MapReduce 编程规范
MapReduce 的开发一共有八个步骤, 其中 Map 阶段分为 2 个步骤,Shuffle 阶段 4 个步骤,Reduce 阶段分为 2 个步骤
Map 阶段 2 个步骤
- 设置 InputFormat 类, 将数据切分为 Key-Value(K1和V1) 对, 输入到第二步
- 自定义 Map 逻辑, 将第一步的结果转换成另外的 Key-Value(K2和V2) 对, 输出结果
Shuffle 阶段 4 个步骤
- 对输出的 Key-Value 对进行分区
- 对不同分区的数据按照相同的 Key 排序
- (可选) 对分组过的数据初步规约, 降低数据的网络拷贝
- 对数据进行分组, 相同 Key 的 Value 放入一个集合中
Reduce 阶段 2 个步骤
- 对多个 Map 任务的结果进行排序以及合并, 编写 Reduce 函数实现自己的逻辑, 对输入的 Key-Value 进行处理, 转为新的 Key-Value(K3和V3)输出
- 设置 OutputFormat 处理并保存 Reduce 输出的 Key-Value 数据
MapReduce 运行模式
本地运行模式
- MapReduce 程序是被提交给 LocalJobRunner 在本地以单进程的形式运行
- 处理的数据及输出结果可以在本地文件系统, 也可以在hdfs上
- 怎样实现本地运行? 写一个程序, 不要带集群的配置文件, 本质是程序的 conf 中是否有
mapreduce.framework.name=local 以及
yarn.resourcemanager.hostname=local 参数
- 本地模式非常便于进行业务逻辑的 Debug , 只要在 Eclipse 中打断点即可
1 configuration.set("mapreduce.framework.name","local");
2 configuration.set("yarn.resourcemanager.hostname","local");
3 TextInputFormat.addInputPath(job,new Path("file:///F:\\wordcount\\input"));
4 TextOutputFormat.setOutputPath(job,new Path("file:///F:\\wordcount\\output"));
集群运行模式
- 将 MapReduce 程序提交给 Yarn 集群, 分发到很多的节点上并发执行
- 处理的数据和输出结果应该位于 HDFS 文件系统
- 提交集群的实现步骤: 将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
hadoop jar hadoop_hdfs_operate-1.0-SNAPSHOT.jar cn.itcast.hdfs.demo1.JobMain
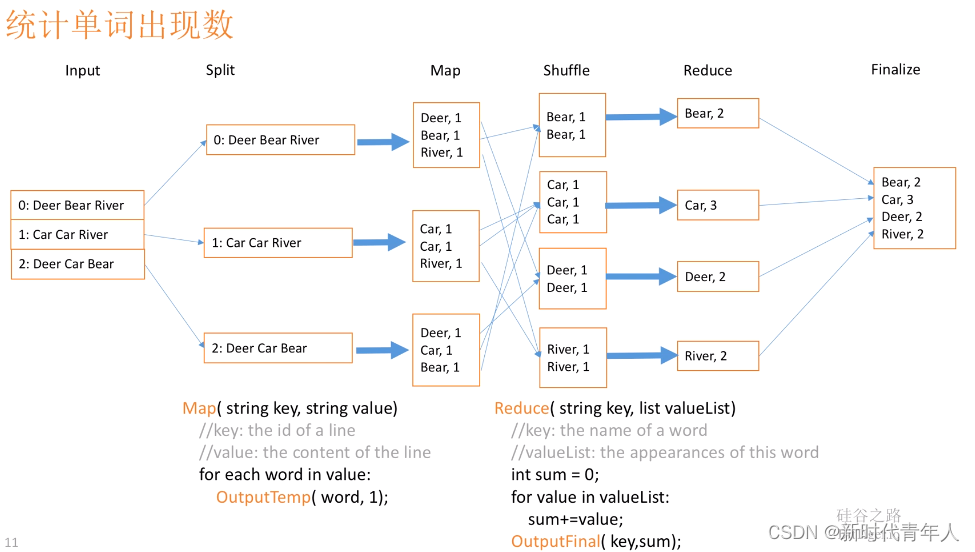
MapReduce 分区
在 MapReduce 中, 通过我们指定分区, 会将同一个分区的数据发送到同一个 Reduce 当中进行处理
例如: 为了数据的统计, 可以把一批类似的数据发送到同一个 Reduce 当中, 在同一个 Reduce 当中统计相同类型的数据, 就可以实现类似的数据分区和统计等其实就是相同类型的数据, 有共性的数据, 送到一起去处理
Reduce 当中默认的分区只有一个
MapReduce 排序和序列化
- 序列化 (Serialization) 是指把结构化对象转化为字节流
- 反序列化 (Deserialization) 是序列化的逆过程. 把字节流转为结构化对象. 当要在进程间传递对象或持久化对象的时候, 就需要序列化对象成字节流, 反之当要将接收到或从磁盘读取的字节流转换为对象, 就要进行反序列化
- Writable 是 Hadoop 的序列化格式, Hadoop 定义了这样一个 Writable 接口. 一个类要支持可序列化只需实现这个接口即可
- 另外 Writable 有一个子接口是 WritableComparable, WritableComparable 是既可实现序列化, 也可以对key进行比较
MapReduce的运行机制详解
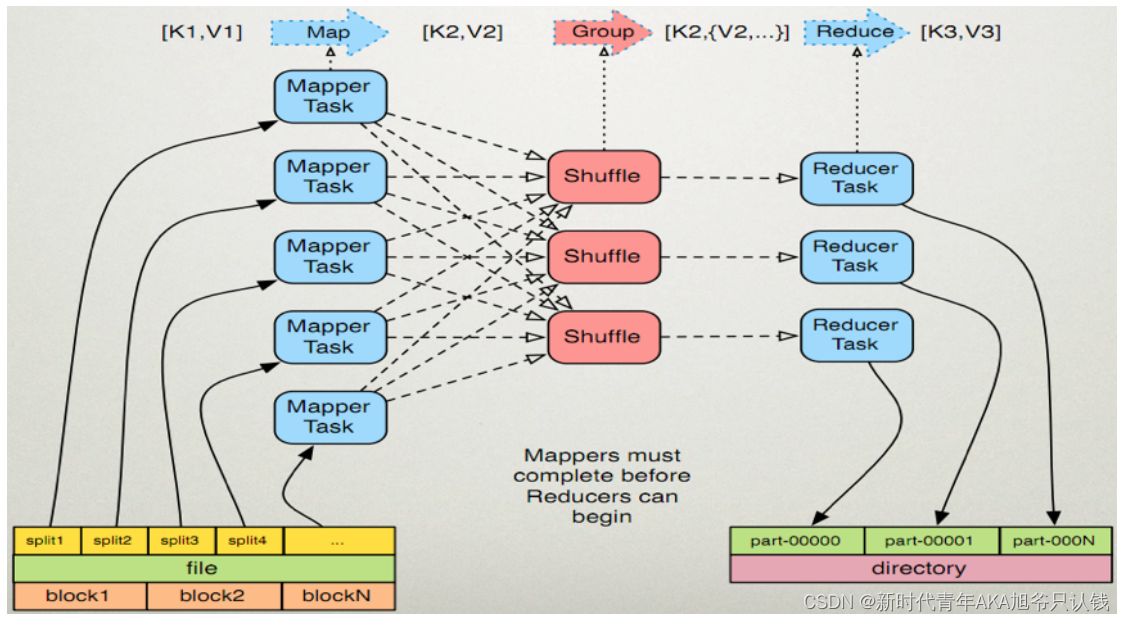
MapTask 工作机制
- 读取数据组件InputFormat(默认TextInputFormat)会通过getSplits方法对输入目录中文件进行逻辑切片规划得到block,有多少个block就对应启动多少个MapTask。
- 将输入文件切分为block之后,由RecordReader对象(默认是LineRecordReader)进行读取,以\n作为分隔符,读取一行数据,返回<key,value>。Key表示每行首字符偏移值,Value表示这一行文本内容
- 读取block返回<key,value>,进入用户自己继承的Mapper类中,执行用户重写的map函数,RecordReader每读取一行block中的内容,这里调用一次map函数
- Mapper逻辑结束之后,将Mapper的每条结果通过context.write进行collect数据收集。在collect中,会先对其进行分区处理,来决定当前的这对输出数据最终应该交由哪个Reduce task处理(默认使用HashPartitioner对Key Hash后再以Reducer数量取模)
- 接下来,会将数据写入内存,内存中这片区域叫做环形缓冲区,缓冲区的作用是批量收集
Mapper结果,减少磁盘IO的影响。我们的Key/Value对以及Partition的结果都会被写入缓冲区。当然,写入之前,Key与Value值都会被序列化成字节数组。 - 当溢写线程启动后,需要对这80MB空间内的Key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序
- 合并溢写文件,每次溢写会在磁盘上生成一个临时文件(写之前判断是否有Combiner),如果Mapper的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个临时文件存在。当整个数据处理结束之后开始对磁盘中的临时文件进行Merge合并,因为最终的文件只有一个,写入磁盘,并且为这个文件提供了一个索引文件,以记录每个reduce对应数据的偏移量
环形缓冲区其实是一个数组,数组中存放着Key,Value的序列化数据和Key,Value的元数据信息,包括Partition,Key的起始位置,Value的起始位置以及Value的长度。环形结构是一个抽象概念。
缓冲区是有大小限制,默认是100MB。当Mapper的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。这个溢写是由单独线程来完成,不影响往缓冲区写Mapper结果的线程。溢写线程启动时不应该阻止Mapper的结果输出,所以整个缓冲区有个溢写的比例spill。percent。这个比例默认是0。8,也就是当缓冲区的数据已经达到阈值 buffersize*spillpercent=100MB*0.8=80MB,溢写线程启动,锁定这80MB的内存,执行溢写过程。Mapper的输出结果还可以往剩下的20MB内存中写,互不影响
如果Job设置过Combiner,那么现在就是使用Combiner的时候了。将有相同Key的Key/Value对的Value加起来,减少溢写到磁盘的数据量。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用
那哪些场景才能使用Combiner呢?从这里分析,Combiner的输出是Reducer的
输入,Combiner绝不能改变最终的计算结果。Combiner只应该用于那种Reduce的输入Key/Value与输出Key/Value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定得慎重,如果用好,它对Job执行效率有帮助,反之会影响Reducer的最终结果
ReduceTask 工作机制
- Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
- Sort阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
- Reduce阶段:reduce()函数将计算结果写到HDFS上。
Shuffle阶段
map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 shuffle—(核心机制:数据分区,排序,分组,规约,合并等过程)
shuffle是Mapreduce 的核心,它分布在 Mapreduce的map阶段和reduce 阶段。一般把从Map 产生输出开始到 Reduce 取得数据作为输入之前的过程称作 shuffle。
- Collect阶段:将 MapTask 的结果输出到默认大小为 100M 的环形缓冲区,保存的是 key/value,Partition 分区信息等。
- Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了 combiner,还会将有相同分区号和 key 的数据进行排序。
- Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个 MapTask 最终只产生一个中间数据文件。
- Copy阶段:ReduceTask 启动 Fetcher 线程到已经完成 MapTask 的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
- Merge阶段:在 ReduceTask 远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
- Sort阶段:在对数据进行合并的同时,会进行排序操作,由于 MapTask 阶段已经对数据进行了局部的排序,ReduceTask 只需保证 Copy 的数据的最终整体有效性即可。
Shuffle中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
缓冲区的大小可以通过参数调整, 参数:mapreduce.task.io.sort.mb 默认100M
HDFS&Map-Reduce&YARN工作提交全流程
| HDFS | YARN | MapReduce |
|---|---|---|
| DataNode NameNode | ResourceManager NodeManager ApplicationMaster Container | MrAppMaster:负责整个程序的过程调度及状态协调。 MapTask:负责Map阶段的整个数据处理流程。 ReduceTask:负责Reduce阶段的整个数据处理流程。 |
- 在客户端执行submit()方法之前,会先去获取一下待读取文件的信息,然后行程一个任务划分的规划
- YarnRunner向ResourceManager申请一个Application。RM将该应用程序的资源路径返回给YarnRunner。
- 将job提交给yarn,这时候会带着三个信息过去(job.split;.jar;job.xml)程序资源提交完毕后,申请运行mrAppMaster。
- yarn 会根据文件的切片信息去计算将要启动的maptask的数量,然后去启动maptask;
- maptask会调用inputFormat()方法去HDFS上面读取文件。inputFormat()方法会再去调用RecordRead()方法,将数据以行首字母的偏移量为key,一行数据为value传给mapper()方法;
- mapper方法做一下逻辑处理后,将数据传到分区方法中,对数据进行一个分区标注后,发送到环形缓冲区中;
- 环形缓冲区默认的大小是100M,达到80%的阈值将会溢写;
- 在溢写之前会做一个排序的动作,排序的规则是按照key进行字典序排序,排序的手段是快排;
- 在溢写会产生出大量的溢写文件,会再次调用marge()方法,使用归并排序默认10个溢写文件合并一个大文件;
- 也可以对溢写文件做一个localReduce也就是combiner的操作,但前提是combiner的结果不能对最终的结果有影响;
- 等待所有的maptask结束后,会启动一定数量的reducetask;
- reducetask会发起拉取线程到map端拉取数据,拉取到数据会先加载到内存中,内存不够会写到磁盘里,等待所有数据拉取完毕,会将这些输出再进行一次归并排序;
- 归并后的文件会在进行一次分组的操作,然后再将数据以组为单位发送到reduce方法();
- reduce方法做一下逻辑判断后,最终调用OutputFormat()会再调用RecordWrite()方法将数据以KV的信息写到HDFS上;