笔记整理:毕祯,浙江大学博士,研究方向为知识图谱、自然语言处理
链接:https://arxiv.org/pdf/2303.03846.pd
本文是谷歌等机构最新发表的论文,旨在研究大模型上下文学习的能力。这篇论文研究了语言模型中的上下文学习是如何受到语义先验和输入-标签映射的影响。作者研究了两种不同的设置,并在各种模型(包括GPT-3, InstructGPT,Codex,PaLM和Flan-PaLM)上进行了实验。实验发现,对于小型语言模型来说,语义先验对于ICL的影响更大,而对于大型语言模型来说,即使有更强的语义先验,也可以通过反转标签或学习无关联标签的方式进行学习任务。此外,作者还发现通过指令学习可以增强语义先验和输入-标签映射的能力。
总体介绍
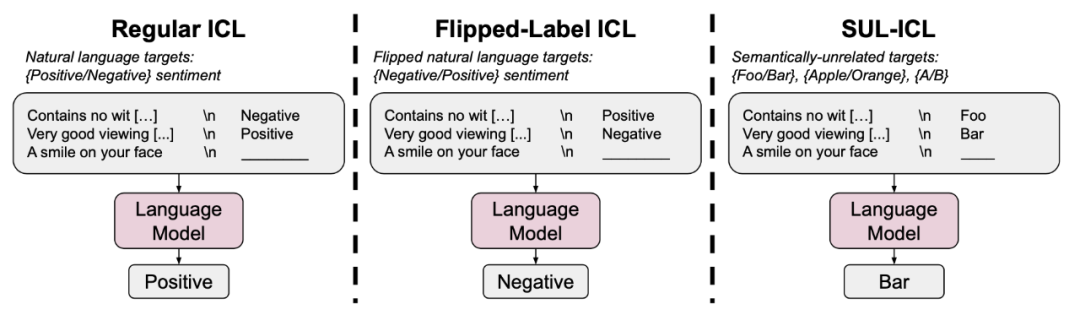
图1
本文展示了三种不同的上下文学习方式:常规上下文学习、反转标签的上下文学习以及不相关标签的上下文学习。在反转标签的上下文学习中,模型需要覆盖原有的语义先验,才能根据输入的示例执行任务。而在不相关标签的上下文学习中,标签与任务语义不相关,因此模型必须学习输入与标签之间的映射,才能执行任务,无法再依赖自然语言标签的语义信息。具体来说,三种不同的上下文学习方式如下:
(1)在常规上下文学习中,语义先验和输入-标签映射都能够使模型成功地进行上下文学习。
(2)在反转标签的上下文学习中,示例中的所有标签都被反转,这意味着语义先验知识和输入-标签映射不一致。评估集中的标签保持不变,因此对于二元分类任务,在此设置中表现优于50%的准确性意味着模型无法覆盖语义先验,而表现低于50%的准确性意味着模型能够学习输入-标签映射并覆盖语义先验。
(3)在不相关标签的上下文学习(SUL-ICL)中,标签与任务语义不相关(例如,在情感分析中,论文使用“foo/bar”代替“negative/positive”)。由于标签与任务语义不相关,模型必须学习输入与标签之间的映射来执行任务,无法再依赖自然语言标签的语义信息。
讨论分析
本文在多种模型上进行了实验,涵盖了不同大小、训练数据和指令学习(GPT-3、InstructGPT、Codex、PaLM、Flan-PaLM),以分析语义先验和输入-标签映射之间的相互作用,并特别关注结果如何随着模型规模的变化而变化。作者在七个被广泛应用于自然语言处理研究的任务上进行了实验。

图2
如图2所示,当面对翻转的标签时,大型模型具备通过覆盖先验语义来学习输入-标签映射的能力,而小型模型无法翻转预测,只会稍微降低性能。需要注意的是,评估示例的真实标签不会翻转。因此,如果模型学会跟随翻转的标签,则其准确性应在超过50%的标签翻转时低于50%。
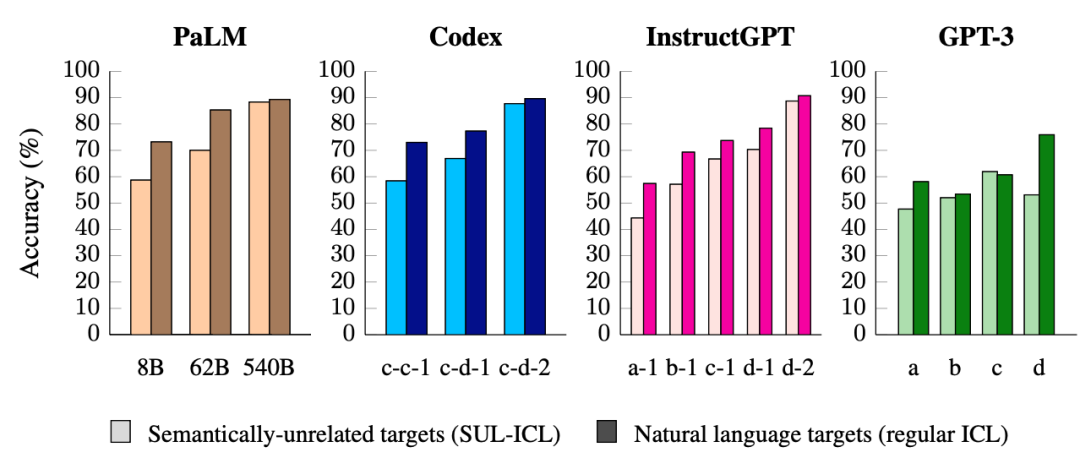
图3
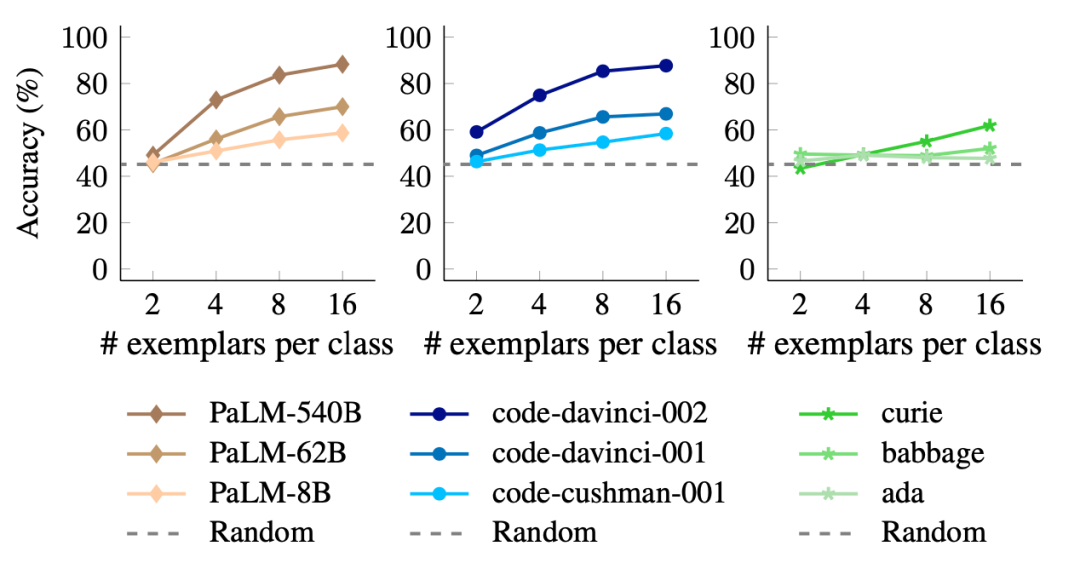
图4
如图3所示,小型模型对语义先验的依赖程度比大型模型更高,因为当使用语义不相关的目标代替自然语言目标时,小型模型的性能下降比大型模型更多。同时在图4的SUL-ICL设置中,较大的模型比较小的模型更受益于额外的示例。
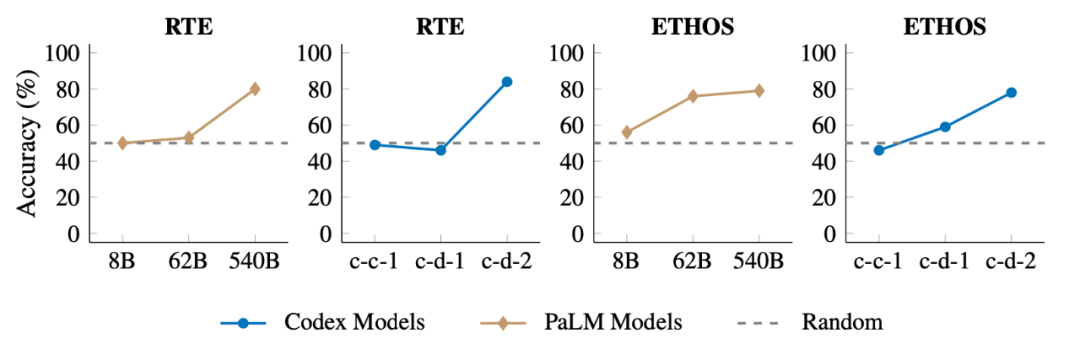
图5
如图5所示,在SUL-ICL环境中,某些任务是随着模型规模的增加而出现的,只有足够大的模型才能成功执行这些任务。
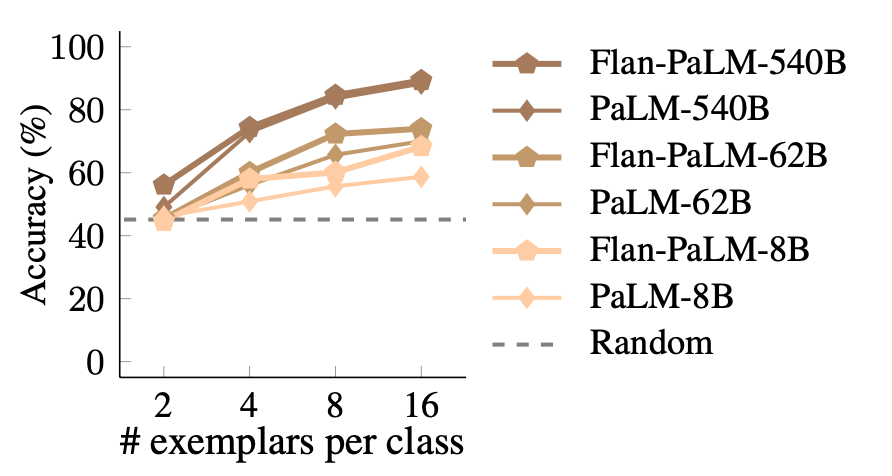
图6
如图6所示,PaLM和Flan-PaLM模型在所有数据集上平均性能与上下文范例数量的关系。可以看到在SUL-ICL环境中,Flan-PaLM的表现比PaLM更好,这种效果在小型模型中最为显著,因为Flan-PaLM-8B的表现优于PaLM-8B 9.6%,几乎赶上了PaLM-62B。这种趋势表明,指令学习可以增强学习输入-标签映射的能力。
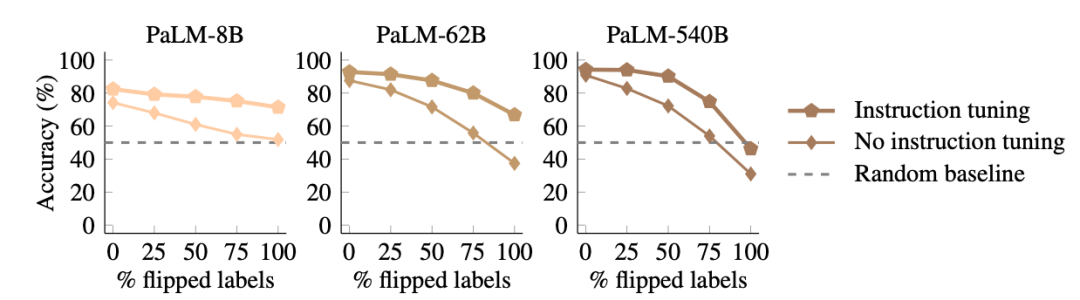
图7
在图7中,论文展示了每个PaLM和Flan-PaLM模型相对于标签翻转比例的性能。与仅使用预训练的模型相比,指令学习的模型更不擅长翻转预测。即使在100%标签翻转的情况下,Flan-PaLM模型也无法超越随机猜测的程度来覆盖它们的语义。而标准的PaLM模型则可以在呈现100%翻转标签时,将准确率降至31%。这些结果表明,指令学习要么增加了模型在有语义先验条件下的依赖程度,要么为模型提供了更多的语义先验,因为指令学习的模型在面对翻转标签时更不擅长翻转其自然语言目标。结合图6的结果,指令学习可以改善模型学习输入-标签映射的能力,但它同时增强了语义先验的使用。
总结
本文研究了语言模型在预训练过程中所学习的先验知识和输入标签映射的上下文学习能力。研究发现,大型语言模型可以学习覆盖语义先验,这种能力与模型规模有关。为了消除标签的语义意义,作者提出了一种实验设置,即语义无关标签上下文学习(SUL-ICL),并发现这种上下文学习能力也与模型规模有关。此外,研究还分析了经过指令学习的语言模型,并发现指令学习可以提高学习输入-标签映射的能力,但同时也强化了语义先验。最后,研究还分析了语言模型在高维线性分类任务上的表现,并发现这种表现能力也与模型规模有关。总之,这些结果表明,语言模型的上下文学习行为会随着模型规模的不同而改变,而大型语言模型具有将输入映射到多种类型标签的能力,这是一种真正的符号推理形式。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。