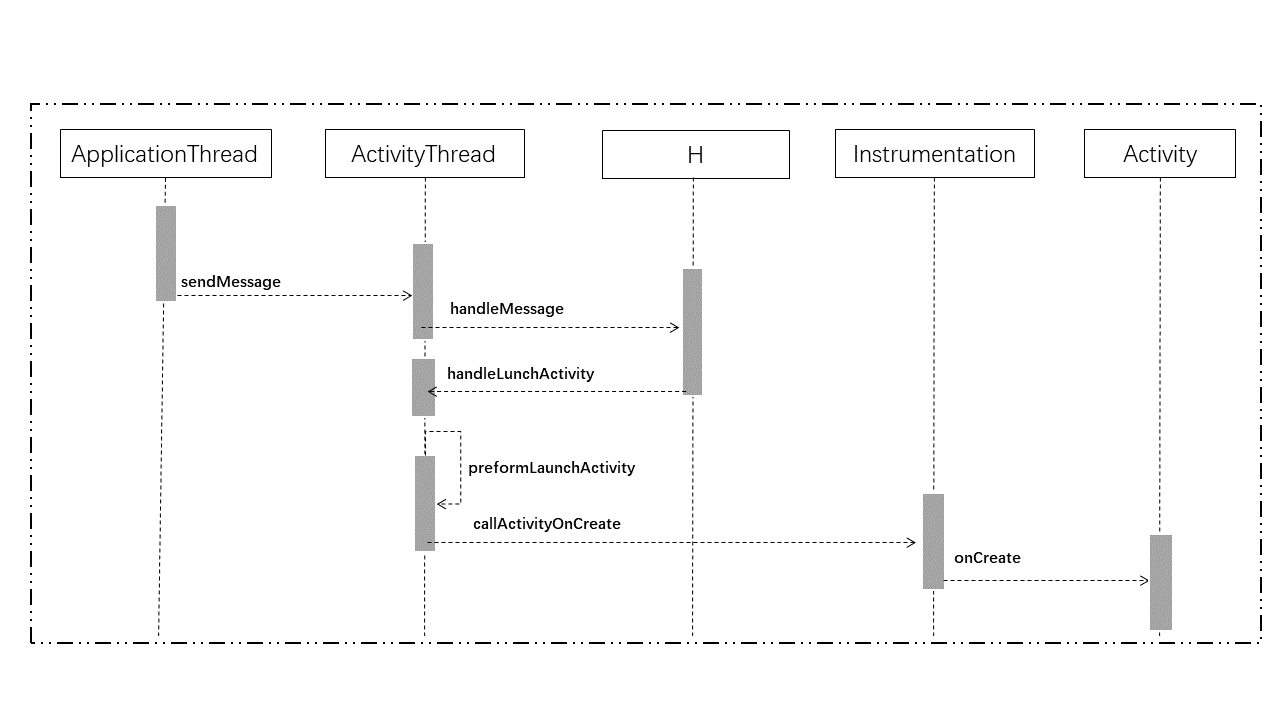
首先来一个全局总览,后面我会分别对每个命令进行说明:

如果你的mysql导入环境变量,可以在命令行输入:
mysql -u root -p
然后输入密码登录数据库
否则,打开mysql command line并输入密码进入数据库
一,基础数据库操作
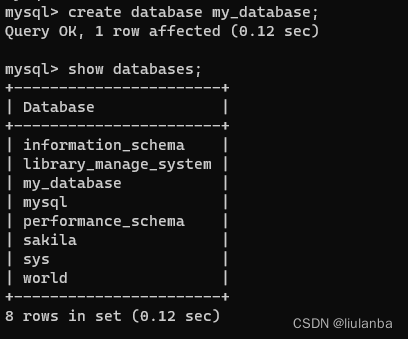
1.创建数据库
create database my_database;
2.查询数据库
show databases;
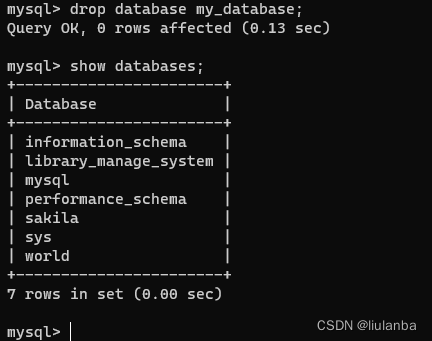
3.删除数据库
drop database my_databases;
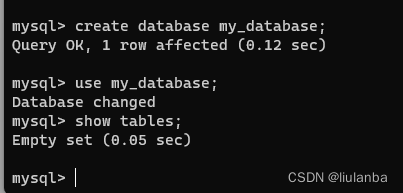
4.选择数据库
use my_database;
5.查询数据表
show tables;
6.创建数据表
create table student(id int,name char(10),age int,sex char(5));
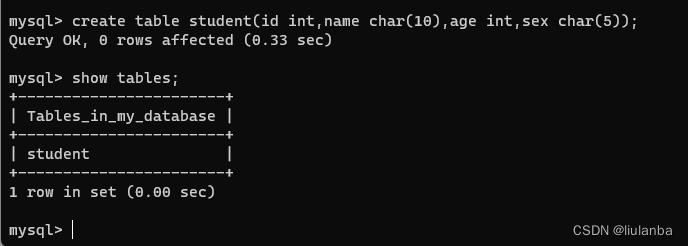
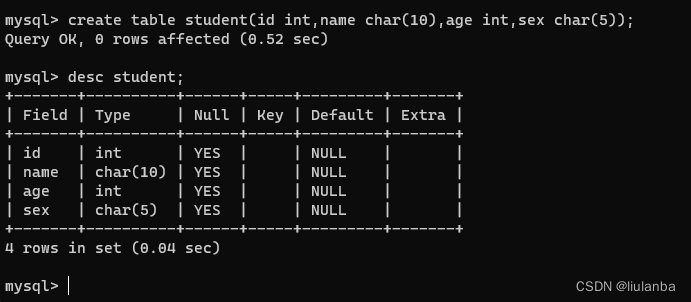
7.查询表结构
desc student;
8.删除表
drop table student;
9.数据表添加列
alter table student add height int(10);
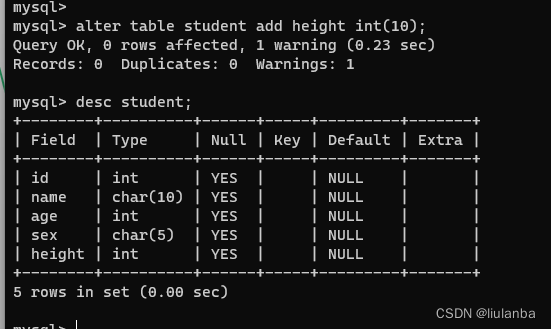
10.数据表删除列
alter table student drop height;
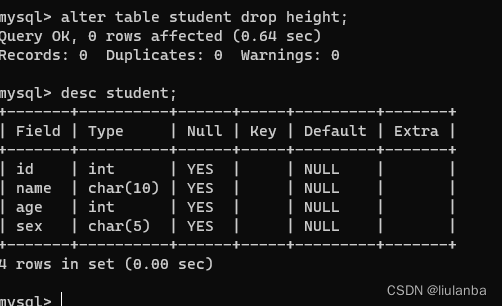
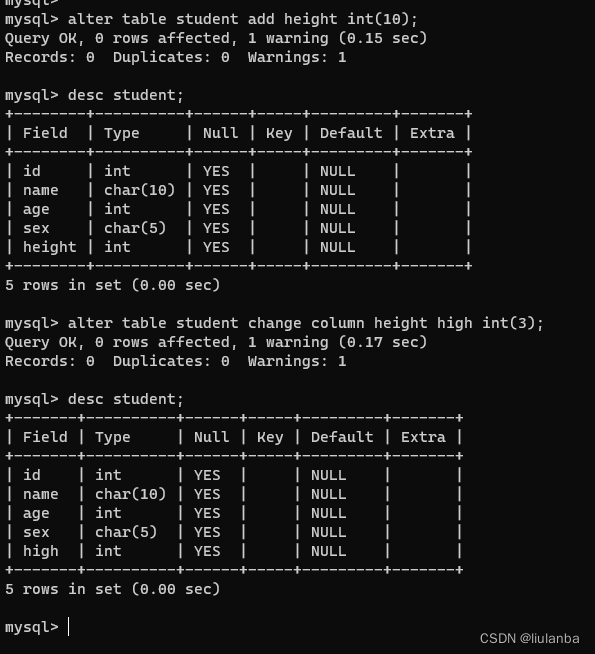
11.数据列改名
alter table student change column height high int(3);
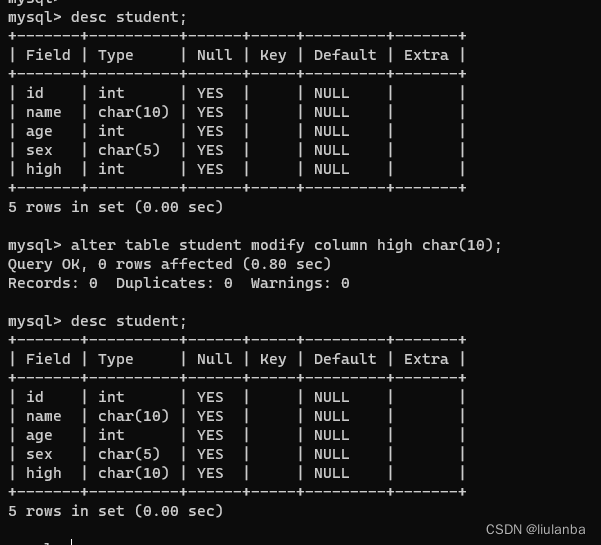
12.数据列修改数据类型
alter table student modify column high char(10);
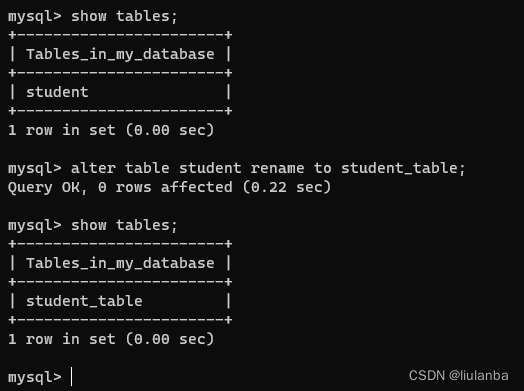
13.修改表名
alter table student rename to student_table;
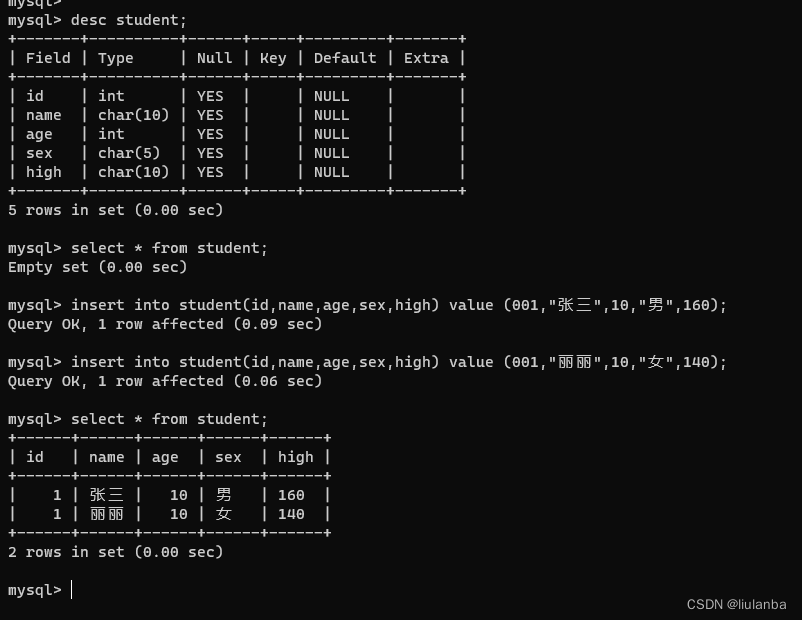
14.插入数据项
insert into student(id,name,age,sex,high) value (001,"张三",10,"男",160);
15.删除数据项
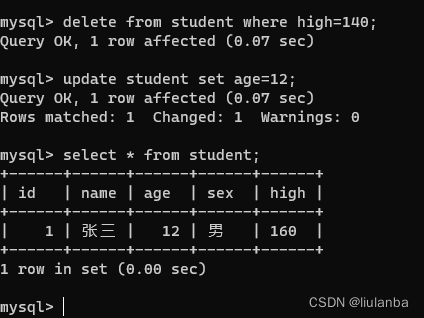
delete from student where high=140;
16.更新数据项
update student set age=12;
二,逻辑运算符
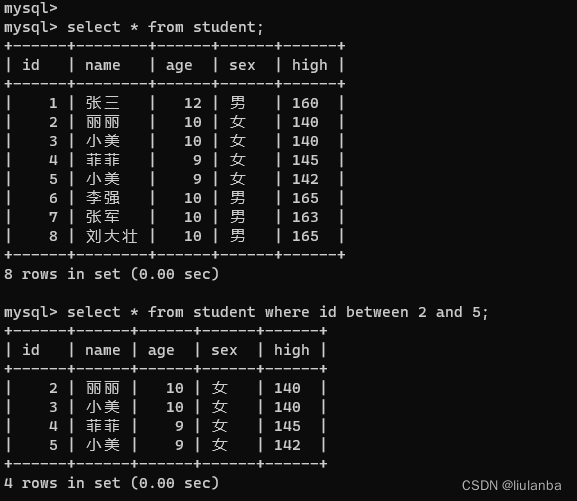
- between 最小值 and 最大值
语法:select * from 表名 where 列名 between 最小值 and 最大值;
select * from student where id between 2 and 5;
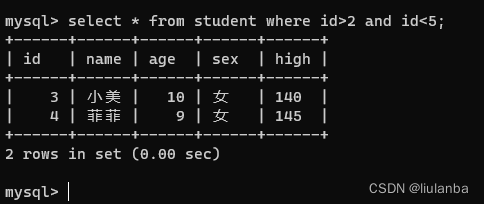
作用和使用><是一样的
select * from student where id>2 and id<5;
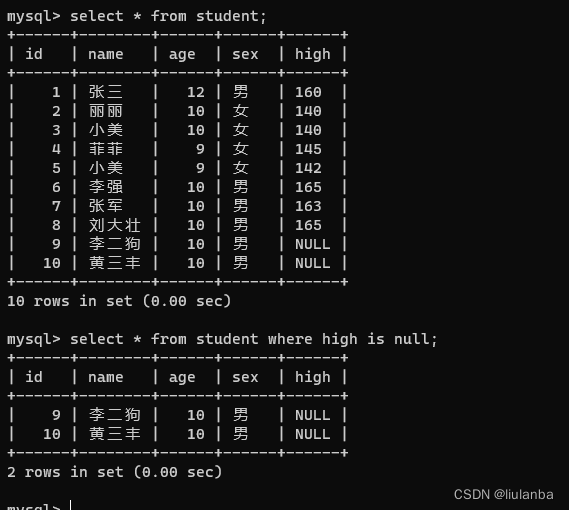
2.null
语法:select * from 表名 where 列名 is null;(判断这一列有空值)
select * from student where high is null;
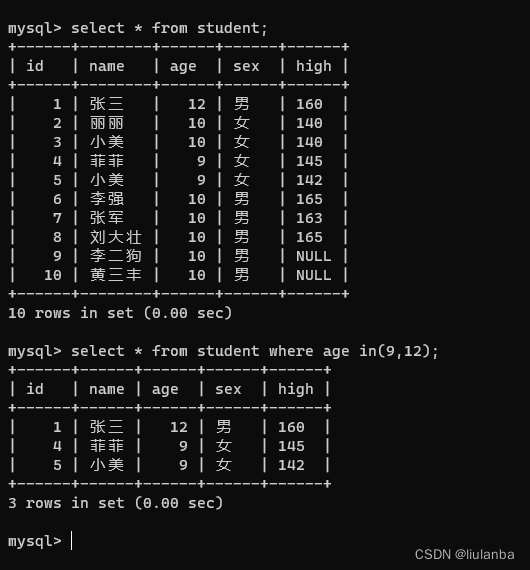
- in (取值范围)
语法:select * from 表名 where 列名 in (值1,值2,…)
select * from student where age in(9,12);
- like 好像
通配符: % 代表任意字符 _ 一个下划线代替一个字符
语法:select * from 表名 where 列名 like ‘通配符 特征 通配符’;
select * from student where name like '张_';
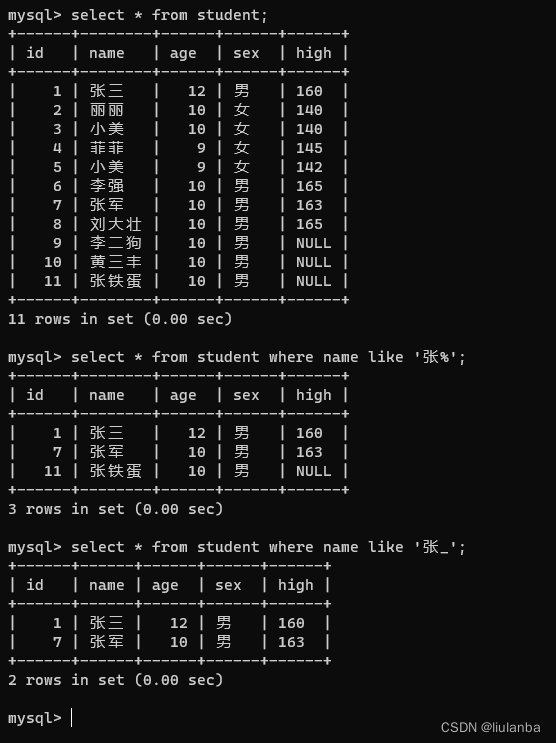
具体参考:mysql的like语句
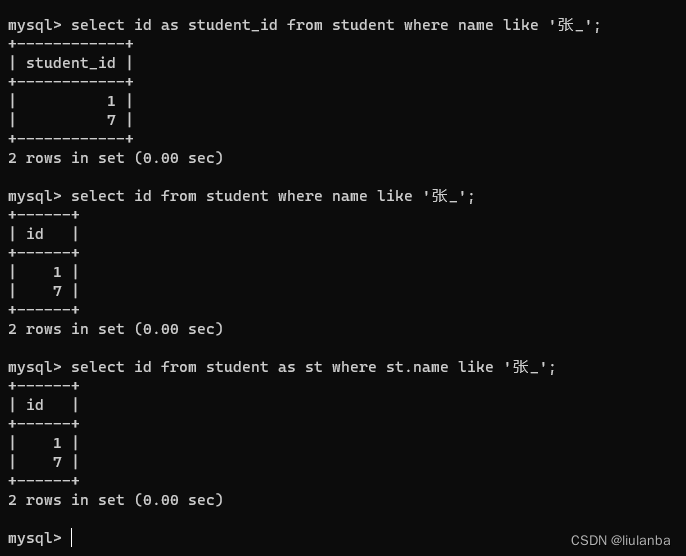
5.as 为表名称或者列名称指定别名
select id as student_id from student where name like '张_';
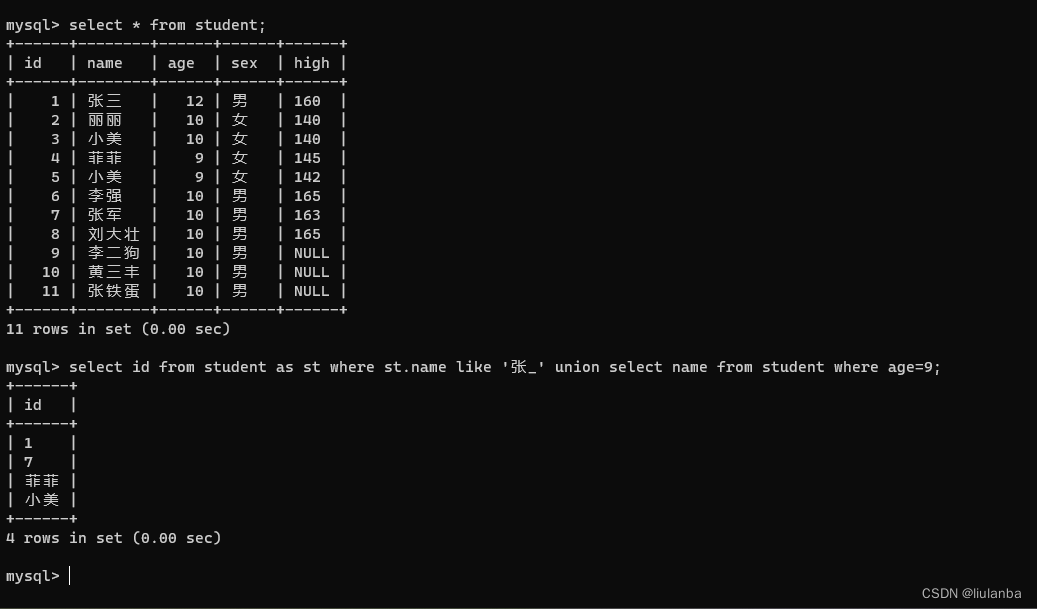
6.union 合并两个或多个select语句结果集
select id from student as st where st.name like '张_' union select name from student where age=9;
三,排序
关键词 order by
排序规则:升序排序 asc (默认可省略) 降序排序 desc
语法:
单列 select * from 表名 order by 列名 asc或者 desc;
多列 select * from 表名 order by 列名 asc或者 desc,列名2 asc或者desc,…;
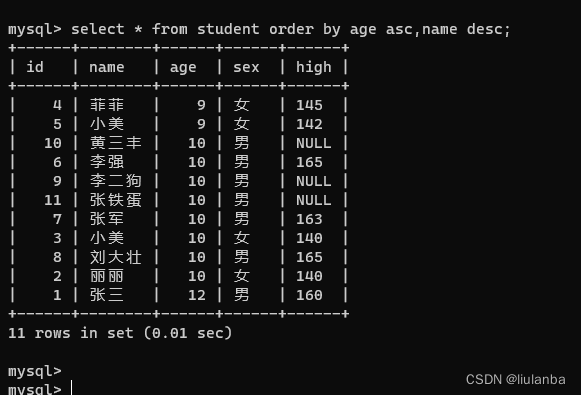
select * from student order by age asc,name desc;
四,去重
GROUP BY 和 DISTINCT 都是用于从数据库中选择唯一值的 SQL 子句
两者的不同请参考:mysql的distinct和group by的区别
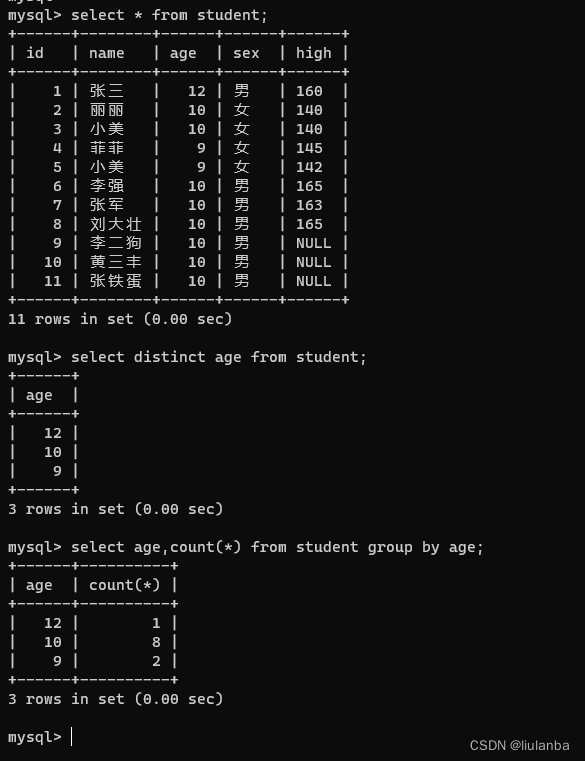
select distinct age from student;
select age,count(*) from student group by age;
五,统计函数
语法:select 统计函数(列名),统计函数(列名2)… from 表名;
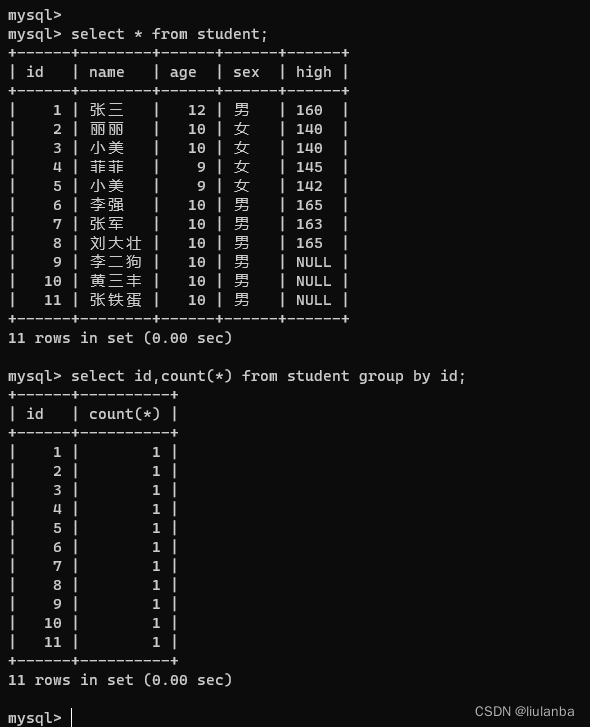
1.count(列名) 统计这一列的非空总行数
select id,count(*) from student group by id;
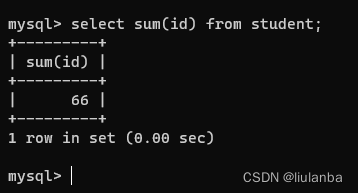
2.sum(列名) 统计这一列的总和
select sum(id) from student;
3.avg(列名) 统计这一列的平均值
select avg(id) from student;
4.max(列名) 统计这一列的最大值
select max(id) from student;
5.min(列名) 统计这一列的最小值
select min(id) from student;
六,多表查询
1. 查询的数据来自于多张表—— 表连接
表连接有三种情况:
内链接: inner join
外链接:
左外链接: left join 获取左表所有记录,即使右表没有对应匹配的记录,则为空
右外链接: right join 获取右表所有记录,即使左表没有对应匹配的记录,则为空
在 MySQL 中,JOIN 是一种用于将多个表中的数据组合在一起的操作。JOIN 通过在多个表之间比较一个或多个列的值来确定如何组合这些表中的数据。
INNER JOIN:INNER JOIN 返回所有在两个表中都有匹配的行。它是默认的 JOIN 类型,如果没有指定 JOIN 类型,则使用 INNER JOIN。
LEFT JOIN(或 LEFT OUTER JOIN):LEFT JOIN 返回左表中所有的行,以及右表中所有匹配的行。如果右表中没有匹配的行,则返回 NULL 值。
RIGHT JOIN(或 RIGHT OUTER JOIN):RIGHT JOIN 返回右表中所有的行,以及左表中所有匹配的行。如果左表中没有匹配的行,则返回 NULL 值。
FULL JOIN(或 FULL OUTER JOIN):FULL JOIN 返回左表和右表中的所有行,并将没有匹配的行设置为 NULL 值。
以下是在 MySQL 中使用 INNER JOIN 和 LEFT JOIN 的示例:
– INNER JOIN 示例
SELECT orders.order_id, customers.customer_name
FROM orders
INNER JOIN customers
ON orders.customer_id = customers.customer_id;
– LEFT JOIN 示例
SELECT customers.customer_name, orders.order_id
FROM customers
LEFT JOIN orders
ON customers.customer_id = orders.customer_id;
在上面的示例中,第一个查询使用 INNER JOIN 将 orders 表和 customers 表组合在一起,并根据它们的 customer_id 列进行匹配。第二个查询使用 LEFT JOIN 将 customers 表和 orders 表组合在一起,并根据它们的 customer_id 列进行匹配,返回所有的 customers 表中的行和与之匹配的 orders 表中的行。如果没有匹配的行,则返回 NULL 值。
INNER JOIN 多表查询
SELECT orders.order_id, customers.customer_name, products.product_name
FROM orders
INNER JOIN customers
ON orders.customer_id = customers.customer_id
INNER JOIN products
ON orders.product_id = products.product_id;
在上面的示例中,INNER JOIN 用于连接三个表:orders、customers 和 products。通过连接 customer_id 和 product_id 列,我们可以获取订单、顾客名称和产品名称的数据。
LEFT JOIN 多表查询
SELECT customers.customer_name, COUNT(orders.order_id)
FROM customers
LEFT JOIN orders
ON customers.customer_id = orders.customer_id
GROUP BY customers.customer_name;
在上面的示例中,LEFT JOIN 用于连接 customers 和 orders 表。通过连接 customer_id 列,我们可以获取每个顾客名称以及他们的订单数量。由于使用了 LEFT JOIN,如果某个顾客没有订单,他们的订单数量将显示为零。
2. 查询的条件来自于多张表—— 子查询
一个查询语句里面 包含了另外一条或多条查询语句
特征:一对 括号 把 查询语句给包起来了
子查询多表查询
SELECT orders.order_id, orders.order_date, customers.customer_name
FROM orders
INNER JOIN (
SELECT customer_id, MAX(order_date) AS latest_order
FROM orders
GROUP BY customer_id
) AS latest_orders
ON orders.customer_id = latest_orders.customer_id
AND orders.order_date = latest_orders.latest_order
INNER JOIN customers
ON orders.customer_id = customers.customer_id;
在上面的示例中,子查询用于获取每个顾客的最新订单日期。然后,INNER JOIN 用于连接 orders 表和 customers 表,并将订单日期与最新订单日期进行比较,以获取最新订单的订单号、订单日期和顾客名称。
还可以别名结合join使用:
select * from 表名 as 别名1 join 表名 as 别名2 on 别名1.列名=别名2.列名;
七,索引
在 MySQL 中创建索引可以大大提高查询效率,加快数据检索速度,他的索引包含 普通索引和唯一索引,以及主键索引
具体参考:mysql索引
八,约束
SQL 约束用于规定表中的数据规则,如果存在违反约束的数据行为,行为会被约束终止。
约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)
CREATE TABLE table_name
(
column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name,
column_name3 data_type(size) constraint_name,
....
);
在 SQL 中,我们有如下约束:
主键约束(Primary Key Constraint):主键是用于标识表中每行记录的唯一标识符。主键可以是一个或多个列组成,用于唯一标识每一行。主键约束确保主键的值不为空并且唯一。
唯一约束(Unique Constraint):唯一约束确保一个或多个列中的每个值都是唯一的。与主键约束不同,唯一约束可以允许空值。
非空约束(Not Null Constraint):非空约束确保一个或多个列中的值不为空,即不允许 NULL 值。
外键约束(Foreign Key Constraint):外键约束用于定义两个表之间的关系。外键约束可以确保一个表中的数据与另一个表中的数据相匹配,通常用于建立表之间的关联关系。
检查约束(Check Constraint):检查约束用于定义列中允许的值的范围或条件。例如,可以使用检查约束确保一个列中的值不超过一定范围。
创建包含主键约束和外键约束的表的示例:
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
在上面的例子中,orders 表中的 order_id 列被定义为主键,customer_id 列定义为外键,关联到 customers 表中的 customer_id 列。
可以使用ALTER TABLE语句来给MySQL数据表添加约束,以下是一些常用的约束类型及其示例:
主键约束:
主键是唯一标识数据表中每个记录的列或列组合,可以使用以下语句添加主键约束:
ALTER TABLE table_name ADD PRIMARY KEY (column_name);
其中,table_name是数据表名称,column_name是要设置为主键的列名。
唯一约束:
唯一约束用于确保数据表中的某个列或列组合中的值是唯一的。可以使用以下语句添加唯一约束:
ALTER TABLE table_name ADD UNIQUE (column_name);
其中,table_name是数据表名称,column_name是要设置为唯一的列名。
外键约束:
外键约束用于确保数据表中的某个列或列组合的值与另一个表中的某个列或列组合的值相匹配。可以使用以下语句添加外键约束:
ALTER TABLE table_name ADD FOREIGN KEY (column_name) REFERENCES other_table_name (other_column_name);
其中,table_name是数据表名称,column_name是要设置为外键的列名,other_table_name是关联的其他表名称,other_column_name是在其他表中要匹配的列名。
九,事务
MySQL 事务是一组操作的集合,这些操作被视为单个不可分割的工作单元,要么全部完成,要么全部不完成。事务通常用于保证数据库操作的一致性和完整性,并且在处理高并发数据操作时非常有用。
在 MySQL 中,事务具有以下四个特性,通常被称为 ACID 特性:
原子性(Atomicity):事务是一个不可分割的工作单元,事务中的所有操作要么全部完成,要么全部不完成。
一致性(Consistency):在事务开始和结束时,数据库必须保持一致状态。这意味着,在事务执行之前和之后,所有相关的数据必须满足所有预定义的规则。
隔离性(Isolation):每个事务必须与其他事务隔离,以避免数据损坏。隔离级别定义了多个事务可以访问数据库的方式。
持久性(Durability):一旦事务完成,它所做的更改必须永久保存在数据库中,并且不应该被回滚。
在 MySQL 中,可以使用 BEGIN、COMMIT 和 ROLLBACK 语句来控制事务。BEGIN 语句用于启动事务,COMMIT 语句用于提交事务,而 ROLLBACK 语句用于撤消事务。例如,以下是在 MySQL 中使用事务的示例:
BEGIN; -- 开始事务
UPDATE accounts SET balance = balance - 1000 WHERE id = 1;
UPDATE accounts SET balance = balance + 1000 WHERE id = 2;
COMMIT; -- 提交事务
在上面的示例中,BEGIN 语句用于启动事务,两个 UPDATE 语句用于更新 accounts 表中的记录,COMMIT 语句用于提交事务。如果其中一个 UPDATE 语句失败,可以使用 ROLLBACK 语句来撤消整个事务:
BEGIN; -- 开始事务
UPDATE accounts SET balance = balance - 1000 WHERE id = 1;
UPDATE accounts SET balance = balance + 1000 WHERE id = 999; -- 无效的ID
ROLLBACK; -- 撤消事务
COMMIT;
在上面的示例中,第二个 UPDATE 语句无效,因为没有 ID 为 999 的记录,所以 ROLLBACK 语句用于撤消整个事务
十,WHERE 和HAVING
在 MySQL 中,WHERE 和 HAVING 是用于筛选数据的两个关键字。
WHERE
WHERE 关键字用于在查询中筛选数据,并返回满足指定条件的行。WHERE 关键字可以使用比较运算符(如 =、<、>、<=、>=、<> 等)和逻辑运算符(如 AND、OR、NOT 等)来指定筛选条件。
以下是一个使用 WHERE 关键字的示例:
SELECT customer_name, city
FROM customers
WHERE city = 'New York';
在上面的示例中,WHERE 关键字用于筛选出位于纽约市的顾客,并返回其名称和所在城市。
HAVING
HAVING 关键字用于在 GROUP BY 子句中筛选分组数据。它与 WHERE 关键字类似,但它是在分组后进行筛选的,而不是在查询的所有行上进行筛选的。
以下是一个使用 HAVING 关键字的示例:
SELECT customer_id, COUNT(order_id)
FROM orders
GROUP BY customer_id
HAVING COUNT(order_id) > 2;
在上面的示例中,GROUP BY 关键字用于按顾客 ID 进行分组,并计算每个顾客的订单数量。然后,HAVING 关键字用于筛选出订单数量大于 2 的顾客。请注意,HAVING 关键字只能用于聚合函数(如 COUNT、SUM、AVG、MIN 和 MAX)所返回的数据。
总之,WHERE 和 HAVING 关键字都是用于筛选数据的关键字,但 WHERE 关键字用于筛选行,而 HAVING 关键字用于筛选分组数据。