因为我本人主要课题方向是处理图像的,RNN是基本的序列处理模型,主要应用于自然语言处理,故这里就简单的学习一下,了解为主
一、问题引入
已知以前的天气数据信息,进行预测当天(4-9)是否下雨
| 日期 | 温度 | 气压 | 是否下雨 |
|---|---|---|---|
| 4-1 | 10 | 20 | 否 |
| 4-2 | 30 | 40 | 是 |
| 4-3 | 40 | 25 | 是 |
| 4-4 | 10 | 30 | 是 |
| 4-5 | 5 | 10 | 否 |
| 4-6 | 10 | 20 | 是 |
| 4-7 | 12 | 60 | 否 |
| 4-8 | 25 | 80 | 是 |
| 4-9 | 20 | 15 | ? |
这里的数据集都是随别胡乱写的哈,就说在阐述一下待解决的问题,随别做的数据集
思路:可以四天一组,每组中有4天的天气信息,包括温度、气压、是否下雨
前三天作为输入,第四天最为输出
在卷积神经网络中,全连接层是权重最多的,也是整个网络中计算量最多的地方
卷积中
输入:128通道
输出:64通道
卷积核:5×5
总共的权重参数:128×64×5×5 = 204800
全连接中
一般都不会直接将一个高维通道直接变为1,而是多几个中间层进行过度
输入:4096
输出:1024
权重参数个数:4096×1024 = 4194304
权重参数个数压根都不在一个数量级上,所以说,正因为卷积的权重共享,导致卷积操作所需参数远小于全连接
RNN循环神经网络主要用在具有序列关系的数据中进行处理,例如:天气的预测,因为前后的天气会相互影响,并不会断崖式的变化、股市预测等,典型的就是自然语言处理
我喜欢beyond乐队这句话的词语之间具有序列关系,随便调换顺序产生的结果肯定很难理解
二、RNN循环神经网络
Ⅰ,RNN Cell
RNN Cell是RNN中的核心单元
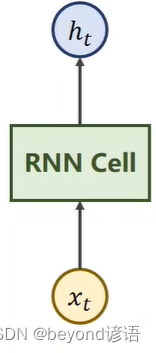
xt:序列当中,时刻t时的数据,这个数据具有一定的维度,例如天气数据就是3D向量的,即,温度、气压、是否下雨
xt通过RNN Cell之后就会得到一个ht,这个数据也是具有一定的维度,假如是5D向量
从xt这个3D向量数据通过RNN Cell得到一个ht这个5D向量数据,很明显,这个RNN Cell本质就是一个线性层
区别:RNN Cell这个线性层是共享的
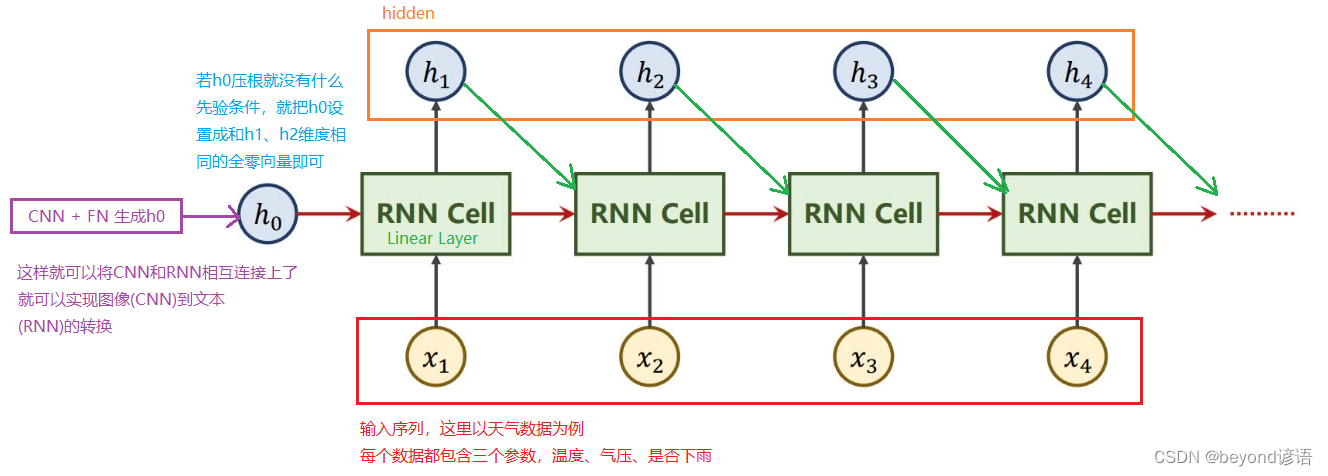

RNN Cell基本流程

现学现卖

import torch
#根据需求设定参数
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
yy_cell = torch.nn.RNNCell(input_size=input_size,hidden_size=hidden_size)
dataset = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(batch_size,hidden_size) #h0设置为全0
for idx,inputs in enumerate(dataset):
print('-----------------)
print("Input size:",inputs.shape)
hidden = yy_cell(inputs,hidden)
print("outputs size:",hidden.shape)
print(hidden)
"""
==================== 0 ====================
Input size: torch.Size([1, 4])
outputs size: torch.Size([1, 2])
tensor([[ 0.6377, -0.4208]], grad_fn=<TanhBackward0>)
==================== 1 ====================
Input size: torch.Size([1, 4])
outputs size: torch.Size([1, 2])
tensor([[-0.2049, 0.6174]], grad_fn=<TanhBackward0>)
==================== 2 ====================
Input size: torch.Size([1, 4])
outputs size: torch.Size([1, 2])
tensor([[-0.1482, -0.2232]], grad_fn=<TanhBackward0>)
"""
Ⅱ,RNN

现学现卖
import torch
#根据需求设定参数
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 2 #两层RNN Cell
cell = torch.nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers)
inputs = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(num_layers,batch_size,hidden_size) #h0设置为全0
out,hidden = cell(inputs,hidden)
print('output size:',out.shape)
print('output:',out)
print('hidden size:',hidden.shape)
print('hidden',hidden)
"""
output size: torch.Size([3, 1, 2])
output: tensor([[[ 0.8465, -0.1636]],
[[ 0.3185, -0.1733]],
[[ 0.0269, -0.1330]]], grad_fn=<StackBackward0>)
hidden size: torch.Size([2, 1, 2])
hidden tensor([[[ 0.5514, 0.8349]],
[[ 0.0269, -0.1330]]], grad_fn=<StackBackward0>)
"""
三、RNN实战
需求:实现将输入beyond转换为ynbode
①文本转向量one-hot
因为RNN Cell单元输入的数据必须是由单词构成的向量 ,根据字符来构建一个词典,并为其分配索引,索引变One-Hot向量,词典中有几项,最终构建的向量也有几列,只能出现一个1,其余都为0
| character | index |
|---|---|
| b | 0 |
| d | 1 |
| e | 2 |
| n | 3 |
| o | 4 |
| y | 5 |


②模型训练
Ⅰ RNN Cell
import torch
input_size = 6
hidden_size = 6
batch_size = 1
dictionary = ['b','e','y','o','n','d'] #字典
x_data = [0,1,2,3,4,5] #beyond
y_data = [2,4,0,3,5,1] #ynbode
one_hot = [[1,0,0,0,0,0],
[0,1,0,0,0,0],
[0,0,1,0,0,0],
[0,0,0,1,0,0],
[0,0,0,0,1,0],
[0,0,0,0,0,1]]
x_one_hot = [one_hot[x] for x in x_data] #将x_data的每个元素从one_hot得到相对于的向量形式
inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size) #inputs形式为(seqlen,batch_size,input_size)
labels = torch.LongTensor(y_data).view(-1,1) #lables形式为(seqlen,1)
class y_rnncell_model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size):
super(y_rnncell_model,self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size,hidden_size=self.hidden_size)
def forward(self,inputs,labels):
hidden = self.rnncell(inputs,labels)
return hidden
def init_hidden(self): #定义h0初始化
return torch.zeros(self.batch_size,self.hidden_size)
y_net = y_rnncell_model(input_size,hidden_size,batch_size)
#定义损失函数和优化器
lossf = torch.nn.CrossEntropyLoss()
optim = torch.optim.Adam(y_net.parameters(),lr=0.001)
# RNN Cell
for epoch in range(800):
loss = 0
optim.zero_grad() #优化器梯度归零
hidden = y_net.init_hidden() #h0
print('Predicted string:',end='')
for x,y in zip(inputs,labels):
hidden = y_net(x,hidden)
loss += lossf(hidden,y) #计算损失之和,需要构造计算图
_,idx = hidden.max(dim=1)
print(dictionary[idx.item()],end='')
loss.backward()
optim.step()
print(',Epoch [%d/20] loss=%.4f'%(epoch+1,loss.item()))
Ⅱ RNN
#引入torch
import torch
input_size = 6 #beyond
hidden_size = 6 #
num_layers = 1
batch_size = 1
seq_len = 6
idx2char = ['b','d','e','n','o','y'] #字典
x_data = [0,2,5,4,3,1] #beyond
y_data = [5,3,0,4,1,2] #ynbode
one_hot = [[1,0,0,0,0,0],
[0,1,0,0,0,0],
[0,0,1,0,0,0],
[0,0,0,1,0,0],
[0,0,0,0,1,0],
[0,0,0,0,0,1]]
x_one_hot = [one_hot[x] for x in x_data] #将x_data的每个元素从one_hot得到相对于的向量形式
inputs = torch.Tensor(x_one_hot).view(seq_len,batch_size,input_size)
labels = torch.LongTensor(y_data)
class y_rnn_model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size,num_layers):
super(y_rnn_model,self).__init__()
self.num_layers = num_layers
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size=self.input_size,hidden_size=self.hidden_size,num_layers=self.num_layers)
def forward(self,inputs):
hidden = torch.zeros(self.num_layers,
self.batch_size,
self.hidden_size)#构造h0
out,_ = self.rnn(inputs,hidden)
return out.view(-1,self.hidden_size) #(seqlen×batchsize,hiddensize)
net = y_rnn_model(input_size,hidden_size,batch_size,num_layers)
lessf = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr=0.05)
for epoch in range(30):
optimizer.zero_grad()
outputs = net(inputs)
loss = lessf(outputs,labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted:',''.join([idx2char[x] for x in idx]),end='')
print(',Epoch[%d/15] loss=%.3f' % (epoch+1,loss.item()))
③one-hot的不足
1,维度过高;一个单词得占用一个维度
2,one-hot向量过于稀疏;就一个1,其余全是0
3,硬编码;一对一
解决方法:EMBEDDING
思路:将高维的向量映射到一个稠密的低维的向量空间里面
即:数据的降维
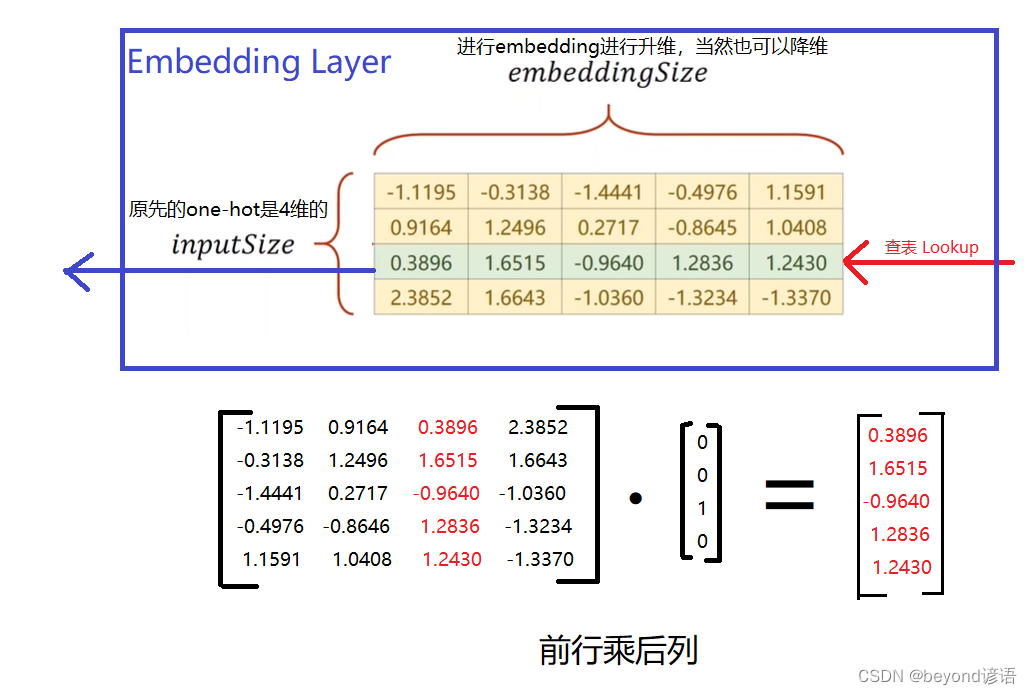
四、Embeding模块
优化RNN
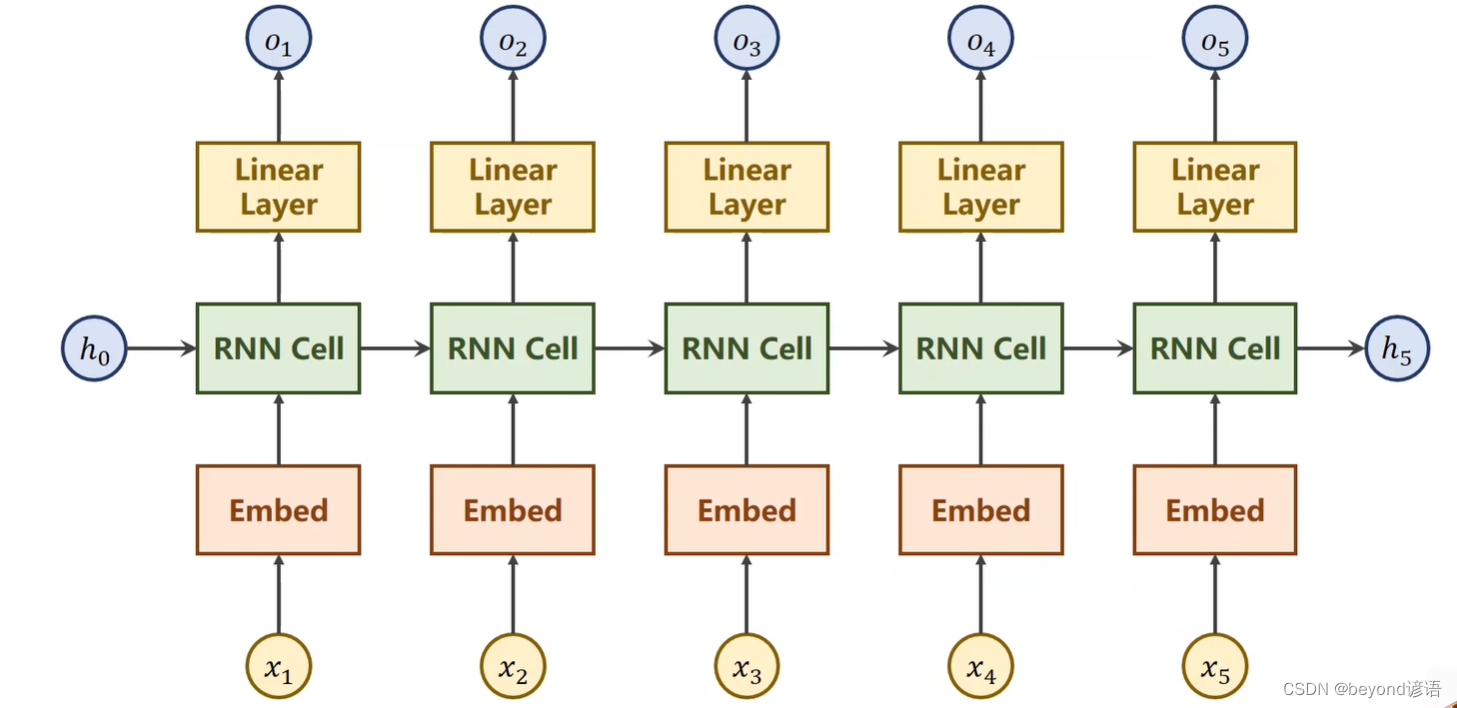
官网torch.nn.Embedding(…)函数详细参数解释
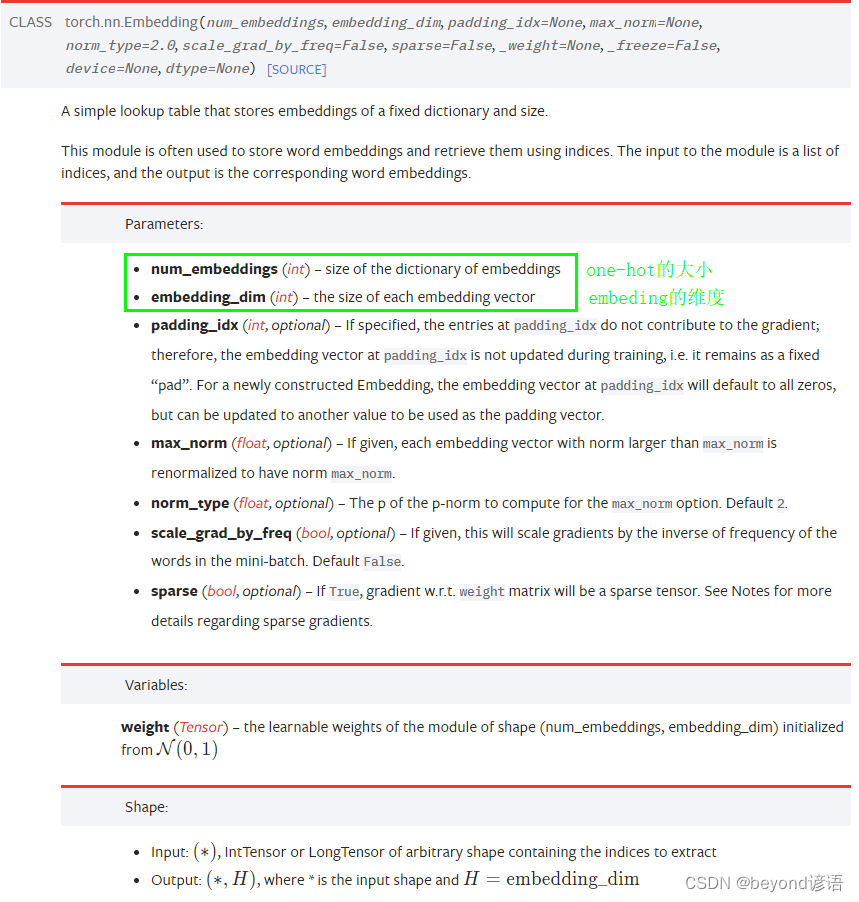
| 参数 | 含义 |
|---|---|
| num_embeddings | one-hot的维度 |
| embedding_dim | embedding的维度 |
| Input: (*)(∗), IntTensor or LongTensor of arbitrary shape containing the indices to extract | 输入需要是一个整型或者长整型IntTensor or LongTensor |
| Output: (*, H), where * is the input shape and H=embedding_dim | (input shape,embedding_dim ) |
import torch
num_class = 6 #类别数6个,'b','d','e','n','o','y'
input_size = 6 #输入6 beyond
seq_len = 6
hidden_size = 8 #输出8维
embedding_size = 10 #嵌入层设置为10层
num_layers = 2 #2层RNN Cell
batch_size = 1
dictionary = ['b','d','e','n','o','y'] #字典
x_data = [[0,2,5,4,3,1]] #beyond (batch_size,seqlen)
y_data = [5,3,0,4,1,2] #ynbode (batch_size * seqlen)
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, num_layers, num_class):
super(Model, self).__init__()
self.embed = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size,hidden_size=hidden_size,num_layers=num_layers,batch_first=True)#batch_first=True 需要注意点格式
#input (batch_size,seqlen,embeddingsize)
#output (batch_size,seqlen,hidden_size)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.embed(x) # (batch, seqLen, embeddingSize)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class) #(batch_size×seqlen,numclass)
emb_net = Model(input_size, embedding_size, hidden_size, num_layers, num_class)
lessf = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(emb_net.parameters(),lr=0.05)
for epoch in range(30):
optimizer.zero_grad()
outputs = emb_net(inputs)
loss = lessf(outputs,labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted:',''.join([dictionary[x] for x in idx]),end='')
print(',Epoch[%d/15] loss=%.3f' % (epoch+1,loss.item()))
五、LSTM(长短时记忆网络)
因为我是主要做图像方面的课题,故这个网络我就不去深究了,感兴趣的家人们可以去官网学习学习,官网API:torch.nn.LSTM(*args, **kwargs)
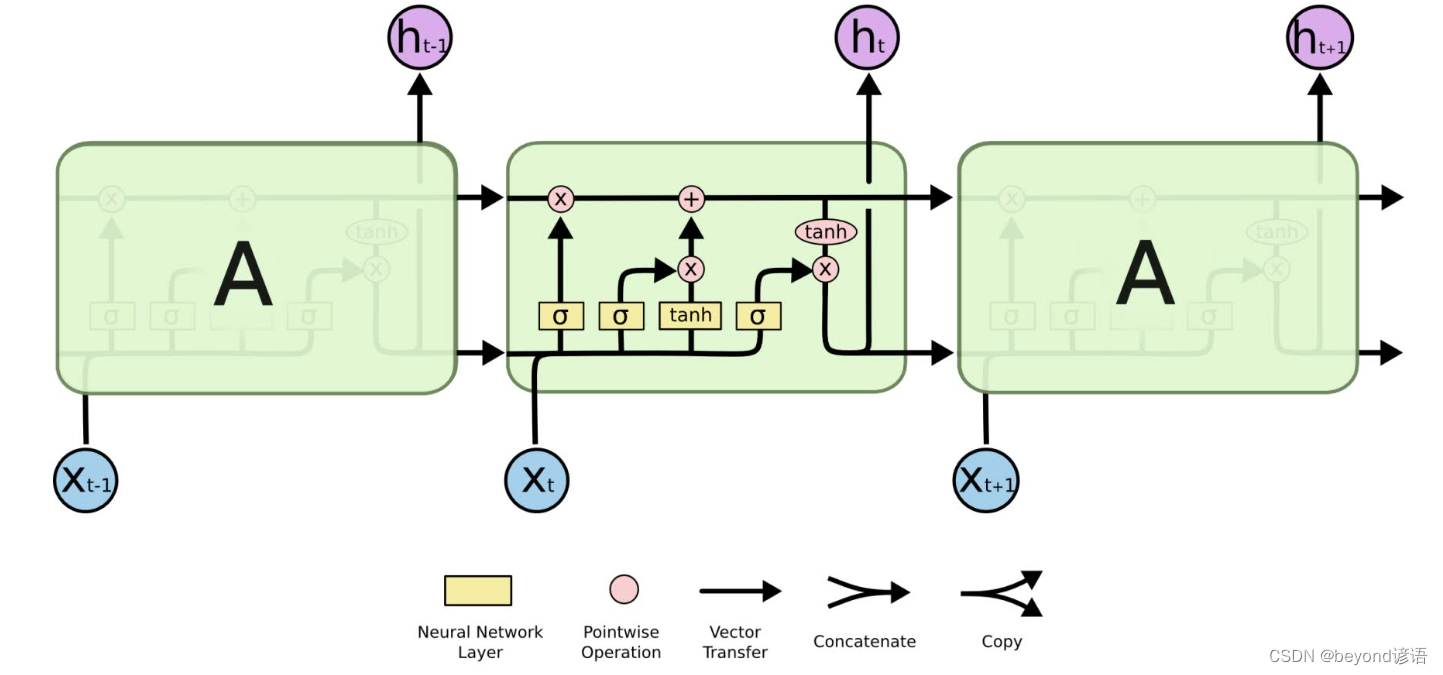
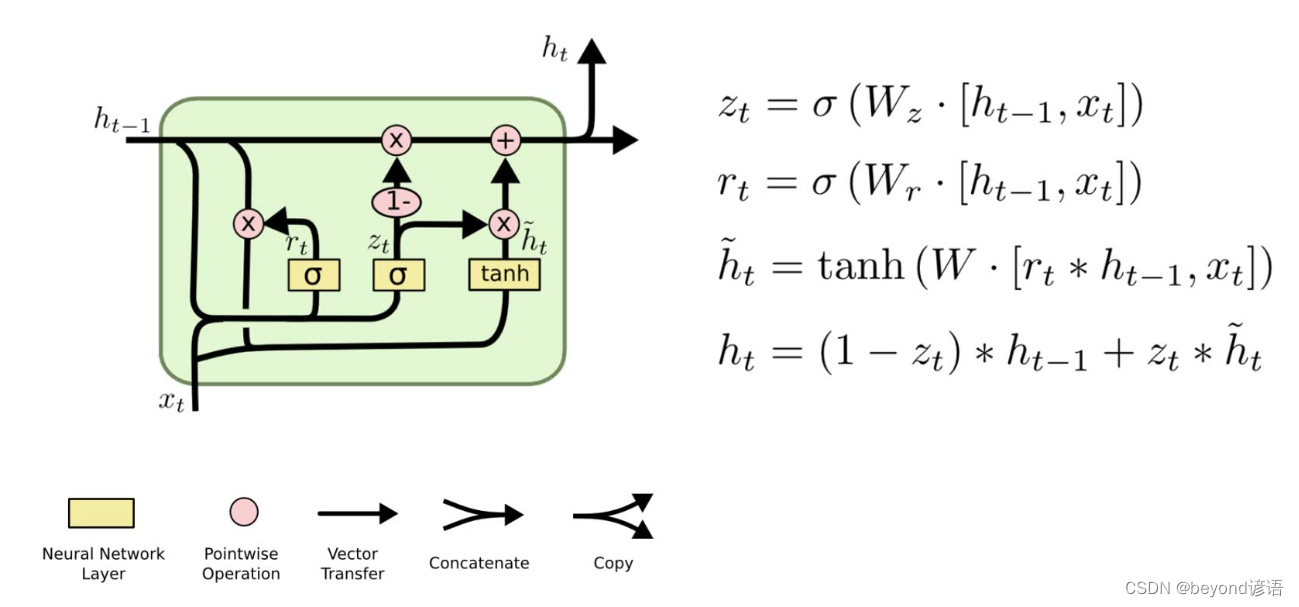
六、GRU模型
官网API:torch.nn.GLU(dim = -1)