文章目录
- 前言
- 基本介绍
- OID
- pg_class
- pg_type
- pg_attribute
- 系统表关系
- 初始化
- 编译阶段
- Initdb 阶段
- 系统表的访问
- SysCache
- 初始化 & 基本结构
- 查找 & 插入 & 扩容
- RelCache
- 初始化
- pg_filenode.map
- pg_internal.init
- 初始化完整步骤
- dynahash 可扩展hash表
- extendible hash
- extendible hash 在 PG中的实现
- Cache 同步机制
前言
近期的工作重心会围绕 系统表相关的技术栈来展开,有较多的特性需要完成,希望将这里的技术栈做一个梳理。
系统表是整个 PostgreSQL 数据库存储体系中最重要的一部分数据,它们用来组织管理PostgreSQL 的数据空间,将用户自己定义的数据集合更好得以一个或者多个表组织起来。它们本质也是一个个表对象,相比于普通表是存储的元数据。
这里的元数据可以理解为描述数据的数据。比如,用户创建的表有 (c1 int, c2 text)两种列类型,这一些类型 int, text 会被单独存放在 pg_type的系统表中,同时 c1, c2 列名字则会被存放在 pg_attribute的系统表中,并和 pg_type 形成关联。这一些 pg_type, pg_attribute 类型的表可以建立对用户表的关系描述,所以它们可以被称为元数据。
本文是基于 PG 15 release 版本介绍的
基本介绍
OID
Oid 在 PostgreSQL 中被用来描述一个个数据表的逻辑对象,比如 Relation, type, attr, namespace等等,每创建一个对象都会为其分配一个属于自己的标识(Oid)。PG 也会通过 Oid 来在不同的数据表之间建立关联,也就是说有一些 对象是全局唯一的(pg_class 表的oid)。但是因为 Oid 是 unsigned int,所以当对象的数量超过42亿之后可能会有回卷,所以PG 对Oid的划分有一些自己的定义,比如预留16383 个Oid 作为全局唯一的对象标识,其他的都是给用户表使用,允许发生回卷。
postgres=# select oid,relname,relnamespace from pg_class where relname='pg_class';
oid | relname | relnamespace
------+----------+--------------
1259 | pg_class | 11
-- 三个 预定义好的Oid 类型
#define FirstGenbkiObjectId 10000
#define FirstUnpinnedObjectId 12000
#define FirstNormalObjectId 16384
接下来看看 PostgreSQL 内部非常重要的一些系统表,以及它们之间的关系模型,从而更好的帮助我们理解创建的一个用户表是如何被组织管理的。
pg_class
pg_class 系统表用来管理一个表的对象属性,就是存储在当前数据库的所有表在此时的固有属性信息都会被统一放在pg_class 系统表中,直接看其列属性的定义 pg_class.h:
因为过多,简单挑几个关键信息如下
// pg_class 的唯一标识
CATALOG(pg_class,1259,RelationRelationId)..
Oid oid; // 当前表对象在 pg_class 的唯一标识,pg_class会以oid 为主键建索引,方便查找
NameData relname; // relation 名字
Oid relnamespace; // 所处的 pg_namespace oid,用来和 pg_namespace系统表建立关联
Oid reltype; // 对象类型,用于和pg_type系统表建立关联
...
Oid relam; // am 类型,比如是heap or 其他的,也是和 pg_amthod 建立管理
...
Oid relfilenode; // 当前对象的物理文件名,pg 内部文件名都是以数字存在。
...
char relpersistence; // 该对象的存储类型, 'p' 表示永久,即基本持久化类型;
//'u' 表示 unlogged,不写wal.
// 't' 表示临时表,session 级别的生命周期
char relkind; // 该对象的类型,'r'=普通表,'i'=索引,'v'=视图, 't'=toast 大value, 'c'=符合类型 等
int16 relnatts; // 该对象的属性列的个数
...
可以看到通过
create type map as (string varchar, int_1 int);
create table map_test (id int, value map);
创建的表在 pg_class 中存储的属性信息 有两个,一个是 类型 map 的属性信息, 一个是表 map_test的属性信息。
-- 复合类型 map 的属性信息
postgres=# select oid,relname,relnamespace,reltype,relam,relfilenode,relpersistence,relkind,relnatts from pg_class where relname='map';
oid | relname | relnamespace | reltype | relam | relfilenode | relpersistence | relkind | relnatts
-------+---------+--------------+---------+-------+-------------+----------------+---------+----------
27737 | map | 2200 | 27739 | 0 | 0 | p | c | 2
-- 表map_test的属性信息
postgres=# select oid,relname,relnamespace,reltype,relam,relfilenode,relpersistence,relkind,relnatts from pg_class where relname='map_test';
oid | relname | relnamespace | reltype | relam | relfilenode | relpersistence | relkind | relnatts
-------+----------+--------------+---------+-------+-------------+----------------+---------+----------
27740 | map_test | 2200 | 27742 | 2 | 27740 | p | r | 2
当然,pg_class 本身也是一个对象,所以在 pg_class 中也会存储自己的对象属性信息。
postgres=# select oid,relname,relnamespace,reltype,relam,relfilenode,relpersistence,relkind,relnatts from pg_class where relname='pg_class';
oid | relname | relnamespace | reltype | relam | relfilenode | relpersistence | relkind | relnatts
------+----------+--------------+---------+-------+-------------+----------------+---------+----------
1259 | pg_class | 11 | 83 | 2 | 0 | p | r | 33
pg_type
该系统表用于记录管理所有的类型定义,比如上面的 create table map_test (id int, value map); 建表过程中用到的类型 int 以及 复合类型 map 都会被存储到 pg_type中,而列名字 id 以及 value 则会被存储到的 pg_attribute 系统表中,这个后面会说。
PG 通过 pg_class 的对象属性描述的系统表 以及 pg_type 和 pg_attribute 两种对列属性描述的系统表 共同构造一个基本表的列信息。
接下来看看pg_type 的定义 pg_type.h,挑选几个简略定义如下:
// pg_type的 固有对象 标识是1247
CATALOG(pg_type,1247,TypeRelationId)
Oid oid; // 类型oid
NameData typname; // 类型名字
...
int16 typlen; // 该类型的长度,对于变长类型则一直是-1,如果是-2则是以null 终止的c字符串。
...
char typtype; // 该类型的基础类型。 'b'=基本类型,'c'=复合类型, 'd'=域类型, 'e'=枚举类型等
比如对于我们前面通过 create type map as (string varchar, int_1 int); 创建的类型,可以从 pg_type中看到其信息如下:
postgres=# select oid,typname,typlen,typtype from pg_type where typname='map';
oid | typname | typlen | typtype
-------+---------+--------+---------
27739 | map | -1 | c
因为 map 是我们自己创建的类型,其在 PG 内部的Oid 会从 16384 之后开始生成,标识其属于用户对象。
对于普通的 int类型,其在数据库初始化的时候 以及在 pg_type 中预先创建好了,且 Oid也是提前分配好的,保证全局唯一:
postgres=# select oid,typname,typlen,typtype from pg_type where typname='int4';
oid | typname | typlen | typtype
-----+---------+--------+---------
23 | int4 | 4 | b
pg_attribute
这个系统表描述的是一个表(对象)的每一个列属性的定义。在 pg_class中我们看到的是这个表对象的列的个数,但是具体每一个列 都是什么类型,名字是什么,长度是多少,是第几列等这样的列的描述信息则是会存储在 pg_attribute 系统表中。
其基本类型定义如下pg_attribute.h:
CATALOG(pg_attribute,1249
Oid attrelid; // 该列属于哪一个关系对象,关系对象的oid (一个数据库只能有一个关系对象的名字)
NameData attname; // 该列的名称
Oid atttypid; // 该列的类型, 指向 pg_type的一条类型
...
int16 attlen; // 该列的长度,同 pg_type中的 typlen,加速读取attr信息。
int16 attnum; // 该列的index,是 attrelid 的第几列。
...
比如我们查看 前面创建的 test_map 表的列描述信息如下:
postgres=# select oid from pg_class where relname='map_test';
oid
-------
27740
postgres=# select attrelid,attname,atttypid,attlen,attnum from pg_attribute where attrelid=27740;
attrelid | attname | atttypid | attlen | attnum
----------+----------+----------+--------+--------
27740 | tableoid | 26 | 4 | -6
27740 | cmax | 29 | 4 | -5
27740 | xmax | 28 | 4 | -4
27740 | cmin | 29 | 4 | -3
27740 | xmin | 28 | 4 | -2
27740 | ctid | 27 | 6 | -1
27740 | id | 23 | 4 | 1
27740 | value | 27739 | -1 | 2
可以看到 pg_attribute 还为 map_test 默认分配了一些默认不可见的属性列,用作 extension 时查看更细粒度的tuple信息。
用户自己创建的两列 id 和 value 则是有自己的typeid信息,可以从 pg_type 中看到其定义。
系统表关系
接下来还是通过上面两个简单语句:
create type map as (string varchar, int_1 int);
create table map_test (id int, value map);
看看最后创建的 map_test表信息 是如何由不同的系统表中的数据共同描述的。
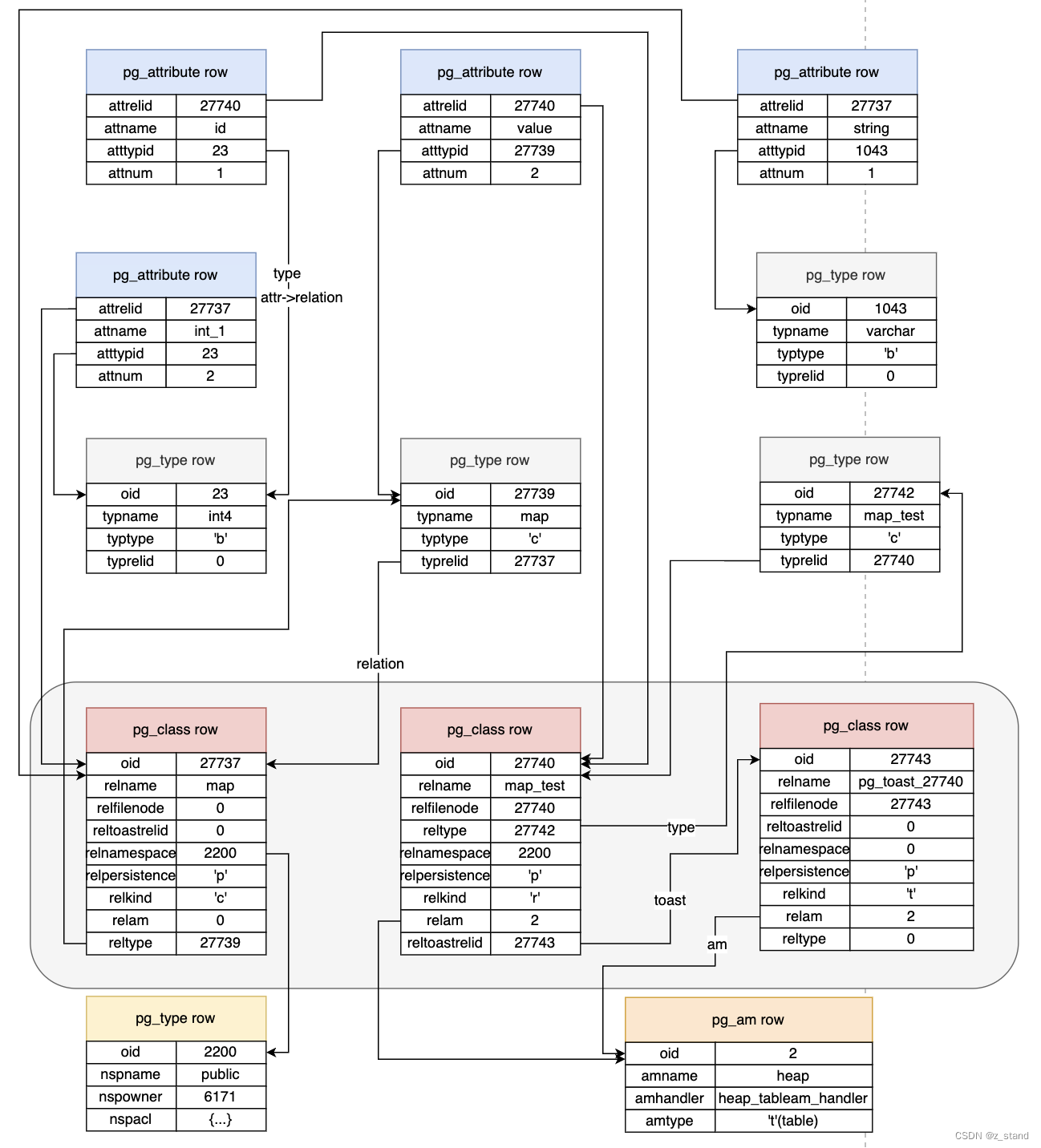
如上图,描述了整个创建过程中涉及到的 系统表信息(并不全面),主要的几个系统表如上。
当我们执行第一条语句 create type map as (string varchar, int_1 int); 按照上图给出的系统表,发生的事情如下:
- 在pg_attribute 增加map的两个列属性,一个是 string,一个是int_1,并标识各自的 pg_type relid;创建好的 string和int_1 行各自的
attrelid都会保存下来,用于指向pg_class 中的 map 对象对应的 oid。 - 在 pg_type 中创建 map类型,因为其是由两个基本类型
int4和varchar组合而成,所以其类型是组合类型。其typerelid也是指向 pg_class 中 map 对象的 oid。 - 在pg_class中创建一行信息, 记录其指向的 pg_type 中的行oid 以及所属的 namespace信息。因为 map对象是 type类型,并不是relation,所以其内部不需要存储数据,也就不需要
relam的智齿了。
当我们执行第二条语句 create table map_test (id int, value map); 就是继续在 pg_type 以及 pg_attribute 系统表中添加对应的行。
- 因为复合类型 map已经存在,则 map_test 表中的行只需要增加对应的 pg_attribute信息了,不需要额外创建pg_type行。增加的
id和value行只需要让atttypid指定 pg_type中的类型即可,id 是基本类型,value 则是已经创建好的复合类型 map。 - pg_class 中增加属于
map_test的行。因为其拥有符合类型的列,且是是一个普通表;所以拥有 toast 以及 am。
可以看到创建表的过程中需要有较多的系统表的读写,上图仅仅展示了写入的系统表 以及很小部分需要读区的系统表,实际执行 SQL 语句的过程中会有更多的对系统表的访问。
接下来我们看看 系统表的初始化以及访问链路。
初始化
用户在一个新的PG集群上 未做任何建表操作之前 系统表就已经存在,元数据本身是需要在为用户提供服务之前就要存在。
PG 对于启动数据库时需要生成的系统表都会在定义时加入 BKI_BOOTSTRAP 标记,比如 pg_class,pg_type (pg_attribute 并不需要启动时就完成初始化)等。
具体可以查看哪一些系统表的定义拥有
BKI_BOOTSTRAP标记,或者去 src/backend/catalog/Makefile 中查看POSTGRES_BKI_DATA,哪一些系统表被添加到了这个变量中。
系统表的初始化基本流程如下:
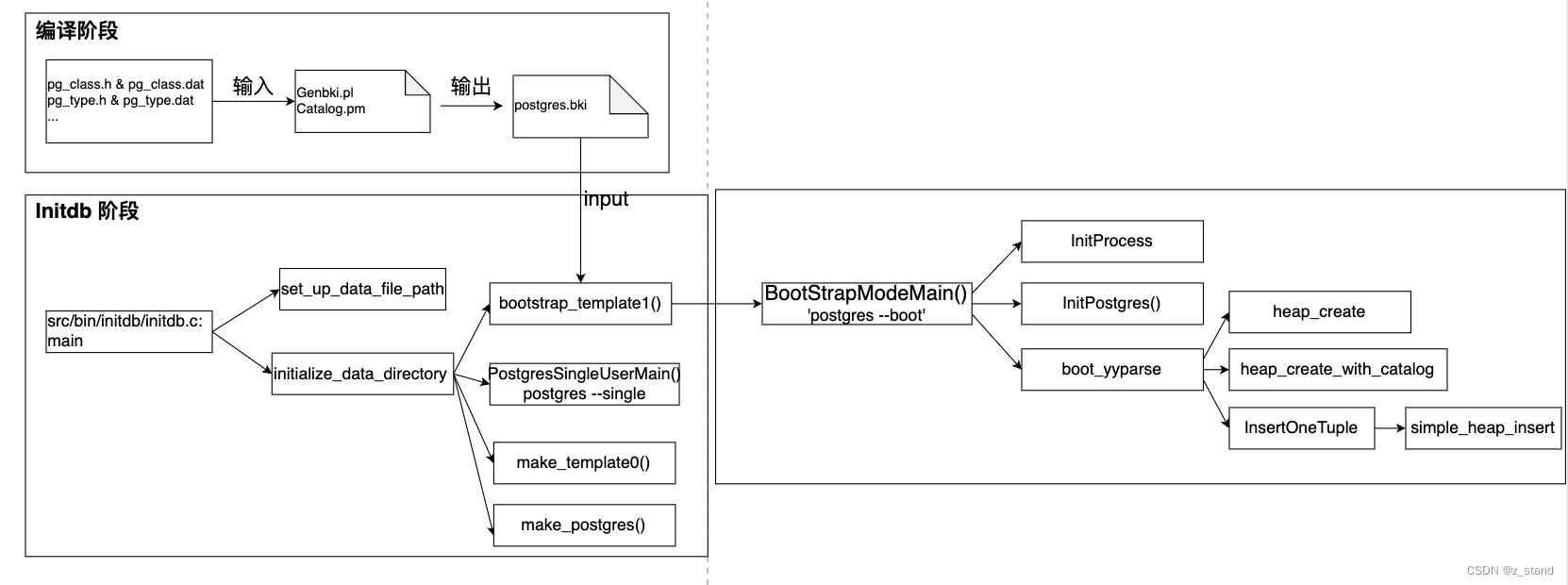
主要分为 编译阶段 和 Initdb 阶段。
- 编译阶段 主要为了生成
postgres.bki文件 (关注系统表部分)。 - Initdb阶段 主要为了解析 bki文件并生成
template1,template0以及postgres数据库。
编译阶段
本文主要关注的是catalog信息,编译过程中还有一些其他文件的生成。
编译阶段 主要是通过 genbki.pl 以及 catalog.pm 生成一个postgres.bki文件(backend interface)放到 PGHOME/share/postgres.bki ,用于后续 initdb时 根据 这个bki 文件生成表对象。genbki.pl 的输入就是 系统表的 .h 以及 .dat文件。
对于 bootstrap 过程中生成的系统表,源代码的定义中能够看到 BKI_BOOTSTRAP 字段。
CATALOG(pg_class,1259,RelationRelationId) BKI_BOOTSTRAP BKI_ROWTYPE_OID(83,RelationRelation_Rowtype_Id) BKI_SCHEMA_MACRO
{
/* oid */
Oid oid;
/* class name */
NameData relname;
...
}
这一些定义也包含了为 pg_class 这个系统表预分配好的oid信息,而 BKI_ROWTYPE_OID 则会被解析,写入到bki 文件中,生成一条唯一的插入语句。
需要注意的是 postgres.bki 文件中的SQL 语句不是标准的sql语法,只是postgres 为了加速initdb的性能设计的伪 sql,能够被 postgres --boot bootstrap 模式启动的 postgres进程解析。
# PostgreSQL 15
create pg_proc 1255 bootstrap rowtype_oid 81
(
oid = oid ,
proname = name ,
pronamespace = oid ,
proowner = oid ,
...
)
insert ( 1242 boolin 11 10 12 1 0 0 0 f f f t f i s 1 0 16 2275 _null_ _null_ _null_ _null_ _null_ boolin _null_ _null_ _null_ _null_ )
insert ( 1243 boolout 11 10 12 1 0 0 0 f f f t f i s 1 0 2275 16 _null_ _null_ _null_ _null_ _null_ boolout _null_ _null_ _null_ _null_ )
insert ( 1244 byteain 11 10 12 1 0 0 0 f f f t f i s 1 0 17 2275 _null_ _null_ _null_ _null_ _null_ byteain _null_ _null_ _null_ _null_ )
...
其中bki的语法如下:
- create : 创建一个系统表
- open: 为插入操作打开一个系统表
- insert: 插入tuple到系统表,tuple 数据的来源是
pg_class.dat类似这样的数据文件 - close: 关闭系统表
Initdb 阶段
Initdb 的过程主要是执行 initdb binary,解析 编译阶段生成的 postgres.bki文件,初始化 template1, template0 以及 postgres 这三个数据库。
需要注意的是实际执行时对这三个数据库的初始化还有
$PGHOME/share目录下的一些其他文件:PostgreSQL.description PostgreSQL.shdescription system_views.sql snowball_create.sql PostgreSQL.conf.sample的参与。
整个过程的实现需要注意的地方如下:
bootstrap_template1中会以--boot模式启动数据库,只有这个模式下能够利用boot_yyparse解析postgres.bki中的特殊sql语法;这里和PG 标准的SQL解析器yyparser不同。而且boot_yyparse不会走执行器的逻辑。postgres.bki文件中初始化的系统表信息存储方式和普通的系统表一样,会存储在heap表中。- 初始化
template0以及postgres数据库时会 用已经 在 bootstrap 模式下完成初始化的template1进行初始化。不过并不会继续用bootstrap模式,而是切换为--single即 single user模式,因为需要执行标准SQL语法。
初始化过程的一些细粒度代码可以看 initdb.c 的main函数就好。
到目前为止,我们看到了整个系统表的基本使用 以及 初始化过程。接下来看看对于系统表的访问过程PG 是一个什么样实现。
系统表的访问
介绍之前,我们先按照前面介绍的系统表关系模型中思考一下系统表的访问过程中可能会产生哪一些问题 或者 需求?
- 从前面介绍系统表的初始化过程中可以看到系统表数据以 heap 表的形态被持久化到磁盘中的不同relfilenode 文件中。用户想要创建一个自己的表,是需要访问多个不同的系统表,如果没有缓存,每次需要读磁盘,且读多次,这个性能显然是接受不到了的。所以就需要有系统表的缓存机制来加速对其访问。
- 缓存设计为什么样的形态能保证性能收益最大化呢?首先PG 是进程模型,就是每一个用户连接到 Postmaster,都会为这个client 连接 fork一个 backend子进程用作服务交互。PG 之所以是多进程还是因为历史原因(1996年PostgreSQL 6.0发布时 linux kernel还不支持 multi-thread),当然良好多进程架构的设计和多线程架构设计的性能是没有差异的。对于缓存的设计,因为系统表的数据量并不大,且DDL 操作并不是高频操作,对于系统表的访问 应该尽可能得让数据靠近CPU,即最大程度得利用好CPU-cache。 所以 PG采用的缓存设计形态可以理解为 per-process-cache,类似thread-cache。每一个backend 进程都维护一个自己进程级别的 cache,每一个backend进程在有访问系统表的需求时可以尽可能得利用好cpu-cache。
- 因为是 per-process-cache, cache需要在 某一个backend 对系统表发生更改时其他的 backend 进程能够感知到。所以需要有一套维护cache 一致性的机制,也就是 PG 的 InvalidMessage机制。
- 有了per-process-cache 能够保障对系统表数据的访问性能,但是多个backend对同一个系统表的同一行的更新则需要有安全性的保障,这个时候就需要有 锁 + MVCC 机制来做保障。
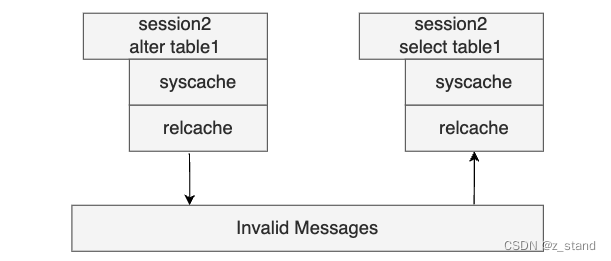
综上,系统表访问的核心 就是 cache + 锁|MVCC。一个保障访问高效,一个保障访问安全。
接下来,我们从这两方便来深入分析 PG cache的实现原理。
PG 的 cache 体系 主要有三种:
- syscache,缓存系统表数据
- relcache,缓存 一个表关系relation 的完整数据(包括用户表的)
- plancache,缓存planstmt,加速一个query对同一个planstmt 的访问
本文主要介绍的是前两种(因为其与存储 & 事务关联较大,优化器 & 执行器 当前没有太深刻的理解,没有办法有准确的描述:( )。
SysCache
系统表缓存,也叫 CatCache catalog cache,这个 Cache用来缓存系统表的数据。
PG 在初始化 backend进程时 会通过 InitPostgres --> InitCatalogCache 完成对 SysCache 的初始化, 这里 SysCache 是一个 CatCache 结构的数组。
之所以系统表的缓存是维护了一个 固定大小的 CatCache数组,是因为系统表的一些关键属性信息在启动数据库之后是不会变更的,一个系统表可能有多个 CatCache 实例,每一个实例能够通过这个系统表的一个属性唯一索引该系统表的tupe 数据。也就说说,不同的CatCache 的查找键时不同的。
初始化 & 基本结构
InitCatalogCache 初始化的基本过程如下:
- 逐个拿
syscache.h预定义好的SysCacheIdentifier作为 cacheid。enum SysCacheIdentifier { AGGFNOID = 0, AMNAME, AMOID, AMOPOPID, AMOPSTRATEGY ... } - 将预定义好的
cacheinfo数组中的CatCache数据结构填充到SysCache[cacheId]中。
cacheinfo中预定义好了每一个 cacheid 对应的CatCache的属性,比如: cacheid 为AMNAME=1的 cacheinfo 内容如下:
可以在初始化时完成static const struct cachedesc cacheinfo[] = { 。。。 {AccessMethodRelationId, /* AMNAME */ AmNameIndexId, 1, { Anum_pg_am_amname, 0, 0, 0 }, 4 }, ...SysCache[AMNAME]的填充,包括CatCache->cc_reloid,CatCache->cc_indexoid,CatCache->cc_nbuckets等信息。如果想要增加更多的 syscache,首先需要确保该cacheid 能够唯一标识一个系统表的一行(该系统表能够在该属性列上建立唯一索引),同时 cacheinfo 数组相应的偏移位置上需要添加该属性列的声明。
直接看一下整个 SysCache 数组以及 CatCache 内部结构如何组织的:
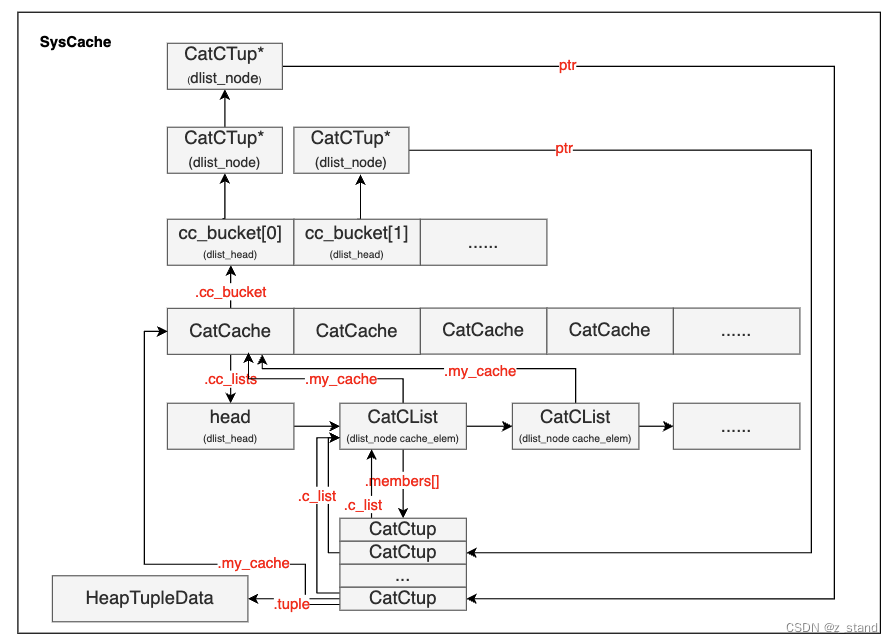
- SysCache数组中每一个元素都是 CatCache结构
- CatCache 内部主要有两个核心元素:
- 一个指针
cc_lists,这个指针是CatList双向链表的 head指针;每一个CatList节点维护了一个CatCTup members数组,这个数组中的CatCTup.tuple字段 就是实际保存的 系统表中某一行的tuple 数据:.tuple可以提取到tuple数据 。每一个CatCTup也保存了管理自己的CatCList节点,通过CatCTup.c_list。每一个CatCList节点也保存了管理自己的 CatCache 结构,通过CatCList->my_cache能够快速访问到。 - 另一个是
cc_bucket数组,每一个cc_bucket元素都是一个CatCTup*双向链表的头指针,实际的CatCTup数据则可以通过该指针访问到。
- 一个指针
这里可能有人会疑惑,好好的 hash table 为什么要多一个 CatCList 数据结构保存实际的
CatCTup数据,不直接将CatCTup数据存储到 cc_bucket 指向的双向链表中,毕竟 cc_bucket保存的也仅仅是指针,直接保存数据的话岂不是访问更方便。这里后续介绍 扩容的时候会细说,简单来说 cc_bucket就是为了实现 hash表的查找 & 插入 & 扩容 这一些基本功能,将实际的元素数据单独放在 CatCTup 指针中,实际扩容的时候不需要搬迁数据,只需要移动 cc_bucket 中的链表头指针到新的 cc_bucket中。
查找 & 插入 & 扩容
SysCache 的查找 PG 提供两种类型的接口:
SearchCatCache支持输入cacheId 以及 最大4个查询键,输出一个 tuple。SearchCatCacheList同样输入 cacheId 以及 查询键,输出一组 tuple。
可以理解为SearchCatCache 是为了点查,要求输入的查询键 和 cacheId 对应的 syscache 支持的查询键匹配,能够精准输出一个tuple。
SearchCatCacheList 则是scan,输入部分查询键,返回以该查询键开头的一组tuples。
对于 SearchCatCache 查找过程如下:
-
输入 cacheId + keys (查询键)
-
通过 cacheId 拿到对应的 CatCache
SysCache[cacheId]; 通过 keys 计算 hashValue 以及 hashIndex 找到对应的cc_bucket[hashIndex]。
这样拿到了一个CatCTup*双向链表的头指针。 -
遍历该 bucket 下所有的 CatCTup 节点,逐个匹配 输入的keys 和 该
CatCtup保存的ct->keys是否相等; -
找到了,将该
CatCTup*移动到双向链表的头部,属于cache-hit。同时判断 该CatCtup->negative字段是否为 true (默认是false。),是 表示上一次从 cache 以及 heap 表中都没有找到这个tuple 应该返回NULL。 -
如果遍历 bucket过程中没有找到匹配的tuple,则需要从 heap表读取 ,通过
SearchCatCacheMiss实现- 打开这个 cacheId 对应的 CatCache 初始化时保存的
cc_reloid对应的系统表 –table_open - 扫描这个系统表的所有数据 –
systable_beginscan - 找到了一个匹配的 tuple,则 通过
CatalogCacheCreateEntry将该tuple插入到当前 cache->cc_bucket[hashIndex] 双向链表的头部;这个过程发现 当前cache的tuple数量已经超过 bucket数量的两倍,通过RehashCatCache函数,将bucket数量扩容为原来的两倍。这个扩容过程需要对所有旧的bucket进行操作,重新计算 hashIndex,将旧的bucket的所有
CatCTup指针添加到新的bucket 头指针下面;不过并不会拷贝真实的 CatCtup 数据。这也回答了前面为什么多了一个保存实际数据的CatCList数据结构的原因。
4.没有找到,则创建一个
dummy CatCTup*节点ct,插入到双向链表,并标记ct->negative为true,并返回 NULL, 因为negative=true,后续的查找就会直接返回 NULL。 - 打开这个 cacheId 对应的 CatCache 初始化时保存的
对于 SearchCatCacheList 的查找过程如下:
输入部分查询键,获取多个tuple,用到了 CatCList 数据结构。
- 输入 cacheId, nkeys,以及查询键。nkeys 表示最后可以拿到的 CatCList节点,因为每一个 CatCList节点添加 members的时候会根据查询键的映射 保存对应的 nkeys个 CatCTups。
- 遍历 cc_lists 双向链表,确认每一个 CatCList 节点的
cl->nkeys个数是否和接口输入的nkeys相等。是则继续计算 查询键 的hash值是否和 CatCList 中每一个 CatCTup 保存的key 的hash值相等,有一个不想等就继续遍历; - 找到了完全匹配的
CatClist节点,将其插入到 cc_list 的头部并返回。 - 找遍了整个 cc_list 双向链表,没有找到;继续从 heap表中查找 ,调用
table_open+systable_beginscan。-
heap表中拿到的匹配查找键的 tupe 需要从 cc_bucket中查找,确认是否已经有一个插入的tuple
(当前syscache的并发更新?),这一步还没有特别理解;如果没有invalid,在 cc_list找不到的话不可能再出现在 cc_bucket中了?这里逻辑有哪位同学看明白了,忙帮解释一下 😃这里是说从cc_bucket 中再次查一下从heap表中读取到的tuple,因为 相同的tuple数据 构造的 CatCTup 可能会有重复的多个被保存到不同的 CatCList中 (同一个系统表有多个syscache,也就会遇到这种情况,不过syscache缓存的系统表数据量有限,额外多消耗一些内存,可以接受)。 CatCTup 中有一个
refcount字段,如果同时被cc_list以及cc_bucket两种数据结构引用,则该值是2,只有当该值是 1 时 从两个数据结构中的一个移除时释放其空间。 -
cc_bucket没有找到,插入到 新的cclist 中,最后遍历完针整个系统表 找到所有的匹配的 tuple之后 统一插入到 cc_list的双向链表中;
-
cc_list 就是纯双向链表,不存在扩容问题,其中每一个节点的 CatCList 的members数组大小是整体扩容或者 移除的, 上面 构造新的满足 SearchCatCacheList 要求(nkeys + 查询键)的 CatCList 时 会重新分配一个指定大小的 members数组。
到此整个 SysCache 的基本操作就描述完了,对于CacheInvalid的介绍 会放在 RelCache 之后。
RelCache
RelationCache 存储表关系 RelationData 的cache,有一些书中也称其为 BufferCache 《PostgreSQL 14 internals》。
SysCache 的定位是缓存数据量有限的系统表表数据,但是因为不同的syscache 缓存的cahcinfo多种多样,有的syscache的查询键可以不需要,只需要一个relid或者indexid;有的syscache查询键有一个,有的有三个。所以 syscache 没有办法用统一的数据结构来管理,只能采用 cc_bucket + cc_list。而 RelationData 是一个固定的表关系数据结构,完全可以采用同一套hash 数据结构来管理。
所以 RelCache 采用的是 dynamic hash表 进行表关系的缓存,这个hash表也是 PG 内部应用最多最广的 hash 数据结构,其性能和稳定性 在PostgreSQL 近三十年的生涯中历经磨练。这个 hash表的实现也是非常值得学习的工业级数据结构 😃
先看一下 RelationData 数据结构基本内容,部分数据结构:
typedef struct RelationData
{
RelFileNode rd_node; /* relation physical identifier 物理文件表示*/
SMgrRelation rd_smgr; /* cached file handle, or NULL,当前表的存储管理器对象 */
int rd_refcnt; /* reference count 引用数 */
BackendId rd_backend; /* owning backend id, if temporary relation temp表的backendId*/
bool rd_islocaltemp; /* rel is a temp rel of this session 这个relation是一个temp表 */
...
Form_pg_class rd_rel; /* 保存在pg_class 表中的 tuple */
...
Form_pg_index rd_index; /* 保存在 pg_index 表中的tuple */
...
整个这个数据结构会作为一条 entry 被保存到 relcache中。
初始化
当我们发起一个连接请求时, Postmaster 会fork一个backend 进程来服务于这个链接请求,提供操作PG数据库的服务。因为 relcache 包括 syscache都是 backend 粒度,所以在PG启动这个backend进程的过程中会进行初始化。对于 relcache的初始化主要是在 InitPostgres 函数中完成的,主要是如下几步:
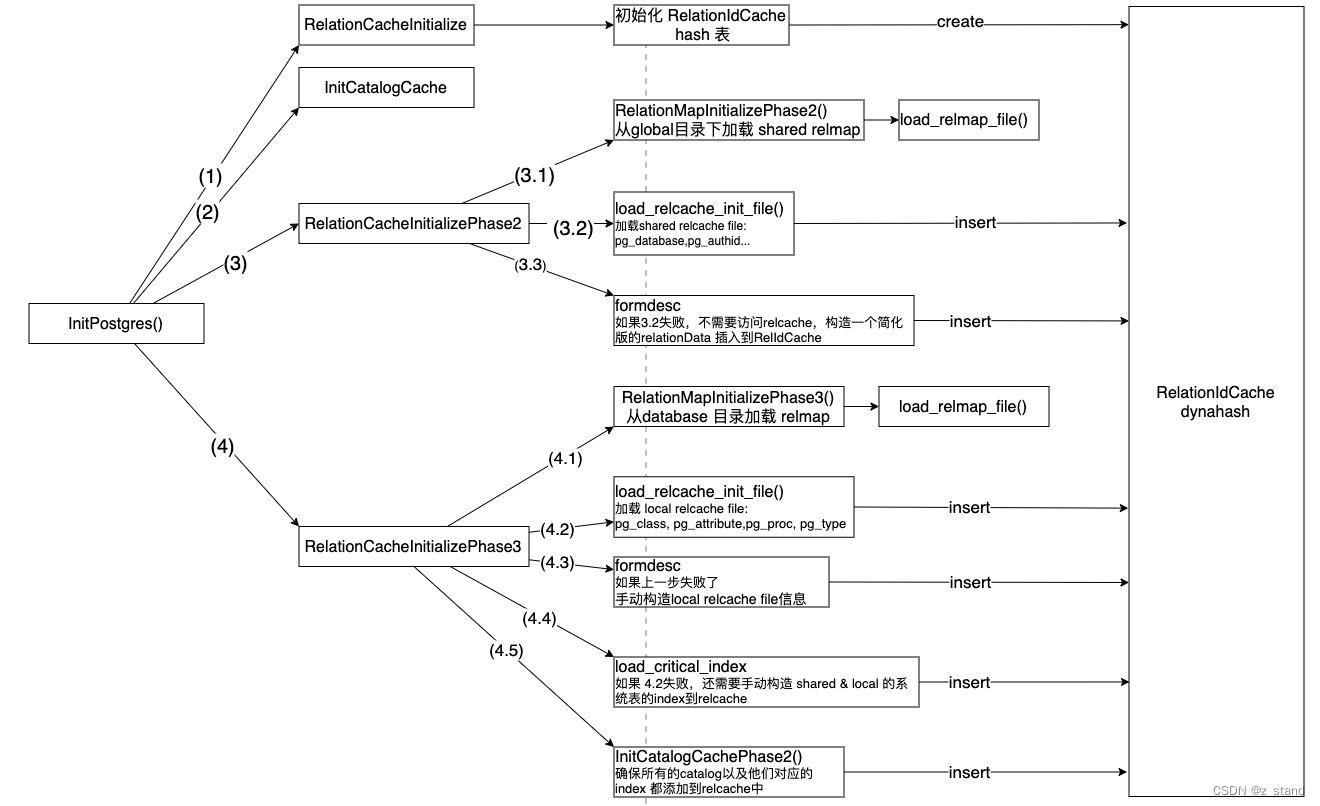
其中会有IO操作,即有读写磁盘的需求,涉及的两个主要的文件分别是 pg_filenode.map 以及 pg_internal.init。
这里需要细致得提一下两个关键文件,这两个文件都只是服务器系统表的relcache 初始化的,与用户表没有关系。
pg_filenode.map
pg_filenode.map 中保存的数据结构是:
typedef struct RelMapFile
{
int32 magic; /* always RELMAPPER_FILEMAGIC */
int32 num_mappings; /* number of valid RelMapping entries */
RelMapping mappings[MAX_MAPPINGS];
pg_crc32c crc; /* CRC of all above */
int32 pad; /* to make the struct size be 512 exactly */
} RelMapFile;
其中核心数据是 RelMapping,在map文件中 最大会有62条这个record,加上 RelMapFile 中其他字段的大小,实际存储时该文件大小会维持在 512bytes,因为生成这个文件也是对该文件中的内容重写,所以512bytes 大小 对文件系统的更新来说非常高效。
typedef struct RelMapping
{
Oid mapoid; /* OID of a catalog */
Oid mapfilenode; /* its filenode number */
} RelMapping;
这一条record 保存的是 一个系统表的 reloid --> relfilenode(实际heap表文件名)的映射,之所以维护这样的信息到磁盘上是因为 对于 pg_class 这样的系统表是无法自管理自己的 relfilenode 到自己的存储中的。毕竟,初始化pg_class的时候需要有一个地方能够找到自己的 relfilenode 文件来加载自己的数据,而且每一个 PG 的 database 都有一套独立的 pg_class 系统表,而 PG 内部也有其他类似 pg_class 这样的系统表,叫做 nailed 系统表。 relation->rd_isnailed 可以标识,像是 pg_database, pg_authid 以及 pg_attribute, pg_proc, pg_type 都是 nailed系统表,所以 需要有 relmapper机制 来保证能够查到这一些系统表的数据文件。
-
load_relmap_file 就是根据初始化阶段完成对
pg_filenode.map的加载,研究过PG 磁盘文件类型的同学会有发现pg_filenode.map在global以及base对应数据库目录下都有存在。其中global目录下保存的是 shared 的 pg_filenode.map 文件,会在 phase2阶段加载。base目录下的 各个数据库中的 map 文件则会在InitPostgres完成 MyDatabaseId 初始化之后到 phase3 阶段进行加载。 -
加载到内存中的 map文件内容会被分别放到
local_map以及shared_map中,在后续的formrdesc以及RelationBuildDesc构建 RelationData内容时 需要访问 nailed 系统表时 被用到。 -
map文件的更新主要有三个地方:一个是 bootstrap时,即初始化整个PG时会在 boot模式下创建map文件,供后续 postmaster 初始化backend进程时来访问;另一个是在 commit/abort transaction时发现有 nailed 系统表的更新,则会进行map文件的重写; 最后一个地方是在recover时,
relmap_redo完成。需要注意的是 map 文件在 PG内部有较高重要性,所以初始化relcache过程中 如果load map文件失败,则会直接FATAL;而对map文件的更新则会写WAL,在recovery时会重写map文件。
pg_internal.init
前面 pg_filenode.map 只是用来能够找到 对应系统表的 refilenode文件,但是启动阶段还没有系统表的索引,想要加载实际的系统表内容则只能通过全表扫描,这个效率是非常低的。如果local 系统表中的数据量非常大(比如普通用户创建了大量的用户表 + 类型,对应的 pg_class, pg_type, pg_attribute 数据量也会非常庞大),这样其他用户建立连接时 初始化backend 会非常慢。为了避免全表扫描,PG 将对应系统表的Relation结构提前构造好,存储到 pg_internal.init 文件中,启动的时候只需要加载一个 这个文件,构建对应的relcache就好了。
同 .map 文件,.init 文件也是分为共享和局部的,即global目录 的 shared 和 base各个数据库目录的 local .init文件。两者的加载在分别在 relcache 初始化的 phase2 和 phase3阶段。
$ fd "pg_internal.init"
base/24650/pg_internal.init
base/5/pg_internal.init
global/pg_internal.init
对 .init文件的重写 会在 phase3阶段,因为这个阶段已经完成所有 syscache 以及 relcache的初始化了。
初始化完整步骤
回到cache 初始化的整体的步骤,主要分为四步:
- RelationCacheInitialize, 这个函数用来完成
RelationIdCache的初始化,包括初始化内存中维护的relmapfile 数据结构。 - InitCatalogCache,这里主要是完成 syscache的初始化,上文已经说过了。
- RelationCacheInitializePhase2 完成relcache 的第二阶段初始化。
- 3.1 从
global目录下加载 shared map文件 - 3.2 从
global目录下加载sharedinit文件,主要包括pg_database以及pg_authid这样的系统表,这一些系统表会用于后续初始化时的 安全验证。 - 3.3 如果 3.2失败了,则会通过
formrdesc生成一个简化版本的 Relation Entry 插入到RelationIdCache中。
这里可能有一些同学会有疑惑,正常我们操作 relation 时 是通过
table_open或者relation_open来完成(PG_15 版本代码,对 table_open有重构,之前应该是 heap_open),为什么初始化的时候不直接用table_open呢?table_open底层的逻辑是先从 relcache中查找这个 Realtion Entry,如果找不到则会通过RelationBuildDesc访问各个系统表重新构建这个 relation结构;但是访问其他系统表时也需要通过 table_open来完成,因为初始化阶段 relcache还没有这一些系统表的数据,而直接用 table_open 这样可能会产生无限递归问题。所以引入 formrdesc 来不加载系统表的情况下构造一个裁剪版本的 relation 也能用。 - 3.1 从
- RelationCacheInitializePhase3 完整整体 syscache + relcache 得初始化。
- 4.1 从
base目录下当前连接建立的数据库目录下加载 localpg_filenode.map文件。 - 4.2 从
base目录下的MyDatabaseId数据库目录中 加载localinit文件,主要包括pg_class,pg_attribute,pg_proc以及pg_type文件。 - 4.3 如果4.2失败,继续通过
formrdesc构造一个裁剪版的 系统表的 relation entry. - 4.4 如果4.2 失败,需要手动构造 shared 以及 local 系统表的 index relation entry。
- 4.5 继续 syscache 的 phase2 初始化,主要是将 syscache中系统表对应的 Relation 再添加到 relcache 中。因为这个时候关键的系统表都已经初始化完了,所以可以通过
table_open完成初始化。
- 4.1 从
到此,对 relcache的初始化就算完成了,但是 relcache 最内核的 RelationIdCache 却还没有介绍,它是一个 dynahash 即 extendible hash 数据结构,也是整个 PG内部应用最广的 hash表。
接下来我们仔细看看这个hash 表的实现,是如何实现高效的可扩展能力的。
dynahash 可扩展hash表
介绍整体 PG 的dynahash 的实现之前我们需要先对 extendible hash 有一个整体的理解。
extendible hash
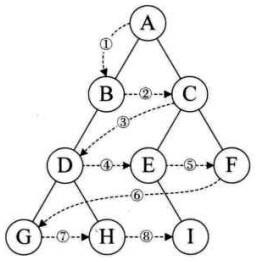
我们的hash表是一个用于 in-memory 场景高效 (平均是 O(1))查找单个元素的一种数据结构,其原本的形态是下图的样子:
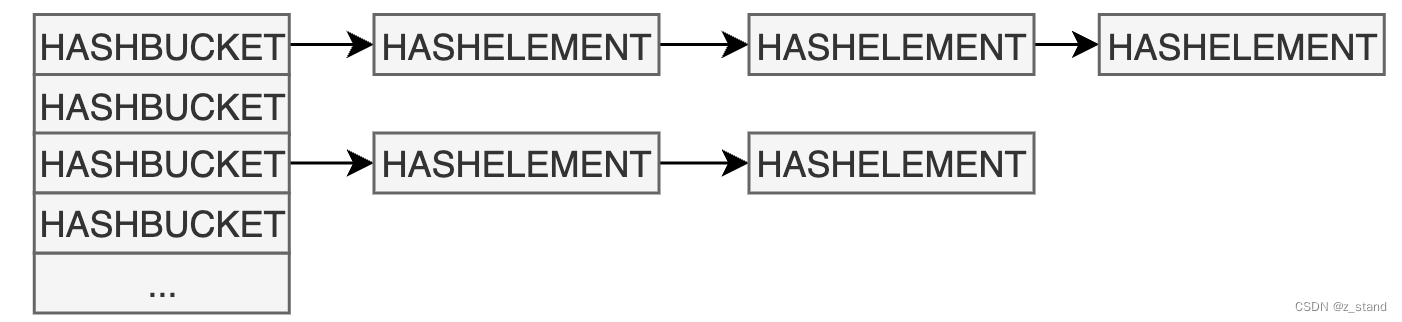
给定一个 key, 通过hash 函数 hash_func(key) 生成一个 hash-value,映射到一个bucket中,因为bucket 数量最开始有限,所以可能多个hash-value 会被映射到一个bucket中,则这个bucket下面可以是多个元素的数组或者链表。要查找的key 在对应的bucket中的链表或者数组中顺序查找 hash-value匹配的 元素。
整个hash 表的构建是与 hash-value 以及 bucket绑定的,哪一个元素处于哪一个bucket,需要 类似 hash-value % bucket-num 或者其他的映射方式来实现。那么问题就来了:内存大小是有限的,hash表总是需要扩容的,当我们变更了 bucket数量之后意味着每一个元素的 hash_value % bucket-num 都发生了变化,也就是 每一个元素都需要重新计算一下映射值,将自己从现在的bucket 搬迁到新的bucket中,这个过程(rehash)是需要整个hash表参与,代价实在是太大了。
extendible hash 就是为了解决 rehash 代价过大的问题,在rehash时尽可能减少对hash元素的移动,且这个过程不引入其他性能上的开销。
实现了引入在 bucket层级之上引入了 directory 概念,类似如下图Extendible hash 描述:
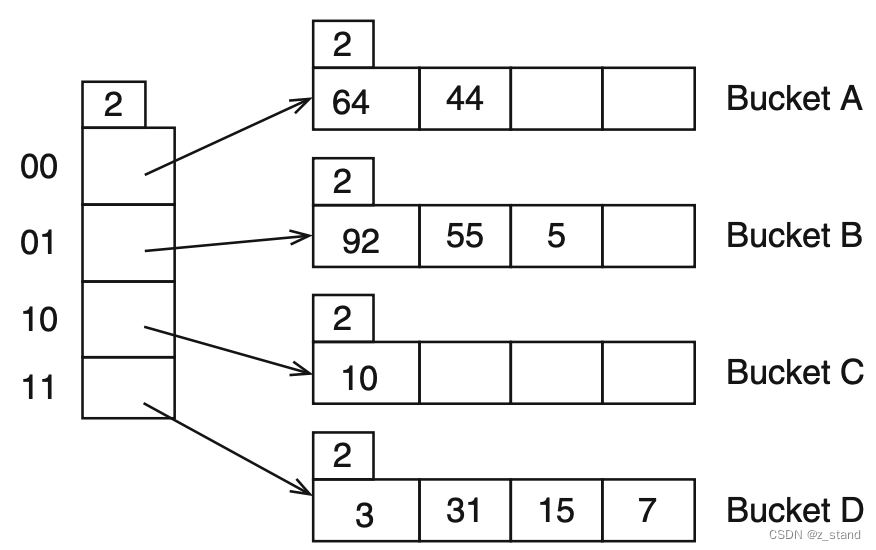
每一个directory 大小是
2
d
2^d
2d, 这里的
d
=
2
d = 2
d=2,directory可以理解为是一个数组,其大小必须是 2的n次方,每一个hash-bucket 中可以填充的元素的个数也必须是
<
=
2
d
<= 2^d
<=2d,同时每一个bucket内部也会维护一个自己的元素个数上限
l
l
l。
- d d d 可以理解为global depth,也就是dir 允许的每一个bucket 中元素数量的上限 2 d 2^d 2d
- l l l 可以理解为 local depth,也就是bucket 本地的元素数量上限(还未扩容) 2 l 2^l 2l
一个 元素
k
k
k 通过
h
(
k
)
h(k)
h(k) 映射到对应的 directory中,每一个dir 指向一个 bucket,多个dir也允许指向同一个bucket。我们想要查找 15,通过 类似如下形态 15 % 4 == 3 找到 15所在的dir 即 二进制为 11 的dir,最后在 Bucket D 中找到。
如果要扩容,比如插入 63 到 hash表中,也需要插入 Bucket D,这里的处理方式是将 dir 容量增加2倍,因为dir 必须是 2 的 n次方,所以对它的每次扩容就是 乘 2。这样它的容量就变成了 8,d 从 2变成了3,但是这次扩容只会为新增的bucket 分配一个dir,多出来的dir还是指向旧的bucket,这个时候会出现多个 dir 指向同一个bucket的情况。
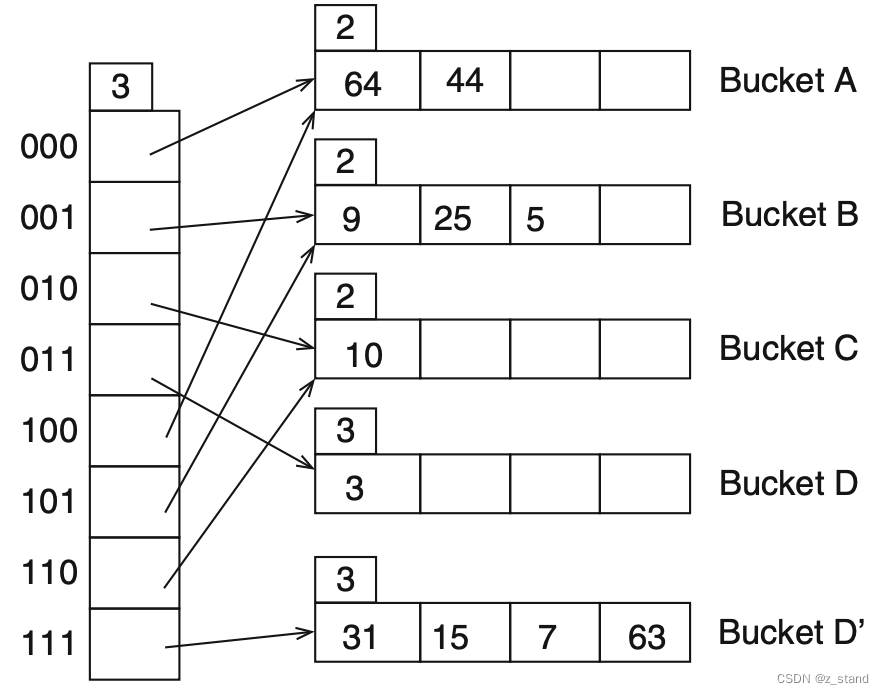
新增的 Bucket D' 只需要将原本 Bucket D中的部分元素移动过来即可 (通过 % 8 知道该移动到哪一个 bucket),其他的bucket 中的元素完全不需要动。对于 bucket D 和 D’ ,它们本地的local depth也都变为了和 global depth 一样的 3,其他的buket 的local depth还是维持在2。这样对于其他的 空闲的dir 就可以通过比较后两位 来确定自己指向的bucket,比如 110 的后两位是 10,那么它们指向原本 10 dir 指向的 bucket C就好了。
两个dir 指向同一个bucket时,后续持续插入到这个bucket,且该bucket达到 2 l 2^l 2l 且 l ! = d l != d l!=d,则只需要创建一个新的bucket,将新元素添加到已经扩容了的新的dir 指向的bucket就好了。
总结一下,extendible hash 的核心优势 就是利用 directory 这个中间指针来在rehash时仅移动一个bucket的数据旧 达成动态扩容的目的,优雅且高效。
extendible hash 在 PG中的实现
PG 中实现 extendible hash 考虑的场景会更多,也更复杂,比如内存管理(内存控制、内存碎片的管理)、接口在复杂场景中的简化。
先看看 PG 中 dynahash 的基本实现结构:
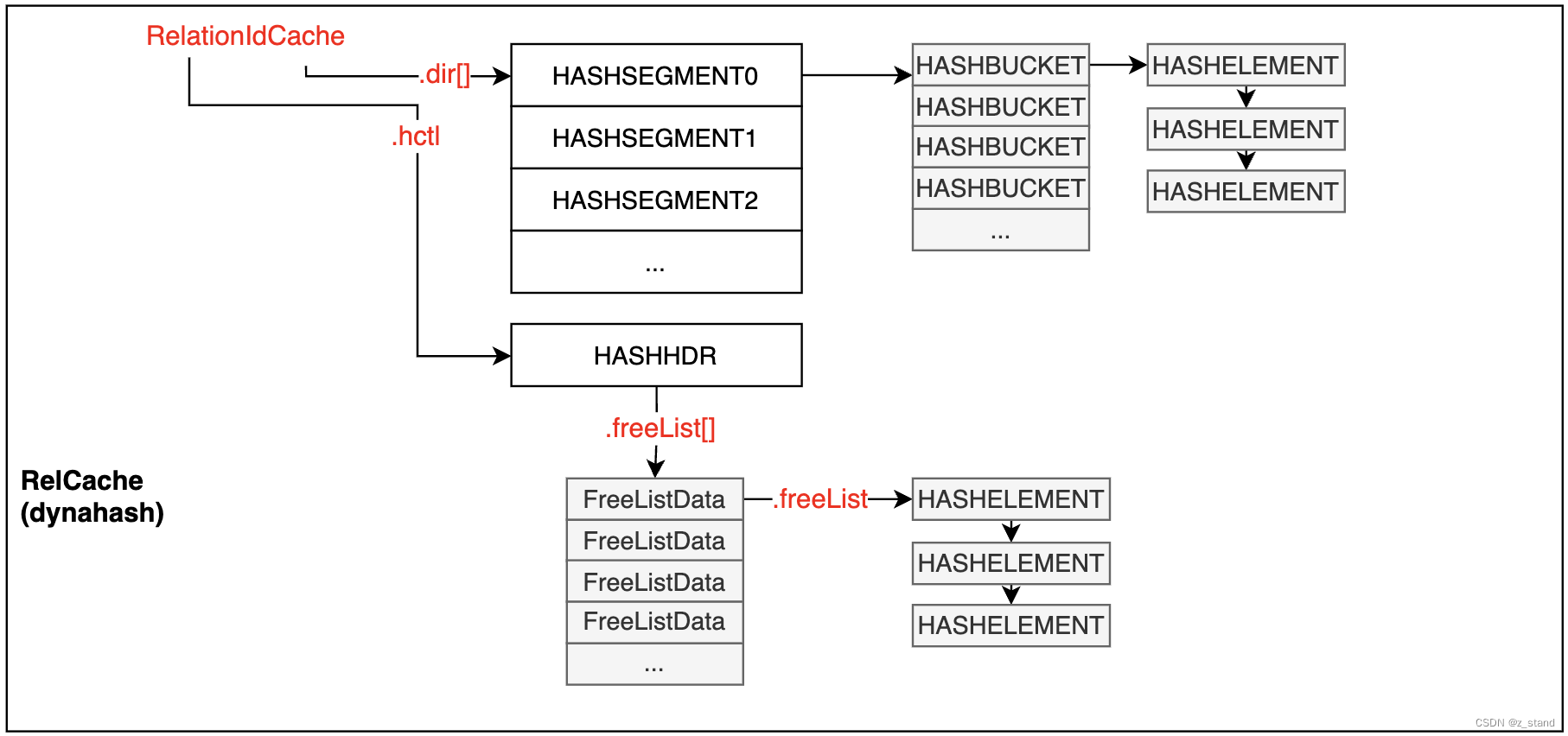
上图中仅列出 HTAB与 extendible hash 实现相关的几个主要的数据结构,还有很多其他的辅助数据结构。
dir[]是一个数组,就是前面介绍 extendible hash时提到的 bucket之上的dir。- 每一个 dir元素指向一个
HASHSEGMENT数组,每一个Segment 的长度必须相同且是 2的 n次方。 - 每一个Segment 是一个数组,数组元素就是bucket。每一个bucket 中存放一个链表,不同的hash-entry可能会被存放到相同的bucket中。
HASHHDR中保存的 freelist 数组。这个 freelist 用来加速 对bucket 内部元素的内存分配,如果发生元素 remove时 该元素对应的 节点内存并不会被立即释放,而是被存储到 freelist中,后续有新的元素的分配需求,会从freelist 中提取。之所以设计为 数组的形态是为了减少并发访问下的 freelist 竞争,数组中 每一个FreelistData 都有一个自己的 mutex, 用 spinlock 来保证访问安全。
可以看到 PG中的 extendible hash 结构相比于经典实现,在 dir 以及 bucket 之间又多了一个 segment数组。
接下来从代码中看看这个 dynahash 的实现是如何支持 查找、插入 和 扩容的。
描述实际的逻辑之前需要理解 HTAB 中的几个关键变量:
- 初始化hash表设置的bucket总数为 k。
hctl->max_bucket是hash表中的bucket数量,表示正在被使用的最大的bucket id,其会动态变化(扩容)。会被初始化为k - 1,这是因为要标识数组下标。hctl->low_maskhash bucket数量的低位表示, 会被初始化为k - 1,如果k 为 16,则low_mask为 15 –0000 1111,hctl->high_maskhash bucket数量的高位表示,会被初始化为1 << (k + 1) -1,high_mask为 31 –0001 1111。hctl->ssize每一个 segment 保存的 bucket 数量上限,必须是2 的整数次幂。初始化时 会通过 k 计算需要多少个 dir segments。比如现在 k为16, ssize 是 8,需要分配 (k - 1) / ssize + 1 个 dir segments,也就是2 个segments就够了。hclt->dsizedir的数量hctl->nsegs已经被分配的dir segments 数量。
接下来我们已 hash_search --> hash_search_with_hash_value 为入口,当然 PG 实现的对hash 表的插入、删除、扩容 逻辑都在这一个函数中。
先看看 calc_bucket 函数,这个函数比较重要,用来根据一个查找键的 hash 值来确定其所属的bucket。
static inline uint32
calc_bucket(HASHHDR *hctl, uint32 hash_val)
{
uint32 bucket;
bucket = hash_val & hctl->high_mask;
if (bucket > hctl->max_bucket)
bucket = bucket & hctl->low_mask;
return bucket;
}
首先我们从前面介绍的 low_mask 和 high_mask 的值,能知道 当前 hash表的 max_bucket 是处于 [low_mask, high_mask] 之间的。最开始 max_bucket 的大小是和 low_mask一样,但是max_bucket 会增加,每次增加一个,直到达到2的整数次幂 才会调整 low_mask 以及 high_mask的值。
从 calc_bucket 中,我们可以看到想要得到一个 hash_val 所属的bucket,只需要两步:
- 确保这个hash_val 小于等于 high_mask && > 0,即
hash_val & hctl->high_mask代码 做的事情。 - 如果得到的结果还是 > max_bucket,则进一步
&<= max_bucket 的 low_mask 就好了。也就是bucket & hctl->low_mask;做的事情了。
这样就得到了一个处于 [0, max_bucket] 的bucket index,接下来拿着这个bucket 去确认所属的 segnum 以及 dir 即可。
回到 calc_bucket 我们能发现一个明显的问题,如果 high_mask 以及 low_mask 的值发生变化,意味着 同一个hash_val 两次查找 得到的bucket 不一样了,这种情况是怎么处理的呢?
这里是发生扩容时的情况,也就是前面介绍 extendible hash时 Bucket D’ 的生成,如何保证之前在 Bucket D 中的元素 在经历扩容之后能够找到属于自己的新家 Bucket D’。
进入扩容逻辑的条件如下:
if (action == HASH_ENTER || action == HASH_ENTER_NULL)
{
/*
* Can't split if running in partitioned mode, nor if frozen, nor if
* table is the subject of any active hash_seq_search scans.
*/
if (hctl->freeList[0].nentries > (long) hctl->max_bucket &&
!IS_PARTITIONED(hctl) && !hashp->frozen &&
!has_seq_scans(hashp))
(void) expand_table(hashp);
}
freeList[0] 是 非 partition模式下 全局只有一个 freelist,这个时候 PG认为其内部 entry的个数超过 max_bucket 的数量,会降低查找效率,则会触发扩容逻辑。
PG 的一些锁(谓词锁、shared buffer) 有partition需求时,则不同partition 的 bucket 在内存空间中基本是隔离的。partition的区分时通过 hash_value 来区分的,确保不同的 hash_value 一定会被映射到指定的 partition。
接下来看看扩容的逻辑都做了什么:
-
基本的需求是 max_bucket 数量 + 1,则先拿到一个 new_bucket = max_bucket+1;并得到该 new_bucket 所属的 new_segnum (dir[new_segnum]) 以及 segindex (seg[segindex])。
-
如果 segnum 没有超过 已经分配的
hctl->nsegs,则转入 5 ;否则继续执行 -
先确认是否需要分配新的dir: 如果 当前segnum >=
hctl->dsize,则需要通过dir_realloc进行 dir扩容,将hctl->dsize << 1即扩容为原来的两倍;否则继续执行 -
继续通过
seg_alloc分配一个新的 segment 填充给dir[new_segnum] -
通过new_bucket & low_mask 找到拥有相同 hash值的 old_bucket。
-
bucket数量自增 并检查 当前bucket数量是否超过
hctl->high_mask,超过了 则需要进行low_mask和high_mask的重写。if ((uint32) new_bucket > hctl->high_mask) { hctl->low_mask = hctl->high_mask; hctl->high_mask = (uint32) new_bucket | hctl->low_mask; }因为 high_mask 一直维持在2 的n次幂 减一的值上,且 max_bucket 的数量每次只 加1,所以这里只有发生max_bucket 是2 的n 次幂时才会进行mask 的重写。目的 还是确保 新的 new_bucket 是处于 [low_mask, high_mask] 之间,因为 new_bucket 是 2 的 n 次幂,则新的 high_mask 一定是 2的n+1 次幂减一(现在的low_mask 是之前的high_mask)。
举例:old_low_mask = 15, old_high_mask = 31; new_bucket = 32, 则 new_low_mask = 31, new_high_mask = 32 | 31 = 63。
-
遍历 old_bucket 中的元素,将其中可以移动的元素移动到新的 bucket, 即移动到
new_seg[new_segindex]链表中。
思考,为什么 max_bucket 的数量增加了,最后在移动 old_bucket 的元素时只需要 判断是否需要移动到new_bucket,不需要去动其他的bucket?
- 确认一个hash_value 属于哪个 bucket,只需要两次映射
high_mask和low_mask。也就是核心转移到在 这两个值发生变化之后如何保证 旧的hash_value 经过这两个值的映射如何维持不变的bucket。 - 再次回到 high_mask 以及 low_mask的初始化上,这两个值的初始值都是 2 的整数次幂 -1,只不过 low_mask 是
1 << n - 1,而 high_mask 是1 << (n + 1) - 1。也就是这两个值的二进制表示全是1,即使这两个值发生变化 也都是维持他们的二进制表示都是1 的原则。找到了old_bucket(hash_value 和 new_bucke 可能相同的bucket)之后, 则剩余bucket中元素对应的 hash_value 在新的 low_mask 以及 high_mask 中计算的值必然是一样的。
到此整个 dynahash 内部的核心旧描述清楚了,保持内存使用率的情况下可以实现高效的动态扩容。至于其他的,比如 insert,remove操作,则是通过 用户在进行 hash_search 操作传入的标记实现的:
- 比如
HASH_ENTER表示是一个插入操作,这个时候 hash_search 会返回一个 HASHELEMENT 的地址 以及found指针,如果found是空,则表示没有找到这个元素,但是已经分配了对应的存储空间。 可以考虑对该地址内容进行填充,就实现了插入;或者修改,就实现了对应元素的修改。 HASH_REMOVE标记则表示找到了对应的元素之后会从 hash表中移除,不过该元素的存储空间会移动到 freelist中,不会立即释放。
Cache 同步机制
前面整体介绍了 PG 除了 PlaneCache之外的整个 Cache实现机制,无论是SysCache 还是 RelCache 都是Backend (会话)级别的缓存,所以需要有同步机制来保证不同的 Backend对 Cache内容的修改能够同步到其他 Backend 的Cache中。
PG 采用 Invalid Message 机制来实现 Cache同步,即 Backend1 修改了Cache中的内容,主动发送invalid message 信息给其他的backend;Backend2 在收到invalid-message 之后会将本地缓存的该条 cache-entry 移除,读的时候缓存未命中,则会从heap表中读取再加载到本地 cache。
RelCache 和 SysCache 都有 invalid 机制,不过在这里遇到一些代码细节没有看明白,Cache一致性部分会考虑单独开一个小篇来详细描述,缓存一致性的设计其中有很多细节很有趣,比如什么时候触发cache invalid, 什么时候发送给其他的backend ? 怎么发送?如何保证发送的可靠性?因为系统表的访问与 PG的事物语义强相关,必须要保证 cache同步的可靠性,才能保证并发访问的准确性。
这里面有非常多的工程设计细节,PG 在当前的 cache 架构下利用 进程级 本地缓存来保证表元数据访问的高效性,但是也会增加其实现准确功能的复杂性。
学习这一段时间的PG之后深刻体会到了其内核的博大精深,如果这个设计能够达成高性能的目的,绝不会向复杂度妥协。
包括heikki 老师主导的 gpdb,为了保障 mpp 在 多个 qe之间高效传输数据,在 UDP 基础上 设计了 interconnect 通信机制 来代替 tcp。