文章目录
- 前言
- 1. 栈
- 1.1 栈的概念及结构
- 1.2栈的实现
- 1.2.1 动态or静态
- 1.2.2 结构介绍
- 1.2.3 初始化栈
- 1.2.4 销毁栈
- 1.2.5 压栈
- 1.2.6 出栈
- 1.2.7 判空
- 1.2.8 取栈顶元素
- 1.2.9 获取有效元素个数
- 1.3 测试
- 1.4 源码展示
- 1.4.1 stack.h
- 1.4.2 stack.c
- 1.4.3 test.c
- 2. 队列
- 2.1 队列的概念及结构
- 2.2 队列的实现
- 2.2.1 结构
- 2.2.2 初始化队列
- 2.2.3 销毁队列
- 2.2.4 队尾入数据
- 2.2.5 队头出数据
- 2.2.6 取队头元素
- 2.2.7 取队尾元素
- 2.2.8 队列判空
- 2.2.9求队列有效元素个数
- 2.3 测试
- 2.4 源码展示
- 2.4.1 Queue.h
- 2.4.2 Queu.c
- 2.4.3 Test.c
前言
这篇文章我们继续线性表的学习,今天我们要学习两种特殊的线性表——限定性线性表,通俗点说,就是操作受限制的线性表。
也是非常常用的两种数据结构:栈和队列!
1. 栈
首先我们来学习栈。
1.1 栈的概念及结构
首先我们来了解一下什么是栈:
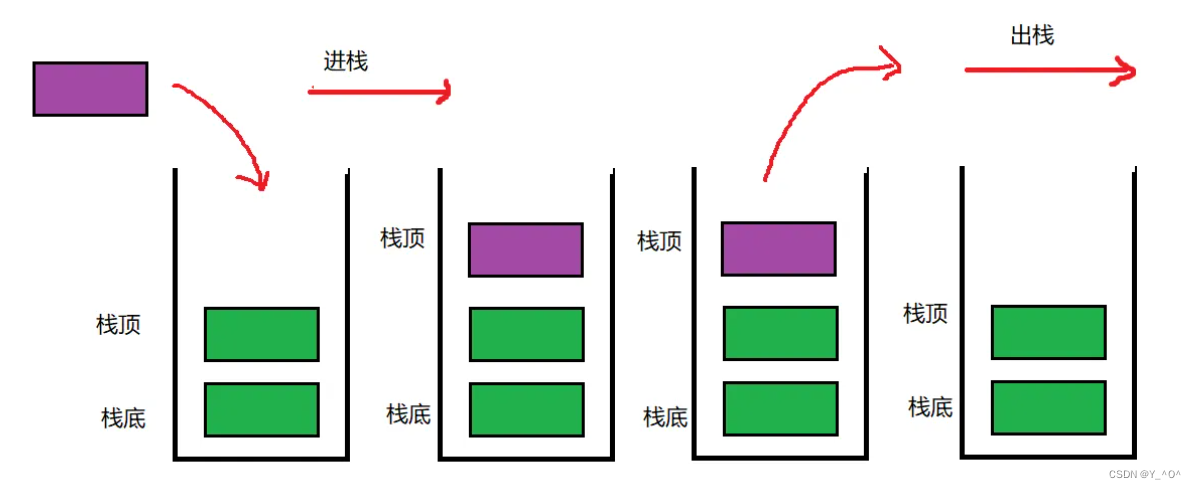
栈(stack)又名堆栈,它是一种运算受限的线性表。
其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
也可以说是先进后出。
向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素。
从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
即入数据和出数据都在栈顶。
1.2栈的实现
了解了什么是栈以及栈的性质,接下来我们就来上手实现一个栈。
那要这么实现呢?
我们之前已经学了两种线性表:链表和顺序表(数组)。
我们说栈和队列是操作受限制的线性表。
因此,栈的实现可以使用数组实现,也可以使用链表实现。
那选择哪一种方式更好呢?
相对而言数组的结构实现更优一些。因为数组在尾上插入删除数据的代价比较小。
下面,我们就用数组来实现一个栈。
1.2.1 动态or静态
和顺序表一样,我们选择数组来实现,可以实现成静态的(即数组的大小是固定的)栈:
typedef int STDataType;
#define N 10
typedef struct Stack
{
STDataType _a[N];
int _top; // 栈顶
}Stack;
也可以选择实现成动态的栈,还是用数组,只不过我们使用动态开辟的数组,这样的话一开始我们不用给太多空间,如果不够用我们可以进行扩容。
那我们选择那种呢?
定长的静态栈的结构,实际中一般不实用,所以我们下面主要实现的支持动态增长的栈。
1.2.2 结构介绍
动态栈的结构是什么样子的?
起始和顺序表差不多,因为我们这里本身就是选择用顺序表来实现栈的。
typedef int STDataType;
typedef struct Stack
{
STDataType* arr;//指向动态开辟的数组
int top;//top为0,表示指向栈顶元素的下一个,也是元素个数
//top为-1,指向栈顶元素
int capacity;//容量
}ST;
简单解释一下:
首先我们还是把栈定义成了一个结构体,因为它不仅仅是一个简单的数组,还有一些其它的属性,所以我们放在了一个结构体中。
因为栈入数据和出数据都是在栈顶进行操作,所以我们定义了一个
top来标识栈顶 ,而top呢?
一般有两种取值,0和-1。
top为0,表示指向栈顶元素的下一个。
每插入一个数据,top++,同时top也是栈中有效数据的个数。
top为-1,指向栈顶元素。
插入数据时top要先++(因为数组下标从0开始),然后再插入数据。
除此之外:
还有一个capacity用来标识栈的容量,因为我们实现的时动态增长的栈,容量时可变的,我们可以扩容。
1.2.3 初始化栈
还是和顺序表一样,在对栈初始化时:
我们可以选择给它一个合适的大小,也可以先不给它分配空间,在我们插入数据时再动态申请空间。
那在实现顺序表的时候我们没有给初始空间,这里我们就换一个写法,给它一个初始空间。
//初始化栈
void StackInit(ST* ps)
{
assert(ps);
//不给初始大小
/*ps->arr = NULL;
ps->capacity = 0;
ps->top = 0;*/
//给一些空间
ps->arr = (STDataType*)malloc(sizeof(STDataType) * 4);
if (ps->arr == NULL)
{
perror("malloc fail!");
exit(-1);
}
ps->capacity = 4;
ps->top = 0;
}
正常情况下,ps接收我们定义好的栈的结构体地址,不可能为空,所以我们加一个断言
assert(ps);,这里我们上去先给栈开辟了4个整型的大小(当然这个按自己的想法随便给),所以capacity要赋值为4,此时栈中还没有入数据,在这里我们选择top的初值为0,即指向栈顶元素的下一个。
1.2.4 销毁栈
与初始化对应,我们就直接把销毁写了:
因为我们实现的时动态增长的栈,数组的空间是在堆上动态开辟的,需要我们最后使用free释放的,否则会发生内存泄漏。
//销毁栈
void StackDestroy(ST* ps)
{
assert(ps);
free(ps->arr);
ps->arr = NULL;
ps->capacity = 0;
ps->top = 0;
}
销毁的逻辑很简单,把
ps->arr指向的栈的空间释放掉,把top和capacity都置为0 就行了。
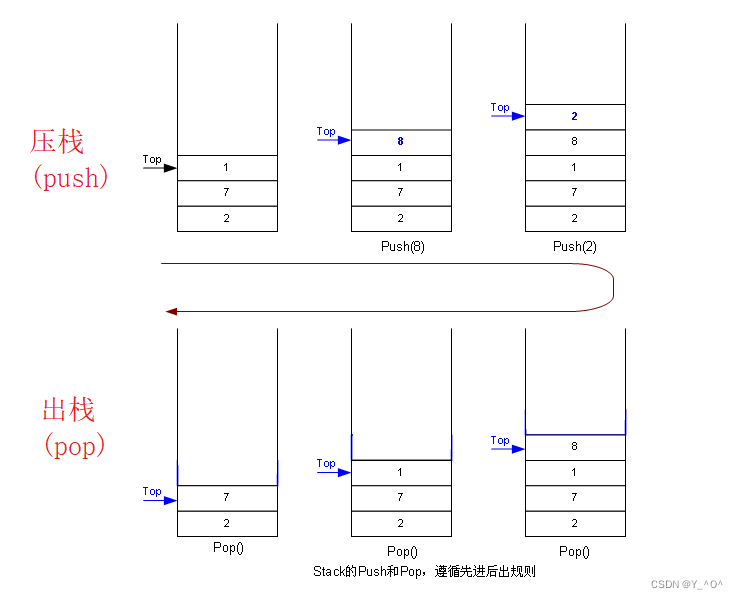
1.2.5 压栈
栈初始化好了,那就往里放数据啊,接下来就写一下压栈对应的函数:
压栈就是从栈顶入数据,怎么入呢?
很简单,就是往数组里放元素嘛,放到那个位置呢?
是不是就是下标为top的位置啊。
因为我们选的top初值为0,数组下标呢也从0开始,那直接放就行了,然后top++,还是指向栈顶的下一个位置。
那有没有什么需要注意的呢?
别忘了,我们初始化只给个4个容量,那就只能入4个数据,所以呢,每次数据压栈之前,我们要检查一下容量。
那是不是也很简单,顺序表的时候我们已经写过。什么时候需要扩容?
是不是ps->top == ps->capacity,因为top从0开始的话,top的值就是栈中有效数据的个数,所以ps->top == ps->capacity就是栈满了,此时需要扩容,这里我们还是选择扩到原来的两倍。
//压栈
void StackPush(ST* ps, STDataType x)
{
assert(ps);
//检查栈满了需要扩容
if (ps->top == ps->capacity)
{
STDataType* tmp = (STDataType*)realloc(ps->arr, sizeof(STDataType) * ps->capacity * 2);
if (tmp == NULL)
{
perror("realloc fail!");
exit(-1);
}
ps->arr = tmp;
ps->capacity *= 2;
}
ps->arr[ps->top] = x;
ps->top++;
}
1.2.6 出栈
出栈就太简单了。
我们只需要让
top--就行了,以后再插入新数据的时候,会覆盖掉原来的值,不会产生任何影响。
当然,这里要注意进行一个判断assert(!StackEmpty(ps));(这个函数我们马上就会实现,栈为空返回真,不空返回假),如果栈为空,就不能再出栈元素了。
//出栈
void StackPop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
ps->top--;
}
1.2.7 判空
既然上面判空的时候使用到了判空的函数,我们就先实现一下:
判空也很容易,直接返回
ps->top == 0,如果等于0 ,就是空,该表达式结果为真,不等于0,就是非空,表达式结果为假。
//判空
bool StackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}
1.2.8 取栈顶元素
栈顶元素怎么取?
是不是就是下标为top的元素,直接拿就行,当然也要记得进行一个判断,如果栈空了,自然没法取了。
//取栈顶元素
STDataType StackTop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
return ps->arr[ps->top - 1];
}
1.2.9 获取有效元素个数
上面已经说过了,我们初始化top的值为0,top的值就是有栈中有效数据的个数。
所以,直接返回top的值就行了。
//获取栈中有效元素个数
int StackSize(ST* ps)
{
assert(ps);
return ps->top;
}
写完这几个函数,大家可能会想,有的函数这么简单,一句代码就搞定了,为什么还要封装成一个函数,有必要嘛?
那我们接下来就来讨论一下这个问题,就拿
StackSize这个函数来说,top就是数据个数,我们直接就可以获取,好像没必要再去写一个函数,再调用这个函数去获取栈中的元素个数。
但是呢?
我们这里的栈是自己写的,我们知道top的初值是0,代表的是元素个数。但是top一定是0吗,我们说过top是不是还可以取值为-1。
那如果你拿到一个别人写的栈,人家的实现一定和你想的一样吗?是不是有可能不一样啊,那这时如果没有提供对应的函数,你想获取栈中的数据个数,是不是还得去看一下栈的具体实现啊,看人家的top是怎么定义的。
但是如果提供的有接口函数(即使非常简单),那这对于使用者来说是不是就更加方便啊,使用者不必关心数据结构的具体实现,直接调用相关函数即可。
设想你是使用者,你希望开发的人怎么搞,是不是还是把所有的功能封装好提供给你啊,而不是觉得某一个函数很简单,让使用者自己解决。
因此,好的做法还是封装成一个函数,即使这个函数的实现可能很简单。
那到这里,栈的几个接口函数我们就实现完毕了。
1.3 测试
我们来简单的测试一下我们写的栈:
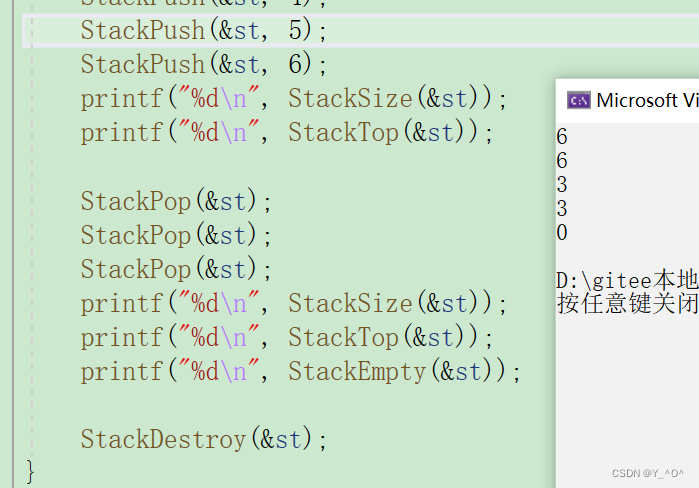
int main()
{
ST st;
StackInit(&st);
StackPush(&st, 1);
StackPush(&st, 2);
StackPush(&st, 3);
StackPush(&st, 4);
StackPush(&st, 5);
StackPush(&st, 6);
printf("%d\n", StackSize(&st));
printf("%d\n", StackTop(&st));
StackPop(&st);
StackPop(&st);
StackPop(&st);
printf("%d\n", StackSize(&st));
printf("%d\n", StackTop(&st));
printf("%d\n", StackEmpty(&st));
StackDestroy(&st);
return 0;
}
1.4 源码展示
下面把源码分享给大家:
1.4.1 stack.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
typedef int STDataType;
typedef struct Stack
{
STDataType* arr;
int top;//top为0,表示指向栈顶元素的下一个,也是元素个数
//top为-1,指向栈顶元素
int capacity;
}ST;
//初始化栈
void StackInit(ST* ps);
//销毁栈
void StackDestroy(ST* ps);
//压栈
void StackPush(ST* ps, STDataType x);
//出栈
void StackPop(ST* ps);
//取栈顶元素
STDataType StackTop(ST* ps);
//获取栈中有效元素个数
int StackSize(ST* ps);
//判空
bool StackEmpty(ST* ps);
1.4.2 stack.c
#define _CRT_SECURE_NO_WARNINGS
#include "Stack.h"
//初始化栈
void StackInit(ST* ps)
{
assert(ps);
//不给初始大小
/*ps->arr = NULL;
ps->capacity = 0;
ps->top = 0;*/
//给一下空间
ps->arr = (STDataType*)malloc(sizeof(STDataType) * 4);
if (ps->arr == NULL)
{
perror("malloc fail!");
exit(-1);
}
ps->capacity = 4;
ps->top = 0;
}
//销毁栈
void StackDestroy(ST* ps)
{
assert(ps);
free(ps->arr);
ps->arr = NULL;
ps->capacity = 0;
ps->top = 0;
}
//压栈
void StackPush(ST* ps, STDataType x)
{
assert(ps);
//检查栈满了需要扩容
if (ps->top == ps->capacity)
{
STDataType* tmp = (STDataType*)realloc(ps->arr, sizeof(STDataType) * ps->capacity * 2);
if (tmp == NULL)
{
perror("realloc fail!");
exit(-1);
}
ps->arr = tmp;
ps->capacity *= 2;
}
ps->arr[ps->top] = x;
ps->top++;
}
//出栈
void StackPop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
ps->top--;
}
//取栈顶元素
STDataType StackTop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
return ps->arr[ps->top - 1];
}
//获取栈中有效元素个数
int StackSize(ST* ps)
{
assert(ps);
return ps->top;
}
//判空
bool StackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}
1.4.3 test.c
#include "Stack.h"
int main()
{
ST st;
StackInit(&st);
StackPush(&st, 1);
StackPush(&st, 2);
StackPush(&st, 3);
StackPush(&st, 4);
StackPush(&st, 5);
StackPush(&st, 6);
printf("%d\n", StackSize(&st));
printf("%d\n", StackTop(&st));
StackPop(&st);
StackPop(&st);
StackPop(&st);
printf("%d\n", StackSize(&st));
printf("%d\n", StackTop(&st));
printf("%d\n", StackEmpty(&st));
StackDestroy(&st);
return 0;
}
2. 队列
接下来我们来学习队列,那什么是队列呢?
2.1 队列的概念及结构
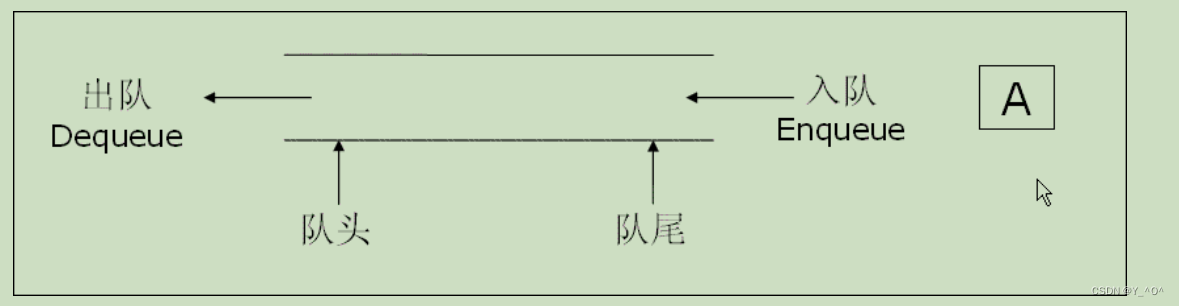
队列是一种特殊的线性表,和栈一样,队列是一种操作受限制的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。
进行插入操作的端称为队尾,进行删除操作的端称为队头。
队列具有先进先出FIFO(First In First Out)的特性。
2.2 队列的实现
队列也可以采用数组和链表两种结构实现。
那对于队列来说,采用哪一种结构实现更好呢?
使用链表的结构实现更优一些,因为如果使用数组的结构,出队列在数组头上的元素,需要挪动数据,效率会比较低。
那链表也有好几种啊。
在这里我们采用单链表来实现队列,单链表就可以了,还能节省一个指针,没必要用双向的或其它更复杂的结构。
那要不要带哨兵位的头呢?
可以带,也可以不带。
带头的好处就是第一次尾插的时候比较方便,不用单独判断,这里我们就不带头,和我们之前写的单链表一样。
那要不要循环呢?
也不需要循环,单链表循环的话,就是尾结点的next指针域指向头,如果我们要找尾还是得从头找。
如果是双向循环的话拿头结点就可以直接找到尾,这里我们采用单链表,循环也没什么用。
2.2.1 结构
那既然我们用单链表来实现,首先就需要有一个结点结构:
typedef int QDataType;
//结点结构
typedef struct QueueNode
{
QDataType data;
struct QueueNode* next;
}QNode;
一个数据域,一个指针域。
然后呢,我们再来想一下:
我们知道队列只允许在队尾入数据,在队头出数据,那对于单链表来说,其实就是只能头删和尾插。
我们知道单链表找尾的话就需要从头遍历找尾,那如果我们每次往队列里入数据的时候,都去遍历找尾,是不是就太麻烦了,所以我们再加一个尾指针来记录尾结点的位置,方便我们尾插。
那正常情况下不是还有一个头指针嘛,现在就有两个指针。
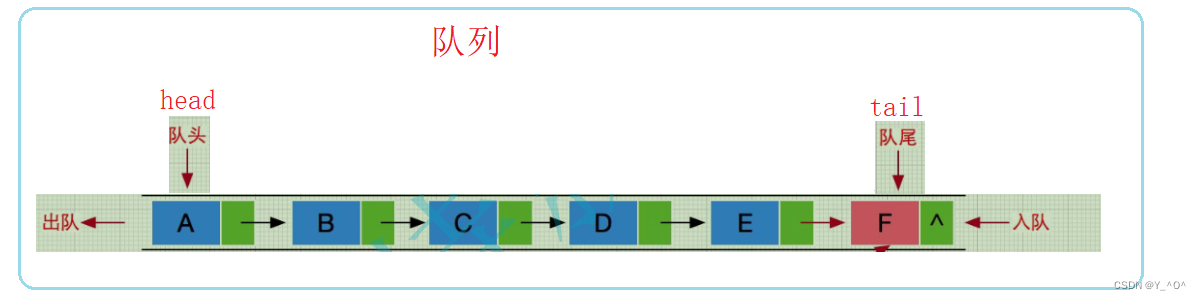
那对于队列来说,有一个头指针指向队头,有一个尾指针指向队尾,我们就可以再搞一个结构体:
//队列结构
typedef struct Queue
{
QNode* head;
QNode* tail;
int size;
}Queue;
除此之外,通常情况下,我们还要获取队列中有效元素的个数,所以我们可以再给队列的结构体加一个成员size,每次入数据我们让size++,每次出数据让size–,这样要获取元素个数的时候直接访问size就行了,不需要我们再遍历队列计算数据个数,就比较方便。
2.2.2 初始化队列
单链表我们没有写初始化的函数,为什么?
因为单链表是不是定义一个头指针就行了,拿到这个头指针,就相当于拿到了整个链表,没必要再写一个函数。
那我们的队列虽然是采用单链表来实现的,但是这里是不是又多了一个尾指针啊,而且还有一个size。
所以呢,我们干脆就加一个初始化的函数。
//初始化队列
void QueueInit(Queue* pq)
{
assert(pq);
pq->head = NULL;
pq->tail = NULL;
pq->size = 0;
}
初始头尾指针都指向空,size为0。
2.2.3 销毁队列
初始化写了,那我们就直接把销毁写了。
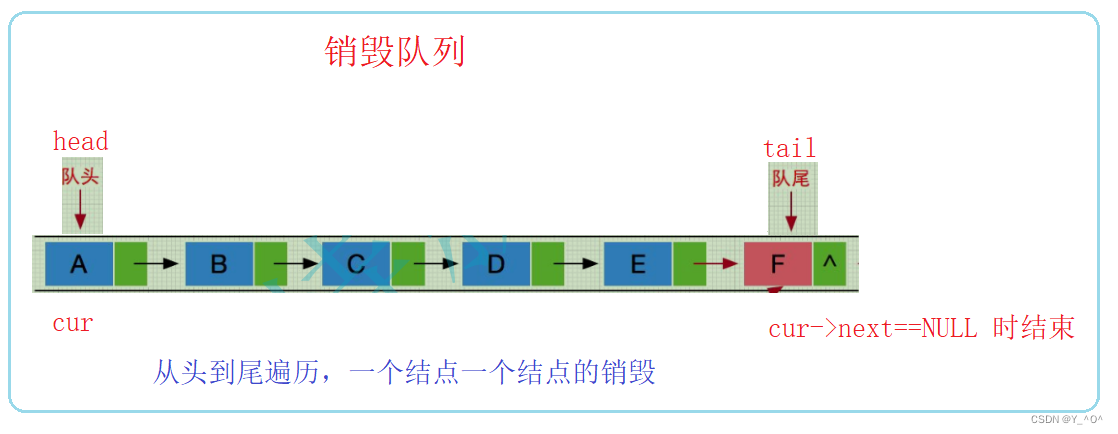
销毁那就和单链表的销毁一个道理,遍历,然后一个结点一个结点的销毁就行了。
//销毁队列
void QueueDestory(Queue* pq)
{
assert(pq);
QNode* cur = pq->head;
while (cur)
{
QNode* nextnode = cur->next;
free(cur);
cur = nextnode;
}
pq->head = pq->tail = NULL;
pq->size = 0;
}
这里的参数呢是
Queue* pq,解释一下:
因为我们的队列定义成了一个结构体,那销毁或者插入删除等这些操作,改变的其实就是队列对应的结构体,所以我们传结构体的地址就行了,那接收就用一个结构体指针Queue*。
2.2.4 队尾入数据
队尾入数据其实就是对尾插嘛。
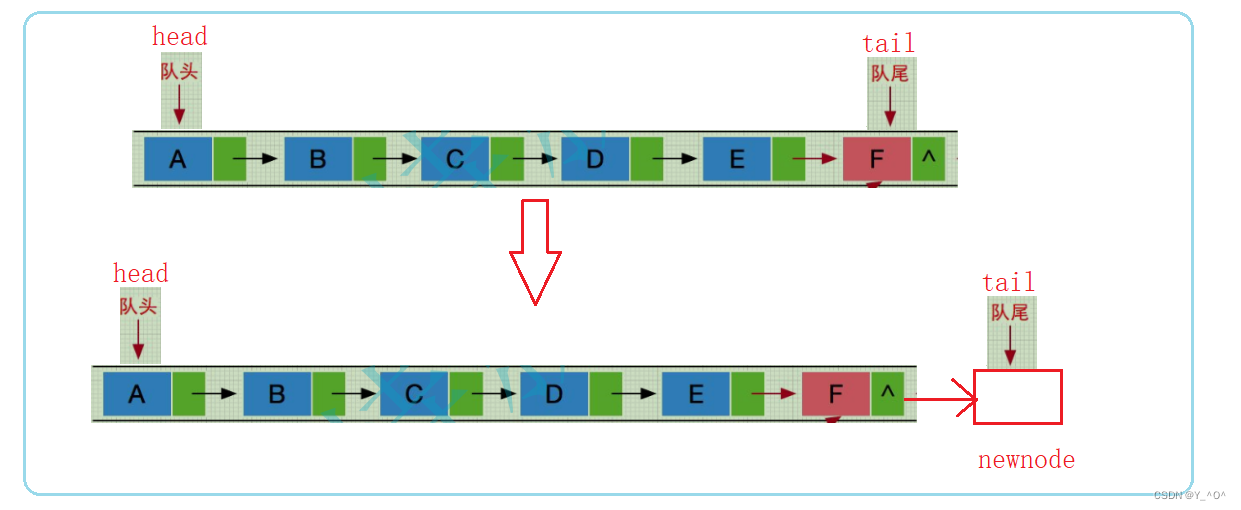
那我们就创建一个新结点,链接在原来的队尾后面就行了嘛。
但是呢?
要注意我们用的是不带哨兵位的单链表实现队列,所以空队列尾插的时候是需要单独处理的。
直接把newnode赋值给头尾指针就行了。
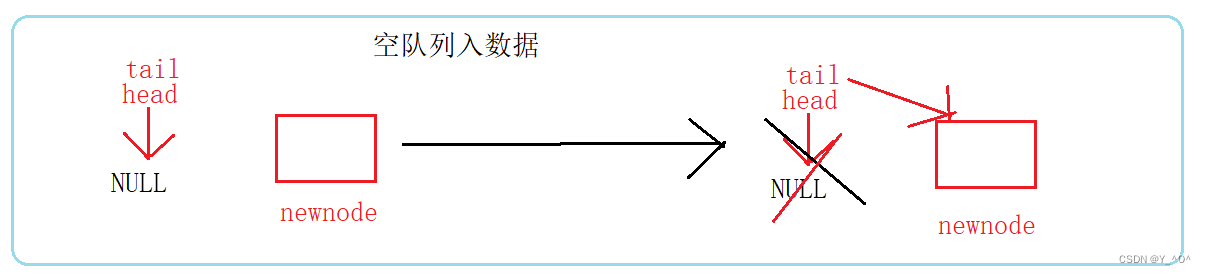
//队尾入数据
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
if (pq->head == NULL)
{
pq->head = pq->tail = newnode;
}
else
{
pq->tail->next = newnode;
pq->tail = newnode;
}
pq->size++;//入数据size++;
}
2.2.5 队头出数据
队头出数据就是头删嘛。
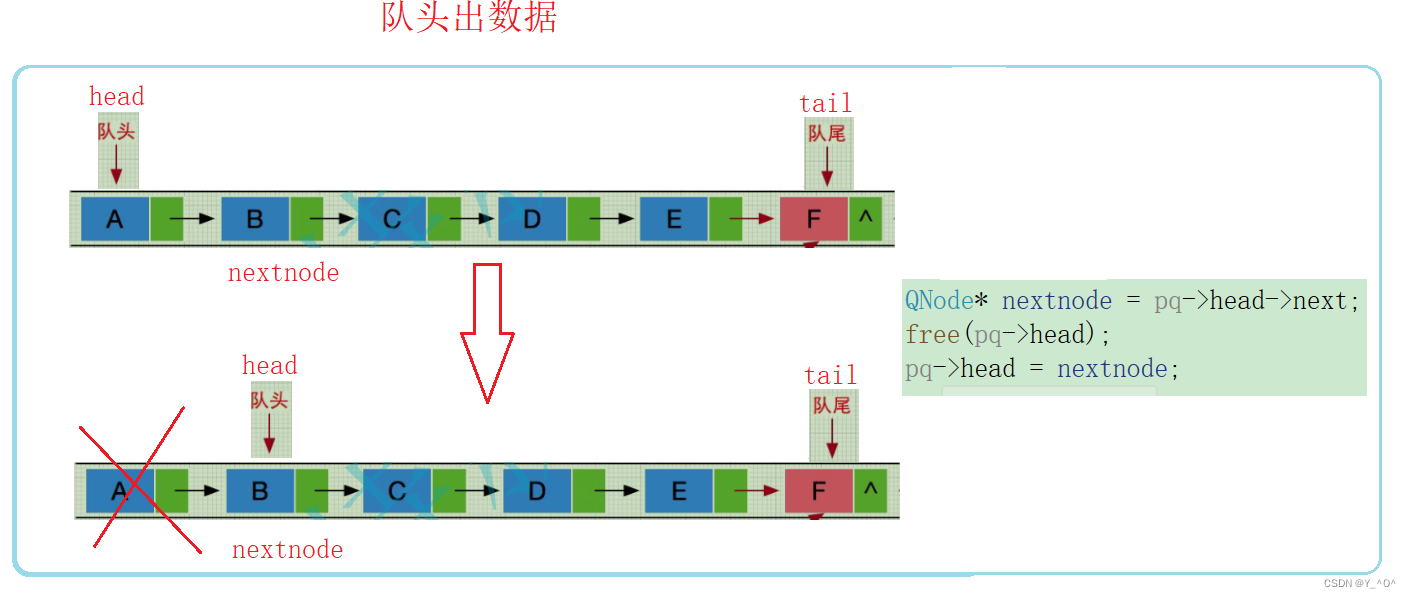
但是需要注意的是:
由于我们这里加了一个尾指针,导致队列中只有一个数据时再去删除需要单独判断。
为什么呢?来看图:
当对列中只有一个元素时,大家按照上面的代码逻辑再走一遍,会发现,删除完最后一个元素之后,head头指针时指向空了,但是尾指针tail还指向最后一个元素的地址,但是最后一个元素已经销毁了,此时它就是一个野指针了。
而且空队列tail和head应该同时指向空,但此时并不是。
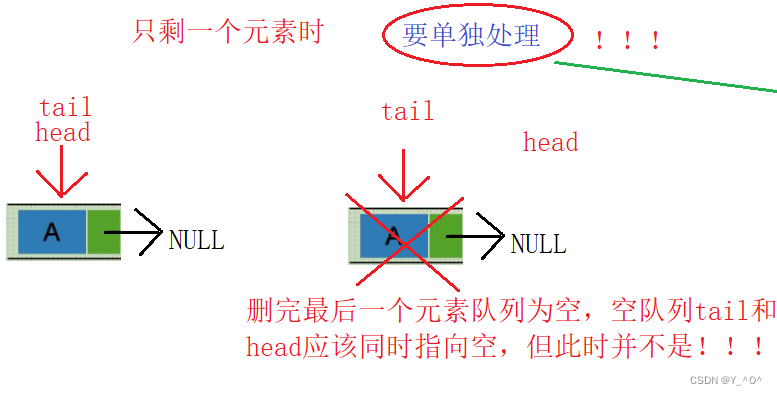
所以呢,这里需要单独处理一下:
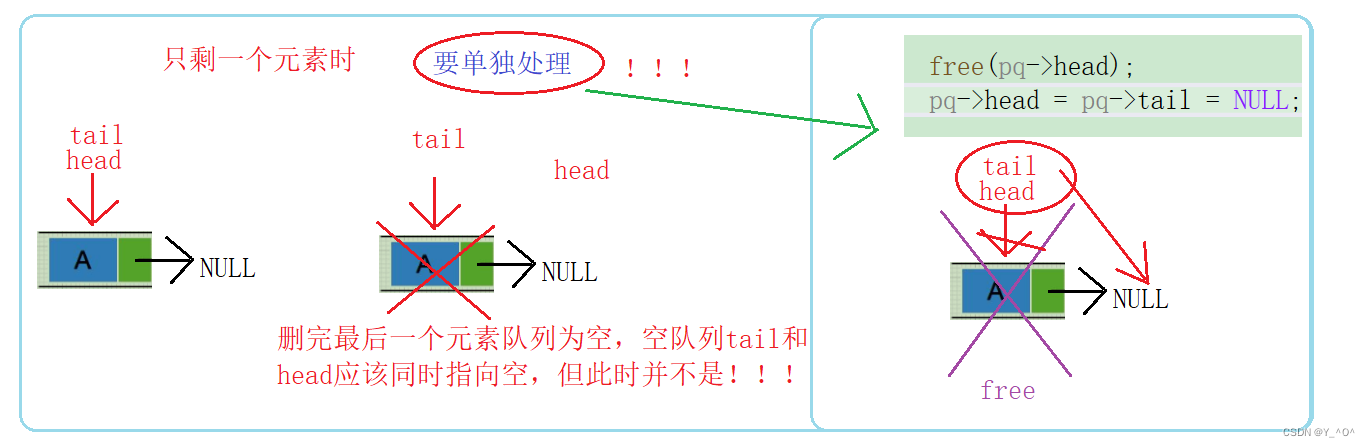
所以,最终的代码时这样的:
//队头出数据
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
if (pq->head->next == NULL)
{
free(pq->head);
pq->head = pq->tail = NULL;
}
else
{
QNode* nextnode = pq->head->next;
free(pq->head);
pq->head = nextnode;
}
pq->size--;
}
2.2.6 取队头元素
取队头元素很简单,就是头指针的data嘛。
//取队头元素
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->head->data;
}
2.2.7 取队尾元素
取队尾元素也很简单:
如果没有尾指针的话,单链表找尾还需要从头遍历,但是我们现在有尾指针啊,那就非常easy了。
//取队尾元素
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->tail->data;
}
2.2.8 队列判空
什么时候队列为空?
是不是size等于0啊,当然当头尾指针都指向空的时候队列也为空。两种方法都可以判断。
//队列判空
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
//return pq->head == NULL && pq->tail == NULL;
}
2.2.9求队列有效元素个数
我们加了成员变量size,现在获取有效数据个数是不是soeasy啊。
//求队列有效元素个数
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}
2.3 测试
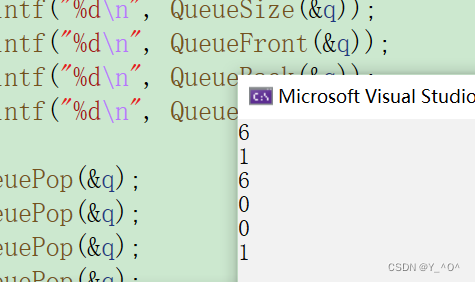
现在对我们实现的队列进行一个测试:
void QueueTest()
{
Queue q;
QueueInit(&q);
QueuePush(&q, 1);
QueuePush(&q, 2);
QueuePush(&q, 3);
QueuePush(&q, 4);
QueuePush(&q, 5);
QueuePush(&q, 6);
printf("%d\n", QueueSize(&q));
printf("%d\n", QueueFront(&q));
printf("%d\n", QueueBack(&q));
printf("%d\n", QueueEmpty(&q));
QueuePop(&q);
QueuePop(&q);
QueuePop(&q);
QueuePop(&q);
QueuePop(&q);
QueuePop(&q);
printf("%d\n", QueueSize(&q));
/*printf("%d\n", QueueFront(&q));
printf("%d\n", QueueBack(&q));*/
printf("%d\n", QueueEmpty(&q));
QueueDestory(&q);
}
2.4 源码展示
源码分享给大家:
2.4.1 Queue.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
typedef int QDataType;
//结点结构
typedef struct QueueNode
{
QDataType data;
struct QueueNode* next;
}QNode;
//队列结构
typedef struct Queue
{
QNode* head;
QNode* tail;
int size;
}Queue;
//初始化队列
void QueueInit(Queue* pq);
//销毁队列
void QueueDestory(Queue* pq);
//队尾入数据
void QueuePush(Queue* pq, QDataType x);
//队头出数据
void QueuePop(Queue* pq);
//取队头元素
QDataType QueueFront(Queue* pq);
//取队尾元素
QDataType QueueBack(Queue* pq);
//队列判空
bool QueueEmpty(Queue* pq);
//求队列有效元素个数
int QueueSize(Queue* pq);
2.4.2 Queu.c
#define _CRT_SECURE_NO_WARNINGS
#include "Queue.h"
//初始化队列
void QueueInit(Queue* pq)
{
assert(pq);
pq->head = NULL;
pq->tail = NULL;
pq->size = 0;
}
//销毁队列
void QueueDestory(Queue* pq)
{
assert(pq);
QNode* cur = pq->head;
while (cur)
{
QNode* nextnode = cur->next;
free(cur);
cur = nextnode;
}
pq->head = pq->tail = NULL;
pq->size = 0;
}
//队尾入数据
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
if (pq->head == NULL)
{
pq->head = pq->tail = newnode;
}
else
{
pq->tail->next = newnode;
pq->tail = newnode;
}
pq->size++;
}
//队头出数据
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
if (pq->head->next == NULL)
{
free(pq->head);
pq->head = pq->tail = NULL;
}
else
{
QNode* nextnode = pq->head->next;
free(pq->head);
pq->head = nextnode;
}
pq->size--;
}
//取队头元素
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->head->data;
}
//取队尾元素
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->tail->data;
}
//队列判空
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
//return pq->head == NULL && pq->tail == NULL;
}
//求队列有效元素个数
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}
2.4.3 Test.c
#include "Queue.h"
void QueueTest()
{
Queue q;
QueueInit(&q);
QueuePush(&q, 1);
QueuePush(&q, 2);
QueuePush(&q, 3);
QueuePush(&q, 4);
QueuePush(&q, 5);
QueuePush(&q, 6);
printf("%d\n", QueueSize(&q));
printf("%d\n", QueueFront(&q));
printf("%d\n", QueueBack(&q));
printf("%d\n", QueueEmpty(&q));
QueuePop(&q);
QueuePop(&q);
QueuePop(&q);
QueuePop(&q);
QueuePop(&q);
QueuePop(&q);
printf("%d\n", QueueSize(&q));
/*printf("%d\n", QueueFront(&q));
printf("%d\n", QueueBack(&q));*/
printf("%d\n", QueueEmpty(&q));
QueueDestory(&q);
}
int main()
{
QueueTest();
return 0;
}
好的,到这里栈和队列的内容就讲解完了,希望能帮助到大家!!!
如果有写的不好的地方,也欢迎大家指正!!!



![二、CSS下拉菜单[颜色布局、子影响父]](https://img-blog.csdnimg.cn/db76ea01636d48c38c74da13622151ee.png)






![[思考进阶]01 如何克服自己的无知?](https://img-blog.csdnimg.cn/5ab95132ca624d70bd18db8c82e1e6c0.png#pic_center)