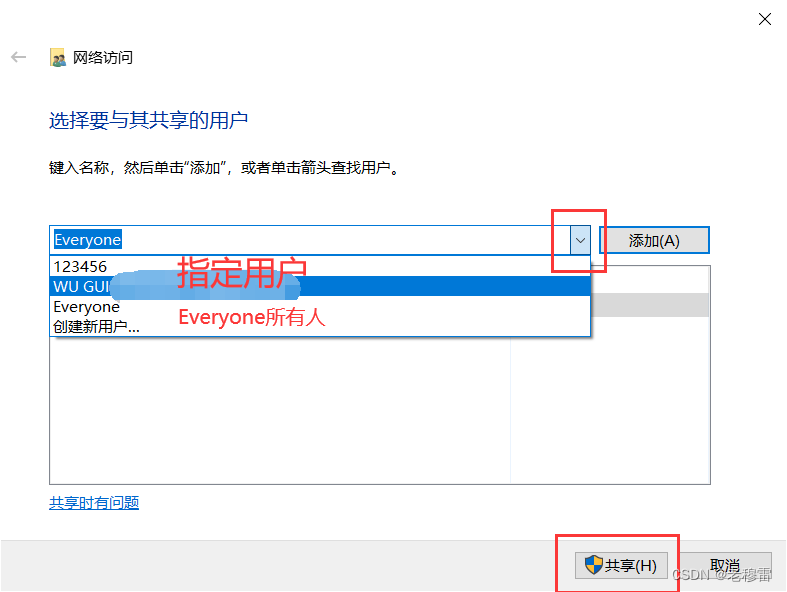
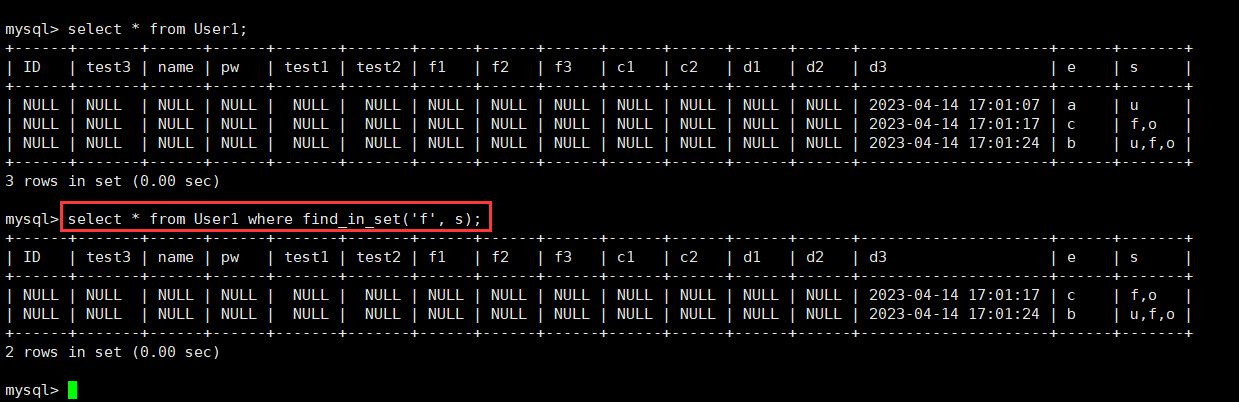
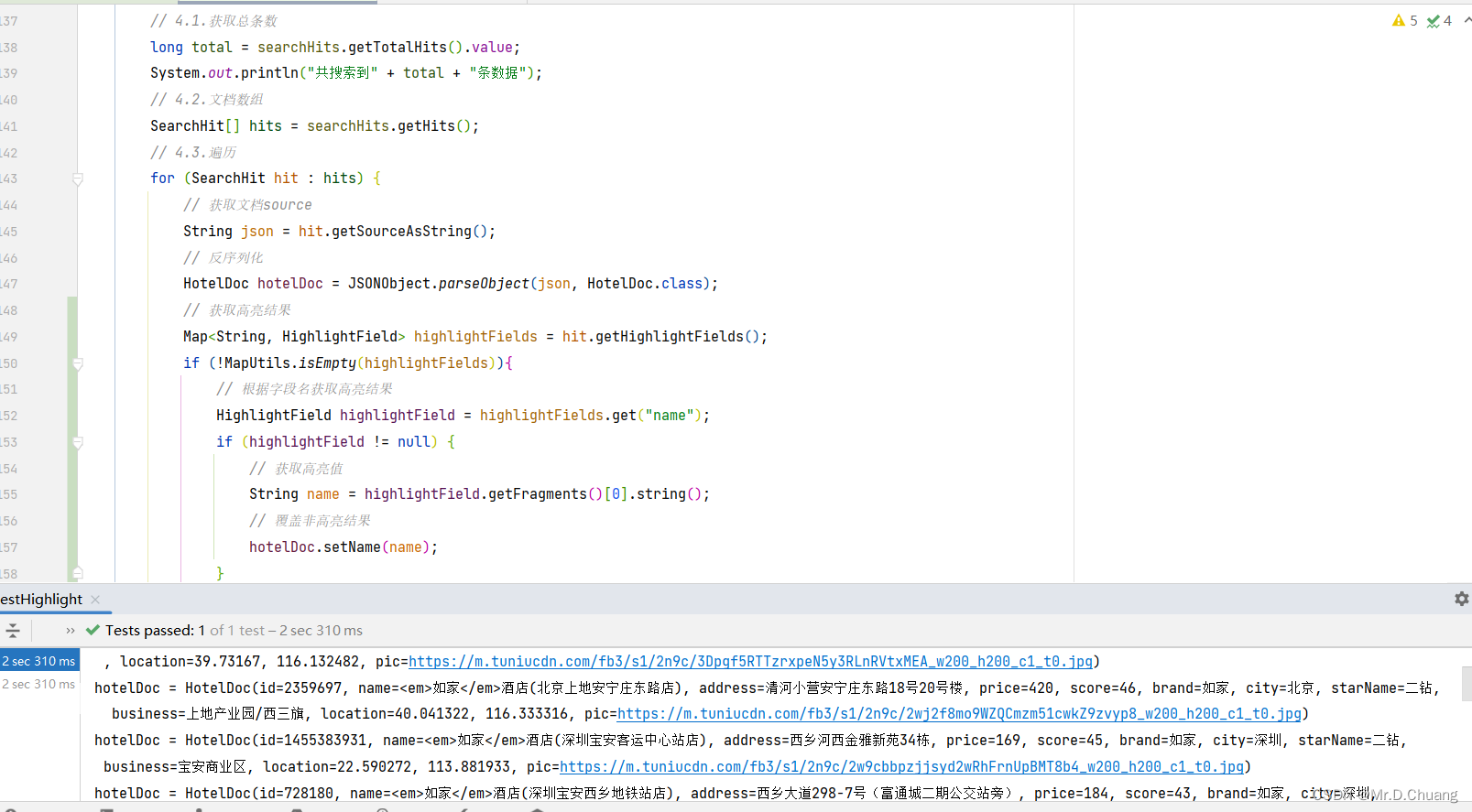
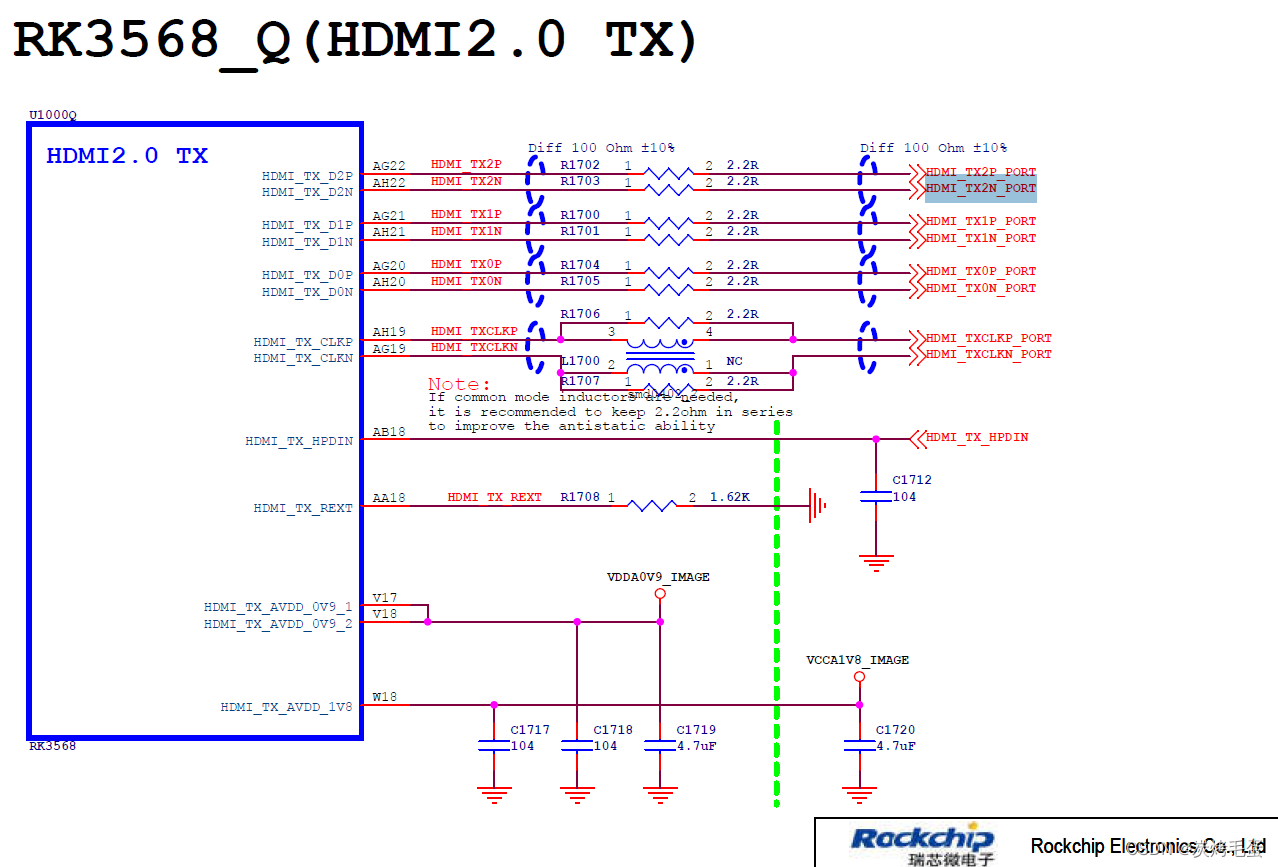
单纯是为了降低大LLM 设计的结构
当前如果transformers 可以 输出一个状态也是可以的
这样串联的好处是每次运行知识一个小模型的计算量
时间换空间的概念
可以训练100个模型而后根据需要进行微调
从100 个中选择一个预测比较接近的进行微调预测
预测后继续进行从100中选择 而后微调预测
不断微调预测
微调推理过程目前先条跳过
优化处理 训练过程和数据处理适配home 环境
epoch=10
batch_size=10
seq_len_max=10
output_dim=32
hidden_dim=128
input_dim=32