记录一个同门给的SNN demo,仅供自己参考
1 SNN和ANN代码的差别
SNN和ANN的深度学习demo还是差一些的,主要有下面几个:
-
输入差一个时间维度
T,比如:在cv中,ANN的输入是:[B, C, W, H],SNN的输入是:[B, T, C, W, H]
补充
为什么snn需要多一个时间维度?
因为相较于ann在做分类后每个神经元可以输出具体的数字(比如在分类问题中这个数字表示概率),但snn每个神经元的输出都是0或1。解决方法就是那么可以模拟时间步(time steps),让这个前向传播的过程多来几次,最后看哪个神经元输出的1比较多,就作为最终结果(类似于ann里输出的数字最大的那个),在train中和label求loss,在应用中就作为模型对应输出。 -
ANN求梯度时可以直接用backward(),SNN由于不可导,需要手写反向传播 -
SNN中涉及神经元的选择问题(比如LIF,IF,SRM神经元等) -
ANN的输入输出都是具体数值,而SNN的输入输出都是脉冲 -
SNN的数据流传播过程是:spike -> u -> spike,u指的是膜电压membrane potential
2 SNN demo讲解
2.1 定义模型
class Model(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
Linear(784, 800),
IF(),
Linear(800, 10),
IF()
)
def forward(self, x):
return self.model(x)
2.2 重新定义Linear
由于nn.Linear()这个函数只能是B * CWH(以cv为例,C, W, H是表示特征的),SNN的数据流需要转化成BT * CWH的形式,经过Linear才有意义,所以重新定义了Linear():
class Linear(Layer):
def __init__(self, in_features: int, out_features: int, bias: bool = False,
device=None, dtype=None) -> None:
super(Linear, self).__init__()
self.model = nn.Linear(in_features, out_features, bias, device, dtype)
class Layer(nn.Module):
def __init__(self) -> None:
super(Layer, self).__init__()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
:param x: input stimuli from pre-synapses in T time steps, shape=[N, T, D], while N is batch size,
T is time step, D is feature dimension.
:return: summation of pre-synapses stimuli to post-synapses neurons through synapse efficiency,
each time step are integrated independently.
"""
return forward_with_time(self.model, x)
def forward_with_time(model: nn.Module, x: torch.Tensor) -> torch.Tensor:
batch_size, steps = x.shape[:2] # x.shape[0-1]
out = model(x.flatten(0, 1).contiguous()) # [N, T, D] -> [N * T, D]
return out.view(batch_size, steps, *out.shape[1:]) # 将经过Linear后的数据再还原成[N, T, D]这样的维度
2.3 神经元定义
spike -> u -> spike这样的数据流是在神经元中实现的,我们以IF神经元为例:
class IF(nn.Module):
def __init__(self, threshold=1., rest=0., surrogate=sigmoid):
super(IF, self).__init__()
self.threshold = threshold
self.rest = rest
self.surrogate = surrogate.apply
def forward(self, inputs):
return self.integrate_fire(inputs)
def integrate_fire(self, inputs):
u = 0
spikes = torch.zeros_like(inputs)
for i in range(inputs.shape[1]): # T
u += inputs[:, i]
spikes[:, i] = self.surrogate(u - self.threshold)
u = u * (1 - spikes[:, i]) + self.rest * spikes[:, i]
return spikes
在integrate_fire函数中,我们不妨举这样一个小例子来模拟一下过程:
t = torch.rand(3, 3)
zero_t = torch.zeros_like(t)
print(t)
print(zero_t)
u = 0
for i in range(t.shape[1]):
print(t[:, i])
u += t[:, i]
print(u) # 单独一个冒号代表从头取到尾
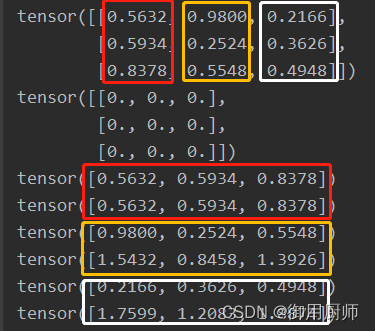
假设每一列代表一排神经元,那么每一次循环其实就是对一排神经元做处理的过程,循环次数为共有多少列(也就是第一维度时间步T)。当spike作为input输进来时,先影响膜电压u,然后根据u,决定输出什么spike。由于输出了spike,自身也要做调整。上面的过程就是integrate_fire()函数的过程,不同神经元的差别也就在于此。
2.4 代理梯度
代理梯度这里用的是sigmoid:
class sigmoid(basic_surrogate):
@staticmethod
def backward(ctx, grad_out):
sgax = (ctx.saved_tensors[0] * ctx.alpha).sigmoid_()
return grad_out * (1. - sgax) * sgax * ctx.alpha, None # sigmoid: σ(x), σ'(x) = σ(x)(1-σ(x))
为了用backward还得把forward补齐,因此完整的反向传播代码如下:
def spike_emiting(potential_cond):
"""
"""
return potential_cond.ge(0.0).to(potential_cond) # u - threshold > 0 才会 emit spike
class basic_surrogate(torch.autograd.Function):
@staticmethod
def forward(ctx, inputs, alpha=4.): # alpha的作用是改变sigmoid的形状,让它更逼近神经元发放脉冲时的图像
if inputs.requires_grad:
ctx.save_for_backward(inputs)
ctx.alpha = alpha
return spike_emiting(inputs)
class sigmoid(basic_surrogate):
@staticmethod
def backward(ctx, grad_out):
sgax = (ctx.saved_tensors[0] * ctx.alpha).sigmoid_()
return grad_out * (1. - sgax) * sgax * ctx.alpha, None # sigmoid: σ(x), σ'(x) = σ(x)(1-σ(x))
3 SNN demo 完整版
解析看不懂没关系,如果要用的话只需要修改下面几个地方:
- 输入输出都是
spike形式,所以要保证自己的输入是[B, T, D]的形式,D可以是[C, H, W](cv),也可以是其他 - 神经元选用的是
IF神经元,如果要用别的就修改一下2.3的integrate_fire()函数 - 网络结构是两层全连接,修改网络结构的话在
2.1下面的代码部分修改 - 要修改代理梯度的函数,去
2.4 - 要修改其他
ANN的model,去2.2
要我的话可能就改前两个…()
最后奉上完整demo(还没测试过等测试完就把括号里这个划掉)
import torch
import torch.nn as nn
@torch.jit.script
def spike_emiting(potential_cond):
"""
"""
return potential_cond.ge(0.0).to(potential_cond)
class basic_surrogate(torch.autograd.Function):
@staticmethod
def forward(ctx, inputs, alpha=4.):
if inputs.requires_grad:
ctx.save_for_backward(inputs)
ctx.alpha = alpha
return spike_emiting(inputs)
class sigmoid(basic_surrogate):
@staticmethod
def backward(ctx, grad_out):
sgax = (ctx.saved_tensors[0] * ctx.alpha).sigmoid_()
return grad_out * (1. - sgax) * sgax * ctx.alpha, None # sigmoid: σ(x), σ'(x) = σ(x)(1-σ(x))
class IF(nn.Module):
def __init__(self, threshold=1., rest=0., surrogate=sigmoid):
super(IF, self).__init__()
self.threshold = threshold
self.rest = rest
self.surrogate = surrogate.apply
def forward(self, inputs):
return self.integrate_fire(inputs)
def integrate_fire(self, inputs):
u = 0
spikes = torch.zeros_like(inputs)
for i in range(inputs.shape[1]):
u += inputs[:, i]
spikes[:, i] = self.surrogate(u - self.threshold)
u = u * (1 - spikes[:, i]) + self.rest * spikes[:, i]
return spikes
# 由于多一个维度T,在使用torch.nn的层时需要多一步处理,每个t的脉冲要独立加权
def forward_with_time(model: nn.Module, x: torch.Tensor) -> torch.Tensor:
"""
..code-block:: python
B, T = 256, 100
l1 = nn.Conv2d(1, 16, 3)
l2 = nn.AvgPool2d(2, 2)
out1 = forward_with_time(l1, torch.randn(B, T, 1, 28, 28))
out2 = forward_with_time(l2, out1)
"""
batch_size, steps = x.shape[:2]
out = model(x.flatten(0, 1).contiguous())
return out.view(batch_size, steps, *out.shape[1:])
class Layer(nn.Module):
def __init__(self) -> None:
super(Layer, self).__init__()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
:param x: input stimuli from pre-synapses in T time steps, shape=[N, T, D], while N is batch size,
T is time step, D is feature dimension.
:return: summation of pre-synapses stimuli to post-synapses neurons through synapse efficiency,
each time step are integrated independently.
"""
return forward_with_time(self.model, x)
class Linear(Layer):
def __init__(self, in_features: int, out_features: int, bias: bool = False,
device=None, dtype=None) -> None:
super(Linear, self).__init__()
self.model = nn.Linear(in_features, out_features, bias, device, dtype)
class Model(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
Linear(784, 800),
IF(),
Linear(800, 10),
IF()
)
def forward(self, x):
return self.model(x)








![[源码解析]socket系统调用上](https://img-blog.csdnimg.cn/7994bde0f3a44fbfb757391af88a2db0.png#pic_center)