笔者最近思考了自己参与的分布式系统业务的架构小细节,虽然笔者每天做的是实现部分需求与业务,但是笔者还是拥有很多时间去读底层源码的,加之笔者自身的思考与实践demo的总结,笔者将在本篇文章中提出笔者自己对“抽离”与“封装”思想的感悟,以及实际代码引发的思考过程,以供您的理解,如有不当之处,大可相互讨论,集思广益。
关于抽离与封装
以下内容是笔者的个人见解,并没有百度找寻资料进行印证,各位读者要怀着辩证的角度思考。
抽离思想是封装的前置,我们通常会在 当多个方法或者类都用到相同代码段或者实例对象时 将公用的重复段进行抽取,分离,封装成新的方法或者组件进行重复调用,达到解耦合,易维护,省资源的意图,但是我们通常也只具备将代码重复的段进行封装抽离的意识,下意识觉得这么做会使自己的代码变得简洁优雅。
笔者这里要告诉大家的是,真作为一个善于思考,致力于优雅编程的技术人员,我们不仅仅要将方法,实例中的重复代码拎出来封装,还要多观察,例如业务中重复的逻辑,运行过程中可以整合的机制,实体的同名字段等等。而封装思想更是造轮子时必不可少的意识之一,容器固然是给我们造轮子带来了巨大的帮助,但是当笔者阅读spring源码,捋顺容器加载过程中历经的流水线式操作,结合jvm虚拟机中类的加载机制,对象的实例化过程,笔者更加深刻的认识到,一个经得住考验的技术,势必是把代码做到了极度优雅的,举个例子,他们封装了一个个工厂,采用各种设计模式到容器中去实现生产,我们能在各种工厂的背影下总结出,好像各担其责,并没有繁复的判断逻辑。
设计模式也没有银弹,都是根据合适的场景去采用合适的设计模式,但是设计模式就默认实现了抽离与封装。
触发笔者写这篇文章的契机
笔者前段时间实现了一个基本没有冗余逻辑的平台,复现了笔者公司采用的部分架构细节,但是笔者发现基本每一个数据库表都能发现一些冗余字段,比如最后一次修改人,最后一次操作时间等记录性字段,当然记录性字段也有它存在的意义,比如数据错乱可以看到谁修改了,可以复现问题,便于修理bug,也可以追责。
那各位读者,我们假如使用mybatisPlus框架进行开发,现在给你商品实体与商品表,订单实体与订单表,两张表里都含有相同的字段updateLastTime(datetime)与updateLastPerson(varchar(32)),你该如何设计实体与表的映射关系呢?
传统的B站网课做法就不说了,mybatisX生成代码?@TableField与@TableId、@TableName注解建立映射?
这里笔者尝试使用抽离的思想实现:
1、将公共的字段抽离出来作为父类:
@NoArgsConstructor
@AllArgsConstructor(access = AccessLevel.PACKAGE)
@Data
@SuperBuilder(toBuilder = true)
public class BaseModel {
@TableField(value = "updateTime", fill = FieldFill.INSERT)
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime updateTime;
@TableField(value = "updatePersonName")
private String updatePersonName;
}2、子类建立传统的实体字段映射:
@EqualsAndHashCode(callSuper = true)
@Getter
@Setter
@AllArgsConstructor(access = AccessLevel.PACKAGE)
@NoArgsConstructor
@SuperBuilder(toBuilder = true)
@TableName("tb_products")
public class Product extends BaseModel {
@TableId(value = "Id", type = IdType.AUTO)
private Integer id;
@TableField("productName")
private String productName;
@TableField("status")
private Integer status;
@TableField("price")
private BigDecimal price;
@TableField("productDesc")
private String productDesc;
@TableField("inventory")
private int inventory;
@Override
public String toString() {
return "Product{" +
"id=" + id +
", productName='" + productName + '\'' +
", status=" + status +
", price=" + price +
", productDesc='" + productDesc + '\'' +
", inventory=" + inventory + '\'' +
", updateTime='" + getUpdateTime() + '\'' +
", updatePersonTime='" + getUpdatePersonName() + '\'' +
'}';
}
}这里有经验的读者会感觉这不是很常见的吗?用lombok注解@SuperBuilder使子类可以直接解析父类的属性(注意子父类都需要打上注解@SuperBuilder且给toBulider值为true),那这里读者们注意没注意这么做就是抽离的一种实现呢?笔者只是因这里的抽离产生了思考,并不是上述代码多么的优雅。
对于上述代码,笔者需要补充的是@EqualsAndHashCode(callSuper = true)这个注解的作用,它其实是为了使得两个继承了同一个父类的子类实例对比时(属性值对比),子类的全部属性都一致,这时要求他俩比较继承父类时产生的HashCode值,以此来实现父类属性的比较。
用Maven实现独特抽离: 打出本地依赖jar包并导入
这里很多读者会觉得不是有远程maven仓库了吗?阿里云的仓库下载速度快,为什么要使用自己本地的jar包呢?
笔者提出一个实际需求:当我们想造轮子,抽离优质逻辑并在日后的项目中都用到呢?我们肯定不会一味的复制粘贴吧?这里何不尝试使用maven的install与远程deploy呢?本地仓库下载依赖包与远程仓库上传更新依赖包。
那么笔者这里就给读者做一个简单的spring boot demo打到仓库变成依赖并使用新的demo导入它的步骤分享:
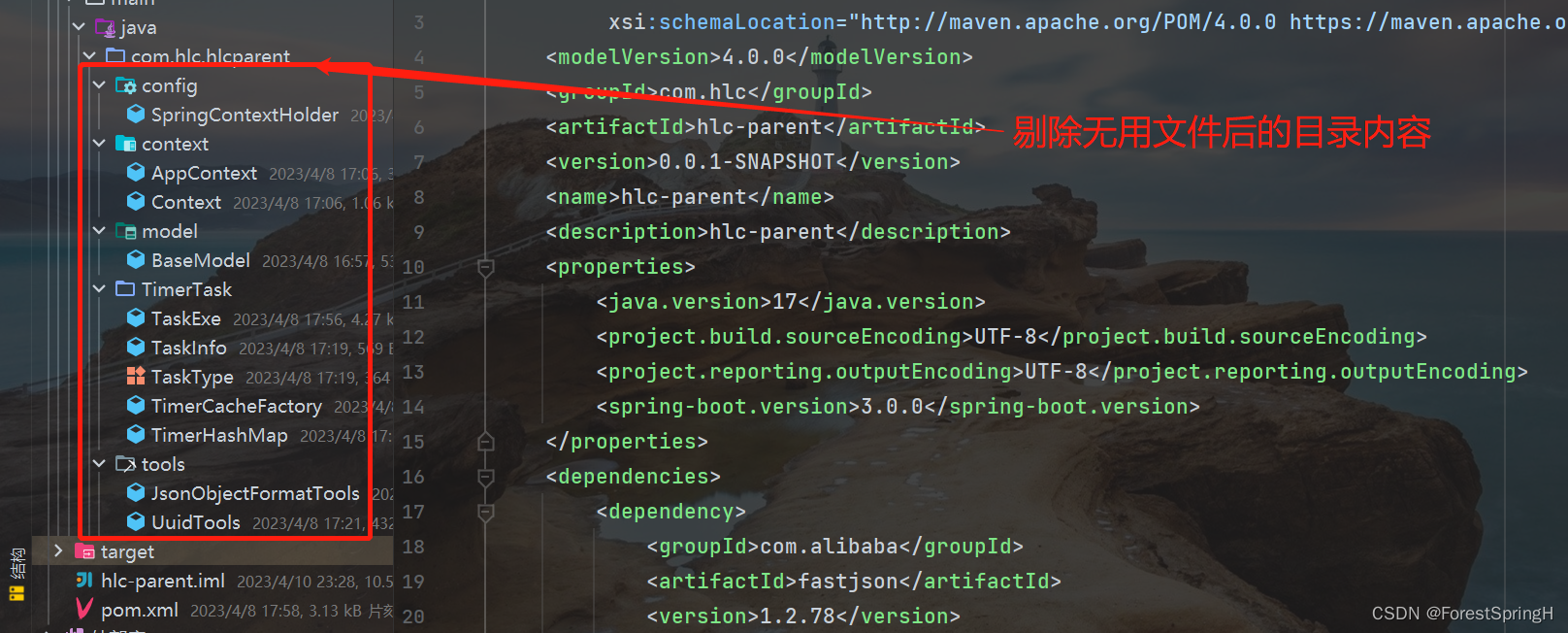
1、去掉没有用处的文件(starter类,resourse包,test包等与抽离无关的都可以丢弃),注意我们打成jar依赖的demo是不能自己启动的(读者也可以带着启动类打成依赖,笔者见过启动依赖里的应用程序的个案):
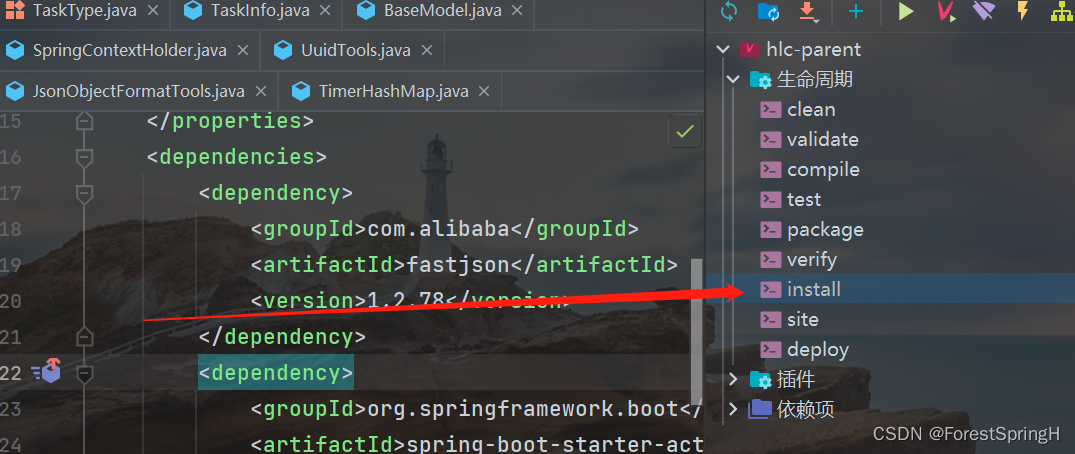
2、点击maven的install进行编译打包并进入本地仓库:
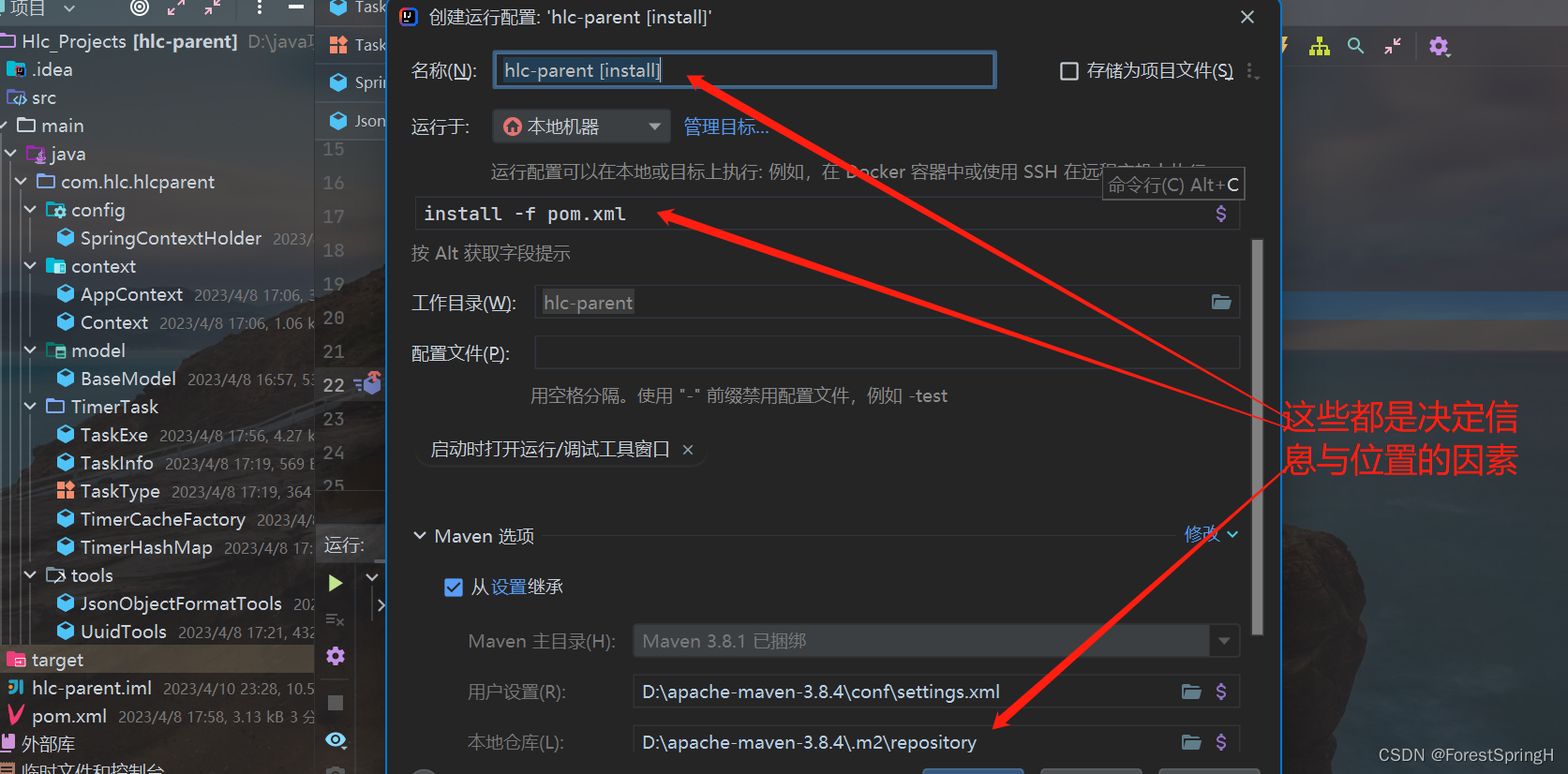
在此之前你可以自定义一些配置,仓库位置,包名,全路径等于你建立项目时的组名:
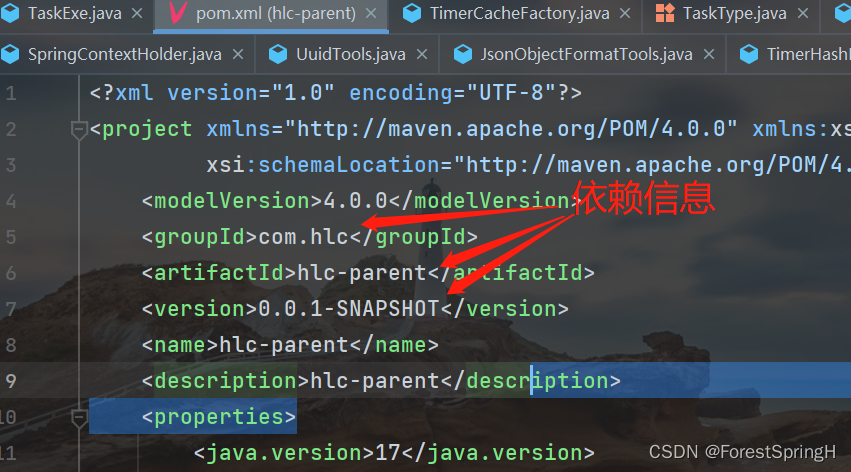
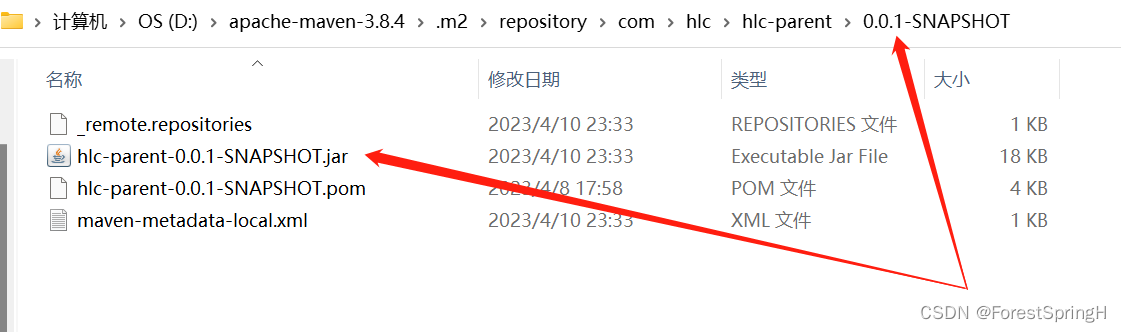
你的依赖信息打成包之后在仓库的位置就是com下的hlc下的hlc-parent中:
3、去仓库查看这个文件:
4、直接导入就可以了:
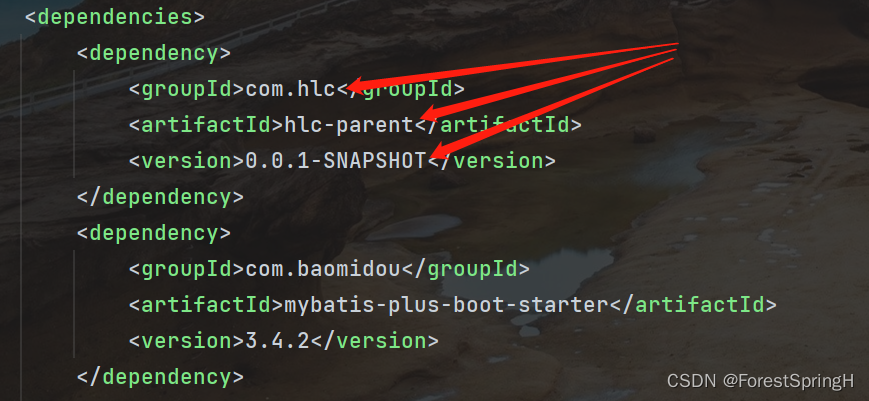
那么看到这儿,又能有多少读者能实际在自己的造轮子之旅上用到呢?
笔者也是个笨蛋,一个不会哭的笨蛋,硬着头皮在繁华中游泳,被浪花洗涤,被美丽的鱼儿咬破皮,被巨大的礁石威吓,但是笔者不想上船,离开了海洋,笔者也就成为了不想成为的自己。






![[Netty] FastThreadLocal (十四)](https://img-blog.csdnimg.cn/9ea96678b6644e3081f149a58dd24392.png)
![[架构之路-159]-《软考-系统分析师》-10-系统分析-6-现有业务流程分析, 系统分析最核心的任务](https://img-blog.csdnimg.cn/e83cacd385c64fa5a7278e09ffd3b3b4.png)
