文章目录
- 一、概述
- 1.1、定义
- 1.2、如何运作?
- 1.3、传统消息队列的应用场景
- 1.4、消息队列的两种模式
- 1.5、Kafka的基础架构
- 二、安装(需要安装zookeeper)
- 三、常用命令行操作
- 3.1、主题命令行操作
- 3.2、生产者命令行操作
- 3.3、消费者命令行操作
一、概述
1.1、定义
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Quere)。
发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接受感兴趣的消息。
1.2、如何运作?
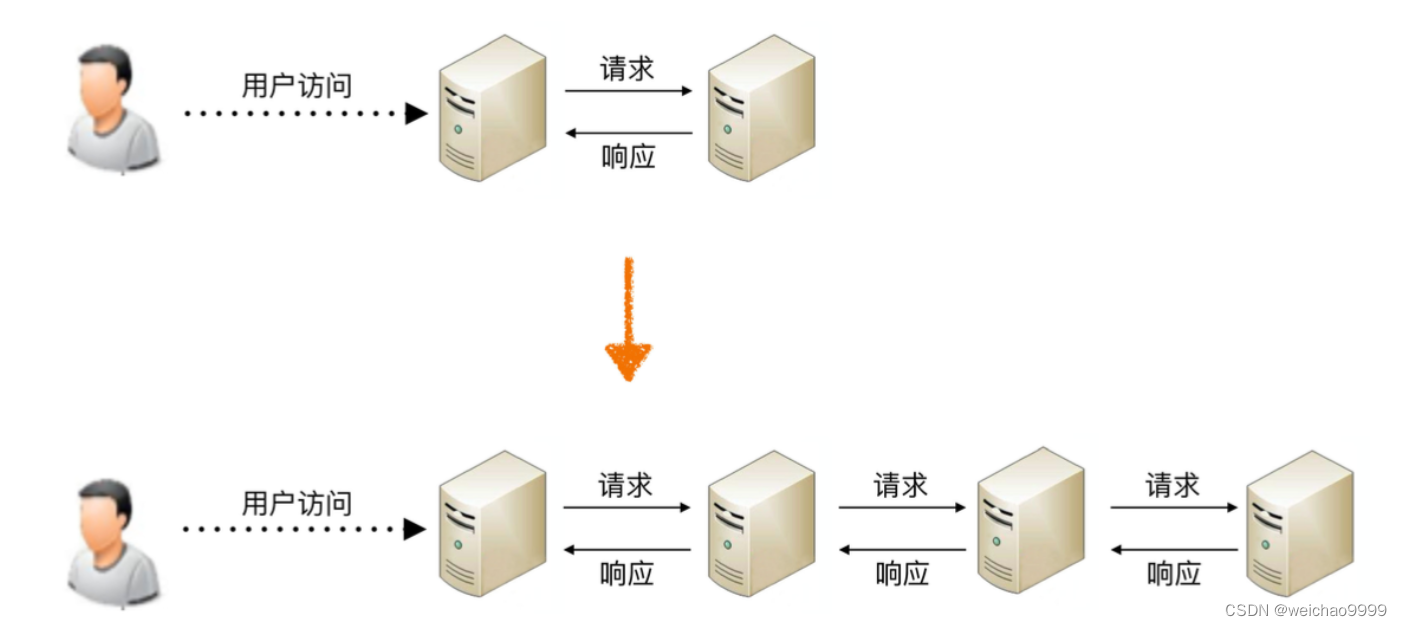
Kafka是一个由服务器和客户端组成的分布式系统,通过高性能TCP网络协议进行通信。它可以部署在本地和云中的裸机硬件、虚拟机和容器上环境。
- 服务器: Kafka作为一个或多个服务器的集群运行,这些服务器可以跨越多个数据中心或云区域。其中一些服务器形成了存储层,成为代理。其他服务器运行Kafka Connect以持续导入和导出数据作为事件流。用于将Kafka与现有的系统、其他Kafka集群集成。Kafka集群具有高度可扩展行和容错:如果其任何服务器发送故障,其他服务器将接管其工作以确保连续操作,没有数据丢失。
- **客户端:**它们允许编写分布式应用程序和微服务,这些应用程序和微服务可以并行地、大规模地读取、写入和处理事件流,并且即使在网络问题或机器故障的情况下也能以容错的方式进行。
1.3、传统消息队列的应用场景
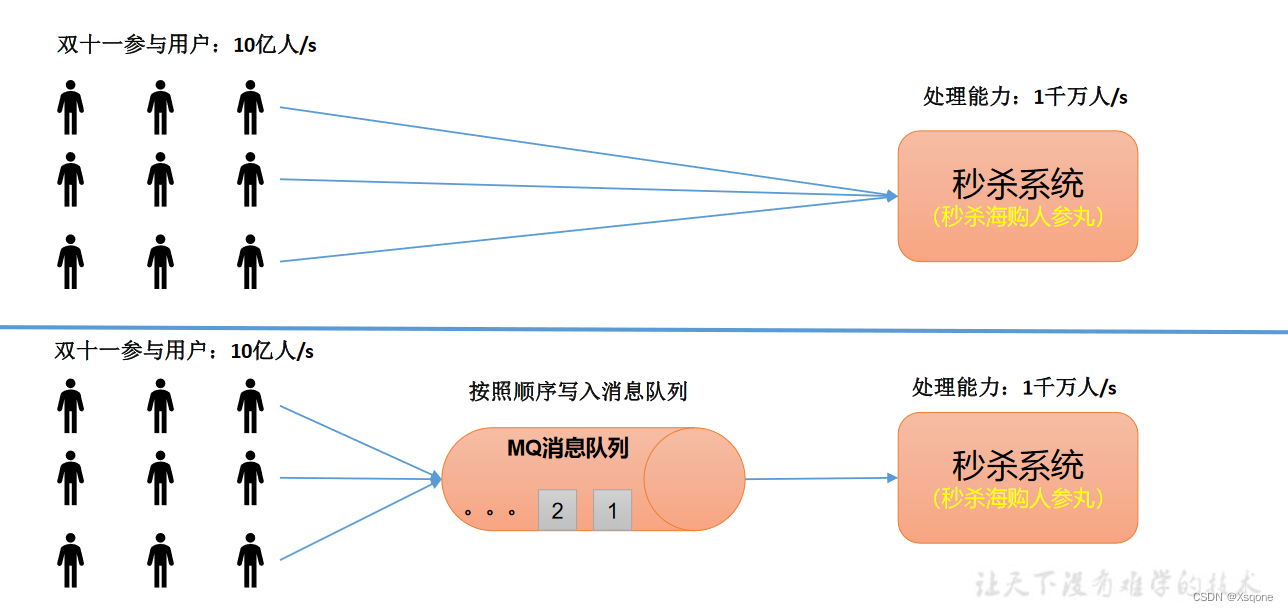
缓存/消峰、解耦、异步通信
-
缓存/消峰:有助于控制和优化数据流经过系统的速度,解决生成消息和消费消息的处理速度不一致的情况。
-
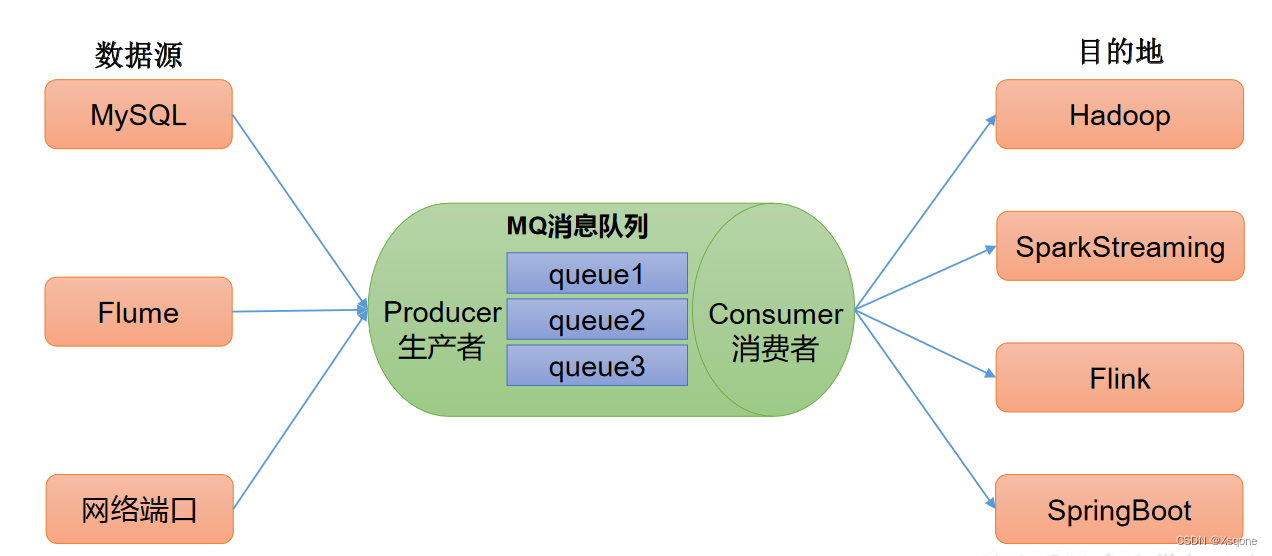
解耦:允许独立扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
 + 异步处理:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候去处理它们。
+ 异步处理:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候去处理它们。
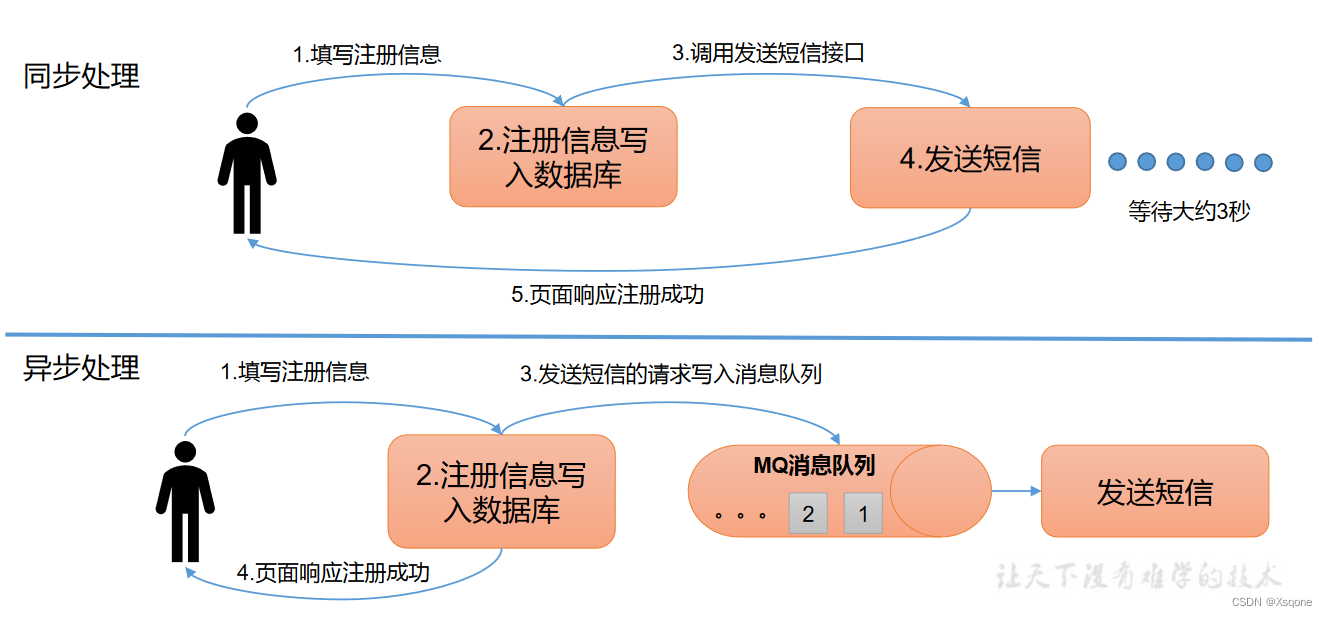
1.4、消息队列的两种模式
- 点对点模式: 消费者主动拉取数据,消息收到后清除消息。

- 发布/订阅模式:
- 可以有多个topic主题。
- 消费者消费数据后,不删除数据。
- 每个消费者相互独立,都可以消费到数据。
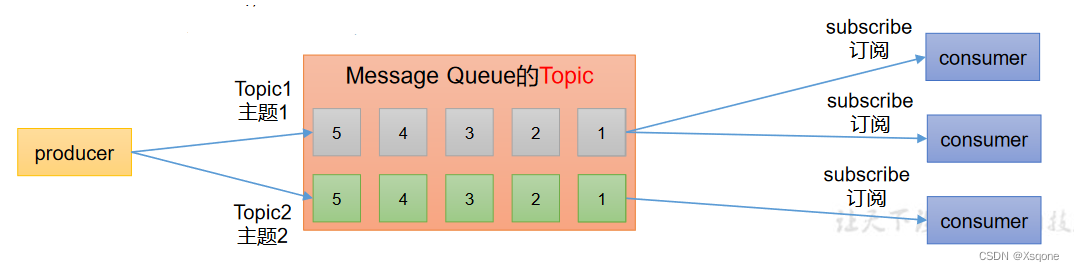
1.5、Kafka的基础架构
- 为方便扩展,并提高吞吐量,一个topic分为多个partition。
- 配合分区的设计,提出消费者组的概念,组内每个消费者并行消费。
- 为提高可用性,为每个partition增加若干个副本。
- ZK中记录谁是leader
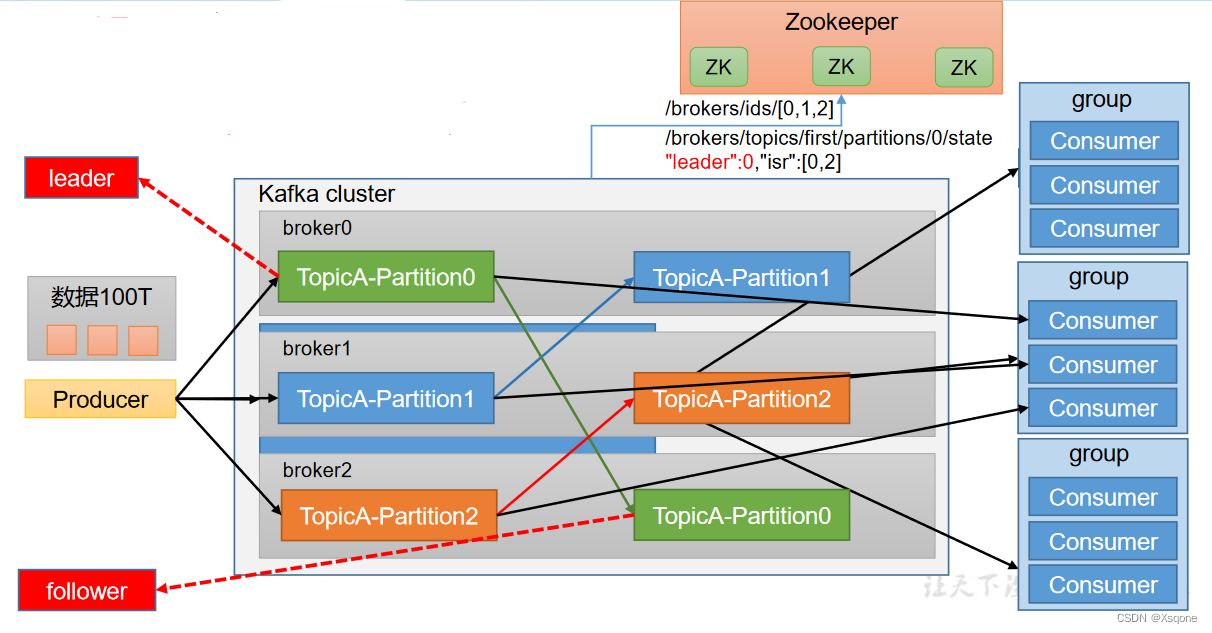
- Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
- Consumer:消息消费者,向 Kafka broker 取消息的客户端。
- Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
- Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
- Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
二、安装(需要安装zookeeper)
- 下载安装包Kafka官网下载地址
- 上传到服务器
- 解压
tar -zxf /opt/install/kafka_2.12-2.8.0.tgz -C /opt/soft/ - 修改目录名
mv /opt/install/kafka2_.12-2.8.0/ kafka212 - 修改配置文件(server.properties)(下面修改前面为第几行注意地址改为自己的地址)
vim /opt/soft/kafka212/config/server.properties 21 broker.id=0 36 advertised.listeners=PLAINTEXT://xsqone144:9092 60 log.dirs=/opt/soft/kafka212/data 103 log.retention.hours=1680 123 zookeeper.connect=xsqone144:2181/kafka 137 delete.topic.enable=true - 设置节点号
echo "0">/opt/soft/kafka212/data/myid - 修改配置文件
vim /etc/profile # KAFKA_HOME export KAFKA_HOME=/opt/soft/kafka212 export PATH=$PATH:$KAFKA_HOME/bin - 重新加载配置文件
source /etc/profile - 测试(启动Kafka)
# 先启动zookeeper zkServer.sh start kafka-server-start.sh -daemon /opt/soft/kafka212/config/server.properties
三、常用命令行操作
3.1、主题命令行操作
- 查看消息队列
kafka-topics.sh --bootstrap-server xsqone144:9092 --list

- 创建消息队列
kafka-topics.sh --bootstrap-server xsqone144:9092 --create --topic taibai --replication-factor 1 --partitions 1

- 查看消息队列详情
kafka-topics.sh --bootstrap-server xsqone144:9092 --describe --topic taibai

- 修改分区数(注意:只能增加,不能减少)
kafka-topics.sh --bootstrap-server xsqone144:9092 --alter --topic taibai --partitions 3

- 删除消息队列
kafka-topics.sh --bootstrap-server xsqone144:9092 --delete --topic taibai

3.2、生产者命令行操作
- 发送消息
kafka-console-producer.sh --bootstrap-server xsqone144:9092 --topic xsqone
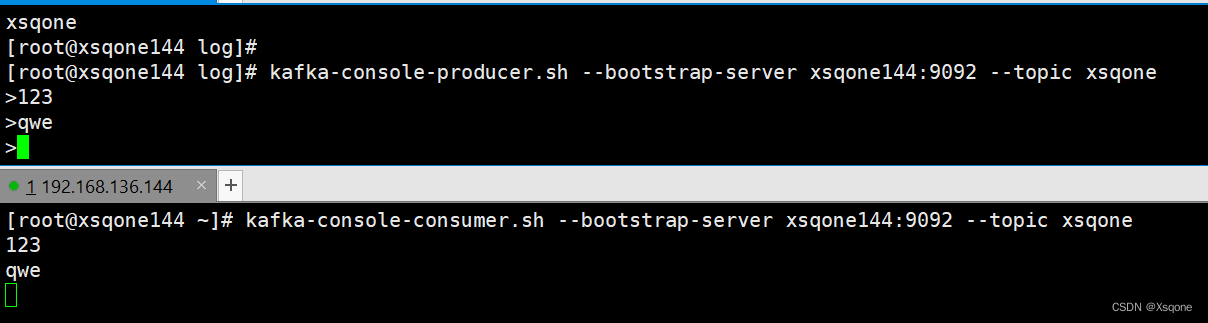
- 查看生产者者offset信息
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list xsqone144:9092 --topic xsqone

3.3、消费者命令行操作
- 消费消息队列中的数据
kafka-console-consumer.sh --bootstrap-server xsqone144:9092 --topic xsqone
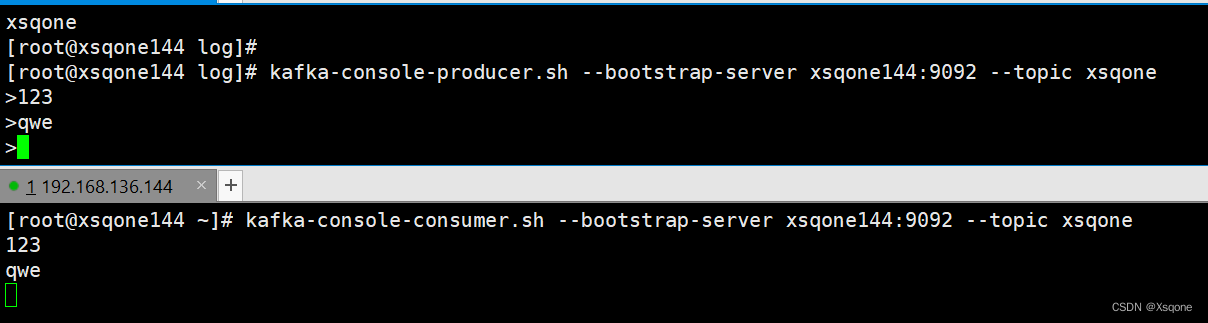
- 消费消息队列中所有数据
kafka-console-consumer.sh --bootstrap-server xsqone144:9092 --from-beginning --topic first
- 查看消费者的offset信息(最后的为消费者IDName)
kafka-consumer-groups.sh --bootstrap-server xsqone144:9092 --describe --group 5
第一列是groupid,第二列是主题名,第三列是分区,第四列是偏移量,第五列是生产者偏移量,第六列偏移量落后