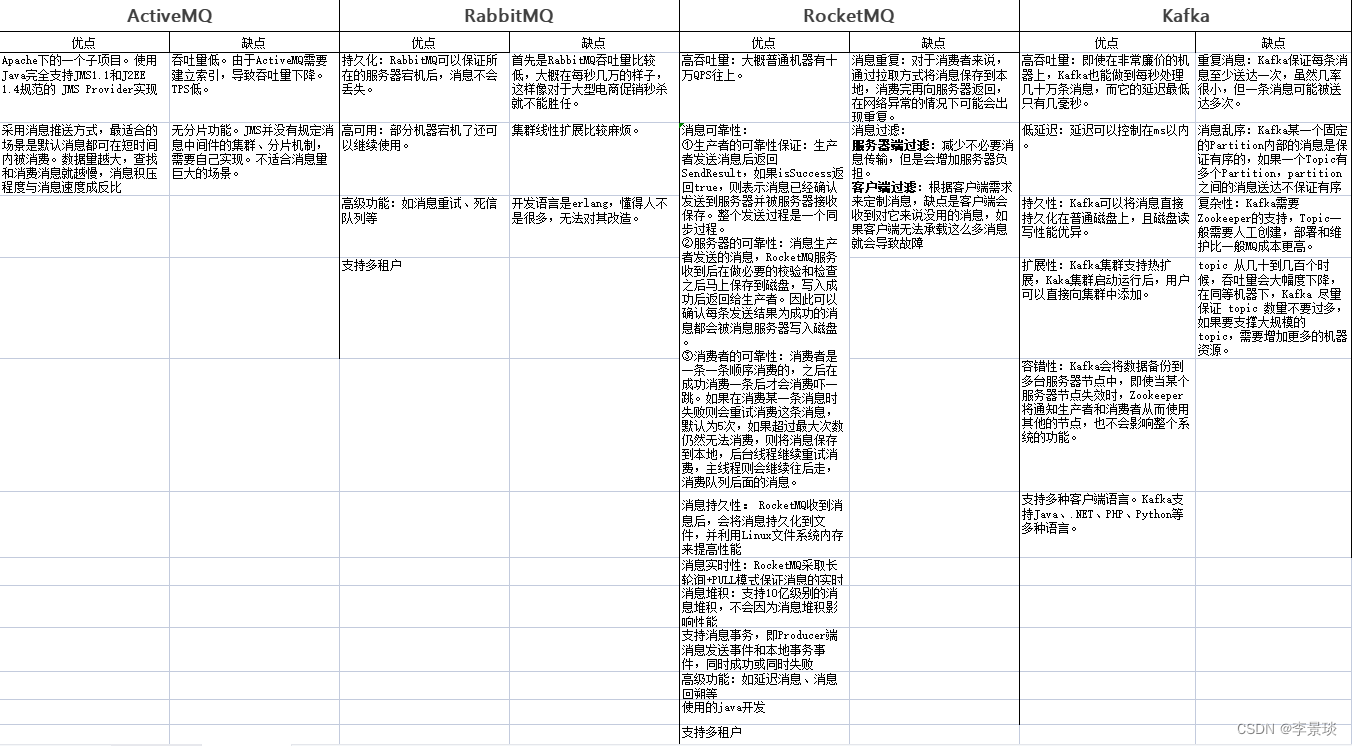
面试中经常会问到损失函数的相关问题,本文推导了深度学习中常用损失函数的计算公式和反向传播公式,并使用numpy实现。
定义损失函数基类:
class Loss:
def loss(self, predictions, targets):
raise NotImplementedError
def grad(self, predictions, targets):
raise NotImplementedError
定义损失函数中会用到的数学函数
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
def softmax(x, dim=-1):
x_max = np.max(x, axis=dim, keepdims=True)
# 减去最大值,防止上溢
x_exp = np.exp(x - x_max)
return x_exp / np.sum(x_exp, axis=dim, keepdims=True)
def log_softmax(x, dim=-1):
x_max = np.max(x, axis=dim, keepdims=True)
x_exp = np.exp(x - x_max)
exp_sum = np.sum(x_exp, axis=dim, keepdims=True)
return x - x_max - np.log(exp_sum)
def one_hot(labels, n_classes):
return np.eye(n_classes)[labels.reshape(-1)]
MAE
平均绝对误差(Mean Absolute Error):模型预测值
y
y
y和真实值
y
^
\hat y
y^之间距离的平均值
l
o
s
s
=
1
n
∑
i
∣
y
i
−
y
^
i
∣
loss = \frac{1}{n}\sum_i{|y_i-\hat y_i|}
loss=n1i∑∣yi−y^i∣
g r a d = 1 n s i g n ( y − y ^ ) grad = \frac{1}{n}sign(y-\hat y) grad=n1sign(y−y^)
class MAE(Loss):
def loss(self, predictions, targets):
return np.sum(np.abs(predictions - targets)) / targets.shape[0]
def grad(self, predictions, targets):
return np.sign(predictions - targets) / targets.shape[0]
MSE
均方差损失(Mean Squared Error Loss):模型预测值
y
y
y和真实值
y
^
\hat y
y^之间差值平方的平均值
l
o
s
s
=
1
2
n
∑
i
∣
∣
y
i
−
y
^
i
∣
∣
2
loss = \frac{1}{2n}\sum_i{||y_i-\hat y_i||^2}
loss=2n1i∑∣∣yi−y^i∣∣2
g r a d = 1 n ( y − y ^ ) grad = \frac{1}{n}(y - \hat y) grad=n1(y−y^)
class MSE(Loss):
def loss(self, predictions, targets):
return 0.5 * np.sum((predictions - targets) ** 2) / targets.shape[0]
def grad(self, predictions, targets):
return (predictions - targets) / targets.shape[0]
Huber Loss
结合了MAE和MSE的优点,也被称为 Smooth Mean Absolute Error
在误差较小时使用MSE,误差较大时使用MAE
l
o
s
s
=
1
n
{
0.5
∗
∑
i
∣
∣
y
i
−
y
^
i
∣
∣
2
,
∣
y
i
−
y
^
∣
<
δ
∑
i
δ
∣
y
i
−
y
^
i
∣
−
0.5
∗
δ
2
,
o
t
h
e
r
w
i
s
e
loss=\frac{1}{n}\left\{ \begin{aligned} & 0.5* \sum_i{||y_i-\hat y_i||^2}, \quad \quad |y_i - \hat y| < \delta \\ & \sum_i{\delta |y_i-\hat y_i| - 0.5 * \delta^2}, \quad \quad otherwise \\ \end{aligned} \right.
loss=n1⎩
⎨
⎧0.5∗i∑∣∣yi−y^i∣∣2,∣yi−y^∣<δi∑δ∣yi−y^i∣−0.5∗δ2,otherwise
g r a d = 1 n { y − y ^ , ∣ y − y ^ ∣ < δ δ s i g n ( y − y ^ ) , o t h e r w i s e grad=\frac{1}{n}\left\{ \begin{aligned} & y-\hat y,\quad \quad |y - \hat y| < \delta \\ & \delta sign(y-\hat y),\quad \quad otherwise \\ \end{aligned} \right. grad=n1{y−y^,∣y−y^∣<δδsign(y−y^),otherwise

class HuberLoss(Loss):
def __init__(self, delta=1.0):
self.delta = delta
def loss(self, predictions, targets):
dist = np.abs(predictions - targets)
l2_mask = dist < self.delta
l1_mask = ~l2_mask
l2_loss = 0.5 * (predictions - targets) ** 2
l1_loss = self.delta * dist - 0.5 * self.delta ** 2
total_loss = np.sum(l2_loss * l2_mask + l1_loss * l1_mask) / targets.shape[0]
return total_loss
def grad(self, predictions, targets):
error = predictions - targets
l2_mask = np.abs(error) < self.delta
l1_mask = ~l2_mask
l2_grad = error
l1_grad = self.delta * np.sign(error)
total_grad = l2_grad * l2_mask + l1_grad * l1_mask
return total_grad / targets.shape[0]
Cross Entropy Loss
熵
熵定义为:信息的数学期望。
H
=
−
∑
i
p
(
x
i
)
l
o
g
(
p
(
x
i
)
)
H = -\sum_i{p(x_i)log(p(x_i))}
H=−i∑p(xi)log(p(xi))
KL散度
KL散度(Kullback-Leibler Divergence)也叫做相对熵,用于度量两个概率分布之间的差异程度,p相对q的KL散度为
D
q
(
p
)
=
H
q
(
p
)
−
H
(
p
)
=
∑
x
p
l
o
g
(
p
)
−
p
l
o
g
(
q
)
D_q(p) = H_q(p) - H(p) = \sum_x{plog(p)-plog(q)}
Dq(p)=Hq(p)−H(p)=x∑plog(p)−plog(q)
交叉熵
预测概率分布q与真实概率分布p的差异
H
q
(
p
)
=
−
∑
x
p
l
o
g
(
q
)
H_q(p) = -\sum_{x} p log(q)
Hq(p)=−x∑plog(q)
详细推导:
l
o
s
s
=
−
1
N
∑
i
=
1
N
∑
k
=
1
K
y
^
i
k
⋅
l
o
g
_
s
o
f
t
m
a
x
(
y
i
k
)
=
−
∑
i
=
1
N
l
o
g
_
s
o
f
t
m
a
x
(
y
i
c
)
loss = -\frac{1}{N} \sum_{i=1}^N\sum_{k=1}^{K}\hat y_i^k \cdot log\_softmax(y_i^k) = -\sum_{i=1}^Nlog\_softmax(y_i^c)
loss=−N1i=1∑Nk=1∑Ky^ik⋅log_softmax(yik)=−i=1∑Nlog_softmax(yic)
y
c
y^c
yc是标签,
y
^
\hat y
y^是标签的独热编码,
y
y
y是预测概率向量,向量长度等于
y
y
y的类别
K
K
K
化简:
C
E
=
−
l
o
g
_
s
o
f
t
m
a
x
(
y
c
)
=
−
l
o
g
(
e
x
p
(
y
c
)
∑
k
=
1
K
e
x
p
(
y
k
)
)
=
−
y
c
+
l
o
g
(
∑
k
=
1
K
e
x
p
(
y
k
)
)
CE = -log\_softmax(y^c) = -log(\frac {exp(y^c)}{\sum_{k=1}^{K}exp(y^k)})=-y^c + log(\sum_{k=1}^{K}exp(y^k))
CE=−log_softmax(yc)=−log(∑k=1Kexp(yk)exp(yc))=−yc+log(k=1∑Kexp(yk))
求导:
g
r
a
d
=
1
N
∑
i
=
1
N
∂
C
E
i
∂
y
i
=
1
N
∑
i
=
1
N
s
o
f
t
m
a
x
(
y
i
)
−
y
^
i
grad = \frac{1}{N}\sum_{i=1}^N\frac{\partial CE_i}{\partial y_i} = \frac{1}{N}\sum_{i=1}^N softmax(y_i) - \hat y_i
grad=N1i=1∑N∂yi∂CEi=N1i=1∑Nsoftmax(yi)−y^i
class CrossEntropy(Loss):
def loss(self, predictions, targets):
# targets是one-hot向量
ce = -log_softmax(predictions, dim=1) * targets
return np.sum(ce) / targets.shape[0]
def grad(self, predictions, targets):
logits = softmax(predictions, dim=1)
return (logits - targets) / targets.shape[0]
上面的代码中不同类别的权重是相等的,如果不同类别的样本数量差异过大,可以调整不同类别的权重。
顺便实现一下KL散度
注意,交叉熵的标签是one-hot向量,KL散度的标签是概率分布向量
下面是更通用的推导,
y
^
\hat y
y^是概率向量,
∑
k
=
1
K
y
^
k
=
1
\sum_{k=1}^{K}\hat y^k=1
∑k=1Ky^k=1
C
E
=
−
∑
k
=
1
K
y
^
k
l
o
g
_
s
o
f
t
m
a
x
(
y
c
)
=
−
∑
k
=
1
K
y
^
k
l
o
g
(
e
x
p
(
y
k
)
∑
k
=
1
K
e
x
p
(
y
k
)
)
=
−
∑
k
=
1
K
[
y
i
k
−
l
o
g
(
∑
k
=
1
K
e
x
p
(
y
k
)
)
]
⋅
y
^
i
k
=
l
o
g
(
∑
k
=
1
K
e
x
p
(
y
k
)
)
−
∑
k
=
1
K
y
i
k
⋅
y
^
i
k
CE = -\sum_{k=1}^{K}\hat y^klog\_softmax(y^c) = -\sum_{k=1}^{K}\hat y^klog(\frac {exp(y^k)}{\sum_{k=1}^{K}exp(y^k)})=-\sum_{k=1}^{K}[y_i^k - log(\sum_{k=1}^{K}exp(y^k))]\cdot \hat y_i^k = log(\sum_{k=1}^{K}exp(y^k))-\sum_{k=1}^{K}y_i^k \cdot \hat y_i^k
CE=−k=1∑Ky^klog_softmax(yc)=−k=1∑Ky^klog(∑k=1Kexp(yk)exp(yk))=−k=1∑K[yik−log(k=1∑Kexp(yk))]⋅y^ik=log(k=1∑Kexp(yk))−k=1∑Kyik⋅y^ik
g r a d = 1 N ∑ i = 1 N ∂ C E i ∂ y i = 1 N ∑ i = 1 N s o f t m a x ( y i ) − y ^ i grad = \frac{1}{N}\sum_{i=1}^N\frac{\partial CE_i}{\partial y_i} = \frac{1}{N}\sum_{i=1}^N softmax(y_i) - \hat y_i grad=N1i=1∑N∂yi∂CEi=N1i=1∑Nsoftmax(yi)−y^i
class KLDivLoss(Loss):
def loss(self, predictions, targets):
# targets是概率向量
ce = (log_softmax(targets) - np.log(predictions)) * targets
return np.sum(ce) / targets.shape[0]
def grad(self, predictions, targets):
logits = softmax(predictions, dim=1)
return (logits - targets) / targets.shape[0]
扩展:
为什么在分类任务中,用交叉熵而不是MSE?
以Logistic Regression为例,分别用交叉熵和MSE推导反向传播过程
f
w
,
b
(
x
)
=
σ
(
∑
i
w
i
x
i
+
b
)
f_{w,b}(x) = \sigma(\sum_i{w_ix_i+b})
fw,b(x)=σ(i∑wixi+b)
其中,
σ
\sigma
σ是Sigmoid激活函数,f是预测值,0 < f(x) < 1
1.交叉熵
L
=
−
[
y
l
n
(
f
(
x
)
)
+
(
1
−
y
)
l
n
(
1
−
f
(
x
)
)
]
y
∈
{
0
,
1
}
L = -[yln(f(x)) + (1-y)ln(1-f(x))] \quad y \in \{0,1\}
L=−[yln(f(x))+(1−y)ln(1−f(x))]y∈{0,1}
反向传播:
∂
L
(
w
,
b
)
∂
w
=
−
[
y
∂
l
n
(
f
(
x
)
)
∂
w
+
(
1
−
y
)
∂
(
1
−
l
n
(
f
(
x
)
)
)
∂
w
]
\frac{\partial L(w,b)}{\partial w} = - [y \frac{\partial ln(f(x))}{\partial w} + (1-y) \frac{\partial (1-ln(f(x)))}{\partial w}]
∂w∂L(w,b)=−[y∂w∂ln(f(x))+(1−y)∂w∂(1−ln(f(x)))]
令
z
=
w
x
+
b
z=wx+b
z=wx+b,
∂
l
n
(
f
(
x
)
)
∂
z
=
∂
l
n
(
σ
(
z
)
)
∂
z
=
1
−
σ
(
z
)
∂
(
1
−
l
n
(
f
(
x
)
)
)
∂
w
=
−
σ
(
z
)
\frac{\partial ln(f(x))}{\partial z} = \frac{\partial ln(\sigma(z))}{\partial z} = 1 - \sigma(z) \qquad \frac{\partial (1-ln(f(x)))}{\partial w} = - \sigma(z)
∂z∂ln(f(x))=∂z∂ln(σ(z))=1−σ(z)∂w∂(1−ln(f(x)))=−σ(z)
∂ L ( w , b ) ∂ z ∂ z ∂ w = − [ y ( 1 − σ ( z ) ) + ( 1 − y ) ( − σ ( z ) ) ] ∂ z ∂ w = − ( y − σ ( z ) ) x \frac{\partial L(w,b)}{\partial z} \frac{\partial z}{\partial w} = -[y(1-\sigma (z)) + (1-y)(-\sigma (z))]\frac{\partial z}{\partial w} = - (y - \sigma(z))x ∂z∂L(w,b)∂w∂z=−[y(1−σ(z))+(1−y)(−σ(z))]∂w∂z=−(y−σ(z))x
梯度下降:
w
t
=
w
t
−
1
−
η
∑
i
(
−
(
y
i
−
σ
(
w
x
+
b
)
)
x
i
)
w_t = w_{t-1} - \eta \sum_i(- (y_i - \sigma(wx+b))x_i)
wt=wt−1−ηi∑(−(yi−σ(wx+b))xi)
- 当标签 y y y和预测值 f ( x ) f(x) f(x)差距越大,梯度越大,下降的越快
2.MSE
L
=
1
2
(
f
(
x
)
−
y
)
2
y
∈
{
0
,
1
}
L = \frac{1}{2}(f(x) - y)^2 \quad y \in \{0,1\}
L=21(f(x)−y)2y∈{0,1}
反向传播:
∂
L
(
w
,
b
)
∂
w
=
(
f
(
x
)
−
y
)
∂
f
(
x
)
∂
w
\frac{\partial L(w,b)}{\partial w} = (f(x) - y) \frac{\partial f(x)}{\partial w}
∂w∂L(w,b)=(f(x)−y)∂w∂f(x)
同令
z
=
w
x
+
b
z=wx+b
z=wx+b,
∂
f
(
x
)
∂
z
∂
z
∂
w
=
σ
(
z
)
(
1
−
σ
(
z
)
)
x
\frac{\partial f(x)}{\partial z} \frac{\partial z}{\partial w} = \sigma(z)(1-\sigma(z))x
∂z∂f(x)∂w∂z=σ(z)(1−σ(z))x
∂ L ( w , b ) ∂ w = ( f ( x ) − y ) f ( x ) ( 1 − f ( x ) ) x \frac{\partial L(w,b)}{\partial w} = (f(x) - y) f(x)(1-f(x))x ∂w∂L(w,b)=(f(x)−y)f(x)(1−f(x))x
- 当 y = 0 y=0 y=0, f ( x ) f(x) f(x)趋近1时,因为有 1 − f ( x ) 1-f(x) 1−f(x)这一项,梯度会消失,然而预测是完全错误的
- 当 y = 1 y=1 y=1, f ( x ) f(x) f(x)趋近0时,因为有 f ( x ) f(x) f(x)这一项,梯度也会消失,预测完全错误
总结:
交叉熵损失函数关于输入权重的梯度表达式与预测值与真实值的误差成正比且不含激活函数的梯度,而均方误差损失函数关于输入权重的梯度表达式中则含有,由于常用的sigmoid/tanh等激活函数存在梯度饱和区,使得MSE对权重的梯度会很小,参数w调整的慢,训练也慢,而交叉熵损失函数则不会出现此问题,其参数w会根据误差调整,训练更快,效果更好。
参考资料:
borgwang/tinynn: A lightweight deep learning library