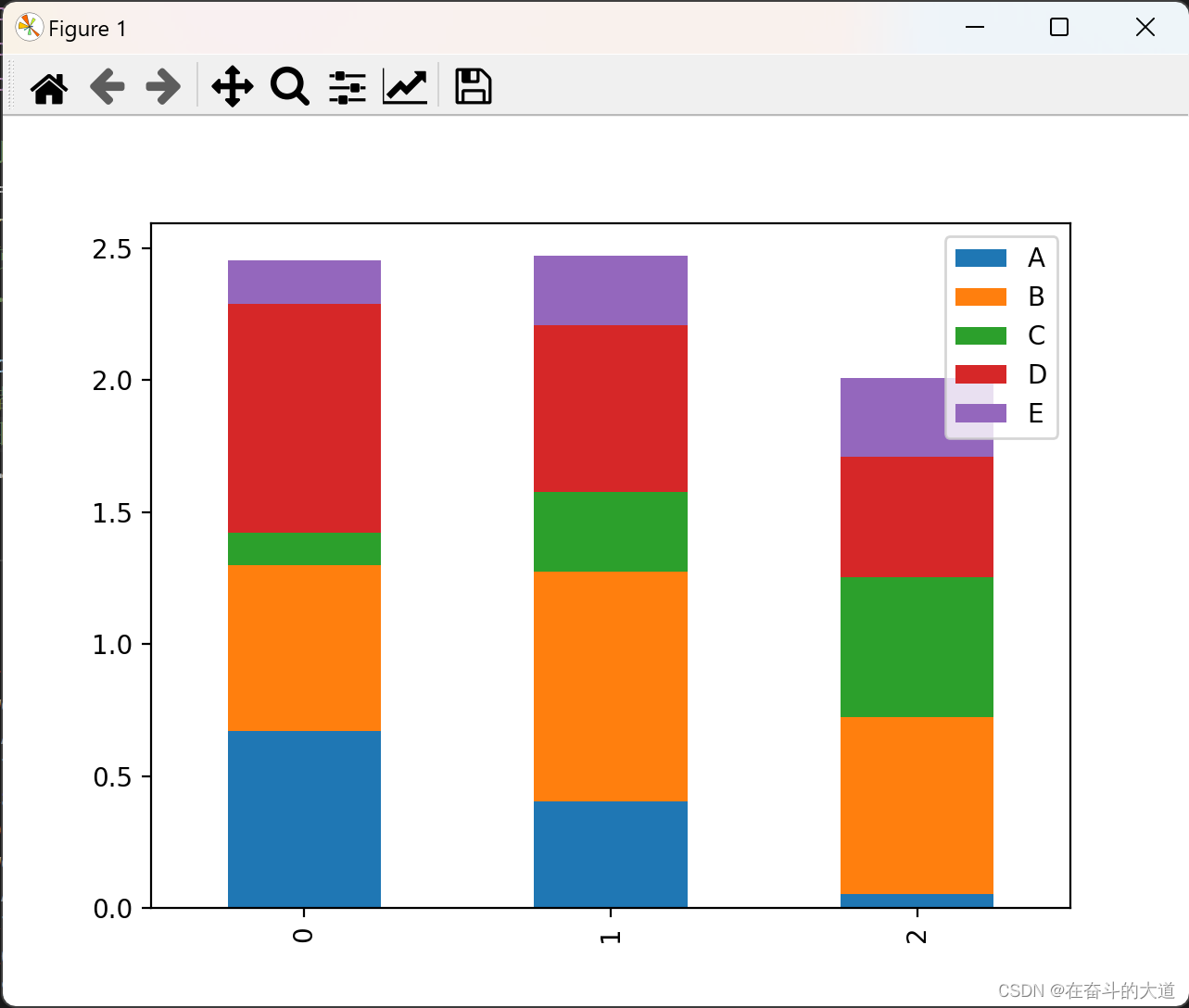
通过设置参数stacked=True可以生成柱状堆叠图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建一个柱状图
df = pd.DataFrame(np.random.rand(3,5),columns=['A','B','C','D','E'])
print(df)
#或使用df.plot(kind="bar")
#df.plot.bar()
df.plot(kind="bar",stacked=True)
#或者使用df.plot.bar(stacked="True")
# 图像显示
plt.show()
Matplotlib 图绘制
如果要绘制水平柱状图,您可以使用以下方法:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建一个DataFrame 对象
df = pd.DataFrame(np.random.rand(3,5),columns=['A','B','C','D','E'])
print(df)
#或使用df.plot(kind="bar")
#df.plot.bar()
#df.plot(kind="bar",stacked=True)
#或者使用df.plot.bar(stacked="True")
# 水平柱状图
df.plot.barh(stacked=True)
# 图像显示
plt.show()
Matplotlib 图绘制
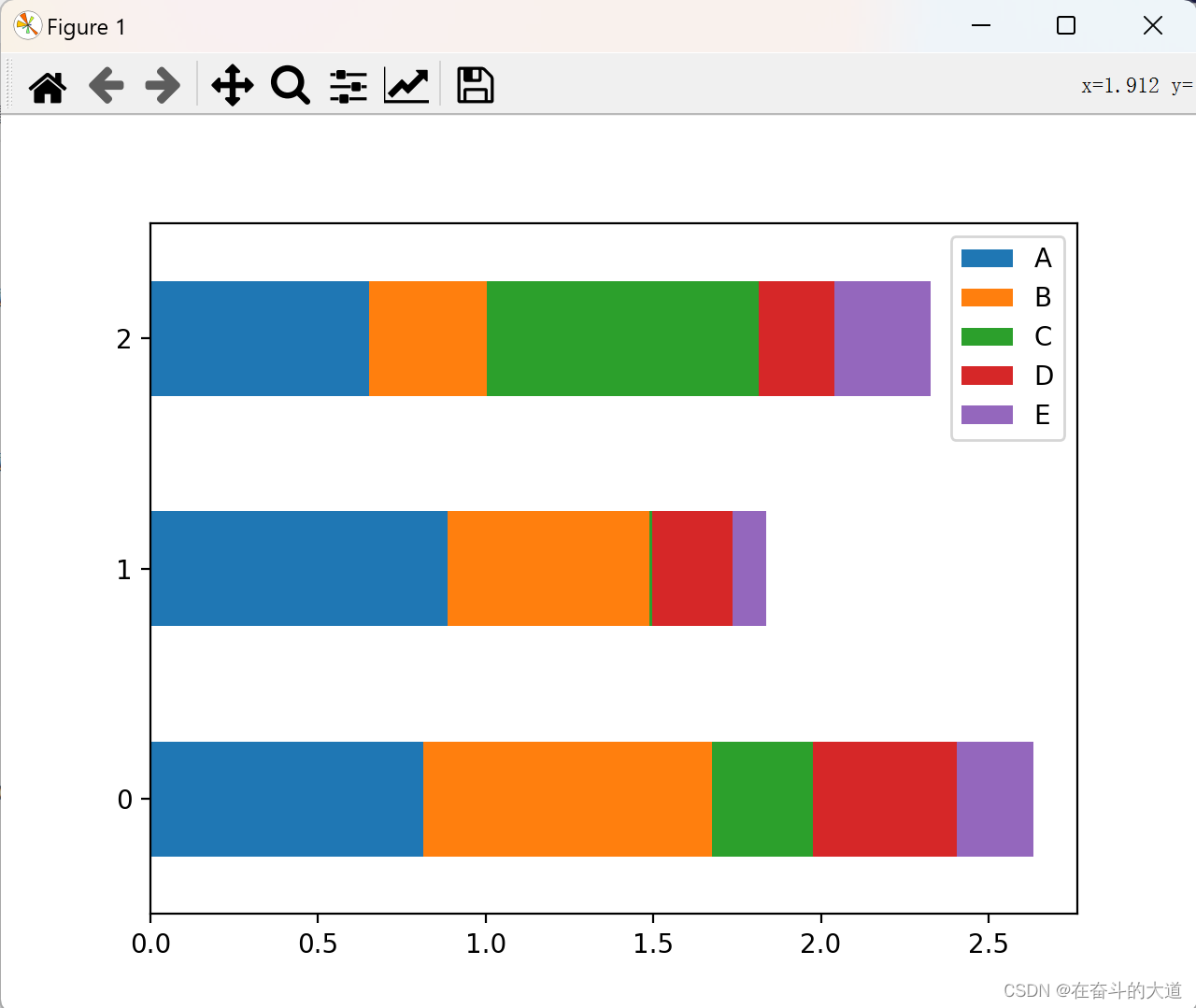
直方图
plot.hist() 可以实现绘制直方图,并且它还可以指定 bins(构成直方图的箱数)。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.DataFrame({'A':np.random.randn(10)+2,'B':np.random.randn(10),'C':
np.random.randn(10)-2}, columns=['A', 'B', 'C'])
print(df)
#指定箱数为10
df.plot.hist(bins=10)
# 图像显示
plt.show()
Matplotlib 图绘制
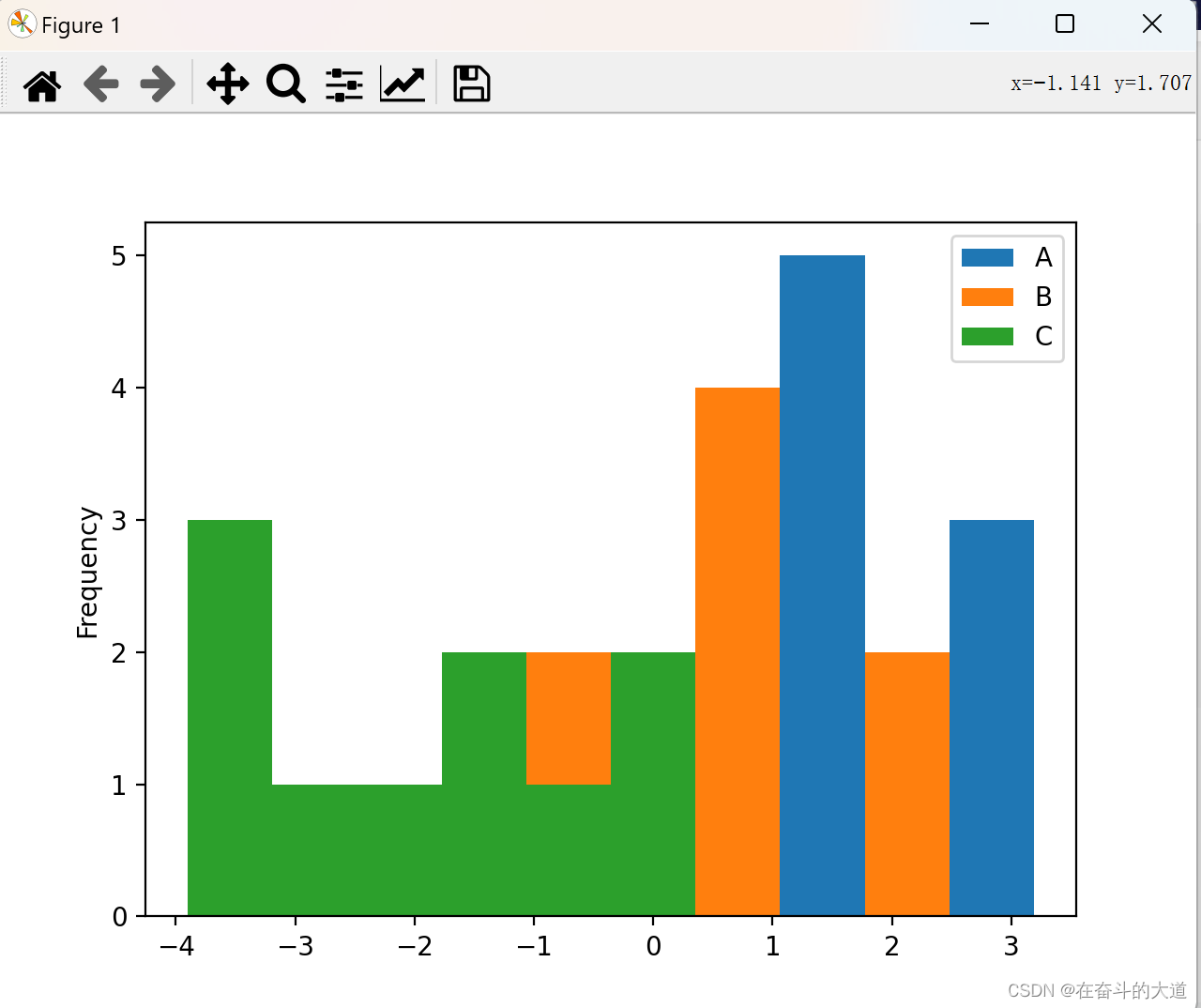
给每一列数据都绘制一个直方图,需要使用以下方法:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.DataFrame({'A':np.random.randn(10)+2,'B':np.random.randn(10),'C':
np.random.randn(10)-2}, columns=['A', 'B', 'C'])
print(df)
#指定箱数为10
# df.plot.hist(bins=10)
#使用diff绘制
df.diff().hist(color="r",alpha=0.5,bins=10)
# 图像显示
plt.show()
Matplotlib 图绘制

箱型图
通过调用 Series.box.plot() 、DataFrame.box.plot() 或者 DataFrame.boxplot() 方法来绘制箱型图,它将每一列数据的分布情况,以可视化的图像展现出来。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建一个DataFrame 对象
df = pd.DataFrame(np.random.rand(10, 4), columns=['A', 'B', 'C', 'D'])
print(df)
# 图像绘制
df.plot.box()
# 图像显示
plt.show()
Matplotlib 图绘制
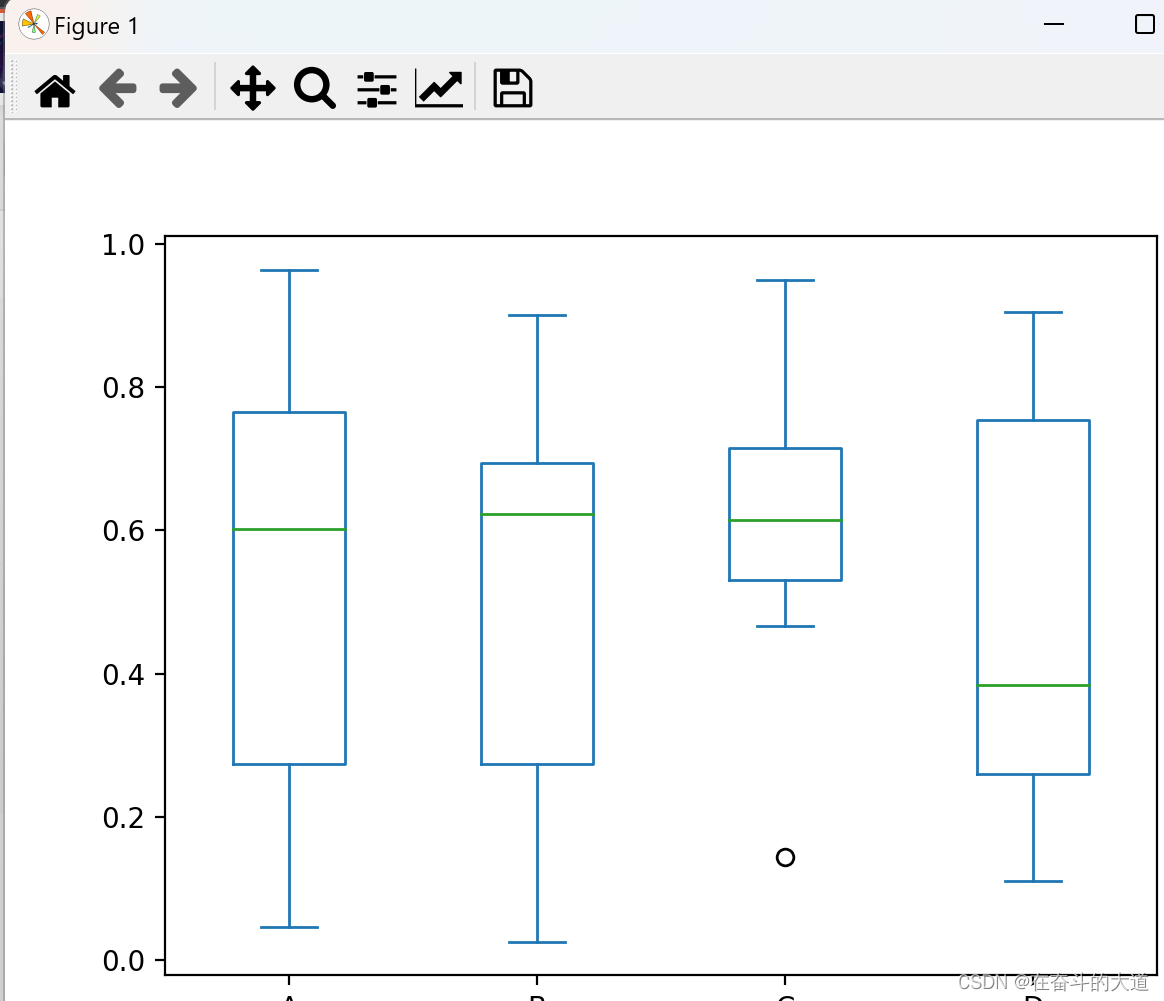
区域图
使用 Series.plot.area() 或 DataFrame.plot.area() 方法来绘制区域图。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建一个DataFrame 对象
df = pd.DataFrame(np.random.rand(10, 4), columns=['A', 'B', 'C', 'D'])
print(df)
# 图像绘制
# df.plot.box()
# 区域图绘制
df.plot.area()
# 图像显示
plt.show()
Matplotlib 图绘制
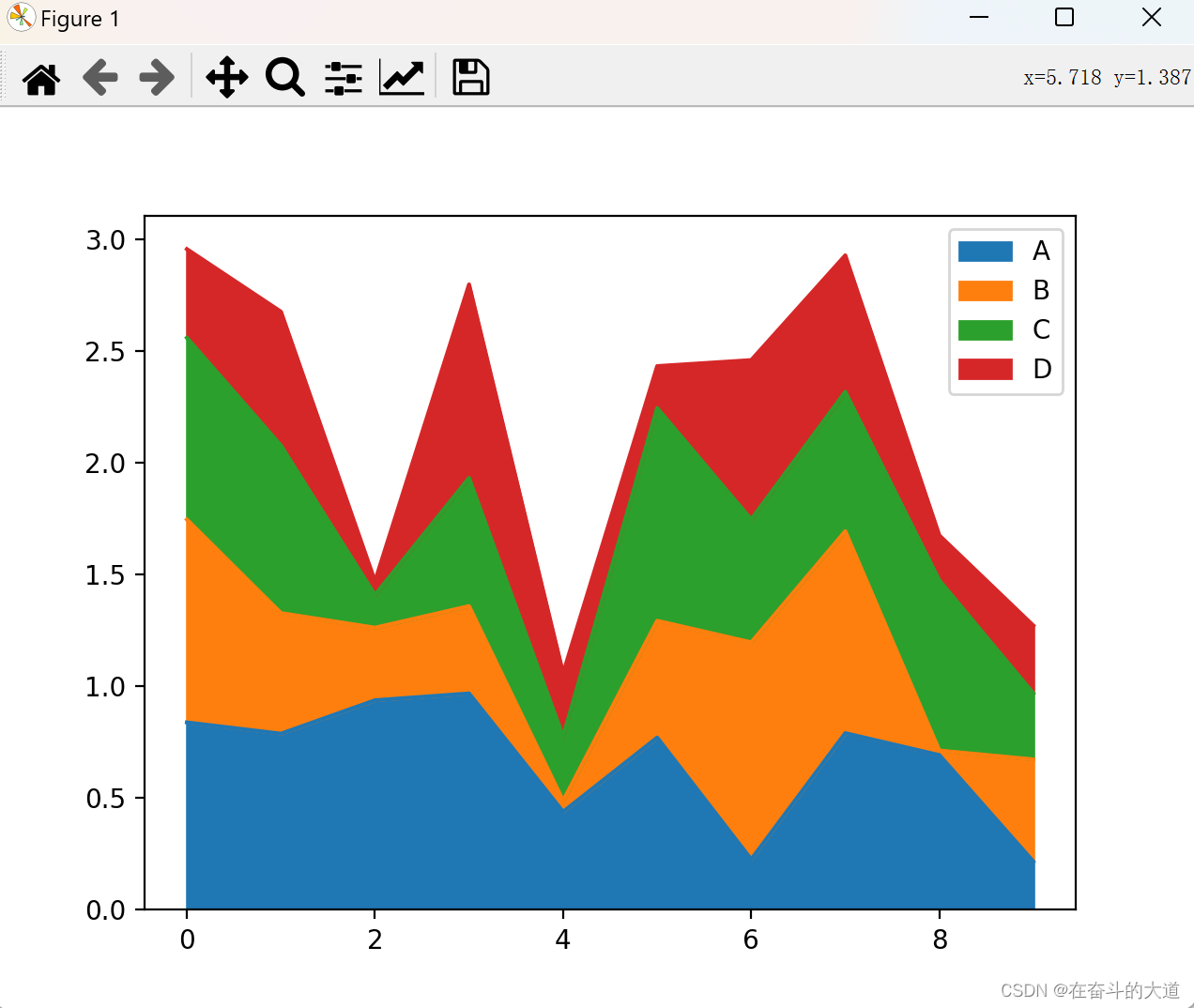
散点图
使用 DataFrame.plot.scatter() 方法来绘制散点图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建一个DataFrame 对象
df = pd.DataFrame(np.random.rand(10, 4), columns=['A', 'B', 'C', 'D'])
print(df)
# 图像绘制
# df.plot.box()
# 区域图绘制
#df.plot.area()
# 绘制闪点图
df.plot.scatter(x='A',y='B')
# 图像显示
plt.show()
Matplotlib 图绘制
饼状图
饼状图可以通过 DataFrame.plot.pie() 方法来绘制。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建DataFrame 对象
df = pd.DataFrame(100 * np.random.rand(4), index=['python', 'java', 'c++', 'c'], columns=['L'])
print(df)
# 图像绘制
df.plot.pie(subplots=True)
# 图像显示
plt.show()Matplotlib 图绘制
Pandas excel/csv 读写
文件的读写操作属于计算机的 IO 操作,Pandas IO 操作提供了一些读取器函数,比如 pd.read_csv()、pd.read_json 等,它们都返回一个 Pandas 对象。
在 Pandas 中用于读取文本的函数有两个,分别是: read_csv() 和 read_table() ,它们能够自动地将表格数据转换为 DataFrame 对象。
新建测试数据csv/test.csv 文件,并添加以下数据:
ID,Name,Age,City,Salary
1,Jack,28,Beijing,22000
2,Lida,32,Shanghai,19000
3,John,43,Shenzhen,12000
4,Helen,38,Hengshui,3500
read_csv()
read_csv() 表示从 CSV 文件中读取数据,并创建 DataFrame 对象。
import pandas as pd
#需要注意文件的路径
df=pd.read_csv("./csv/test.csv")
print (df)
输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-excel-csv-one.py
ID Name Age City Salary
0 1 Jack 28 Beijing 22000
1 2 Lida 32 Shanghai 19000
2 3 John 43 Shenzhen 12000
3 4 Helen 38 Hengshui 35001) 自定义索引
在 CSV 文件中指定了一个列,然后使用index_col可以实现自定义索引。
import pandas as pd
#需要注意文件的路径
df=pd.read_csv("./csv/test.csv", index_col=["ID"])
print (df)
输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-excel-csv-one.py
Name Age City Salary
ID
1 Jack 28 Beijing 22000
2 Lida 32 Shanghai 19000
3 John 43 Shenzhen 12000
4 Helen 38 Hengshui 35002) 设置指定列的dtype
import pandas as pd
import numpy as np
#需要注意文件的路径
df=pd.read_csv("./csv/test.csv", dtype={'Salary':np.float64})
print (df.dtypes)
输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-excel-csv-one.py
ID int64
Name object
Age int64
City object
Salary float64
dtype: object3) 更改文件标头名
使用 names 参数可以指定头文件的名称。
import pandas as pd
import numpy as np
#需要注意文件的路径
df=pd.read_csv("./csv/test.csv", names=["A", "B", "C", "D", "E"])
print (df)
输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-excel-csv-one.py
A B C D E
0 ID Name Age City Salary
1 1 Jack 28 Beijing 22000
2 2 Lida 32 Shanghai 19000
3 3 John 43 Shenzhen 12000
4 4 Helen 38 Hengshui 3500注意:文件标头名是附加的自定义名称,但是您会发现,原来的标头名(列标签名)并没有被删除,此时您可以使用header参数来删除它。
通过传递标头所在行号实现删除,如下所示:
import pandas as pd
import numpy as np
#需要注意文件的路径
df=pd.read_csv("./csv/test.csv", names=["A", "B", "C", "D", "E"], header=0)
print (df)
输出结果
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-excel-csv-one.py
A B C D E
0 1 Jack 28 Beijing 22000
1 2 Lida 32 Shanghai 19000
2 3 John 43 Shenzhen 12000
3 4 Helen 38 Hengshui 35004) 跳过指定的行数
skiprows参数表示跳过指定的行数。
import pandas as pd
import numpy as np
#需要注意文件的路径
df=pd.read_csv("./csv/test.csv", names=["A", "B", "C", "D", "E"], header=0, skiprows=1)
print (df)
输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-excel-csv-one.py
A B C D E
0 2 Lida 32 Shanghai 19000
1 3 John 43 Shenzhen 12000
2 4 Helen 38 Hengshui 3500to_csv()
Pandas 提供的 to_csv() 函数用于将 DataFrame 转换为 CSV 数据。如果想要把 CSV 数据写入文件,只需向函数传递一个文件对象即可。否则,CSV 数据将以字符串格式返回。
import pandas as pd
import numpy as np
# 基于字典创建DataFrame 对象
data = {'Name': ['小王', '小周'], 'ID': [10, 20], 'Language': ['Python', 'JavaScript']}
info = pd.DataFrame(data)
print('DataFrame Values:\n', info)
#转换为csv数据
csv_data = info.to_csv()
print('\nCSV String Values:\n', csv_data) 输出结果:
PS E:\py_workspace\conda-demo> & D:/anaconda3/envs/python310/python.exe e:/py_workspace/conda-demo/pandas-excel-csv-two.py
DataFrame Values:
Name ID Language
0 小王 10 Python
1 小周 20 JavaScript
CSV String Values:
,Name,ID,Language
0,小王,10,Python
1,小周,20,JavaScript指定 CSV 文件输出时的分隔符,并将其保存在 pandas.csv 文件中,代码如下:
import pandas as pd
import numpy as np
# 基于字典创建DataFrame 对象
data = {'Name': ['小王', '小周'], 'ID': [10, 20], 'Language': ['Python', 'JavaScript']}
info = pd.DataFrame(data)
print('DataFrame Values:\n', info)
#写入指定csv数据文件, 温馨提示:在csv/文件夹下 创建pandas.csv 文件
csv_data = info.to_csv("./csv/pandas.csv",sep='|')查看pandas.csv 文件:

to_excel()
通过 to_excel() 函数可以将 Dataframe 中的数据写入到 Excel 文件。
如果想要把DataFrame对象写入 Excel 文件,那么必须指定目标文件名;如果想要写入到多张工作表中,则需要创建一个带有目标文件名的ExcelWriter对象,并通过sheet_name参数依次指定工作表的名称。
to_ecxel() 语法格式如下:
def to_excel(
self,
excel_writer,
sheet_name: str = "Sheet1",
na_rep: str = "",
float_format: str | None = None,
columns: Sequence[Hashable] | None = None,
header: Sequence[Hashable] | bool_t = True,
index: bool_t = True,
index_label: IndexLabel = None,
startrow: int = 0,
startcol: int = 0,
engine: str | None = None,
merge_cells: bool_t = True,
encoding: lib.NoDefault = lib.no_default,
inf_rep: str = "inf",
verbose: lib.NoDefault = lib.no_default,
freeze_panes: tuple[int, int] | None = None,
storage_options: StorageOptions = None,
) -> None:下表列出函数的常用参数项,如下表所示:

Python 功能代码:
import pandas as pd
import numpy as np
#创建DataFrame数据
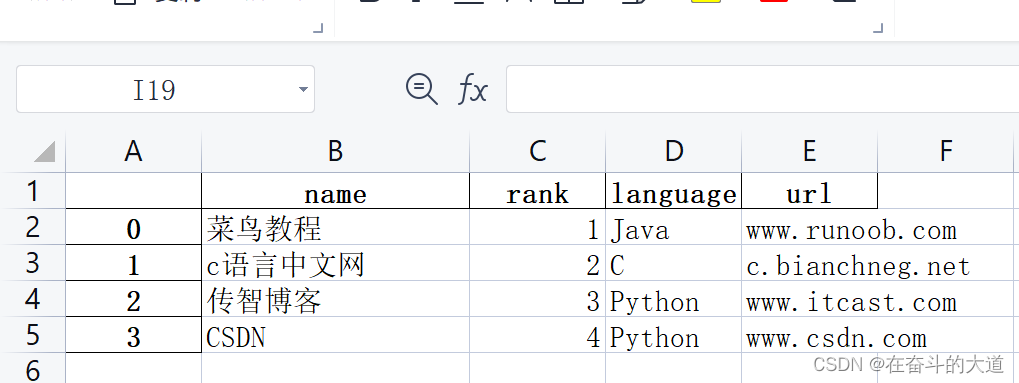
info_website = pd.DataFrame({'name': ['菜鸟教程', 'c语言中文网', '传智博客', 'CSDN'],
'rank': [1, 2, 3, 4],
'language': ['Java', 'C', 'Python','Python' ],
'url': ['www.runoob.com', 'c.bianchneg.net', 'www.itcast.com','www.csdn.com' ]})
#创建ExcelWrite对象
writer = pd.ExcelWriter('./excel/content.xlsx')
#DataFrame 写入指定excel 文件
info_website.to_excel(writer)
# 记得执行保存方法
writer.save()
print('输出成功')Excel 结果查看:
read_excel()
read_excel() 方法,其语法格式如下:
def read_excel(
io,
# sheet name is str or int -> DataFrame
sheet_name: str | int = ...,
header: int | Sequence[int] | None = ...,
names: list[str] | None = ...,
index_col: int | Sequence[int] | None = ...,
usecols: int
| str
| Sequence[int]
| Sequence[str]
| Callable[[str], bool]
| None = ...,
squeeze: bool | None = ...,
dtype: DtypeArg | None = ...,
engine: Literal["xlrd", "openpyxl", "odf", "pyxlsb"] | None = ...,
converters: dict[str, Callable] | dict[int, Callable] | None = ...,
true_values: Iterable[Hashable] | None = ...,
false_values: Iterable[Hashable] | None = ...,
skiprows: Sequence[int] | int | Callable[[int], object] | None = ...,
nrows: int | None = ...,
na_values=...,
keep_default_na: bool = ...,
na_filter: bool = ...,
verbose: bool = ...,
parse_dates: list | dict | bool = ...,
date_parser: Callable | None = ...,
thousands: str | None = ...,
decimal: str = ...,
comment: str | None = ...,
skipfooter: int = ...,
convert_float: bool | None = ...,
mangle_dupe_cols: bool = ...,
storage_options: StorageOptions = ...,
) -> DataFrame:下表对常用参数做了说明:

Python 功能代码
#读取excel数据
df = pd.read_excel('./excel/content.xlsx',index_col='name',skiprows=[2])
print(df)
#修改列 名称
df.columns = df.columns.str.replace('url.*', '地址')
print(df)输出结果:
e:\py_workspace\conda-demo\pandas-excel-csv-three.py:23: FutureWarning: The default value of regex will change from True to False in a future version.
df.columns = df.columns.str.replace('url.*', '地址')
Unnamed: 0 rank language 地址
name
菜鸟教程 0 1 Java www.runoob.com
传智博客 2 3 Python www.itcast.com
CSDN 3 4 Python www.csdn.com至此,Pandas 快速入门到此结束。
补充参考资料: