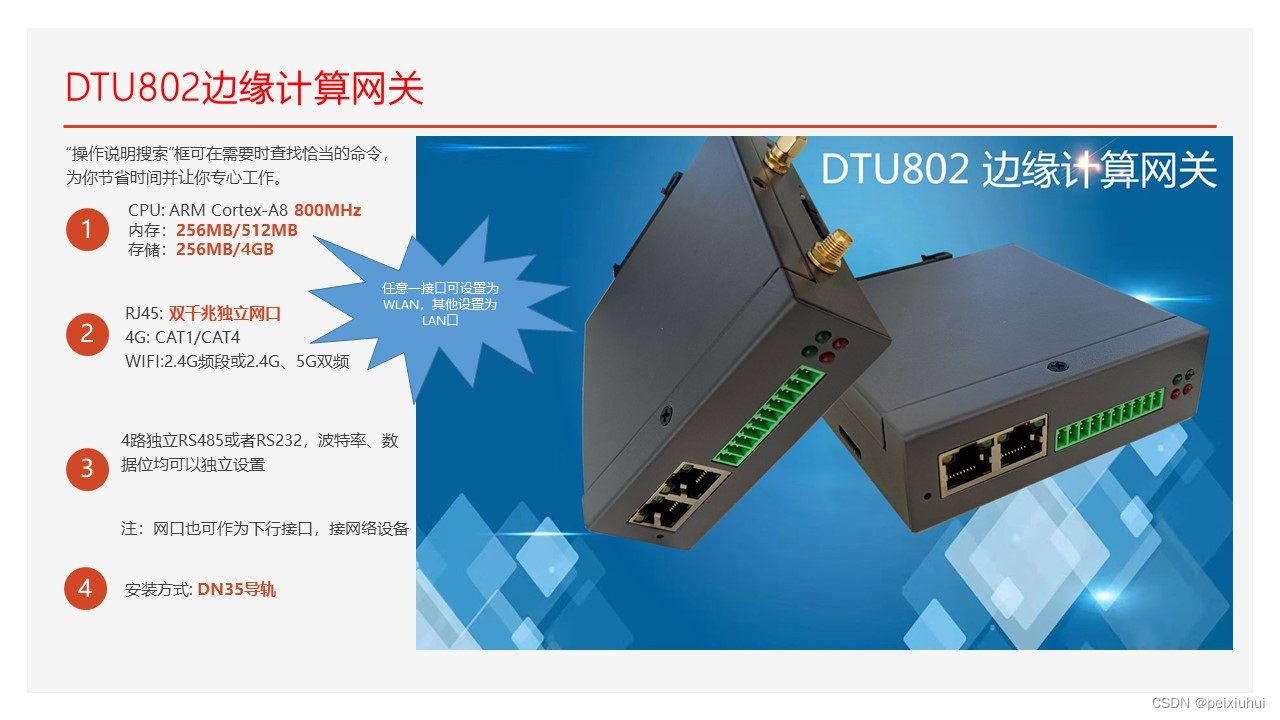
前两天看了SVM、逻辑回归、KNN、决策树、贝叶斯分类这几个很成熟的机器学习方法,但是,今天不看方法了,来看一种思想:集成学习:
先来看一下集成学习的基本原理:通过融合多个模型,从不同的角度降低模型的方差或者偏差,典型的有三种:Bagging、Boosting、Stacking,集成学习分四天来学习,今天先看一一下:偏差、方差这两个概念:
对于一个回归问题,我们假设,样本(x,y)服从P(x,y),再假设是集合D中的样本,D从P分布采样得到,因为采样过程会存在噪声
,或者也可以叫他采样误差,早上一般服从高斯分布
:
这里我们假设我们需要优化得到的模型为f(X),是其在D上的优化结果,由于D是随机采样得到的任意一个分布,所以
也是随机变量,我们定义
是在D上的期望为:
,再定义bias(x)为期望值和真实值之间的平方差:
定义采样分布D的偏差bias(x)为期望值和采样值之间的平方差:
又可以知道:
所以,
模型随机变量再D上的方差var(x)为:
实际优化的摸底是让模型随机变量在所有可能的样本集合分布D上的预测误差的平方误差的期望最小,也就是最小化:
是个常量,优化的最终目的是降低模型的方差和偏差,方差越小,说明不同的采样分布D下,模型的泛化能力大致相当,从侧面反映了模型没有发生过你和,偏差越小,说明模型对样本预测的越准,模型的拟合能力会越好。
实际在选择模型的时候,随着模型复杂度的增加,模型的偏差bias(x)越来越小,而方差var(x)越来越大,我们需要找的,就是某一个时刻,模型的方差和偏差值之和达到最小,此时,可以仍未说模型性能在误差及泛化能力方面达到最优。