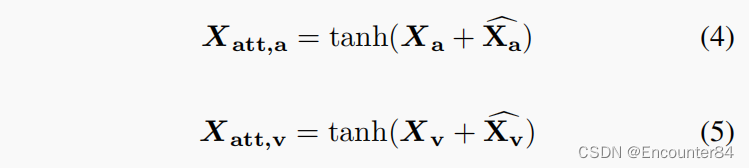Abstract
摘要——多模态分析最近引起了人们对情感计算的极大兴趣,因为它可以提高情感识别相对于孤立的单模态方法的整体准确性。 最有效的多模态情绪识别技术有效地利用各种免费的信息源,例如面部、声音和生理模式,以提供全面的特征表示。 在本文中,我们专注于基于从视频中提取的面部和声音模态融合的维度情绪识别,其中可以捕获复杂的时空关系。 大多数现有的融合技术依赖于循环网络或传统的注意机制,这些机制不能有效地利用视听 (A-V) 模态的互补性。 我们引入了一种交叉注意融合方法来提取跨 A-V 模态的显着特征,从而可以准确预测效价和唤醒的连续值。 我们新的交叉注意力 A-V 融合模型有效地利用了模态间关系。 特别是,它计算交叉注意力权重以关注跨单个模态的更有贡献的特征,从而组合有贡献的特征表示,然后将其馈送到完全连接的层以预测效价和唤醒。 所提出方法的有效性在来自 RECOLA 和Fatigue
(private)数据集的视频上得到了实验验证。 结果表明,我们的交叉注意力 A-V 融合模型是一种具有成本效益的方法,优于最先进的融合方法。 代码可用:https://github.com/praveena2j/Cross-Attentional-AV-Fusion
主要贡献:(1)我们提出了一种基于互相关的交叉注意 A-V 融合模型,以有效地利用跨模态的互补关系进行维度情绪识别。 (2) 与之前的方法不同,我们利用 A-V 特征之间的相互作用(模态间关系)来获得维度情绪识别的补充表示。 (3) 对于概念验证,我们考虑使用 Inflated 3D CNN 模型 [14] 来有效地提取面部模态的时空特征,并结合 2D-CNN 模型从声谱图表示中提取 A 特征来表示声音模态。 RECOLA 和Fatigue
(private)数据集的实验结果表明,我们提出的交叉注意 A-V 融合可以胜过用于维度情绪识别的最先进的融合模型。
PROPOSED APPROACH
在本节中,我们介绍交叉注意力 A-V 融合模型,该模型提取面部和声音模态的互补特征,从而提供全面的表示以提高整体性能。
A. 视频中的视觉网络面部表情涉及视频序列的外观和时间动态。 视频序列的空间和时间动态的有效建模在提取鲁棒特征方面起着至关重要的作用,这反过来又提高了整体系统性能。 最先进的性能通常是使用 CNN 结合递归神经网络 (RNN) 来捕获有效的潜在外观表示以及时间动态 [26]。 已经探索了几种基于 LSTM [27]、[28] 的维度情绪识别方法。 然而,发现 3D-CNN 在捕捉视频中的时空动态方面非常有效。 具体来说,我们考虑使用 Inflated 3D-CNN [14] 从视频序列中提取面部剪辑的时空特征。 与传统的 3D CNN 相比,I3D 可以有效地捕获 V 模态的时空动态,同时使用比 3D CNN 更少的参数进行训练。 此外,它有助于探索现有的预训练 2D-CNN,这些 2D-CNN 在许多具有面部表情的图像上进行训练,从而提高视频的空间辨别力。 在提议的方法中,我们分别为面部模态训练了 I3D 模型(参见第 IV-B 节中的实现细节)。 B. 音频网络语音信号的副语言信息被发现具有传达一个人的情绪状态的重要信息。 尽管使用传统的手工特征(如 MFCC、全局特征 [29])广泛探索了使用语音的情感识别,但近年来随着 DL 模型的引入有了显着改进。 发现频谱图携带与一个人的情感状态有关的重要的副语言信息 [30],[31]。 因此,在基于语音的情感识别的 DL 模型框架中使用了频谱图。 在用于情感识别的文献中,已经使用各种 2D CNN 探索了频谱图 [32]、[33]。 我们使用表 I 中所示的 A 网络(参见第 IV-B 节中的实现细节)。
C. Cross-Attentional Fusion 分别训练了A和V模型,并为A和V模态提取了深层特征。 对于 A 和 V 模态,效价和唤醒的表现差异很大。 由于 V 模态中丰富的基于外观的信息,它在描述序列的表达式时传达了与效价相关的重要信息。 音频信号携带与表情强度相关的重要信息,这在 A 信号的能量中得到有效体现。 对于给定的视频序列,V 模态在某些视频剪辑中携带相关信息,而 A 模态可能与其他剪辑更相关。 由于与单一模态相比,多种模态传达了不同的效价和唤醒信息,因此可以通过以互补方式融合 A 和 V 模态来有效地利用多种模态。 为了可靠地融合这些模态以预测效价和唤醒,我们使用基于交叉注意的融合机制来有效地编码模态间信息,同时保留模态内特征。 所提出模型的框图如图 1 所示。

互相关矩阵 Z 给出了 A 和 V 特征之间的相关性度量。 矩阵 Z 中较高的相关系数表明子序列对应的 A 和 V 特征相互之间有很强的相关性。 因此,互相关矩阵 Z 的第 l 列显示了第 l 个 V 特征与 L A 个特征的相关性度量。 基于这个想法,我们分别通过应用 Z 和 Z T 的列向 softmax 来计算 A 和 V 特征 Aa 和 Av 的交叉注意力权重:
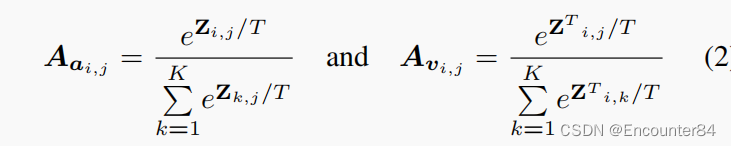
其中 i 和 j 表示互相关矩阵 Z 的第 i 行和第 j 列,T 表示 softmax 温度。 由于权重 W 是基于 A 和 V 特征的互相关学习的,因此每个模态的注意力权重由另一个模态引导,从而有效地利用 A 和 V 模态的互补性质。 得到cross-attention weights后,用来得到A和V特征的attention maps,使其更全面,更有判别力:
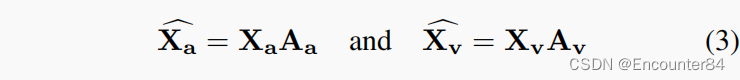
其中 Aa 和 Av 分别表示 A 和 V 特征的交叉注意力权重。 将重新加权的注意力图添加到相应的特征中以获得参与特征: