本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章中,我不仅会讲解多种解题思路及其优化,还会用多种编程语言实现题解,涉及到通用解法时更将归纳总结出相应的算法模板。
为了方便在PC上运行调试、分享代码文件,我还建立了相关的仓库。在这一仓库中,你不仅可以看到LeetCode原题链接、题解代码、题解文章链接、同类题目归纳、通用解法总结等,还可以看到原题出现频率和相关企业等重要信息。如果有其他优选题解,还可以一同分享给他人。
由于本系列文章的内容随时可能发生更新变动,欢迎关注和收藏征服LeetCode系列文章目录一文以作备忘。
相关公司:亚马逊
You are given the head of a linked list with n nodes.
For each node in the list, find the value of the next greater node. That is, for each node, find the value of the first node that is next to it and has a strictly larger value than it.
Return an integer array answer where answer[i] is the value of the next greater node of the ith node (1-indexed). If the ith node does not have a next greater node, set answer[i] = 0.
Example 1:
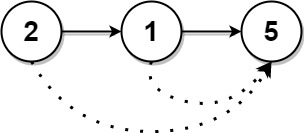
Input: head = [2,1,5]
Output: [5,5,0]
Example 2:
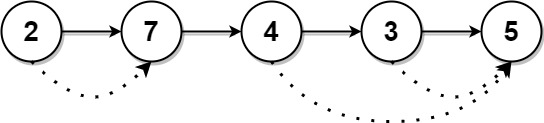
Input: head = [2,7,4,3,5]
Output: [7,0,5,5,0]
Constraints:
- The number of nodes in the list is
n. 1 <= n <= 10^41 <= Node.val <= 10^9
题意:给出一个链表,对链表中的每个元素,找到其后第一个大于它的元素,如果没有这样的元素,则为0。
解法1 从后往前+单调栈(用其他数更新每个元素的下个更大元素)
以下图为例,从数组说起,如何计算每个
a
[
i
]
a[i]
a[i] 的下一个更大的元素呢?——从后往前遍历
a
a
a ,我们就知道它右侧有哪些元素了,那么怎么维护这些元素呢?如果全部保留就和暴力没区别了。
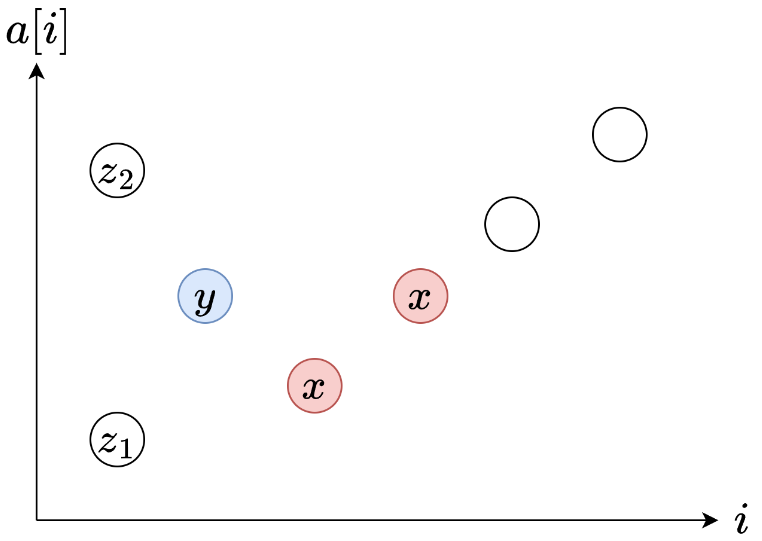
不难发现:
- 遍历到 y y y 时、后面的 x ≤ y x \le y x≤y 就没有用了,它一定不是 y y y 的下个更大元素。
- 且由于有 y y y 的存在,如果左边有个 z 1 < y z_1 < y z1<y ,这些 x x x 绝不会是 z 1 z_1 z1 的下个更大元素
- 如果左边有个 z 2 ≥ y z_2 \ge y z2≥y ,由于 z 2 ≥ y ≥ x z_2 \ge y \ge x z2≥y≥x ,这些 x x x 同样不是 z 2 z_2 z2 的下个更大的数。
- 这样一看, x x x 对前面的元素全 无 作 用,可以干掉它!
为此,我们需要一个底大顶小的单调栈(从右往左看)来维护这些信息。对于 y y y ,如果栈顶 ≤ y \le y ≤y ,就不断弹出栈顶,直到栈顶为空、或栈顶 > y > y >y 。如果栈非空,那么栈顶就是 y y y 的下个更大元素。
由于是链表,我们从头结点开始递归,在「归来」的过程中就相当于从右往左遍历链表了——反转链表属实不必要。
class Solution {
private int[] ans;
private final Deque<Integer> st = new ArrayDeque<>(); // 单调栈(节点值)
private void f(ListNode node, int i) {
if (node == null) {
ans = new int[i]; // i就是链表长度
return;
}
f(node.next, i + 1);
while (!st.isEmpty() && st.peek() <= node.val)
st.pop(); // 弹出无用数据
if (!st.isEmpty()) ans[i] = st.peek(); // 栈顶就是第i个节点的下个更大元素
st.push(node.val);
}
public int[] nextLargerNodes(ListNode head) {
f(head, 0);
return ans;
}
}
复杂度分析
- 时间复杂度: O ( n ) O(n) O(n) ,其中 n n n 为链表的长度。虽然写了个二重循环,但站在每个元素的视角看,这个元素在二重循环中最多入栈出栈各一次,因此整个二重循环的时间复杂度为 O ( n ) O(n) O(n) 。
- 空间复杂度: O ( n ) O(n) O(n) 。单调栈中最多有 O ( n ) O(n) O(n) 个数。
解法2 从前往后+单调栈(用每个数更新其他数的下一个更大元素)
从后往前可以,从前往后也行。姿势是很丰富滴……方法一是对每个
y
y
y ,找它的下个更大元素;反过来说,对每个
y
y
y ,它是哪些元素的下个更大元素?

不难发现,对于
x
<
y
x <y
x<y 来说,无论
y
y
y 右边的元素多小或多大,
y
y
y 就是
x
x
x 的命运、是
x
x
x 的下个更大元素。我们可以算出
x
x
x 的答案,然后
x
x
x 就没有任何作用了,可以扫地出门了!
类似方法一,用一个底大顶小的单调栈(从前往后看)。对于 y y y ,如果栈顶 < y <y <y ,那么就不断弹出栈顶,记录栈顶的答案为 y y y ,直到栈为空,或栈顶 ≥ y \ge y ≥y 。遍历结束后,栈中所有元素都没有下个更大元素,要把栈中的下标对应的 a n s ans ans 置为 0 0 0 。
class Solution {
public:
vector<int> nextLargerNodes(ListNode* head) {
vector<int> vals; // 记录原数组的值,随后vals[i]被赋值为大于它的第一个值
stack<int> pos; // 单调栈,只存下标
while (head) {
while (!pos.empty() && head->val > vals[pos.top()] ) { // 这里的vals代表原数组
vals[pos.top()] = head->val; // 被赋值为大于它的第一个值,且之后不会被修改和访问
pos.pop();
}
pos.push(vals.size()); // 当前ans的长度就是当前节点的下标
vals.push_back(head->val);
head = head->next;
}
while (!pos.empty()) vals[pos.top()] = 0, pos.pop(); // 剩下的就是没有下一个更大值的下标位置
return vals;
}
};
复杂度分析:
- 时间复杂度: O ( n ) O(n) O(n)
- 空间复杂度: O ( n ) O(n) O(n)