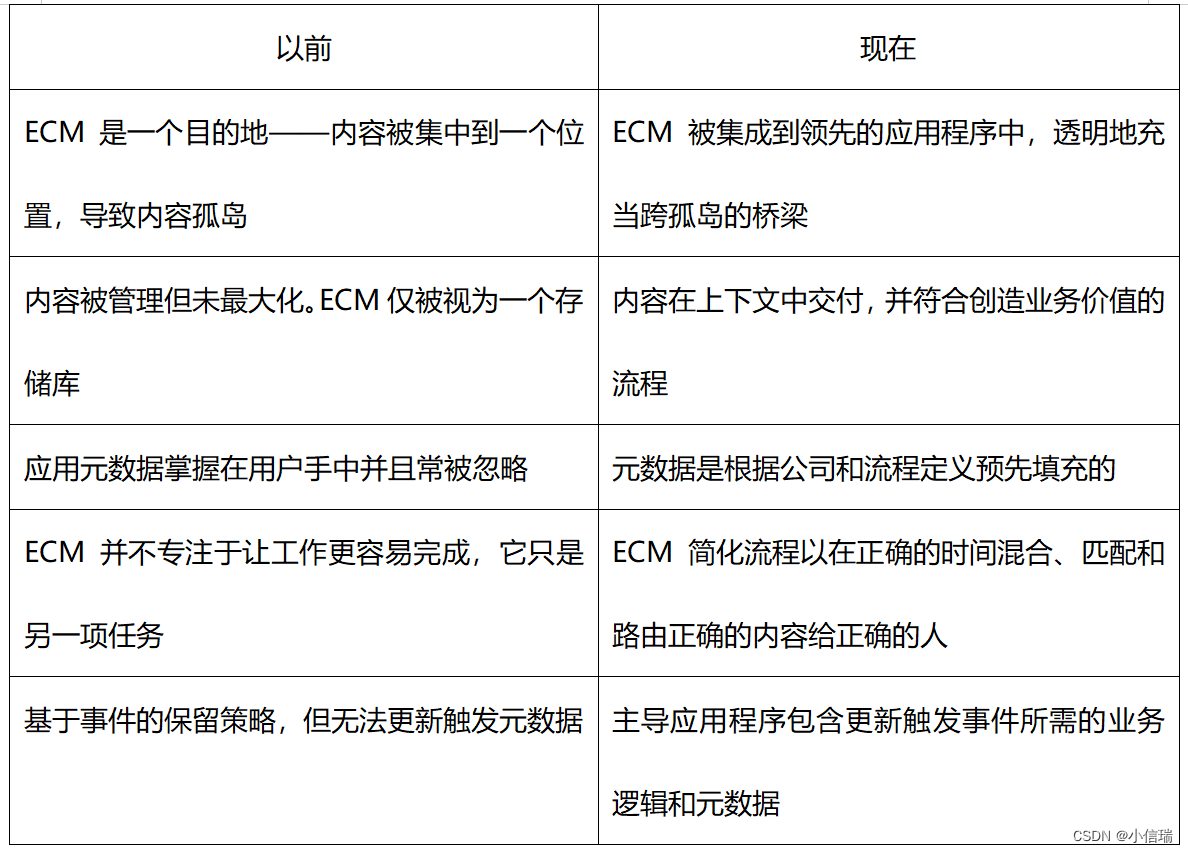
目录标题
- 实验1
- 实验2
- 实验3
- 实验4
- 实验5
import findspark
findspark.init()
from pyspark import SparkContext
sc = SparkContext()
实验1
实验1:已知内存数据源 list01 = [1, 2, 3, 4, 11, 12, 13, 14, 21, 22, 23, 24, 31, 32, 33, 34, 41, 42, 43, 44, 51, 52, 53, 54]
(1) 获取其默认的RDD分区数
list01 =\
[1, 2, 3, 4, 11, 12, 13, 14, 21, 22, 23, 24, 31, 32, 33, 34, 41, 42, 43, 44, 51, 52, 53, 54]
sc.parallelize(list01).getNumPartitions()
12
(2) 查看各个分区上的数据,以列表形式返回
sc.parallelize(list01).glom().collect()
[[1, 2],
[3, 4],
[11, 12],
[13, 14],
[21, 22],
[23, 24],
[31, 32],
[33, 34],
[41, 42],
[43, 44],
[51, 52],
[53, 54]]
(3) 统计各个分区上数据的行数,以列表形式返回
sc.parallelize(list01).glom().map(lambda x:[x,1]).collect()
[[[1, 2], 1],
[[3, 4], 1],
[[11, 12], 1],
[[13, 14], 1],
[[21, 22], 1],
[[23, 24], 1],
[[31, 32], 1],
[[33, 34], 1],
[[41, 42], 1],
[[43, 44], 1],
[[51, 52], 1],
[[53, 54], 1]]
(4) 把分区个数设置为2,并再次查看各个分区上的数据
sc.parallelize(list01).coalesce(2).glom().collect()
[[1, 2, 3, 4, 11, 12, 13, 14, 21, 22, 23, 24],
[31, 32, 33, 34, 41, 42, 43, 44, 51, 52, 53, 54]]
实验2
实验2:已知 scores = [(“Jim”, (“Hadoop”, 80)), (“Jack”, (“Hadoop”, 69)), (“Mike”, (“Hadoop”, 88)), (“Jackson”, (“Hadoop”, 69)),
(“Jim”, (“Spark”, 66)), (“Jack”, (“Spark”, 91)),(“Mike”, (“Spark”, 77)), (“Jackson”, (“Spark”, 79)),
(“Jim”,(“NoSQL”, 62)), (“Jack”, (“NoSQL”, 72)), (“Mike”, (“NoSQL”, 89)), (“Jackson”, (“NoSQL”, 99))]
(1) 查看各个分区上的数据
scores =\
[("Jim", ("Hadoop", 80)), ("Jack", ("Hadoop", 69)), ("Mike", ("Hadoop", 88)), ("Jackson", ("Hadoop", 69)),
("Jim", ("Spark", 66)), ("Jack", ("Spark", 91)),("Mike", ("Spark", 77)), ("Jackson", ("Spark", 79)),
("Jim",("NoSQL", 62)), ("Jack", ("NoSQL", 72)), ("Mike", ("NoSQL", 89)), ("Jackson", ("NoSQL", 99))]
sc.parallelize(scores).glom().collect()
[[('Jim', ('Hadoop', 80))],
[('Jack', ('Hadoop', 69))],
[('Mike', ('Hadoop', 88))],
[('Jackson', ('Hadoop', 69))],
[('Jim', ('Spark', 66))],
[('Jack', ('Spark', 91))],
[('Mike', ('Spark', 77))],
[('Jackson', ('Spark', 79))],
[('Jim', ('NoSQL', 62))],
[('Jack', ('NoSQL', 72))],
[('Mike', ('NoSQL', 89))],
[('Jackson', ('NoSQL', 99))]]
(2) 把分区个数设置为2, 且把将Key相同的数据放在同一个分区上
sc.parallelize(scores).coalesce(2).glom().collect()
# sc.parallelize(scores).partitionBy(2).glom().collect()
[[('Jim', ('Hadoop', 80)),
('Jack', ('Hadoop', 69)),
('Mike', ('Hadoop', 88)),
('Jackson', ('Hadoop', 69)),
('Jim', ('Spark', 66)),
('Jack', ('Spark', 91))],
[('Mike', ('Spark', 77)),
('Jackson', ('Spark', 79)),
('Jim', ('NoSQL', 62)),
('Jack', ('NoSQL', 72)),
('Mike', ('NoSQL', 89)),
('Jackson', ('NoSQL', 99))]]
sc.parallelize(scores).coalesce(2)\
.partitionBy(2,lambda x:x=='Mike')\
.glom().collect()
[[('Jim', ('Hadoop', 80)),
('Jack', ('Hadoop', 69)),
('Jackson', ('Hadoop', 69)),
('Jim', ('Spark', 66)),
('Jack', ('Spark', 91)),
('Jackson', ('Spark', 79)),
('Jim', ('NoSQL', 62)),
('Jack', ('NoSQL', 72)),
('Jackson', ('NoSQL', 99))],
[('Mike', ('Hadoop', 88)), ('Mike', ('Spark', 77)), ('Mike', ('NoSQL', 89))]]
(3) 分区数仍然是2, 但是把名字长度等于4(Mike和Jack)的数据放在同一个分区上
输出结果:
[[(‘Jim’, (‘Hadoop’, 80)), (‘Jackson’, (‘Hadoop’, 69)), (‘Jim’, (‘Spark’, 66)), (‘Jackson’, (‘Spark’, 79)), (‘Jim’, (‘NoSQL’, 62)),
(‘Jackson’, (‘NoSQL’, 99))],
[(‘Jack’, (‘Hadoop’, 69)), (‘Mike’, (‘Hadoop’, 88)), (‘Jack’, (‘Spark’, 91)), (‘Mike’, (‘Spark’, 77)), (‘Jack’, (‘NoSQL’, 72)),
(‘Mike’, (‘NoSQL’, 89))]]
sc.parallelize(scores)\
.repartitionAndSortWithinPartitions(2,lambda x : len(x)==4)\
.glom().collect()
[[('Jackson', ('Hadoop', 69)),
('Jackson', ('Spark', 79)),
('Jackson', ('NoSQL', 99)),
('Jim', ('Hadoop', 80)),
('Jim', ('Spark', 66)),
('Jim', ('NoSQL', 62))],
[('Jack', ('Hadoop', 69)),
('Jack', ('Spark', 91)),
('Jack', ('NoSQL', 72)),
('Mike', ('Hadoop', 88)),
('Mike', ('Spark', 77)),
('Mike', ('NoSQL', 89))]]
实验3
实验3:
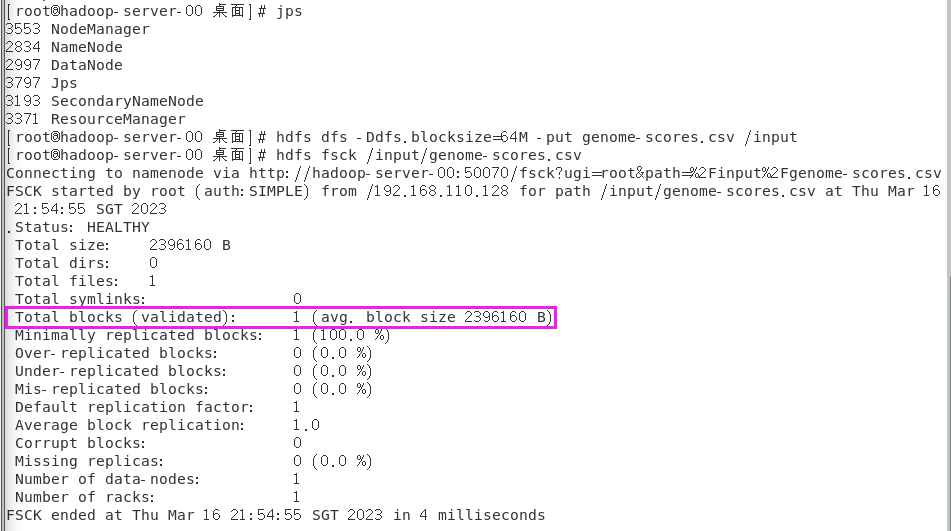
(1) 把genome-scores.csv文件上传到Ubuntu虚拟机的HDFS的/input目录中,同时设置以64MB作为HDFS数据块的分割依据
hdfs dfs -Ddfs.blocksize=64M -put genome-scores.csv /input
(2) 查看genome-scores.csv被分多少个HDFS数据块
hdfs fsck /input/genome-scores.csv
(3) 在Windows中读取HDFS的genome-scores.csv文件后,获取RDD的的分区个数
sc.textFile("hdfs://hadoop-server-00:9000/input/genome-scores.csv")\
.getNumPartitions()
2
(4) 在Windows中读取HDFS的genome-scores.csv文件后, 将其减少到1个分区,并以"org.apache.hadoop.io.compress.GzipCodec"形式压缩后重新保存到/input/scores目录中
sc.textFile(r"hdfs://hadoop-server-00:9000/input/genome-scores.csv")\
.coalesce(1).saveAsTextFile(r"hdfs://hadoop-server-00:9000/input/scores","org.apache.hadoop.io.compress.GzipCodec")
实验4
实验4:已知:list01= [“Java”, “HBase”, “MongoDB”, “Hive”, “Python”, “Hadoop”], 请编程找出该列表中的并以"H"开头的课程,以列表返回。同时通过累加器变量返回以"H"开头的课程的个数
# 创建累加器变量
count01 = sc.accumulator(0)
list01= ["Java", "HBase", "MongoDB", "Hive", "Python", "Hadoop"]
rdd = sc.parallelize(list01)
# rdd1 = rdd.filter(lambda x:'H' in x)
def f(x):
global count01;
if 'H' in x:
# count01.add(1)
count01 += 1
return True
print(rdd.filter(f).collect(),count01,sep ="\n")
['HBase', 'Hive', 'Hadoop']
3
实验5
实验5:已知:
gender = { 0: “男”, 1: “女”}
address = [(“张三”, 0, “郑州”), (“李四”, 0, “洛阳”), (“王五”, 0, “许昌”), (“赵柳”, 1, “开封”)]
请利用广播变量编程,将address列表关联到gender字典,输出结果:
[(“张三”, “男”, “郑州”), (“李四”, “男”, “洛阳”), (“王五”, “男”, “许昌”), (“赵柳”, “女”, “开封”)]
gender = { 0: "男", 1: "女"}
address = [("张三", 0, "郑州"), ("李四", 0, "洛阳"), ("王五", 0, "许昌"), ("赵柳", 1, "开封")]
# 创建广播变量
broadcast_states = sc.broadcast(gender)
rdd = sc.parallelize(address)
def state_convert(code):
return broadcast_states.value[code]
result = rdd.map(lambda x:(x[0],state_convert(x[1]),x[2])).collect()
result
[('张三', '男', '郑州'), ('李四', '男', '洛阳'), ('王五', '男', '许昌'), ('赵柳', '女', '开封')]