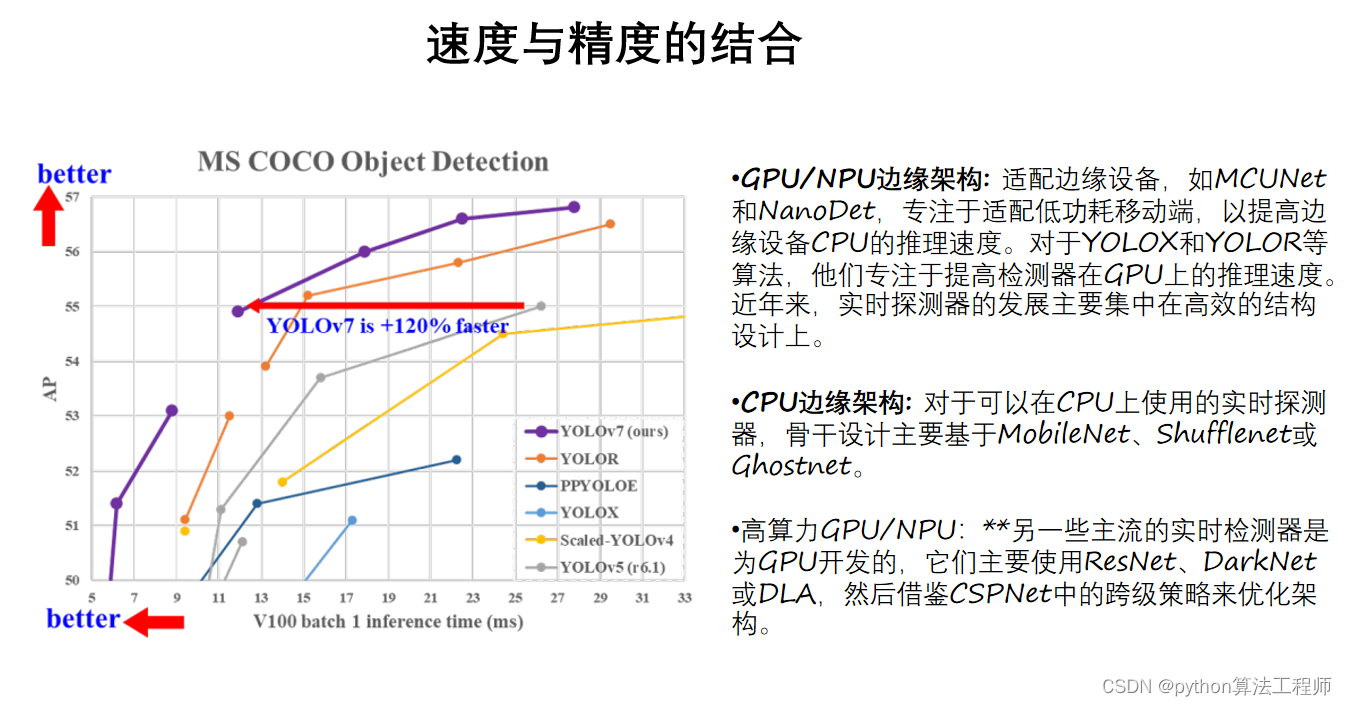
论文: https://arxiv.org/abs/2207.02696
论文: https://arxiv.org/abs/2207.02696
代码: https://github.com/WongKinYiu/yolov7
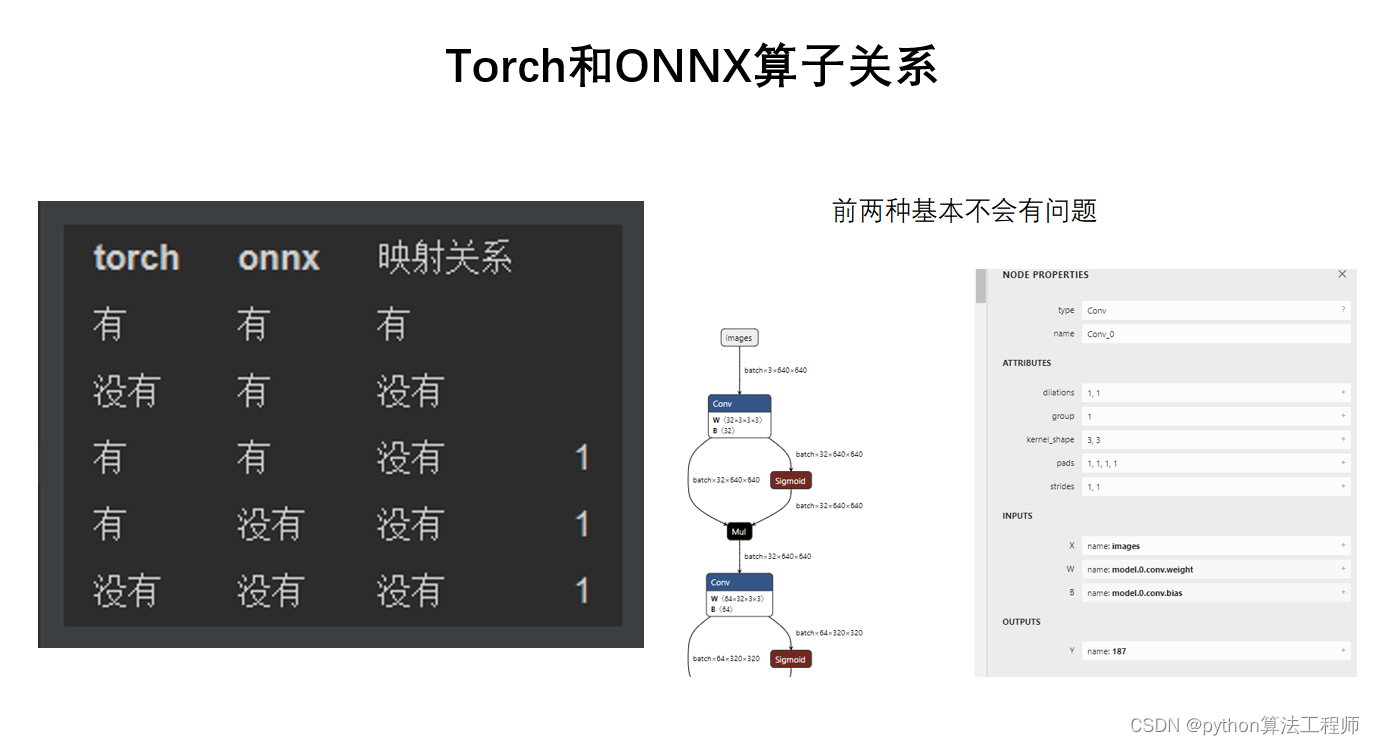
Anchor
Anchor是一种用于目标检测的先验框(prior box)生成方法,由Ren等人在2015年提出。Anchor可以在不同尺度和不同纵横比下生成多个先验框,并通过与真实目标框的匹配来预测目标的位置和类别。
在传统的目标检测方法中,先验框通常是手工设计的,因此需要人工经验和大量的实验来确定先验框的尺度和纵横比等参数。而Anchor方法则通过在输入图像的不同位置和尺度下生成多个先验框,并通过训练来自动学习先验框的参数,从而克服了手工设计先验框的局限性。
Anchor方法的核心思想是将目标检测任务转化为一个回归问题,即通过预测先验框与真实目标框之间的偏移量来确定目标的位置。同时,Anchor方法还引入了分类损失函数和位置损失函数,通过最小化损失函数来训练模型。在训练过程中,Anchor方法还采用了随机采样和在线硬负样本挖掘等技术,以提高模型的性能和鲁棒性。
总之,Anchor是一种用于目标检测的先验框生成方法,通过在不同尺度和不同纵横比下生成多个先验框,并通过训练来自动学习先验框的参数。Anchor方法可以克服手工设计先验框的局限性,并且在一些目标检测任务中取得了很好的效果。
FPN
FPN全称为Feature Pyramid Network,是一种用于目标检测和语义分割的神经网络结构,由Lin等人在2017年提出。FPN可以通过多层次的特征金字塔来提取图像特征,并通过横向连接和上采样操作来将不同层次的特征进行融合,从而实现高效的目标检测和语义分割。
FPN的核心思想是在特征金字塔中引入横向连接,将下采样得到的高分辨率特征图与上采样得到的低分辨率特征图进行融合。具体来说,FPN首先通过下采样操作从输入图像中提取多层次的特征图,然后通过上采样和卷积操作来将低分辨率特征图进行上采样,使其与高分辨率特征图在尺度上保持一致。最后,FPN通过横向连接和卷积操作将不同层次的特征图进行融合,从而得到更加丰富和准确的特征表示。
FPN的优点在于,它可以在不同尺度上提取丰富的特征信息,并通过横向连接和上采样操作将不同层次的特征进行融合,从而有效地解决了目标检测和语义分割中的尺度不一致和语义信息丢失等问题。此外,FPN还可以与不同的目标检测和语义分割算法相结合,实现更加高效和准确的图像分析任务。
总之,FPN是一种用于目标检测和语义分割的神经网络结构,通过横向连接和上采样操作将不同层次的特征进行融合,实现高效的图像分析任务。FPN在目标检测和语义分割领域取得了很好的效果,并且在许多现代的目标检测和语义分割算法中得到了广泛应用。
马赛克数据增强
马赛克数据增强是一种常见的图像数据增强技术,可以用于提高深度学习模型在目标检测、图像分割等任务中的性能。马赛克数据增强的核心思想是在图像中随机选取一些区域,然后用这些区域的平均值或中值来替换原图像中的像素值,从而产生一种模糊的效果,类似于图像中的马赛克。
具体来说,马赛克数据增强可以通过以下步骤来实现:
随机选取一些区域:在原图像中随机选取一些区域,可以使用固定大小的窗口或者根据图像大小和目标尺寸来计算合适的窗口大小。
生成马赛克效果:将选取的区域用区域内像素值的平均值或中值来替换原图像中的像素值,从而产生一种模糊的效果。
调整参数:可以根据需要调整马赛克窗口的大小和像素值替换的方法,以得到更好的数据增强效果。
马赛克数据增强可以帮助深度学习模型更好地学习和识别目标,从而提高模型的性能和鲁棒性。此外,马赛克数据增强还可以有效地防止过拟合,增加数据的多样性,从而提高模型的泛化能力。
总之,马赛克数据增强是一种常见的图像数据增强技术,可以用于提高深度学习模型在目标检测、图像分割等任务中的性能,防止过拟合,增加数据的多样性,提高模型的泛化能力。
FPN-pAN
FPN-pAN是一种用于目标检测的神经网络结构,由Tian等人在2019年提出。FPN-pAN是在FPN的基础上进一步改进而来,通过引入级联的注意力机制和双线性插值来提高目标检测的性能。
FPN-pAN的核心思想是将注意力机制和双线性插值结合起来,以提高多尺度特征的表示能力。具体来说,FPN-pAN使用级联的注意力机制来加权不同尺度的特征图,使得在低层次的特征图中重点关注目标的局部信息,而在高层次的特征图中重点关注目标的全局信息。同时,FPN-pAN还使用双线性插值来对低分辨率的特征图进行上采样,使其与高分辨率的特征图在尺度上保持一致,从而提高特征的表示能力。
FPN-pAN的优点在于,它可以有效地提高多尺度特征的表示能力,从而实现更加准确和鲁棒的目标检测。此外,FPN-pAN还具有可扩展性和通用性,可以与不同的目标检测算法相结合,适用于不同的图像数据集和应用场景。
总之,FPN-pAN是一种用于目标检测的神经网络结构,通过引入级联的注意力机制和双线性插值来提高多尺度特征的表示能力,实现更加准确和鲁棒的目标检测。FPN-pAN在目标检测领域取得了很好的效果,并且在许多现代的目标检测算法中得到了广泛应用。
REP
REP是一种用于图像分割的神经网络结构,由Yuan等人在2018年提出。REP可以有效地处理图像中的细节信息,并在保持低计算复杂度的同时实现高效的图像分割。
REP的核心思想是将图像分割任务分解为两个子任务:边缘预测和区域分割。具体来说,REP首先使用卷积神经网络对输入图像进行特征提取,然后将特征图分别输入到两个分支中进行处理。其中,边缘分支用于预测图像中的边缘信息,而区域分支则用于对图像进行分割。最后,REP通过将边缘信息与区域分割结果进行融合,得到最终的图像分割结果。
REP的优点在于,它可以有效地处理图像中的细节信息,从而实现更加准确的图像分割。同时,REP还具有低计算复杂度和易于实现等优点,适用于在资源受限的环境下进行图像分割。
总之,REP是一种用于图像分割的神经网络结构,通过将图像分割任务分解为边缘预测和区域分割两个子任务,并将其结果进行融合,实现更加准确和高效的图像分割。REP在图像分割领域取得了很好的效果,并且在许多现代的图像分割算法中得到了广泛应用。
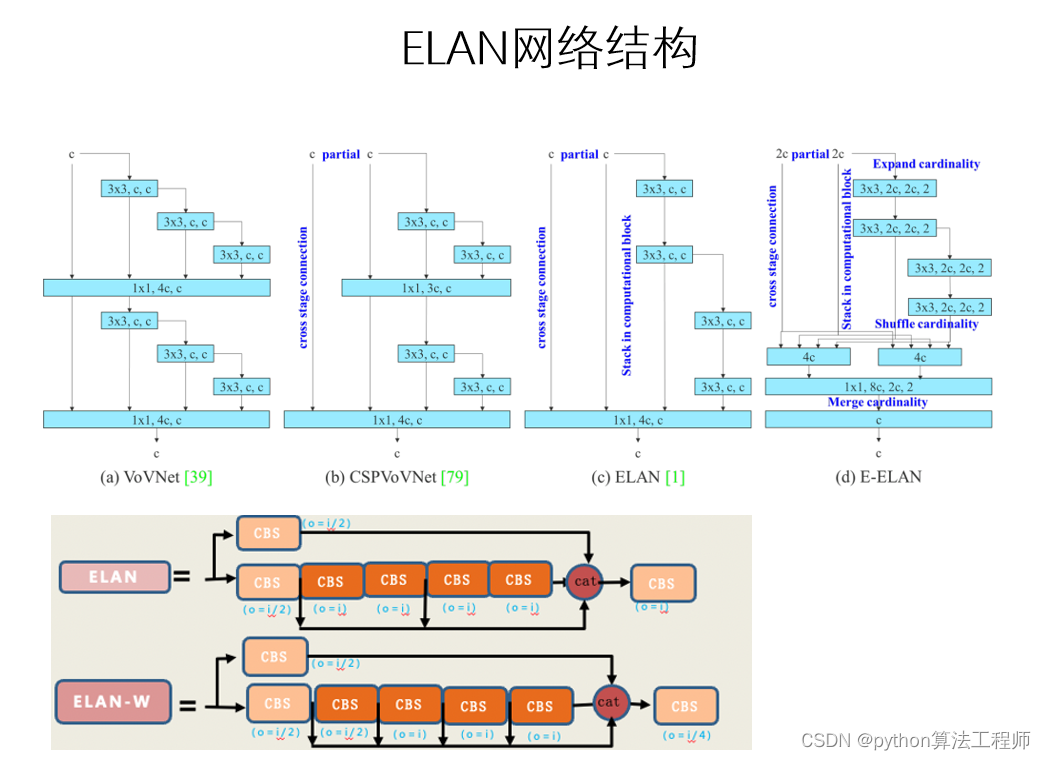
ELAN
ELAN是一种用于图像分割的神经网络结构,由Liu等人在2020年提出。ELAN可以有效地处理图像中的细节信息,并在保持高准确率的同时实现低计算复杂度和低存储成本。
ELAN的核心思想是将图像分割任务分解为两个子任务:边缘定位和区域分割。具体来说,ELAN首先使用卷积神经网络对输入图像进行特征提取,然后将特征图分别输入到两个分支中进行处理。其中,边缘定位分支用于预测图像中的边缘位置,而区域分割分支则用于对图像进行分割。最后,ELAN通过将边缘信息与区域分割结果进行融合,得到最终的图像分割结果。
ELAN的优点在于,它可以有效地处理图像中的细节信息,从而实现更加准确的图像分割。同时,ELAN还具有低计算复杂度和低存储成本的优点,适用于在资源受限的环境下进行图像分割。
总之,ELAN是一种用于图像分割的神经网络结构,通过将图像分割任务分解为边缘定位和区域分割两个子任务,并将其结果进行融合,实现更加准确和高效的图像分割。ELAN在图像分割领域取得了很好的效果,并且在许多现代的图像分割算法中得到了广泛应用。

全局池化层是一种常用于卷积神经网络中的池化层,它的作用是对输入特征图进行降维处理,从而得到全局的特征表示。
具体来说,全局池化层的操作是将输入特征图的每个通道上的所有元素进行平均池化或最大池化,得到每个通道上的一个标量输出,最终将所有通道上的标量输出进行拼接,得到全局的特征表示。
全局池化层的优点在于:
降低了计算量:全局池化层对输入特征图进行降维处理,降低了计算量,从而提高了网络的计算效率。
提高了网络的鲁棒性:全局池化层对输入特征图进行全局处理,能够得到更加全局的特征表示,从而提高了网络的鲁棒性。
防止过拟合:全局池化层对输入特征图进行降维处理,减少了网络的参数数量,从而防止了过拟合的发生。
全局池化层常用于卷积神经网络中的分类任务,例如在ResNet、Inception、VGG等经典网络结构中都采用了全局池化层。同时,全局池化层的设计思想也为解决计算机视觉领域的其他问题提供了新的思路和方法。
CSP模块是一种用于卷积神经网络的模块,全称为Cross Stage Partial
Network。它将输入特征图分成两部分,一部分进行卷积和通道数缩减,另一部分不做处理,然后将两部分特征图进行拼接,最后再进行残差连接。这种结构可以有效地提高网络的表示能力和计算效率。具体来说,CSP模块由以下几部分组成:
主分支:对输入特征图进行卷积和通道数缩减,得到主分支的输出。
支路分支:不对输入特征图做任何处理,直接将输入特征图和主分支输出进行拼接,得到支路分支的输出。
拼接层:将主分支输出和支路分支输出进行拼接,得到CSP模块的输出。
残差连接:将CSP模块的输出和输入特征图进行残差连接,得到最终的输出。
CSP模块的优点在于:
提高了网络的表示能力:CSP模块将输入特征图分成两部分,并对其中一部分进行卷积和通道数缩减,从而提高了网络的表示能力。
提高了网络的计算效率:CSP模块减少了计算量,从而提高了网络的计算效率。
易于扩展和优化:CSP模块的设计思想简单、清晰,易于扩展和优化,能够满足不同场景和任务的需求。
CSP模块被广泛应用于卷积神经网络中,例如CSPDarknet53网络结构中就采用了CSP模块。同时,CSP模块的设计思想和网络结构也为解决计算机视觉领域的其他问题提供了新的思路和方法。
CSPDarknet53的网络结构分为两部分:前半部分是由一系列CSP模块和池化层组成的特征提取网络;后半部分是由全局池化层、全连接层和Softmax层组成的分类网络。CSP模块是该网络的核心部分,它包含两个分支:主分支和支路分支。主分支对输入特征图进行卷积和通道数缩减,然后将结果进行拼接;支路分支不对输入特征图做任何处理,直接将输入特征图和主分支输出进行拼接,最后再通过残差连接将两部分特征图相加。
CSPDarknet53的优点在于:
高效的特征提取:CSP模块能够有效地提高网络的表示能力和计算效率,从而实现更加高效的特征提取。
高精度的分类:CSPDarknet53采用了全局池化层、全连接层和Softmax层来构建分类网络,能够实现更加高精度的分类。
易于扩展和优化:CSPDarknet53的网络结构简单、清晰,易于扩展和优化,能够满足不同场景和任务的需求。
YOLOv7的网络结构分为两部分:主干网络和头部网络。
主干网络采用了CSPDarknet53架构,它是一种高效的卷积神经网络结构,能够有效地提取图像特征。具体来说,CSPDarknet53采用了“Cross Stage Partial Network”(CSP)模块来构建网络结构,该模块将输入特征图分成两部分,一部分进行卷积和通道数缩减,另一部分不做处理,然后将两部分特征图进行拼接,最后再进行残差连接。这种结构可以有效地提高网络的表示能力和计算效率。
头部网络则负责检测目标,并生成边界框和类别预测。头部网络由多个卷积层和池化层组成,其中包括3个输出层,用于检测不同尺度的目标。每个输出层都会生成一组边界框和类别预测,然后通过非极大值抑制(NMS)算法来剔除重复的边界框,得到最终的检测结果。
YOLOv7采用了一些新的技术和优化,包括:
1.新的特征融合方法:YOLOv7采用了一种新的特征融合方法,能够更加精确地捕捉目标特征。具体来说,它采用了“SPP-FPN”结构,将不同尺度的特征图进行特征金字塔融合,从而提高了检测准确率。
2.新的分类器:YOLOv7采用了一种新的分类器,能够更加准确地预测目标类别。具体来说,它采用了“Class Activation Mapping”(CAM)算法,将分类器的输出可视化为图像,从而更加直观地理解分类器的预测结果。
3.新的优化技术:YOLOv7采用了一些新的优化技术,包括“MixUp”数据增强、“DropBlock”正则化和“ResDrop”残差连接等,能够在保持准确率的同时大幅提高推理速度。
总之,YOLOv7的网络结构采用了CSPDarknet53和SPP-FPN等先进的技术和优化,能够在保持准确率的同时大幅提高检测速度和效率。YOLOv7的设计思想和网络结构为解决目标检测问题提供了新的思路和方法,对于推动计算机视觉领域的发展具有重要的意义。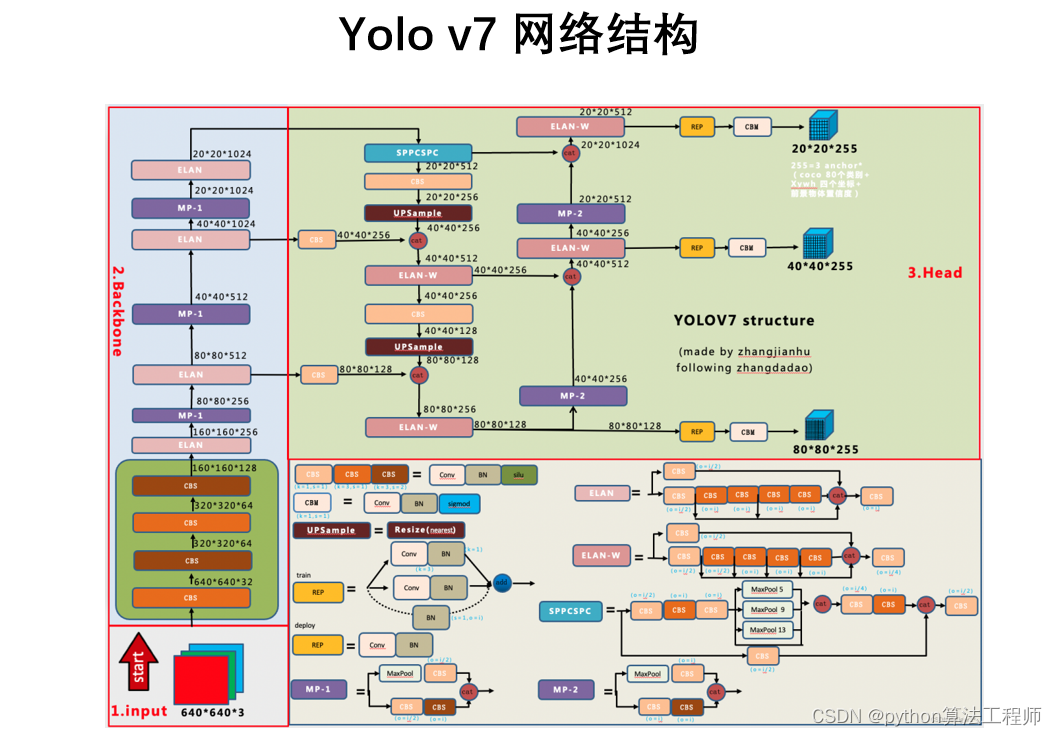
ELAN的网络结构主要由两个分支构成:边缘定位分支和区域分割分支。边缘定位分支用于预测图像中的边缘位置,区域分割分支则用于对图像进行分割。两个分支的输出结果在最后进行融合得到最终的分割结果。ELAN采用了“局部聚合”的机制来提高特征的表示能力,即在每个卷积层中,都会对局部区域进行聚合,从而提高特征的代表性和区分度。此外,ELAN还采用了边缘引导的方式,通过引入边缘信息来指导区域分割,从而提高分割的准确率和鲁棒性。
ELAN在多个公开数据集上进行了实验验证,并与其他现有的图像分割方法进行了比较。实验结果表明,ELAN不仅具有较高的分割准确率,而且具有较低的计算复杂度和存储成本。因此,ELAN适用于在资源受限的环境下进行图像分割,例如移动设备和嵌入式系统等。
VoVNet是一种基于轻量化网络设计的卷积神经网络结构,全称为“Vortex of Vectorized Neural Network”。该网络结构是由美国华盛顿大学的研究人员于2019年提出的,旨在解决当前计算机视觉中的一些问题,如物体检测、图像分类等。
VoVNet的特点是采用了一种新的网络模块,称为“Vortex”,它是一种基于轻量化设计的卷积模块,能够有效地提高网络的表示能力和计算效率。Vortex模块采用了分离卷积和跨层连接等技术,能够有效地处理诸如高分辨率、多种比例和多种通道等复杂的输入模式,从而提高网络的泛化能力和鲁棒性。
VoVNet网络结构主要由一系列Vortex模块和池化层组成,其中每个Vortex模块内部包含了多个分支,每个分支都采用了不同大小的卷积核和不同数量的通道,从而能够提取出不同尺度和不同层次的特征表示。此外,VoVNet还采用了通道注意力机制,能够自适应地调整各个通道的权重,从而进一步提高网络的表示能力。
VoVNet相对于传统的卷积神经网络具有以下优点:
更高的表示能力:采用轻量化设计的Vortex模块,能够提高网络的表示能力。
更高的计算效率:采用分离卷积和跨层连接等技术,能够减少网络的参数数量和计算量,从而提高网络的计算效率。
更强的泛化能力:采用了多尺度和多层次的特征表示,能够提高网络的泛化能力和鲁棒性。
VoVNet已经被广泛应用于计算机视觉领域中的各种任务,如图像分类、目标检测、语义分割等。同时,VoVNet的设计思想和网络结构也为解决计算机视觉领域的其他问题提供了新的思路和方法。
DenseNet是一种基于密集连接的卷积神经网络结构,全称为“Dense Convolutional Network”。该网络结构是由斯坦福大学的研究人员于2017年提出的,旨在解决当前计算机视觉中的一些问题,如梯度消失、特征稀疏、网络参数过多等。
DenseNet的特点是采用了密集连接设计,即将每层的输出与前面所有层的输出连接在一起,从而能够构建出一个非常深的网络结构。这种设计方式能够有效地提高网络的表示能力和计算效率,同时还能够减少梯度消失和特征稀疏等问题的出现。
DenseNet网络结构主要由多个Dense Block和Transition Layer组成,其中Dense Block是密集连接的基本模块,包含了多个卷积层和池化层,每个卷积层的输入都是前面所有层的输出连接在一起,从而能够保留更多的特征信息。而Transition Layer则用于调整网络的通道数和分辨率,以便适应不同的任务需求。
DenseNet相对于传统的卷积神经网络具有以下优点:
更高的表示能力:采用密集连接设计,能够充分保留特征信息,从而提高网络的表示能力。
更少的参数:采用了共享权值的设计,能够减少网络的参数数量,从而降低过拟合的风险。
更强的泛化能力:采用了残差学习和批量归一化等技术,能够提高网络的泛化能力和鲁棒性。
DenseNet已经被广泛应用于计算机视觉领域中的各种任务,如图像分类、目标检测、语义分割等。同时,DenseNet的设计思想和网络结构也为解决计算机视觉领域的其他问题提供了新的思路和方法。
 MP降维结构是一种用于卷积神经网络中的特征降维结构,全称为“Max-Pooling Reduction”。该结构是由谷歌公司的研究人员于2016年提出的,旨在解决当前计算机视觉中的一些问题,如计算量过大、特征稀疏等。
MP降维结构是一种用于卷积神经网络中的特征降维结构,全称为“Max-Pooling Reduction”。该结构是由谷歌公司的研究人员于2016年提出的,旨在解决当前计算机视觉中的一些问题,如计算量过大、特征稀疏等。
MP降维结构的特点是采用了最大池化和卷积操作相结合的方式进行特征降维,从而能够有效地减少特征稀疏和计算量等问题的出现。具体来说,MP降维结构的操作包括以下几个步骤:
采用多个不同大小的卷积核对输入特征图进行卷积操作,得到多个卷积特征图。
对每个卷积特征图进行最大池化操作,得到每个特征图上的最大值。
将每个特征图上的最大值进行拼接,得到一个全局的特征向量。
对全局特征向量进行全连接操作,得到最终的输出结果。
MP降维结构相对于传统的卷积神经网络具有以下优点:
更少的计算量:采用最大池化操作,能够有效地减少计算量,提高网络的计算效率。
更高的特征表达能力:采用多个卷积核和拼接操作,能够提高特征表达能力,从而提高网络的表示能力。
更强的泛化能力:采用了批量归一化和残差连接等技术,能够提高网络的泛化能力和鲁棒性。
MP降维结构已经被广泛应用于计算机视觉领域中的各种任务,如图像分类、目标检测、语义分割等。同时,MP降维结构的设计思想和网络结构也为解决计算机视觉领域的其他问题提供了新的思路和方法。

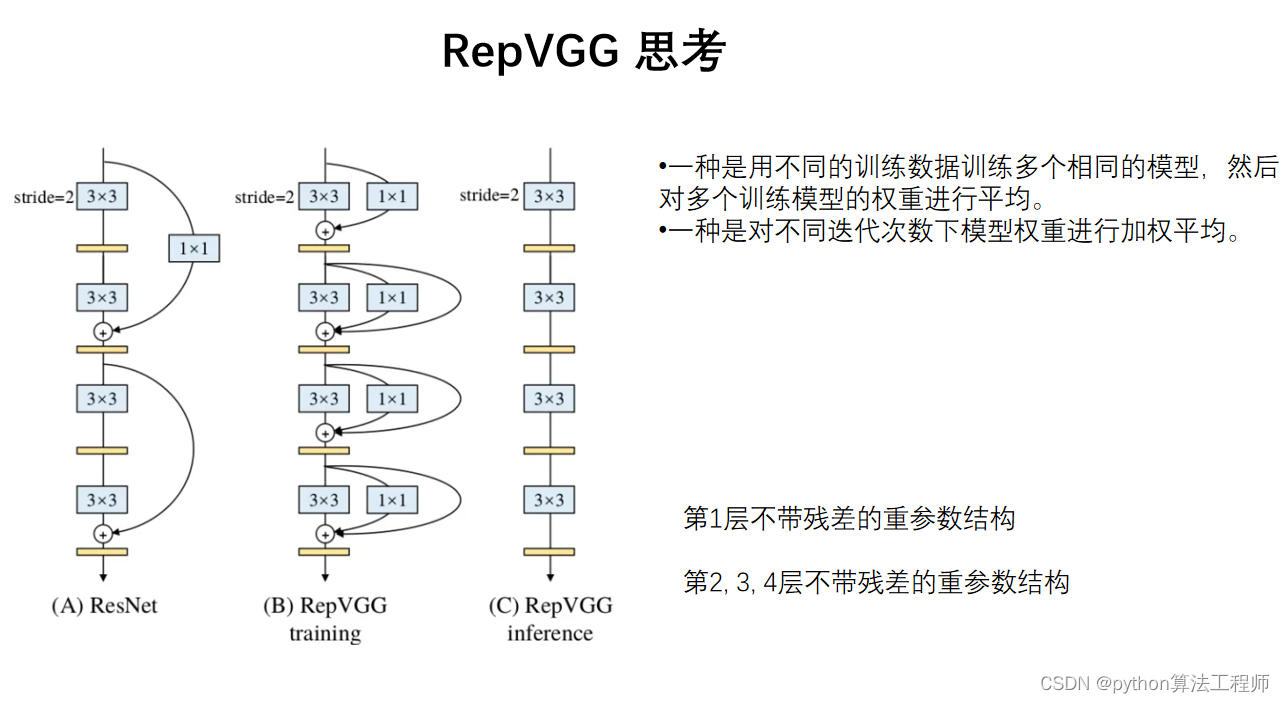
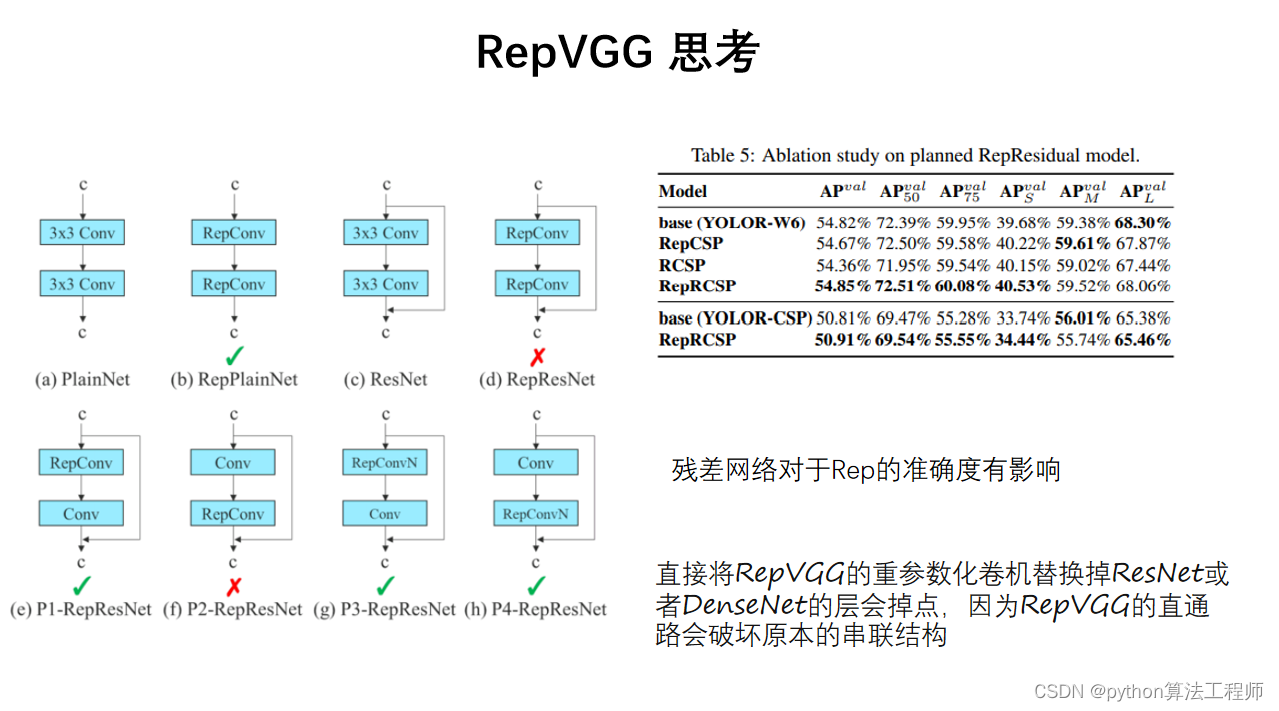
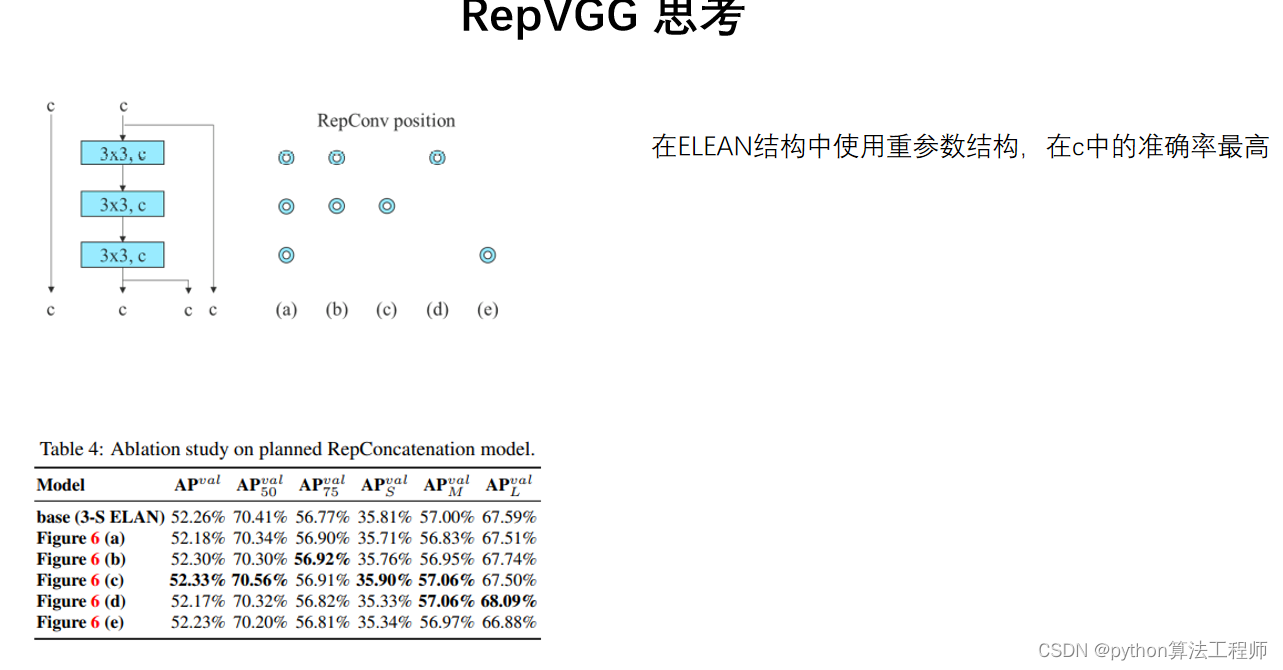
RepVGG是一种基于卷积神经网络的网络结构,全称为“Reparameterized Convolutional Neural Network”。该网络结构是由华为公司的研究人员于2021年提出的,旨在解决当前计算机视觉中的一些问题,如模型参数过多、计算量过大等。
RepVGG的特点是采用了可重参数化卷积和残差连接的设计方式,能够构建出一个非常深的网络结构,并且只需要很少的参数量。具体来说,RepVGG网络结构主要分为两个部分:基础网络和解析网络。
基础网络部分采用了可重参数化卷积的设计方式,将传统的卷积层替换为可重参数化卷积层,从而能够减少网络的参数量和计算量。可重参数化卷积层的设计方式是将传统的卷积核拆分成两个矩阵,一个用于卷积操作,另一个用于重参数化,从而实现了卷积操作和重参数化操作的分离。
解析网络部分采用了残差连接的设计方式,将基础网络部分得到的特征图与输入特征图进行残差连接,从而能够提高网络的表示能力和泛化能力。
RepVGG相对于传统的卷积神经网络具有以下优点:
更少的参数量:采用可重参数化卷积的设计方式,能够减少网络的参数量和计算量,提高网络的计算效率。
更高的表示能力:采用残差连接的设计方式,能够提高网络的表示能力和泛化能力。
更强的泛化能力:采用了批量归一化和残差连接等技术,能够提高网络的泛化能力和鲁棒性。
RepVGG已经被广泛应用于计算机视觉领域中的各种任务,如图像分类、目标检测、语义分割等。同时,RepVGG的设计思想和网络结构也为解决计算机视觉领域的其他问题提供了新的思路和方法。
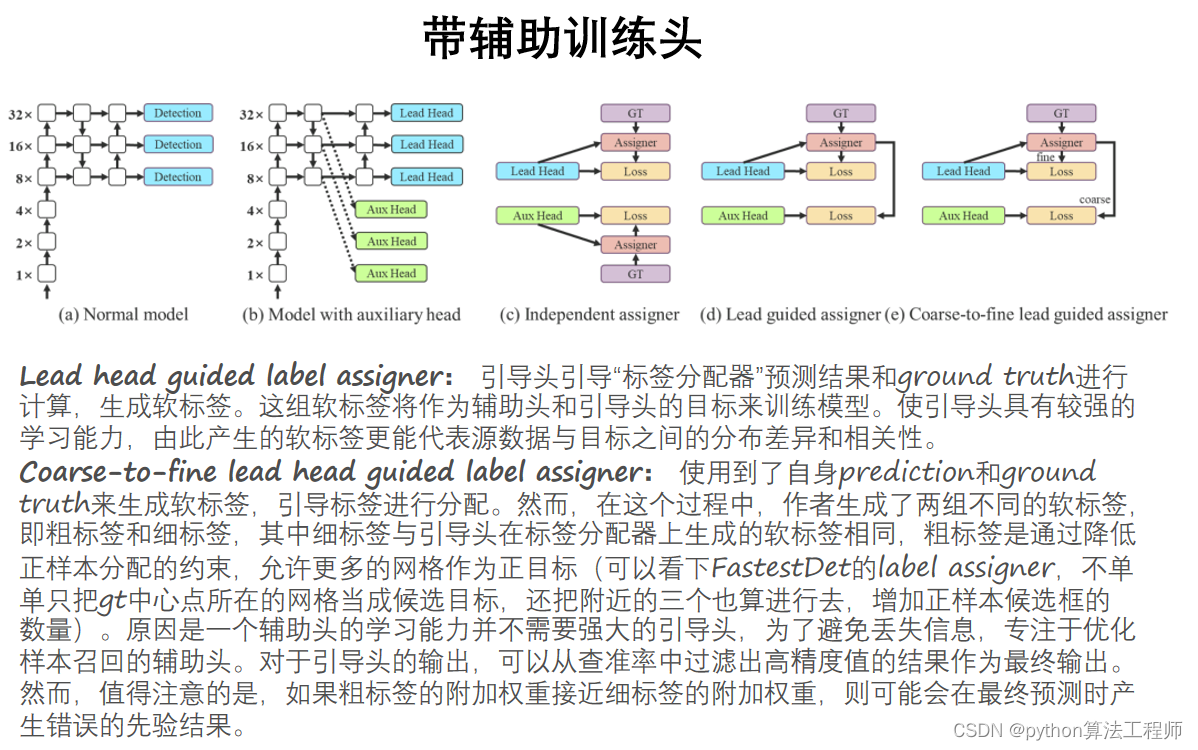
 辅助训练头(Auxiliary Heads)是一种用于卷积神经网络中的辅助分类器,通常用于解决深层神经网络训练中的梯度消失和模型过拟合等问题。
辅助训练头(Auxiliary Heads)是一种用于卷积神经网络中的辅助分类器,通常用于解决深层神经网络训练中的梯度消失和模型过拟合等问题。
辅助训练头的设计方式是在网络的中间层添加一个分支,该分支包含一个或多个卷积层和全局平均池化层,用于提取中间层的特征表示,并在该分支上添加一个分类器,用于进行分类任务的预测。辅助训练头的输出结果可以与主分类器的输出结果进行结合,从而提高网络的泛化能力和减少模型过拟合的风险。
辅助训练头相对于传统的卷积神经网络具有以下优点:
缓解梯度消失:由于辅助训练头在网络的中间层添加了分类器,可以有效地缓解网络训练过程中的梯度消失问题。
减少过拟合:在训练过程中,辅助训练头可以作为一种正则化机制,从而减少模型的过拟合风险。
提高泛化能力:通过结合辅助训练头和主分类器的输出结果,可以提高网络的泛化能力和分类精度。
辅助训练头已经被广泛应用于计算机视觉领域中的各种任务,如图像分类、目标检测、语义分割等。同时,辅助训练头也为解决深层神经网络训练中的一些问题提供了新的思路和方法。
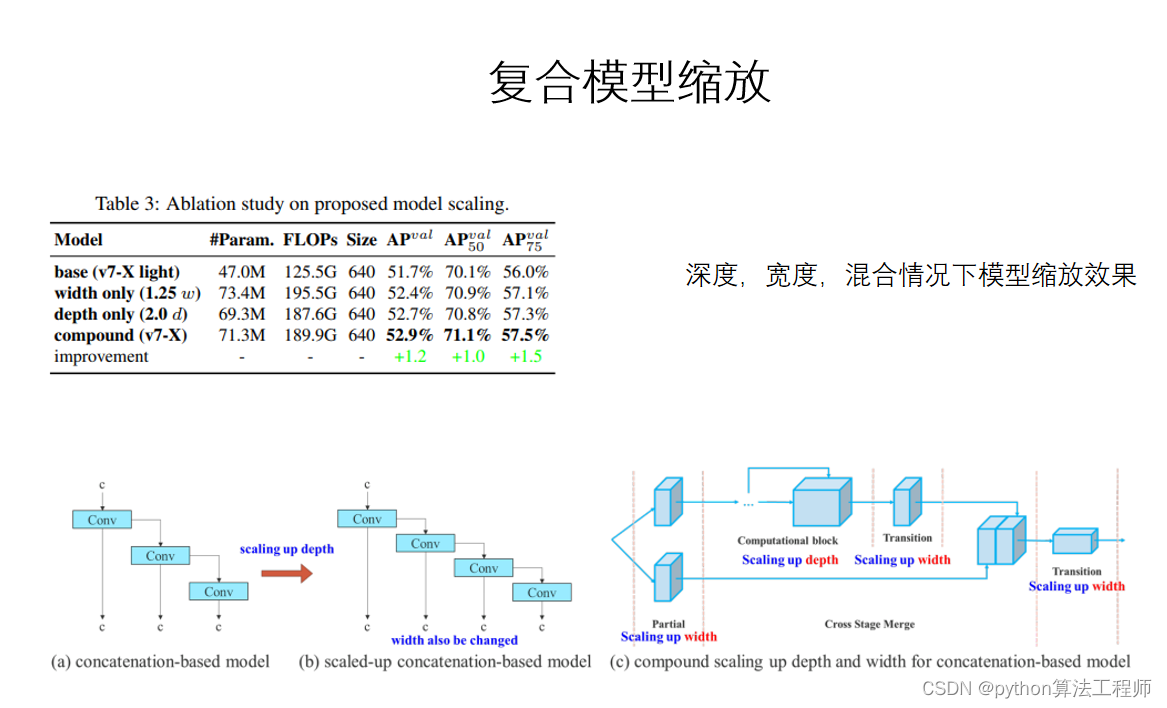
 复合模型缩放(Ensemble Model Scaling)是一种用于卷积神经网络中的模型优化方法,主要目的是通过组合多个模型的预测结果,提高模型的预测精度和稳定性。
复合模型缩放(Ensemble Model Scaling)是一种用于卷积神经网络中的模型优化方法,主要目的是通过组合多个模型的预测结果,提高模型的预测精度和稳定性。
复合模型缩放的基本思想是,将多个预测模型的输出结果进行加权平均,从而得到一个最终的预测结果。加权平均的权重可以根据模型的预测精度和稳定性进行调整,从而使得最终的预测结果更加准确和可靠。
具体来说,复合模型缩放包括以下几个步骤:
训练多个预测模型:通过训练多个不同的卷积神经网络,得到多个预测模型。
进行预测:使用多个预测模型对待预测数据进行预测,得到多个预测结果。
加权平均:对多个预测结果进行加权平均,得到最终的预测结果。权重可以根据模型的预测精度和稳定性进行调整。
复合模型缩放相对于传统的单一模型具有以下优点:
提高预测精度:通过组合多个预测模型的输出结果,可以提高预测精度和稳定性。
减少过拟合:由于使用了多个不同的预测模型,可以减少模型的过拟合风险。
更好的泛化能力:通过使用多个不同的预测模型,可以提高模型的泛化能力,适应更多的预测场景。
复合模型缩放已经被广泛应用于计算机视觉领域中的各种任务,如图像分类、目标检测、语义分割等。同时,复合模型缩放也为解决模型预测精度和稳定性等问题提供了新的思路和方法。
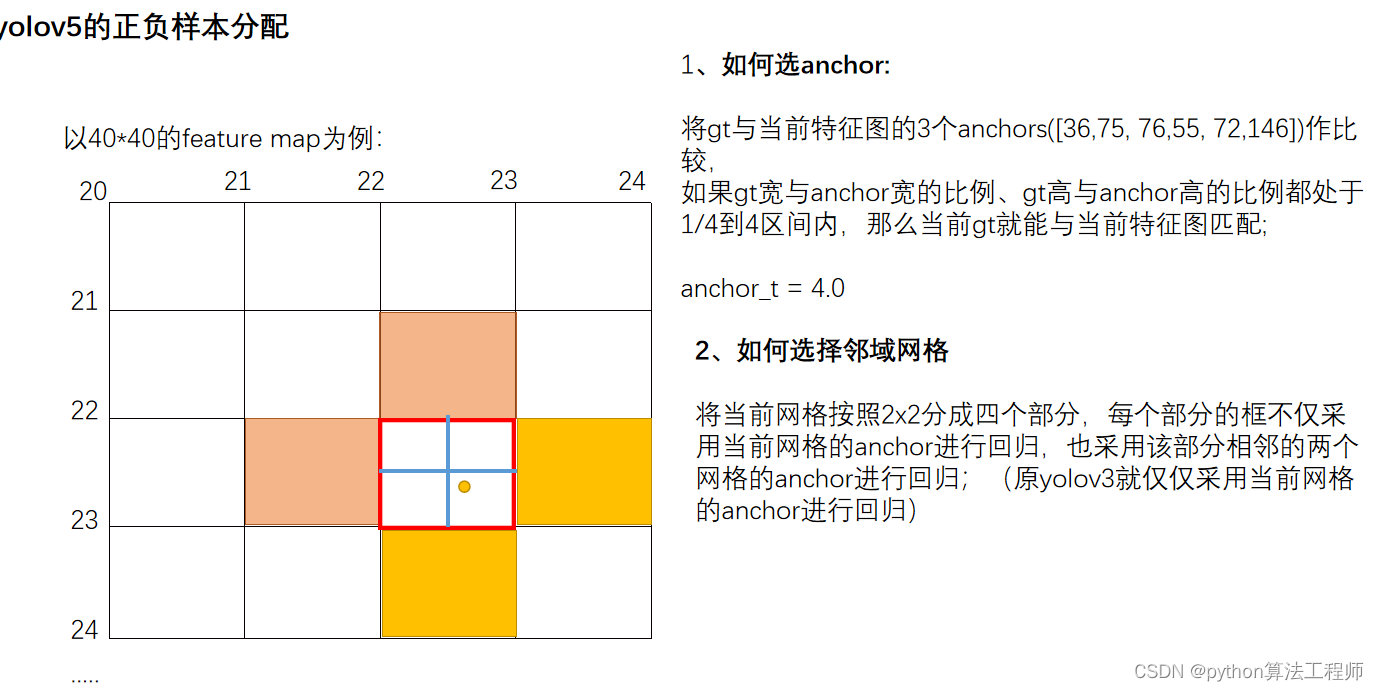
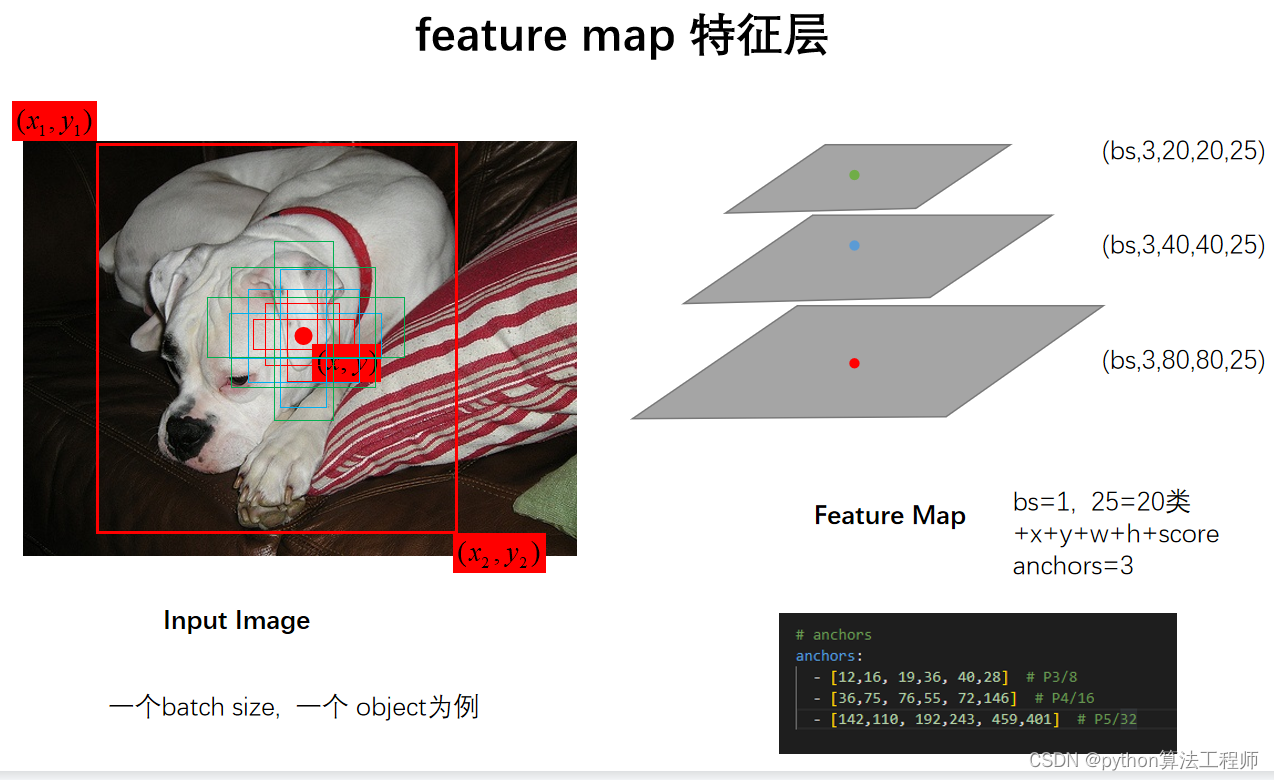 YOLOv7使用了一种基于IoU(Intersection over Union)的正负样本分配策略,即根据候选框与真实框之间的IoU值判断候选框是正样本还是负样本。
YOLOv7使用了一种基于IoU(Intersection over Union)的正负样本分配策略,即根据候选框与真实框之间的IoU值判断候选框是正样本还是负样本。
具体来说,对于每个真实框,YOLOv7会在候选框中选择一个IoU值最大的候选框作为正样本,并且将其IoU值设置为该候选框的最大IoU值。同时,对于每个候选框,如果其IoU值大于阈值(默认为0.5),则将其视为正样本;如果其IoU值小于阈值,则将其视为负样本。这种正负样本分配策略能够有效地提高模型的检测精度和鲁棒性。
此外,YOLOv7还引入了一种难样本挖掘(Hard Example Mining)的方法,即对于一些难以分类的样本,将其视为正样本进行训练,从而进一步提高模型的性能。
总之,YOLOv7的正负样本分配策略基于IoU值,能够有效地提高模型的检测精度和鲁棒性。同时,难样本挖掘的方法也为解决一些复杂场景下的目标检测问题提供了新的思路和方法。

 YOLOv7的损失函数包括三个部分:目标检测损失、分类损失和框回归损失。
YOLOv7的损失函数包括三个部分:目标检测损失、分类损失和框回归损失。
目标检测损失:目标检测损失主要用于度量模型对检测目标的准确性。YOLOv7采用了Focal Loss作为目标检测损失函数,它能够解决样本类别不平衡问题,从而提高模型的分类精度。
分类损失:分类损失用于度量模型对目标类别的识别能力。YOLOv7采用了Cross-Entropy Loss作为分类损失函数,它能够有效地提高模型的分类精度。
框回归损失:框回归损失主要用于度量模型对目标位置的准确性。YOLOv7采用了Smooth L1 Loss作为框回归损失函数,它能够在保持较好回归精度的同时,抑制异常值的影响,提高模型的鲁棒性。
YOLOv7的损失函数的简化表达式:
L
=
L
o
b
j
+
λ
c
l
s
L
c
l
s
+
λ
r
e
g
L
r
e
g
L = L_{obj} + \lambda_{cls} L_{cls} + \lambda_{reg} L_{reg}
L=Lobj+λclsLcls+λregLreg
目标检测损失
L
o
b
j
L_{obj}
Lobj计算公式如下:
L o b j = ∑ i = 0 S 2 ∑ j = 0 B ( 1 i , j o b j BCE ( y ^ i , j o b j , y i , j o b j ) + 1 i , j n o o b j α i , j n o o b j BCE ( y ^ i , j o b j , y i , j o b j ) ) L_{obj} = \sum_{i=0}^{S^2}\sum_{j=0}^{B}(1_{i,j}^{obj}\text{ } \text{BCE}(\hat{y}{i,j}^{obj},y{i,j}^{obj})+1_{i,j}^{noobj}\alpha_{i,j}^{noobj}\text{ } \text{BCE}(\hat{y}{i,j}^{obj},y{i,j}^{obj})) Lobj=i=0∑S2j=0∑B(1i,jobj BCE(y^i,jobj,yi,jobj)+1i,jnoobjαi,jnoobj BCE(y^i,jobj,yi,jobj))
其中, L i , j o b j L_{i,j}^{obj} Li,jobj和 L i , j n o o b j L_{i,j}^{noobj} Li,jnoobj分别表示该单元格是否包含目标, α i , j n o o b j \alpha_{i,j}^{noobj} αi,jnoobj表示目标不存在时的权重系数, y ^ i , j o b j \hat{y}{i,j}^{obj} y^i,jobj表示模型预测的目标存在概率, y i , j o b j y{i,j}^{obj} yi,jobj表示对应的真实值。
分类损失 L c l s L_{cls} Lcls计算公式如下:
L c l s = ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j BCE ( y ^ i , j c l s , y i , j c l s ) L_{cls} = \sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{i,j}^{obj}\text{ } \text{BCE}(\hat{y}{i,j}^{cls},y{i,j}^{cls}) Lcls=i=0∑S2j=0∑B1i,jobj BCE(y^i,jcls,yi,jcls)
其中, y ^ i , j c l s \hat{y}{i,j}^{cls} y^i,jcls表示模型预测的目标类别概率, y i , j c l s y{i,j}^{cls} yi,jcls表示对应的真实值。
框回归损失 L r e g L_{reg} Lreg计算公式如下:
L r e g = ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j SmoothL1 ( y ^ i , j b o x , y i , j b o x ) L_{reg} = \sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{i,j}^{obj}\text{ } \text{SmoothL1}(\hat{y}{i,j}^{box},y{i,j}^{box}) Lreg=i=0∑S2j=0∑B1i,jobj SmoothL1(y^i,jbox,yi,jbox)
其中,
y
^
i
,
j
b
o
x
\hat{y}{i,j}^{box}
y^i,jbox表示模型预测的边界框坐标,
y
i
,
j
b
o
x
y{i,j}^{box}
yi,jbox表示对应的真实值。Smooth L1 Loss是一种平滑的L1 Loss,能够在保持较好回归精度的同时,抑制异常值的影响,提高模型的鲁棒性。
其中,
L
o
b
j
L_{obj}
Lobj表示目标检测损失,
L
c
l
s
L_{cls}
Lcls表示分类损失,
L
r
e
g
L_{reg}
Lreg表示框回归损失,
λ
c
l
s
\lambda_{cls}
λcls和
λ
r
e
g
\lambda_{reg}
λreg分别表示分类损失和框回归损失的权重系数。

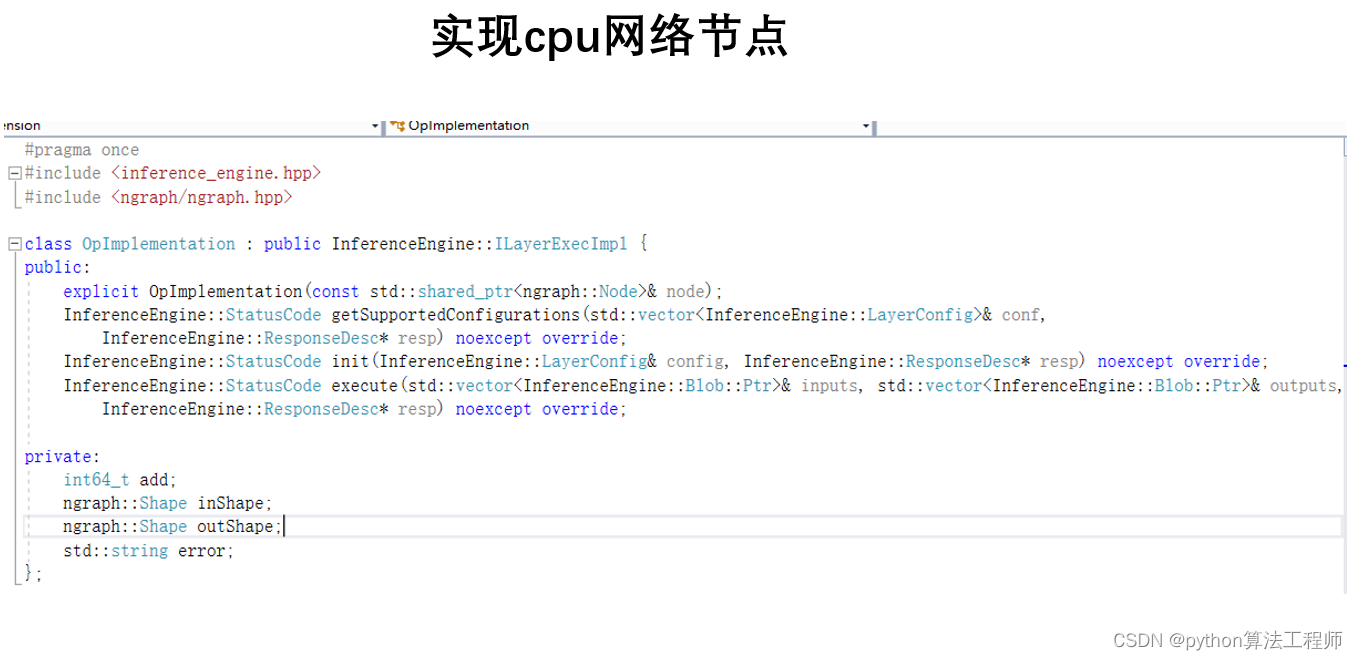
OpenVINO 部署
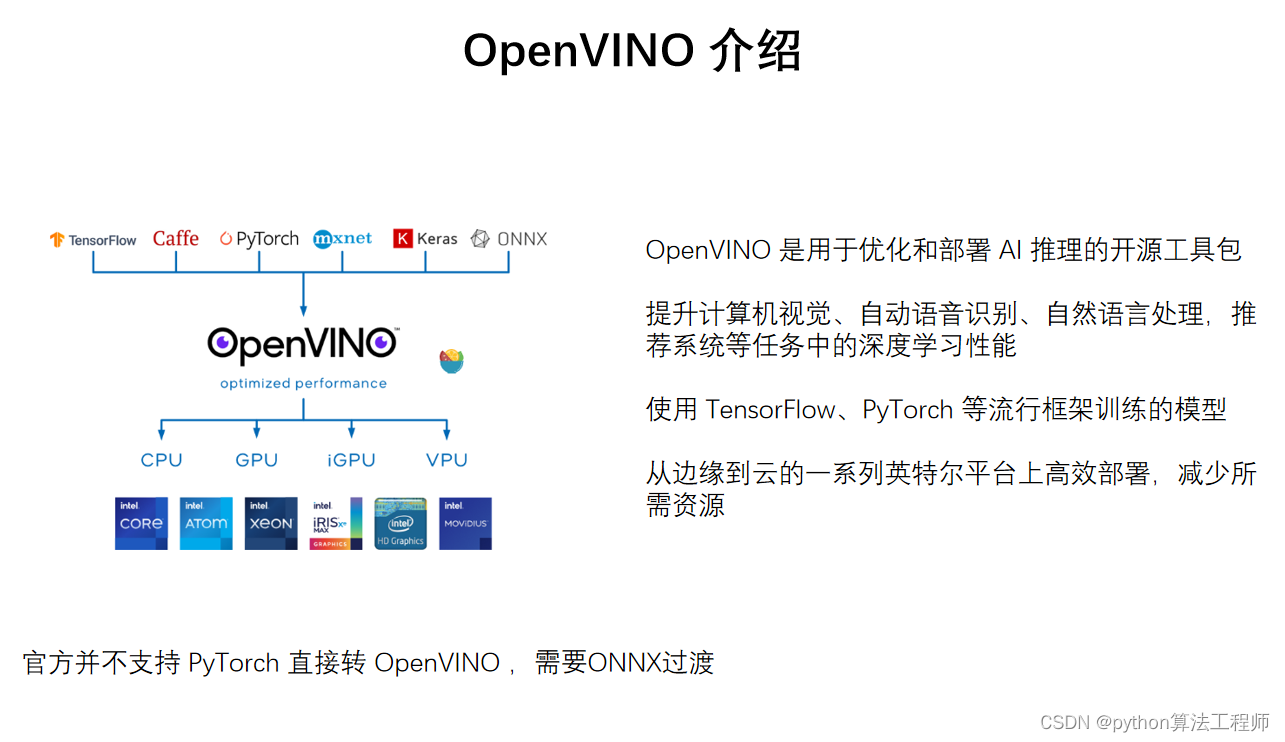
OpenVINO(Open Visual Inference and Neural network Optimization)是英特尔推出的一套端到端的深度学习推理工具集,旨在帮助开发者加速深度学习模型的推理过程。它可以在各种设备上运行,包括英特尔的CPU、集成GPU、FPGA和神经计算棒(Neural Compute Stick)等,从而实现高效的推理加速。
OpenVINO主要包括以下几个组件:
Model Optimizer:将深度学习框架训练出来的模型转换为OpenVINO可以使用的中间表示(Intermediate Representation,IR),并对其进行优化,使其更适合于在英特尔硬件上进行推理。
Inference Engine:用于在英特尔硬件上进行深度学习模型的推理。它支持多种推理引擎,包括CPU、集成GPU、FPGA、神经计算棒等,可以根据不同的场景和需求选择不同的硬件加速方案。
Pre-Trained Models:OpenVINO还提供了一些预训练好的深度学习模型,包括人脸检测、人脸识别、姿态估计、车辆检测等多个领域。用户可以直接使用这些模型进行推理,也可以基于这些模型进行二次开发。
Deep Learning Workbench:是一个可视化工具,用于对深度学习模型进行训练、优化和部署。用户可以通过图形化界面快速构建和调整模型,同时也可以在工作台上进行模型训练和调试。
OpenVINO的优势在于它可以在多种硬件平台上进行高效的深度学习模型推理。同时,其模型优化和转换工具也能够帮助开发者更方便地部署深度学习模型,提高模型的推理性能和精度。
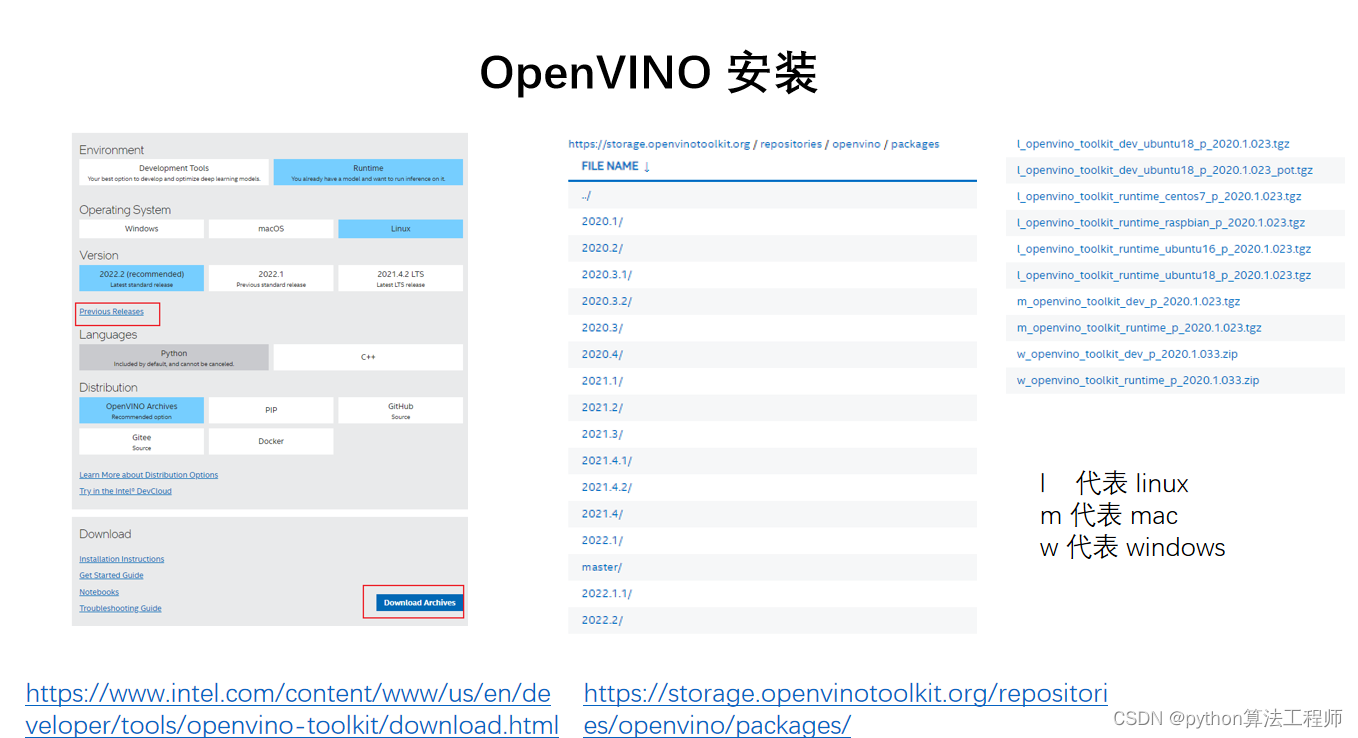
 以下是在Ubuntu 18.04上安装OpenVINO的步骤:
以下是在Ubuntu 18.04上安装OpenVINO的步骤:
下载并安装OpenVINO。
a. 访问OpenVINO官网下载页面:
https://software.intel.com/content/www/us/en/develop/tools/openvino-toolkit/download.html
b. 下载所需版本的OpenVINO安装包,例如:l_openvino_toolkit_p_2021.3.394.tgz
c. 将安装包解压到合适的目录下,例如:/opt/intel/openvino_2021/
tar -xzf l_openvino_toolkit_p_2021.3.394.tgz
cd /opt/intel/openvino_2021/install_dependencies
sudo -E ./install_openvino_dependencies.sh
cd ..
sudo ./install.sh
d. 安装过程中会提示输入许可证协议的同意,以及选择安装组件的选项。根据需要进行选择和确认。
配置OpenVINO。
a. 运行配置脚本:/opt/intel/openvino_2021/bin/setupvars.sh
source /opt/intel/openvino_2021/bin/setupvars.sh
b. 运行命令添加OpenVINO环境变量到bashrc文件中,以便每次登录自动设置环境变量。
echo "source /opt/intel/openvino_2021/bin/setupvars.sh" >> ~/.bashrc
source ~/.bashrc
安装Python API。
a. 安装Python3和pip3。
sudo apt-get update
sudo apt-get install python3 python3-pip
b. 安装OpenVINO Python API。
cd /opt/intel/openvino_2021/deployment_tools/inference_engine/samples/python/
sudo -H pip3 install -r requirements.txt
sudo python3 setup.py install
安装模型优化器。
a. 安装CMake。
sudo apt-get install cmake
b. 安装模型优化器。
cd /opt/intel/openvino_2021/deployment_tools/model_optimizer/
sudo apt-get install python3-pip
sudo -H pip3 install -r requirements.txt
sudo python3 setup.py install
安装完成后,可以在终端中输入以下命令进行测试:
cd /opt/intel/openvino_2021/deployment_tools/demo/
./demo_squeezenet_download_convert_run.sh
该命令会下载、转换和运行SqueezeNet模型。如果一切正常,将会看到模型推理的结果。
 以下是使用OpenVINO进行深度学习模型推理的基本流程:
以下是使用OpenVINO进行深度学习模型推理的基本流程:
准备模型。
a. 在深度学习框架中训练模型,并将其保存为支持的模型格式(如TensorFlow、Caffe、MXNet等)。
b. 使用OpenVINO Model Optimizer将模型转换为OpenVINO IR格式,以便在OpenVINO Inference Engine中进行推理。可以使用以下命令进行转换:
python3 mo.py --input_model <path_to_model> --output_dir <output_directory> --data_type <data_type>
其中,<path_to_model>是源模型路径,<output_directory>是输出路径,<data_type>是指定数据类型(如FP32、FP16、INT8等)。
创建Inference Engine实例。
a. 导入OpenVINO库并初始化Inference Engine。
from openvino.inference_engine import IECore
ie = IECore()
b. 加载IR模型文件。
net = ie.read_network(model="<path_to_xml_file>", weights="<path_to_bin_file>")
其中,<path_to_xml_file>是IR模型的XML文件路径,<path_to_bin_file>是IR模型的bin文件路径。
配置输入和输出。
a. 获取模型输入和输出的名称。
input_name = next(iter(net.inputs))
output_name = next(iter(net.outputs))
b. 获取模型输入和输出的形状。
input_shape = net.inputs[input_name].shape
output_shape = net.outputs[output_name].shape
c. 创建输入和输出Blobs。
input_blob = next(iter(exec_net.inputs))
output_blob = next(iter(exec_net.outputs))
进行推理。
a. 创建执行引擎。
exec_net = ie.load_network(network=net, device_name="<device_name>")
其中,<device_name>是设备的名称,如CPU、GPU、FPGA等。
b. 准备输入数据。
input_data = np.random.rand(*input_shape)
c. 进行推理。
result = exec_net.infer(inputs={input_name: input_data})
d. 获取输出结果。
output_data = result[output_name]
处理输出数据。
a. 根据需要将输出数据转换为合适的格式,如图像、文本、音频等。
b. 对输出数据进行后处理,如解码、解析、可视化等。
以上是使用OpenVINO进行深度学习模型推理的基本流程,具体操作可以根据实际需求进行调整和优化。
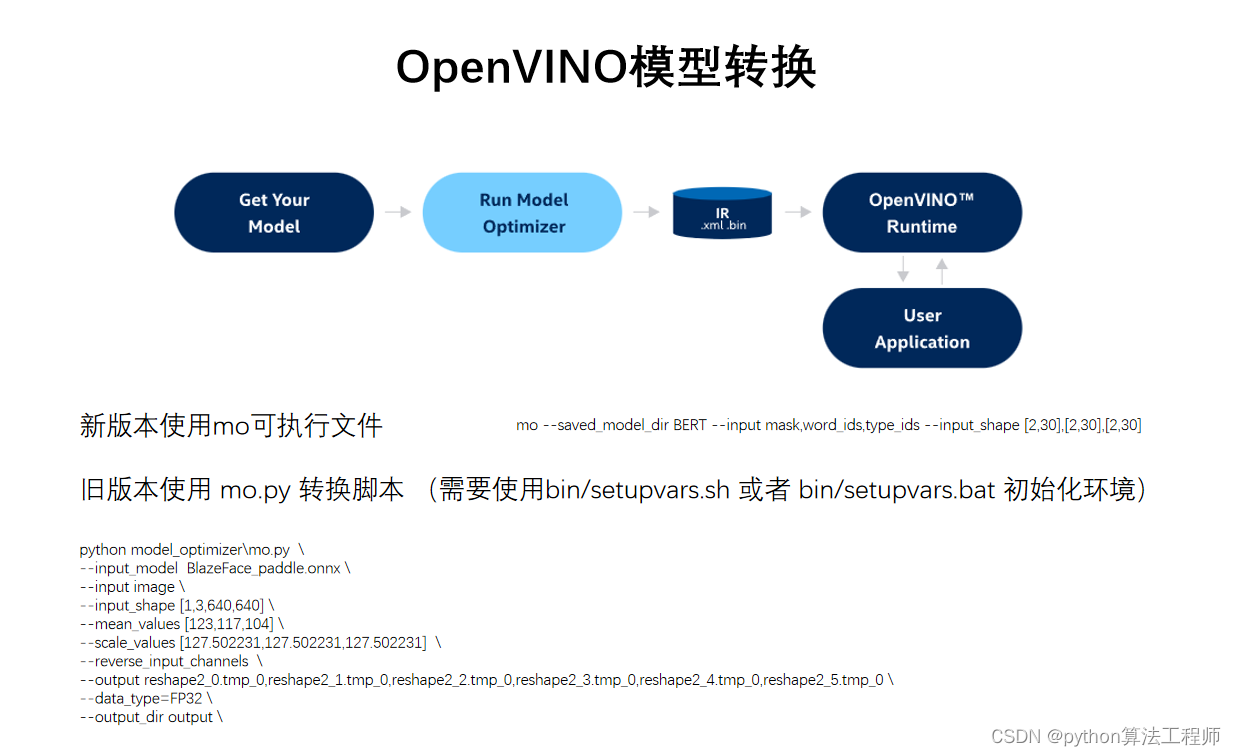
 OpenVINO提供了Model Optimizer工具,可以将深度学习模型转换为OpenVINO IR格式,以便在OpenVINO Inference Engine中进行推理。以下是使用Model Optimizer进行模型转换的基本流程:
OpenVINO提供了Model Optimizer工具,可以将深度学习模型转换为OpenVINO IR格式,以便在OpenVINO Inference Engine中进行推理。以下是使用Model Optimizer进行模型转换的基本流程:
- 安装OpenVINO。
a. 下载并安装OpenVINO,可以参考上述安装步骤。
- 准备模型。
a. 在深度学习框架中训练模型,并将其保存为支持的模型格式(如TensorFlow、Caffe、MXNet等)。
b. 确认模型输入和输出的形状和数据类型,并将其记录下来。
- 运行Model Optimizer。
a. 进入Model Optimizer工具的目录。
cd /opt/intel/openvino_2021/deployment_tools/model_optimizer/
b. 运行Model Optimizer脚本。
python3 mo.py --input_model <path_to_model> --output_dir <output_directory> --data_type <data_type> --input_shape <input_shape> --output <output_node_name>
其中,<path_to_model>是源模型路径,<output_directory>是输出路径,<data_type>是指定数据类型(如FP32、FP16、INT8等),<input_shape>是输入形状,<output_node_name>是输出节点名称。
例如,以下命令将Caffe模型转换为FP16格式的OpenVINO IR模型:
python3 mo.py --input_model model.caffemodel --input_proto model.prototxt --output_dir ir_model --data_type FP16 --input_shape [1,3,224,224] --output output_node
使用IR模型进行推理。
a. 加载IR模型文件。
from openvino.inference_engine import IECore
ie = IECore()
net = ie.read_network("<path_to_xml_file>", "<path_to_bin_file>")
其中,<path_to_xml_file>是IR模型的XML文件路径,<path_to_bin_file>是IR模型的bin文件路径。
b. 配置输入和输出。
input_name = next(iter(net.inputs))
output_name = next(iter(net.outputs))
input_shape = net.inputs[input_name].shape
output_shape = net.outputs[output_name].shape
input_blob = next(iter(exec_net.inputs))
output_blob = next(iter(exec_net.outputs))
c. 创建执行引擎。
exec_net = ie.load_network(network=net, device_name="<device_name>")
其中,<device_name>是设备的名称,如CPU、GPU、FPGA等。
d. 准备输入数据并进行推理。
input_data = np.random.rand(*input_shape)
result = exec_net.infer(inputs={input_name: input_data})
output_data = result[output_name]
以上是使用Model Optimizer将深度学习模型转换为OpenVINO IR格式的基本流程,具体操作可以根据实际需求进行调整和优化。
OpenVINO IR是OpenVINO推理引擎所使用的中间表示格式,它是一种供OpenVINO推理引擎使用的二进制文件格式,包含了深度学习模型的网络结构、权重和其他相关信息。IR文件一般包括两个文件:一个XML文件和一个bin文件,它们分别描述了深度学习模型的结构和权重。
以下是IR文件的基本组成部分:
- 网络结构。
网络结构描述了深度学习模型的层次结构和连接关系,包括输入输出节点、卷积层、池化层、全连接层等,以及它们的参数和超参数。
- 模型权重。
模型权重是训练好的模型参数,它们被保存在bin文件中,以供IR文件加载时使用。
- 数据类型。
IR文件中的数据类型指定了模型权重和输入输出数据的精度,包括FP32、FP16、INT8等。
- 输入输出。
IR文件中定义了模型的输入和输出节点名称、形状和数据类型,以便在推理时进行正确的输入输出。
- 优化信息。
OpenVINO的Model Optimizer工具可以对深度学习模型进行优化,生成IR文件时可以包含一些优化信息,如量化、融合、剪枝等。这些优化可以提高模型的推理速度和精度。
IR文件在OpenVINO中具有良好的跨平台和跨设备的兼容性和可移植性,可以在各种平台和设备上加载和运行。同时,IR文件也可以通过OpenVINO的Model Optimizer工具进行转换,以适应不同的硬件和推理需求。


OpenVINO是一种用于深度学习模型推理的工具集,可以在各种硬件平台上进行部署。以下是使用OpenVINO进行部署的基本步骤:
- 安装OpenVINO。
a. 下载OpenVINO工具集,并按照官方文档进行安装。
b. 设置OpenVINO环境变量。
source /opt/intel/openvino_2021/bin/setupvars.sh
- 准备模型。
a. 在深度学习框架中训练模型,并将其保存为支持的模型格式(如TensorFlow、Caffe、MXNet等)。
b. 确认模型输入和输出的形状和数据类型,并将其记录下来。
使用Model Optimizer进行模型转换。
a. 进入Model Optimizer工具的目录。
cd /opt/intel/openvino_2021/deployment_tools/model_optimizer/
b. 运行Model Optimizer脚本。
python3 mo.py --input_model <path_to_model> --output_dir <output_directory> --data_type <data_type> --input_shape <input_shape> --output <output_node_name>
其中,<path_to_model>是源模型路径,<output_directory>是输出路径,<data_type>是指定数据类型(如FP32、FP16、INT8等),<input_shape>是输入形状,<output_node_name>是输出节点名称。
- 加载IR模型文件。
a. 使用OpenVINO Inference Engine加载IR模型文件。
from openvino.inference_engine import IECore ie = IECore() net = ie.read_network("<path_to_xml_file>", "<path_to_bin_file>")
b. 配置输入和输出。
input_name = next(iter(net.inputs))
output_name = next(iter(net.outputs))
input_shape = net.inputs[input_name].shape
output_shape = net.outputs[output_name].shape
input_blob = next(iter(exec_net.inputs))
output_blob = next(iter(exec_net.outputs))
- 创建执行引擎。
a. 使用OpenVINO Inference Engine创建执行引擎。
exec_net = ie.load_network(network=net, device_name="<device_name>")
其中,<device_name>是设备的名称,如CPU、GPU、FPGA等。
- 准备输入数据。
a. 将输入数据转换为正确的形状和数据类型。
input_data = np.random.uniform(-1, 1, input_shape)
执行推理。
a. 使用执行引擎进行推理。
result = exec_net.infer(inputs={input_name: input_data})
处理输出数据。
a. 将输出数据转换为正确的形状和数据类型。
output_data = result[output_name]
以上是使用OpenVINO进行部署的基本步骤,具体的部署方式可能因硬件平台、模型类型和推理需求而有所不同。

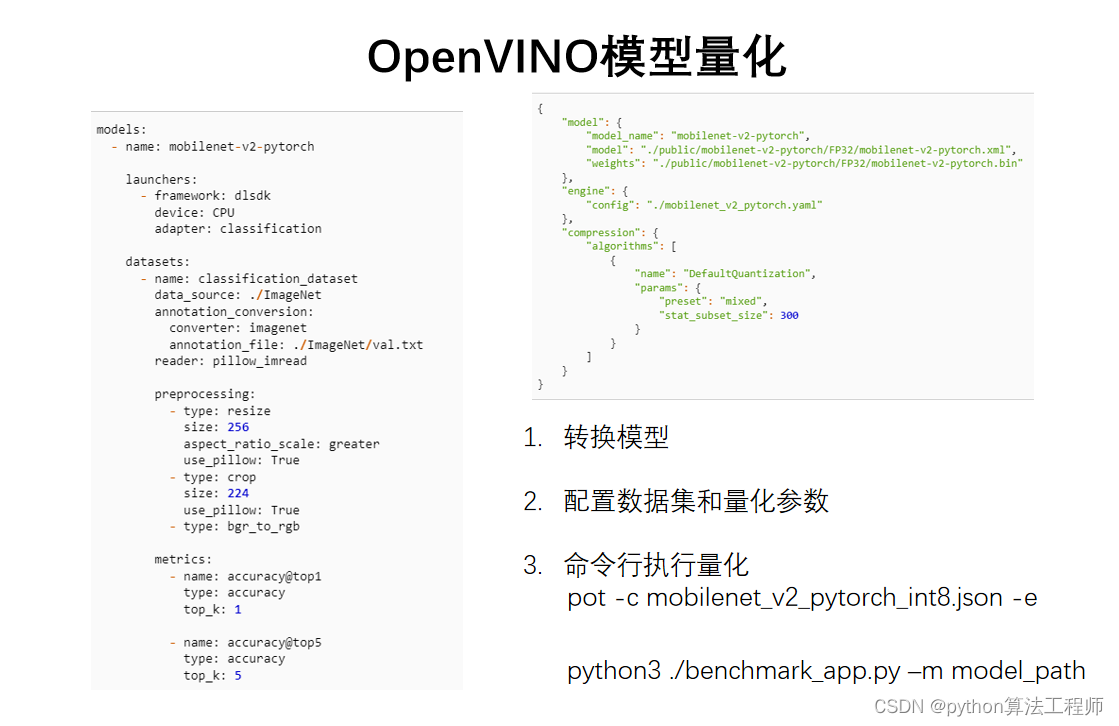
 OpenVINO提供了模型量化功能,可以将浮点型的深度学习模型转换为定点型模型,以提高推理速度和减少内存占用。以下是使用OpenVINO进行模型量化的基本步骤:
OpenVINO提供了模型量化功能,可以将浮点型的深度学习模型转换为定点型模型,以提高推理速度和减少内存占用。以下是使用OpenVINO进行模型量化的基本步骤:
- 准备模型。
a. 在深度学习框架中训练模型,并将其保存为支持的模型格式(如TensorFlow、Caffe、MXNet等)。
b. 确认模型输入和输出的形状和数据类型,并将其记录下来。
- 使用Model Optimizer进行模型转换。
a. 进入Model Optimizer工具的目录。
cd /opt/intel/openvino_2021/deployment_tools/model_optimizer/
b. 运行Model Optimizer脚本。
python3 mo.py --input_model <path_to_model> --output_dir <output_directory> --data_type <data_type> --input_shape <input_shape> --output <output_node_name>
其中,<path_to_model>是源模型路径,<output_directory>是输出路径,<data_type>是指定数据类型(如FP32、FP16、INT8等),<input_shape>是输入形状,<output_node_name>是输出节点名称。
- 进行模型量化。
a. 进入Model Optimizer工具的extensions目录。
cd /opt/intel/openvino_2021/deployment_tools/model_optimizer/extensions/front/tf/
b. 运行quantize.py脚本。
python3 quantize.py --input_model <path_to_model> --output_dir <output_directory> --data_type <data_type> --input_shape <input_shape> --output <output_node_name>
其中,<path_to_model>是源模型路径,<output_directory>是输出路径,<data_type>是指定数据类型(如FP32、FP16、INT8等),<input_shape>是输入形状,<output_node_name>是输出节点名称。
- 加载量化后的IR模型文件。
a. 使用OpenVINO Inference Engine加载IR模型文件。
from openvino.inference_engine import IECore
ie = IECore()
net = ie.read_network("<path_to_xml_file>", "<path_to_bin_file>")
b. 配置输入和输出。
input_name = next(iter(net.inputs))
output_name = next(iter(net.outputs))
input_shape = net.inputs[input_name].shape
output_shape = net.outputs[output_name].shape
input_blob = next(iter(exec_net.inputs))
output_blob = next(iter(exec_net.outputs))
- 创建执行引擎。
a. 使用OpenVINO Inference Engine创建执行引擎。
exec_net = ie.load_network(network=net, device_name="<device_name>")
其中,<device_name>是设备的名称,如CPU、GPU、FPGA等。
- 准备输入数据。
a. 将输入数据转换为正确的形状和数据类型。
input_data = np.random.uniform(-1, 1, input_shape)
- 执行推理。
a. 使用执行引擎进行推理。
result = exec_net.infer(inputs={input_name: input_data})
- 处理输出数据。
a. 将输出数据转换为正确的形状和数据类型。
output_data = result[output_name]
以上是使用OpenVINO进行模型量化的基本步骤,具体的量化方式可能因硬件平台、模型类型和推理需求而有所不同。
 在使用OpenVINO进行模型推理的过程中,可能会出现各种问题,以下是一些常见的问题和解决方法:
在使用OpenVINO进行模型推理的过程中,可能会出现各种问题,以下是一些常见的问题和解决方法:
- OpenVINO无法加载模型。
解决方法:
a. 确认模型文件是否存在。
b. 确认模型文件是否正确,是否符合OpenVINO支持的格式。
c. 确认模型输入和输出的形状和数据类型是否正确。
- OpenVINO推理结果不正确。
解决方法:
a. 确认模型输入数据是否正确,是否符合模型输入要求。
b. 确认模型输出数据是否正确,是否符合模型输出要求。
c. 确认模型转换过程中是否出错。
d. 确认执行引擎是否正确配置。
- OpenVINO执行速度较慢。
解决方法:
a. 使用OpenVINO提供的优化方法,如异步推理、多线程并行推理、批量推理等。
b. 确认是否使用了适合硬件平台的优化方法,如使用FPGA硬件加速推理。
- OpenVINO无法找到设备或无法使用设备。
解决方法:
a. 确认设备是否正确连接或是否被占用。
b. 确认设备是否支持OpenVINO要求的硬件要求。
c. 确认OpenVINO是否正确配置了设备。
- OpenVINO出现其他异常错误。
解决方法:
a. 检查OpenVINO的版本是否正确,是否缺少依赖库。
b. 查看OpenVINO的日志,确定错误原因。
c. 在OpenVINO的社区中寻求帮助,或者联系OpenVINO的技术支持团队。
以上是一些常见的OpenVINO问题和解决方法,如果在使用过程中遇到其他问题,可以参考OpenVINO的官方文档或者在OpenVINO的社区中寻求帮助。
在使用OpenCV或OpenVINO进行图像处理或深度学习推理时,通常需要对输入图像进行标准化(Normalization),即将图像像素值减去均值(mean)并除以标准差(std),以便更好地适应模型。如果没有提供输入图像的mean和std,可以通过以下方法来计算它们:
对于一组图像,可以使用下面的代码来计算它们的均值和标准差:
import cv2
import numpy as np
img_list = [...] # 一组图像
img_mean = np.zeros(3)
img_std = np.zeros(3)
for img_path in img_list:
img = cv2.imread(img_path)
img = img.astype(np.float32) / 255.0
img_mean += np.mean(img, axis=(0,1))
img_std += np.std(img, axis=(0,1))
img_mean /= len(img_list)
img_std /= len(img_list)
print("mean:", img_mean)
print("std:", img_std)
其中,img_list是一组图像的路径,img_mean和img_std是像素通道的均值和标准差,可以用于对输入图像进行标准化。需要注意的是,这里假设图像是RGB格式,因此img_mean和img_std都是长度为3的一维数组,分别对应R、G、B通道。
对于单张图像,可以使用下面的代码来计算它的均值和标准差:
import cv2
import numpy as np
img_path = [...] # 单张图像
img = cv2.imread(img_path)
img = img.astype(np.float32) / 255.0
img_mean = np.mean(img, axis=(0,1))
img_std = np.std(img, axis=(0,1))
print("mean:", img_mean)
print("std:", img_std)
这里假设图像是RGB格式,因此img_mean和img_std都是长度为3的一维数组,分别对应R、G、B通道。
以上是两种计算图像均值和标准差的方法,可以根据需要选择合适的方法来计算输入图像的mean和std。



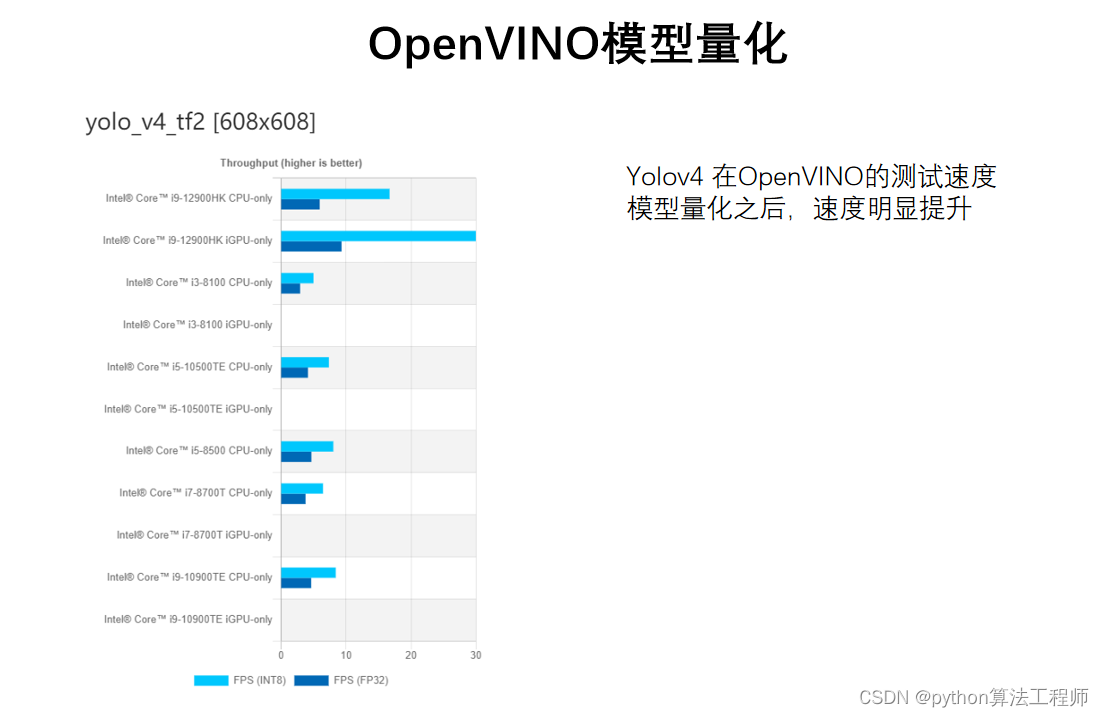
 Yolov7 int8 量化
Yolov7 int8 量化
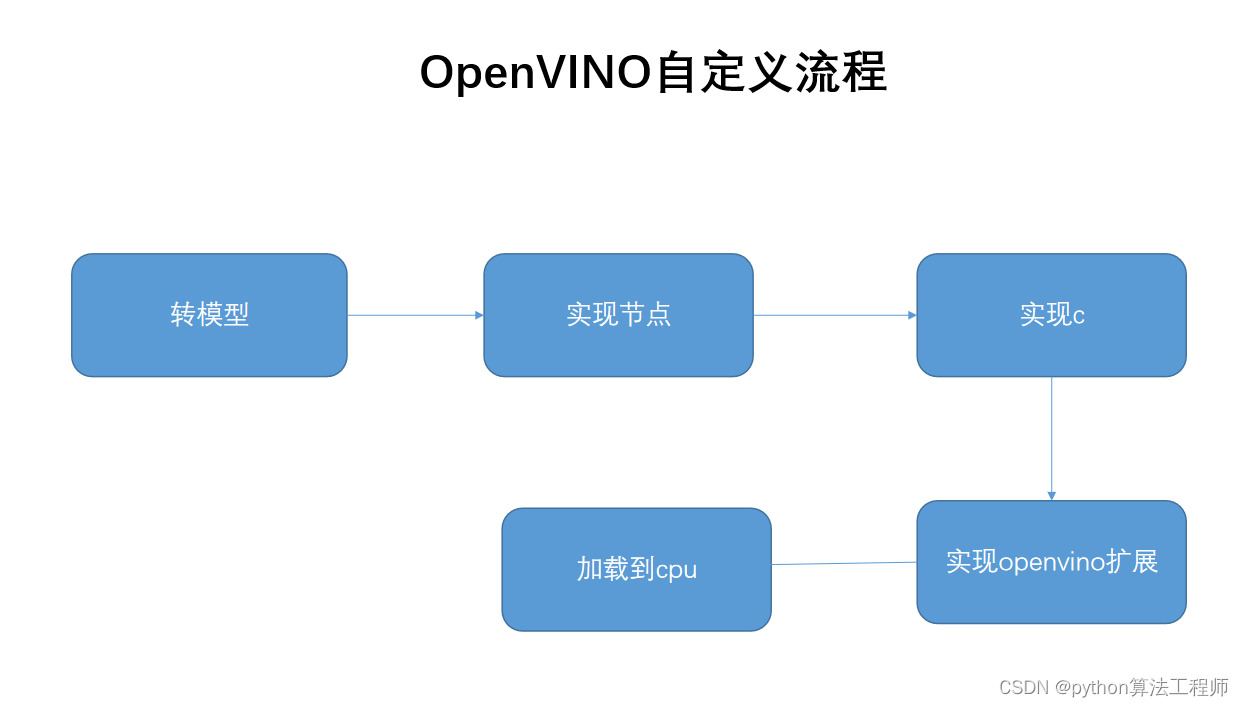
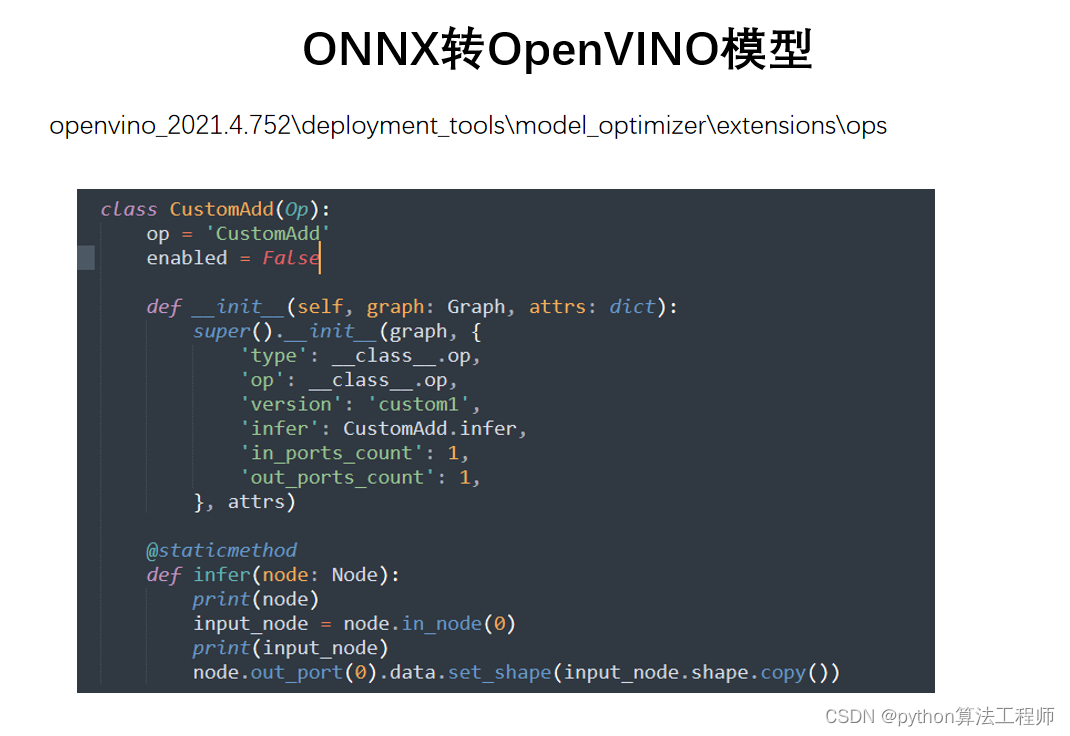
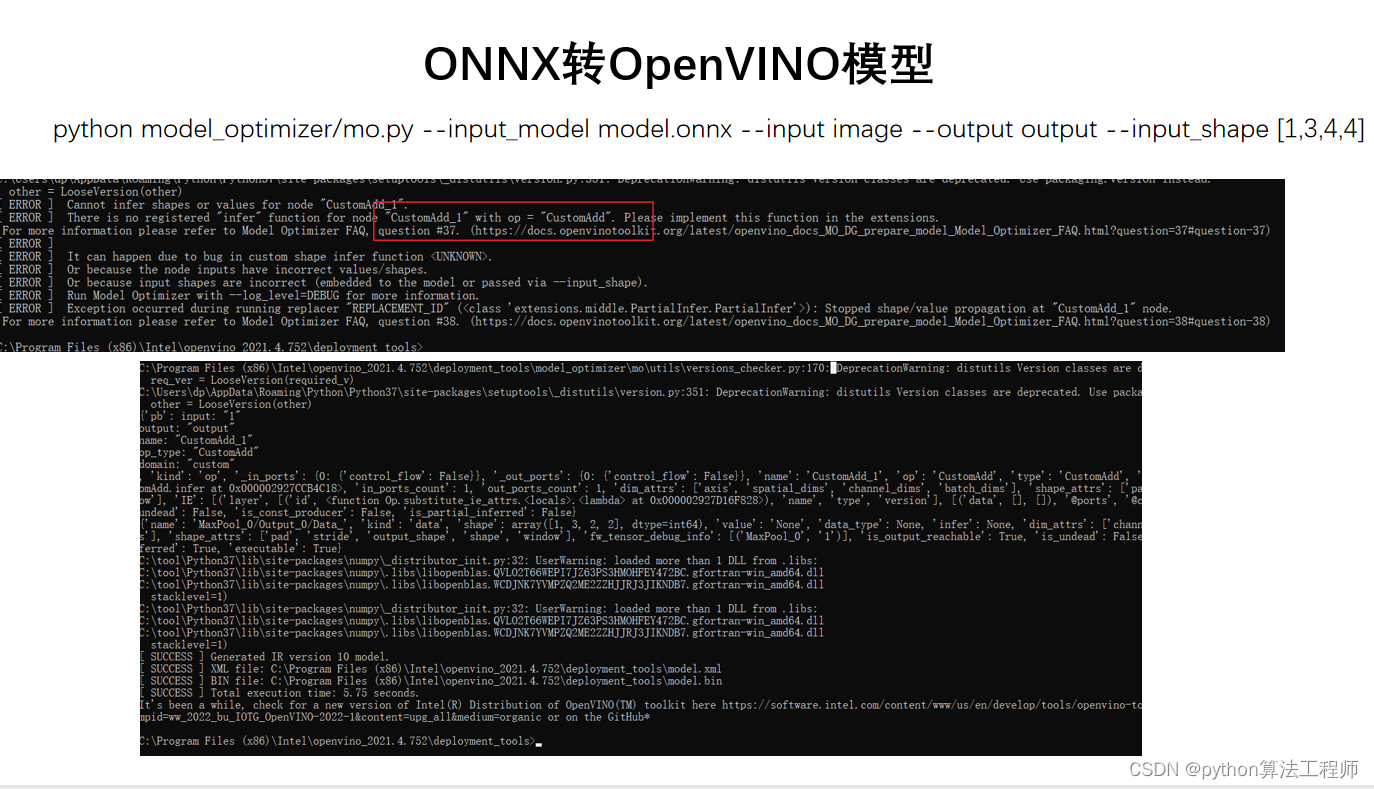
OpenVINO自定义层