文章目录
- 方法
- 实验
- Limitation
论文:https://arxiv.org/abs/2303.10438
代码:https://github.com/wpy1999/SAT/blob/main/Model/SAT.py
方法
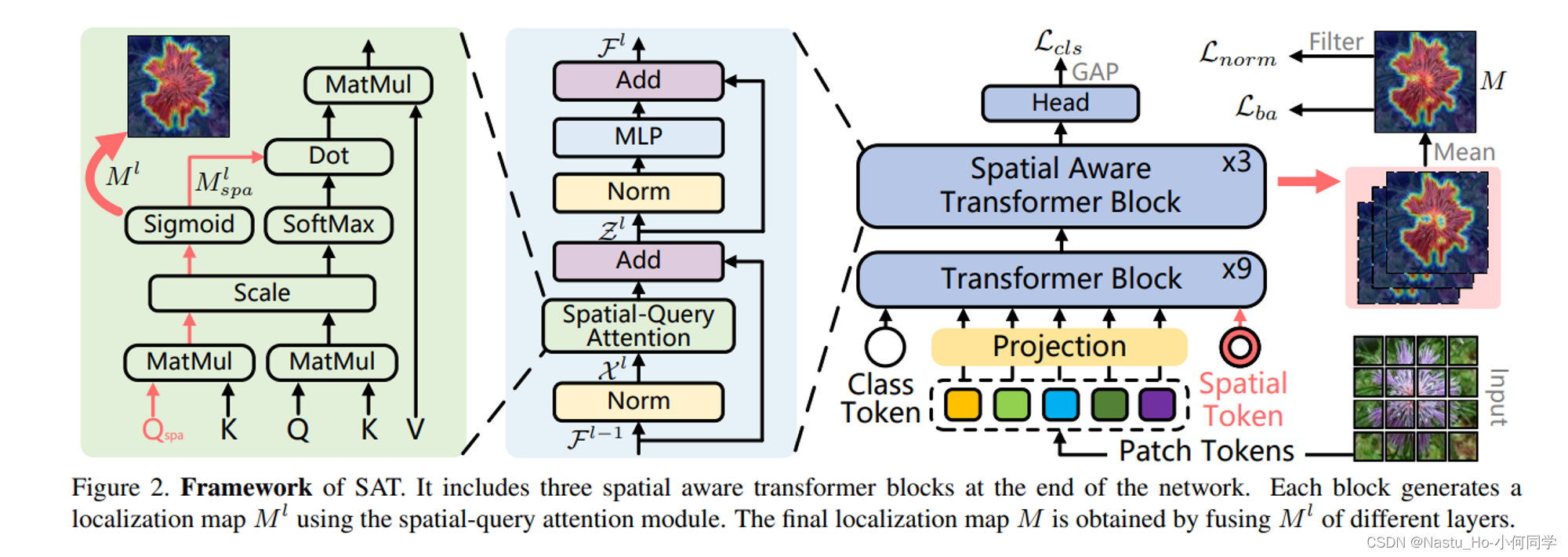
这篇文章的方法应该属于FAM这一类。
-
额外添加的一个spatial token,从第10-12层开始,利用其得到的attn map (对hea求mean–B, 1, 1, N+2) 作为visual cue去指出oject region,作用方式为将attn map 点乘到 attn weights(B, h, N+2, N+2)
-
attn map得到的方式:不同与attn weights 是经过softmax,它这里是经过Sigmoid的。至于为什么,可能是Sigmoid后得到的map 激活更完整吧
-
最后的localization map是将前面L层的attn map求mean。虽然这种方法可以最大限度地捕获分类网络中的定位信息,但是从图像级标签获得的像素级监督是稀疏和不平衡的。为了补偿和加强这种监督,我们设计了批量区域损失和归一化损失。
-
Bach Area Loss
L b a = ∣ ∑ b B ∑ i H ∑ j W ( λ − M b ( i , j ) B × H × W ) ∣ \mathcal{L}_{b a}=\left|\sum_{b}^{B} \sum_{i}^{H} \sum_{j}^{W}\left(\lambda-\frac{M_{b}(i, j)}{B \times H \times W}\right)\right| Lba= b∑Bi∑Hj∑W(λ−B×H×WMb(i,j))
让激活区域更紧致,这类Loss这WSOL和WSSS很常见。
where λ is a sparse area supervision with prior knowledge.The λ is set to 0.25 and 0.35 on CUB-200 and ImageNet.
-
Normalization Loss
L norm = 1 H × W ∑ i H ∑ i W M ∗ ( i , j ) ( 1 − M ∗ ( i , j ) ) \mathcal{L}_{\text {norm }}=\frac{1}{H \times W} \sum_{i}^{H} \sum_{i}^{W} M^{*}(i, j)\left(1-M^{*}(i, j)\right) Lnorm =H×W1i∑Hi∑WM∗(i,j)(1−M∗(i,j))
增强前-背景的区分度。应该会使得前景的激活响应更强,背景的激活响应更弱。
在计算这个loss之前先用高斯滤波对loc map处理,增强局部一致性。(那为什么batch area loss之前 不先用高斯滤波处理??)
-
-
分类就跟之前transformer-based的方法一样,将patch token 变回feature map的形式,经过一层3x3 conv 后接avgpooling
注意:这篇文章的定位仅依赖于spatial token 带来的 attn map,不同与一些之前transformer-based的方法将attn map 与 semantic map 耦合。
实验
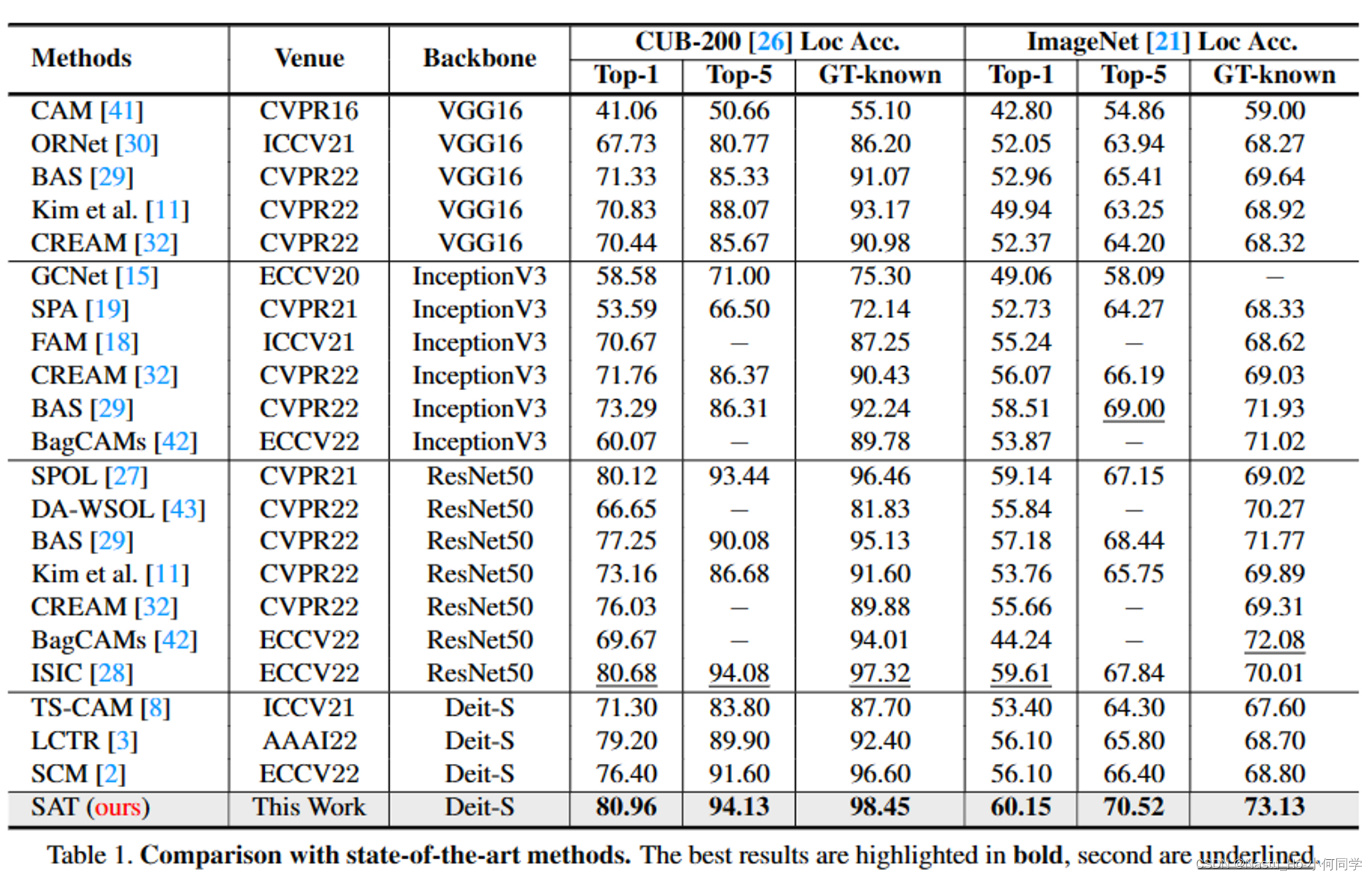
现有方法对比
在ImageNet上的消融,四幅图对应四种情况
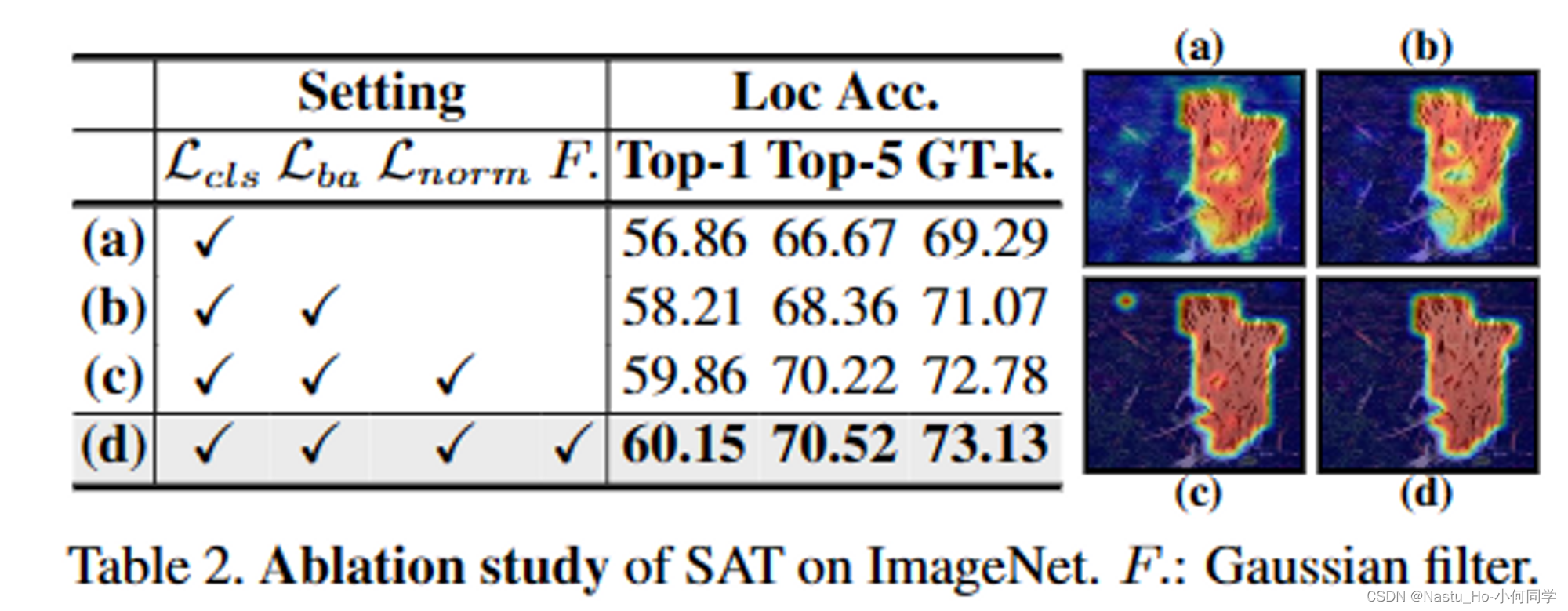
area loss 和 normalization loss 效果我比较关注;
不同backone下验证
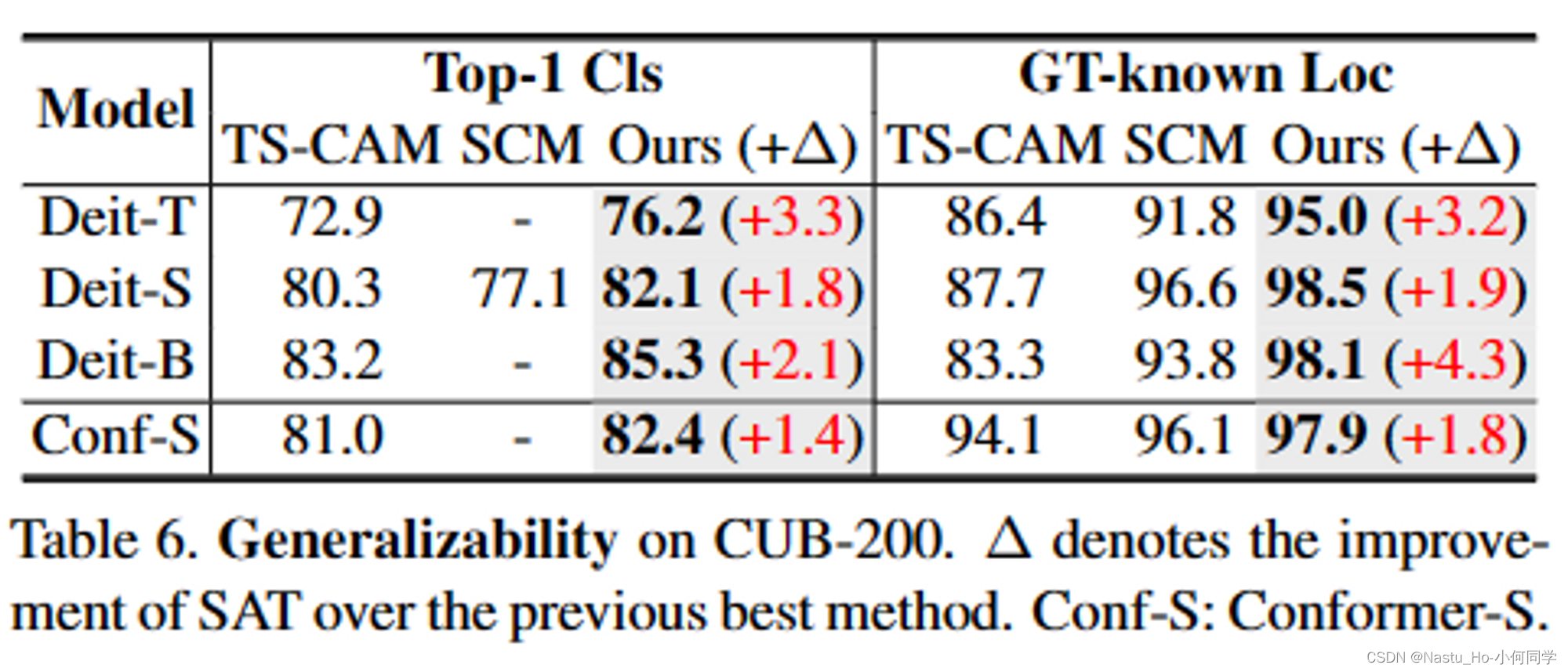
为什么要额外加一个spatial token 而不直接利用原有的cls token?

文章里从优化角度解释
Limitation

在ImageNet上应该会有更多困难的情况。