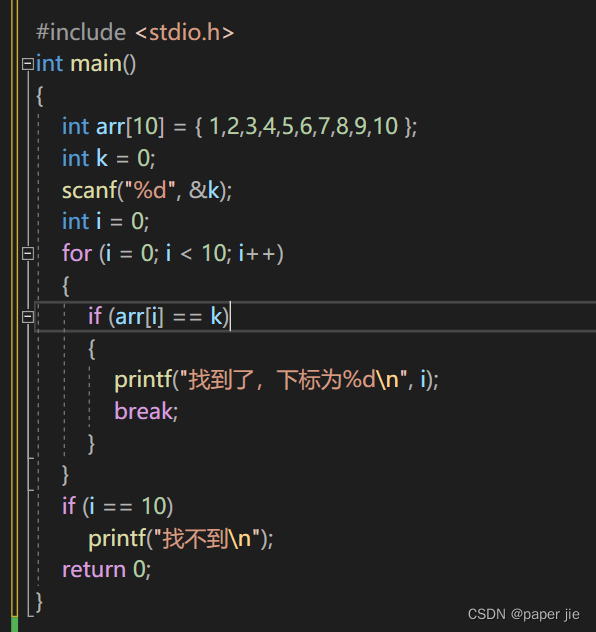
Cat原理简析
- 链路追踪系统设计思路
- 如何高效组织业务日志
- 如何动态串联业务日志
- 通用解决方案
- 链路定义
- 链路染色
- 链路上报
- 链路存储
- Cat原理
- 客户端原理
- API设计
- 序列化和通信
- 客户端埋点
- 核心类分析
- 流程分析
- 启动流程:
- 消息生产
- Context 线程本地变量
- Transaction事务的开启
- 其他类型消息组合
- 关闭Transaction:
- 发送数据
- 消息序列化
- MessageID
- 服务端原理
- 存储数据设计
- 小结
本文为Cat链路追踪监控工具原理简析篇,主要参考官方文档和其他资料整理而来:
- 官方文档: Cat设计方案
- 美团技术团队: CAT 3.0 开源发布,支持多语言客户端及多项性能提升-
- 美团技术团队: 深度剖析开源分布式监控CAT
- 美团技术团队: 可视化全链路日志追踪
- 美团技术团队: 日志篇文章汇总
- 美团技术团队: 分布式会话跟踪系统架构设计与实践
- 凤凰架构: 可观测性
- 美团点评CAT源码分析
链路追踪系统设计思路
链路追踪系统设计需要考虑三个方面:
- 事件日志
- 输出
- 收集与缓冲
- 加工与聚合
- 存储与查询
- 链路追踪
- 追踪与跨度
- 数据收集方式
- 聚合指标
- 指标收集
- 存储查询
- 监控告警
本节主要针对链路追踪这个环节进行讨论,链路追踪的难点在于:
- 如何从大量离散日志中快速收集并筛选出需要的日志,并按照链路执行流程串联起来进行可视化展示,即可视化的全链路日志追踪
可视化的全链路日志追踪需要解决两个问题:
- 如何高效组织业务日志
- 为了实现高效的业务追踪,首先需要准确完整地描述出业务逻辑,形成业务逻辑的全景图,而业务追踪其实就是通过执行时的日志数据,在全景图中还原出业务执行的现场。
- 如何动态串联业务日志
- 业务逻辑执行时的日志数据原本是离散存储的,而此时需要实现的是,随着业务逻辑的执行动态串联各个逻辑节点的日志,进而还原出完整的业务逻辑执行现场。
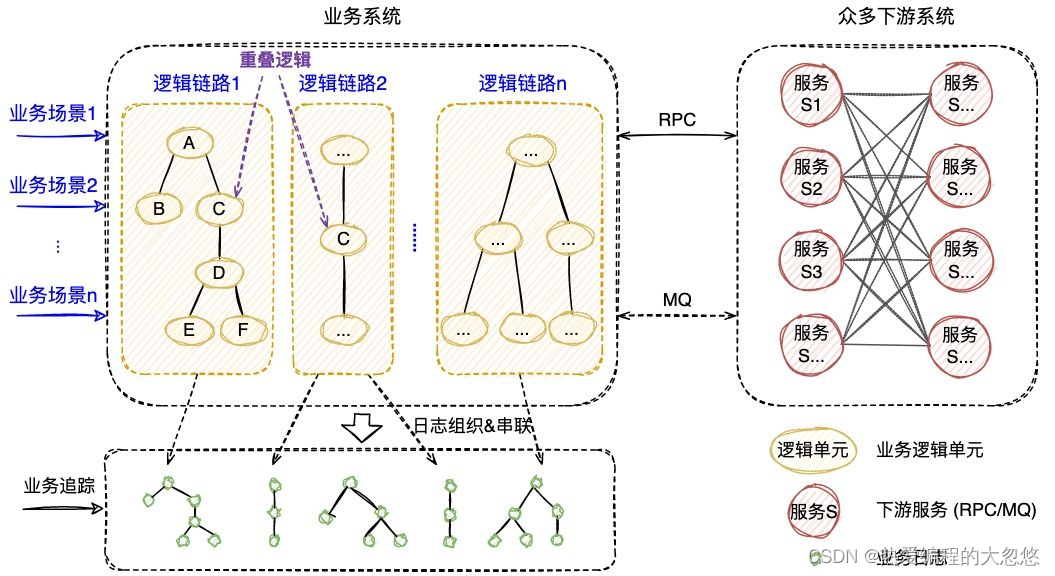
- 业务逻辑执行时的日志数据原本是离散存储的,而此时需要实现的是,随着业务逻辑的执行动态串联各个逻辑节点的日志,进而还原出完整的业务逻辑执行现场。
如何高效组织业务日志
通过对业务逻辑进行抽象,定义出业务逻辑链路:
- 逻辑节点:业务系统的众多逻辑可以按照业务功能进行拆分,形成一个个相互独立的业务逻辑单元,即逻辑节点,可以是本地方法也可以是RPC等远程调用方法。
- 逻辑链路:业务系统对外支撑着众多的业务场景,每个业务场景对应一个完整的业务流程,可以抽象为由逻辑节点组合而成的逻辑链路。
一次业务追踪就是逻辑链路的某一次执行情况的还原,逻辑链路完整准确地描述了业务逻辑全景,同时作为载体可以实现业务日志的高效组织。
如何动态串联业务日志
由于逻辑节点之间、逻辑节点内部往往通过MQ或者RPC等进行交互,所以可以采用分布式会话跟踪提供的分布式参数透传能力实现业务日志的动态串联:
- 通过在执行线程和网络通信中持续地透传参数,实现在业务逻辑执行的同时,不中断地传递链路和节点的标识,实现离散日志的染色。
- 基于标识,染色的离散日志会被动态串联至正在执行的节点,逐渐汇聚出完整的逻辑链路,最终实现业务执行现场的高效组织和可视化展示。
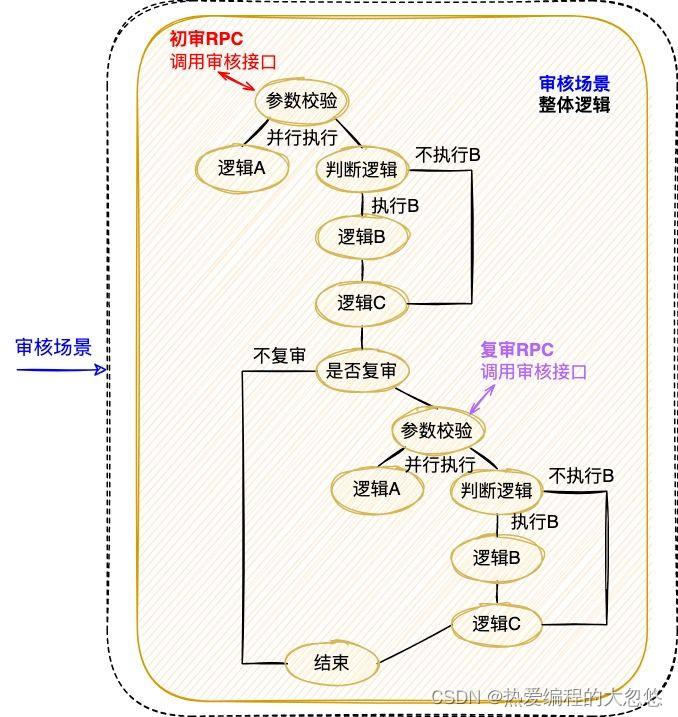
与分布式会话跟踪方案不同的是,当同时串联多次分布式调用时,需要结合业务逻辑选取一个公共id作为标识。
例如上面的审核场景涉及2次RPC调用,为了保证2次执行被串联至同一条逻辑链路,此时结合审核业务场景,选择初审和复审相同的“任务id”作为标识,完整地实现审核场景的逻辑链路串联和执行现场还原。
通用解决方案
明确日志的高效组织和动态串联这两个基本问题后,通用解决方案可以拆解为以下步骤:
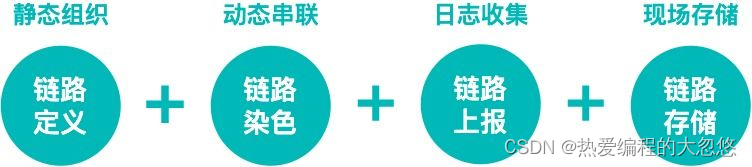
链路定义
“链路定义”的含义为:使用特定语言,静态描述完整的逻辑链路,链路通常由多个逻辑节点,按照一定的业务规则组合而成,业务规则即各个逻辑节点之间存在的执行关系,包括串行、并行、条件分支。
DSL(Domain Specific Language)是为了解决某一类任务而专门设计的计算机语言,可以通过JSON或XML定义出一系列节点(逻辑节点)的组合关系(业务规则)。因此,本方案选择使用DSL描述逻辑链路,实现逻辑链路从抽象定义到具体实现。
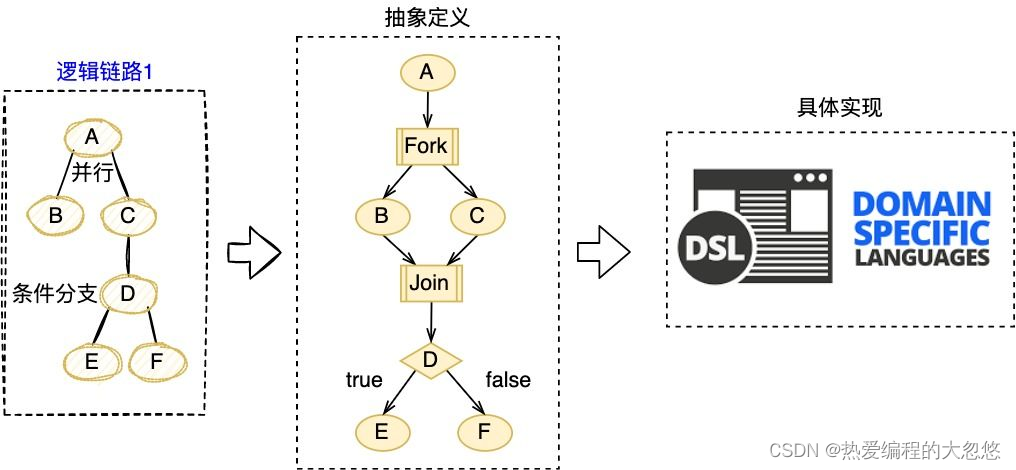
- 逻辑链路1-DSL:
[
{
"nodeName": "A",
"nodeType": "rpc"
},
{
"nodeName": "Fork",
"nodeType": "fork",
"forkNodes": [
[
{
"nodeName": "B",
"nodeType": "rpc"
}
],
[
{
"nodeName": "C",
"nodeType": "local"
}
]
]
},
{
"nodeName": "Join",
"nodeType": "join",
"joinOnList": [
"B",
"C"
]
},
{
"nodeName": "D",
"nodeType": "decision",
"decisionCases": {
"true": [
{
"nodeName": "E",
"nodeType": "rpc"
}
]
},
"defaultCase": [
{
"nodeName": "F",
"nodeType": "rpc"
}
]
}
]
链路染色
“链路染色”的含义为:在链路执行过程中,通过透传串联标识,明确具体是哪条链路在执行,执行到了哪个节点。
链路染色包括两个步骤:
- 步骤一:确定串联标识,当逻辑链路开启时,确定唯一标识,能够明确后续待执行的链路和节点。
- 链路唯一标识 = 业务标识 + 场景标识 + 执行标识 (三个标识共同决定“某个业务场景下的某次执行”)
- 业务标识:赋予链路业务含义,例如“用户id”、“活动id”等等。
- 场景标识:赋予链路场景含义,例如当前场景是“逻辑链路1”。
- 执行标识:赋予链路执行含义,例如只涉及单次调用时,可以直接选择“traceId”;涉及多次调用时则,根据业务逻辑选取多次调用相同的“公共id”。
- 节点唯一标识 = 链路唯一标识 + 节点名称 (两个标识共同决定“某个业务场景下的某次执行中的某个逻辑节点”)
- 节点名称:DSL中预设的节点唯一名称,如“A”。
- 步骤二:传递串联标识,当逻辑链路执行时,在分布式的完整链路中透传串联标识,动态串联链路中已执行的节点,实现链路的染色。例如在“逻辑链路1”中:
- 当“A”节点触发执行,则开始在后续链路和节点中传递串联标识,随着业务流程的执行,逐步完成整个链路的染色。
- 当标识传递至“E”节点时,则表示“D”条件分支的判断结果是“true”,同时动态地将“E”节点串联至已执行的链路中。
链路上报
“链路上报”的含义为:在链路执行过程中,将日志以链路的组织形式进行上报,实现业务现场的准确保存。
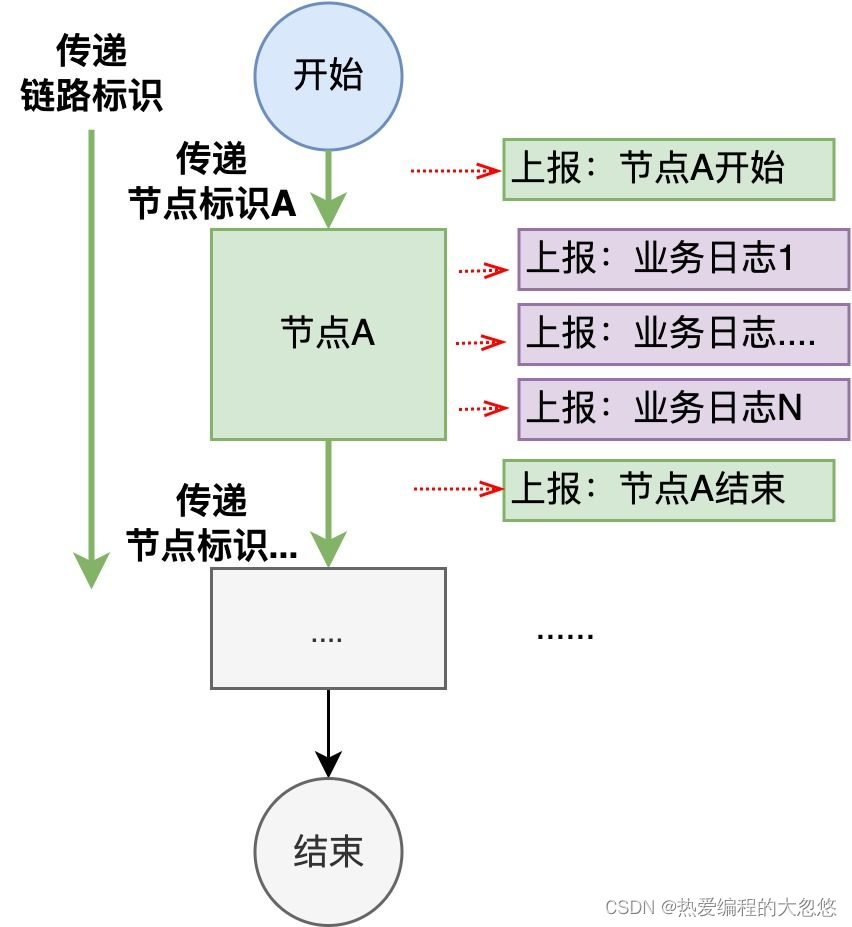
上报的日志数据包括:节点日志和业务日志。
- 节点日志的作用是绘制链路中的已执行节点,记录了节点的开始、结束、输入、输出;
- 业务日志的作用是展示链路节点具体业务逻辑的执行情况,记录了任何对业务逻辑起到解释作用的数据,包括与上下游交互的入参出参、复杂逻辑的中间变量、逻辑执行抛出的异常。
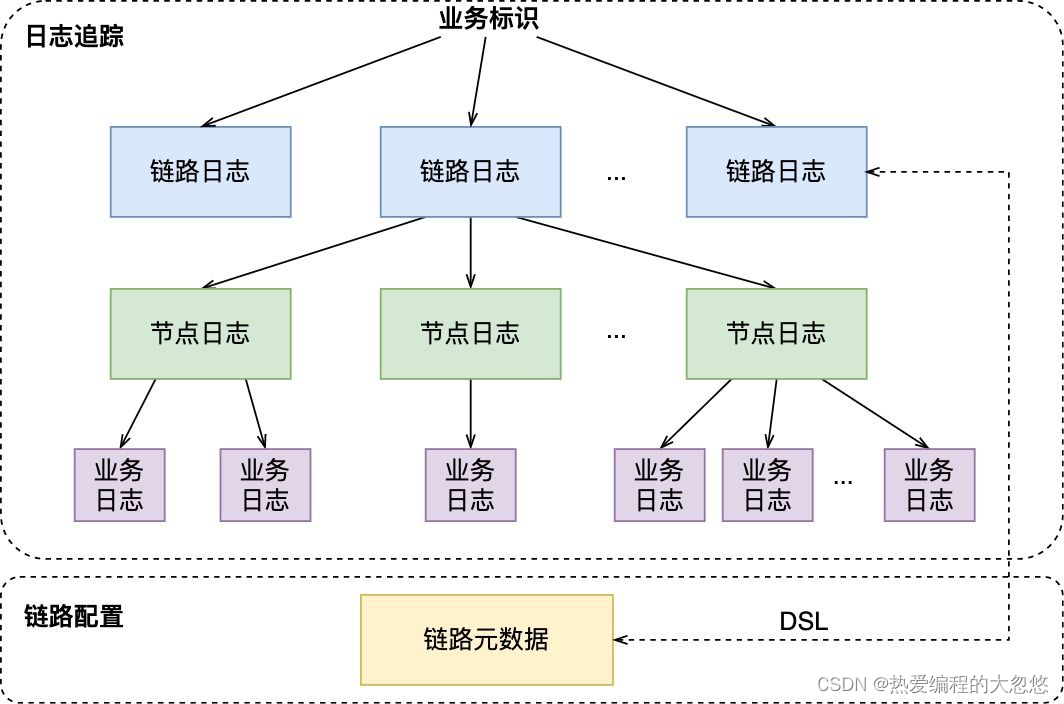
链路存储
“链路存储”的含义为:将链路执行中上报的日志落地存储,并用于后续的“现场还原”。上报日志可以拆分为链路日志、节点日志和业务日志三类:
- 链路日志:链路单次执行中,从开始节点和结束节点的日志中提取的链路基本信息,包含链路类型、链路元信息、链路开始/结束时间等。
- 节点日志:链路单次执行中,已执行节点的基本信息,包含节点名称、节点状态、节点开始/结束时间等。
- 业务日志:链路单次执行中,已执行节点中的业务日志信息,包含日志级别、日志时间、日志数据等。
下图就是链路存储的存储模型,包含了链路日志,节点日志,业务日志、链路元数据(配置数据),并且是如下图所示的树状结构,其中业务标识作为根节点,用于后续的链路查询。
Cat原理
监控整体要求就是快速发现故障、快速定位故障以及辅助进行程序性能优化。为了做到这些,监控系统需要具备以下要求:
- 实时处理:信息的价值会随时间锐减,尤其是事故处理过程中。
- 全量数据:最开始的设计目标就是全量采集,全量的好处有很多。
- 高可用:所有应用都倒下了,需要监控还站着,并告诉工程师发生了什么,做到故障还原和问题定位。
- 故障容忍:CAT本身故障不应该影响业务正常运转,CAT挂了,应用不该受影响,只是监控能力暂时减弱。
- 高吞吐:要想还原真相,需要全方位地监控和度量,必须要有超强的处理吞吐能力。
- 可扩展:支持分布式、跨IDC部署,横向扩展的监控系统。
- 不保证可靠:允许消息丢失,这是一个很重要的trade-off,目前CAT服务端可以做到4个9的可靠性,可靠系统和不可靠性系统的设计差别非常大。
在整个CAT从开发至今,一直秉承着简单的架构就是最好的架构原则,整个CAT主要分为三个模块,cat-client,cat-consumer,cat-home。
- cat-client 提供给业务以及中间层埋点的底层sdk。
- cat-consumer 用于实时分析从客户端提供的数据。
- cat-home 作为用户提供给用户的展示的控制端。
在实际开发和部署中,cat-consumer和cat-home是部署在一个jvm内部,每个CAT服务端都可以作为consumer也可以作为home,这样既能减少整个CAT层级结构,也可以增加整个系统稳定性。
客户端原理
客户端设计是CAT系统设计中最为核心的一个环节,客户端要求是做到API简单、高可靠性能,因为监控只是公司核心业务流程一个旁路环节,无论在任何场景下都不能影响业务性能。
CAT客户端在收集端数据方面使用ThreadLocal(线程局部变量),是线程本地变量,也可以称之为线程本地存储。其实ThreadLocal的功用非常简单,就是为每一个使用该变量的线程都提供一个变量值的副本,属于Java中一种较为特殊的线程绑定机制,每一个线程都可以独立地改变自己的副本,不会和其它线程的副本冲突。
在监控场景下,为用户提供服务都是Web容器,比如tomcat或者Jetty,后端的RPC服务端比如Dubbo或者Pigeon,也都是基于线程池来实现的。业务方在处理业务逻辑时基本都是在一个线程内部调用后端服务、数据库、缓存等,将这些数据拿回来再进行业务逻辑封装,最后将结果展示给用户。所以将所有的监控请求作为一个监控上下文存入线程变量就非常合适。
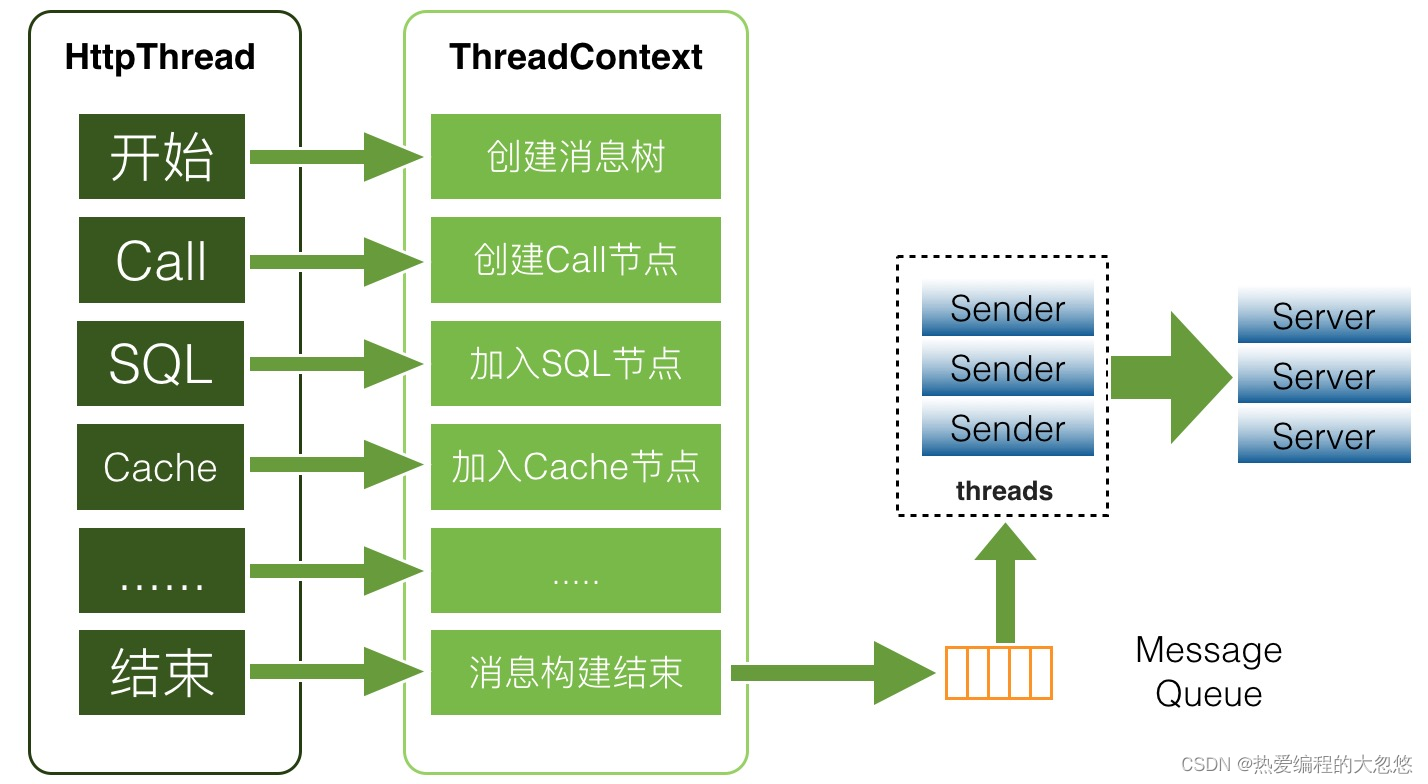
如上图所示,业务执行业务逻辑的时候,就会把此次请求对应的监控存放于线程上下文中,存于上下文的其实是一个监控树的结构。在最后业务线程执行结束时,将监控对象存入一个异步内存队列中,CAT有个消费线程将队列内的数据异步发送到服务端。
总结流程如下:
- 业务线程产生消息,交给消息Producer,消息Producer将消息存放在该业务线程消息栈中;
- 业务线程通知消息Producer消息结束时,消息Producer根据其消息栈产生消息树放置在同步消息队列中;
- 消息上报线程监听消息队列,根据消息树产生最终的消息报文上报CAT服务端。
API设计
监控API定义往往取决于对监控或者性能分析这个领域的理解,监控和性能分析所针对的场景有如下几种:
- 一段代码的执行时间,一段代码可以是URL执行耗时,也可以是SQL的执行耗时。
- 一段代码的执行次数,比如Java抛出异常记录次数,或者一段逻辑的执行次数。
- 定期执行某段代码,比如定期上报一些核心指标:JVM内存、GC等指标。
- 关键的业务监控指标,比如监控订单数、交易额、支付成功率等。
在上述领域模型的基础上,CAT设计自己核心的几个监控对象:Transaction、Event、Heartbeat、Metric。
一段监控API的代码示例如下:

序列化和通信
序列化和通信是整个客户端包括服务端性能里面很关键的一个环节。
- CAT序列化协议是自定义序列化协议,自定义序列化协议相比通用序列化协议要高效很多,这个在大规模数据实时处理场景下还是非常有必要的。
- CAT通信是基于Netty来实现的NIO的数据传输,Netty是一个非常好的NIO开发框架,在这边就不详细介绍了。
客户端埋点
日志埋点是监控活动的最重要环节之一,日志质量决定着监控质量和效率。当前CAT的埋点目标是以问题为中心,像程序抛出exception就是典型问题。
我个人对问题的定义是:不符合预期的就可以算问题,比如请求未完成、响应时间快了慢了、请求TPS多了少了、时间分布不均匀等等。
在互联网环境中,最突出的问题场景,突出的理解是:跨越边界的行为。包括但不限于:
- HTTP/REST、RPC/SOA、MQ、Job、Cache、DAL;
- 搜索/查询引擎、业务应用、外包系统、遗留系统;
- 第三方网关/银行, 合作伙伴/供应商之间;
- 各类业务指标,如用户登录、订单数、支付状态、销售额。
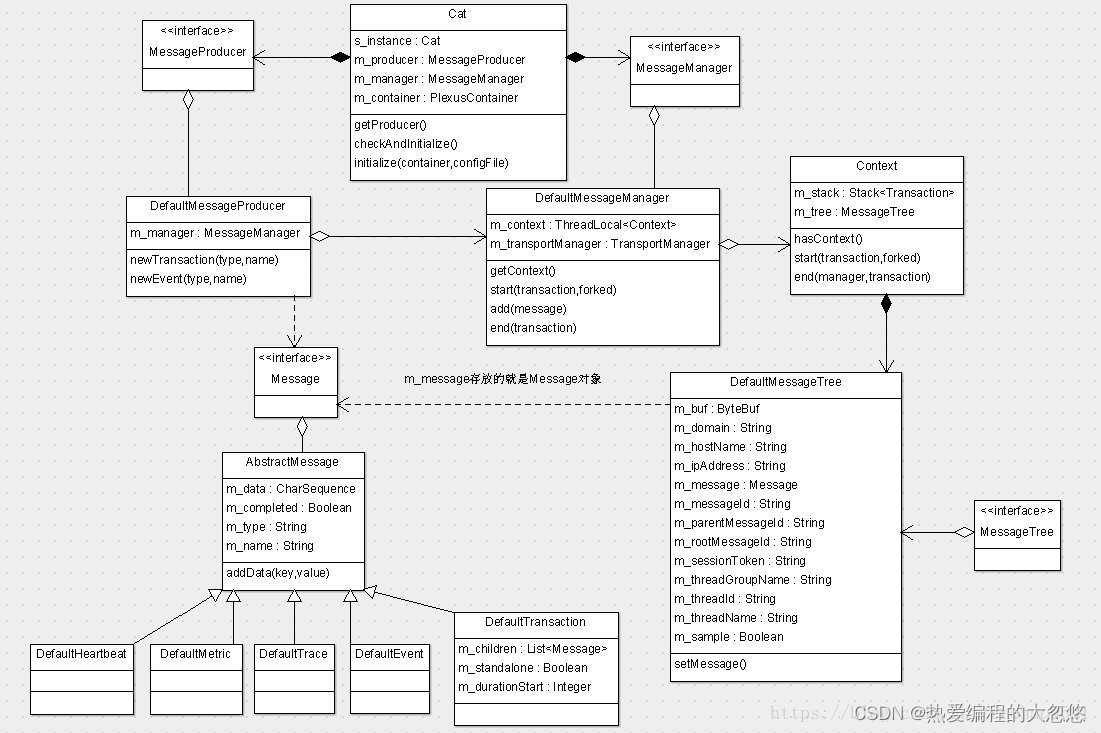
核心类分析
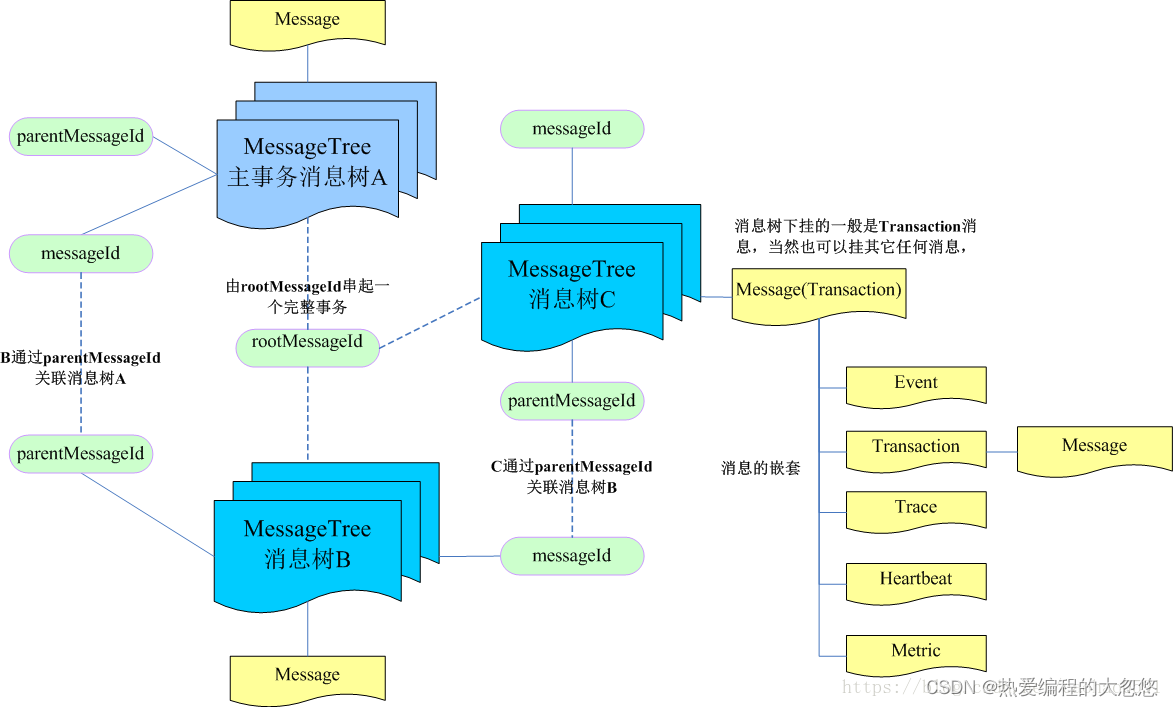
Cat使用消息树(MessageTree)组织日志,下面为消息树的类定义:
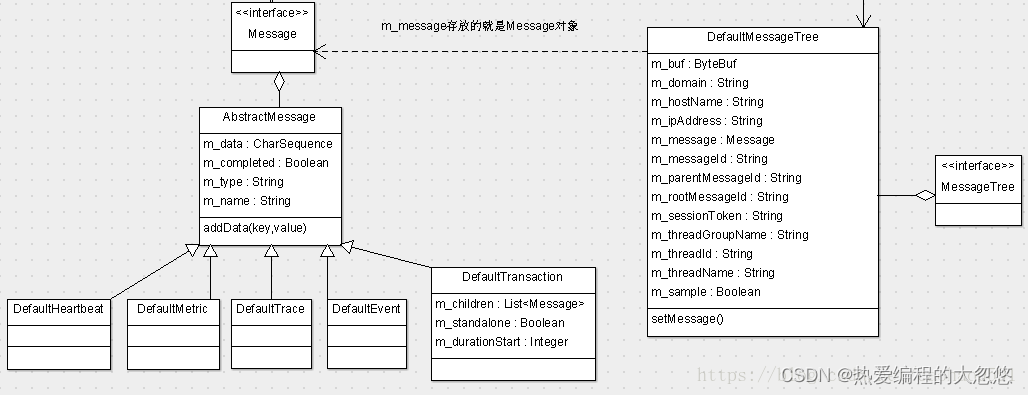
我们每次操作的实体都是消息树,其中有个domain字段,这是cat中一个非常重要的概念,一个domain可以对应成一个project,每个消息树拥有一个唯一的MessageId, 不同的消息树(比如微服务中A服务调用B服务,A,B都会生成消息树) 通过 parenMessageId、rootMessageId 串联起来,消息树下的所有实体都是Message,一共有5种类型的Message, 分别是Transaction, Event, Trace, Metric和Heartbeat。
-
Transaction:可以理解为是一个事务,事务之间可以互相嵌套,事务还可以嵌套任意其他消息类型,存放在List m_children 成员变量中,也只有事务才可以嵌套。一般用来记录跨越系统边界的程序访问行为,比如远程调用,数据库调用,也适合执行时间较长的业务逻辑监控。
-
Event:代表系统是在某个时间点发生的一次事件,例如新用户注册、登陆,系统异常等,理论上可以记录任何事情,它和transaction相比缺少了时间的统计,开销比transaction要小。还可以用来记录两个事务之间的关系,分支事务通过设置消息树的parentMessageId维护与主事务消息之间的关系。
-
Trace:用于记录一些trace、debug这类的信息,比如log4j打印日志。以便于快速调试定位问题
-
Metric:用于记录业务指标、指标可能包含对一个指标记录次数、记录平均值、记录总和
-
Heartbeat:主要用于记录系统的心跳信息,比如CPU%, MEM%,连接池状态,系统负载等。
流程分析
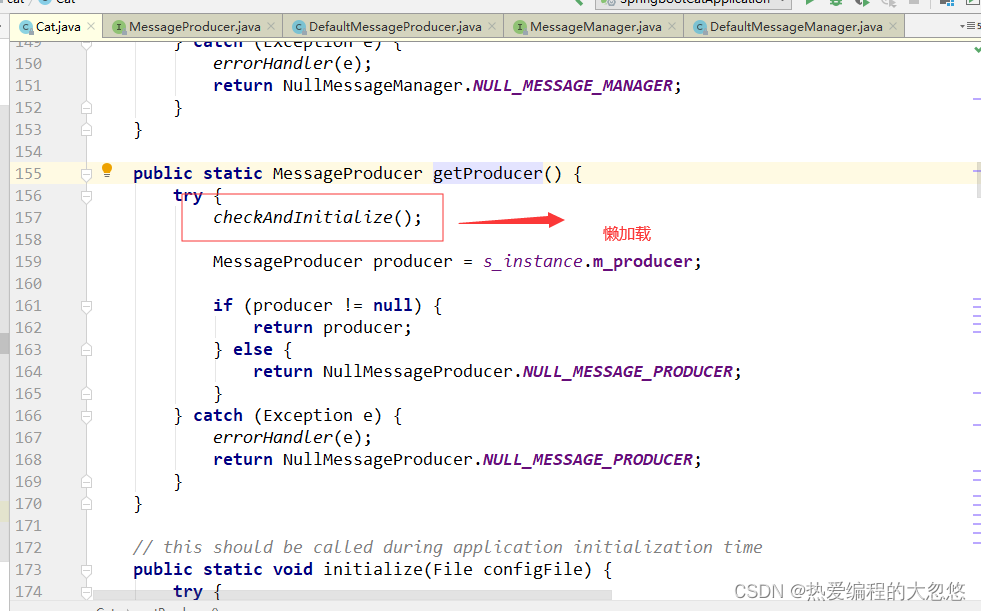
启动流程:
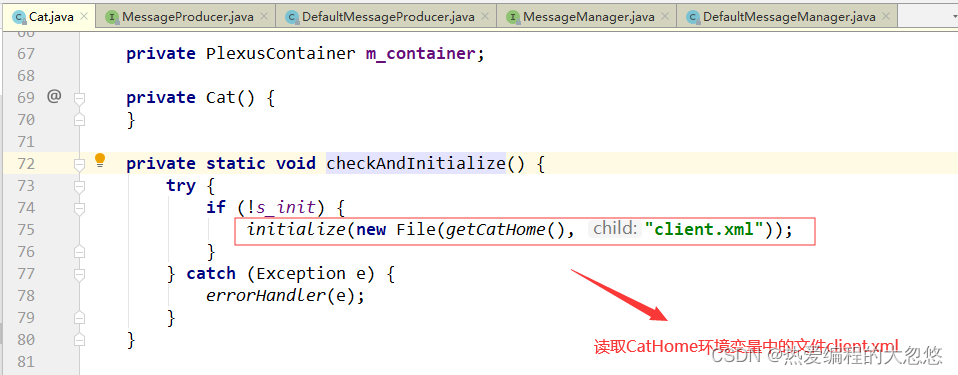
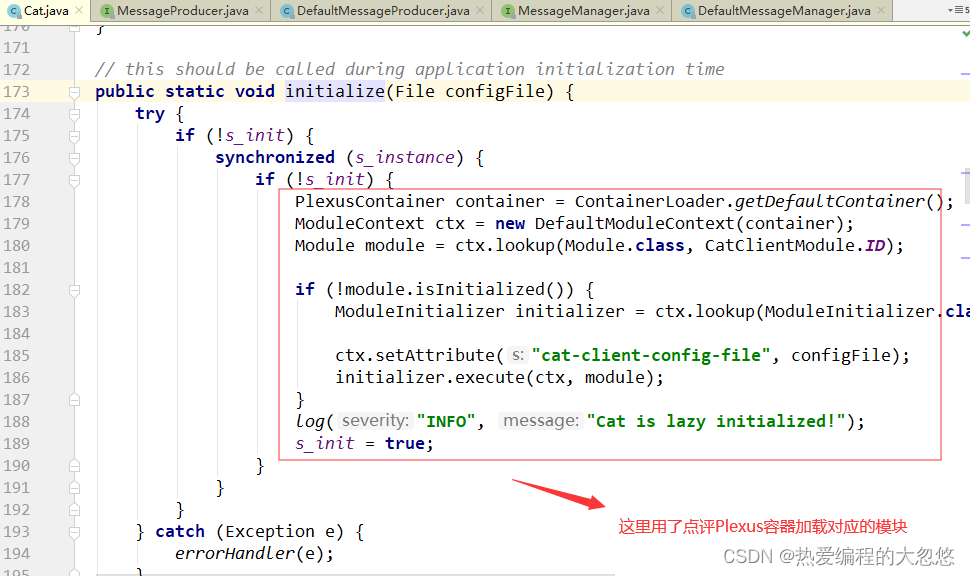
创建transaction首先会通过getProducer函数获取消息生产者MessageProducer对象,在返回MessageProducer对象之前,函数会对客户端进行初始化,设置 CatHome目录,默认是/data/appdatas/cat ,读取配置文件 client.xml,使用Plexus容器加载对应的模块:
消息生产
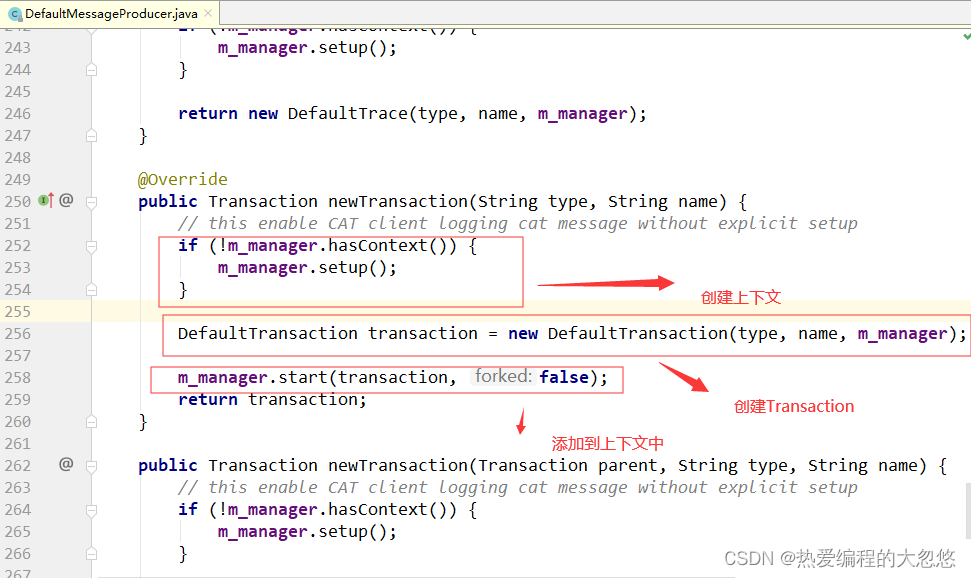
我们获取消息生产者对象 MessageProducer 之后,就可以调用 newTransaction(type, name) 来创建 Transaction类消息了,
值得注意的是MessageProducer对业务封装了CAT内部的所有细节,所以业务方只需要一个MessageProducer对象就可以完成消息的所有操作。
创建消息具体步骤如下:
- 他首先通过消息管理者MassageManager判断是否存在消息上下文context,如果不存在则在setup中创建消息上下文。
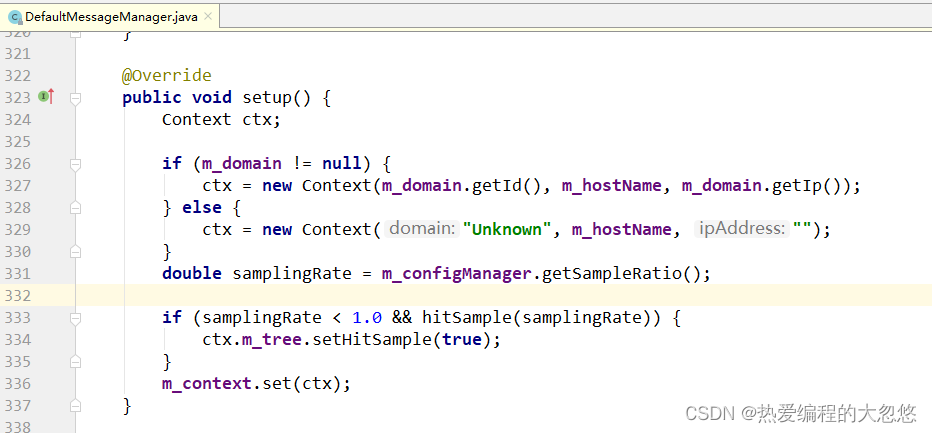
Context 线程本地变量
消息上下文 Context 采用的是线程本地变量。通过ThreadLocal存取Context数据。
高并发下日志的打印通常会采用这种方式,或者说一次事务的日志一起打印,因为一般默认一次事务都是由同一个线程执行的(如一次http请求),将事务的日志保存在线程局部变量当中,当事务执行完成的时候统一打印。
为什么需要用到线程本地变量?在低并发请求下,一条日志会很快被处理,普通变量即可满足需求,很少出现多个线程同时读写同一个变量,
然在高并发场景下,多个线程同时读写同一个变量会导致不可预知的结果,我们称这为线程非安全,比如线程A要写一大段日志,写到一半,线程B获得CPU执行时间片开始写日志,AB的日志就会交错混乱,有同学会问,为什么不用同步锁?这是一个方案,同步锁是一个相对较复杂的保证线程安全,保证同时只有一个线程可以读写变量,其它线程要读写变量就需要排队,这就必然会带来高延迟,
线程本地变量功用则非常简单,就是为每一个使用该变量的线程都提供一个变量值的副本,是Java中一种较为特殊的线程绑定机制,JVM 为每个运行的线程,绑定了私有的本地实例存取空间,每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突,从而为多线程环境常出现的并发访问问题提供了一种隔离机制,但是会造成数据冗余,是一种用空间换时间的线程安全方案。
- 创建上下文:
Context的构造函数:
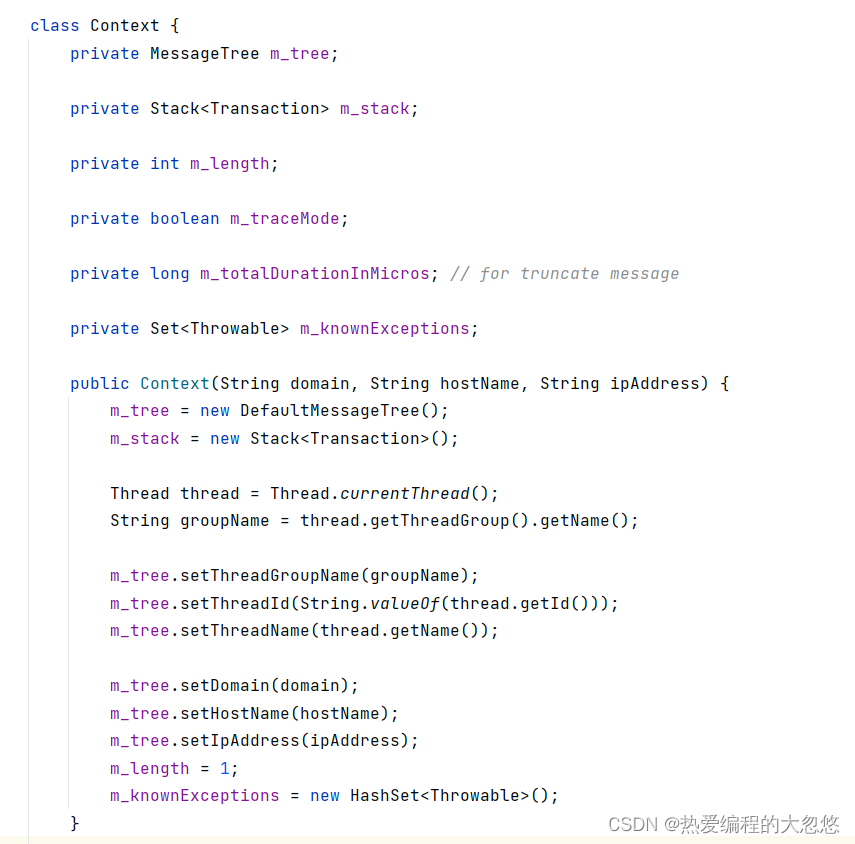
在Context构造函数里,我们可以看到消息树MessageTree和Transaction栈被创建了,由于Context是线程本地变量,由此可以推断,每个线程都拥有各自的消息树和事务栈,这里所说的线程都是业务线程,Context属于MessageManager的内部类。
可以认为MessageManager的其中一个功能是作为context的一个代理,MessageManager的start、add、end等方法,核心都是调用当前线程context的start、add、end方法。
Transaction事务的开启
接着MessageProducer就会创建一个Transation对象,然后将Transaction对象交给 MessageManager启动。
1.添加Transaction到上下文中—> 关注ctx.start方法
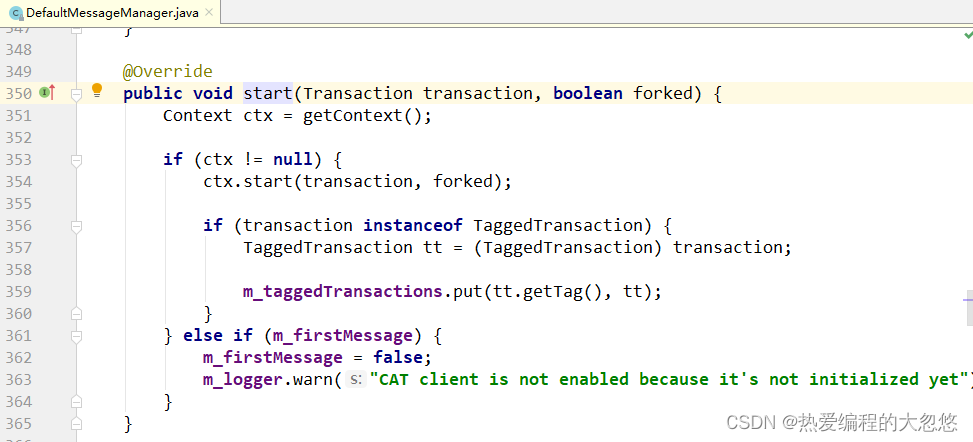
- 添加Transaction到Context中的DefaultMessageTree中
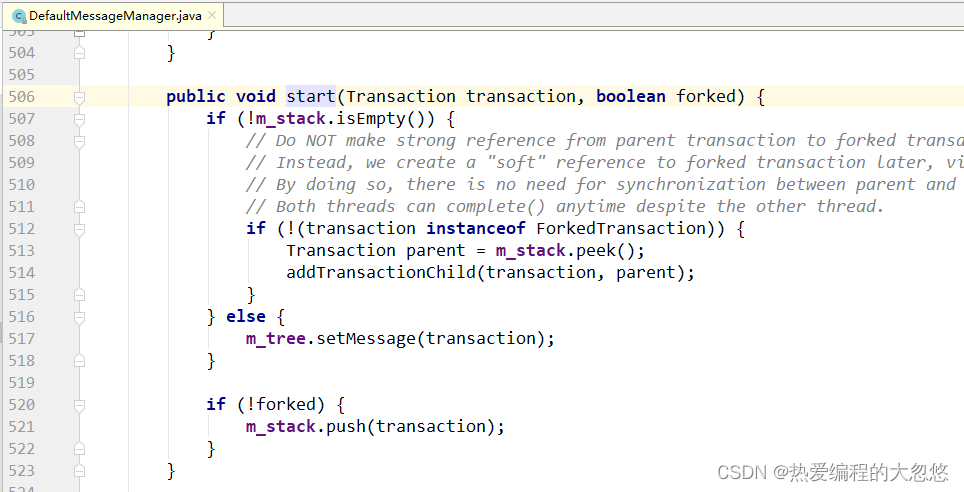
-
如果 m_stack 不为空, 而且 transaction 类型不为 ForkedTransaction
- 计算时间 或 长度条件,如果需要发送到Server,就发送到Server里(truncateAndFlush)
- 将当前 transaction 加到 m_stack 栈顶元素的子消息中去。
- m_length++
-
如果m_stack为空,就把当前这个Transaction加到MessageTree里面。
-
最后判断 transaction 是否是forked的事务,不是则将transaction加入 m_stack 。
其他类型消息组合
@RunWith(JUnit4.class)
public class AppSimulator extends CatTestCase {
@Test
public void simulateHierarchyTransaction() throws Exception {
MessageProducer cat = Cat.getProducer();
Transaction t = cat.newTransaction("URL", "WebPage");
String id1 = cat.createMessageId();
String id2 = cat.createMessageId();
try {
// do your business here
t.addData("k1", "v1");
t.addData("k2", "v2");
t.addData("k3", "v3");
Thread.sleep(5);
cat.logMetric("payCount", "C", "1");
cat.logMetric("totalfee", "S", "30.5");
cat.logMetric("avgfee", "T", "25.6");
cat.logMetric("order", "S,C", "3,25.6");
Metric event = Cat.getProducer().newMetric("kingsoft", "praise");
event.setStatus("C");
event.addData("3");
event.complete();
Cat.getManager().setTraceMode(true);
cat.logTrace("Trace1", "debug", SUCCESS, "user_debug_data");
cat.logEvent("RuntimeException", "Name1", "ERROR", "data1");
cat.logEvent("Error", "Name2", SUCCESS, "data2");
cat.logEvent("RemoteCall", "Service1", SUCCESS, id1);
t.setStatus(SUCCESS);
} catch (Exception e) {
t.setStatus(e);
} finally {
t.complete();
}
}
}
可以通过 MessageProducer的 logEvent 记录event类型的消息,方法首先会调用newEvent方法创建Event对象,如果有消息数据,就用addData方法添加数据,然后setStatus设置消息状态,complete完成日志记录。
public class DefaultMessageProducer implements MessageProducer {
@Override
public void logEvent(String type, String name, String status, String nameValuePairs) {
Event event = newEvent(type, name);
if (nameValuePairs != null && nameValuePairs.length() > 0) {
event.addData(nameValuePairs);
}
event.setStatus(status);
event.complete();
}
@Override
public Event newEvent(String type, String name) {
if (!m_manager.hasContext()) {
m_manager.setup();
}
if (m_manager.isMessageEnabled()) {
DefaultEvent event = new DefaultEvent(type, name, m_manager);
return event;
} else {
return NullMessage.EVENT;
}
}
}
event.complet 做了什么事情? 他会首先设置消息complete状态为true,然后调用 MessageManager 的 add 方法,并传入自身的指针,在Context 线程本地变量章节的时候说过MessageManager是context的代理,MessageManager 的add方法核心是调用的context得add方法。
context的add方法,会首先判断m_stack栈是否为空,如果是空的说明这个消息是一个单独的非事务类型消息, 直接将消息放入MessageTree然后发送到服务器。
如果m_stack 不为空,说明这个event消息处在一个事务下面,我们从m_stack 栈顶获取事务,将event消息嵌套到事务里,等待事务结束的时候一同推送到服务器。上边的案例就是这种情况。
class Context {
public void add(Message message) {
if (m_stack.isEmpty()) {
MessageTree tree = m_tree.copy();
tree.setMessage(message);
flush(tree);
} else {
Transaction parent = m_stack.peek();
addTransactionChild(message, parent);
}
}
}
我们也可以不用logEvent 记录日志,而是自己通过newEvent创建Event消息实例, 然后由自己控制什么时候add数据、setStatus以及complete消息。
Heartbeat, Metric, Trace类别的消息操作流程和Event消息基本一样,其中Trace消息需要MessageManager开启TradeMode追踪模式才可以用,类似我们开发中的Debug模式,调用 Cat.getManager().setTraceMode(true) 方法可以开启追踪模式。
关闭Transaction:
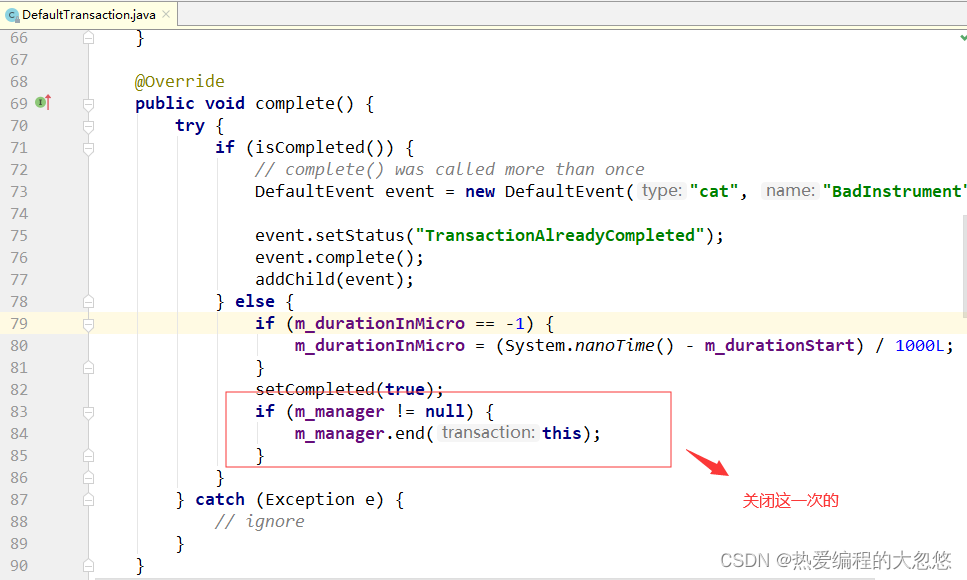
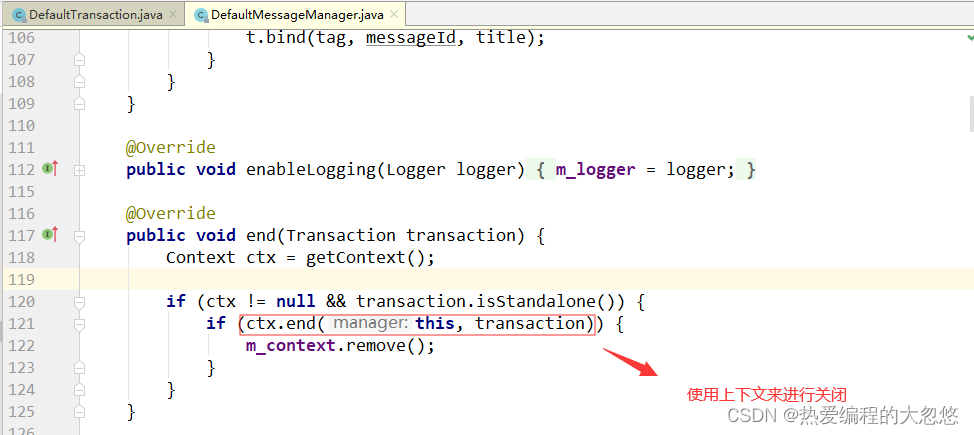
Contex的end方法会从栈顶弹出事务, 如果弹出的事务不等于end方法传入的事务,则认为弹出的事务不是我们需要结束的事务,而是被嵌套的子事务,我们继续弹出下一个栈顶元素,即父事务,直到弹出我们需要结束的事务为止。在这个过程,会调用validate对事务进行校验。
然后我们判断栈是否为空,如果为空,则认为end传入的事务为根事务,这个时候我们才调用 m_manager.flush 将消息树上报到服务器。
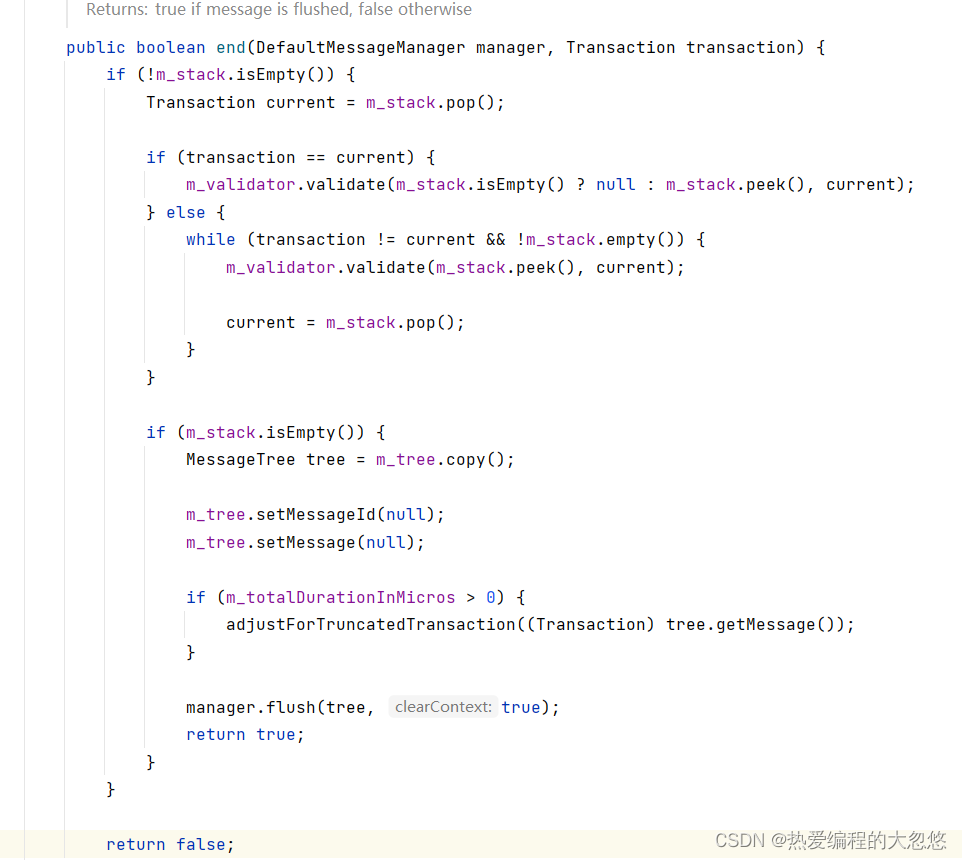
这里需要介绍一下,消息进入到上下文之后,是通过栈的方式来存储的:
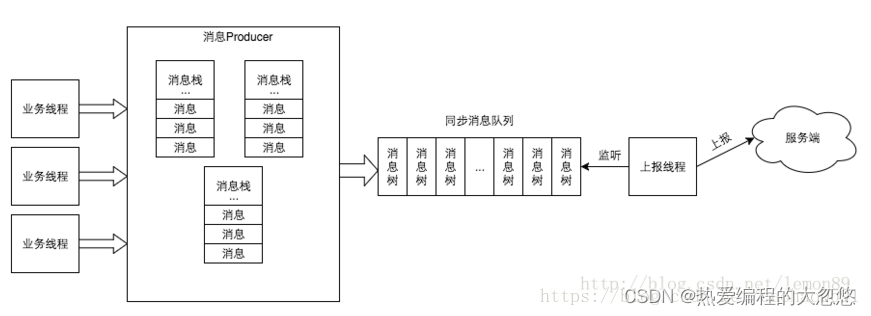
Context以ThreadLocal形式存储,所以每个业务线程都有自己的Context,同时Context还是属于Prducer的一个内部类
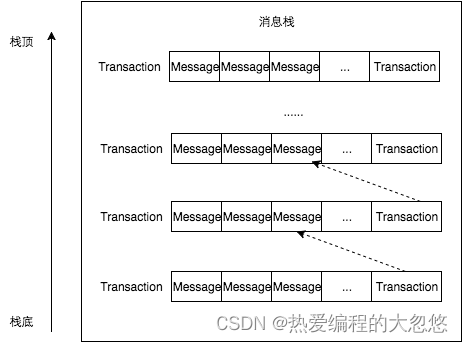
Transaction之间是有引用的,因此在end方法中只需要将第一个Transaction(封装在MessageTree中)通过MessageManager来flush,在拼接消息时可以根据这个引用关系来找到所有的Transaction 。所以来看代码:
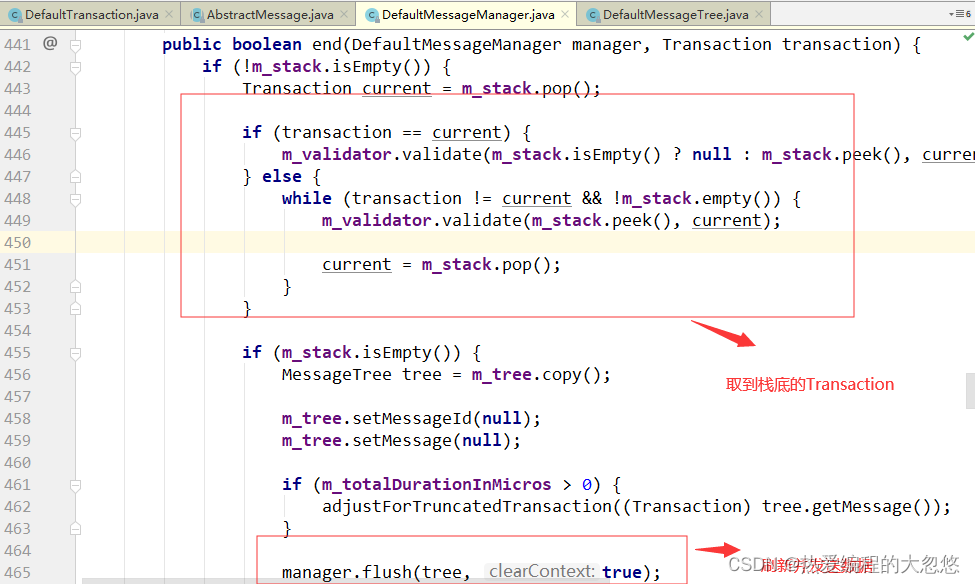
发送数据
MessageManager 会通过 flush 将消息树上报到服务器,我们来通过下面源码分析一下flush方法,函数首先判断是否分配MessageID,没有则分配, 然后调用TcpSocketSender的send函数来发送消息。
send函数也不是立即发送, 仅仅只是插入内存队列。读者可以去看看 TcpSocketSender 的 initialize() 方法, 有行代码 Threads.forGroup(“cat”).start(this) ,这行代码使得客户端在初始化的时候, 就开启一个上报线程,上报线程一直读取内存队列,获取要发送的消息树,调用 sendInternal(MessageTree tree) 方法将消息树发送到服务器。
这样子,客户端就实现了消息的多线程、异步化、队列化,从而保证日志的记录不会因为CAT系统异常而影响主业务线程。
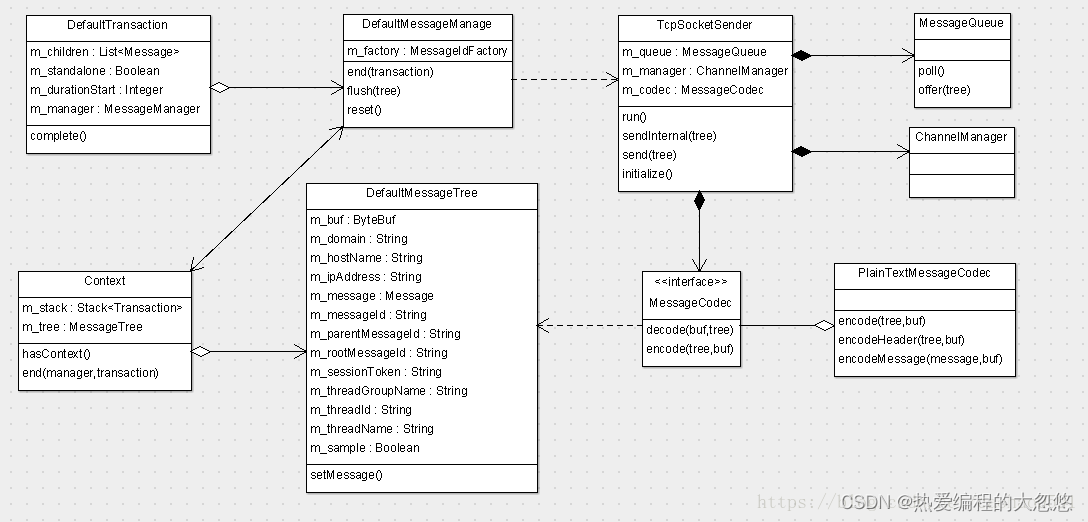
1.首先获取到发送类的对象,调用其方法进行发送:
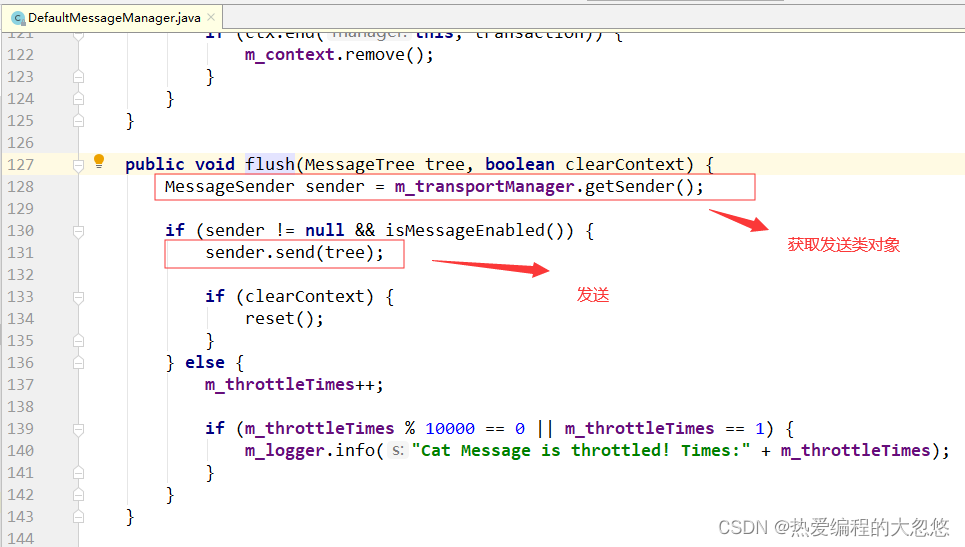
2.发送时是经典的生产者-消费者模型,生产者只需要向队列中放入数据,消费者监听队列,获取数据并发送:
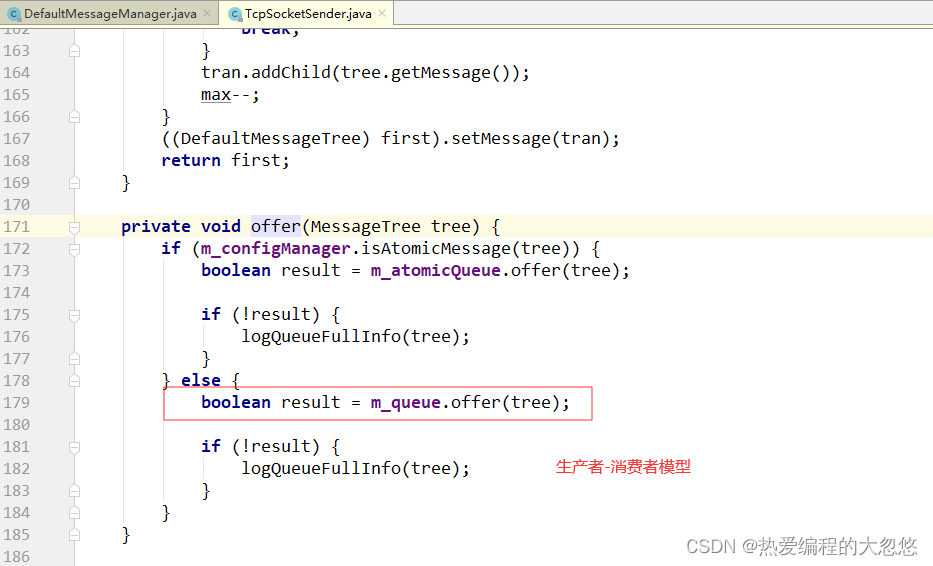
3.消费者线程拉取消息:
消息序列化
上报线程通过 sendInternal(MessageTree tree) 将消息发送到服务器,在 sendInternal 方法内, TcpSocketSender 在发送报文之前,会先调用m_codec.encode(tree, buf) 对消息树进行序列化,序列化就是将对象编码为一组字节,使得对象能够通过 tcp/ip 协议发送到服务器端的技术, 服务器再通过反序列化, 将字节解码为对象。
在Java中,只要一个类实现了java.io.Serializable接口,那么它就可以被序列化。但是通过公共接口编码的字节会有很多冗余信息来保证不同对象与字节之间的正确编解码,在CAT中,需要传输的只有MessageTree这么一个对象。通过自定义的序列化方案可以节省许多不必要的字节信息,保证网络传输的高效性。
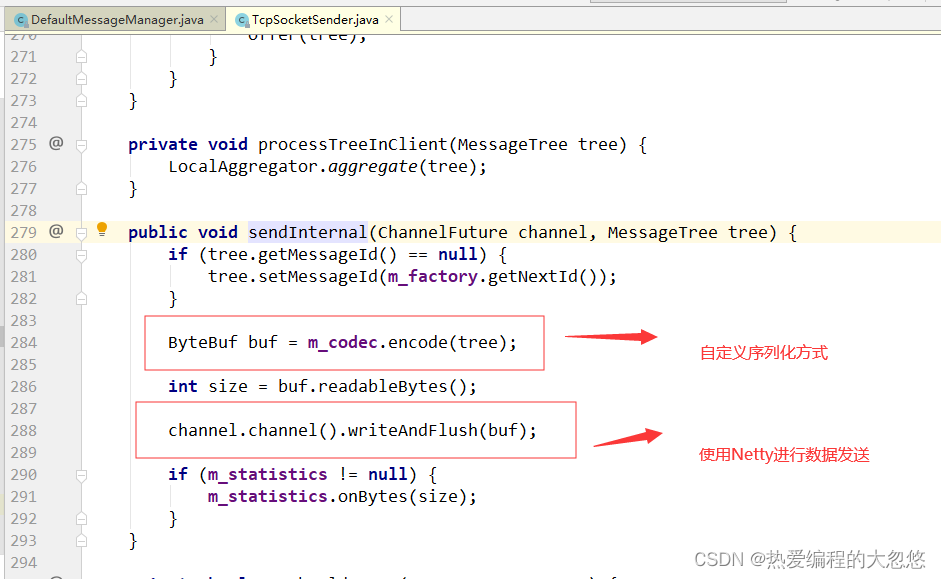
public class PlainTextMessageCodec implements MessageCodec, LogEnabled {
@Override
public void encode(MessageTree tree, ByteBuf buf) throws UnsupportedEncodingException {
int count = 0;
int index = buf.writerIndex();
buf.writeInt(0); // place-holder
count += encodeHeader(tree, buf);
if (tree.getMessage() != null) {
count += encodeMessage(tree.getMessage(), buf);
}
buf.setInt(index, count);
}
}
被序列化的字节码包含3个部分:
1、 前4个字节包含整组字节串的长度,首先通过buf.writeInt(0)占位,编码完通过buf.setInt(index, count)将字节码长度写入buf头4个字节。
2、编码消息树的头部,依次将tree的version, domain, hostName, ipAdress, treadGroupName, treadId, threadName, MessageId, parentMessageId, rootMessageId, sessionToken写入头部,字段之间以"\t"分隔,并以"\n"结尾。空用null表示。
3、编码消息体,每个消息都是以一个表示消息类型的字符开头。
a."A"表示没有嵌套其他类型消息的事务,
b.有嵌套其他消息的事务,以一个 "t" 开头,然后递归去遍历并编码子消息, 最后以一个"T"结束,
c."E"/"L"/"M"/"H"分别表示Event/Trace/Metric/Heartbeat类型消息;
- 然后依次记录时间、type、name
- 然后根据条件依次写入status、duration+us、data
- 字段之间依然以"\t"分割,以"\n"结尾,空用null表示
比如上面其它消息组合章节的案例中,MessageTree通过编码之后:
口PT1 Cat Win7-caoh.kingsoft.cn 192.168.37.41 main 1 main Cat-c0a82529-423686-40028 null null null
t2018-05-02 22:59:05.347 URL WebPage
H2018-05-02 22:59:05.353 Heartbeat1 hearbeat 0 cpu=90&mem=70
M2018-05-02 22:59:05.353 metric1 0 total_fee
L2018-05-02 22:59:05.354 Trace1 debug 0 user_debug_data
E2018-05-02 22:59:05.354 Event1 Name1 0 data1
E2018-05-02 22:59:05.354 Event2 Name2 0 data2
E2018-05-02 22:59:05.354 RemoteCall Service1 0 Cat-c0a82529-423686-40026
T2018-05-02 22:59:07.507 URL WebPage 0 2160695us k1=v1&k2=v2&k3=v3
上面一串字符串,是通过字节码转换成string的结果, 最前面的乱码,实际上表示的是4个字节的int类型转为string类型表现形式。字节码转int后是541,是整个字节码的长度。
最终TcpSocketSender 通过ChannelManager 将编码后的字节码发送到服务器。这里采用的是netty客户端。
MessageID
CAT每个消息都有一个唯一的ID,这个ID在客户端生成,后续都通过这个ID在进行消息内容的查找。典型的RPC消息串起来的问题,比如A调用B的时候,在A这端生成一个Message-ID,在A调用B的过程中,将Message-ID作为调用传递到B端,在B执行过程中,B用context传递的Message-ID作为当前监控消息的Message-ID。
CAT消息的Message-ID格式ShopWeb-0a010680-375030-2,CAT消息一共分为四段:
- 第一段是应用名shop-web。
- 第二段是当前这台机器的IP的16进制格式,01010680表示10.1.6.108。
- 第三段的375030,是系统当前时间除以小时得到的整点数。
- 第四段的2,是表示当前这个客户端在当前小时的顺序递增号。
一定得注意的是,同一台客户端机器产生的Message-ID的第四段,即当前小时的顺序递增号,在当前小时内一定不能重复,因为在服务端,CAT会为每个客户端IP、每个小时的原始消息存储都创建一个索引文件,每条消息的索引记录在索引文件内的偏移位置是由顺序递增号决定的,一旦顺序号重复生成,那么该小时的重复索引数据将会被覆盖,导致我们无法通过索引找到原始消息数据。
服务端原理
单机的consumer架构设计如下:
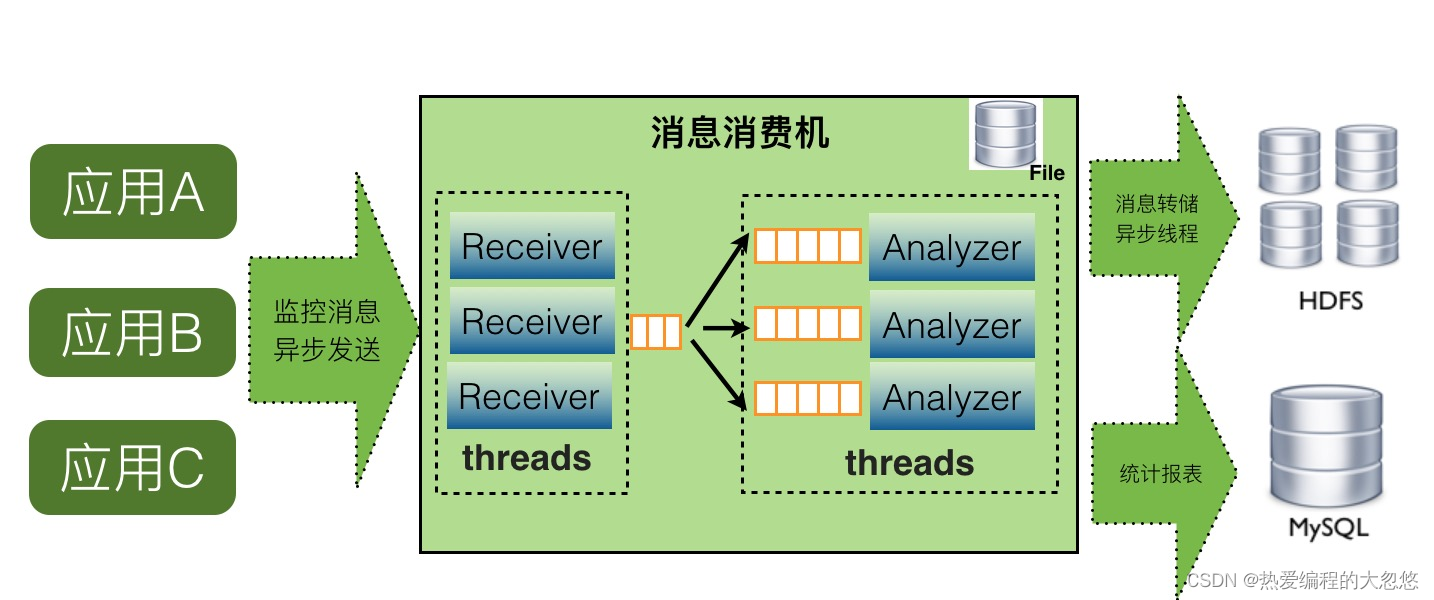
如上图,CAT服务端在整个实时处理中,基本上实现了全异步化处理。
- 消息接受是基于Netty的NIO实现。
- 消息接受到服务端就存放内存队列,然后程序开启一个线程会消费这个消息做消息分发。
- 每个消息都会有一批线程并发消费各自队列的数据,以做到消息处理的隔离。
- 消息存储是先存入本地磁盘,然后异步上传到HDFS文件,这也避免了强依赖HDFS。
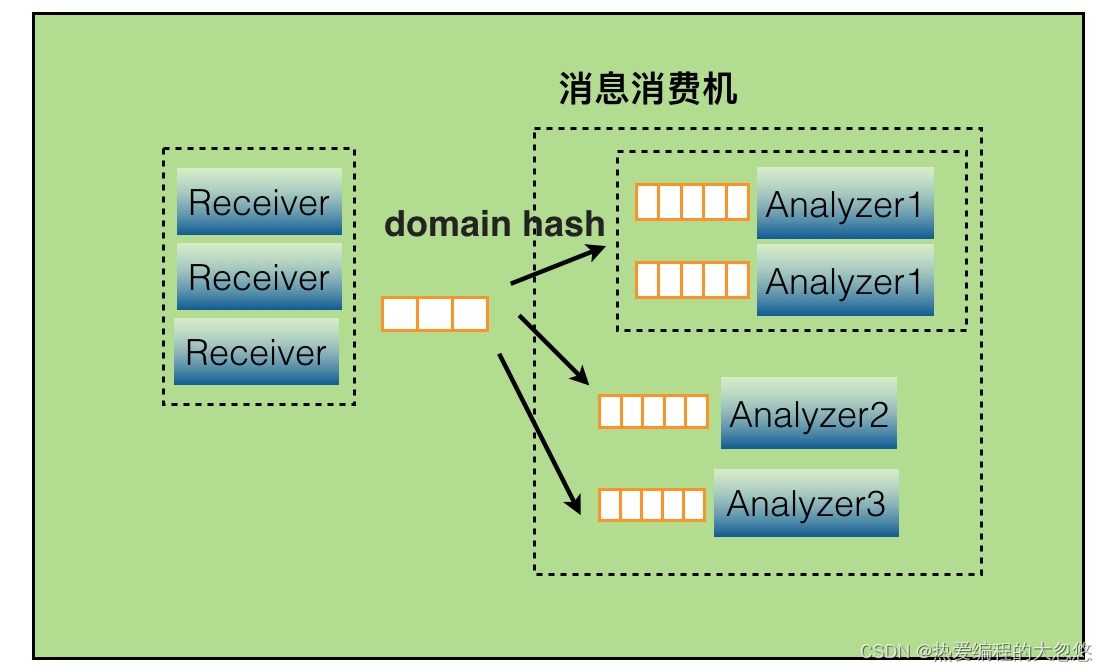
当某个报表处理器处理来不及时候,比如Transaction报表处理比较慢,可以通过配置支持开启多个Transaction处理线程,并发消费消息。
存储数据设计
消息存储是CAT最有挑战的部分。关键问题是消息数量多且大,目前美团每天处理消息1000亿左右,大小大约100TB,单物理机高峰期每秒要处理100MB左右的流量。CAT服务端基于此流量做实时计算,还需要将这些数据压缩后写入磁盘。
整体存储结构如下图:
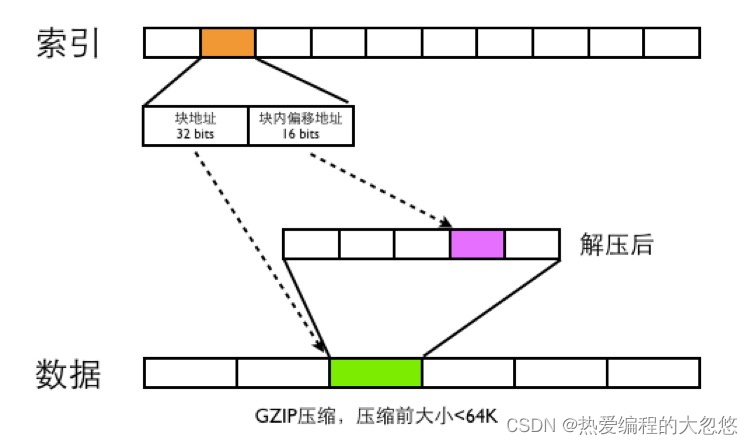
CAT在写数据一份是Index文件,一份是Data文件.
- Data文件是分段GZIP压缩,每个分段大小小于64K,这样可以用16bits可以表示一个最大分段地址。
- 一个Message-ID都用需要48bits的大小来存索引,索引根据Message-ID的第四段来确定索引的位置,比如消息Message-ID为ShopWeb-0a010680-375030-2,这条消息ID对应的索引位置为2*48bits的位置。
- 48bits前面32bits存数据文件的块偏移地址,后面16bits存数据文件解压之后的块内地址偏移。
- CAT读取消息的时候,首先根据Message-ID的前面三段确定唯一的索引文件,在根据Message-ID第四段确定此Message-ID索引位置,根据索引文件的48bits读取数据文件的内容,然后将数据文件进行GZIP解压,在根据块内偏移地址读取出真正的消息内容。
小结
大家在学习Cat客户端原理时,可以对照一开始给出的通用解决四部曲来看,看看理论与实践落地的差异与联系。
更多Cat源码可以参考该系列: Cat源码系列,大佬分析的很透彻,本文在客户端源码分析部分,也是大量借鉴了该系列中客户端源码篇,对于服务端原理篇和其他部分,本文只是一笔带过,更多详情,大家可以参考该源码系列。