Contents
- Installation
- Implement
- 1、一个最简单的OpenMP代码:
- 2、如何规定线程数
- 2、如何设置OpenMP分配线程的schedule
- 3、 冲突避免机制 --Reduction(规约)
- Discovery
写在最前面:
并行化虽好,但并不是所有任务在并行化后都能得到性能的提升!
首先要满足的是所要完成的任务量远大于分配其他线程的消耗。
Installation
一般Ubuntu系统自带
Implement
1、一个最简单的OpenMP代码:
#include <iostream>
#include <omp.h>
using namespace std;
int main(){
#pragma omp parallel default(none) shared(cout) // This is the parallel region
{
int ID = omp_get_thread_num();
int num = omp_get_num_threads();
cout << "Hello World " << ID << " from " << num << endl;
}
代码编译:
| 命令 | 编译方式 |
|---|---|
| gcc/g++ –fopenmp hello_world.c | gcc |
| icc/icpc –openmp hello_world.c | intel (linux) |
| cc –openmp hello_world.c | Cray |
| pgcc –mp hello_world.c | pgi |
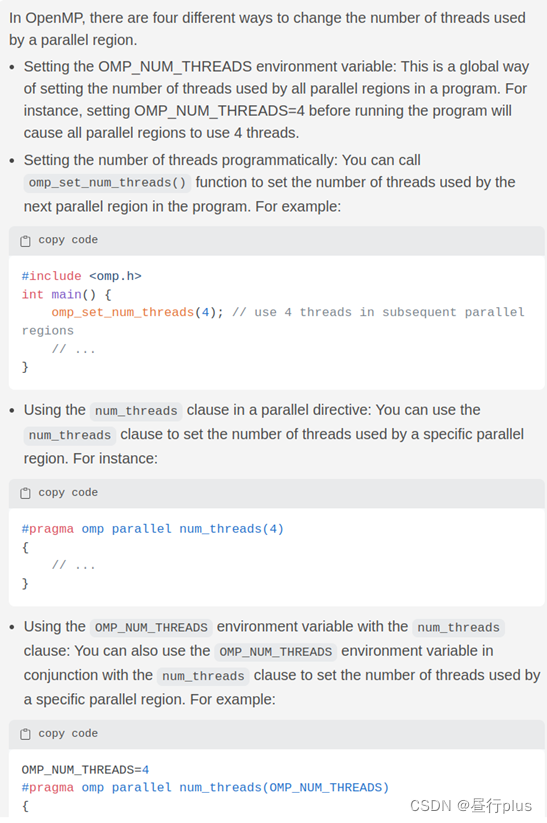
2、如何规定线程数
有三种方法,下面是当初的截图,忘了翻译了… 或者问GPT也行。
2、如何设置OpenMP分配线程的schedule
| schedule | description |
|---|---|
| Static | (默认)Chunk-size固定,线程所执行的chunk固定 |
| Dynamic | Chunk-size固定,线程按需请求chunk执行 |
| Guided | Chunk-size逐渐降低,线程按需请求chunk执行 |
没法说哪个更好,你每个线程的任务基本一致的话static理论上比较好,如果不一致的话Dynamic和Guided可能更好。针对不同的任务需要自己测试后择优。
更详细介绍的看:
OpenMP的schedule机制
3、 冲突避免机制 --Reduction(规约)
OpenMP的reduction指令用于将计算结果从并行循环中的多个线程合并为单个结果。通过使用reduction指令,每个线程都会维护一个私有的变量,并在循环结束时将这些变量组合成单个结果。
支持多种操作符:+、-、*、/、max、min等
使用OpenMP的reduction指令计算向量中所有元素的和的示例:
#include<omp.h>
#include<stdio.h>
#include<stdlib.h>
#define SIZE 10000000
int main() {
int i;
double sum = 0.0;
double *array = (double*) malloc(SIZE * sizeof(double));
// 初始化数组
for (i = 0; i < SIZE; i++) {
array[i] = i * 0.1;
}
// 使用OpenMP并行计算数组总和
#pragma omp parallel for default(none) reduction(+: sum)
for (i = 0; i < SIZE; i++) {
sum += array[i];
}
printf("Sum of array elements = %lf\n", sum);
free(array);
return 0;
}
上例中,通过使用#pragma omp parallel for reduction(+: sum)指令,将计算数组所有元素总和的任务划分给多个线程并使用加法操作符(+)将每个线程私有的sum变量的值累加到共享的sum变量中,最终输出结果的正确和最终值。
Discovery
另外经过实验我发现,针对同一代码,使用C编译和C++编译得到的性能是不同的。
如针对下面这个计算圆周率
π
\pi
π的例子:
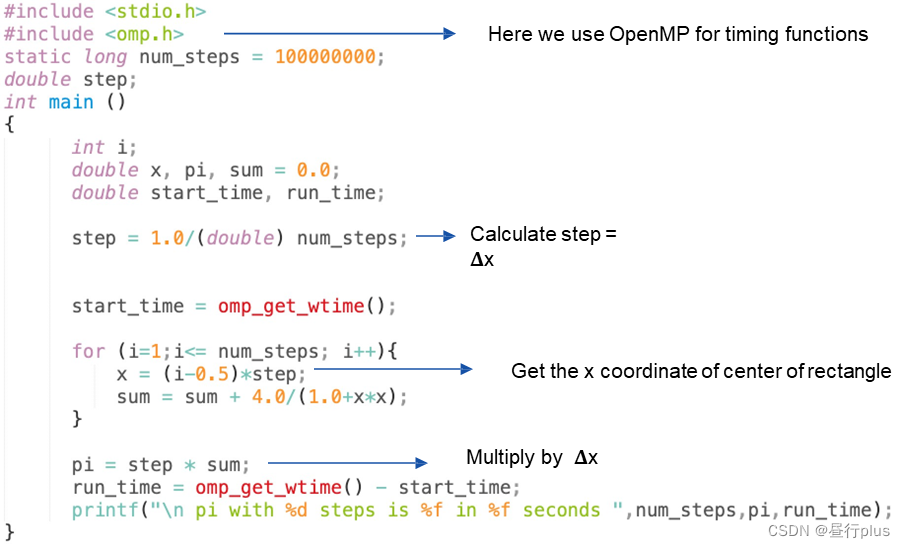
相关理论在这:
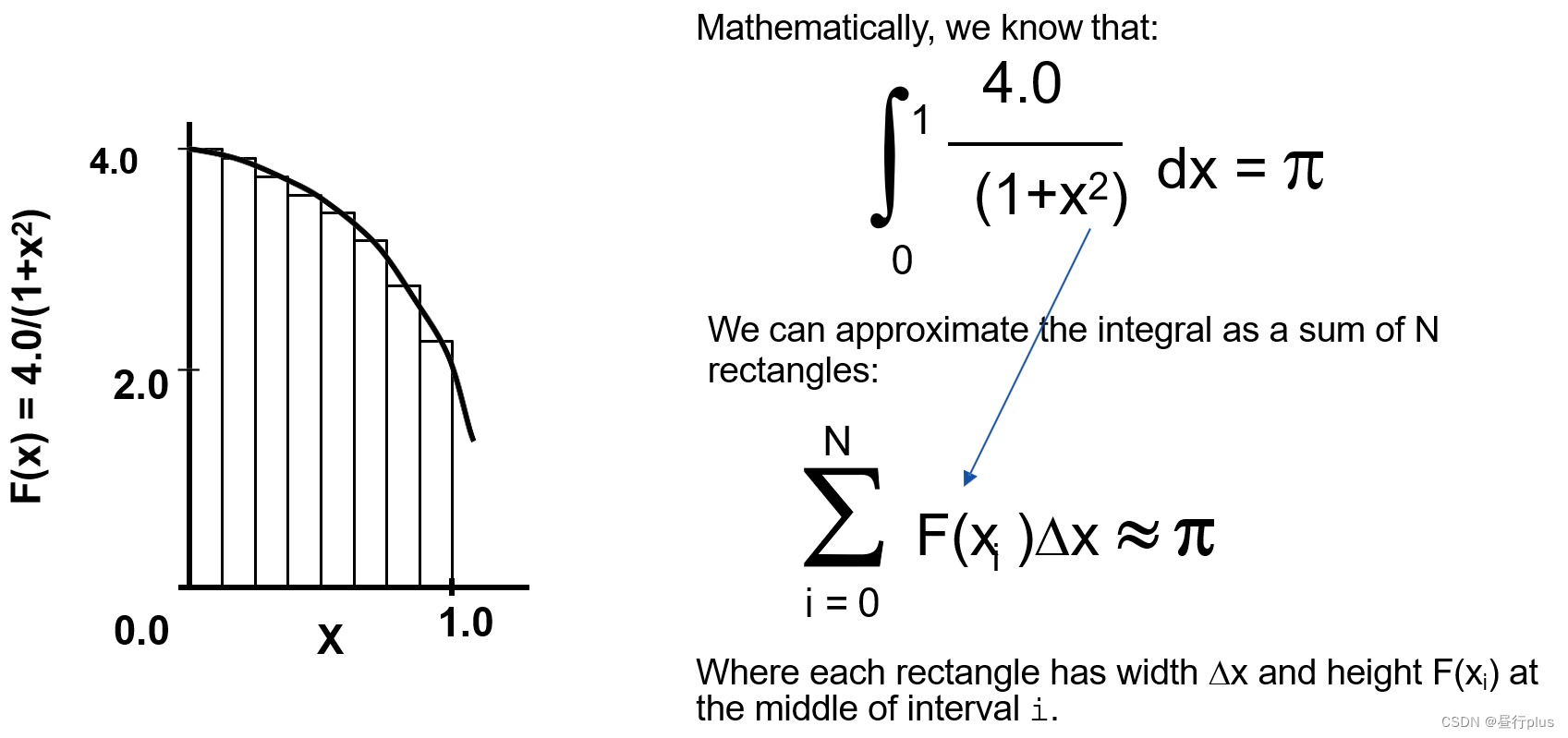
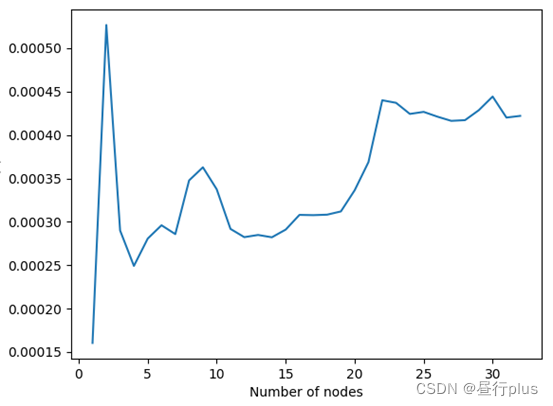
现在来看下随着使用的线程数增加,我们的运算耗时如何变化:
PC的CPU: AMD 5800H
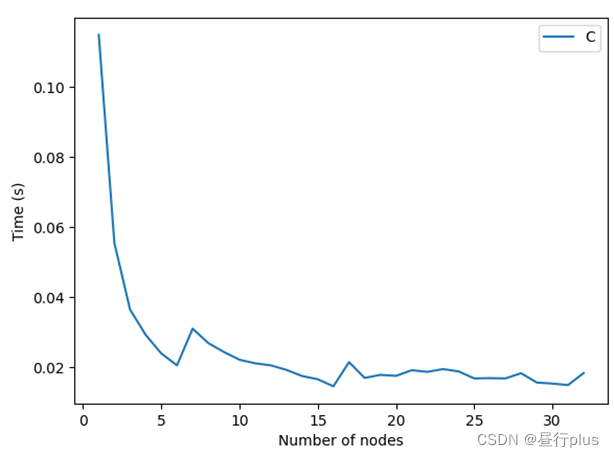
C++编译后的性能变化趋势如下:
可以看到,C的结果与我们的预想基本一致,线程数越大运算越快;线程数大到一定程度速度就不怎么增加了。
而C++的结果却出乎意料,但仅就耗时的数量级来看,C++的性能是远高于C的。我暂时还不能解释原因…