变量(variable)是用来从内存找到某个东西的标记
#去掉s两边的空格,再处理
value = process(s.strip())s = " hello World "
value1 = len(s)
value2 = len(s.strip())
print(value1)
print(value2)#用户输入可能会有空格,使用strip()去掉空格
username = extract_username(input_string.strip())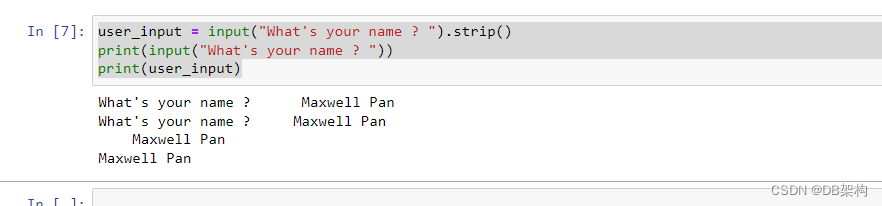
user_input = input("What's your name ? ").strip()
print(input("What's your name ? "))
print(user_input)1.1 基础知识
1.1.1 变量常见用法
>>
>>> author = 'Maxwell'
>>> print('Hello, {}!'.format(author))
Hello, Maxwell!
>>>在一行语句里同时操作多个变量,比如调换两个变量所指向的值
>>>
>>> author,reader = 'Maxwell','Ray'
>>> author,reader = reader,author
>>> author
'Ray'
>>>01.变量解包
变量解包(unpacking)是Python里的一种特殊赋值操作,允许我们把一个可迭代对象(比如列表)的所有成员,一次性赋值给多个变量:
# 注意: 左侧变量的个数必须和待展开的列表长度相等,否则会报错。
>>>
>>> usernames = ['Maxwell', 'Ray']
>>> author, reader = usernames
>>> author
'Maxwell'
>>>假如在赋值语句左侧添加小括号(...),甚至可以一次展开多层嵌套数据:
>>>
>>> attrs = [1, ['maxwell', 100]]
>>> user_id, (username, score) = attrs
>>> user_id
1
>>> username
'maxwell'
>>>Python还支持更灵活的动态解包语法。只要用星号表达式(*variables)作为变量名,它便会贪婪[插图]地捕获多个值对象,并将捕获到的内容作为列表赋值给variables。
>>>
>>> data = ['Maxwell', 'apple','orange','banana', 100]
>>> username, *fruits, score = data
>>> username
'Maxwell'
>>> fruits
['apple', 'orange', 'banana']
>>> score
100
>>>和常规的切片赋值语句比起来,动态解包语法要直观许多:
#1. 动态解包
>>> username, *fruits, score = data
# 2. 切片赋值
>>> username, fruits, score = data[0], data[1:-1], data[-1]
# 两种变量赋值方式完全等价>>>
>>>
>>> for username, score in [('Maxwell',100), ('Ray', 60)]:
... print(username)
...
Maxwell
Ray
>>>
02.单下划线变量名_
在常用的诸多变量名中,单下划线_是比较特殊的一个。它常作为一个无意义的占位符出现在赋值语句中。_这个名字本身没什么特别之处,这算是大家约定俗成的一种用法。
举个例子,假如你想在解包赋值时忽略某些变量,就可以使用_作为变量名
#忽略展开时的第二个变量
>>> author, _ = usernames
# 忽略第一个和最后一个变量之间的所有变量
>>> username, *_, score = data而在Python交互式命令行(直接执行python命令进入的交互环境)里,_变量还有一层特殊含义——默认保存我们输入的上个表达式的返回值:
>>>
>>> 'foo'.upper()
'FOO'
>>> print(_)
FOO
>>>1.1.2 给变量注明类型
为了解决动态类型带来的可读性问题,最常见的办法就是在函数文档(docstring)里做文章。我们可以把每个函数参数的类型与说明全都写在函数文档里。
def remove_invalid(items):
"""剔除 items 里面无效的元素
:param items: 待剔除对象
:type items: 包含整数的列表,[int, ...]
"""下面是给remove_invalid()函数添加类型注解后的样子:
from typing import List
def remove_invalid(items: List[int]): ➊
"""剔除 items 里面无效的元素"""
... ...❶List表示参数为列表类型,[int]表示里面的成员是整型
强烈建议在多人参与的中大型Python项目里,至少使用一种类型注解方案——Sphinx格式文档或官方类型注解都行。能直接看到变量类型的代码,总是会让人更安心。
1.1.3 变量命名原则
计算机科学领域只有两件难事:缓存失效和命名。——Phil Karlton
01.遵循PEP 8原则
给变量起名主要有两种流派:一是通过大小写界定单词的驼峰命名派CamelCase,二是通过下划线连接的蛇形命名派snake_case。这两种流派没有明显的优劣之分,似乎与个人喜好有关
ython制定了官方的编码风格指南:PEP 8。这份风格指南里有许多详细的风格建议,比如应该用4个空格缩进,每行不超过79个字符,等等。其中,当然也包含变量的命名规范:
· 对于普通变量,使用蛇形命名法,比如max_value;
· 对于常量,采用全大写字母,使用下划线连接,比如MAX_VALUE;
· 如果变量标记为“仅内部使用”,为其增加下划线前缀,比如_local_var;
· 当名字与Python关键字冲突时,在变量末尾追加下划线,比如class_。
除变量名以外,PEP 8中还有许多其他命名规范,比如类名应该使用驼峰风格(FooClass)、函数应该使用蛇形风格(bar_function),等等。给变量起名的第一条原则,就是一定要在格式上遵循以上规范。
PEP 8是Python编码风格的事实标准。“代码符合PEP 8规范”应该作为对Python程序员的基本要求之一。
02.描述性要强
#描述性弱的名字:看不懂在做什么
value = process(s.strip())
# 描述性强的名字:尝试从用户输入里解析出一个用户名
username = extract_username(input_string.strip())表1-1 描述性弱和描述性强的变量名示例

03.要尽量短
中诀窍在于:为变量命名要结合代码情境和上下文。比如在上面的代码里,upgrade_to_level3(user)函数已经通过自己的名称、文档表明了其目的,那在函数内部,我们完全可以把how_many_points_needed_for_user_level3直接删减成level3_points。
04.要匹配类型
匹配布尔值类型的变量名
布尔值(bool)是一种很简单的类型,它只有两个可能的值:“是”(True)或“不是”(False)。
表1-2 布尔值变量名示例

匹配int/float类型的变量名
自然就会认定它们是int或float类型。这些名字可简单分为以下几种常见类型:
- 释义为数字的所有单词,比如port(端口号)、age(年龄)、radius(半径)等;
- 使用以_id结尾的单词,比如user_id、host_id;
- 使用以length/count开头或者结尾的单词,比如length_of_username、max_length、users_count。
匹配其他类型的变量名
字符串(str)、列表(list)、字典(dict)
05.超短命名
在众多变量名里,有一类非常特别,那就是只有一两个字母的短名字。这些短名字一般可分为两类,一类是那些大家约定俗成的短名字,比如:
· 数组索引三剑客i、j、k
· 某个整数n
· 某个字符串s
· 某个异常e
· 文件对象fp
其他技巧
除了上面这些规则外,下面再分享几个给变量命名的小技巧:
· 在同一段代码内,不要出现多个相似的变量名,比如同时使用users、users1、users3这种序列;
· 可以尝试换词来简化复合变量名,比如用is_special来代替is_not_normal;
· 如果你苦思冥想都想不出一个合适的名字,请打开GitHub[插图],到其他人的开源项目里找找灵感吧!
1.1.4 注释基础知识
注释(comment)是代码非常重要的组成部分。通常来说,注释泛指那些不影响代码实际行为的文字,它们主要起额外说明作用。
Python里的注释主要分为两种,一种是最常见的代码内注释,通过在行首输入#号来表示:
#用户输入可能会有空格,使用strip去掉空格
username = extract_username(input_string.strip())
另一种注释则是我们前面看到过的函数(类)文档(docstring),这些文档也称接口注释(interface comment)。
class Person:
"""人
:param name: 姓名
:param age: 年龄
:param favorite_color: 最喜欢的颜色
"""
def __init__(self, name, age, favorite_color):
self.name = name
self.age = age
self.favorite_color = favorite_color接口注释有好几种流行的风格,比如Sphinx文档风格、Google风格等,其中Sphinx文档风格目前应用得最为广泛。上面的Person类的接口注释就属于Sphinx文档风格。
编程新手们常常会犯同类型的错误,以下是我整理的最常见的3种。
01.用注释屏蔽代码
#源码里有大段大段暂时不需要执行的代码
# trip = get_trip(request)
# trip.refresh()
# ... ...
对于不再需要的代码,我们应该直接把它们删掉,而不是注释掉。
02.用注释复述代码
在编写注释时,新手常犯的另一类错误是用注释复述代码。
#调用strip()去掉空格
input_string = input_string.strip()指引性注释。这种注释并不直接复述代码,而是简明扼要地概括代码功能,起到“代码导读”的作用。
以下代码里的注释就属于指引性注释:
#初始化访问服务的client对象
token = token_service.get_token()
service_client = ServiceClient(token=token)
service_client.ready()
# 调用服务获取数据,然后进行过滤
data = service_client.fetch_full_data()
for item in data:
if item.value > SOME_VALUE:
...
指引性注释并不提供代码里读不到的东西——假如没有注释,耐心读完所有代码,你也能知道代码做了什么事儿。指引性注释的主要作用是降低代码的认知成本,让我们能更容易理解代码的意图。
03.弄错接口注释的受众
接口文档主要是给函数(或类)的使用者看的,它最主要的存在价值,是让人们不用逐行阅读函数代码,也能很快通过文档知道该如何使用这个函数,以及在使用时有什么注意事项。
对于上面的resize_image()函数来说,文档里提供以下内容就足够了:
def resize_image(image, size):
"""将图片缩放到指定尺寸,并返回新的图片。
注意:当文件超过 5MB 时,请使用resize_big_image()
:param image: 图片文件对象
:param size: 包含宽高的元组:(width, height)
:return: 新图片对象
"""1.3 编程建议
1.3.1 保持变量一致性
在foo()函数的作用域内,users变量被使用了两次:第一次指向字典,第二次则变成了列表。虽然Python的类型系统允许我们这么做,但这样做其实有很多坏处,比如变量的辨识度会因此降低,还很容易引入bug。
建议在这种情况下启用一个新变量:
def foo():
users = {'data': ['piglei', 'raymond']}
...
# 使用一个新名字
user_list = []
...1.3.2 变量定义尽量靠近使用
def generate_trip_png(trip):
"""
根据旅途数据生成 PNG 图片
"""
# 预先定义好所有的局部变量
waypoints = []
photo_markers, text_markers = [], []
marker_count = 0
# 开始初始化 waypoints 数据
waypoints.append(...)
...
# 经过几行代码后,开始处理 photo_markers、text_markers
photo_markers.append(...)
...
# 经过更多代码后,开始计算 marker_count
marker_count += ...
# 拼接图片:已省略……1.3.3 定义临时变量提升可读性
#为所有性别为女或者级别大于3的活跃用户发放10000个金币
user_is_eligible = user.is_active and (user.sex == 'female' or user.level > 3)
if user_is_eligible:
user.add_coins(10000)
return1.3.4 同一作用域内不要有太多变量
代码清单1-3 局部变量过多的函数
def import_users_from_file(fp):
"""尝试从文件对象读取用户,然后导入数据库
:param fp: 可读文件对象
:return: 成功与失败的数量
"""
# 初始化变量:重复用户、黑名单用户、正常用户
duplicated_users, banned_users, normal_users = [], [], []
for line in fp:
parsed_user = parse_user(line)
# …… 进行判断处理,修改前面定义的{X}_users 变量
succeeded_count, failed_count = 0, 0
# …… 读取 {X}_users 变量,写入数据库并修改成功与失败的数量
return succeeded_count, failed_count代码清单1-4 对局部变量分组并建模
class ImportedSummary:
"""保存导入结果摘要的数据类"""
def __init__(self):
self.succeeded_count = 0
self.failed_count = 0
class ImportingUserGroup:
"""用于暂存用户导入处理的数据类"""
def __init__(self):
self.duplicated = []
self.banned = []
self.normal = []
def import_users_from_file(fp):
"""尝试从文件对象读取用户,然后导入数据库
:param fp: 可读文件对象
:return: 成功与失败的数量
"""
importing_user_group = ImportingUserGroup()
for line in fp:
parsed_user = parse_user(line)
# …… 进行判断处理,修改上面定义的importing_user_group 变量
summary = ImportedSummary()
# …… 读取 importing_user_group,写入数据库并修改成功与失败的数量
return summary.succeeded_count, summary.failed_count1.3.5 能不定义变量就别定义
定义临时变量可以提高代码的可读性。但有时,把不必要的东西赋值为临时变量,反而会让代码显得啰唆:
def get_best_trip_by_user_id(user_id):
# 心理活动:嗯,这个值未来说不定会修改/二次使用,我们先把它定义成变量吧!
user = get_user(user_id)
trip = get_best_trip(user_id)
result = {
'user': user,
'trip': trip
}
return result上面这段代码里的三个临时变量完全可以去掉,变成下面这样:
def get_best_trip_by_user_id(user_id):
return {
'user': get_user(user_id),
'trip': get_best_trip(user_id)
}1.3.6 不要使用locals()
locals()是Python的一个内置函数,调用它会返回当前作用域中的所有局部变量:
def foo():
name = 'piglei'
bar = 1
print(locals())
# 调用foo() 将输出:
{'name': 'piglei', 'bar': 1}Python之禅:显式优于隐式
"Python之禅"中有一句“Explicit is better than implicit”(显式优于隐式)
1.3.7 空行也是一种“注释”
代码里的注释不只是那些常规的描述性语句,有时候,没有一个字符的空行,也算得上一种特殊的“注释”。
1.3.8 先写注释,后写代码
每个函数的名称与接口注释(也就是docstring),其实是一种比函数内部代码更为抽象的东西。你需要在函数名和短短几行注释里,把函数内代码所做的事情,高度浓缩地表达清楚。
在写出一句有说服力的接口注释前,别写任何函数代码。
1.4 总结
以下是本章要点知识总结。
(1)变量和注释决定“第一印象”
· 变量和注释是代码里最接近自然语言的东西,它们的可读性非常重要
· 即使是实现同一个算法,变量和注释不一样,给人的感觉也会截然不同(2)基础知识·
Python的变量赋值语法非常灵活,可以使用*variables星号表达式灵活赋值
· 编写注释的两个要点:不要用来屏蔽代码,而是用来解释“为什么”
· 接口注释是为使用者而写,因此应该简明扼要地描述函数职责,而不必包含太多内部细节· 可以用Sphinx格式文档或类型注解给变量标明类型
(3)变量名字很重要· 给变量起名要遵循PEP 8原则,代码的其他部分也同样如此
· 尽量给变量起描述性强的名字,但评价描述性也需要结合场景
· 在保证描述性的前提下,变量名要尽量短
· 变量名要匹配它所表达的类型
· 可以使用一两个字母的超短名字,但注意不要过度使用
(4)代码组织技巧
· 按照代码的职责来组织代码:让变量定义靠近使用
· 适当定义临时变量可以提升代码的可读性
· 不必要的变量会让代码显得冗长、啰唆
· 同一个作用域内不要有太多变量,解决办法:提炼数据类、拆分函数
· 空行也是一种特殊的“注释”,适当的空行可以让代码更易读
(5)代码可维护性技巧
· 保持变量在两个方面的一致性:名字一致性与类型一致性
· 显式优于隐式:不要使用locals()批量获取变量
· 把接口注释当成一种函数设计工具:先写注释,后写代码


![状态设计模式(State Pattern)[论点:概念、相关角色、图示、示例代码、框架中的运用、适用场景]](https://img-blog.csdnimg.cn/dde5eda6e370408bbc329458b5d5d5dd.png#pic_center)