脏页落盘
什么是脏页?
对数据的修改,首先改内存中的缓冲池的页,由于缓冲区的数据跟磁盘中的数据不一致,所以称缓冲区的页为脏页。
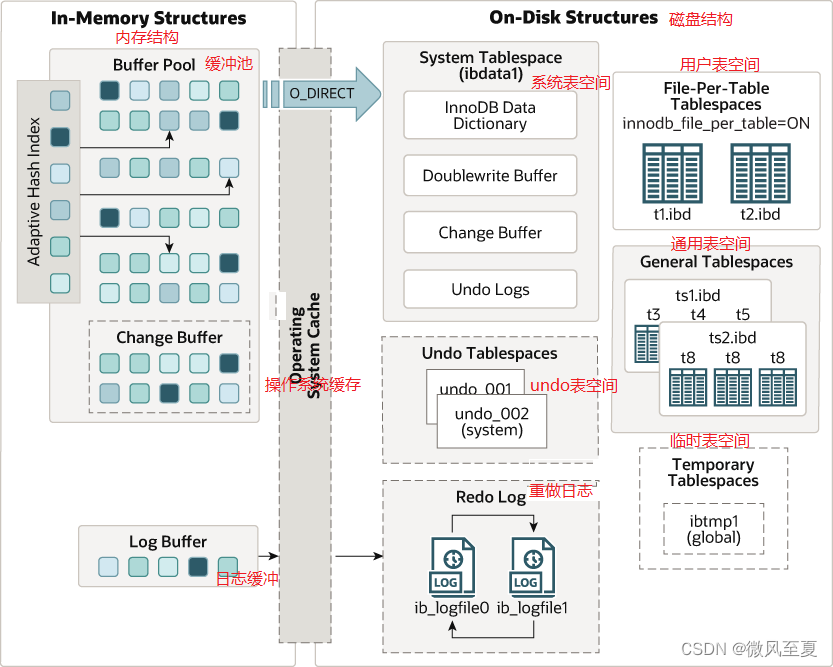
脏页如何写入到磁盘?
不是每次更新都触发脏页落盘,而是通过CheckPoint机制刷新磁盘。
InnoDB数据落盘流程(大概)
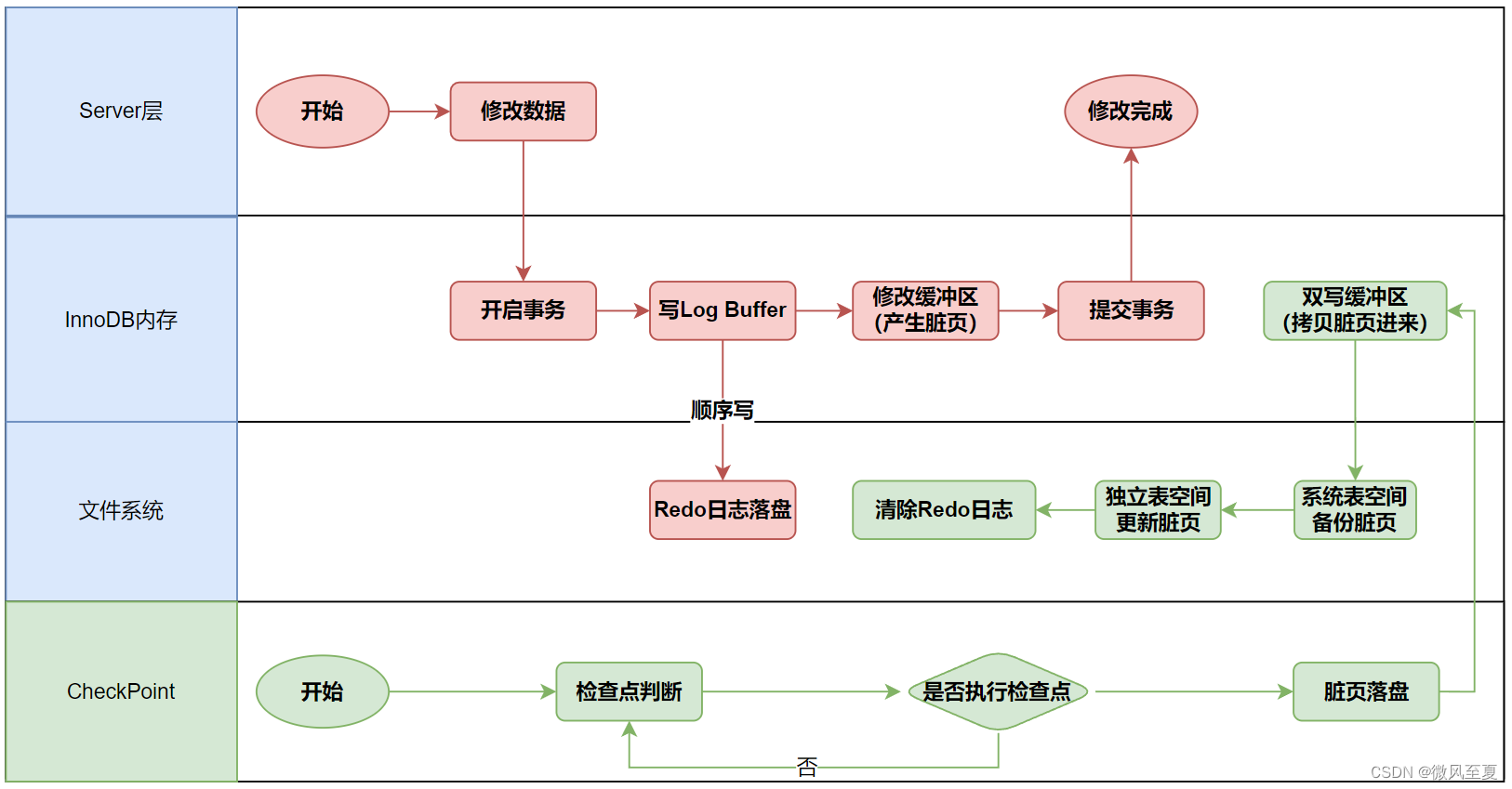
为什么性能好
- 从流程中,可以看到,事务的操作全是在内存中进行,所以性能好。
如何持久化
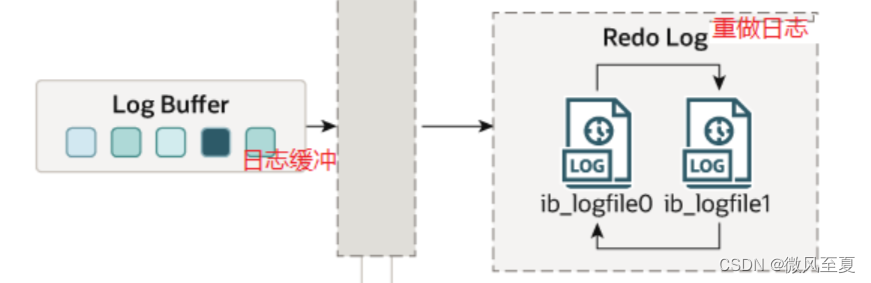
- 在修改缓冲区之前,所有操作先写入Log Buffer,提交事务之前持久化到Redio日志,后面通过CheckPoint机制,将脏页落盘。
如何保证数据安全
- Write Ahead Log 策略(日志先行)。
- Force Log at Commit机制(提交事务时,将日志写入到磁盘)。
- CheckPoint机制。
- 双写机制:脏页拷贝到双写缓冲区之后,持久化到对应系统表空间的位置,然后把脏页更新到独立表空间,最后清除Redo日志。
为什么不马上更新到磁盘?
- 因为每次页的更新,都落盘的话,必将伴随4次磁盘IO,性能不会很高,随着写入操作的增加,性能指数下降。
如何确保日志安全进入磁盘?
- 日志写入Log Buffer之后,调用fsync函数确保日志从缓存写入磁盘。
fsync的功能是确保文件fd所有已修改的内容已经正确同步到硬盘上,该调用会阻塞等待直到设备报告IO完成。
Redo日志落盘策略
写入磁盘时机由 innodb_flush_log_at_trx_commit 控制。
- 0:每秒写入,跟事务无关,最多丢失1秒的的事务操作。
- 1:事务提交时写入磁盘,不丢失数据,效率也是最低。
- 2:事务提交,写入OS Buffer,间隔1秒写入,性能、安全性相比前两个居中。
CheckPoint机制
解决了什么问题
对缓冲池的操作,避免了直接修改磁盘,但是数据最终还是要写入到磁盘,通过此机制,不断将脏页落盘,这样可以减少Redo日志大小,在宕机的时候不用重做所有日志;
同时可以缓冲池内存不够用;
刷新脏页,还可以循环使用Redo日志,不会无限增大。
分类
sharp checkpoint:关闭数据库时,将缓冲池的脏页全部刷新到磁盘。
fuzzy checkpoint:数据库运行期间,选择不同时机将部分脏页写入磁盘。避免刷新全部带来的性能问题。
- Master Thread Checkpoint:固定频率刷新部分脏页到磁盘,异步操作不会阻塞用户线程。
- FLUSH_LRU_LIST Checkpoint:缓冲池淘汰非热点Page,如果该Page是脏页会执行CheckPoint。
- Async/Sync Flush Checkpoint:redo日志不可用时,强制脏页落盘,有了前两个这种一般不会发生。
- Dirty Page too much Checkpoint:脏页占比太多强制进行刷盘,阈值75%
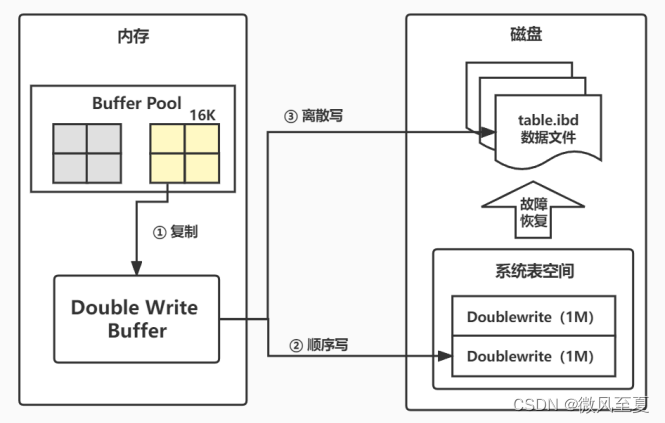
Double Write机制
如果写入脏页时发生宕机怎么办法?
我们在修改更新Redo日志时,先将缓冲池的脏页拷贝到双写缓冲区,然后将数据顺序写到系统表空间的双写缓冲区,再离散写入独立表空间。这样,即使发生宕机,数据也能从系统表空间中恢复。
Redo日志只记录对页的修改而非数据本身。
从缓冲池复制到双写缓冲区 -> 顺序写入系统表空间 -> 离散写入独立表空间。



![[附源码]计算机毕业设计springboot餐馆点餐管理系统](https://img-blog.csdnimg.cn/680a81d53114401cb1710cd74fd42c62.png)