【备注】部分图片引至他人博客,详情关注参考链接
【PS】query 、 key & value 的概念其实来源于推荐系统。基本原理是:给定一个 query,计算query 与 key 的相关性,然后根据query 与 key 的相关性去找到最合适的 value。举个例子:在电影推荐中。query 是某个人对电影的喜好信息(比如兴趣点、年龄、性别等)、key 是电影的类型(喜剧、年代等)、value 就是待推荐的电影。在这个例子中,query, key 和 value 的每个属性虽然在不同的空间,其实他们是有一定的潜在关系的,也就是说通过某种变换,可以使得三者的属性在一个相近的空间中。
1.综述
Transformer是一个利用注意力机制来提高模型训练速度的模型。关于注意力机制可以参看这篇文章,trasnformer可以说是完全基于自注意力机制的一个深度学习模型,因为它适用于并行化计算,和它本身模型的复杂程度导致它在精度和性能上都要高于之前流行的RNN循环神经网络。
那什么是transformer呢?
你可以简单理解为它是一个黑盒子,当我们在做文本翻译任务是,我输入进去一个中文,经过这个黑盒子之后,输出来翻译过后的英文。

那么在这个黑盒子里面都有什么呢?
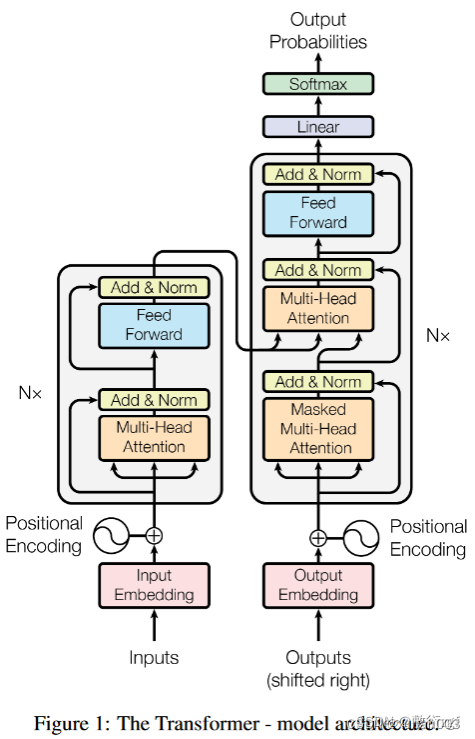
里面主要有两部分组成:Encoder 和 Decoder

当我输入一个文本的时候,该文本数据会先
经过一个叫Encoders的模块,对该文本进行编码,然后将编码后的数据再传入一个叫Decoders的模块进行解码,解码后就得到了翻译后的文本,对应的我们称Encoders为编码器,Decoders为解码器。
那么编码器和解码器里边又都是些什么呢?
细心的同学可能已经发现了,上图中的Decoders后边加了个s,那就代表有多个编码器了呗,没错,这个编码模块里边,有很多小的编码器,一般情况下,Encoders里边有6个小编码器,同样的,Decoders里边有6个小解码器。

我们看到,在编码部分,每一个的小编码器的输入是前一个小编码器的输出,而每一个小解码器的输入不光是它的前一个解码器的输出,还包括了整个编码部分的输出。
整个的transformer流程图如下:
2.embedding
对于要处理的一串文本,我们要让其能够被计算机处理,需要将其转变为词向量,方法有最简单的one-hot,或者有名的Word2Vec等,甚至可以随机初始化词向量。具体的实现细节参考本人博客:Word2vec词向量文本分析详解,
经过Embedding后,文本中的每一个字就被转变为一个向量
,能够在计算机中表示。《Attention is all you need》这一论文中,作者采用的是
512维词向量
表示,也就是说,每一个字被一串长度为512的字向量表示。
3.Positional Encoding
首先为什么需要位置编码?我们对于RNN在处理文本时,由于天然的顺序输入,顺序处理,当前输出要等上一步输出处理完后才能进行,因此不会造成文本的字词在顺序上或者先后关系出现问题。但对于Transformer来说,由于其在处理时是并行执行,虽然加快了速度,但是忽略了词字之间的前后关系或者先后顺序。同时Transformer基于Self-Attention机制,而self-attention不能获取字词的位置信息,即使打乱一句话中字词的位置,每个词还是能与其他词之间计算出attention值,因此我们需要为每一个词向量添加位置编码。
那么位置编码如何计算?
这是《Attention is all you need》论文中给出的计算公式。
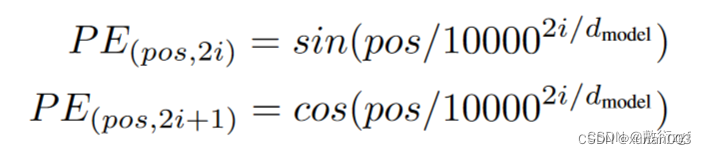
pos表示字词的位置,2i表示在512维词向量中的偶数位置,2i+1表示在512维词向量中的奇数位置,dmodel表示词向量的维度(例如为512);公式表达的含义是在偶数的位置使用sin函数计算,在奇数的位置使用cos函数计算,如下图。
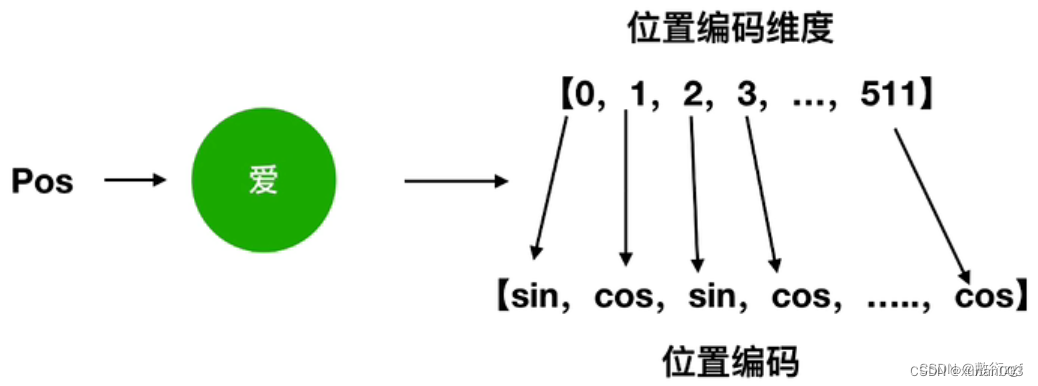
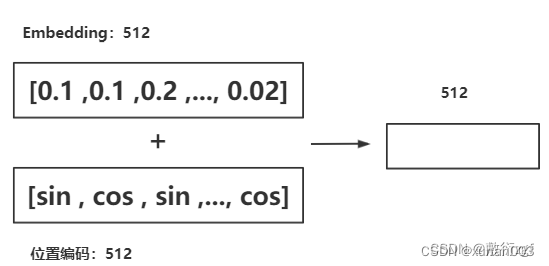
得到512维的位置编码后,我们将512维的位
置编码与512维的词向量相加,得到
最终的512维词向量
作为最终的Transformer输入。
4.Encoder
放大一个encoder,发现里边的结构是一个自注意力机制加上一个前馈神经网络。

5.self-attention
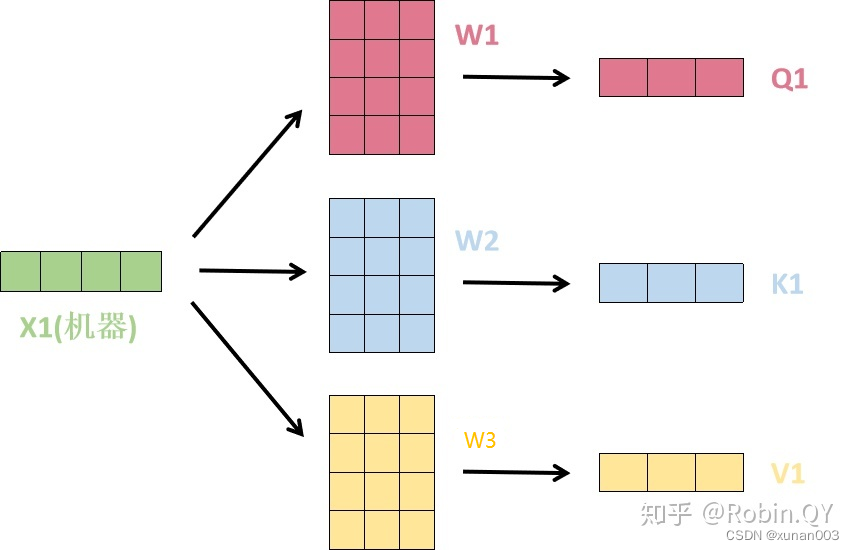
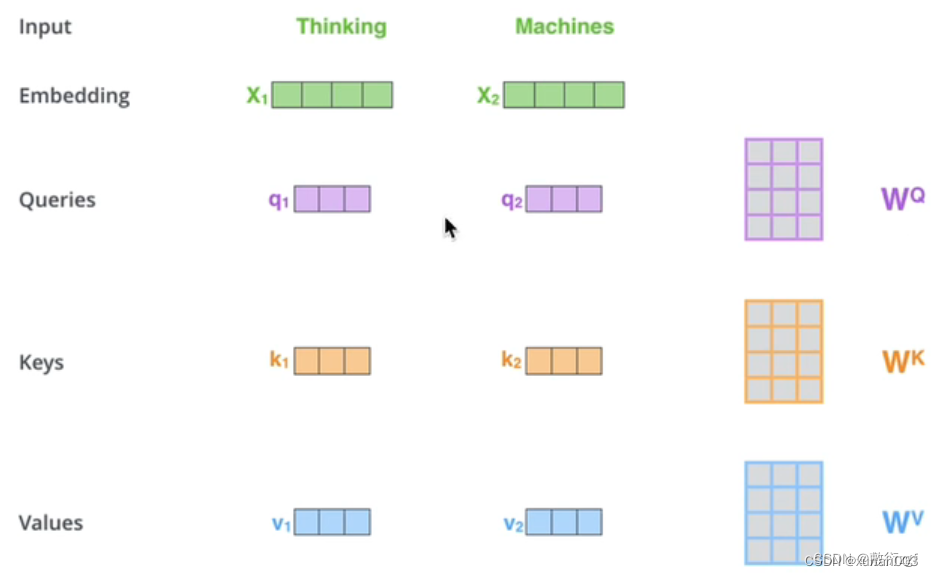
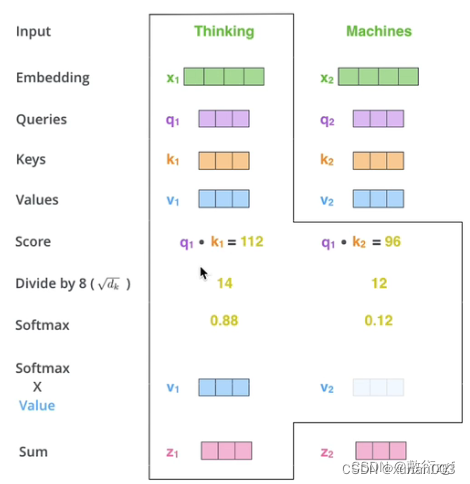
首先,self-attention的输入就是词向量,即整个模型的最初的输入是词向量的形式。那自注意力机制呢,顾名思义就是自己和自己计算一遍注意力,即对每一个输入的词向量,我们需要构建self-attention的输入。在这里,transformer首先将词向量乘上三个矩阵,得到三个新的向量,之所以乘上三个矩阵参数而不是直接用原本的词向量是因为这样增加更多的参数,提高模型效果。对于输入X1(Thinking),乘上三个矩阵后分别得到Q1,K1,V1,同样的,对于输入X2(Machines),也乘上三个不同的矩阵得到Q2,K2,V2。
那接下来就要计算注意力得分了,这个得分是通过计算Q与各个单词的K向量的点积得到的。我们以X1为例,分别将Q1和K1、K2进行点积运算,假设分别得到得分112和96。
将得分分别除以一个特定数值8(K向量的维度的平方根,通常K向量的维度是64)这能让梯度更加稳定。
将上述结果进行softmax运算得到,softmax主要将分数标准化,使他们都是正数并且加起来等于1。
将V向量乘上softmax的结果,这个思想主要是为了保持我们想要关注的单词的值不变,而掩盖掉那些不相关的单词(例如将他们乘上很小的数字)。
步骤结果如下图:
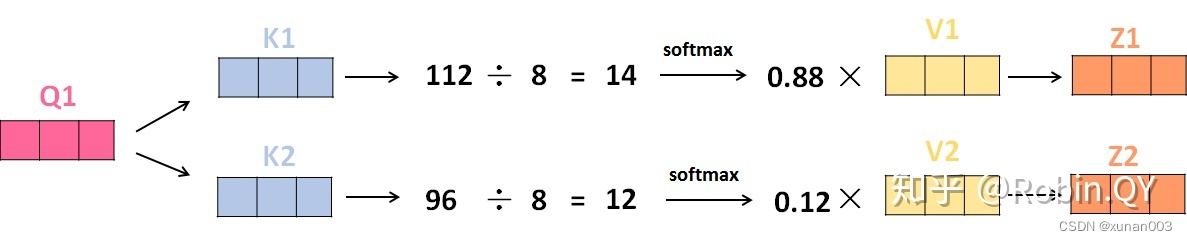
将带权重的各个Z向量加起来,至此,产生在这个位置上(第一个单词)的self-attention层的输出,其余位置的self-attention输出也是同样的计算方式。

将上述的过程总结为一个公式就可以用下图表示(其中dk一般取64):
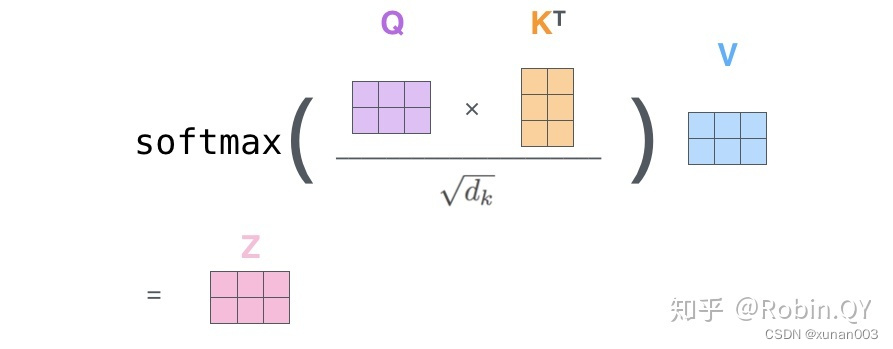
在上面的案例中,有两个序列“Thinking”,“Machines”,那么X矩阵第一行表示“Thinking”,第二行表示“Machines”,X矩阵是2×512维。权重矩阵WQ,WK,WV都是512×64维的【这里的64 = 512 / 8 (8:表示论文中作者定义多头个数)】,因此得到的Query、Keys、Values三个矩阵都是2×64维的。
得到Query、Keys、Values三个矩阵后,计算Attention Value,步骤如下:
a. 将Query(2×64)矩阵与Keys矩阵的转置(64×2)相乘,【作者论文中采用的是两个矩阵点积,当然还可以采用其他方式计算相似度得分(余弦相似度,MLP等)】得到相关性得分score(2×2);
b. 将相关性得分score / 根号下(dk),dk=64是矩阵Keys的维度,这样可以保证梯度稳定;
c. 进行softmax归一化,将相关性评分映射到0-1之间,得到一个2×2的概率分布矩阵α
d. 将概率分布矩阵α与Values矩阵进行点积运算,得到(2×2) ⊙ (2×64) = 2×64 维的句子Z。
6.MultiHead-attention
为了进一步细化自注意力机制层,增加了“多头注意力机制”的概念。
对于多头自注意力机制,我们不止有一组Q/K/V权重矩阵,而是有多组(论文中使用8组),所以每个编码器/解码器使用8个“头”(可以理解为8个互不干扰自的注意力机制运算),每一组的Q/K/V都不相同。然后,得到8个不同的权重矩阵Z,每个权重矩阵被用来将输入向量投射到不同的表示子空间。
在Transformer中使用的是MultiHead Attention,其实这玩意和Self Attention区别并不是很大。先明确以下几点,然后再开始讲解:
a. MultiHead的head不管有几个,参数量都是一样的。并不是head多,参数就多。
b. 当MultiHead的head为1时,并不等价于Self Attetnion,MultiHead Attention和Self Attention是不一样的东西
c. MultiHead Attention使用的也是Self Attention的公式
d. MultiHead除了 Wq, Wk, Wv
三个矩阵外,还要多额外定义一个Wo
。
而MultiHead Attention在带入公式前做了一件事情,就是拆,它按照“词向量维度”这个方向,将Q,K,V拆成了多个头,如图所示:
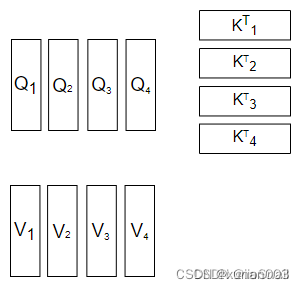
这里我的head数为4。既然拆成了多个head,那么之后的计算,也是各自的head进行计算,如图所示:
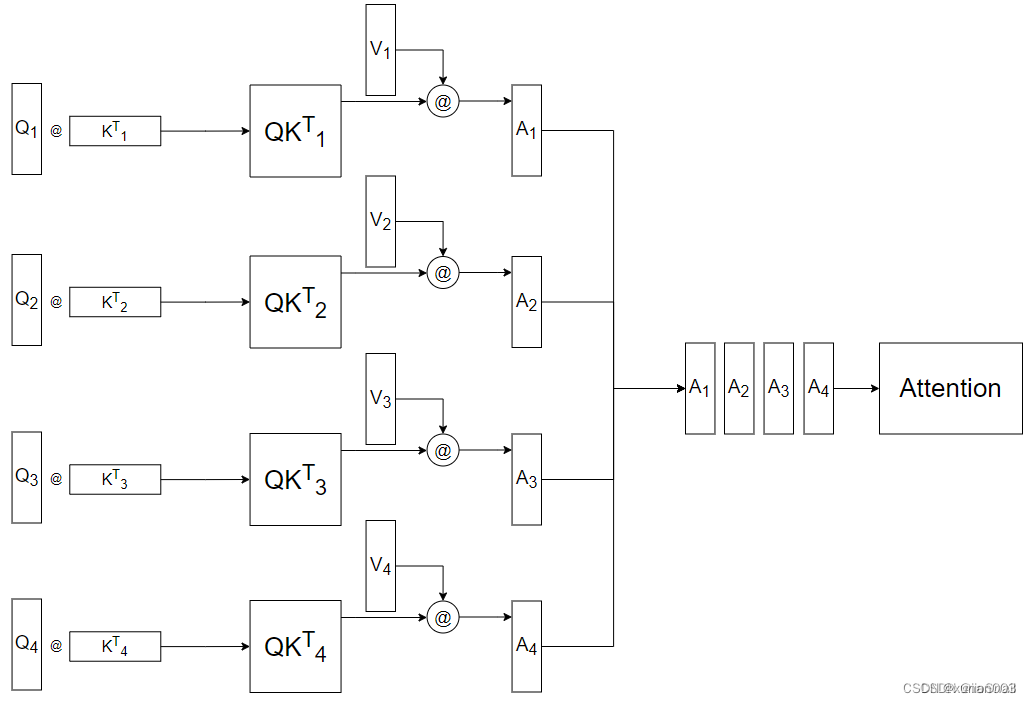
但这样拆开来计算的Attention使用Concat进行合并效果并不太好,所以最后需要再采用一个额外的Wo矩阵,对Attention再进行一次线性变换。
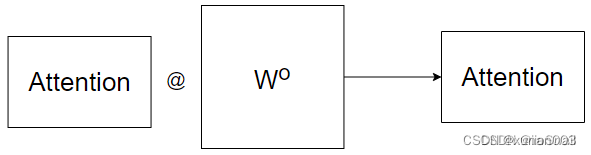
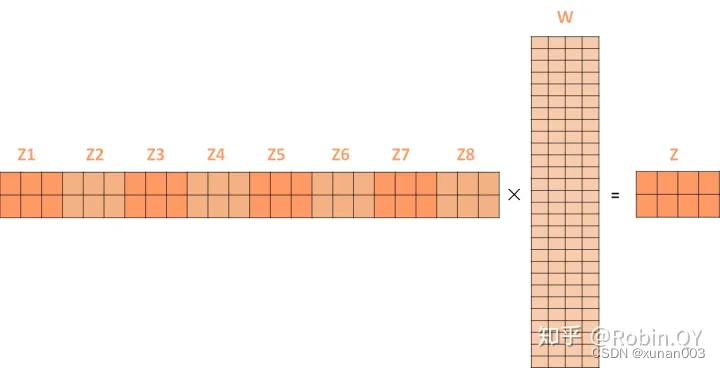
对于第5节中的案例,两组词向量2x512对应的原始维度为512x512的WQ、WK和WV被拆分为8个512x64的矩阵,故计算后得到8个2x64的Z矩阵,形式类似下图:

然后前馈神经网络的输入只需要一个矩阵就可以了,不需要八个矩阵,所以我们需要把这8个矩阵压缩成一个。只需要把这些矩阵拼接起来然后用一个额外的权重矩阵Wo与之相乘即可。
最终的Z经过残差后就作为前馈神经网络的输入。
如下图(图中W即为上文中提到的Wo):
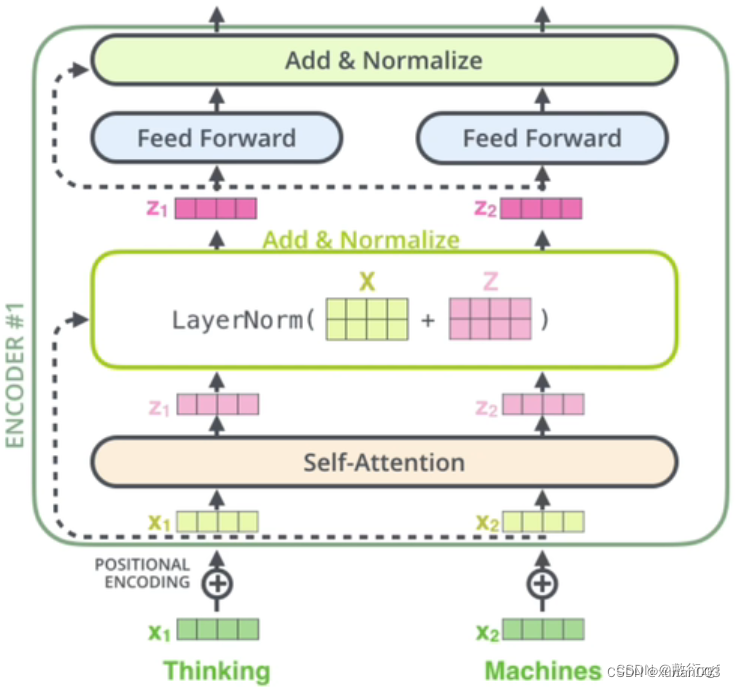
7.残差结构
下图中X1,X2词向量经过添加位置编码后(黄色的X1,X2)输入到自注意力层,输出Z1,Z2;接着将添加位置编码后(黄色的X1,X2)组成的矩阵与Z1,Z2组成的矩阵对位相加;将对位相加后的结果进行LayerNormalize操作。LayerNormalize后得到的新的Z1和Z2作为输入喂给前馈网络。
8.Feed_Forward(前馈网络)
在Transformer中前馈全连接层就是具有两层线性层的全连接网络。即FC+ReLU+FC。作用是考虑到注意力机制可能对复杂过程的拟合程度不够,通过增加两层网络来增强模型的能力。其公式如下:
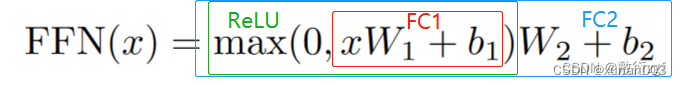
公式中的x表示多头注意力机制输出的Z(2×64),假设W1是64×1024,W2是1024×64,那么经过FFN(x) = (2×64)⊙(64×1024)⊙(1024×64) = 2×64,最终的维度并没有变。这两层的全连接层作用是将输入的Z映射到高维 (2×64)⊙(64×1024)=(2×1024),然后再变为原来的维度。
最后再经过一次残差结构并计算Add&Normalization,输入到下一个Encoder中,经过6次,就可以输入到Decoder中。
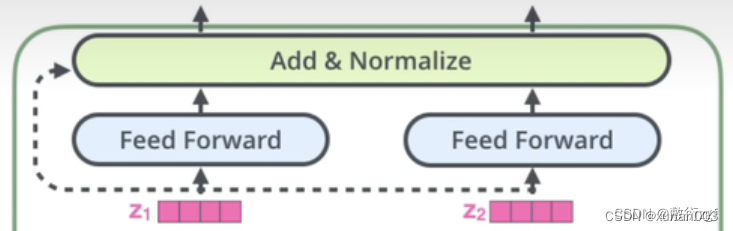
9.Decoder
首先来看看Decoder模块的整体架构图。同样,Decoder也是堆叠6层,虽然Decoder的模块比Encoder部分多,但很多是重复的。
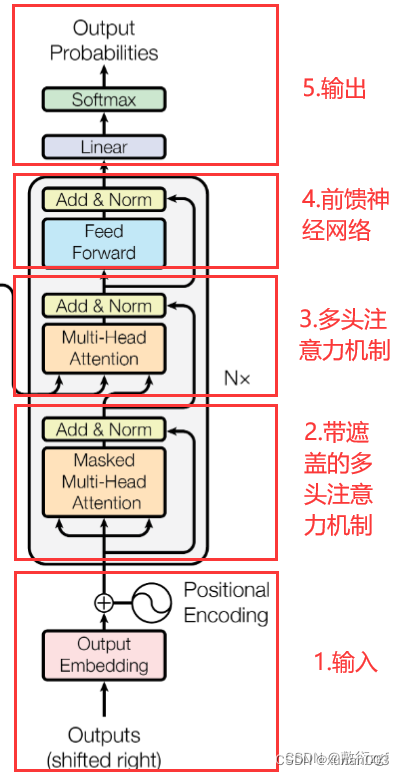
10.Decoder输入
论文中的结构图采用的是Outputs进行表示,其实是整个Transformer上一时刻的输出作为Decoder的输入。具体可以分类为训练时的输入和预测时的输入。
训练时:就是对已经准备好对应的target数据(类似CV groundtruth标定)。例如翻译任务,Encoder输入“Tom chase Jerry”,Decoder输入对应的中文翻译标定“汤姆追逐杰瑞”。
预测时:预测时Decoder的输入其实按词向量的个数来做循环输入,Decoder首次输入为起始符,然后每次的输入是上一时刻Transformer的输出。例如,Decoder首次输入“”,Decoder输出为本时刻预测结果“汤姆”;然后Decoder输入“汤姆”,Decoder输出预测结果“汤姆追逐”;之后Decoder输入“汤姆追逐”,则输出预测结果“汤姆追逐杰瑞”;最后Decoder输入“汤姆追逐杰瑞”,预测输出“汤姆追逐杰瑞”,此时输入输出一致,则结果整个流程。
可以看出,预测阶段的Decoder其实是一个循环推理的过程,为了词的前后关联性,从而根据分词方式来确定时间序列的长度t(Decoder执行的次数)。
而前述的Encoder的输出给到Decoder作为输入,其实是Encoder给了Decoder的Multi-Head Attention提供可Keys和Values矩阵。故6个叠加的Decoder中每个注意力均使用同一个Keys和Values矩阵。整个流程可以使用下面的一个流程范例来帮助理解。
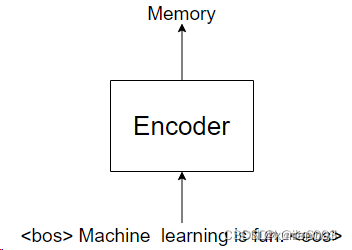
假设我们是要用Transformer翻译“Machine learning is fun”这句话。首先,我们会将“Machine learning is fun” 送给Encoder,输出一个名叫Memory的Tensor,如图所示:
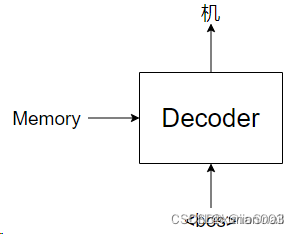
之后我们会将该Memory作为Decoder的一个输入,使用Decoder预测。Decoder并不是一下子就能把“机器学习真好玩”说出来,而是一个词一个词说(或一个字一个字,这取决于你的分词方式),首次输入起始值<pos>,Decoder根据Memory推理输出“机”字,如图所示:
紧接着,我们会再次调用Decoder,这次是传入“<bos> 机”,然后推理得到“器”字:
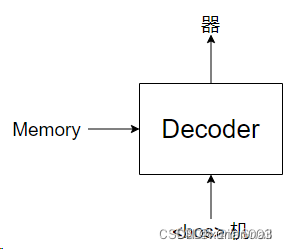
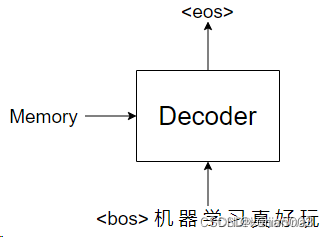
依次类推,直到最后输出<eos>结束,当Transformer输出<eos>时,预测就结束了。
11.Masked MultiHead-attention
由于解码器采用自回归auto-regressive,即
在过去时刻的输出作为当前时刻的输入,也就是说在预测时无法看到之后的输入输出,但是在注意力机制当中,可以看到完整的输入(每一个词都要和其他词做点积,计算相关性),为了避免这种情况的发生,在解码器训练时,在预测t时刻的输出时,不应该能看到t时刻以后的输入。做法是:采用带掩码的Masked注意力机制,从而保证在t时刻无法看到t时刻以后的输入,保证训练和预测时的行为一致性。
所以,Masked-MultiHead-attention的其它部分计算流程实际上与Encoder中的计算过程一致,区别只是在计算出scores矩阵时对其沿对角线上部分进行mask掩码。其主要在训练阶段屏蔽t时刻之后的输入生效,而在预测阶段其实并没有真实作用。
如第10节所举之例,预测“机器学习真好玩”的过程。对于Decoder来说是一个字一个字预测的,所以假设我们Decoder的输入是“机器学习”时,“习”字只能看到前面的“机器学”三个字,所以此时对于“习”字只有“机器学习”四个字的注意力信息。但是,训练阶段传的是“机器学习真好玩”,还是不能让“习”字看到后面“真好玩”三个字,所以要使用mask将其盖住,这又是为什么呢?原因是:如果让“习”看到了后面的字,那么“习”字的编码就会发生变化。
例如:我们只传入了“机”,此时使用attention机制,将“机”字编码为了 [ 0.13 , 0.73 , . . . ] 。但如果传入了“机器”,此时使用attention机制,如果我们不将“器”字盖住的话,那“机”字的编码就会发生变化,它就不再是是[ 0.13 , 0.73 , . . . ]了,也许就变成了[ 0.95 , 0.81 , . . . ]。这样就可能会让网络有问题。所以我们为了不让“机”字的编码产生变化,所以我们要使用mask,掩盖住“机”字后面的字。
而mask掩码的方式,原理很简单,self-attention的输出是经过softmax的scores向量,故对应scores屏蔽即可。例如v1、v2为Decoder输入的词向量,矩阵A(元素为α)为self-attention计算得到的分数,则输出为向量o。当只输入词向量v1时,得到的输出o1为:
而当输入两个词向量时,得到的输出o1和o2为:
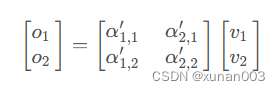
此时对应的输出o1=α11*v1+α21*v2,与只输入v1得到的o1完全不同。
所以,这样看那这样看,我们只需要将α21盖住即可,这样就能保证两次的o1一致了。如下图:
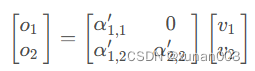
依次类推,如果执行到第n时刻时,scores矩阵A(α)、词向量v和输出o的关系应当如下:
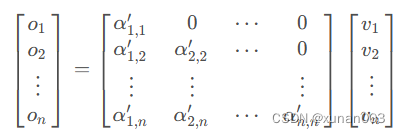
但是,在实际代码中scores矩阵中的mask掩码并非置0,而是使用了-1e9(负无穷)。这是由于代码中在softmax之前已初始化掩码矩阵,故softmax(-1e9)约等于0,如下:

Transformer推理时是一个一个词预测,而训练时会把所有的结果一次性给到Transformer,但效果等同于一个一个词给,而之所以可以达到该效果,就是因为对target进行了掩码,防止其看到后面的信息,也就是不要让前面的字具备后面字的上下文信息。
12.Masked Multi-Head attention输出
第11节输出的向量o即可看作第8节所述的attention输出的矩阵Z,然后通过残差结构和Masked Mukti-Head attention输入X做add和LayerNormalize。
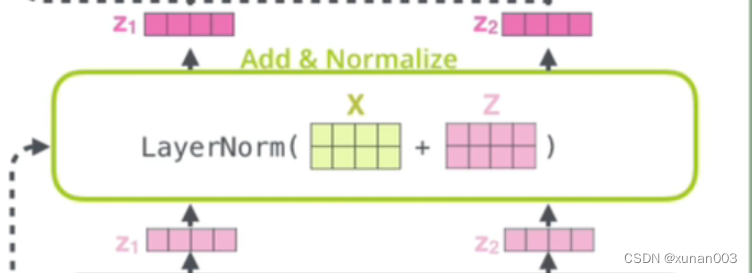
而重Add&Normalize的输出可以作为Decoder模块Multi-Head attention的输入Q(Query)矩阵,同时联合Encoder输出的Keys、Values矩阵进行Decoder的Multi-Head attention模块。而Decoder的Multi-Head attention模块计算流程与Encoder部分完全一致。Multi-Head attention计算完毕后进入同Encoder一样的Feed-Forward前馈模块。
整个Masked Multi-Head attention+Add&Norm+Multi-Head attention+Add&Norm+Feed Forward+Add&Norm被执行6次。
13.Transformer输出
Liner和Softmax层将解码器最终输出的实数向量变成一个word,线性变换层是全连接神经网络,将解码器产生的向量投影到一个比它大得多的、被称作对数几率(logits)的向量里。假设模型从训练集中学习一万个不同的word,则对数几率向量为一万个单元格长度的向量,每个单元格对应某一个单词的分数。softmax层将分数变成概率,概率最高的单元格对应的单词被作为该时间的输出。
仍按前例,如输入一个2x512的词向量矩阵,前述Decoder重复执行6次后得到一个2x64的矩阵,然后进过FC(Linear)线性变换后得到一个1x2的向量,进行最终的softmax评分得到最高分数即为target中某个词的概率。
参考链接:
[1]
Transformer原理详解_敷衍zgf的博客-CSDN博客
[2]
十分钟理解Transformer - 知乎 (zhihu.com)
[3]
MultiHead-Attention和Masked-Attention的机制和原理_masked multi-head attention_iioSnail的博客-CSDN博客
[4]
【手撕Transformer】Transformer输入输出细节以及代码实现(pytorch)_顾道长生'的博客-CSDN博客
[5]
举个例子讲下transformer的输入输出细节及其他 - 知乎 (zhihu.com)