说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

1.项目背景
2019年Heidari等人提出哈里斯鹰优化算法(Harris Hawk Optimization, HHO),该算法有较强的全局搜索能力,并且需要调节的参数较少的优点。
本项目通过HHO哈里斯鹰优化算法寻找最优的参数值来优化CNN分类模型。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
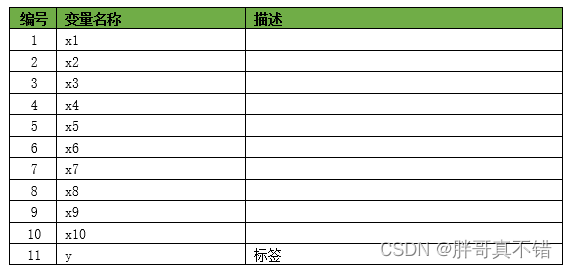
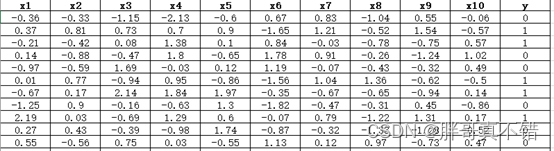
数据详情如下(部分展示):
3.数据预处理
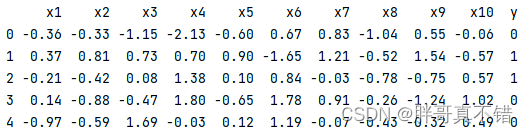
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
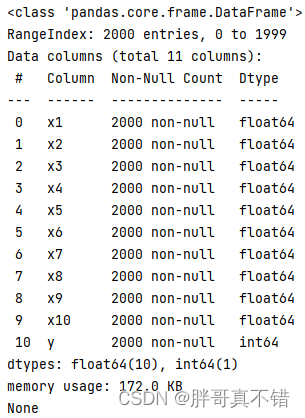
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
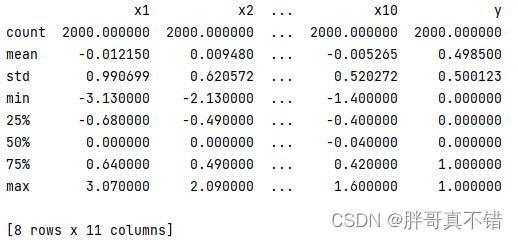
关键代码如下:

4.探索性数据分析
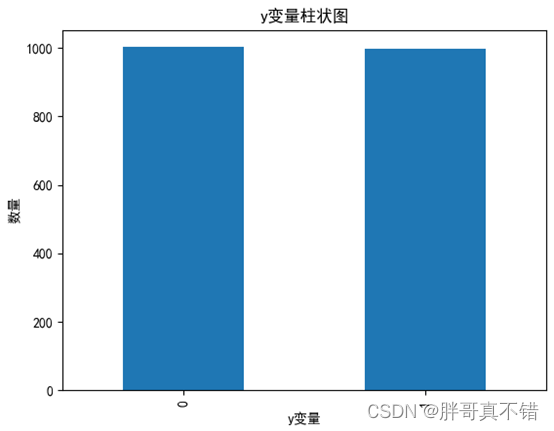
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制直方图:
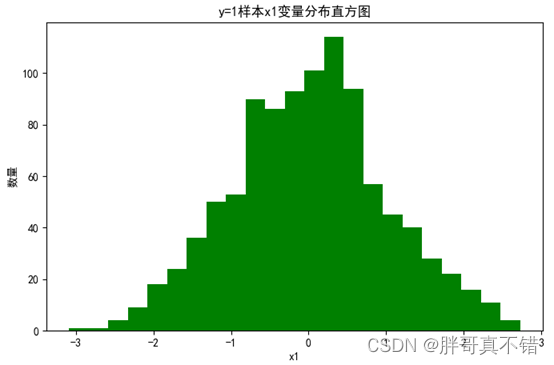
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.3 相关性分析
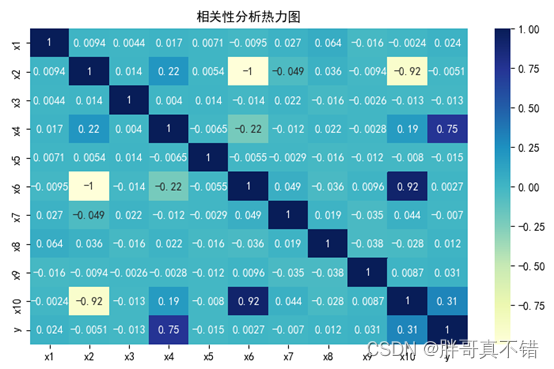
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:
5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:
![]()
5.3 数据样本增维
数据样本增加维度后的数据形状:

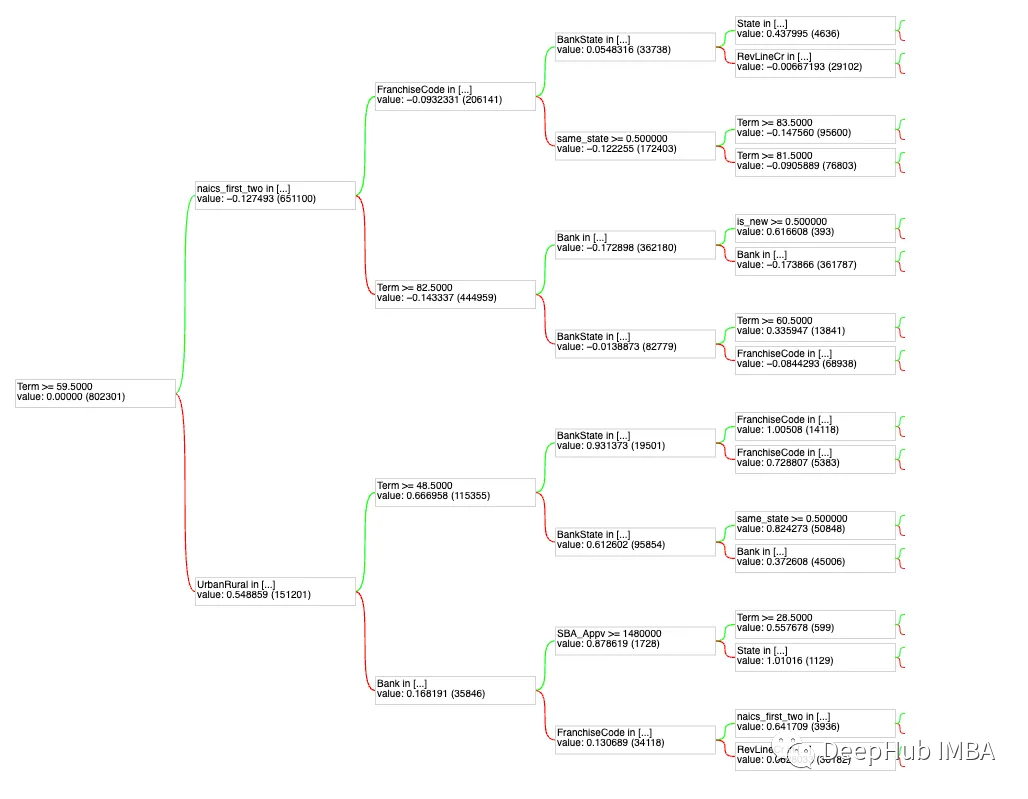
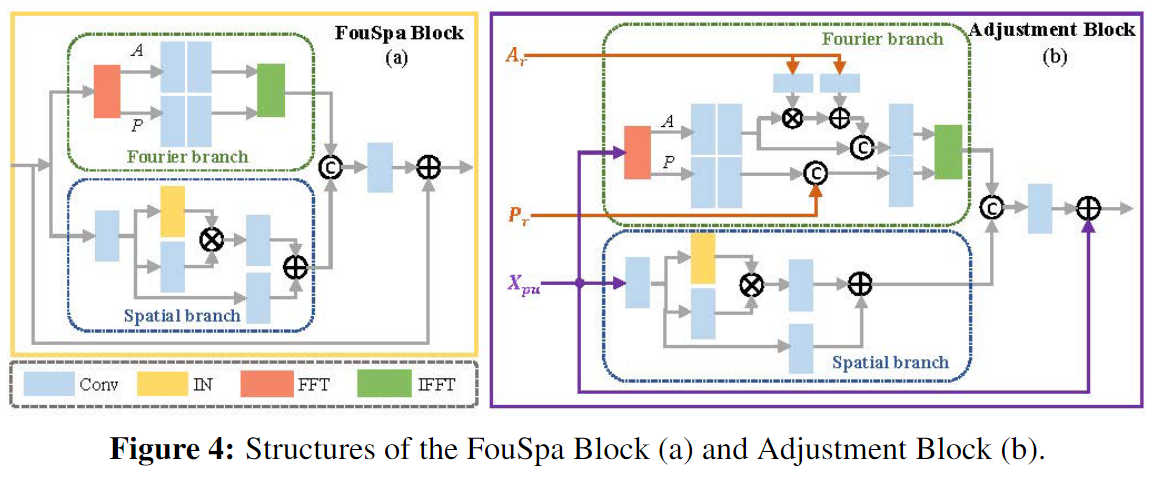
6.构建HHO哈里斯鹰优化算法优化CNN分类模型
主要使用HHO哈里斯鹰优化算法优化CNN分类算法,用于目标分类。
6.1 HHO哈里斯鹰优化算法寻找的最优参数
关键代码:

每次迭代的过程数据:

最优参数:

6.2 最优参数值构建模型

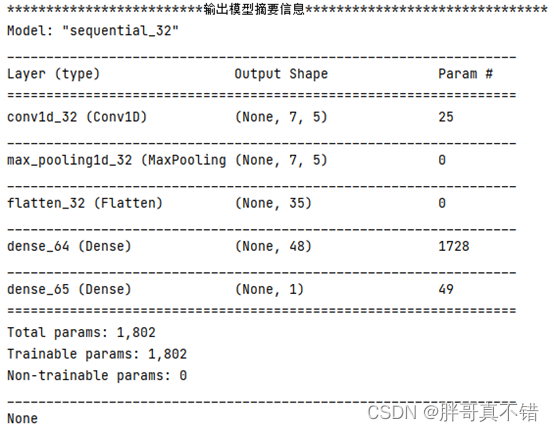
6.3 最优参数模型摘要信息
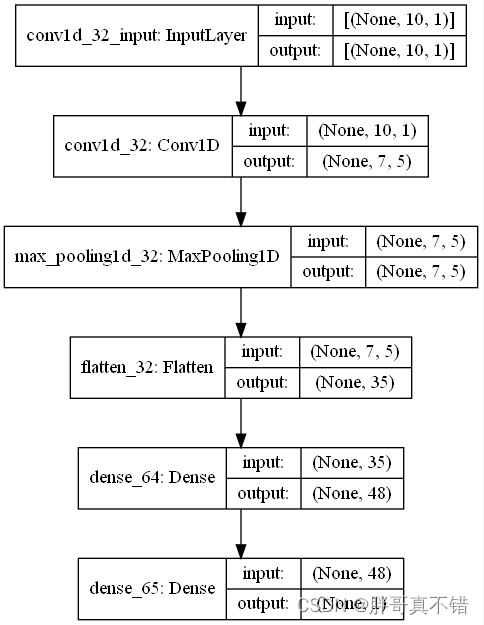
6.4 最优参数模型网络结构
6.5 最优参数模型训练集测试集损失和准确率曲线图
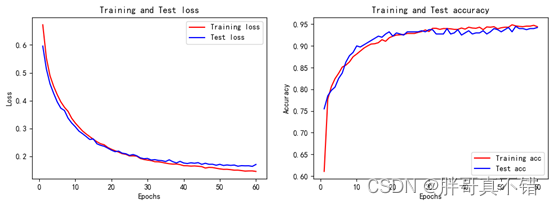
7.模型评估
7.1 评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
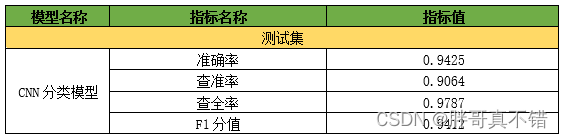
从上表可以看出,F1分值为0.9412,说明模型效果较好。
关键代码如下:

7.2 分类报告
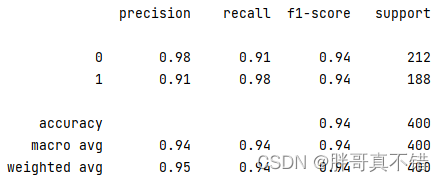
从上图可以看出,分类为0的F1分值为0.94;分类为1的F1分值为0.94。
7.3 混淆矩阵
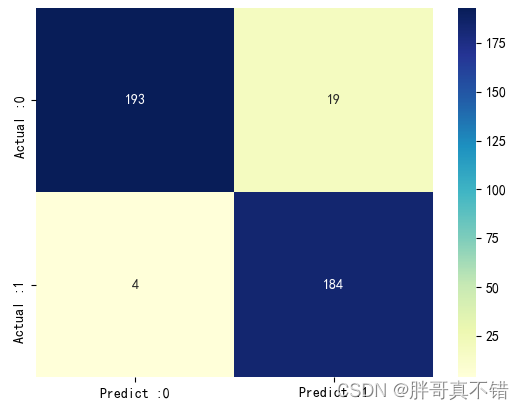
从上图可以看出,实际为0预测不为0的 有19个样本;实际为1预测不为1的 有4个样本,整体预测准确率良好。
8.结论与展望
综上所述,本文采用了HHO哈里斯鹰优化算法寻找CNN分类算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。
#!/usr/bin/env python
# coding: utf-8
# 定义初始化位置函数
def init_position(lb, ub, N, dim):
X = np.zeros([N, dim], dtype='float') # 位置初始化为0
for i in range(N): # 循环
for d in range(dim): # 循环
X[i, d] = lb[0, d] + (ub[0, d] - lb[0, d]) * rand() # 位置随机初始化
return X # 返回位置数据
# ******************************************************************************
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 链接:https://pan.baidu.com/s/1c6mQ_1YaDINFEttQymp2UQ
# 提取码:thgk
# ******************************************************************************
# 定义转换函数
def binary_conversion(X, thres, N, dim):
Xbin = np.zeros([N, dim], dtype='int') # 位置初始化为0
for i in range(N): # 循环
for d in range(dim): # 循环
if X[i, d] > thres: # 判断
Xbin[i, d] = 1 # 赋值
else:
Xbin[i, d] = 0 # 赋值
return Xbin # 返回数据
更多项目实战,详见机器学习项目实战合集列表:
机器学习项目实战合集列表_机器学习实战项目_胖哥真不错的博客-CSDN博客