一、概述
Motivation:GPT系列的模型,像GPT-3,CodeX,InstructGPT,ChatGPT,尽管很多人关注他们能力的不同,但是很少关注GPT系列模型随着时间变化其能力的变化情况。
Methods: 在9个NLU任务(21个数据集)上,评估了2个GPT-3系列,4个GPT-3.5系列模型的效果,同时基于zero-shot和few-shot场景都做了评估。
Finding:GPT系列模型在NLU任务上的表现并没有随着模型的演进而提升,特别是在经过RLHF训练策略后,反而限制了他解决任务的能力,同时其在模型鲁棒性上也有比较多的提升空间。
Conclusion:
随着GPT系列的演变,其能力并不是逐步增强,他与训练策略和任务的特性有关,同时尽管效果可能有提升,但是其鲁棒性也没有明显增强,这值得更多的研究。
如何平衡任务解决能力和用户友好的回复生成能力,也是一个值得研究的方向。
如何在提升performance的同时,提升鲁棒性也是一个值得研究的方向。
注意:gpt4 没有拿到api接口,所以没有来得及测试。
二、详细内容
Abstract

模型演变过程
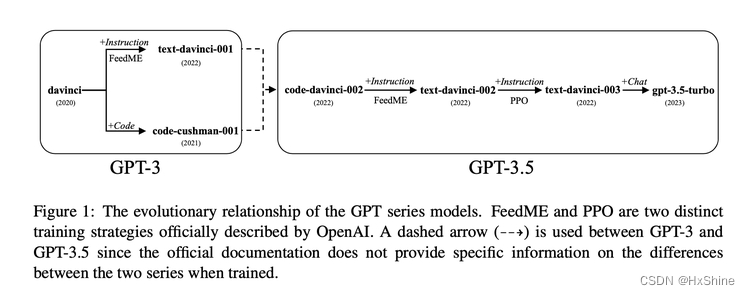
Experiment
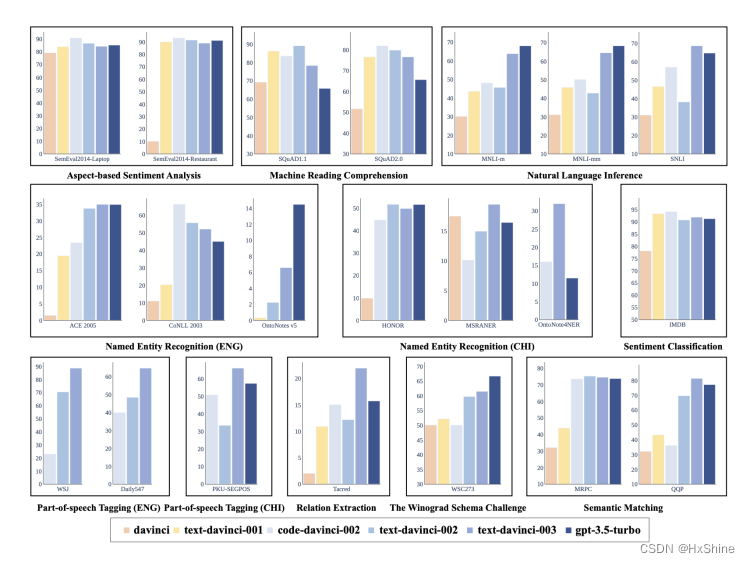
- 情感分析
- 有下降趋势,下降不多 阅读理解 下降挺明显,特别是经过强化学习训练后 NLI 还有一定提升
- NER(英文)
有些数据集下降挺明显,有些数据集还提升 - NER(中文)
下降趋势大一点,特别是强化学习后 - 情感匹配
- 有一点下降趋势
- 词性标注(part-of-speech Tagging 英文)
- 有不错的提升
- 词性标注(part-of-speech Tagging 中文)
- 下降
- 关系抽取
- 下降趋势大一点,特别是强化学习后
- 其他
- 从gpt3到gpt3.5还是有不少任务得到了提升
Conclusion

随着GPT系列的演变,其能力并不是逐步增强,他与训练策略和任务的特性有关,同时尽管效果可能有提升,但是其鲁棒性也没有明显增强,这值得更多的研究。
如何平衡任务解决能力和用户友好的回复生成能力,也是一个值得研究的方向。
如何在提升performance的同时,提升鲁棒性也是一个值得研究的方向。
注意:gpt4 没有拿到api接口,所以没有来得及测试。