一、pom依赖
测试案例中,pom依赖如下,根据需要自行删减。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.test</groupId>
<artifactId>Examples</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<hadoop.version>2.6.0</hadoop.version>
<flink.version>1.14.5</flink.version>
<kafka.version>2.0.0</kafka.version>
<hbase.version>1.2.0</hbase.version>
<hudi.version>0.12.0</hudi.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink1.14-bundle</artifactId>
<version>${hudi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<classifier>core</classifier>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
</exclusions>
</dependency>
<!--下面是打印日志的,可以不加-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<scope>provided</scope>
<version>2.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<scope>provided</scope>
<version>2.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<scope>provided</scope>
<version>2.17.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba.fastjson2/fastjson2 -->
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.16</version>
</dependency>
<!--restTemplate启动器-->
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-rest -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-rest</artifactId>
<version>2.7.0</version>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 配置管理 -->
<dependency>
<groupId>com.typesafe</groupId>
<artifactId>config</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
<build>
<finalName>${pom.artifactId}-${pom.version}</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.test.main.Examples</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
<resources>
<resource>
<directory>src/main/resources</directory>
<excludes>
<exclude>environment/dev/*</exclude>
<exclude>environment/test/*</exclude>
<exclude>environment/smoke/*</exclude>
<exclude>environment/pre/*</exclude>
<exclude>environment/online/*</exclude>
<exclude>application.properties</exclude>
</excludes>
</resource>
<resource>
<directory>src/main/resources/environment/${environment}</directory>
<targetPath>.</targetPath>
</resource>
</resources>
</build>
<profiles>
<profile>
<!-- 开发环境 -->
<id>dev</id>
<properties>
<environment>dev</environment>
</properties>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
</profile>
<profile>
<!-- 测试环境 -->
<id>test</id>
<properties>
<environment>test</environment>
</properties>
</profile>
<profile>
<!-- 冒烟环境 -->
<id>smoke</id>
<properties>
<environment>smoke</environment>
</properties>
</profile>
<profile>
<!-- 生产环境 -->
<id>online</id>
<properties>
<environment>online</environment>
</properties>
</profile>
</profiles>
</project>Hudi官网文档链接:
Flink Guide | Apache Hudi
二、DataStream API方式读写Hudi
2.1 写Hudi
package com.test.hudi;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.runtime.state.StateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.GenericRowData;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.data.StringData;
import org.apache.hudi.common.model.HoodieTableType;
import org.apache.hudi.configuration.FlinkOptions;
import org.apache.hudi.util.HoodiePipeline;
import java.util.HashMap;
import java.util.Map;
public class FlinkDataStreamWrite2HudiTest {
public static void main(String[] args) throws Exception {
// 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.必须开启checkpoint 默认有5个checkpoint后,hudi目录下才会有数据;不然只有一个.hoodie目录
String checkPointPath = "hdfs://hw-cdh-test02:8020/flinkinfo/meta/savepoints/FlinkDataStreamWrite2HudiTest";
StateBackend backend = new EmbeddedRocksDBStateBackend(true);
env.setStateBackend(backend);
CheckpointConfig conf = env.getCheckpointConfig();
// 任务流取消和故障应保留检查点
conf.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
conf.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
conf.setCheckpointInterval(1000);//milliseconds
conf.setCheckpointTimeout(10 * 60 * 1000);//milliseconds
conf.setMinPauseBetweenCheckpoints(2 * 1000);//相邻两次checkpoint之间的时间间隔
conf.setCheckpointStorage(checkPointPath);
// 3.准备数据
DataStreamSource<Student> studentDS = env.fromElements(
new Student(101L, "Johnson", 17L, "swimming"),
new Student(102L, "Lin", 15L, "shopping"),
new Student(103L, "Tom", 5L, "play"));
// 4.创建Hudi数据流
// 4.1 Hudi表名和路径
String studentHudiTable = "ods_student_table";
String studentHudiTablePath = "hdfs://hw-cdh-test02:8020/user/hive/warehouse/lake/" + studentHudiTable;
Map<String, String> studentOptions = new HashMap<>();
studentOptions.put(FlinkOptions.PATH.key(), studentHudiTablePath);
studentOptions.put(FlinkOptions.TABLE_TYPE.key(), HoodieTableType.MERGE_ON_READ.name());
HoodiePipeline.Builder studentBuilder = HoodiePipeline.builder(studentHudiTable)
.column("id BIGINT")
.column("name STRING")
.column("age BIGINT")
.column("hobby STRING")
.pk("id")
// .pk("id,age")// 可以设置联合主键,用逗号分隔
.options(studentOptions);
// 5.转成RowData流
DataStream<RowData> studentRowDataDS = studentDS.map(new MapFunction<Student, RowData>() {
@Override
public RowData map(Student value) throws Exception {
try {
Long id = value.id;
String name = value.name;
Long age = value.age;
String hobby = value.hobby;
GenericRowData row = new GenericRowData(4);
row.setField(0, Long.valueOf(id));
row.setField(1, StringData.fromString(name));
row.setField(2, Long.valueOf(age));
row.setField(3, StringData.fromString(hobby));
return row;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
});
studentBuilder.sink(studentRowDataDS, false);
env.execute("FlinkDataStreamWrite2HudiTest");
}
public static class Student{
public Long id;
public String name;
public Long age;
public String hobby;
public Student() {
}
public Student(Long id, String name, Long age, String hobby) {
this.id = id;
this.name = name;
this.age = age;
this.hobby = hobby;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Long getAge() {
return age;
}
public void setAge(Long age) {
this.age = age;
}
public String getHobby() {
return hobby;
}
public void setHobby(String hobby) {
this.hobby = hobby;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
", hobby='" + hobby + '\'' +
'}';
}
}
}
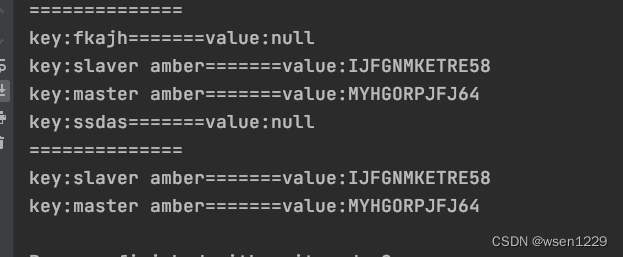
案例中,通过env.fromElements造三条数据写入Hudi,通过查询,可证明3条数据写入成功:
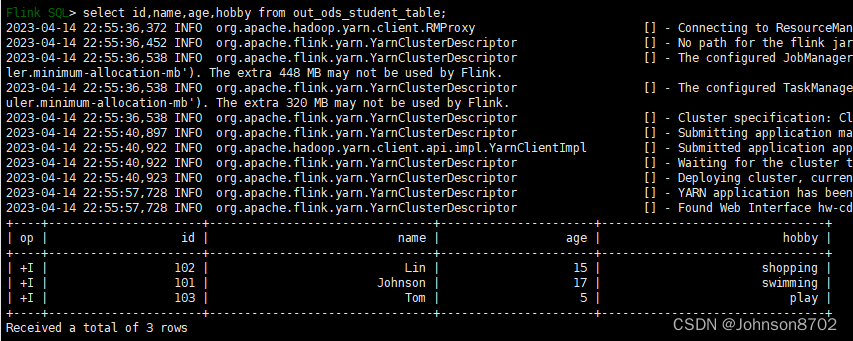
在实际开发中,需要切换数据源,比如从kafka读取数据,写入Hudi,将上面的数据源进行替换,并完成RowData转换即可。(切记,一定要开启checkpoint,否则只有一个,hoodie目录。本人在这里踩过坑,调了一个下午,数据都没有写入成功,只有一个hoodie目录,后来经过研究才知道需要设置checkpoint。本案例中,由于是造的三条数据,跑完之后程序就停了,不设置checkpoint,数据也会写入hudi表;但是如果正在的流计算,从kafka读数据,写入hudi,如果不设置checkpoint,数据最终无法写入hudi表)。
2.2 读Hudi
package com.test.hudi;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hudi.common.model.HoodieTableType;
import org.apache.hudi.configuration.FlinkOptions;
import org.apache.hudi.util.HoodiePipeline;
import java.util.HashMap;
import java.util.Map;
public class FlinkDataStreamReadFromHudiTest {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.创建Hudi数据流
String studentHudiTable = "ods_student_table";
String studentHudiTablePath = "hdfs://hw-cdh-test02:8020/user/hive/warehouse/lake/" + studentHudiTable;
Map<String, String> studentOptions = new HashMap<>();
studentOptions.put(FlinkOptions.PATH.key(), studentHudiTablePath);
studentOptions.put(FlinkOptions.TABLE_TYPE.key(), HoodieTableType.MERGE_ON_READ.name());
studentOptions.put(FlinkOptions.READ_AS_STREAMING.key(), "true");// this option enable the streaming read
studentOptions.put(FlinkOptions.READ_START_COMMIT.key(), "16811748000000");// specifies the start commit instant time
studentOptions.put(FlinkOptions.READ_STREAMING_CHECK_INTERVAL.key(), "4");//
studentOptions.put(FlinkOptions.CHANGELOG_ENABLED.key(), "true");//
HoodiePipeline.Builder studentBuilder = HoodiePipeline.builder(studentHudiTable)
.column("id BIGINT")
.column("name STRING")
.column("age BIGINT")
.column("hobby STRING")
.pk("id")
.options(studentOptions);
DataStream<RowData> studentRowDataDS = studentBuilder.source(env);
// 3. 数据转换与输出
DataStream<Student> studentDS = studentRowDataDS.map(new MapFunction<RowData, Student>() {
@Override
public Student map(RowData value) throws Exception {
try {
String rowKind = value.getRowKind().name();
Long id = value.getLong(0);
String name = value.getString(1).toString();
Long age = value.getLong(2);
String hobby = value.getString(3).toString();
Student student = new Student(id, name, age, hobby, rowKind);
return student;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
});
studentDS.print();
env.execute("FlinkDataStreamReadFromHudiTest");
}
public static class Student{
public Long id;
public String name;
public Long age;
public String hobby;
public String rowKind;
public Student() {
}
public Student(Long id, String name, Long age, String hobby, String rowKind) {
this.id = id;
this.name = name;
this.age = age;
this.hobby = hobby;
this.rowKind = rowKind;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Long getAge() {
return age;
}
public void setAge(Long age) {
this.age = age;
}
public String getHobby() {
return hobby;
}
public void setHobby(String hobby) {
this.hobby = hobby;
}
public String getRowKind() {
return rowKind;
}
public void setRowKind(String rowKind) {
this.rowKind = rowKind;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
", hobby='" + hobby + '\'' +
", rowKind='" + rowKind + '\'' +
'}';
}
}
}
输出结果:

其中,rowKind,是对行的描述,有 INSERT, UPDATE_BEFORE, UPDATE_AFTER, DELETE,分别对应op的 +I, -U, +U, -D,表示 插入、更新前、更新后、删除 操作。
三、Table API方式读写Hudi
3.1 写Hudi
3.1.1 数据来自DataStream
package com.test.hudi;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.runtime.state.StateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FlinkDataStreamSqlWrite2HudiTest {
public static void main(String[] args) throws Exception {
// 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tabEnv = StreamTableEnvironment.create(env);
// 2.必须开启checkpoint 默认有5个checkpoint后,hudi目录下才会有数据;不然只有一个.hoodie目录
String checkPointPath = "hdfs://hw-cdh-test02:8020/flinkinfo/meta/savepoints/FlinkDataStreamWrite2HudiTest";
StateBackend backend = new EmbeddedRocksDBStateBackend(true);
env.setStateBackend(backend);
CheckpointConfig conf = env.getCheckpointConfig();
// 任务流取消和故障应保留检查点
conf.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
conf.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
conf.setCheckpointInterval(1000);//milliseconds
conf.setCheckpointTimeout(10 * 60 * 1000);//milliseconds
conf.setMinPauseBetweenCheckpoints(2 * 1000);//相邻两次checkpoint之间的时间间隔
conf.setCheckpointStorage(checkPointPath);
// 3.准备数据,真实环境中,这里可以替换成从kafka读取数据
DataStreamSource<Student> studentDS = env.fromElements(
new Student(201L, "zhangsan", 117L, "eat"),
new Student(202L, "lisi", 115L, "drink"),
new Student(203L, "wangwu", 105L, "sleep"));
// 由于后续没有DataStream的执行算子,可以会报错:
// Exception in thread "main" java.lang.IllegalStateException: No operators defined in streaming topology. Cannot execute.
// 不过不影响数据写入Hudi
// 当然,也可以加一步DataStream的执行算子,比如 print
// studentDS.print("DataStream: ");
// 4.通过DataStream创建表
// 4.1 第一个参数:表名;第二个参数:DataStream;第三个可选参数:指定列名,可以指定DataStream中的元素名和列名的匹配关系,比如 "userId as user_id, name, age, hobby"
tabEnv.registerDataStream("tmp_student_table", studentDS, "id, name, age, hobby");
// 5.准备Hudi表的数据流,并将数据写入Hudi表
tabEnv.executeSql("" +
"CREATE TABLE out_ods_student_table(\n" +
" id BIGINT COMMENT '学号',\n" +
" name STRING\t COMMENT '姓名',\n" +
" age BIGINT COMMENT '年龄',\n" +
" hobby STRING COMMENT '爱好',\n" +
" PRIMARY KEY (id) NOT ENFORCED\n" +
")\n" +
"WITH(\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 'hdfs://hw-cdh-test02:8020/user/hive/warehouse/lake/ods_student_table',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'compaction.async.enabled' = 'true',\n" +
" 'compaction.tasks' = '1',\n" +
" 'compaction.trigger.strategy' = 'num_commits',\n" +
" 'compaction.delta_commits' = '3',\n" +
" 'hoodie.cleaner.policy'='KEEP_LATEST_COMMITS',\n" +
" 'hoodie.cleaner.commits.retained'='30',\n" +
" 'hoodie.keep.min.commits'='35' ,\n" +
" 'hoodie.keep.max.commits'='40'\n" +
")");
tabEnv.executeSql("insert into out_ods_student_table select id,name,age,hobby from tmp_student_table");
env.execute("FlinkDataStreamSqlWrite2HudiTest");
}
public static class Student{
public Long id;
public String name;
public Long age;
public String hobby;
public Student() {
}
public Student(Long id, String name, Long age, String hobby) {
this.id = id;
this.name = name;
this.age = age;
this.hobby = hobby;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Long getAge() {
return age;
}
public void setAge(Long age) {
this.age = age;
}
public String getHobby() {
return hobby;
}
public void setHobby(String hobby) {
this.hobby = hobby;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
", hobby='" + hobby + '\'' +
'}';
}
}
}
通过查看Hudi表,证明3条数据写入成功:
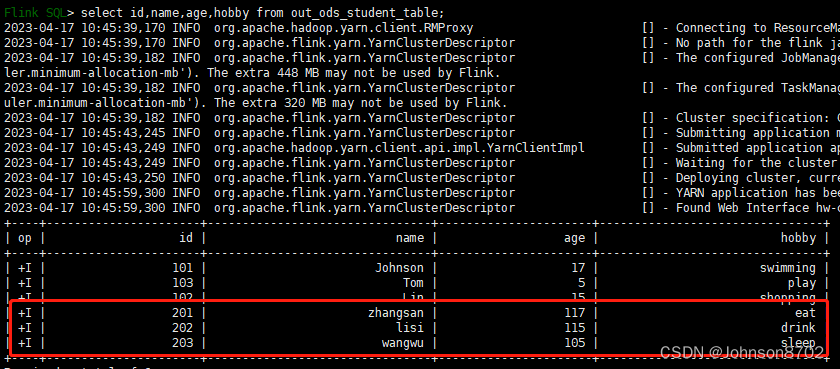
3.1.2 数据来自Table
package com.test.hudi;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.runtime.state.StateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FlinkValuesSqlWrite2HudiTest {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tabEnv = StreamTableEnvironment.create(env);
// 2.必须开启checkpoint 默认有5个checkpoint后,hudi目录下才会有数据;不然只有一个.hoodie目录
String checkPointPath = "hdfs://hw-cdh-test02:8020/flinkinfo/meta/savepoints/FlinkDataStreamWrite2HudiTest";
StateBackend backend = new EmbeddedRocksDBStateBackend(true);
env.setStateBackend(backend);
CheckpointConfig conf = env.getCheckpointConfig();
// 任务流取消和故障应保留检查点
conf.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
conf.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
conf.setCheckpointInterval(1000);//milliseconds
conf.setCheckpointTimeout(10 * 60 * 1000);//milliseconds
conf.setMinPauseBetweenCheckpoints(2 * 1000);//相邻两次checkpoint之间的时间间隔
conf.setCheckpointStorage(checkPointPath);
// 3.准备Hudi表的数据流,并将数据写入Hudi表
tabEnv.executeSql("" +
"CREATE TABLE out_ods_student_table(\n" +
" id BIGINT COMMENT '学号',\n" +
" name STRING\t COMMENT '姓名',\n" +
" age BIGINT COMMENT '年龄',\n" +
" hobby STRING COMMENT '爱好',\n" +
" PRIMARY KEY (id) NOT ENFORCED\n" +
")\n" +
"WITH(\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 'hdfs://hw-cdh-test02:8020/user/hive/warehouse/lake/ods_student_table',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'compaction.async.enabled' = 'true',\n" +
" 'compaction.tasks' = '1',\n" +
" 'compaction.trigger.strategy' = 'num_commits',\n" +
" 'compaction.delta_commits' = '3',\n" +
" 'hoodie.cleaner.policy'='KEEP_LATEST_COMMITS',\n" +
" 'hoodie.cleaner.commits.retained'='30',\n" +
" 'hoodie.keep.min.commits'='35' ,\n" +
" 'hoodie.keep.max.commits'='40'\n" +
")");
tabEnv.executeSql("" +
"insert into out_ods_student_table values\n" +
" (301, 'xiaoming', 201, 'read'),\n" +
" (302, 'xiaohong', 202, 'write'),\n" +
" (303, 'xiaogang', 203, 'sing')");
env.execute("FlinkValuesSqlWrite2HudiTest");
}
}
通过查看Hudi表,证明3条数据写入成功:
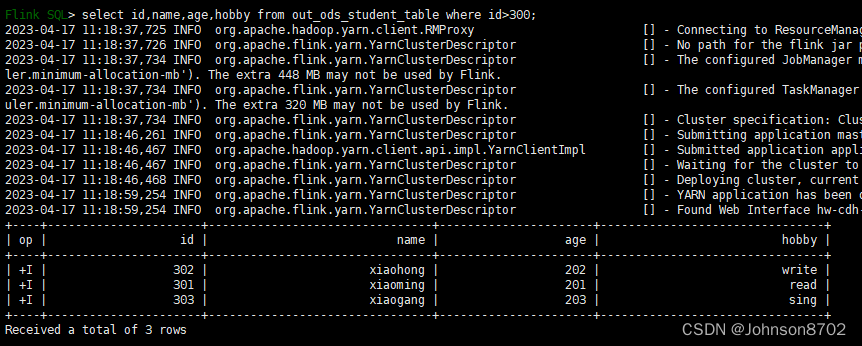
3.2 读Hudi
package com.test.hudi;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FlinkSqlReadFromHudiTest {
public static void main(String[] args) throws Exception {
// 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tabEnv = StreamTableEnvironment.create(env);
// 2.准备Hudi表的数据流,并从Hudi表读取数据
tabEnv.executeSql("" +
"CREATE TABLE out_ods_student_table(\n" +
" id BIGINT COMMENT '学号',\n" +
" name STRING\t COMMENT '姓名',\n" +
" age BIGINT COMMENT '年龄',\n" +
" hobby STRING COMMENT '爱好',\n" +
" PRIMARY KEY (id) NOT ENFORCED\n" +
")\n" +
"WITH(\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 'hdfs://hw-cdh-test02:8020/user/hive/warehouse/lake/ods_student_table',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'compaction.async.enabled' = 'true',\n" +
" 'compaction.tasks' = '1',\n" +
" 'compaction.trigger.strategy' = 'num_commits',\n" +
" 'compaction.delta_commits' = '3',\n" +
" 'hoodie.cleaner.policy'='KEEP_LATEST_COMMITS',\n" +
" 'hoodie.cleaner.commits.retained'='30',\n" +
" 'hoodie.keep.min.commits'='35' ,\n" +
" 'hoodie.keep.max.commits'='40'\n" +
")");
tabEnv.executeSql("select id,name,age,hobby from out_ods_student_table").print();
env.execute("FlinkSqlReadFromHudiTest");
}
}
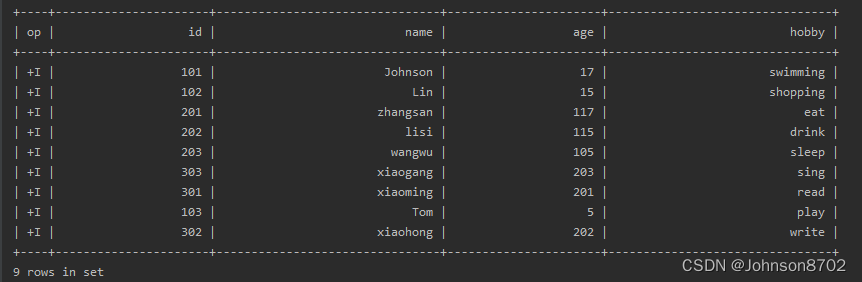
输出结果:
四、补充
在Flink Table操作Hudi的时候,可能会涉及到联合组件,可以在SQL中加入联合主键。比如:
tabEnv.executeSql("" +
"CREATE TABLE out_ods_userinfo_table_test(\n" +
" province_id BIGINT COMMENT '省份编号',\n" +
" user_id BIGINT COMMENT '用户编号',\n" +
" name STRING\t COMMENT '姓名',\n" +
" age BIGINT COMMENT '年龄',\n" +
" hobby STRING COMMENT '爱好',\n" +
" PRIMARY KEY (province_id,user_id) NOT ENFORCED\n" +
")\n" +
"WITH(\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 'hdfs://hw-cdh-test02:8020/user/hive/warehouse/lake/ods_userinfo_table_test',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'hoodie.datasource.write.keygenerator.class'='org.apache.hudi.keygen.ComplexKeyGenerator',\n" +
" 'hoodie.datasource.write.recordkey.field'= 'province_id,user_id',\n" +
" 'compaction.async.enabled' = 'true',\n" +
" 'compaction.tasks' = '1',\n" +
" 'compaction.trigger.strategy' = 'num_commits',\n" +
" 'compaction.delta_commits' = '3',\n" +
" 'hoodie.cleaner.policy'='KEEP_LATEST_COMMITS',\n" +
" 'hoodie.cleaner.commits.retained'='30',\n" +
" 'hoodie.keep.min.commits'='35' ,\n" +
" 'hoodie.keep.max.commits'='40'\n" +
")");