文章目录
- 一、clip论文阅读
- 二、prompt
- 1.除prompt之外的预训练语言模型
- 2.prompt
- 2.1. prompt定义
- 2.2. prompt类型
- 2.3. prompt重构
- `2.3.1 prompt template`
- `2.3.2 Answer engineering`
- 2.4 多个 prompt的使用
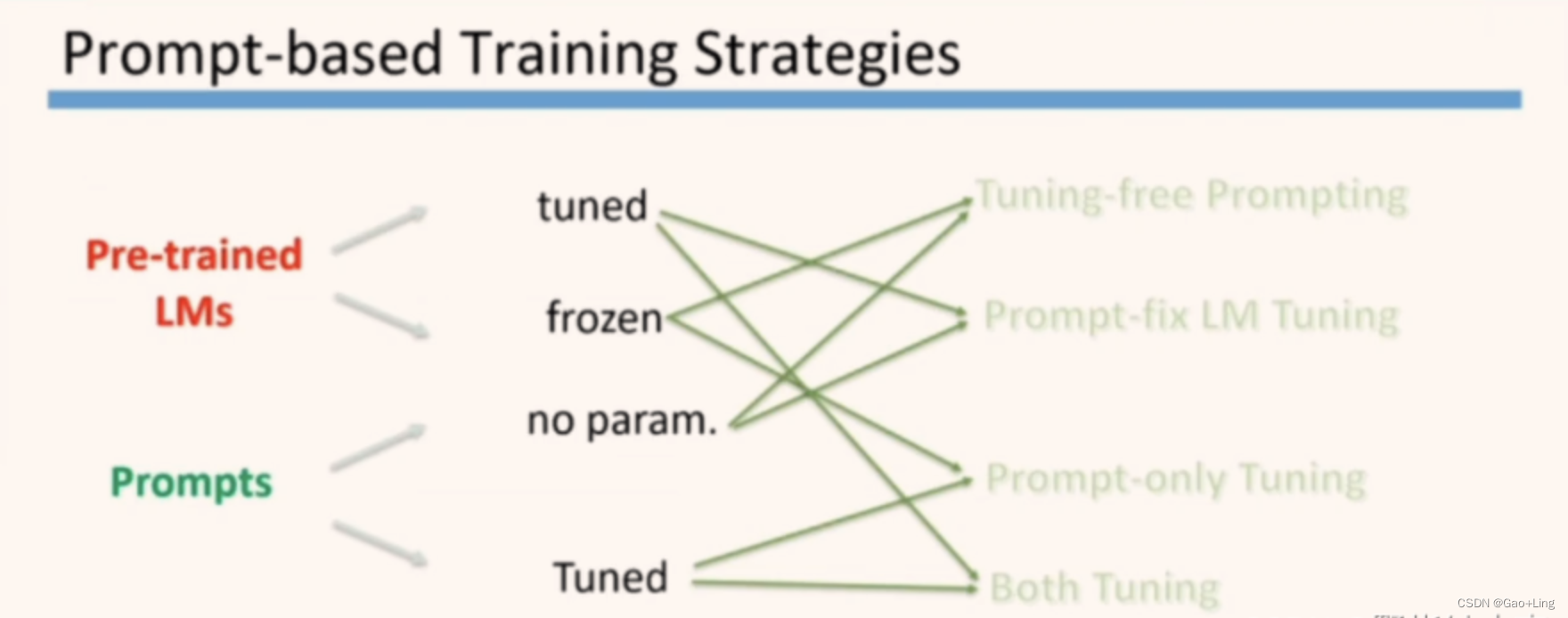
- 2.5 prompt的训练
- 总结
- 参考(博文、论文)
一、clip论文阅读
论文阅读是跟随沐神视频:CLIP 论文逐段精读【论文精读】
二、prompt
在阅读clip论文时,注意到里面提到的prompt。所以想了解并学习一下。
1.除prompt之外的预训练语言模型

这三种预训练语言模型需要人力
- feature engineering 需要人工提取特征
- architecture engineering 需要人工设计网络结构
- objective engineering 需要人工设计目标函数
2.prompt
2.1. prompt定义
prompt learning :提示学习
prompt learning 对 输入的文本信息 按照 特定模板 进行处理把任务重构成一个 更能够充分利用预训练语言模型处理的形式 。
以情感分析为例,传统情感分析是如下的:
Input: 你是个好人。
Output: positive 或 negative
而采用 prompt learning 的话,输入输出就会变为如下:
Input: 你是个好人。那么她____和你耍朋友。
Output: 想 或者 不想
简而言之:
将输入文本作为一个 提示(prompt),接着拼一个语句,再让模型来对这个语句进行完形填空。
prompt 的重构方式可以总结为:
- 输入数据不变;
- 给定一个 prompt 模板;
- 给定一个答案范围。(后面会分别简单讲解这三个步骤)
进行完形填空的目的是,因为 BERT 的训练任务就是做完形填空。就是为了让下游任务更适配语言模型,而基于目标工程的预训练语言模型则是让模型去适配下游任务比如传统的 BERT 要做情感分析还要在输入时第一个位置添加一个 [CLSL,然后输出这个ICLS] 的隐藏状态后还要再接全连接层才能预测情感标签),
下图展示了几个不同的语言模型之间的关系(图来自刘鹏飞大佬的论文中):
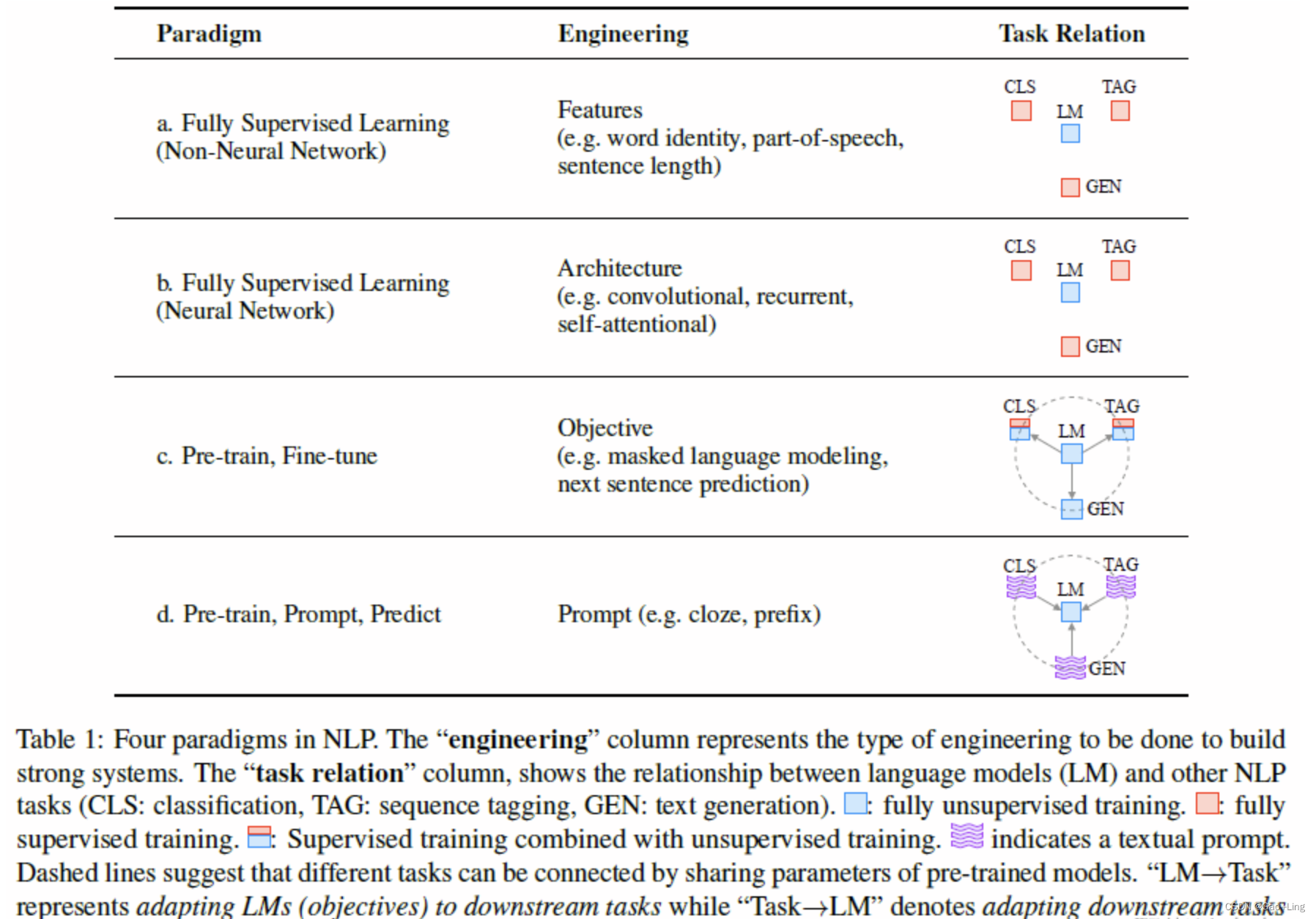
与前三种预训练语言模型一样,prompt learning 同样需要人工在里面,即人工设计 提示模板(prompt template)和 答案模板(answer template)。
2.2. prompt类型
prompt 分为了两类:cloze prompt 和 prefix prompt。
首先介绍一下4种预训练方法:
由于每一类 prompt 都要让下游任务满足 预训练方法,所以作者在论文里把这些方法抽象成了以下4种。
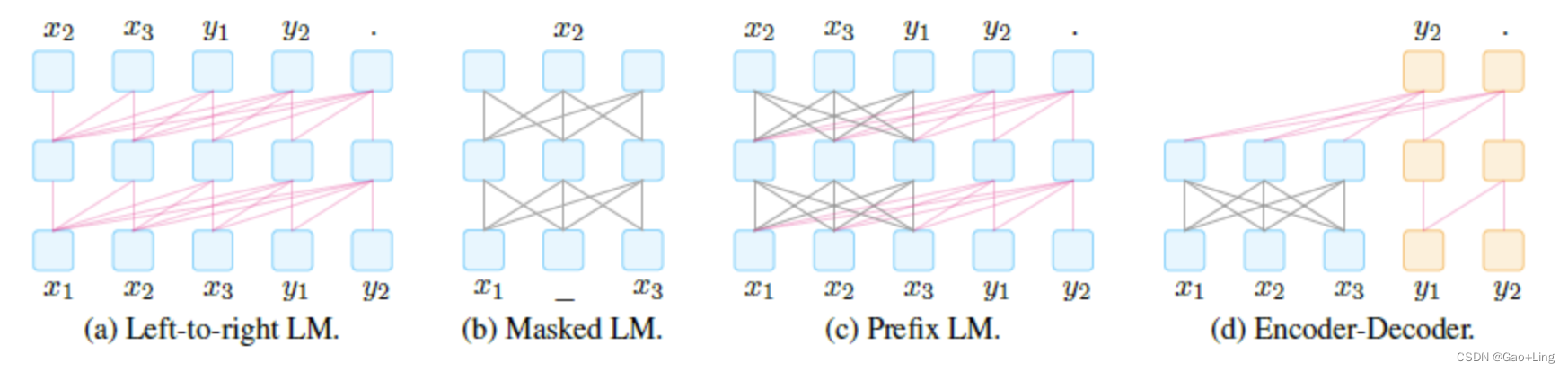

基于以上4种预训练语言类型,我们再来讨论两类 prompt:cloze prompt 和 prefix prompt
cloze prompt:在 prompt 中有插槽 (slot) 的类型为 cloze prompt
这类 prompt 就是需要模型去填充这个 slot。这类可以选用 L2R LM (ELMo) 或者 Masked LM (BERT) 来实现。prefix prompt:输入的文本全部在 answer 前的类型为 prefix prompt
这类 prompt 通常是需要模型去预测或者生成这个 slot。这类模型可以选用 L2R LM (RNN),Prefix LM,以及 Encoder-Decoder (GPT) 去实现。
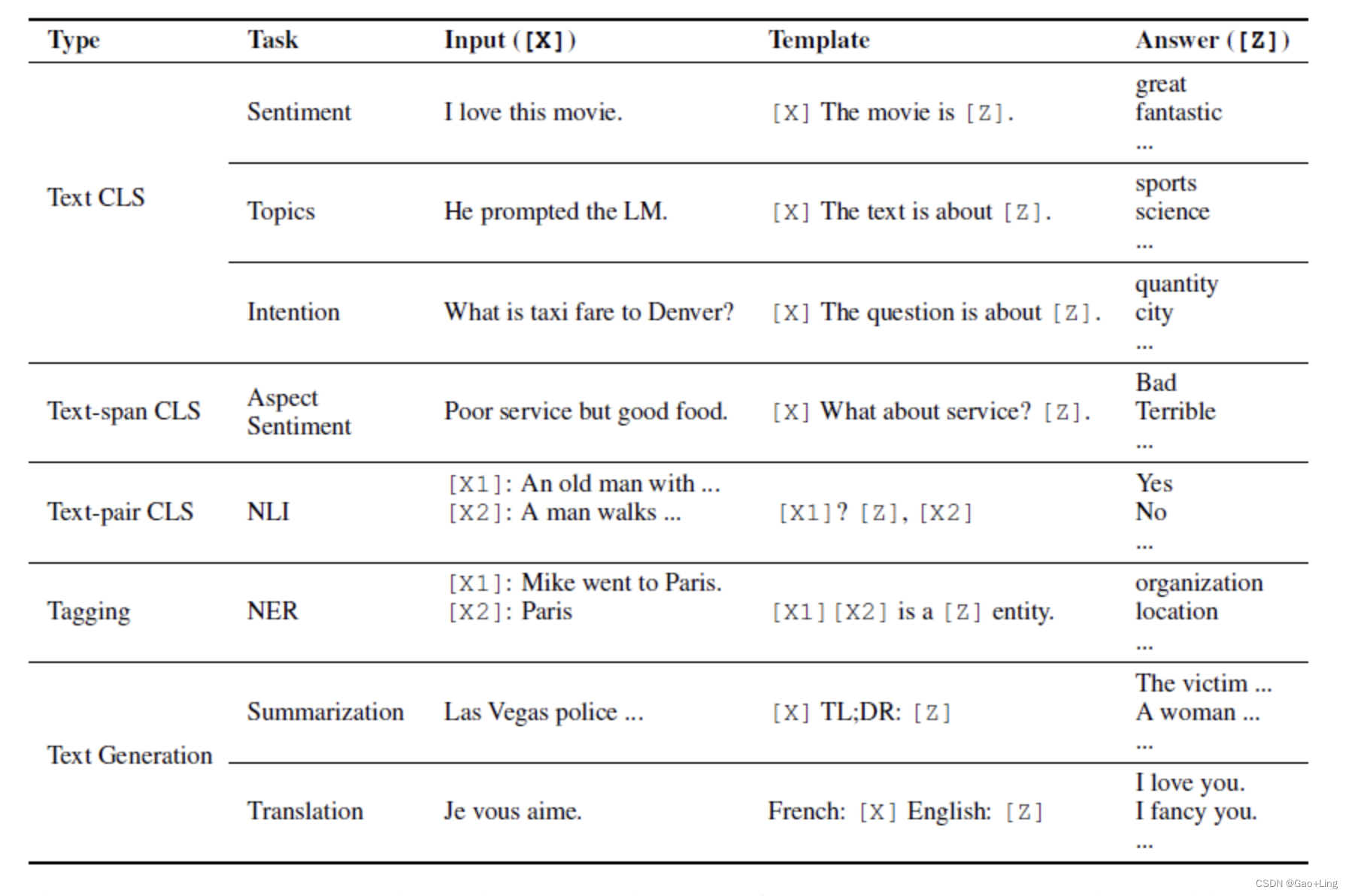
针对不同任务的 prompt 都可以用下表展示:
2.3. prompt重构
在 prompt 重构的过程中,就需要两个关键的模板:prompt template 和 answer template。
2.3.1 prompt template
有两种方法来生成:人工设计模板和自动生成模板
人工设计模板:人工设计模板是最直观的方法。抽象来看,设文本为 [ X ],插槽为 [ Z ],人工设计的模板为 [ X ] template words [ Z ]。
尽管这样非常直觉,易于理解,而且无需额外的计算代价,但是人工设计模板有很大的缺陷:- 人工设计模板是很花费时间且需要先验知识的;
- 人工设计也会有失败的情况在内。
为了解决上面的问题,就提出了通过训练的方式自动生成模板。
自动生成模板: 自动生成模板有两种类型。discrete prompts(离散提示, a. k. a. hard prompts),这类型 prompts 就是让模型在一组离散模板的空间中选择一个最优的模板。continuous prompts(连续提示, a. k. a. soft prompts),这类型 prompts 就是让语言模型自动训练一个 prompts 出来。
2.3.2 Answer engineering
Answer engineering 目的是找到一个答案 **[ Z ]**的空间,并且将这个空间映射到输出的标签 y上。
答案会有三种种类,tokens (比如文本分类),span (比如方面级情感分析中的方面识别),Sentence (比如机器翻译)。
与 prompt engineering 相同,answer engineering 同样有人工设计与自动获取两种方法。
人工设计答案: 人工设计分为两类 [ Z ]空间。- Unconstrained spaces 中的 [ Z ]空间包含了输出空间的所有结果,token 级的话则是全部词表中的词 (比如 W2V 的输出层),其余类型相同。这类方法可以直接找到 [ Z ]与 y的映射关系。
- Constrained spaces,这类方法通常输出是在一个限定范围内 (比如 positive 和 negative),这类方法就需要一个映射关系来映射 [ Z ]与 y。
自动学习答案: 与 prompt engineering 相同,有 discrete answer search 和 continuous answer searchdiscrete promptscontinuous prompts
2.4 多个 prompt的使用
根据研究显示,使用多个 prompt 可以有效提升性能。 由于多个 prompt 集成后,每个 prompt 都会有一个输出,对这些输出我们也需要有相应的取舍。最简单的方法就是对每个 prompt 的输出概率求和取平均。但是这样有个问题就是可能有的 prompt 占比高,有的占比低,于是就有了带权平均方法。也有研究是采用 majority voting 的方法 (我没看过论文,但是我个人觉得就是对于分类问题,选择最多分类的那一类)。还有采用知识蒸馏和集成做文本分类的方法
对于 prompt ensembling有以下四种方法:
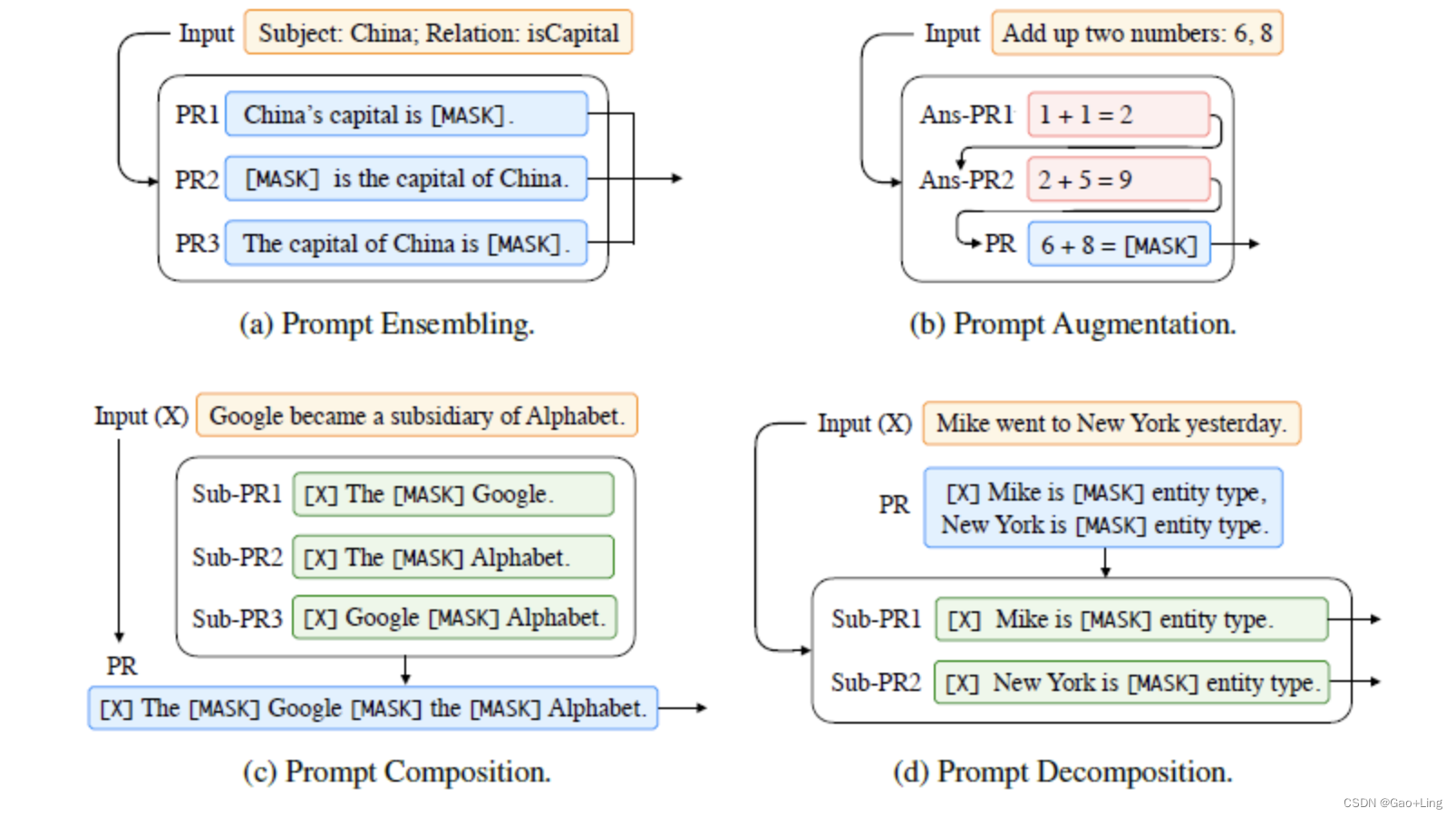

2.5 prompt的训练

总结
Prompt Learning激活了很多新的研究场景,比如小样本学习,可以成为那些GPU资源受限研究者的福音。
Prompt Learning最重要的一个作用在于给我们prompt(提示)了NLP发展可能的核心动力是什么。
参考(博文、论文)
参考的博文:
博主:野指针小李
参考的论文:
刘鹏飞大佬的论文