第1章 如何听起来像数据科学家
文章目录
- 第1章 如何听起来像数据科学家
- 1.1.1 基本的专业术语
- 1.1.3 案例:西格玛公司
- 1.2.3 为什么是Python
- 1.4.2 案例:市场营销费用
- 1.4.3 案例:数据科学家的岗位描述
我们拥有如此多的数据,而且正在生产更多数据,我们甚至创造了很多疯狂的小机器24×7不间断的收集数据,在21世纪,我们面对的真正问题是如何搞懂这些数据。
数据就在那里,总有一些对我们有价值的!肯定有!
我们要从数据中探寻洞察和知识。
1.1.1 基本的专业术语
当使用**数据(data)这个词时,我们指的是以有组织(organized)和无组织(unorganized)**格式聚集在一起的信息。
- 有组织数据(organized data):指以行列结构分类存储的数据,每一行代表一个观测对象(observation),每一列代表一个观测特征(characteristic)。
- 无组织数据(unorganized data):指以自由格式存储的数据,通常指文本、原始音频/信号和图片等。这类数据必须进行解析才能成为有组织的数据。
数据科学是关于如何处理数据、获取知识,并用知识完成以下任务的过程:
- 决策
- 预测未来
- 理解过去或现在
- 创造新产业或新产品
1.1.3 案例:西格玛公司
今天,许多严重依靠直觉的CEO希望快速做出决定,并尝试所有的方案,直到找到答案。
数据科学家Hughan博士则具有分析能力,她的策略是从用户产生的数据中寻找答案,而不是依靠直觉。数据科学正是利用这样的分析能力,帮助“司机”做决定。
1.2.3 为什么是Python
案例:分析一条推文
在本例中,我们将分析一些含有股票价格信息的推文。
tweet="RT @robdv: $TWTR now top holding for Andor,unseating $AAPL"
words_in_tweet=tweet.split(' ')
for word in words_in_tweet:
if '$' in word:
print("THIS IS ABOUT",word)
下面解释一下上面的代码片段:
(1)用变量tweet存储推文信息(Python中的string类型):RT @robdv: $TWTR now top holding for Andor,unseating $AAPL
(2)word_in_tweet变量用于对原始推文进行切分(将文字隔开)该变量的内容如下:
['RT', '@robdv:', '$TWTR', 'now', 'top', 'holding', 'for', 'Andor,unseating', '$AAPL']
(3)用for循环对切分开的列表进行迭代,逐个查看列表中的内容
(4)用if语句判断推文中的每一个词是否包含$符号(人们在推文中使用$表示股票行情)
(5)如果推文中包含$符号,则输出该词
这段代码的运行结果如下:
THIS IS ABOUT $TWTR
THIS IS ABOUT $AAPL
它们是这段推文中仅有的两个含有$符号的单词
1.4.2 案例:市场营销费用
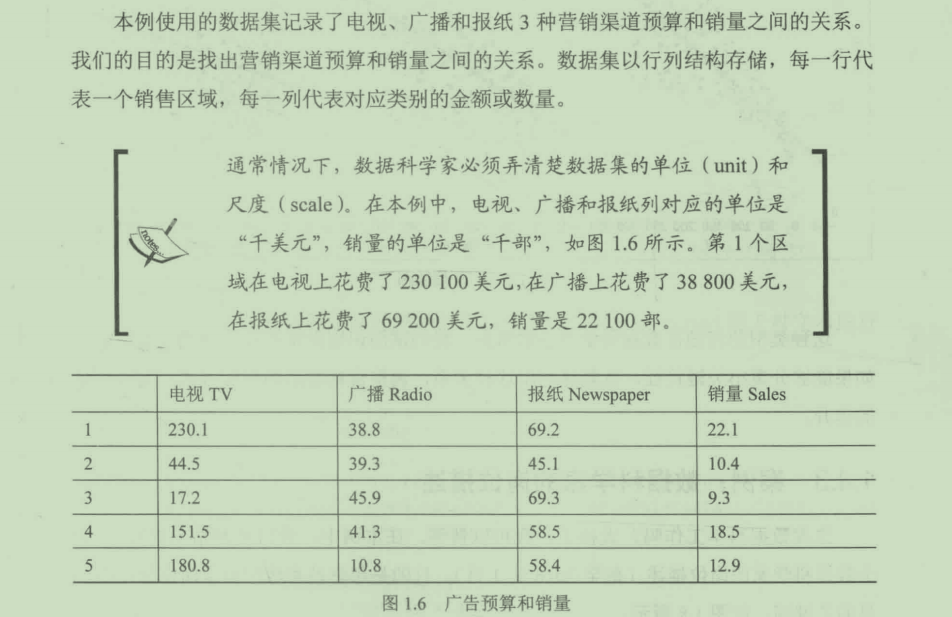
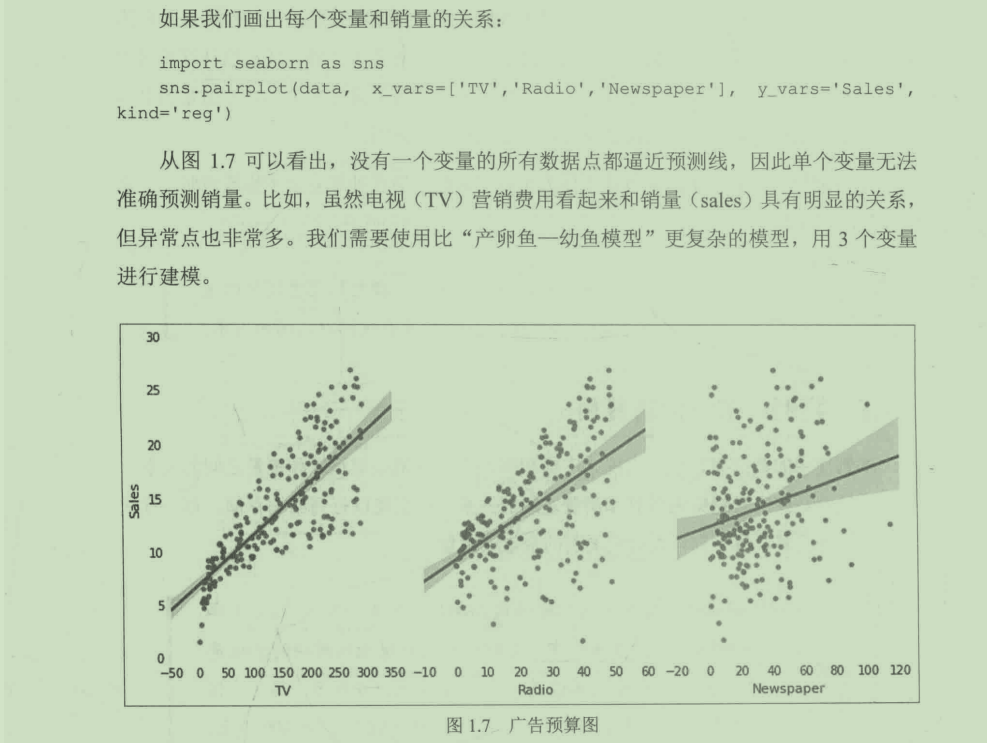
这种类型的问题在数据科学中非常常见。我们试图识别影响产品销量的关键特征,如果能够分离出关键特征,就能够利用这种关系,调整营销费用的分配方式,实现销量的提升。
实际上这是一个商业问题。
需求是:用最少(尽量少)的广告预算得到最大(尽量大)的销量
所以我们真正的目的是:找到电视、广播、报纸上花费的广告预算和销量之间的关系。
我们用t代表电视广告花费,r代表广播广告花费,n代表报纸广告花费,s代表产品销量
f ( t , r , n ) = s f(t,r,n)=s f(t,r,n)=s 找到这个函数关系;或者至少找到t、r、n对s影响的权重
1.4.3 案例:数据科学家的岗位描述

请注意第二家公司要求掌握的核心的Python库,本书将会对这些库进行介绍。
import requests
#used to grab data from the web 从网站中抓取数据
from bs4 import BeautifulSoup
#used to parse HTML 解析HTML
from sklearn.feature_extraction.text import CountVectorizer
#used to count number of words and phrases (we will be using this module a lot)
前两行imports代码用于从招牌网站中抓取数据,第三行import用于对文本进行计数。
texts=[]
#hold our job descriptions in this list
for index in range(0,1000,10): #go through 100 pages of indeed
page='https://www.indeed.com/jobs?q=data+scientist&start='+str(index)
#identify the url of the job listings
web_result=requests.get(page).text
#use requests to actually visit the url
soup=BeautifulSoup(web_result)
#parse the html of the resulting page
for listing in soup.findAll('span',{'class':'summary'}):
#for each listing on the page
texts.append(listing.text)
#append the text of the listing to our list
以上代码的功能是打开100个网页,抓取网页中的岗位描述信息。最重要的变量是texts,它存储了1000个岗位描述。
type(texts) #==list
vect=CountVectorizer(ngram_range(1,2),stop_words='english')
#get basic counts of one and two word phrases
matrix=vect.fit_transform(texts)
#fit and learn to the vocabulary in the corpus
print(len(vect.get_feature_names())) #how many features are there
#There are 11,293 total one and two words phrases in my case!!


本案例的代码由于网站反爬虫机制或者网页结构变化等其他一系列原因,并不能直接运行。
`
[外链图片转存中…(img-S5Zo0ehs-1681435562538)]
[外链图片转存中…(img-pTLTzwIz-1681435562538)]
本案例的代码由于网站反爬虫机制或者网页结构变化等其他一系列原因,并不能直接运行。







![[Python工匠]输出① 变量与注释](https://img-blog.csdnimg.cn/ecef55451942454c9f0b3b1fddb6946b.png)


![状态设计模式(State Pattern)[论点:概念、相关角色、图示、示例代码、框架中的运用、适用场景]](https://img-blog.csdnimg.cn/dde5eda6e370408bbc329458b5d5d5dd.png#pic_center)