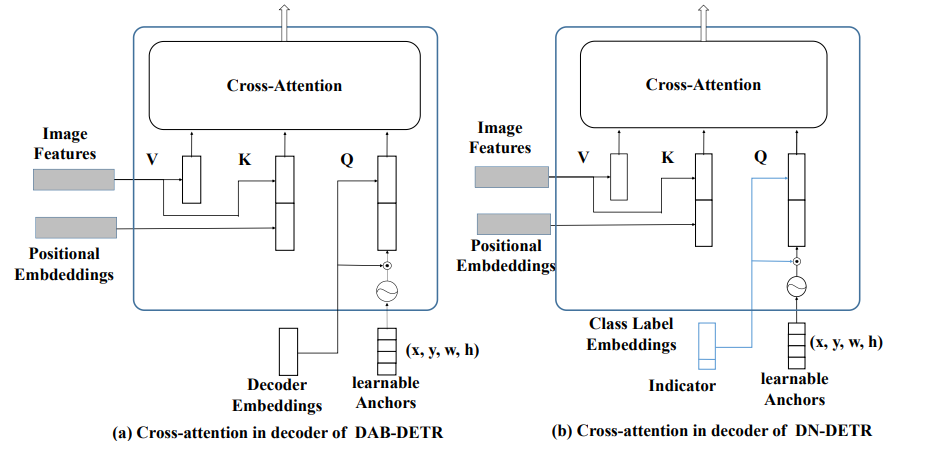
DN-DETR是在DAB-DETR的基础上完成的,DN-DETR的作者认为导致DETR类模型收敛慢的原因在于匈牙利匹配所导致的二义性,即匈牙利算法匹配的离散性和模型训练的随机性,导致ground-truth的匹配变成了一个动态的、不稳定的过程。举个例子,在epoch=8时,1号预测框与2号真实框匹配,但到了epoch=9时,5号预测框与2号真实框相匹配。这种不确定性将会导致模型在前期要消耗大量的资源来学习特征(损失函数的计算是对通过匈牙利算法匹配上的预测框与真实框来进行计算,而匹配的不稳定性自然会使其学习困难)
故而,DN-DETR的作者提出使用一个denoising task作为一个shortcut来学习相对偏移,它跳过了匹配过程直接进行学习。如果把query看作四维坐标,可以通过在真实框附近添加一个微小的扰动作为噪声,这样我们的denoising task就有了一个清晰的目标–直接重建真实框而不需要匈牙利匹配。
如此一来,输入是通过对 gt 加噪而获得,输出是为了去重构原来的 gt。
同时,由于所加的噪声都很小,因此模型也比较容易根据这些噪声输入去预测对应的 gt,从而降低了学习的难度。并且,学习的目标很明确,通过哪个 gt 加噪而来的输入,就会负责预测对应的那个 gt,这也避免了匈牙利匹配中存在的二义性现象。这就是一条捷径,匈牙利匹配结果与加入噪声的预测结果都将计算loss,这就相当于告诉每个query应该去找哪个target。这样也就提升了训练收敛速度。
Decoder Query构造
那么这个query是如何构造的呢,其结构图如下:
我们举一个简单例子来介绍下query的构造过程。
首先,将原本的Decoder-Embeding变为了Class Label Embeding,这里的改变只是变个名字罢了,方便我们理解。
随后假设 batch-size=3,image0中有9个target,image1中有1个target,image2中有2个target,总计12个target。设置加入噪声的group组为5组,设置类别噪声比例为0.2,x,y,w,h噪声比例为0.4。
即12个target,5组,那么有12X5=60个真实框,0.2作为比例或阈值,比如取60X0.2=12个target加入类别噪声,即将其真实类别替换为其他类别,这个比例可以随便取。0.4则是box的xy偏移比例与wh的缩放比例
接着我们取3个batch中最大的target的数量,在这里为9,由于group=5,所有5X9=45,构造噪声query的结构为【3,45,256】,这里注意256的最后一维为indicator标识,值为1,代表噪声。
同样的沿用DAB-DETR的query构造方式为【3,300,256】,此时256最后一维indicator=0;
同理构造learnable Anchor为【3,45,4】,原始为【3,300,4】
将其cat起来,得到class label embeding为【3,345,256】
learnable Anchor为【3,345,4】随后送入Decoder进行计算。如上图所示。
代码实现
match query构造
以下部分还未涉及到去噪部分的 queries,为了让去噪任务与匈牙利匹配任务兼容,需要对后者的 queries 也做些改动。主要是将 queries 的 content 部分(以下代码中的 tgt)初始化为 non-object class,并且加入值为 0 的 indicator 向量用作指示这部分 queries 是做匈牙利匹配任务的。
def prepare_for_dn(dn_args, embedweight, batch_size, training, num_queries, num_classes, hidden_dim, label_enc):
"""
prepare for dn components in forward function
Args:
dn_args: (targets, args.scalar, args.label_noise_scale,
args.box_noise_scale, args.num_patterns) from engine input
embedweight: positional queries as anchor
training: whether it is training or inference
num_queries: number of queries
num_classes: number of classes
hidden_dim: transformer hidden dimenstion
label_enc: label encoding embedding
Returns: input_query_label, input_query_bbox, attn_mask, mask_dict
"""
if training:
# targets 是 List[dict],代表1个 batch 的标签,其中每个 dict 是每張圖的标签
# scalar 代表的是 dn groups,去噪的组数,默认是 5
targets, scalar, label_noise_scale, box_noise_scale, num_patterns = dn_args
else:
num_patterns = dn_args
if num_patterns == 0:
num_patterns = 1
''' 原始 DETR 匹配任务的 content & position queries '''
# content 部分
# 用於指示匹配(matching)任務的向量,先初始化300*1,全部为0.shape (300,1)
indicator0 = torch.zeros([num_queries * num_patterns, 1]).cuda()
# label_enc 是 nn.Embedding(),其 weight 的 shape 是 (num_classes+1, hidden_dim-1)
# 第一維之所以是 num_classes+1 是因為以下 tgt 的初始化值是 num_classes,因此要求 embedding 矩陣的第一維必須有 num_classes+1;
# 而第二維之所以是 hidden_dim-1 是因為要留一個位置給以上的 indicator0
# 由于去噪任务的 label noise 是在 gt label(0~num_classes-1) 上加噪,
# 因此这里 tgt 的初始化值是 num_classes,代表 non-object,以区分去噪任(dn)务和匹配(matching)任务
# (hidden_dim-1,)->(num_queries*num_patterns,hidden_dim-1)
tgt = label_enc(torch.tensor(num_classes).cuda()).repeat(num_queries * num_patterns, 1)
# (num_queries*num_patterns,hidden_dim)
tgt = torch.cat([tgt, indicator0], dim=1)
# position 部分
# (num_queries,4)->(num_query*num_patterns,4)
refpoint_emb = embedweight.repeat(num_patterns, 1)
接下来,就真正开始对去噪部分“动手”了,首先是为噪声 queries 分配标签:
dn query构造
训练期间,引入去噪任务相关的部分
''' 计算一些索引,以便后续计算 loss 时用作 query & gt 的匹配 '''
# list 中的每個都是值為 1 shape 為 (num_gt_img,) 的張量
# 注意,每個張量的 shape 不一定一樣,因為每張圖片的 gt 數量不一定一致
known = [(torch.ones_like(t['labels'])).cuda() for t in targets]

# 该 batch 里每张图中各 gt 在圖片中的 index
# torch.nonzero() 返回的是張量中值不為0的元素的索引,list 中的每個張量 shape 是 (num_gt_img,1)
know_idx = [torch.nonzero(t) for t in known]
# 该 batch 中各圖片的 gt 數量
known_num = [sum(k) for k in known] #第一张是9,第二张1,第三张2

# 对 gt 在整个 batch 中计算索引
# (num_gts_batch,) 其中每個值都是1
unmask_bbox = unmask_label = torch.cat(known)

# (num_gts_batch,1)
known_indice = torch.nonzero(unmask_label + unmask_bbox)
# (num_gts_batch,)
known_indice = known_indice.view(-1)
# “复制”到所有去噪组
# (num_gts_batch,)->(scalar,num_gts_batch)->(scalar*num_gts_batch)
known_indice = known_indice.repeat(scalar, 1).view(-1)

取出真实标签
# gt labels 取出真实标签 (num_gts_batch,)
labels = torch.cat([t['labels'] for t in targets])

取出真实box
# gt boxes (num_gts_batch,4)
boxes = torch.cat([t['boxes'] for t in targets])

获取每个target所对应的图片
# 每張圖片的 batch 索引,這個變量用於代表各圖片是第幾張圖
# (num_gts_batch,)
batch_idx = torch.cat([torch.full_like(t['labels'].long(), i) for i, t in enumerate(targets)])

重复5组
# 将以上“复制”到所有去噪组
# (num_gts_batch,4)->(scalar*num_gts_batch,4)
known_bboxs = boxes.repeat(scalar, 1)
# (num_gts_batch,)->(scalar*num_gts_batch,)
known_labels = labels.repeat(scalar, 1).view(-1)
# (num_gts_batch,)->(scalar*num_gts_batch,)
known_bid = batch_idx.repeat(scalar, 1).view(-1)
对labels与boxs进行克隆

# 用於在 gt labels上加噪
known_labels_expaned = known_labels.clone()
# 用於在 gt boxes 上加噪
known_bbox_expand = known_bboxs.clone()

很直观,标签的分配就是将所有 gt(包括 labels & boxes)在 S 个去噪组(dn group)中的每个都 copy 一份,比如1个 batch 中 gt 的数量为 num_gt,那么总的标签数量就是 num_gt x S。
对 gt labels 加噪
标签制作完毕,是时候开始加噪了,先来对 gt labels 加噪(类别“翻转”):
# label_noise_scale 是用於 gt classes 的噪聲概率,默認是 0.2,即有20%的噪聲比例
if label_noise_scale > 0:
# (scalar*num_gts_batch,) 从均匀分布中采样
p = torch.rand_like(known_labels_expaned.float())
# (scalar*num_gts_batch,)
chosen_indice = torch.nonzero(p < (label_noise_scale)).view(-1) # usually half of bbox noise
首先生成60个随机数(0-1之间),然后判断如果该随机数小于0.2,则将其所对应的标签进行翻转。被选择的16个id

获得new label,改成不同的类别id
# paper 中的 'flip' 操作,随机分配类别
new_label = torch.randint_like(chosen_indice, 0, num_classes) # randomly put a new one here
# 在 dim0 中使用 chosen_indice 作為 index,new_label 作為值
known_labels_expaned.scatter_(0, chosen_indice, new_label)

随后将原始的query与加入噪声的query构造在一起。
m = known_labels_expaned.long().to('cuda')
# 加噪後的類別標籤對應的 embedding 向量
# (scalar*num_gts_batch)->(scalar*num_gts_batch,hidden_dim-1)
input_label_embed = label_enc(m)
# 用於指示去噪(dn)任務的向量
# (scalar*num_gts_batch,1)
indicator1 = torch.ones([input_label_embed.shape[0], 1]).cuda()
# 作为去噪任务的 content quries
# add dn part indicator
# (scalar*num_gts_batch,hidden_dim)
input_label_embed = torch.cat([input_label_embed, indicator1], dim=1)
逻辑很简单,首先,从均匀分布中采样噪声,使得每个 gt 都有一定机率将其类别“翻转”(替换)为其它类别(根据代码实现,其实翻转后有可能是原类别);然后,计算翻转后的 embedding 向量;最后,加入值为 1 的 indicator 指示向量,用以和匈牙利匹配任务的 quries 作区分。
紧接着,对 gt boxes 加噪(中心位移&尺度缩放):
对 gt boxes 加噪
# noise on the box
# box_noise_scale 是用於 gt boxes 的 scale 超參(paper 中的 lambda),默認是 0.4
if box_noise_scale > 0:
# 噪聲偏移量,作用在 gt boxes 上以實現中心點位移以及尺度縮放
# (scalar*num_gts_batch,4)
diff = torch.zeros_like(known_bbox_expand)
# bbox 中心點坐標: w/2,h/2
diff[:, :2] = known_bbox_expand[:, 2:] / 2
# bbox 寬高: w,h
diff[:, 2:] = known_bbox_expand[:, 2:]
# 在原 gt boxes 上加上偏移量,并且保证加噪后框的中心点在原来的框内
# torch.rand_like(known_bbox_expand) * 2 - 1.0 的值域是 [-1,1)
known_bbox_expand += torch.mul((torch.rand_like(known_bbox_expand) * 2 - 1.0), diff).cuda() * box_noise_scale
known_bbox_expand = known_bbox_expand.clamp(min=0.0, max=1.0)
# 原 gt boxes 是 [0,1] 归一化的数值,于是这里进行反归一化
# (scalar*num_gts_batch,4)
input_bbox_embed = inverse_sigmoid(known_bbox_expand)
实际上完成的就是下面的工作:

将 batch 中所有图片的 queries 数量“对齐”到一致
在去噪任务中,由于每张图片的 gt 数量不一致,而在每个 dn group 中 query 与 gt 是一对一的,从而导致每张图片的 queries 数量不一致,无法组成1个 batch 的 tensor。比如image0 有9个target,image1有1个target,image2有2个target。为了保持一致,选择最大的9,由于5组,则为45,即将所有的target统一为45。
因此,我们需要进行 ‘padding’,将每张图片的 queries 数量都 pad 到一致:
''' padding: 使得该 batch 中每張圖都擁有相同數量的 noised labels & noised boxes '''
# 該 batch 中一張圖最多的 gt 數量
single_pad = int(max(known_num))
# 将以上“扩展”到所有去噪组
pad_size = int(single_pad * scalar)
padding_label = torch.zeros(pad_size, hidden_dim).cuda()
padding_bbox = torch.zeros(pad_size, 4).cuda()
''' 將去噪(dn)任務和匹配(matching)任務的 queries 拼接在一起 '''
# (batch_size,pad_size + num_queries*num_patterns,hidden_dim)
input_query_label = torch.cat([padding_label, tgt], dim=0).repeat(batch_size, 1, 1)
# (batch_size,pad_size + num_queries*num_patterns,4)
input_query_bbox = torch.cat([padding_bbox, refpoint_emb], dim=0).repeat(batch_size, 1, 1)
''' 由于以上 input_query_label & input_query_bbox 是 padded 的,
因此要将每张图片真实有效的 noised lables(前面的 input_label_embed) & noised boxes(前面的 input_bbox_embed) 放到正确的位置上 '''
# map in order
map_known_indice = torch.tensor([]).to('cuda')
if len(known_num):
# 将 gt 在其所在圖片中排序,以计算索引
# 以下 List 中每个 tensor 的值域是 [0,num_gt_img-1]
# (num_gts_batch,)
map_known_indice = torch.cat([torch.tensor(range(num)) for num in known_num])
# 计算出去噪任务中真实有效的(非 padding 的) queries 对应的索引
# 給每個去噪組加上一個對應的 offset,使得不同去噪組的 indices 可區分
# i 的值域是 [0, scalar-1],以上 map_known_indice 的值域是 [0,single_pad-1],
# 因此以下计算出的 map_known_indice 的值域不會超過 pad_size(即 single_pad * scalar)
# (num_gts_batch*scalar,)
map_known_indice = torch.cat([map_known_indice + single_pad * i for i in range(scalar)]).long()
if len(known_bid):
# 將去噪任务中真实有效的 noised lables & noised boxes “塞”到正确的位置上
# known_pid 和 map_known_indice 的 shape 都是 (scalar*num_gts_batch),一一对应
input_query_label[(known_bid.long(), map_known_indice)] = input_label_embed
input_query_bbox[(known_bid.long(), map_known_indice)] = input_bbox_embed
在这里map_know_indice的每组分别加0,9,18,27,36。最终加上偏移后在0-45以内,共计加5次,此时就可与【3,45,245】的前45个对应了。

known_bid代表的是每个target所属的图片

开始时input_query_lable与input_query_box为0

检测一下input_query_label[(known_bid.long(), map_known_indice)] = input_label_embed代表什么
其为(所属图片id,对应的噪声框id),即完成了图片与噪声query的对齐。
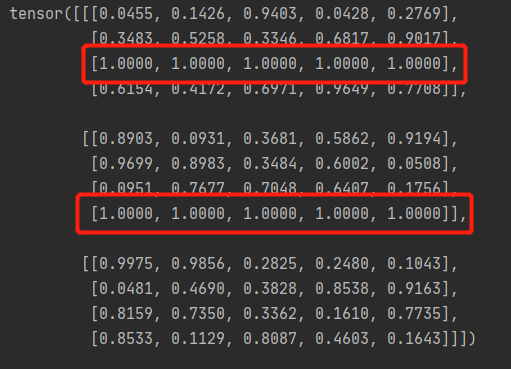
测试如下:分别替换【0,2】【1,3】
import torch
map=torch.rand((3,4,5))
print(map)
index=[0,1]
index1=[2,3]
map[(index,index1)]=1
print(map)
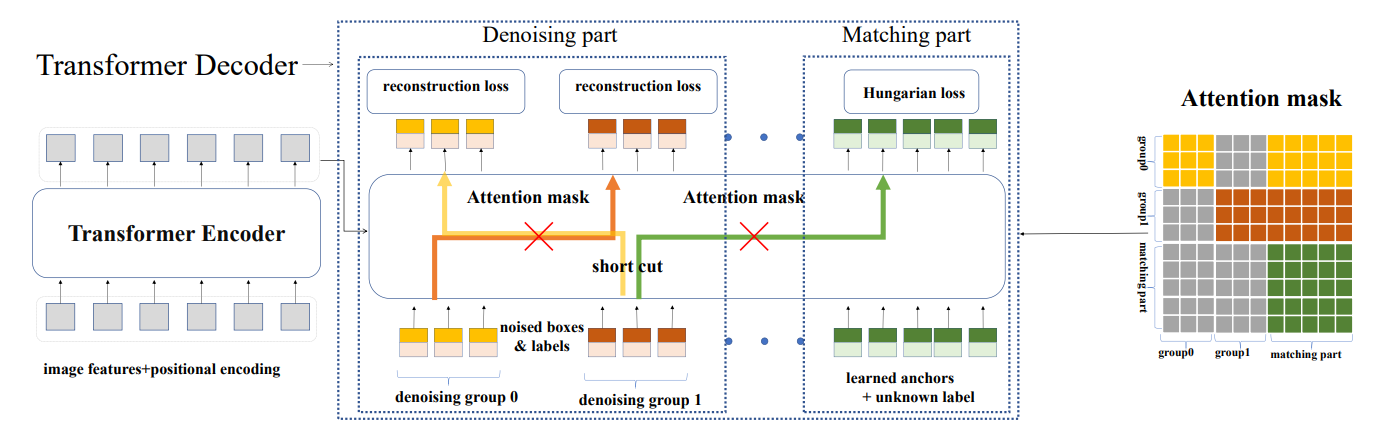
attention mask
加入噪声后,还需要注意的一点便是信息之间的是否可见问题,噪声 queries 是会和匈牙利匹配任务的 queries 拼接起来一起送入 transformer 中的。在 transformer 中,它们会经过 attention 交互,这势必会得知一些信息,这是作弊行为,是绝对不允许的。好在attention中有个防窥利器:attention mask
因此,需要“有针对性”地去设计这个 attention mask。
怎么个有针对性法?
首先,如上所述,匈牙利匹配任务的 queries 肯定不能看到 DN 任务的 queries。
其次,不同 dn group 的 queries 也不能相互看到。为何?因为综合所有组来看,gt -> query 是 one-to-many 的,每个 gt 在每组都会有 1 个 query 拥有自己的信息。于是,对于每个 query 来说,在其它各组中都势必存在 1 个 query 拥有自己负责预测的那个 gt 的信息。
接着,同一个 dn group 的 queries 呢?没关系!尽情看吧 。因为在每组内,gt -> query 是 one-to-one 的关系,对于每个 query 来说,其它 queries 都不会有自己 gt 的信息。
最后,DN 任务的 queries 可以去看匈牙利匹配任务的 queries 吗?Em… 大方点,看吧!毕竟前者才拥有 gt 信息,而后者是“凭空构造”的(主要是先验,需要自己去学习)。
总的来说,attention mask 的设计归纳为:
- 匈牙利匹配任务的 queries 不能看到 DN任务的 queries;
- DN 任务中,不同组的 queries 不能相互看到;
- 其它情况均可见
构造后的attention mask如下图所示:
代码实现
由上可知attention mask 的设计在 DN-DETR 中很是关键,如果没有这一 part,那模型会成为通过作弊而拿到高分的坏家伙,并不能真正学到东西。
# 去噪任务 & 匹配任务 的 queries 总数
tgt_size = pad_size + num_queries * num_patterns
# (i,j) = True 代表 i 不可見 j
attn_mask = torch.ones(tgt_size, tgt_size).to('cuda') < 0
# match query cannot see the reconstruct
# 令匹配任務的 queries 看不到做去噪任務的 queries,因為後者含有真實標籤的信息
attn_mask[pad_size:, :pad_size] = True
# reconstruct cannot see each other
# 对于去噪任务的 queries,只有同组内的相互可见,避免跨组泄露真實標籤的信息,
# 因为每组中,gt 和 query 是 one-to-one 的。
# 于是,在同一组内,对于每个 query 来说,其它 queries 都不会有自己 gt 的信息
for i in range(scalar):
if i == 0:
attn_mask[single_pad * i:single_pad * (i + 1), single_pad * (i + 1):pad_size] = True
if i == scalar - 1:
attn_mask[single_pad * i:single_pad * (i + 1), :single_pad * i] = True
else:
attn_mask[single_pad * i:single_pad * (i + 1), single_pad * (i + 1):pad_size] = True
attn_mask[single_pad * i:single_pad * (i + 1), :single_pad * i] = True
首先,最重要的是要保证匈牙利匹配任务的 queries 不能看到去噪任务的 queries,因为后者包含了真实标签的信息;其次,对于同是去噪任务的 queries,也要避免跨组泄露信息。
返回兼容去噪任务与匈牙利匹配任务的处理结果
最后就是将以上处理的结果作为 transformer 的输入,这个结果兼容了去噪任务与匈牙利匹配任务,同时也考虑了训练与推理时的差异。
mask_dict = {
'known_indice': torch.as_tensor(known_indice).long(), # (scalar*num_gts_batch,) 每个 gt 在整个 batch 中的索引
'batch_idx': torch.as_tensor(batch_idx).long(), # (num_gts_batch,) 每个 gt 所在图片的 batch 索引
'map_known_indice': torch.as_tensor(map_known_indice).long(), # (num_gts_batch*scalar,) 噪声 queries(非 padding 的) 的索引
'known_lbs_bboxes': (known_labels, known_bboxs), # (scalar*num_gts_batch,), (scalar*num_gts_batch,4)
'know_idx': know_idx, # List[Tensor]: 其中每個 Tensor 的 shape 是 (num_gt_img,1) 每个 gt 在其图片中的索引
'pad_size': pad_size # 该 batch 中噪声 queries 的数量(包括 padding 的)
}
# 推理时仅有原始 DETR 匹配任务的 queries
else:
# (num_queries*num_patterns,hidden_dim)->(batch_size,num_queries*num_patterns,hidden_dim)
input_query_label = tgt.repeat(batch_size, 1, 1)
# (num_query*num_patterns,4)->(batch_size,num_query*num_patterns,4)
input_query_bbox = refpoint_emb.repeat(batch_size, 1, 1)
attn_mask = None
mask_dict = None
# 將 batch 對應的維度置換到第二維(dim1),以適配 transformer 的輸入
# (num_queries,batch,hidden_dim)
input_query_label = input_query_label.transpose(0, 1)
# (num_queries,batch,4)
input_query_bbox = input_query_bbox.transpose(0, 1)
return input_query_label, input_query_bbox, attn_mask, mask_dict
分离去噪任务与匈牙利匹配任务的输出
由于在 transformer 输入端将去噪任务与匈牙利匹配任务的 queries 拼接到了一起,因此在输出端需要将它们分离,以便计算各自的 loss。
def dn_post_process(outputs_class, outputs_coord, mask_dict):
"""
post process of dn after output from the transformer
put the dn part in the mask_dict
"""
# 分離 去噪(dn)任務 和 原始 DETR 匹配(matching)任務 的預測結果
if mask_dict and mask_dict['pad_size'] > 0:
# 取出去噪任務的預測結果
# (num_layers,batch,pad_size,num_classes)
output_known_class = outputs_class[:, :, :mask_dict['pad_size'], :]
# (num_layers,batch,pad_size,4)
output_known_coord = outputs_coord[:, :, :mask_dict['pad_size'], :]
# 將去噪任務的預測結果記錄到 mask_dict
mask_dict['output_known_lbs_bboxes'] = (output_known_class, output_known_coord)
# 讓 outputs_class & outputs_coord 保持為原始 DETR 匹配任務的預測結果,與原始 DETR 架構兼容
outputs_class = outputs_class[:, :, mask_dict['pad_size']:, :]
outputs_coord = outputs_coord[:, :, mask_dict['pad_size']:, :]
return outputs_class, outputs_coord
去噪任务的输出结果被放到 mask_dict 中,而 outputs_class & outputs_coord 保留为匈牙利匹配任务的输出,从而兼容了原模型的架构。