锁的分类
锁占用少量内存,实际上在不竞争的情况下性能不错.
第一个就是靠test_and_set实现的自旋锁,高效,因为在用户态,但是却不可扩展,对cache,os都不友好

第二个是mutex,实际上两个部分组成,一个在内核态,一个夺锁失败要陷入内核态os latch等待调度。

第三个
Adaptive spinlock是一种锁机制,用于在多线程环境中防止对共享资源的并发访问。它的工作原理是当一个线程请求获取锁时,如果锁是可用状态,该线程会直接获取锁并进入临界区域执行任务;如果锁已经被其他线程占用,则该线程不会阻塞等待锁的释放,而是在一定时间内尝试反复获取锁(自旋),直到锁被释放或者达到最大自旋次数后才会进入睡眠状态,等待通知唤醒。
Adaptive spinlock的优点是:
- 适应性好:由于自旋的次数是根据当前系统负载情况动态调整的,因此可以避免多余的自旋等待,减少了资源的浪费和响应时间的延迟。
- 减少上下文切换:相比于传统的阻塞式锁,在自旋等待过程中,线程并没有被挂起,所以可以减少上下文切换的开销。
- 避免死锁:自旋锁只会在短时间内占用CPU资源,因此不会像阻塞式锁那样容易出现死锁问题。
但是,Adaptive spinlock也存在一些缺点:
- 自旋等待会占用CPU资源,如果自旋的时间过长或者发生争用时容易导致系统负载升高。
- 自旋锁不适用于较长时间的临界区,因为在这种情况下自旋等待会过于耗费CPU资源,导致性能下降。
- 如果线程释放锁的通知被延迟或者遗失,将会导致自旋无法结束,浪费CPU资源。

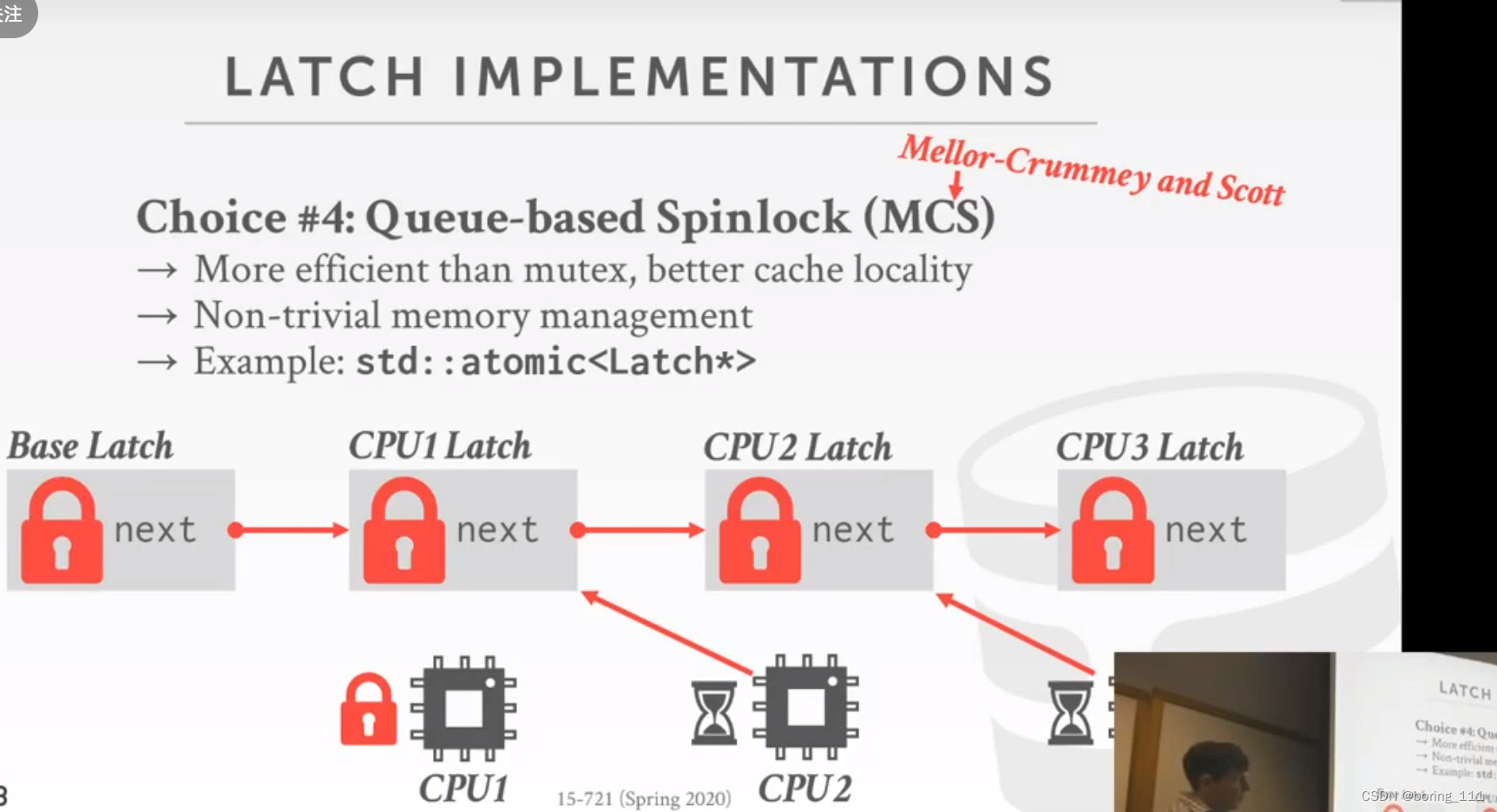
第四个
Queue-Based Spinlock(MCS Spinlock)是一种旨在解决自旋锁长时间自旋浪费CPU资源的问题,同时还可以避免多核系统中的总线争用和缓存同步的问题。
MCS Spinlock的工作原理如下:
- 每个线程都有自己的一个等待节点(MCS Node),该节点包含一个标志位(locked)和一个指向前一个节点的指针(prev)。
- 当一个线程需要获取锁时,它会先将自己的节点加入到锁的等待队列的末尾,并将自己的标志位置为true。然后线程会检查它的前一个节点是否已经释放了锁,如果已经释放则该线程直接进入临界区,否则线程会自旋等待。
- 当一个线程完成临界区的操作后,它会将自己的节点从队列中移除,并将它的前一个节点的标志位置为false,通知下一个节点可以继续执行。
Queue-Based Spinlock(MCS Spinlock)的优点如下:
- 减少了不必要的自旋:每个线程只需要检查自己的前一个节点是否已经释放锁,而不是像传统自旋锁那样不断尝试获取锁,这样可以减少不必要的自旋,降低了系统的开销。
- 降低了总线争用和缓存同步:MCS Spinlock的节点是分散存储在不同的处理器缓存中,而不是像传统自旋锁那样共享一个内存变量,这样可以减少不必要的总线争用和缓存同步,提高了系统的可扩展性。
- 可以有效避免死锁问题:每个线程都有一个自己的等待节点,并且节点之间是单向链表结构,所以不存在像传统自旋锁那样的死锁问题。
Queue-Based Spinlock(MCS Spinlock)的缺点如下:
- 实现复杂:相比于传统自旋锁,MCS Spinlock的实现更加复杂,需要额外的数据结构来维护节点的关系。
- 需要更多的内存:由于每个线程都需要一个等待节点,所以在多线程的情况下,需要消耗更多的内存。
第5个读写锁,这个就注意一个点,如果有写锁被阻塞的化,后来的写锁也要被阻塞,目的是为了写饿死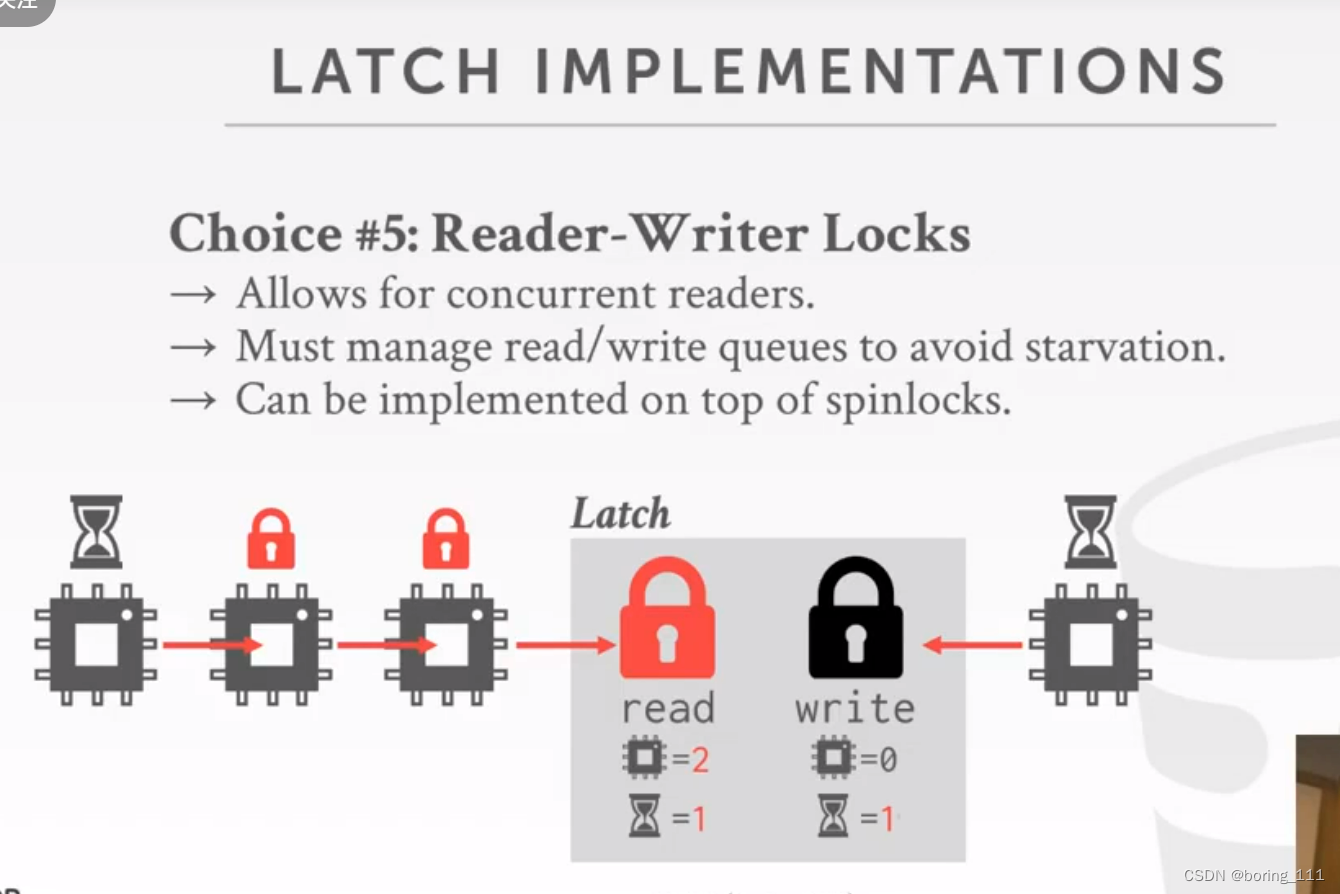
B+树锁策略优化
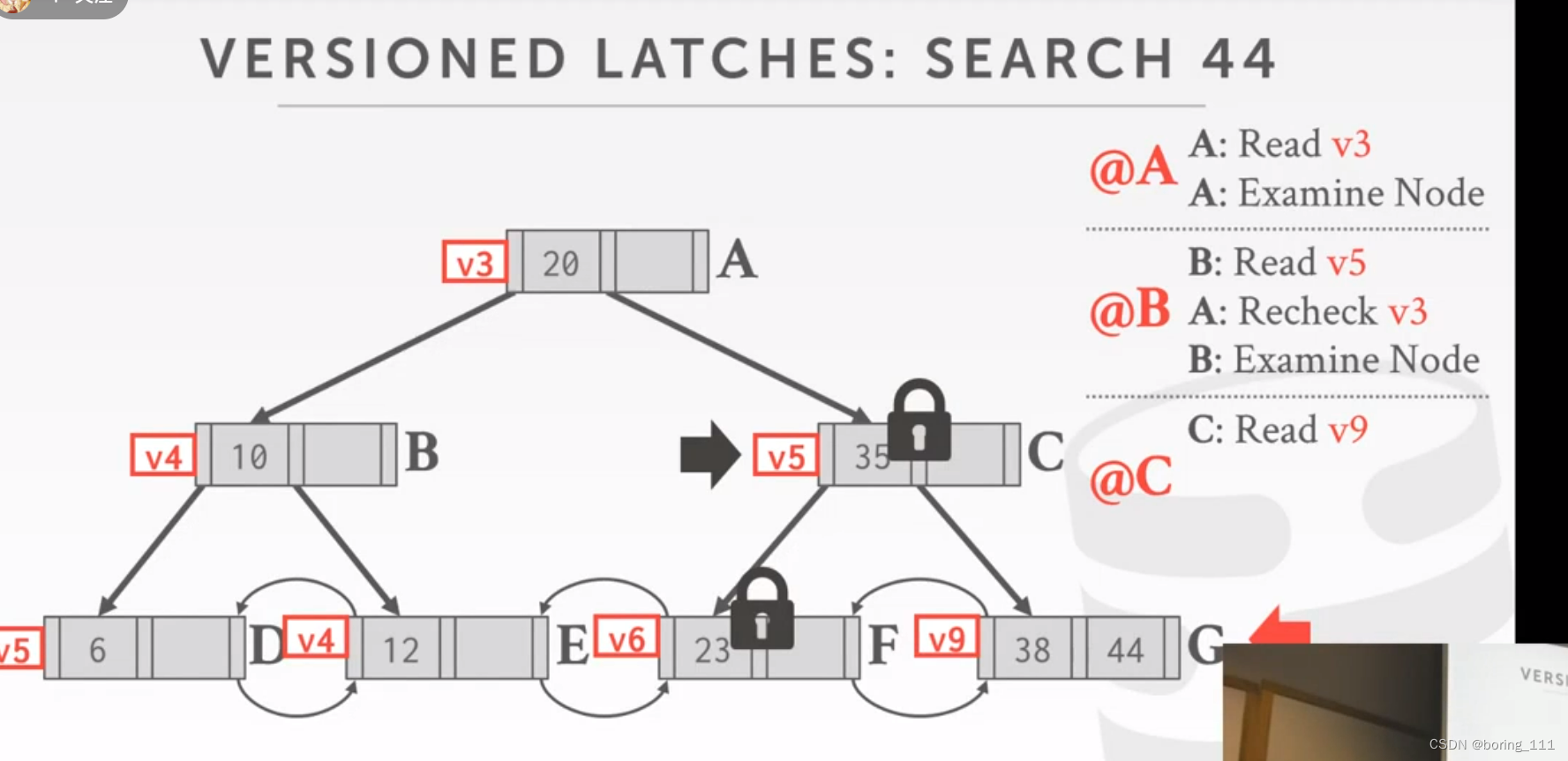
1.就是读的话,拿到下面的节点后就可以释放上面一个节点,写的话,就是写入安全,不会分裂或者使节点少于一半,可以释放祖先节点全部的锁。还要类似的occ策略,在已知冲突少的情况下,我们可以到最后的叶子节点再加写锁,默认是不会对父节点做改变,如果改变的话,我们就加写锁重试。
2.
这个类似mvcc策略就是看看父节点是不是版本变化,变化的话说明我们错过了跟新,可能导致错误状态,我们要重试啦
Trie
因为cache miss也是内存数据库的瓶颈,树高logN的话,那么可能就有log N 次cache miss,而Trie是logK,其中N是节点个数,而k是key的长度。

这个做了水平和垂直两方面的优化,水平就是把0和1,用位置来代替后就可以去掉了。垂直就是如果没有分叉的话,为了节省内存,我们直接指针指向tuple,到tuple验证, 同时减少了cache miss。但是有可能出现假阳性,就像个布隆过滤器一样。
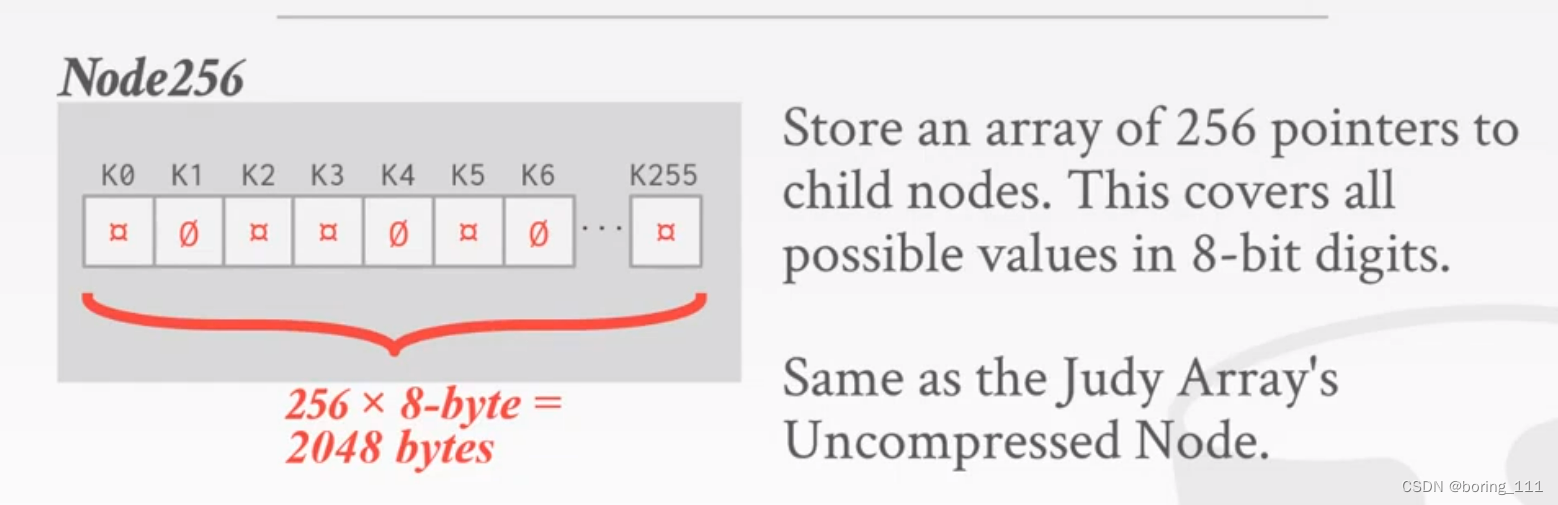
judy array



judy vs ART