目录
🍁部署主从复制
🍁mycat读写分离
🍂修改配置文件
🍂设置balance与writeType
🍂设置switchType与slaveThreshold
🍂启动程序
🍂验证读写分离
🍁垂直拆分-分库
🍂实现分库
🍂测试分库
🍂总结分库
🍁水平拆分-分表
🍂实现分表
🍂测试分表
🍂连接查询
🍁全局表
🍂修改配置文件
🍂测试全局表
🍂常用分片规则
🦐博客主页:大虾好吃吗的博客
🦐MySQL专栏:MySQL专栏地址
部署目标:本次需要开启五台服务器,主机及ip如下图所示。master1部署1主2从,master2省略从服务器,但理论上讲master2也是主服务器,只是这里省略了从服务器。Mycat的读写分离是建立在Mysql的主从复制的基础上的,所以前提是要配置好主从复制。
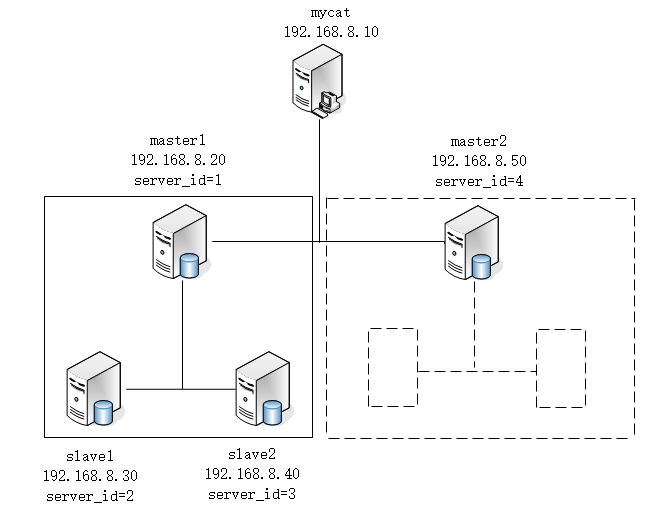
部署主从复制
前提条件,修改my.cof文件,master1、master2开启二进制日志和server_id,从节点开启server_id,最后重启mysqld服务。
[root@master1 ~]# cat /etc/my.cnf
[mysqld]
user=mysql
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/tmp/mysql.sock
server_id=1
log_bin=mysql-binmastr1登录mysql,创建主从复制用户,查看二进制文件
mysql> grant replication slave on *.* to rep@'192.168.8.%' identified by '123';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show master status\G
*************************** 1. row ***************************
File: mysql-bin.000006
Position: 446
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)登录slave1,指定主服务器。
mysql> change master to
-> master_host='192.168.8.20',
-> master_port=3306,
-> master_user='rep',
-> master_password='123',
-> master_log_file='mysql-bin.000007',
-> master_log_pos=655;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.8.20
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000007
Read_Master_Log_Pos: 655
Relay_Log_File: slave-relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000007
Slave_IO_Running: Yes
Slave_SQL_Running: Yes登录slave2,指定主服务器。
mysql> change master to
-> master_host='192.168.8.20',
-> master_port=3306,
-> master_user='rep',
-> master_password='123',
-> master_log_file='mysql-bin.000007',
-> master_log_pos=655;
Query OK, 0 rows affected, 2 warnings (0.02 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.8.20
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000007
Read_Master_Log_Pos: 655
Relay_Log_File: slave2-relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000007
Slave_IO_Running: Yes
Slave_SQL_Running: Yesmaster2因为省略了两个从节点,所以目前还不需要配置。
mycat读写分离
修改配置文件
重点修改的是baliance=“3”和主机。
[root@mycat ~]# cat /usr/local/mycat/conf/schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="localhost1" database="mytest" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://192.168.8.20:3306" user="root"
password="123">
<readHost host="hostS1" url="jdbc:mysql://192.168.8.30:3306" user="root"
password="123"></readHost>
<readHost host="hostS2" url="jdbc:mysql://192.168.8.40:3306" user="root"
password="123"></readHost>
</writeHost>
</dataHost>
</mycat:schema>可以看到远程的主机用户都是root,所以需要在所有mysql主机都创建一个远程root用户。注意:master1、master2、slave1、slave2都需要创建。
mysql> grant all on *.* to root@'192.168.8.%' identified by '123';
Query OK, 0 rows affected, 1 warning (0.00 sec)设置balance与writeType
Balance参数设置:
修改的balance属性,通过此属性配置读写分离的类型,负载均衡类型,目前的取值有4 种:
-
balance="0",不开启读写分离机制, 所有读操作都发送到当前可用的 writeHost 上。
-
balance="1",全部的 readHost与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从 模式(M1->S1, M2->S2,并且M1 与 M2 互为主备),正常情况下, M2,S1,S2 都参与 select 语句的负载均衡。
-
balance="2",所有读操作都随机的在 writeHost、 readhost 上分发。
-
balance="3",所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力
WriteType参数设置:
-
writeType=“0”, 所有写操作都发送到可用的writeHost上。
-
writeType=“1”,所有写操作都随机的发送到readHost。
-
writeType=“2”,所有写操作都随机的在writeHost、readhost分上发。
“readHost是从属于writeHost的,即意味着它从那个writeHost获取同步数据,因此,当它所属的writeHost宕机了,则它也不会再参与到读写分离中来,即“不工作了”,这是因为此时,它的数据已经“不可靠”了。基于这个考虑,目前mycat 1.3和1.4版本中,若想支持MySQL一主一从的标准配置,并且在主节点宕机的情况下,从节点还能读取数据,则需要在Mycat里配置为两个writeHost并设置banlance=1。”
设置switchType与slaveThreshold
switchType 目前有三种选择:
-1:表示不自动切换
1 :默认值,自动切换
2 :基于MySQL主从同步的状态决定是否切换
“Mycat心跳检查语句配置为 show slave status ,dataHost 上定义两个新属性: switchType="2" 与slaveThreshold="100",此时意味着开启MySQL主从复制状态绑定的读写分离与切换机制。Mycat心跳机制通过检测 show slave status 中的 "Seconds_Behind_Master", "Slave_IO_Running", "Slave_SQL_Running" 三个字段来确定当前主从同步的状态以及Seconds_Behind_Master主从复制时延。“
启动程序
-
控制台启动 : 去mycat/bin 目录下执行 ./mycat console
-
后台启动 :去mycat/bin 目录下./mycat start 为了能第一时间看到启动日志,方便定位问题,这里我们选择控制台启动。
[root@mycat ~]# mycat console
Running Mycat-server...
Removed stale pid file: /usr/local/mycat/logs/mycat.pid
wrapper | --> Wrapper Started as Console
wrapper | Launching a JVM...
jvm 1 | Wrapper (Version 3.2.3) http://wrapper.tanukisoftware.org
jvm 1 | Copyright 1999-2006 Tanuki Software, Inc. All Rights Reserved.
jvm 1 |
jvm 1 | Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.验证读写分离
登录master1修改my.cnf文件,添加binlog_format参数。创建mytest库、tb1表。
[root@master1 ~]# vim /etc/my.cnf
#添加下面参数
binlog_format=STATEMENT
[root@master1 ~]# systemctl restart mysql #重启后稍等查看slave两个线程yes
[root@master1 ~]# mysql -uroot -p123
#省略部分内容
mysql> create database mytest character set utf8;
Query OK, 1 row affected (0.01 sec)
mysql> use mytest;
Database changed
mysql> create table tb1(
-> id int,
-> name varchar(20));
Query OK, 0 rows affected (0.02 sec)1. 在master1主机插入下列数据,就可以测试主从主机数据不一致了。 (@@hostname表示插入的变量为主机名)
mysql> insert into tb1 values(1,@@hostname);
Query OK, 1 row affected, 1 warning (0.02 sec)2. 登录mycat里查询tb1表,刷新两次可以看到两个name列不同,因为读的是从表,但是主机名不一样。所以可以分析出,读写分离成功。
[root@master2 ~]# mysql -umycat -p123456 -P8066 -h 192.168.8.10
#省略部分内容
mysql> use TESTDB;
mysql> select * from tb1;
+----+-------+
| id | name |
+----+-------+
| 1 | slave |
+----+-------+
1 row in set (0.01 sec)
mysql> select * from tb1;
+----+--------+
| id | name |
+----+--------+
| 1 | slave2 |
+----+--------+
1 row in set (0.01 sec)垂直拆分-分库
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类, 分布到不同 的数据库上面,这样也就将数据或者说压力分担到不同的库上面, 如何划分表 分库的原则: 有紧密关联关系的表应该在一个库里,相互没有关联关系的表可以分到不同的库里。
#客户表 rows:20万
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(200),
PRIMARY KEY(id)
);
#订单表 rows:600万
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
#订单详细表 rows:600万
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
#订单状态字典表 rows:20
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);上面有四个表如何分库?客户表分在一个数据库,另外三张都需要关联查询,分在另外一个数据库。
实现分库
因为master2没有mytest库,所以提前需要登录master2,创建该库(生产环境中,会直接备份,然后导入)。
[root@master2 ~]# mysql -uroot -p123
#省略部分内容
mysql> create database mytest character set utf8;
Query OK, 1 row affected (0.00 sec)修改配置文件
登录mycat,修改schema.xml 配置文件
[root@mycat conf]# cd /usr/local/mycat/conf/
[root@mycat conf]# cat schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="customer" dataNode="dn2"></table> #添加
</schema>
<dataNode name="dn1" dataHost="localhost1" database="mytest" />
<dataNode name="dn2" dataHost="localhost2" database="mytest" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://192.168.8.20:3306" user="root"
password="123">
<readHost host="hostS1" url="jdbc:mysql://192.168.8.30:3306" user="root"
password="123"></readHost>
<readHost host="hostS2" url="jdbc:mysql://192.168.8.40:3306" user="root"
password="123"></readHost>
</writeHost>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0" #下面七行添加
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM2" url="jdbc:mysql://192.168.8.50:3306" user="root"
password="123">
</writeHost>
</dataHost>
</mycat:schema>
[root@mycat conf]# mycat console
Running Mycat-server...
wrapper | --> Wrapper Started as Console
wrapper | Launching a JVM...
jvm 1 | Wrapper (Version 3.2.3) http://wrapper.tanukisoftware.org
jvm 1 | Copyright 1999-2006 Tanuki Software, Inc. All Rights Reserved.
jvm 1 |
jvm 1 | Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.测试分库
登录mycat登录,创建四个表。
[root@master2 ~]# mysql -umycat -p123456 -P8066 -h 192.168.8.10
#省略登录信息
mysql> use TESTDB;
mysql> CREATE TABLE customer(
-> id INT AUTO_INCREMENT,
-> NAME VARCHAR(200),
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.02 sec)
OK!
mysql> CREATE TABLE orders(
-> id INT AUTO_INCREMENT,
-> order_type INT,
-> customer_id INT,
-> amount DECIMAL(10,2),
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.01 sec)
OK!
mysql> CREATE TABLE orders_detail(
-> id INT AUTO_INCREMENT,
-> detail VARCHAR(2000),
-> order_id INT,
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.01 sec)
OK!
mysql> CREATE TABLE dict_order_type(
-> id INT AUTO_INCREMENT,
-> order_type VARCHAR(200),
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.03 sec)
OK!分别登录master1、master2,查看表。
master1为:
mysql> show tables;
+------------------+
| Tables_in_mytest |
+------------------+
| dict_order_type |
| orders |
| orders_detail |
| tb1 |
+------------------+
4 rows in set (0.00 sec)master2为:
mysql> show tables;
+------------------+
| Tables_in_mytest |
+------------------+
| CUSTOMER |
+------------------+
1 row in set (0.00 sec)
mysql> desc CUSTOMER;
+-------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+----------------+
| ID | int(11) | NO | PRI | NULL | auto_increment |
| NAME | varchar(200) | YES | | NULL | |
+-------+--------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)总结分库
由上可见,分库成功,简单的来讲,由mycat修改配置文件,dn1指向master1,dn2指向master2。登录mycat创建表,customer表已经指定dn2了,而其他表则创建到dn1。
水平拆分-分表
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中, 每个表中 包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就 是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中。
实现分表
选择要拆分的表 MySQL 单表存储数据条数是有瓶颈的,单表达到 1000 万条数据就达到了瓶颈,会影响查询效率, 需要进行水平拆分(分表) 进行优化。 例如:例子中的 orders、 orders_detail 都已经达到600 万行数据,需要进行分表优化。 分表字段 以 orders 表为例,可以根据不同自字段进行分表
| 编号 | 分表字段 | 效果 |
|---|---|---|
| 1 | id(主键、 或创建时间) | 查询订单注重时效,历史订单被查询的次数少,如此分片会造成一个节点访问多,一个访问少,不平均。 |
| 2 | customer_id(客户id) | 根据客户 id 去分,两个节点访问平均,一个客户的所有订单都在同一个节点 |
修改配置文件
登录mycat服务器,修改schema.xml 配置文件,为 orders 表设置数据节点为 dn1、 dn2, 并指定分片规则为 mod_rule(自定义的名字)
[root@mycat conf]# cat schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="customer" dataNode="dn2"></table>
<table name="orders" dataNode="dn1,dn2" rule="mod_rule"> #添加
</table> #添加
</schema>
<dataNode name="dn1" dataHost="localhost1" database="mytest" />
<dataNode name="dn2" dataHost="localhost2" database="mytest" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://192.168.8.20:3306" user="root"
password="123">
<readHost host="hostS1" url="jdbc:mysql://192.168.8.30:3306" user="root"
password="123"></readHost>
<readHost host="hostS2" url="jdbc:mysql://192.168.8.40:3306" user="root"
password="123"></readHost>
</writeHost>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM2" url="jdbc:mysql://192.168.8.50:3306" user="root"
password="123">
</writeHost>
</dataHost>
</mycat:schema>登录mycat服务器,修改配置文件 rule.xml,具体修改内容看下图红框中内容。
[root@mycat conf]# vim rule.xml
#省略部分内容
<tableRule name="mod_rule"> #修改
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
#省略部分内容
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property> #修改
</function>
#省略部分内容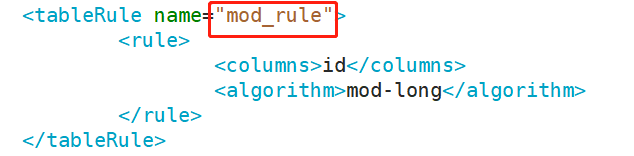

#在 rule 配置文件里新增分片规则 mod_rule,并指定规则适用字段为id。
#还有选择分片算法 mod-long(对字段求模运算) , id 对两个节点求模,根据结果分片。
#配置算法 mod-long 参数 count 为 2,两个节点。
测试分表
1. 在数据节点 dn2 上建 orders 表
[root@master2 ~]# mysql -uroot -p123
#省略部分内容
mysql> use mytest;
mysql> CREATE TABLE orders(
-> id INT AUTO_INCREMENT,
-> order_type INT,
-> customer_id INT,
-> amount DECIMAL(10,2),
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.03 sec)2. 重启 Mycat,让配置生效
[root@mycat conf]# mycat console3. 访问 Mycat 实现分片
[root@master2 ~]# mysql -umycat -p123456 -P8066 -h192.168.8.104. 在 mycat 里向 orders 表插入下面六行数据, INSERT 字段不能省略
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);5. 分别在mycat、master1、master2中查看orders表数据,分表成功
#mycat
mysql> select * from orders;
+------+------------+-------------+-----------+
| id | order_type | customer_id | amount |
+------+------------+-------------+-----------+
| 2 | 101 | 100 | 100300.00 |
| 4 | 101 | 101 | 103000.00 |
| 6 | 102 | 100 | 100020.00 |
| 1 | 101 | 100 | 100100.00 |
| 3 | 101 | 101 | 120000.00 |
| 5 | 102 | 101 | 100400.00 |
+------+------------+-------------+-----------+
6 rows in set (0.01 sec)
#master1
mysql> select * from orders;
+----+------------+-------------+-----------+
| id | order_type | customer_id | amount |
+----+------------+-------------+-----------+
| 2 | 101 | 100 | 100300.00 |
| 4 | 101 | 101 | 103000.00 |
| 6 | 102 | 100 | 100020.00 |
+----+------------+-------------+-----------+
3 rows in set (0.00 sec)
#master2
mysql> select * from orders;
+----+------------+-------------+-----------+
| id | order_type | customer_id | amount |
+----+------------+-------------+-----------+
| 1 | 101 | 100 | 100100.00 |
| 3 | 101 | 101 | 120000.00 |
| 5 | 102 | 101 | 100400.00 |
+----+------------+-------------+-----------+
3 rows in set (0.00 sec)连接查询
1. 登录mycat服务器,修改配置文件,添加下列内容,表示可以外键连接。
[root@mycat conf]# cat schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="customer" dataNode="dn2"></table>
<table name="orders" dataNode="dn1,dn2" rule="mod_rule">
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" /> #添加
</table>
#省略部分内容2. 登录master2上创建 orders_detail表。
[root@master2 ~]# mysql -uroot -p123
mysql> use mytest;
mysql> CREATE TABLE orders_detail(
-> id INT AUTO_INCREMENT,
-> detail VARCHAR(2000),
-> order_id INT,
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.01 sec)3. 重启 Mycat 访问,并登录Mycat 向 orders_detail 表插入数据
[root@mycat conf]# mycat console重启后登录mycat
[root@master2 ~]# mysql -umycat -p123456 -P8066 -h192.168.8.10
#省略部分内容
mysql> use TESTDB;
mysql> insert into orders_detail(id,detail,order_id) values (1,'detail',1);
Query OK, 1 row affected (0.25 sec)
OK!
mysql> insert into orders_detail(id,detail,order_id) values (2,'detail',2);
Query OK, 1 row affected (0.02 sec)
OK!
mysql> insert into orders_detail(id,detail,order_id) values (3,'detail',3);
Query OK, 1 row affected (0.01 sec)
OK!
mysql> insert into orders_detail(id,detail,order_id) values (4,'detail',4);
Query OK, 1 row affected (0.01 sec)
OK!
mysql> insert into orders_detail(id,detail,order_id) values (5,'detail',5);
Query OK, 1 row affected (0.01 sec)
OK!
mysql> insert into orders_detail(id,detail,order_id) values (6,'detail',6);
Query OK, 1 row affected (0.01 sec)
OK!
mysql> select o.*,od.detail from orders as o inner join orders_detail as od on o.id=od.order_id;
+------+------------+-------------+-----------+--------+
| id | order_type | customer_id | amount | detail |
+------+------------+-------------+-----------+--------+
| 2 | 101 | 100 | 100300.00 | detail |
| 4 | 101 | 101 | 103000.00 | detail |
| 6 | 102 | 100 | 100020.00 | detail |
| 1 | 101 | 100 | 100100.00 | detail |
| 3 | 101 | 101 | 120000.00 | detail |
| 5 | 102 | 101 | 100400.00 | detail |
+------+------------+-------------+-----------+--------+
6 rows in set (0.07 sec)全局表
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联, 就成了比较 棘手的问题,考虑到字典表具有以下几个特性:
1、 变动不频繁
2、 数据量总体变化不大
3、数据规模不大,很少有超过数十万条记录 鉴于此, Mycat 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
-
全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
-
全局表的查询操作,只从一个节点获取
-
全局表可以跟任何一个表进行 JOIN 操作 将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据 JOIN 的难题。 通过全局表+基于 E-R 关系的分片策略, Mycat 可以满足 80%以上的企业应用开发
修改配置文件
登录mycat修改 schema.xml 配置文件
[root@mycat conf]# cat schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="customer" dataNode="dn2"></table>
<table name="orders" dataNode="dn1,dn2" rule="mod_rule">
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" />
</table>
<table name="dict_order_type" dataNode="dn1,dn2" type="global">
</table>
</schema>
#省略部分内容
测试全局表
1. 在master2创建 dict_order_type 表
[root@master2 ~]# mysql -uroot -p123
#省略部分内容
mysql> use mytest
mysql> CREATE TABLE dict_order_type(
-> id INT AUTO_INCREMENT,
-> order_type VARCHAR(200),
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.01 sec)2. 重启 Mycat
[root@mycat conf]# mycat console3. 访问 Mycat 向 dict_order_type 表插入数据
[root@master2 ~]# mysql -umycat -p123456 -P8066 -h192.168.8.10
#省略部分内容
mysql> use TESTDB
mysql> insert into dict_order_type (id,order_type) values (101,'type1');
Query OK, 1 row affected (0.22 sec)
OK!
mysql> insert into dict_order_type (id,order_type) values (102,'type2');
Query OK, 1 row affected (0.03 sec)
OK!4. 分别登录mycat、master1、master2,查看表,最终都可以看到id为101,102的数据内容。
mysql> select * from dict_order_type;
+-----+------------+
| id | order_type |
+-----+------------+
| 101 | type1 |
| 102 | type2 |
+-----+------------+
2 rows in set (0.00 sec)常用分片规则
1、 取模 此规则为对分片字段求摸运算。 也是水平分表最常用规则。 5.1 配置分表中, orders 表采用了此规则。
2、 分片枚举 通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务 需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则。