正则化
- (一) 拟合与欠拟合
- (二) 正则化的目的
- (三) 惩罚项
- (3.1)常用的惩罚项:
- (3.2)L-P范数:
- (3.3)L1与L2的选择:
(一) 拟合与欠拟合
欠拟合:
是指测试级与训练集都不理想。
过拟合:
训练集的结果准确但测试集的训练结果不理想,模型不适用。
(二) 正则化的目的
正则化就是防止过拟合,增加模型的鲁棒性 robust,鲁棒是 Robust 的音译,也就是强壮的意思。就像计算机软件在面临攻击、网络过载等情况下能够不死机不崩溃,这就是该软件的鲁棒性。鲁棒性调优就是让模型拥有更好的鲁棒性,也就是让模型的泛化能力和推广能力更加的强大。
(三) 惩罚项
正则化(鲁棒性调优)的本质就是牺牲模型在训练集上的正确率来提高推广能力,
W 在数值上越小越好,这样能抵抗数值的扰动。同时为了保证模型的正确率 W 又不能极小。故而人们将原来的损失函数加上一个惩罚项,这里面损失函数就是原来固有的损失函数,比如回归的话通常是 MSE,分类的话通常是 cross entropy 交叉熵,然后在加上一部分惩罚项来使得计算出来的模型 W 相对小一些来带来泛化能力。
(3.1)常用的惩罚项:

其中:
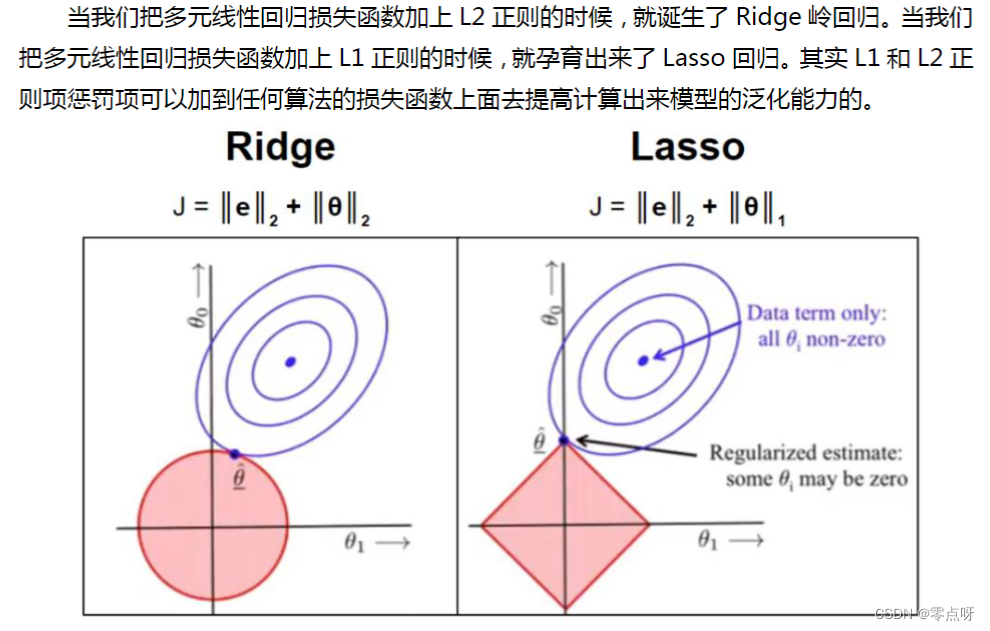
(3.2)L-P范数:

(3.3)L1与L2的选择:
L1 正则会使得计算出来的模型有的 W 趋近于 0,有的 W 相对较大,而 L2 会使得 W 参数整体变小。


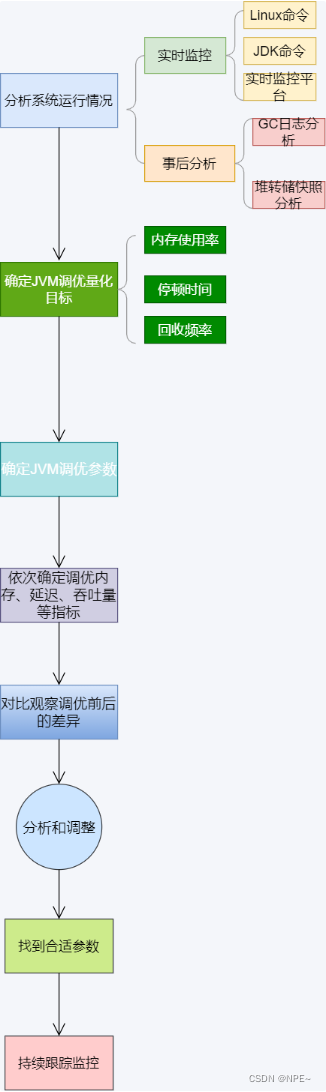
![[abc复盘] abc297 20230409](https://img-blog.csdnimg.cn/c76ede8bf7f6457db4997c659245a528.png)