刚入门的产品经理经常会听到前辈们说应该懂点技术,却不明白为什么。本文作者分享了几个被迫妥协的产品设计的例子,希望能让不是技术出身的产品经理了解到“产品经理应该懂点技术”在产品设计中有什么指导意义,一起来看一下吧。
刚入门的产品经理经常听前辈们或者网上的产品“专家”们说应该懂点技术,这个说要懂点前端技术,那个说要懂点后端技术,有的说要懂点数据库,也有的说要了解服务器,搞得他们觉得在成为产品经理之前,应该先成为一个全栈工程师。
现在产品经理的门槛越来越低,一方面,市场上的产品越来越多,同质化也越来越严重,有时候产品经理只要稍加借鉴就可以做出不错的交互设计,虽然有时候他们未必清楚为什么要这么设计;另一方面,产品经理在设计上对技术不友好的地方往往会在技术评审中被指出,并按研发工程师的要求进行调整,所以有些即使完全不懂技术的产品经理,一样能够很好地完成工作。
下文分享的几个小案例,希望能够让不是技术出身的产品经理了解到“产品经理应该懂点技术”到底在产品设计中有什么指导意义。
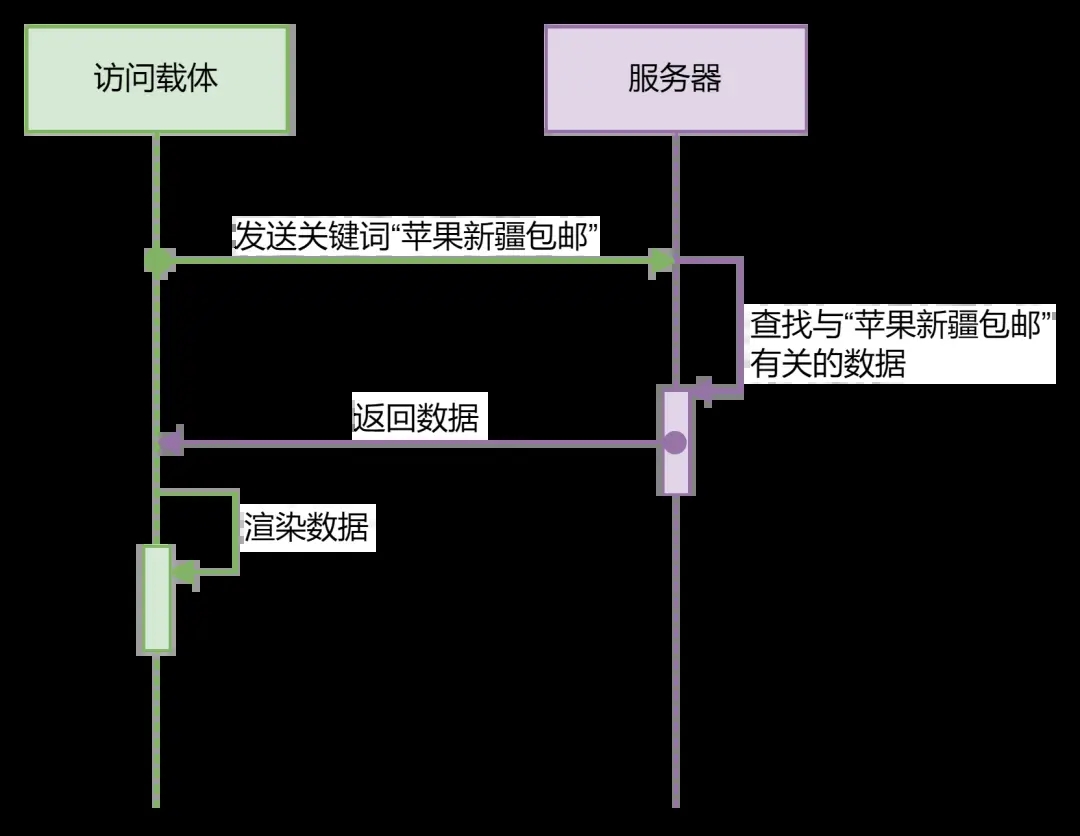
我们日常使用软件产品的时候,其实都是在跟服务器资源进行交互,大致的过程是这样的:

当我们在访问载体(浏览器、APP或者小程序中)进行某个操作(如点击按钮),这个时候会向服务器发送请求(请求的内容由具体的操作所决定),服务器在收到后,将请求对应的内容“响应”回来,这时访问载体再将响应的内容“渲染”出来,就完成了一次资源交互。
你可以把服务器想象成一个虚拟的商家,经营着各种商品,而我们请求的过程,就是告诉商家我们需要的商品,商家根据我们的需求给我们提供商品。
上面的过程你可以这么理解:你告诉(发送请求)商家(服务器),说你需要一个苹果(请求信息),商家接到信息后,把苹果给你(响应)。
下文的案例需要你先能够理解上述的原理。
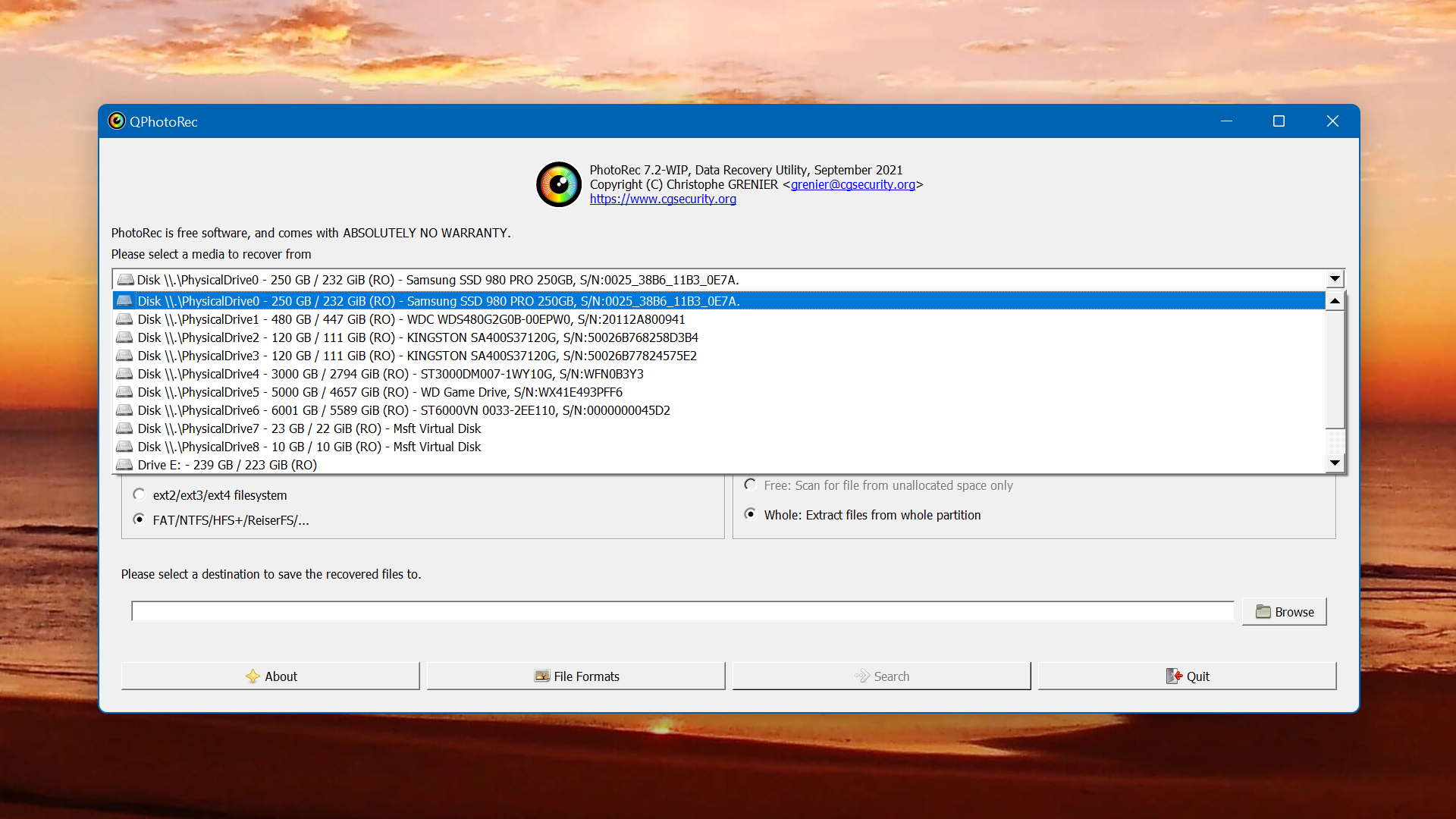
一、分页
分页设计在软件产品中随处可见,下图是一个最基础的分页器,支持上一页、下一页以及跳转到指定页的操作。

分页本身是一个妥协的设计,如果数据少,没有必要分页,如果数据多,分页也没有用,基本靠搜索,你可以想想平时在分页器上用得最多的,是不是就是“下一页”?
有些信息流的页面对分页的功能做了调整,如下图一样,只剩下一个“下一页”(加载更多)的操作,每次点击加载一页数据,之前已经加载的数据仍保留在页面上,这种技术,叫做“懒加载”。

后来,为了方便用户,“懒加载”又演变出一种新的交互形式,就是当列表快翻到页尾的时候,页面就自动进行“懒加载”,在用户看来,就好像没有了翻页的操作。

即使是“懒加载”,本质上还是需要翻页,只是弱化了用户对分页操作的感知,为什么不直接将全部内容显示出来?分页的意义在哪里?
你可以想象,如果你跟商家购买1吨的苹果,并要求商家将这吨苹果一次性放入你的仓库,商家装箱需要时间,运输需要时间,到达目的地卸货也需要时间,而因为货物太多,这几个时间加起来都非常长,其中任何一个环节出现问题都有可能导致你收到的苹果货不对板,比如商家装箱工人不足,处理不了这么多苹果的装箱工作;比如运输时间太长,过程中苹果腐烂或遗失;比如到达目的地发现仓库太小,容纳不了这么多苹果入库。
从技术上来讲,就是当你发送请求时,如果请求到的数据量很大,服务器处理大量数据可能会“超时”,数据传输过程中“失真”风险增加,访问载体加载大量数据时可能出现“假死”甚至“崩溃”的现象,这些都可能导致你无法获取到完整的信息。
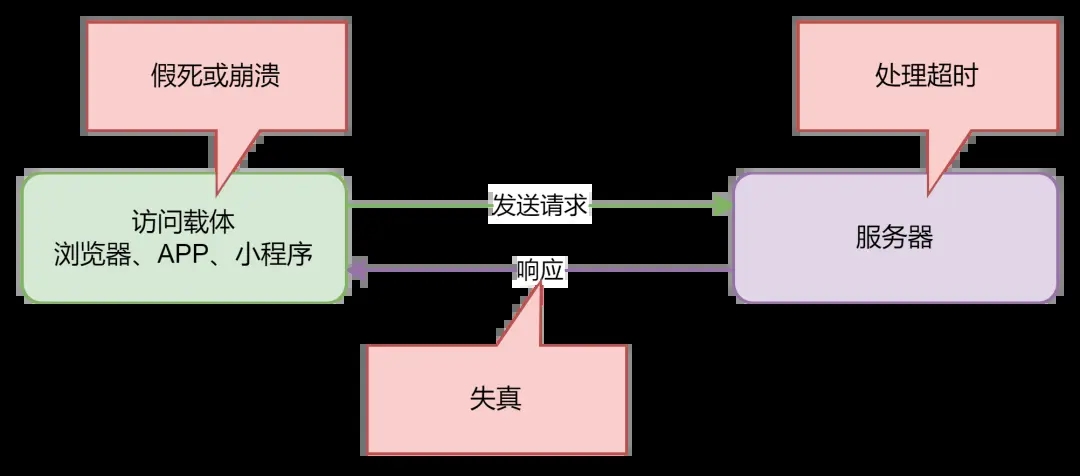
分页,就能解决这样的问题。
首先,服务器收到请求后,只响应1页数据(具体1页多少条数据由分页逻辑决定),这个时候传输的数据量很小,如果用户想要看更多内容,就可以通过分页器来选择下一页或跳转到指定页,当用户通过分页器发送指令之后,服务器再根据指令返回对应页的数据,这样,从“全量供应”变成了“按需供应”,减少了每次传输的数据量,不仅从等待的时间上改善了用户体验,也减轻了服务器的负担。
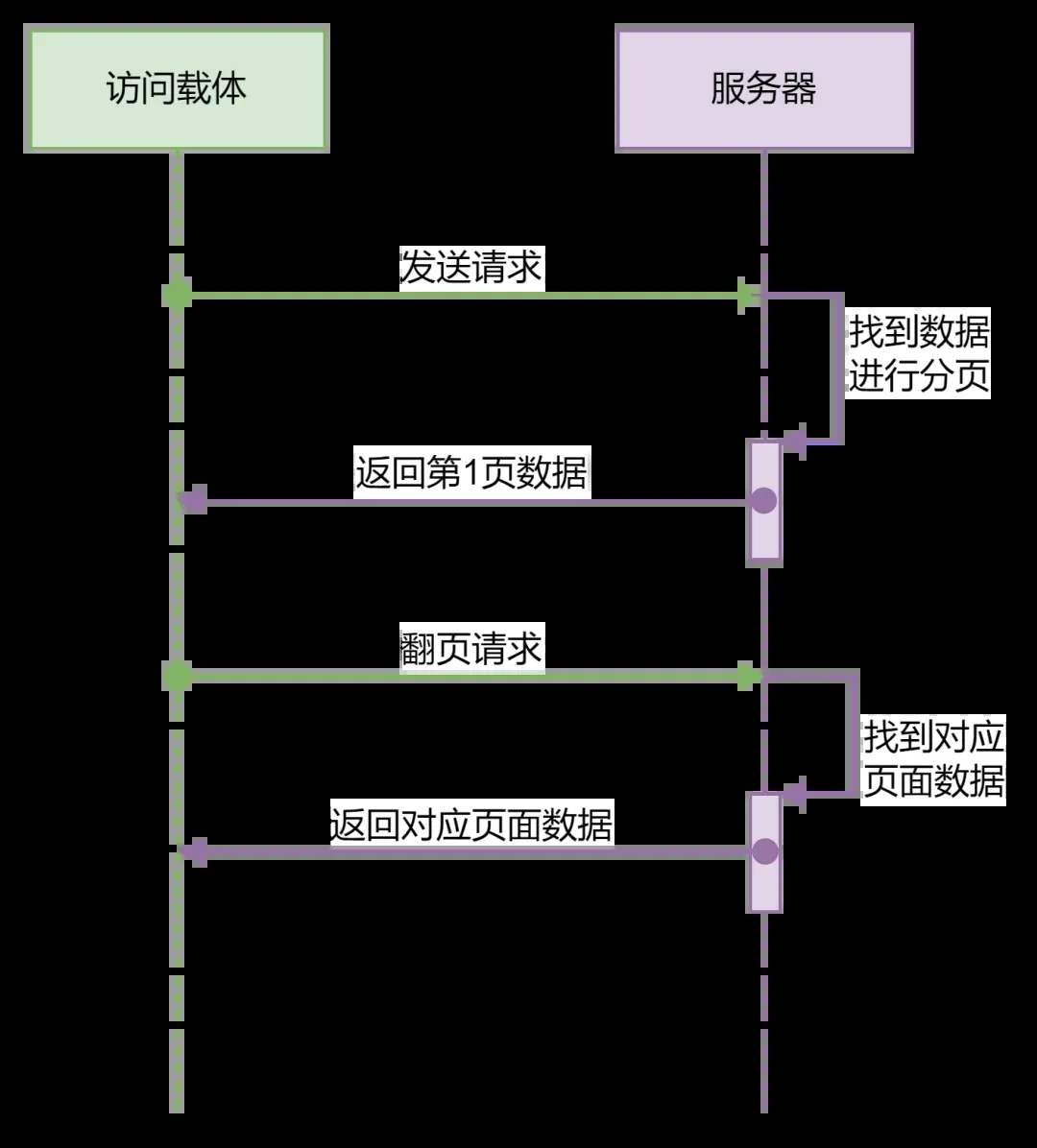
分页就好比你跟商家说要1吨苹果,商家说没问题,但每次只给你100斤,等你需要更多的时候,你再跟商家说,商家再给你100斤,直到1吨苹果全部给完为止,这样可以减轻商家的负担,缩短运输时间,降低运输风险,也可以给仓库留够余量。
现在很多分页器会提供每页显示多少条数据的操作,这就好比你可以告诉商家每次给你提供多少斤苹果,这种方式方便了用户自定义单次请求的数据量,又同时将单次请求的最大数据量控制在系统能够稳定处理的范围内。但说到底,它始终都是被迫妥协做出来的产品设计。

二、实时搜索
实时搜索并不是被迫妥协的设计,相反,它是一个对用户非常友好,体验极佳的设计。
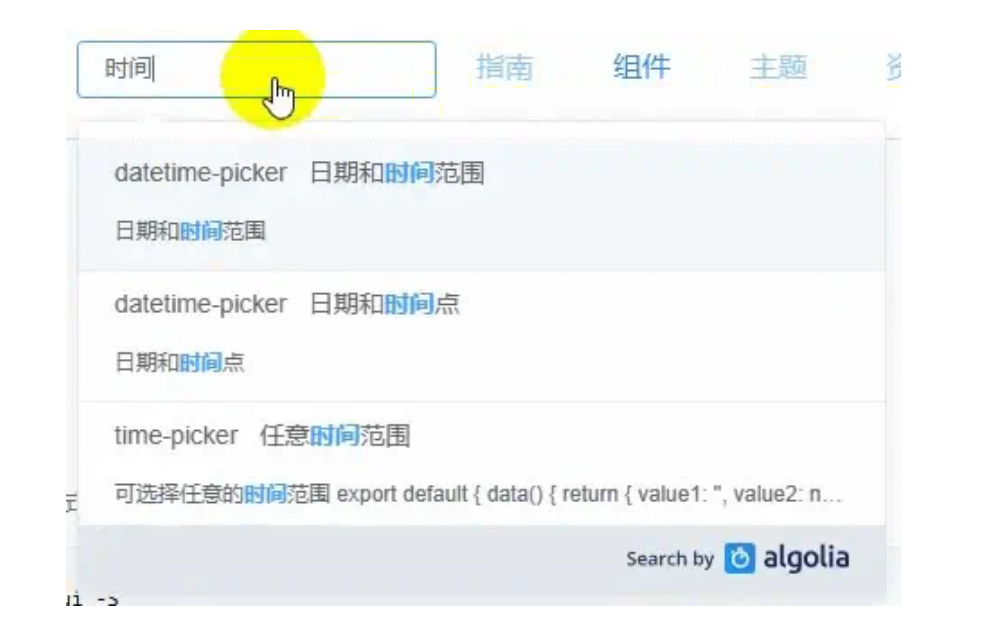
实时搜索是什么,是当我们提供搜索条件的时候,系统根据搜索条件实时匹配内容。如上图所示,当我们输入关键词时,系统就自动查询出匹配的结果。
可是这个设计,却并非在产品设计中随处可见,在系统设计中,更多的是像下图所示这样输入关键词之后手动触发查询。为什么实时搜索不能在产品设计中普及,而被迫妥协采用这样的设计呢。

首先我们要知道,实时搜索的每一次请求都可能是一次关键词不精准或不完整的查询,最终的结果可能是经过多轮查询后得到的,而手动触发搜索在关键词足够准确的情况下,只需要通过一轮查询就能得到最终结果。
还是那个苹果的例子,实时查询等于你先告诉商家你需要苹果,这个时候商家马上要给你做出回应,但是“苹果”这个词太笼统了,你到底是要苹果手机还是可以吃的苹果,商家也不清楚,所以只能将所有符合条件的商品都给你;这个时候你又向商家追加了关键词“新疆”,商家猜测,你应该是想要购买产地是新疆的苹果;最后你又追加了关键词“包邮”,此时商家重新在所有产地为新疆的苹果中找出支持包邮的。而手动触发搜索等于你直接告诉商家“苹果新疆包邮”,商家直接根据你的要求给你找出符合条件的结果。
从上述的例子我们可以看到,实时搜索查询请求次数更多,对服务器的资源消耗也更大,除了服务端的压力,前端访问载体需要在短时间内多次渲染查询结果,一边查询一边渲染,可能会造成页面卡顿等体验不好的结果。
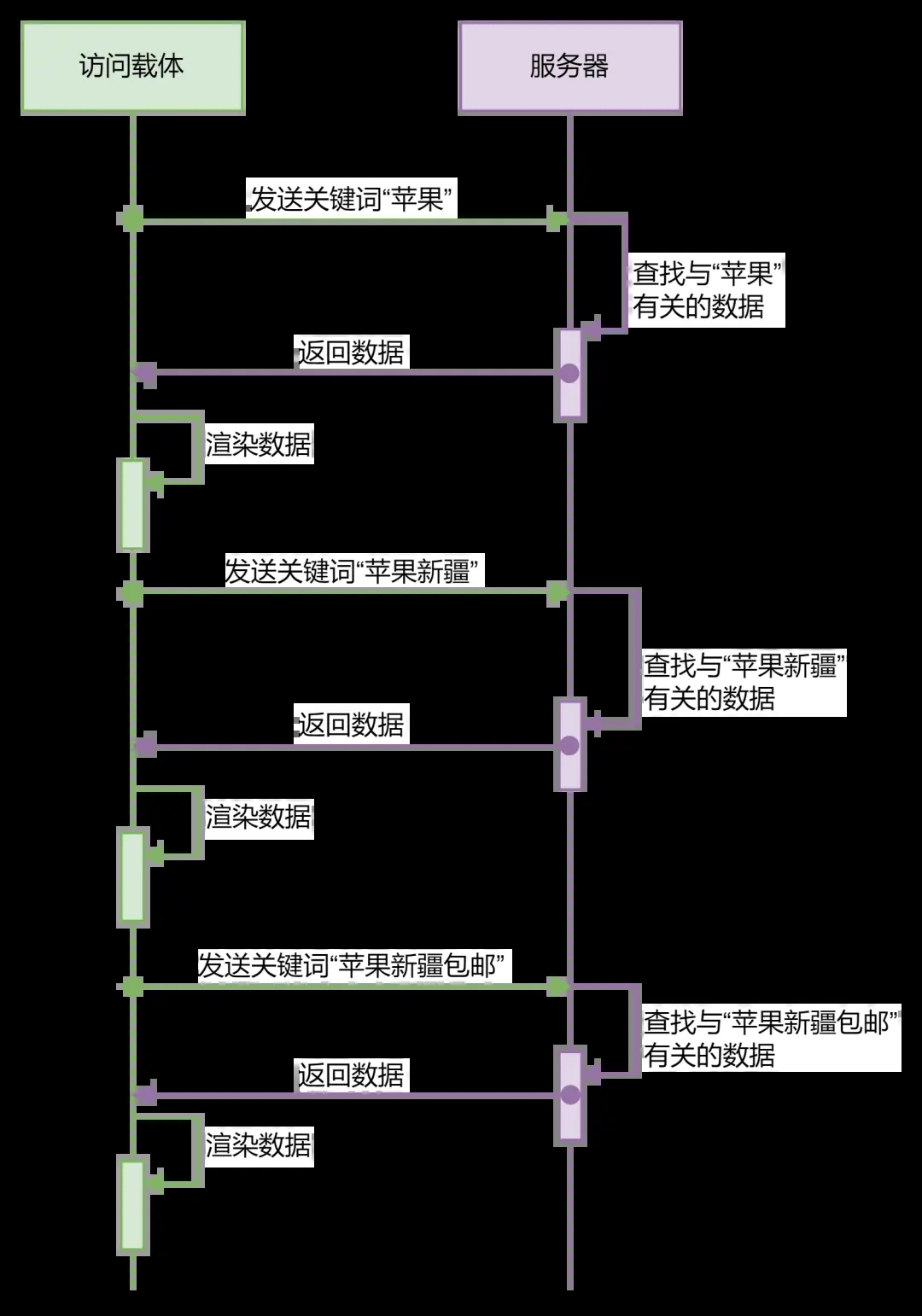
相比之下,要完成相同关键词的搜索,手动触发查询只需要进行一次查询和一次渲染就完成了,对服务器和访问载体更加友好。
你可能会以为手动触发搜索是为了避免实时搜索带来的频繁请求而造成服务器和访问端的压力,被迫妥协而诞生,而实际上,查询最早就是以手动触发查询的形式存在的,而实时搜索因为体验更加优秀而诞生,并在特定的场景下被使用。
什么情况下可以采用实时搜索设计呢?
1)数据体量小且增长可控或不会增长
比如国家的行政区划数据,数量级不会很大,且不会动不动就增加几十个省份或几百个城市的数据。
2)查询条件相对单一
现在有很多平台有聚合搜索的功能,一个输入框可以查询数据库的 N 个字段,这种如果做实时搜索服务器压力将非常大。
3)前端二次查询
查询是访问端发送关键词到服务端,服务端返回结果的过程,但有时候我们还会在拿到服务端的查询结果的情况下,直接在访问端做二次查询。比如我向服务端查询广东的城市,服务端返回了广东的所有城市名称,这个时候如果我想查询这些城市里面有没有我要找的,就可以在访问端做二次查询,由于结果已经事先从服务端拿到,现在是对结果进行二次查询,无需再次请求服务器,在这种情况下,也可以做实时搜索。
三、进度条 与 Loading
进度条是伟大的设计;比进度条更伟大的设计是进度条百分比,这个我们在上传时经常看到;比进度条百分比更伟大的设计是进度完成剩余时间,这个我们在下载时经常看到。
但等待的时间并不总是以进度条的形式出现,有时候陪伴我们度过等待时光的,叫做——Loading。

如果说,进度条卡在99.9%是一个令人抓狂的时间点,那么 Loading 动画出现时,就是另一个令人抓狂的时间点。当 Loading 动画出现的时候,就意味着一个信息,那就是没有任何信息,我们不知道它要持续多久,不知道它什么时候结束,加载时间太久我们甚至不知道它是还没加载完还是已经“死掉了”,也做不了任何操作,除了等待,我们没有任何办法。
虽然我们很希望在访问端发送请求时,能马上得到所有信息,但是因为服务器的处理、响应、访问端的渲染,包括物理端的存储(下载)等,都需要时间,为了让这个时间可视化,所以出现了进度条,那为什么还会出现 Loading 这个设计?为什么不把所有的 loading 都换成进度条呢?
1)懒得做
因为做进度条是需要计算总进度以及已完成和未完成进度来绘制出可视化的进度条图形,包括百分比和剩余时间,也都需要进行计算,相比直接显示 Loading 动画来说,开发量更大,有时候并不一定都是开发人员懒得做,而是企业或产品经理基于时间和成本考虑,以牺牲用户体验为代价,用 Loading 来取代进度条的设计。
2)效益低
这种就是在一些特定的场景下选择放弃进度条而改用 Loading 的设计,比如在上传图片时,系统限制了最大只能上传2M的图片,在5G的网速下这样的一张图片一瞬间就上传完了,这样的情况下,用户可能还没看到进度条出现就已经看到上传成功的提示,那这个进度条就没什么意义了,相反,有时候为了呈现完整的进度条动画,图片已经上传完了,进度条动画还没播放完,对用户来讲,体验就更加糟糕了。
3)难以量化
假如我有10个苹果,吃了一个,你可以说我吃掉了10%,但如果我咬了一口,问你我吃了多少,这个是很难准确回答的。同理,大文件的上传下载可以通过文件大小和网速来计算时间以及百分比,但是如果是查询、读取文本数据的时候,则较难量化。
虽然 Loading 是被迫妥协的设计,但每天为了用户体验“殚精竭虑”的产品经理们还是尽可能地让它变得更加友好,我们可以看看 Loading 的几个发展阶段。
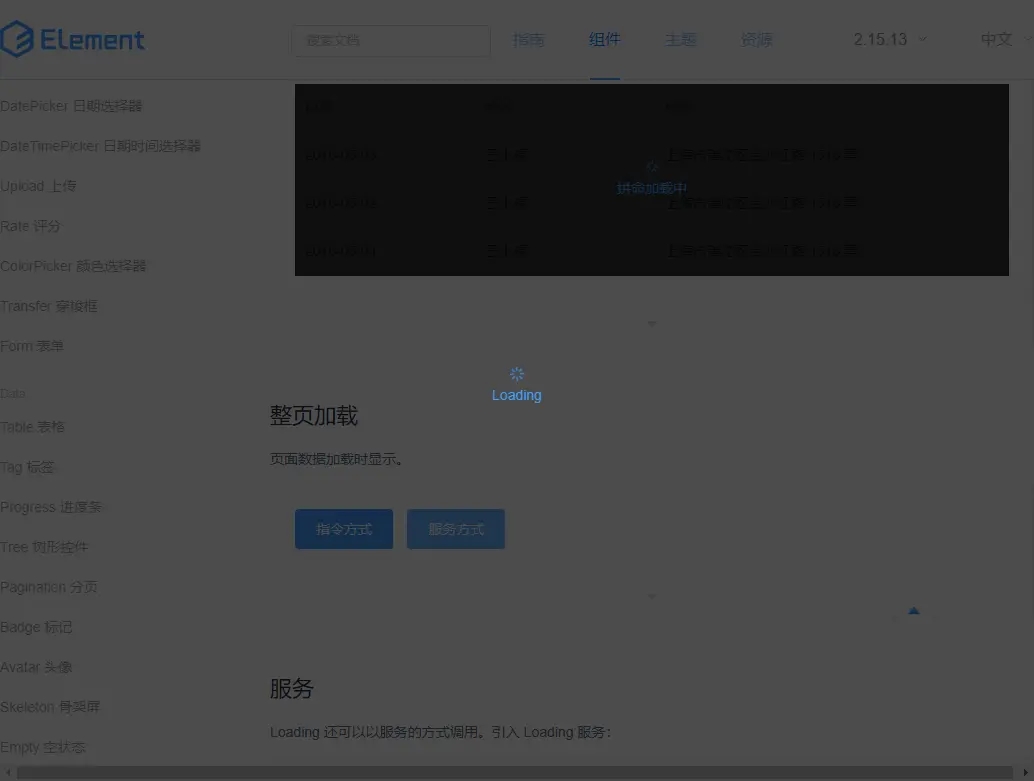
1、Loading 动画出现时,整个页面出现遮罩,什么都做不了,加载超时 Loading 动画也不会消失,只能刷新页面。
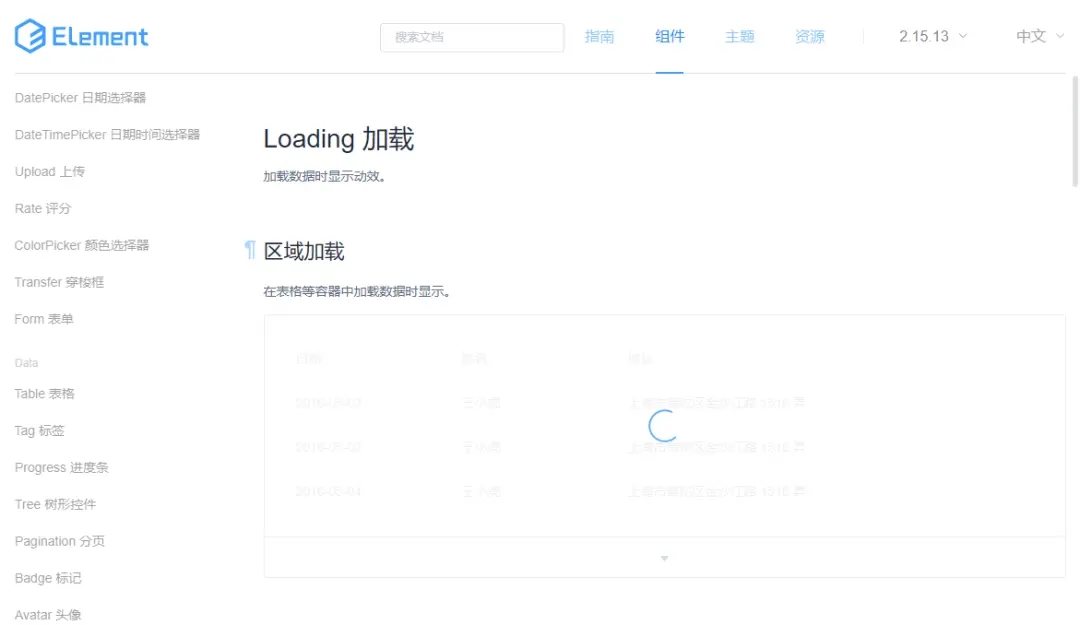
2、页面分区域加载,只在对应加载区域出现 Loading 动画,加载时不影响其他区域的操作。
3、在上一阶段的基础上,给 Loading 加一个延迟出现的时间,比如2秒,如果数据在2秒内就加载完成则不会出现 Loading 动画;设置加载超时时间,比如加载了10秒钟还没有出来,可能已经加载失败,则停止加载和 Loading 动画,允许用户手动点击重新加载。
什么情况下用进度条?什么情况下用 Loading?等待时间较长,但数据可量化的情况下,用进度条,比如上传、下载等;等待时间较短,或处理数据体量较小,或较难量化的情况下,用Loading,如提交、查询数据等。
四、并发
有时候我们在进行一些操作,比如点击一些按钮时,会发现它有一个处理的过程,在处理完成之前,不允许我们多次点击,如下图。

还有发送短信验证码的按钮,等待时间更长,要我们等60秒。

我们有这样一种体验,当我们在饭店吃饭的时候,如果上菜时间太久,我们一般会让服务员去后厨催一下厨师。
我们可以设想一下这种场景,我们刚让一个服务员去催菜,这个服务员还没走到后厨,我们又让另外一个服务员去催,同样,第二个服务员还没走到后厨,我们又让第三个服务员去催,接下来厨师就会连续收到3个服务员的催菜要求,你想想,这个厨师会怎样。
或者我们设想另外一种场景,我们让服务员去催菜,这个时候,另外两桌的客人也同时找了服务员去催菜,我们假设,如果这3个服务员刚好催的是同一个厨师,你可以想想,这个厨师会怎样。
上面所讲的例子,在技术中,叫做——“并发”。第一种场景是同一个用户短时间内重复发送相同的请求;第二种场景是多个用户同一时间发送相同的请求。
第一种场景中,可能是因为用户习惯性双击按钮,或者系统反应不够及时,让用户以为系统假死,用户会习惯性多次点击,或者系统遭遇病毒或网络爬虫的暴力请求,在这种情况下,系统会在短时间内收到多次相同的请求,这个时候系统往往还没有处理完前面的请求,就要介入处理新的请求,如果短时间内请求达到一定数量,可能会直接导致系统卡死。
针对这种场景的并发,一般处理方式有两种。
1)前端优化
功能触发后,在处理完成前禁止再次点击。这种就好比你刚找服务员催菜,没隔多久又找服务员催,服务员就告诉你,刚催过了,耐心等待。
2)后端策略
短时间内的多次点击只处理一次,比如在1秒内连续点击一个按钮,系统只当作是点击了一次处理。这种就好比你刚找服务员催菜,没隔多久又找服务员催,服务员说了一句好的就走开了,但是其实他没有帮你去催。
以上两种方式,条件允许的情况下前后端都应该同步做,比如上文提到的短信验证码,有时候我们点击发送按钮出现倒计时之后,刷新页面会发现发送按钮又可以点击了,但再次点击时,系统又提示发送验证码太频繁之类的,这就是前后端共同作用的效果,至于为什么要让用户等待60秒这么长的时间,除了基于系统性能原因考虑之外,另一个原因就是成本,假如平台用户量大,如果用户每点击一次就发送一条短信,那么每个用户无意间点多几下,平台可能就要支付巨额的短信费用。
第二种场景常见于秒杀,或者像过年大家都在平台上抢红包之类的,大量的用户涌入到平台,几乎同一时间都在发送相同的请求,这种场景考验的就不只是系统的稳定性,更考验服务器的性能,我们有时候会听到研发说每秒多少并发,指的就是系统最多能够处理多少个人同时发送的请求。
要处理这种场景的并发,首要是提升服务器的性能,支持更多并发数,这就是我们经常看到一些大平台,在大型节假日做活动之前,有时候会公告说在升级服务器、提升服务器性能之类的,这些手段都是为了服务器接下来在活动期间能够更好地迎接流量冲击。当然,服务器升级扩容等是有成本的,一定要根据平台的实际情况来确定,如果平台的最高并发数是10万,你把服务器性能提升到可承受100万并发数,那就大可不必。
另一方面,系统上也需要在一些容易产生高并发的操作中加入优化策略,比如我们有时候会遇到,在秒杀的时候,系统提示正在排队,其实是系统延迟向服务器发送你的请求,把你的请求放在一个队列中,按顺序发送请求,这样在一定程度上可以有效防止服务器因为一瞬间收到太多请求而承受不住。