pytorch注意力机制
最近看了一篇大佬的注意力机制的文章然后自己花了一上午的时间把按照大佬的图把大佬提到的注意力机制都复现了一遍,大佬有一些写的复杂的网络我按照自己的理解写了几个简单的版本接下来就放出我写的代码。顺便从大佬手里盗走一些图片,等我有时间一起进行替换,在此特别鸣谢这位大佬。
链接: 大佬博客论文地址
SENet
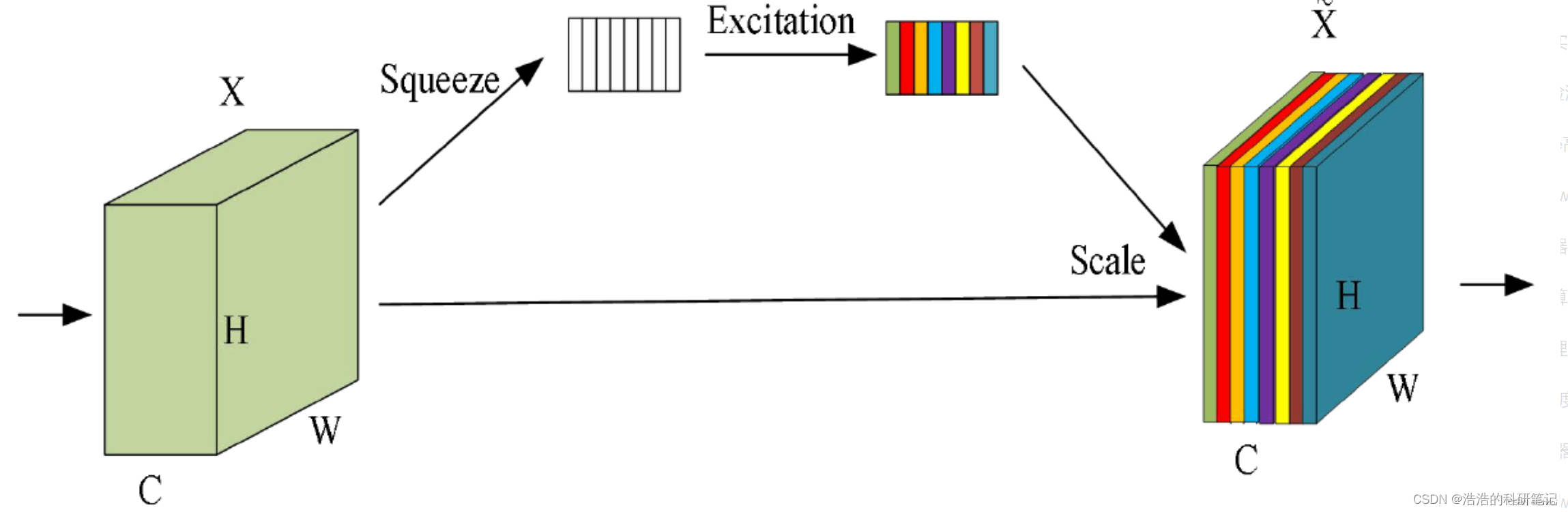
SE是一类最简单的通道注意力机制,主要是使用自适应池化层将[b,c,w,h]的数据变为[b,c,1,1],然后对数据进行维度变换
使数据变为[b,c]然后通过两个全连接层使数据变为[b,c//ratio]->再变回[b,c],然后使用维度变换重新变为[b,c,1,1],然后与输入数据相乘。
import torch
class SE_block(torch.nn.Module):
def __init__(self,in_channel,ratio):
super(SE_block, self).__init__()
self.avepool = torch.nn.AdaptiveAvgPool2d(1)
self.linear1 = torch.nn.Linear(in_channel,in_channel//ratio)
self.linear2 = torch.nn.Linear(in_channel//ratio,in_channel)
self.sigmoid = torch.nn.Sigmoid()
self.Relu = torch.nn.ReLU()
def forward(self,input):
b,c,w,h = input.shape
x = self.avepool(input)
x = x.view([b,c])
x = self.linear1(x)
x = self.Relu(x)
x = self.linear2(x)
x = self.sigmoid(x)
x = x.view([b,c,1,1])
return input*x
if __name__ == "__main__":
input = torch.randn((1,512,224,224))
model = SE_block(in_channel=512,ratio=8)
output = model(input)
print(output.shape)
ECAnet
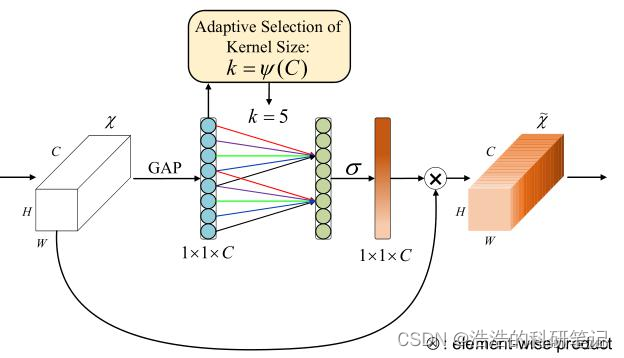
ECANet是SENet的改进版本中间使用卷积层来代替全连接层来实现ECA的通道注意力机制
import torch
import math
class ECA_block(torch.nn.Module):
def __init__(self,in_channel,gama=2, b=1):
super(ECA_block, self).__init__()
# 自适应核宽
kernel_size = int(abs(math.log(in_channel,2)+b)/gama)
kernel_size = kernel_size if kernel_size%2 else kernel_size + 1
self.ave_pool = torch.nn.AdaptiveAvgPool2d(1)
self.sigmoid = torch.nn.Sigmoid()
self.conv = torch.nn.Conv1d(in_channels=1,out_channels=1,kernel_size=kernel_size,padding=kernel_size//2)
def forward(self,input):
b,c,w,h = input.shape
x = self.ave_pool(input)
x = x.view([b,1,c])
x = self.conv(x)
x = self.sigmoid(x)
x = x.view([b,c,1,1])
return input*x
if __name__ == "__main__":
input = torch.randn((1,512,224,224))
model = ECA_block(in_channel=512)
output = model(input)
print(output.shape)
CMBA
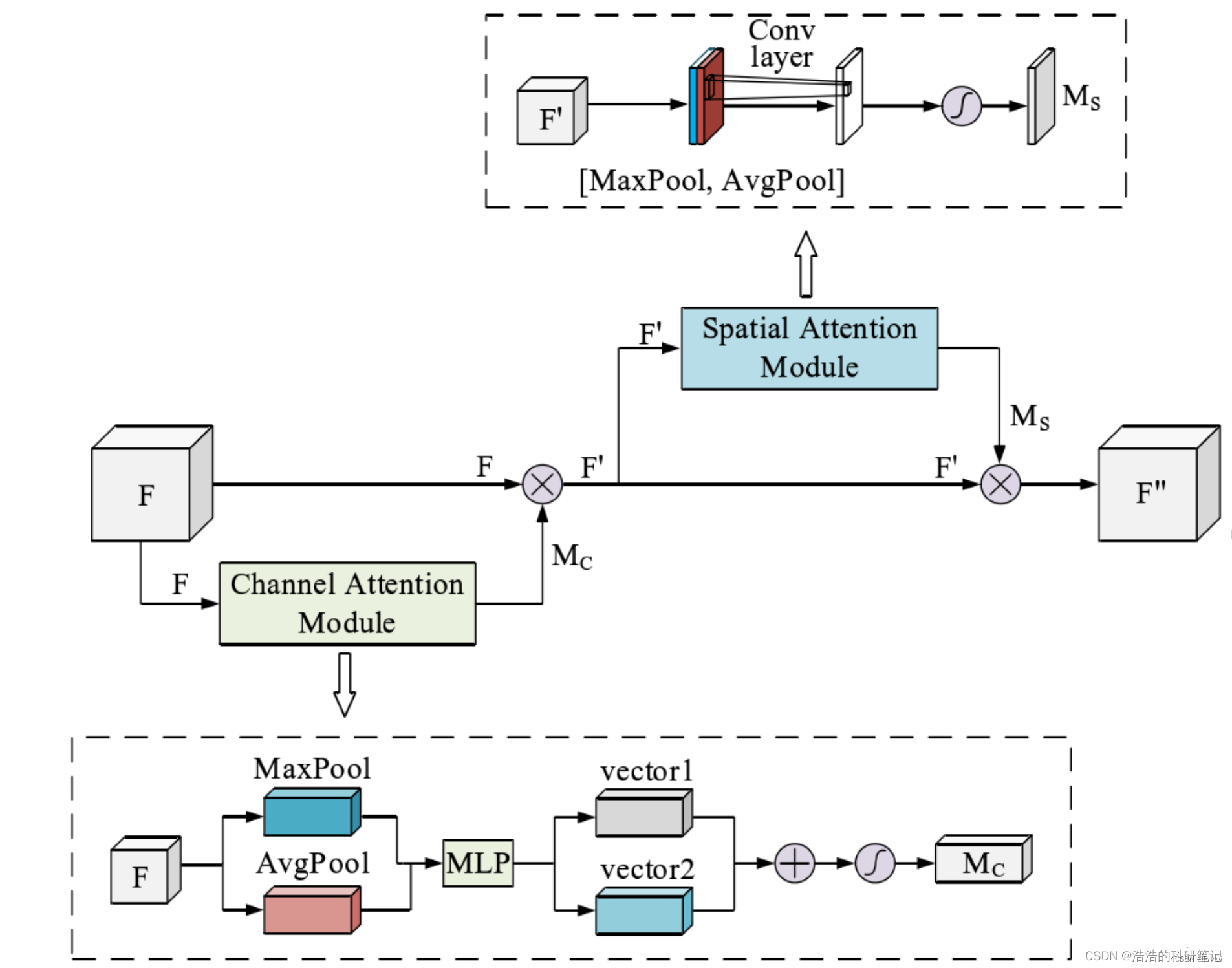
CMBA注意力机制模块将数据依次通过通道注意力机制和空间注意力机制
import torch
class channel_attention(torch.nn.Module):
def __init__(self,in_channel,ratio):
super(channel_attention, self).__init__()
self.ave_pool = torch.nn.AdaptiveAvgPool2d(1)
self.max_pool = torch.nn.AdaptiveMaxPool2d(1)
self.linear1 = torch.nn.Linear(in_channel,in_channel//ratio)
self.linear2 = torch.nn.Linear(in_channel//ratio,in_channel)
self.relu = torch.nn.ReLU()
self.sigmoid = torch.nn.Sigmoid()
def forward(self,input):
b,c,w,h = input.shape
ave = self.ave_pool(input)
max = self.max_pool(input)
ave = ave.view([b,c])
max = ave.view([b,c])
ave = self.relu(self.linear1(ave))
max = self.relu(self.linear1(max))
ave = self.sigmoid(self.linear2(ave))
max = self.sigmoid(self.linear2(max))
x = self.sigmoid(ave+max).view([b,c,1,1])
return x*input
class spatial_attention(torch.nn.Module):
def __init__(self,kernel_size = 7):
super(spatial_attention, self).__init__()
self.conv = torch.nn.Conv2d(2,1,kernel_size=kernel_size,padding=kernel_size//2)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,input):
b,c,w,h = input.shape
max,_ = torch.max(input,dim=1,keepdim=True)
ave = torch.mean(input,dim=1,keepdim=True)
x = torch.cat([ave,max],dim=1)
x = self.conv(x)
x = self.sigmoid(x)
return x*input
class CMBA(torch.nn.Module):
def __init__(self,in_channel,ratio,kernel_size):
super(CMBA, self).__init__()
self.channel_attention = channel_attention(in_channel=in_channel,ratio=ratio)
self.spatial_attention = spatial_attention(kernel_size=kernel_size)
def forward(self,x):
x = self.channel_attention(x)
x = self.spatial_attention(x)
return x
if __name__ == "__main__":
input = torch.randn((1,512,224,224))
# model = channel_attention(in_channel=512,ratio=8)
# model = spatial_attention(kernel_size=7)
model = CMBA(in_channel=512,ratio=8,kernel_size=7)
output = model(input)
print(output.shape)
SKnet
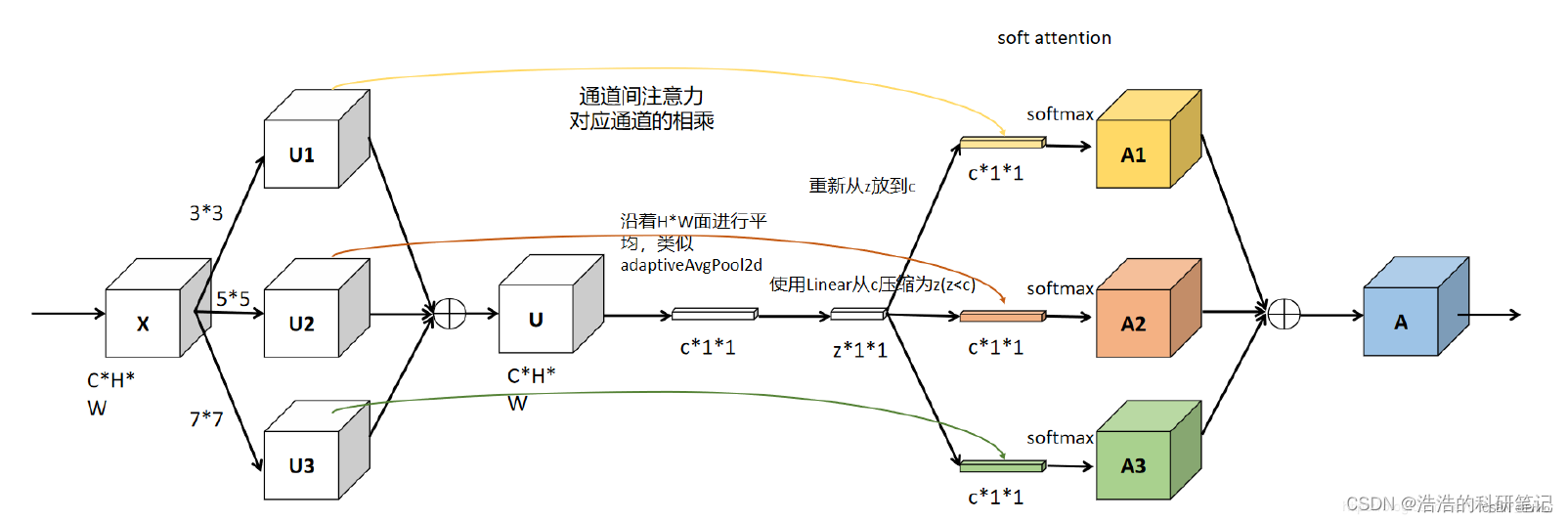
这是一个给予多个感受野的卷积核的通道注意力机制
目前这个代码是CPU的代码如想使用GUP的SKNet请联系作者
import torch
# 获得layer_num=3个卷积层
class convlayer(torch.nn.Sequential):
def __init__(self,in_channel,layer_num=3):
super(convlayer, self).__init__()
for i in range(layer_num):
layer = torch.nn.Conv2d(in_channel,in_channel,kernel_size=i*2+3,padding=i+1)
self.add_module('convlayer%d'%(i),layer)
# 获得layer_num=3个用于反向压缩卷积的线性层
class linearlayer(torch.nn.Sequential):
def __init__(self,in_channel,out_channel,layer_num=3):
super(linearlayer, self).__init__()
for i in range(layer_num):
layer = torch.nn.Linear(in_channel,out_channel)
self.add_module('linearlayer%d'%(i),layer)
class SK(torch.nn.Module):
def __init__(self,in_channel,ratio,layer_num):
super(SK, self).__init__()
self.conv = convlayer(in_channel,layer_num)
self.linear1 = torch.nn.Linear(in_channel,in_channel//ratio)
self.linear2 = linearlayer(in_channel//ratio,in_channel,layer_num)
self.softmax = torch.nn.Softmax()
self.ave = torch.nn.AdaptiveAvgPool2d(1)
def forward(self,input):
b,c,w,h = input.shape
# 用来保存不同感受野的加和
x = torch.zeros([b,c,w,h])
# 存储每个感受野的输出
x_list = []
# 使用感受野不同的卷积层输出不同的值
for i in self.conv:
# 得到对应卷积层的结果
res = i(input)
# 保存每个卷积层的输出
x_list.append(res)
# 对输出求和
x += res
# 进行全局平均池化进行压缩
x = self.ave(x)
# 对数据进行维度变化方便进入线性层
x = x.view([b,c])
# 将维度变化之后的数据通道第一个线形层
x = self.linear1(x)
# 新建一个变量保存输出
output = torch.zeros([b,c,w,h])
for j,k in enumerate(self.linear2):
# 使用第j个全连接层进行数据升维
s = k(x)
# 改变数据结构
s = s.view([b,c,1,1])
# 进行softmax
s = self.softmax(s)
# 将softmax的值与卷积分支的结果相乘然后相加
output += s*x_list[j]
return output
if __name__ == "__main__":
input = torch.randn((1,512,224,224))
model = SK(512,8,3)
print(model(input).shape)
SCSE
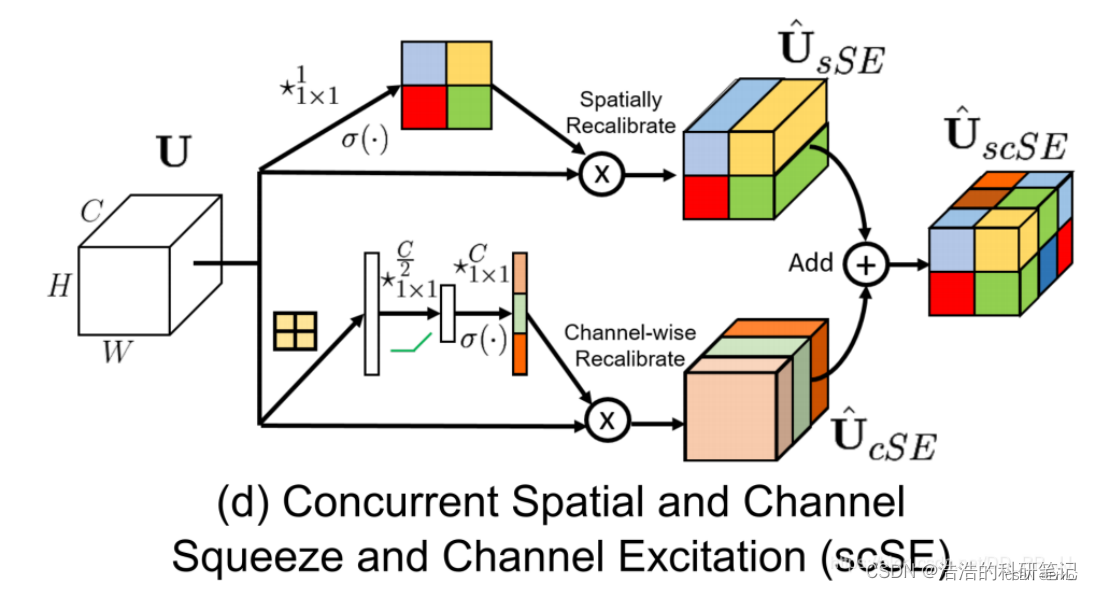
本注意力机制是将数据分别通过空间注意力机制和通道注意力机制然后再相加的一种注意力机制
import torch
class sSE(torch.nn.Module):
def __init__(self,in_channel):
super(sSE, self).__init__()
self.conv = torch.nn.Conv2d(in_channel,1,kernel_size=1,bias=False)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,input):
x = self.conv(input)
x = self.sigmoid(x)
return input*x
class cSE(torch.nn.Module):
def __init__(self,in_channel):
super(cSE, self).__init__()
self.ave = torch.nn.AdaptiveAvgPool2d(1)
self.conv1 = torch.nn.Conv2d(in_channel,in_channel//2,1,bias=False)
self.conv2 = torch.nn.Conv2d(in_channel//2, in_channel,1,bias=False)
self.sigmoid = torch.nn.Sigmoid()
self.relu = torch.nn.ReLU()
def forward(self,input):
x = self.ave(input)
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.sigmoid(x)
return x*input
class SCSE(torch.nn.Module):
def __init__(self,in_channel):
super(SCSE, self).__init__()
self.cse = cSE(in_channel)
self.sse = sSE(in_channel)
def forward(self,x):
out_cse = self.cse(x)
out_sse = self.sse(x)
return out_cse+out_sse
if __name__ == "__main__":
input = torch.randn((1,512,224,224))
# model = sSE(in_channel=512)
# model = cSE(in_channel=512)
model = SCSE(in_channel=512)
print(model(input).shape)
NoLocalNet
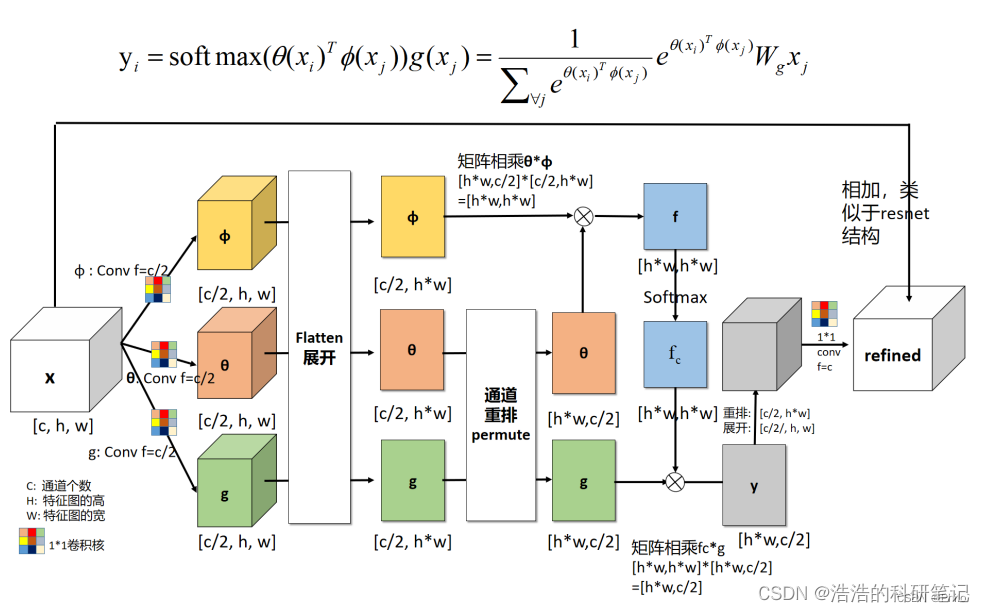
本注意力机制是使用三个卷积核然后互相进行矩阵相乘的注意力机制最终将相乘的成功与输入相加
import torch
class NonLocalNet(torch.nn.Module):
def __init__(self,in_channel):
super(NonLocalNet, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channel,in_channel//2,1)
self.conv2 = torch.nn.Conv2d(in_channel,in_channel//2,1)
self.conv3 = torch.nn.Conv2d(in_channel,in_channel//2,1)
self.conv4 = torch.nn.Conv2d(in_channel//2,in_channel,1)
self.softmax = torch.nn.Softmax(dim=-1)
def forward(self,input):
b,c,w,h = input.shape
c1 = self.conv1(input).view([b,c//2,w*h])
c2 = self.conv2(input).view([b,c//2,w*h]).permute(0,2,1)
c3 = self.conv3(input).view([b,c//2,w*h]).permute(0,2,1)
f = torch.bmm(c2,c1)
f = self.softmax(f)
y = torch.bmm(f,c3).permute(0,2,1).view([b,c//2,w,h])
y = self.conv4(y)
return y+input
if __name__ == "__main__":
input = torch.randn((1,24,100,100))
model = NonLocalNet(in_channel=24)
print(model(input).shape)
GCnet
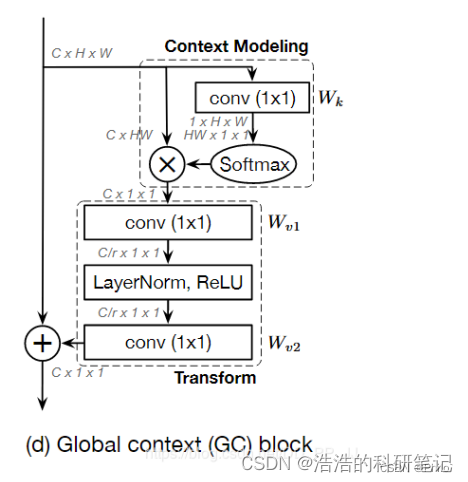
本注意力机制使用了类似SENet的分支结构
import torch
class GC(torch.nn.Module):
def __init__(self,in_channel,ratio):
super(GC, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channel,1,kernel_size=1)
self.conv2 = torch.nn.Conv2d(in_channel,in_channel//ratio,kernel_size=1)
self.conv3 = torch.nn.Conv2d(in_channel//ratio,in_channel,kernel_size=1)
self.softmax = torch.nn.Softmax(dim=1)
self.ln = torch.nn.LayerNorm([in_channel//ratio,1,1])
self.relu = torch.nn.ReLU()
def forward(self,input):
b,c,w,h = input.shape
x = self.conv1(input).view([b,1,w*h]).permute(0,2,1)
x = self.softmax(x)
i = input.view([b,c,w*h])
x = torch.bmm(i,x).view([b,c,1,1])
x = self.conv2(x)
x = self.ln(x)
x = self.relu(x)
x = self.conv3(x)
return x+input
if __name__ == "__main__":
input = torch.randn((1,24,100,100))
model = GC(in_channel=24,ratio=8)
print(model(input).shape)