前言
TensorFlow是一个在机器学习和深度学习领域被广泛使用的开源软件库,用于各种感知和语言理解任务的机器学习。

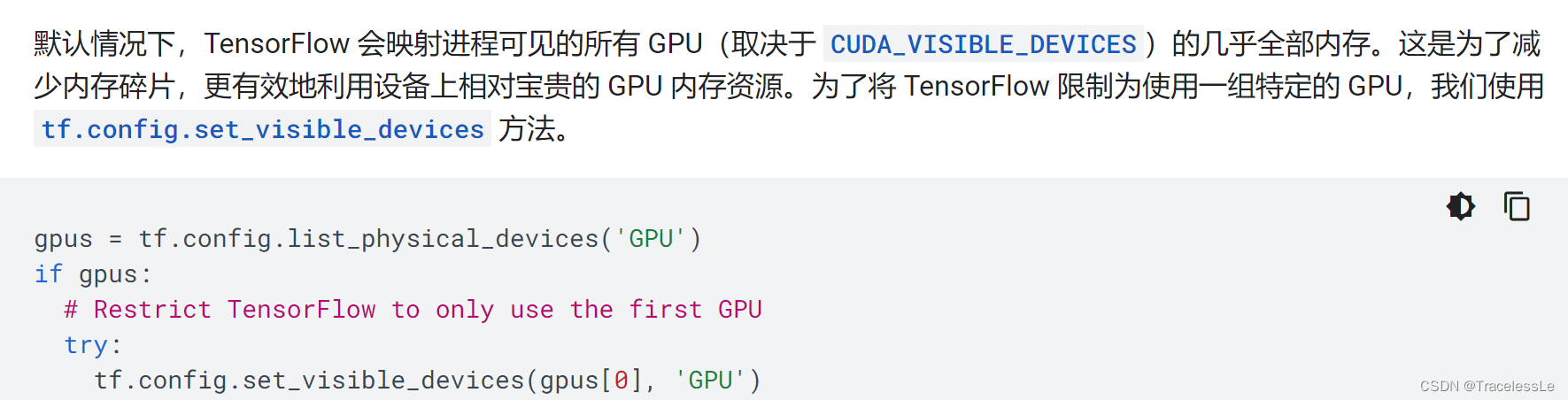
默认情况下,TensorFlow 会映射进程可见的所有 GPU(取决于 CUDA_VISIBLE_DEVICES)的几乎全部内存。这是为了减少内存碎片,更有效地利用设备上相对宝贵的 GPU 内存资源。但有时我们不需要这种特性,所以需要想办法避免这种情况。
本文简要介绍TensorFlow的GPU使用相关设置。
import tensorflow as tf
显卡使用设置方式
- 设置进程在指定的显卡上运行
device_id = 5
gpus = tf.config.experimental.list_physical_devices('GPU')
gpu = gpus[device_id]
tf.config.set_visible_devices(gpu, 'GPU')
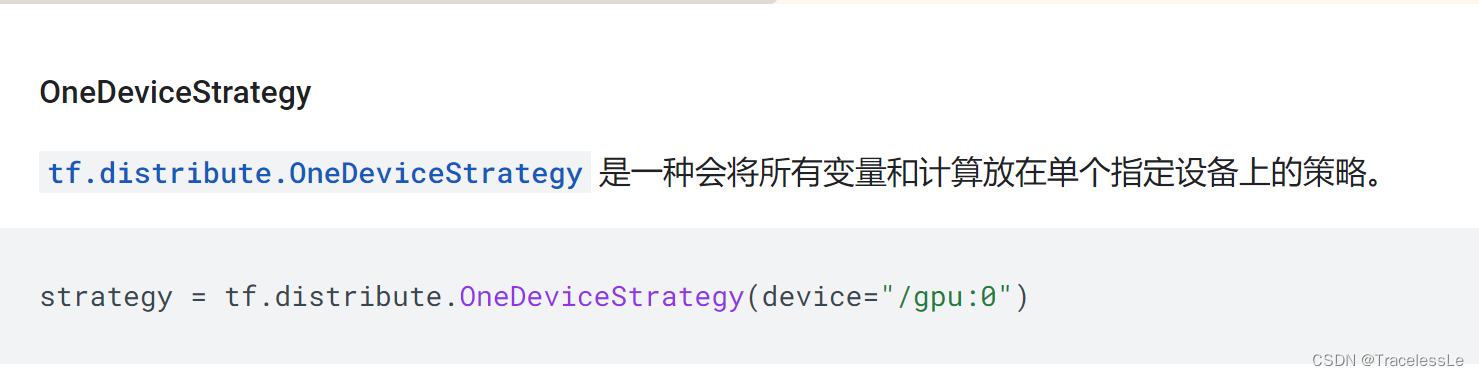
- 设置单卡分布式模式运行
strategy = tf.distribute.OneDeviceStrategy(device=f"/gpu:{device_id}")
with self.strategy.scope():
outputs = model(inputs)
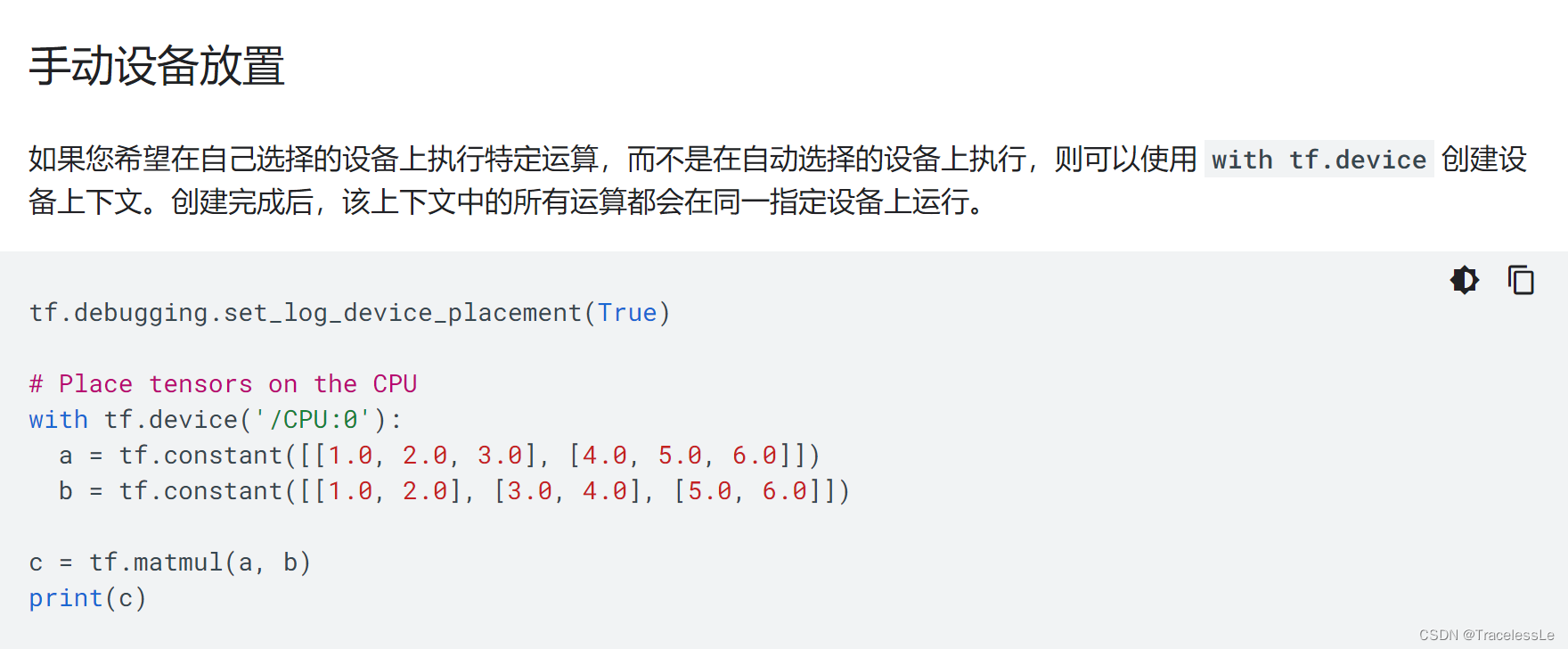
3. 设备指定显卡放置变量和运行计算
device_id = 2
with tf.device(f"/gpu:{device_id}"):
outputs = model(inputs)
显存占用设置方式
- 设置每张卡上所运行进程占用的显存比
tf_config = tf.compat.v1.ConfigProto()
tf_config.gpu_options.per_process_gpu_memory_fraction = 0.15 # 设置太小可能会导致所加载的网络某些层初始化失败
session = tf.compat.v1.Session(config=tf_config)
该方法为兼容v1版本的TensorFlow的方法,相应的还有set_memory_growth方法。见参考资料[3]。
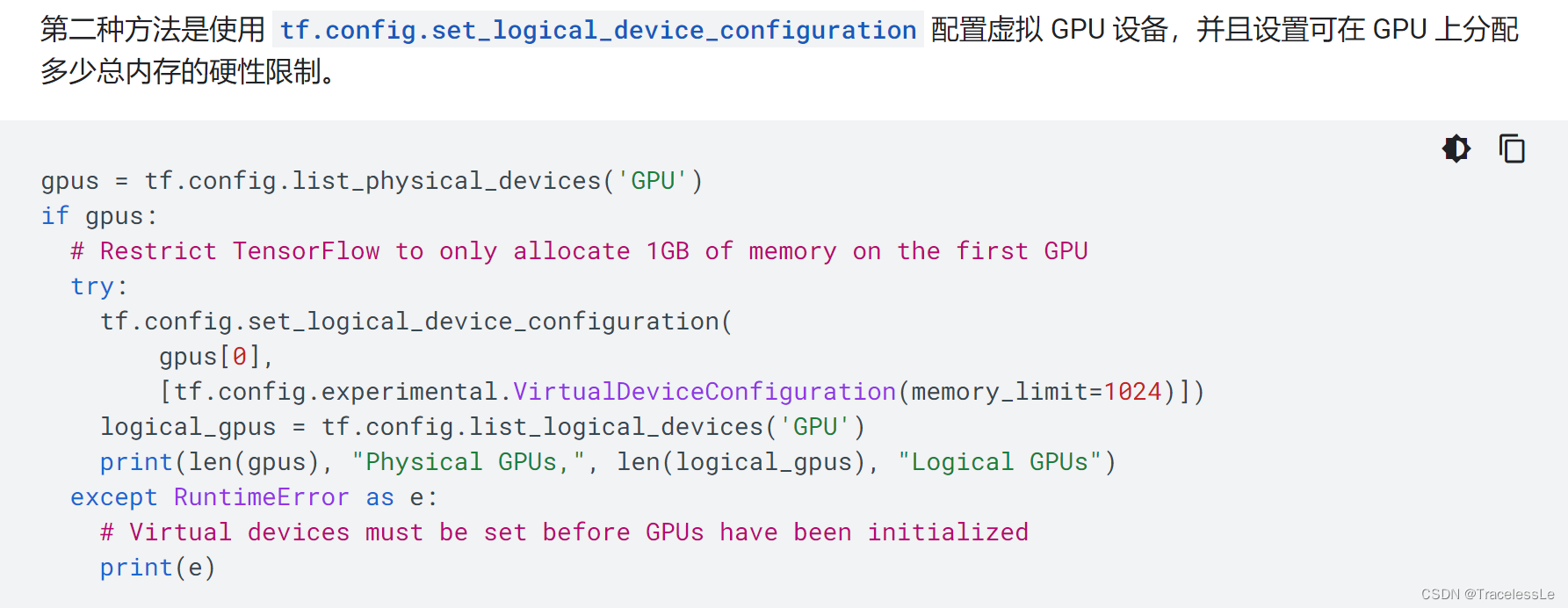
- 设置每张卡上所运行进程的显存占用上限
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu_i in gpus:
tf.config.experimental.set_virtual_device_configuration(gpu_i, [tf.config.experimental.VirtualDeviceConfiguration(memory_limit=3096)])
其他说明
实测发现以下组合能够较好控制显卡和显存的使用:
device_id = 5
gpus = tf.config.experimental.list_physical_devices('GPU')
gpu = gpus[device_id]
tf.config.experimental.set_virtual_device_configuration(gpu, [tf.config.experimental.VirtualDeviceConfiguration(memory_limit=3096)])
tf.config.set_visible_devices(gpu, 'GPU')
版权说明
本文为原创文章,独家发布在blog.csdn.net/TracelessLe。未经个人允许不得转载。如需帮助请email至tracelessle@163.com或扫描个人介绍栏二维码咨询。
参考资料
[1] 使用 GPU | TensorFlow Core
[2] 使用 TensorFlow 进行分布式训练 | TensorFlow Core
[3] tf.config.experimental.set_memory_growth | TensorFlow v2.10.0
[4] machine learning - Why Tensorflow’s MirroredStrategy and OneDevicestrategy does not work on colab? - Stack Overflow
[5] tf.distribute.OneDeviceStrategy | TensorFlow v2.10.0
[6] Tensorflow v2 Limit GPU Memory usage · Issue #25138 · tensorflow/tensorflow



![[Linux打怪升级之路]-yun安装和gcc的使用](https://img-blog.csdnimg.cn/fd5b4868e8174ab3967724da7eaa62db.png)