C++标准库-体系结构与内核分析
根据源代码来分析
介绍
自学C++侯捷老师的STL源码剖析的个人笔记,方便以后进行学习,查询。
为什么要学STL?按侯捷老师的话来说就是:使用一个东西,却不明白它的道理,不高明!

Level 0 使用C++标准库
标准库和STL是同样的东西吗?
不是,在标准库当中百分之80左右是STL,STL分为六大部件。
一些新旧标准:
- C++标准库没有.h的后缀了,例如
#include <vector> - 新式的头文件不带.h,例如
#include <cstdio>,但是原来的带有.h的依然可以使用 - 命名空间,把什么函数,模板之类的可以封装起来,新式的头文件以及组件都被封装到
std当中
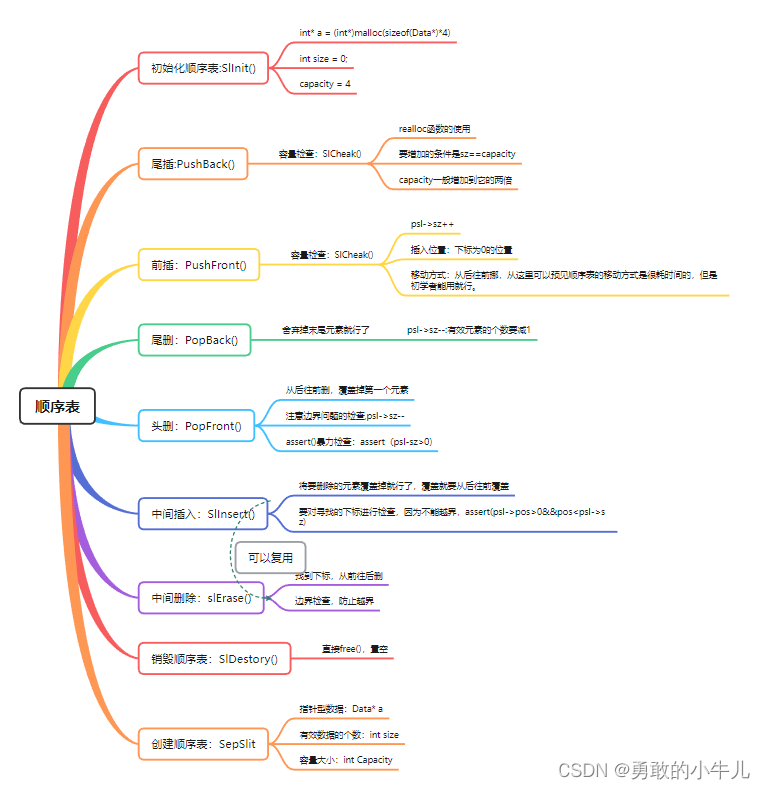
STL六大部件
- 容器
- 分配器
- 算法
- 迭代器
- 适配器
- 分配器
- 容器:容器要放东西,东西要占用内存,所以容器他非常好的是可以帮我们把内存的问题给解决掉,你看不到内存这个东西,只需要不断从容器当中放入/取出东西就好了,所以容器的背后需要另外一个部件去支持它,这个部件就是分配器,数据在容器里面。
- 分配器:是用来支持容器的。
- 算法:有一些函数/操作是由容器做的,但是更多的是包含在算法当中,操作数据的操作在算法里面。
- 迭代器:如何用算法去操作数据呢?使用迭代器,也就是泛化指针。
- 仿函数:作用像是一种函数。
- 适配器:把容器/算法/迭代器做一些转换。

六大部件之间的关系

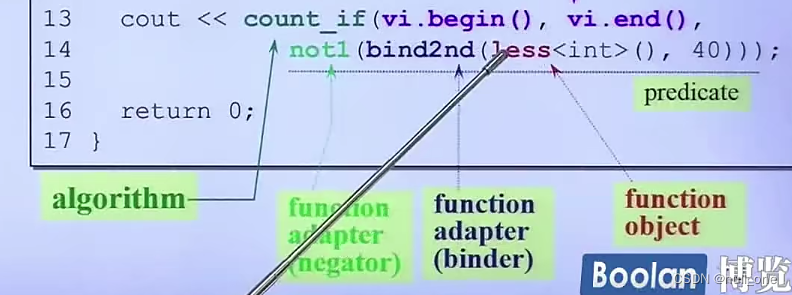
vector<int, allocator<int>>,第二个参数是allocator。
以上为六大部件之间具体的联系与配合。在上方的程序当中,less<int>()这是标准库当中的一个仿函数,然后他的作用是进行比较,比如说a < b,然后现在利用了count_if这个算法,其作用是找到我们指定目标的数值,现在假如需要找到小于40的值,但是仿函数少了第二参数,所以就可以利用之前适配器的功能,适配器就是把容器/算法/迭代器做出一些转换,使用bind2nd这个转换,即可有了第二参数40;之后又进行函数的转换,加了一个not1,以前要找小于等于40,现在要大于40。
#include<vector>
#include<algorithm>
#include<functional>
#include<iostream>
using namespace std;
int main(void) {
int ia[ 6 ] = { 27, 210, 12, 47, 109, 83};
vector<int, allocator<int>> vi(ia, ia+6);
cout<< count_if(vi.begin(), vi.end(), not1(bind2nd(less<int>(), 40)));
return 0;
}
结果:
4
...Program finished with exit code 0
Press ENTER to exit console.
疑惑
- 仿函数:less()这是标准库当中的一个仿函数,然后他的作用是进行比较,比如说a < b
- 适配器
复杂度

前闭后开的区间
把元素放到容器当中,容器当然是有头有尾的,所有容器都提供begin(),end()迭代器,头没有疑虑,尾巴呢?所谓容器的前闭后开区间,标准库规定,begin()要表示开始的启动,end()表示最后一个元素的下一个元素。

###容器的遍历(C++11之前的写法):
Container<T> c;
...
Container<T>::iterator ite = c.begin();
for (; ite != c.end(); ++ite)
...
最新的写法(最推荐C++11)基于范围的for循环
for (auto decl : coll)
{
statement;
}
decl是一个声明,coll是一个容器,相比以前的写法,方便太多了。
不是非必要的时候不用auto,因为知道一个元素的类型还是很重要的。

容器的结构

容器的分类
1.序列式容器

| 序列式容器 | 特点 | 额外学习材料 |
|---|---|---|
| array | 一段连续空间,不论是否使用,都会全部占用 | array |
| vector | 尾部可进可出,当空间不够时会自动扩充 | vector |
| deque | 双向都可扩充,两端都可进可出 | deque |
| list | 一个双向环状链表,有向前后和向后两个指针 | list |
| forward_list | 一个单向链表,仅有向后一个指针 | forward_list |
关联型容器
联式容器类似于key-value,非常适合于查找操作
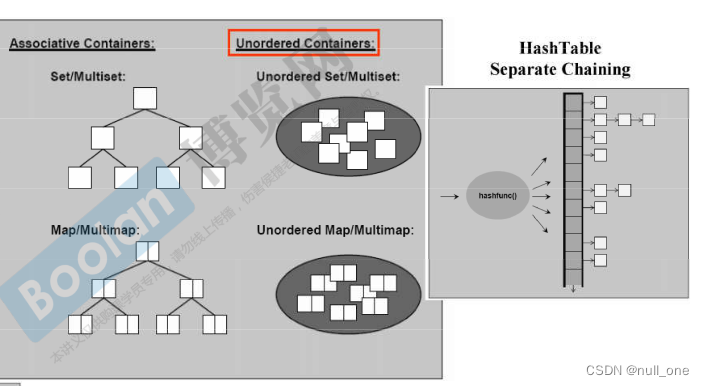
| 关联式容器名 | 特点 | 实现 | 注释 | 额外学习材料 |
|---|---|---|---|---|
| set/multiset | key和value是同一个,BST存储是有序的 | 红黑树 | 加上multi意味着可以重复键值对 | set,multiset |
| map/multimap | 每一个key对应一个value,BST存储是有序的 | 红黑树 | 加上multi意味着可以重复键值对 | map,multimap |
| unordered_set/unordered_multiset | 相对于set/multiset,存储是无序的 | 哈希表 | 加上multi意味着可以重复键值对 | unordered_set,unordered_multiset |
| unordered_map/unordered_multimap | 相对于map/multimap,存储是无序的 | 哈希表 | 加上multi意味着可以重复键值对 | unordered_map,unordered_multimap |

在标准库当中,并没有规定set和map用什么来实现,但是用红黑树(因为左右两边会自己平衡)非常好,所以各家IDE都用红黑树来做set和map。
map,每一个节点,都有key和value,set却没有明确划分。
选择普通的set和map,里面的元素的key是不能重复的,但是使用multiset以及multimap的时候,里面的key是可以重复的。
哈希表的某一条链表不能太长,因为单链表是要不断进行遍历的,这样时间复杂度就会很高。